结合Bi-LSTM与VDCNN的社交网络攻击性言论识别方法
2022-12-30李永忠
李永忠 赵 艺
(福州大学经济与管理学院, 福建福州 350108)
社交网络语言攻击一般是指涉及分歧和言语敌意的网络骂战,通常包括各种文本元素的使用,如充满攻击性的和敌意的语言、脏话、贬义名称、负面评论、威胁和性不当评论。(1)刘梦玲:《新浪微博骂战结束方式的网络语用研究》,硕士学位论文,华侨大学外国语学院,2018年,第9页。社交网络语言攻击多发生于粉丝群体,当明星网红受到网民群体攻击时,粉丝为了维护他们的正面形象往往会群起攻之,感兴趣路人的不断加入和相关者的转发传播让事件不断发酵。事件的影响不断扩大,一是导致社交网络语言攻击本身在一定程度上掩盖事件真相,不利于网民理性思考问题;二是占用公共资源,错误引导舆论关注点;三是传递负面情绪,不利于营造积极向上的网络环境。
采用智能化手段及时识别社交网络语言攻击能够帮助察觉事件的发展态势,从而及时控制事件的进一步发展,有助于营造良性互动的“饭圈”文化。自然语言处理技术的发展逐步打破了人与计算机之间的沟通壁垒,文本情感分类技术能够帮助我们实现文本的自动分类和识别任务。社交网络语言攻击的识别可以看作一项特殊的攻击性言论识别任务,在机器学习领域,基于深度学习的攻击性言论识别表现出了比传统机器学习算法更为优异的成绩,在相关任务中已经成为研究主流。所以本文选取微博粉丝攻击性言论作为研究对象,运用自然语言处理领域的相关技术,融合VDCNN的基础架构和Bi-LSTM结构,以期实现社交网络语言攻击相关评论的识别,维护风清气正的网络环境。
一、文献综述
“饭圈”文化背景下,粉丝已经成为网络这一虚拟公共领域里一只数量庞大的舆论新军,非专一性、非崇拜性、攻击性的粉丝特征推动了社交网络语言攻击的形成。(2)靖鸣、王瑞:《微博“粉丝”:虚拟公共领域的舆论新军》,《新闻爱好者》2012年第19期。目前国内针对社交网络语言攻击的研究主要集中在社会学、新闻与传播学等领域。黄辉闪从心理学角度出发,探究了粉丝网络攻击的个体因素、群体因素、家庭因素、社会和文化因素。(3)黄辉闪:《EXO“对战”TFboys:从心理学角度浅析偶像粉丝团之间的骂战行为》,《河南教育学院学报》(自然科学版)2016年第1期。常乐融融指出,信息茧房造成的个体判断力的丧失、观点的极化以及网络群体的极化是粉丝网络攻击的重要成因。(4)常乐融融:《解析饭圈文化下的网络舆论暴力——由“蔡徐坤粉丝人肉辱骂网友事件”引发的思考》,《时代报告》2018年第7期。洪培琳分析了冲突视角下的粉丝骂战原因,认为宽松的媒体环境、社群认同感、年龄段特征以及微博营销导致粉丝骂战频发。(5)洪培琳:《冲突视角下的粉丝文化现象分析——浅谈粉丝微博骂战频发症候》,《现代营销》(下旬刊)2018年第1期。吴永珍选取社会交换理论和“使用与满足”理论对粉丝文化现象进行理论阐释,并将社交网络语言攻击频发的成因归咎于网络环境下的粉丝行为转换。(6)吴永珍:《浅析新媒体环境下的“粉丝”文化现象》,《新闻研究导刊》2019年第10期。曾潇基于网络舆论的蝴蝶效应模型分析了舆论的诱发因素及演化过程。(7)曾潇:《基于网络舆论“蝴蝶效应”模型的“肖战粉丝事件”分析》,《声屏世界》2021年第3期。
在深度学习领域,和社交网络语言攻击相关的攻击性言论识别任务在近几年得到了广泛关注。(8)万珂蓝:《攻击性言论识别的研究》,《现代计算机》2021年第6期。Badjatiya等使用多个深度学习框架实现Twitter 仇恨言论检测任务,实验结果表明CNN的仇恨言论检测能力优于LSTM并显著优于FastText。(9)Badjatiya P.,Gupta S.,Gupta M.,et al.,Deep Learning for Hate Speech Detection in Tweets, International World Wide Web Conferences Steering Committee, 2017.Park等在侮辱性语言检测任务中探索了两步分类器的有效性,建立了提取字符级别和单词级别特征的HybridCNN模型,实验结果表明,和一步分类器相比HybridCNN在该任务上的表现更为优异。(10)Ji H.P.,Fung P.,One-step and Two-step Classification for Abusive Language Detection on Twitter, Proceedings of the First Workshop on Abusive Language Online, 2017.Zhang等在推文的反讽检测任务中,使用了基于情感的迁移学习技术,提出了attention机制和Bi-LSTM的结合模型,融合了情感迁移学习提取的显式、隐式情绪特征和初次学习的语义特征,提升了模型在反讽检测任务上的表现。(11)Zhang S.,Zhang X.,Chan J.,et al.,“Irony detection via sentiment-based transfer learning”, Information Processing & Management,vol.56,no.5(2019),pp.1633-1644.卢欣等针对中文文本反讽识别展开研究,基于社交网络中的中文反讽自身特点归纳了显示语言特征,建立了结合特征矩阵和句子矩阵的双输入CNN,在人工标注的微博情感数据库上验证了语言特征提取和深度学习框架能够有效提升反讽识别的精度。(12)卢欣、李旸、王素格:《融合语言特征的卷积神经网络的反讽识别方法》,《中文信息学报》2019年第5期。万珂蓝将攻击性言论检测作为主任务、情感分析作为辅助任务,提出了多任务攻击性言论检测模型BMTD,在利用微调的BERT模型实现共享词嵌入的基础上,融合了注意力机制和Bi-LSTM进行特征提取及后续训练,验证了模型在中文微博攻击性言论数据集上的有效性。(13)万珂蓝:《基于多任务学习的网络攻击性言论检测与识别研究》,硕士学位论文, 四川大学计算机学院,2021年,第63页。Aluru等首次针对多语言仇恨言论进行了大规模分析, 使用MUSE+CNN-GRU、Translation+BERT、LASER+LR、mBert四种深度学习模型框架对来自16个数据集上的9种语言类型的仇恨言论进行多情景实验,结果表明,对于低资源语言,LASER + LR的表现更为出色;而对于高资源语言,BERT 模型的表现更好。(14)Aluru S.S.,Mathew B.,Saha P.,et al.,Deep learning models for multilingual hate speech detection, ECML-PKDD, 2020.Plaza-del-Arco等在进行了预训练模型和传统机器学习模型对比实验的基础上,使用BERT、XLM 和 BETO等多个多语言和单语言预训练模型解决了西班牙语仇恨言论的识别问题。(15)Plaza-del-Arco F.M.,Molina-González M.D.,Urena-López L. A.,et al.,“Comparing pre-trained language models for Spanish hate speech detection”,Expert Systems with Applications,vol.166(2021),pp.114-120.刘洋等利用神经网络模型融合Bi-LSTM提取文本和图片的特征,实现了不同模态间的知识交互,该模型在自构建的旅游评论数据集上的反讽识别能力优于各基线。(16)刘洋、马莉莉、张雯、胡忠义、吴江:《基于跨模态深度学习的旅游评论反讽识别》,《数据分析与知识发现》2022年第6期。师夏阳等针对低资源语言攻击性言论的标注语料匮乏问题,通过迁移跨语言预训练模型mBERT实现了对低资源语言的攻击性言论的自动检测。(17)师夏阳、张风远、袁嘉琪、黄敏:《基于多语BERT的无监督攻击性言论检测》,《计算机应用》2022年第6期 。袁明森收集了语境相关和语境无关的反讽语料集,使用CNN、LSTM、Attention+LSTM、主题模型+LSTM、主题模型+Attention+LSTM 等多种机器学习方法对反讽句子进行分类,其中主题模型+Attention+LSTM 在反讽语料集上表现最好。(18)袁明森:《基于网络文本的反讽识别方法研究》,硕士学位论文, 上海交通大学计算机科学与工程系,2020年,第57页。
攻击性言论识别任务的本质是对文本进行分类,但是攻击性言论识别任务不能直接应用于社交网络语言攻击的识别,主要有以下几个方面的原因:一是目前攻击性言论缺乏一个统一的定义,社交网络语言攻击相关的评论包含了大量的网络用语,比如“但是,他不皇谁皇”中的“皇”的意思是皇族,通常用于指代一个组合里成员资源分配不均时,资源过度倾斜的那位成员,因为这条评论中并没有表现出传统概念上的恶意辱骂、隐喻挖苦、歧视煽动和威胁恐吓等特点,在攻击性语言识别中很有可能被标注为不具有攻击性。二是目前用深层CNN进行攻击性言论识别的研究较少,深度学习在NLP领域的应用基本被RNN和LSTM垄断,而且基本是浅层网络。针对以上问题,本文提出了一种结合Bi-LSTM的深度卷积神经网络模型Bi-LSTM-VDCNN,通过与单一Bi-LSTM、单一VDCNN,其他Bi-LSTM和VDCNN混合模型以及基于深度学习的文本分类器进行对比,证明了该模型的可行性和优越性。
二、实验数据集及预处理
(一)实验数据采集与清洗

表1 数据集样例
为了实现对于社交网络语言攻击的识别,本文利用网络爬虫技术从新浪微博平台获取了粉丝评论共10063条,内容涉及55位艺人。采集到的部分粉丝评论如表1所示。
因为数据是直接采集自新浪微博的,所以语言不十分规范,为了规范数据格式,我们对采集到的数据进行了以下处理。
(1)去除无关词语。无关词语是指与评论文本表达的内容不相关的词汇,包括用户ID、姓名、昵称,以及新浪微博平台的默认注释比如查看动图、图片评论和网页链接等。
(2)去除含义不清楚的emoji和标点符号。比如长串的控评符号,如图1所示。

图1 布满控评符号的粉丝评论
(3)去除停用词。因为停用词不会影响评论文本的语义,所以去除停用词以保留精简有效的文本信息。
(二)样本标注
对清洗后的6860条粉丝评论进行样本标注,本研究在样本标注过程中不仅考虑到常见情绪,还根据讨论的背景充分考虑了反讽、嘲笑等情绪,对粉丝评论进行手工标注,其中攻击性言论3928条,非攻击性言论2932条。攻击性言论涵盖了愤怒、反讽、嘲笑等情绪,非攻击性言论则涵盖了欣赏、赞美、喜欢等情绪。
三、研究设计
(一)BERT
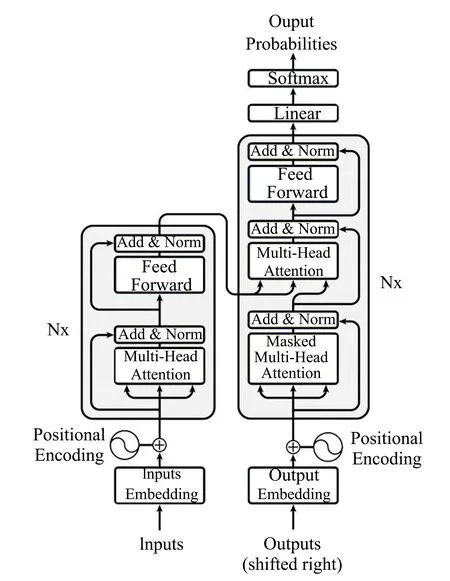
图2 Transformer模型结构
BERT是一种使用MLM目标生成双向特征表示的预训练语言表征的方法,BERT是多层Transformer编码器堆叠起来的模型结构,Transformer本质上是一个Encoder-Decoder,Encoder 和 Decoder 都包含 6 个 block。Transformer 的内部结构如图2所示。
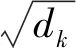
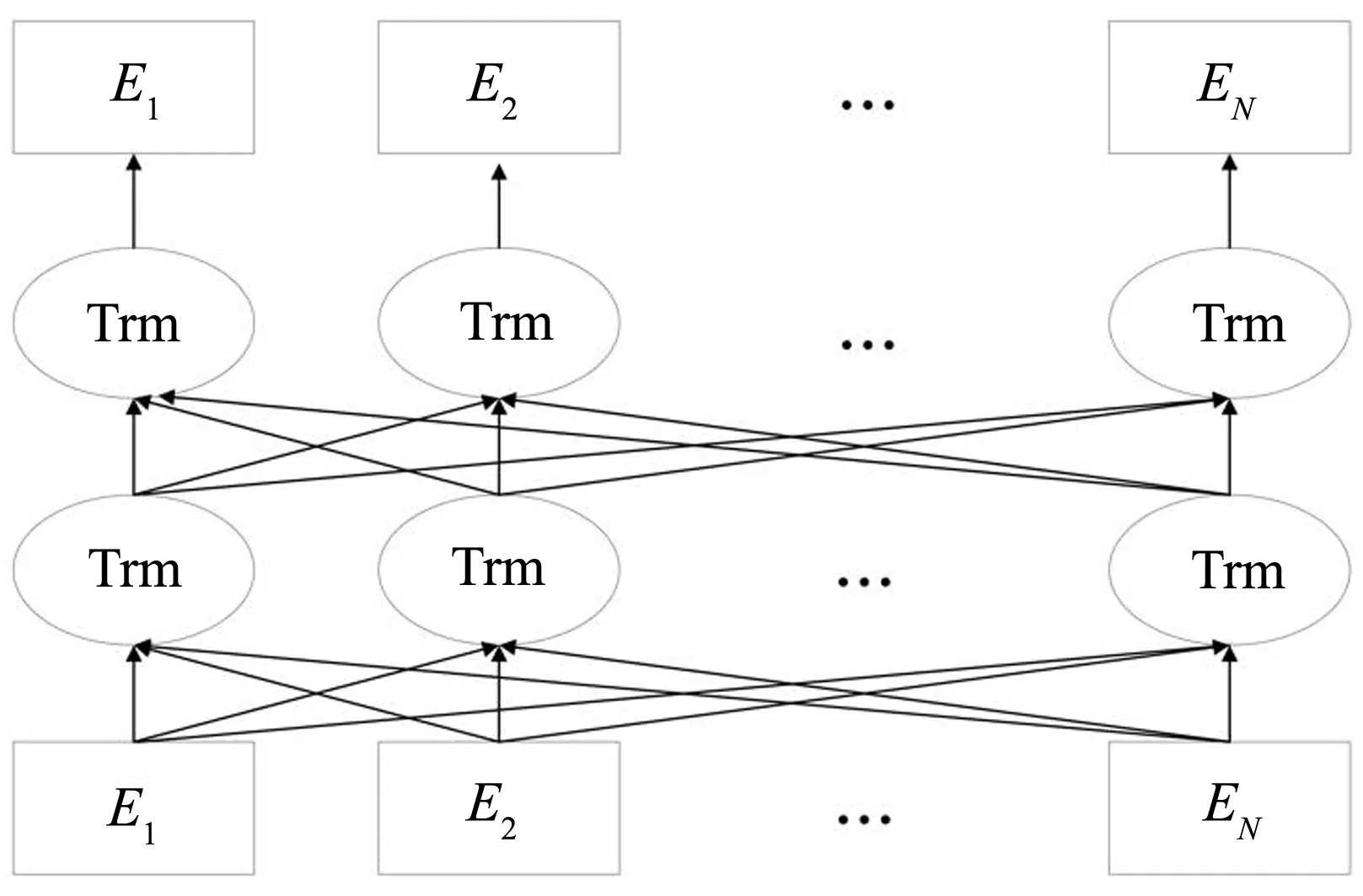
图3 BERT主体结构
BERT采用双向的Transformer的结构,经过多层Transformer结构的堆叠后,形成BERT的主体结构,如图3所示。因为BERT可以生成深度的双向的特征表示,所以预训练的BERT在利用特定领域的语料微调后广泛适用于先进模型的构建,不需要对架构进行大幅度的修改。
(二)VDCNN
CNN作为深度学习的经典算法之一,已经被广泛应用于机器视觉和自然语言处理等领域。CNN具有优秀的特征自提取能力,并且速度很快,在很多自然语言处理的任务中表现优异。大多数传统的CNN体系结构是基于单词的,需要学习合适的词嵌入方法作为它们训练过程的一部分。但是社交网络语言攻击中的网络用语具有创新性和不规范性等的特点,创新性意味着网络用语很难建立起一个专业全面的词库,即使建立起来了,也难以做到实时更新;不规范性则导致难以提炼出清晰的语法句法结构。
VDCNN模型由facebook的Alexis Conneau等提出,输入是以字符为单位,无须建立词库,契合了社交网络语言攻击中的网络用语的创新性和不规范性的特点。(19)Conneau A., Schwenk H., Barrault L., et al.,Very deep convolutional networks for text classification, https://arxiv.org/abs/1606.01781.同时,VDCNN利用深层网络进行文本分类,可以达到比传统CNN结构更好的效果。
(三)Bi-LSTM
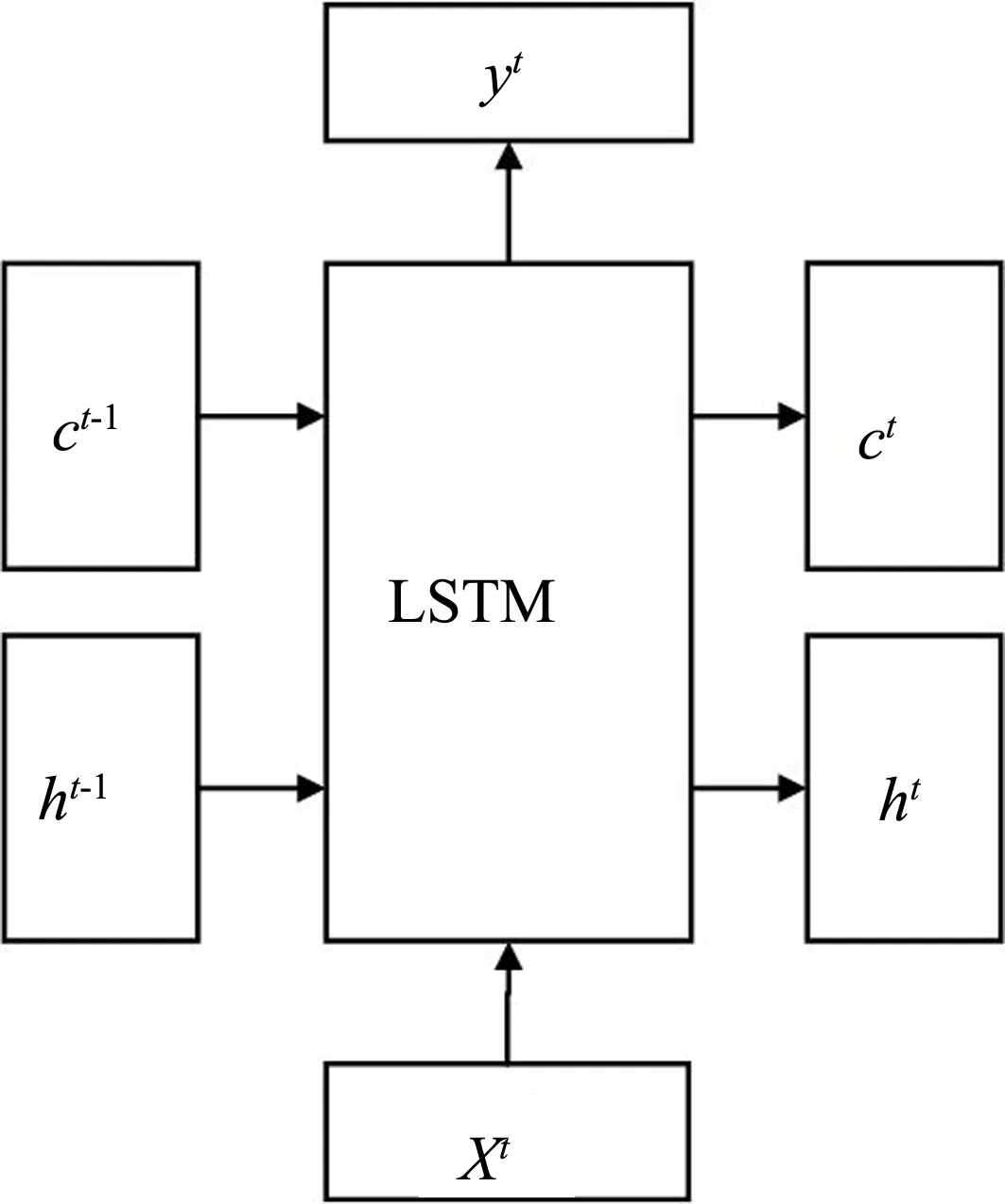
图4 LSTM外部结构
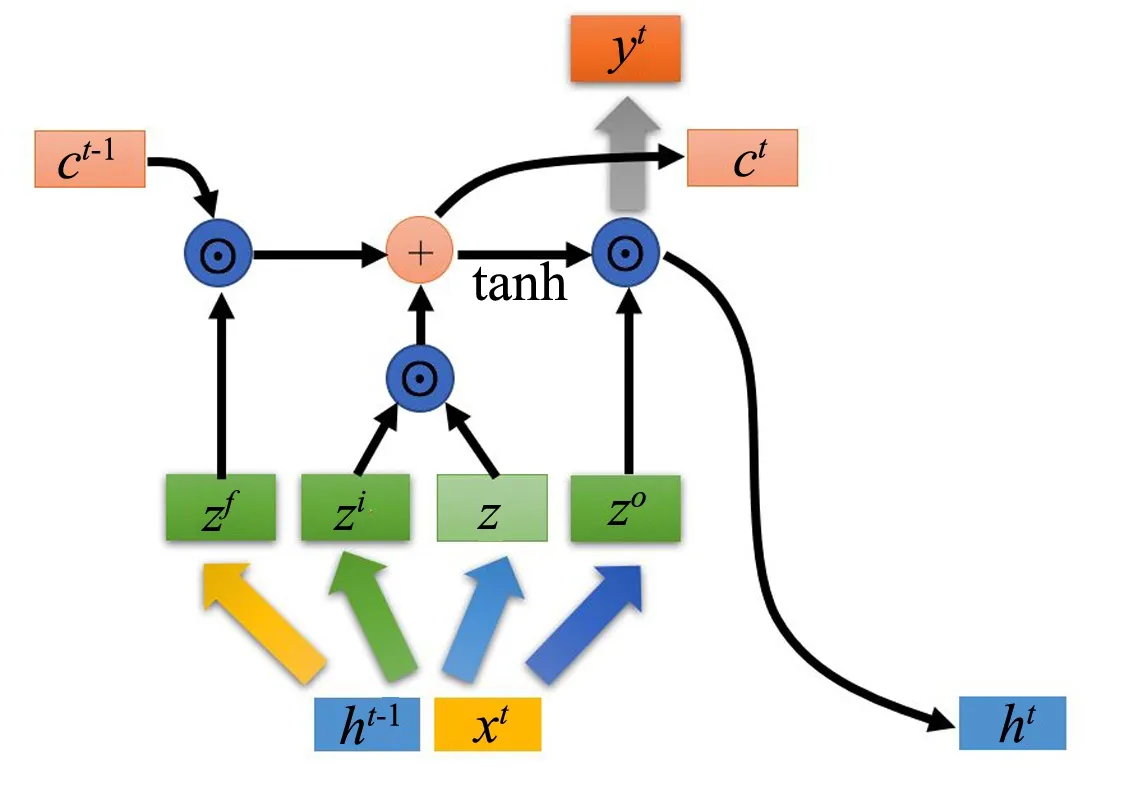
图5 LSTM内部结构
Bi-LSTM 由两个LSTM叠加而成,LSTM(长短期记忆网络,Long short-term memory)是一种可以处理长期依赖信息的特殊的RNN网络,在时序数据上有着优异的表现。LSTM的外部结构如图4所示。xt是当前输入,yt是输出,ct和ht是LSTM的两个传输状态。
LSTM使用当前输入xt和上一个状态传递下来的ht-1拼接得到四个状态。
z=tanh(w·[xt,ht-1]+b)
(1)
zi=σ(wi·[xt,ht-1]+bi)
(2)
zf=σ(wf·[xt,ht-1]+bf)
(3)
zo=σ(wo·[xt,ht-1]+bo)
(4)
其中,zi,zf,zo是由拼接向量乘以权重矩阵之后,通过一个sigmoid激活函数转换成0到1之间的数值,作为一种门控状态。而z则是将结果通过一个 tanh 激活函数将转换成-1到1之间的值。
LSTM的内部结构如图5所示。
LSTM内部主要有三个阶段:在忘记阶段,zf(f表示forget)作为忘记门控,来控制上一个状态的ct-1哪些需要留哪些需要忘。在选择记忆阶段,zi作为选择门控,对当前的输入z进行选择记忆。将上面两步得到的结果相加,即可得到传输给下一个状态的ct。在输出阶段,zo用来决定哪些将会被当成当前状态的输出。通过一个tanh激活函数进行变化,对上一阶段得到的ct进行放缩。得到隐层状态ht后,输出yt往往通过ht变化得到。具体计算过程如式(5)—(7)所示。
ct=zf⊙ct-1+zi⊙z
(5)
ht=zo⊙tanh(ct)
(6)
yt=σ(W′ht)
(7)
Bi-LSTM由前向LSTM与后向LSTM组合而成。通过Bi-LSTM可以更好地捕捉双向的语义依赖。
(四)Bi-LSTM-VDCNN模型架构
为了实现微博粉丝评论的分类任务,同时鉴于社交网络语言攻击中的网络用语的创新性、不规范性等特点,本文使用BERT文本嵌入作为输入来训练文本分类模型,基于VDCNN结构引入Bi-LSTM,捕捉文本数据中的时序信息、逻辑序列信息等其他序列信息,并将这类序列信息和CNN捕捉到的句子中类似于n-gram的局部相关性信息融合起来,建立Bi-LSTM-VDCNN模型,从而实现文本的特征融合,模型的结构如图6所示。
1. 输入数据表示
对于输入数据的表示是NLP中重要的环节,是对文本数据进行特征提取和分类预测的前提。作为网络模型的输入,一条评论文本要表示为网络能够接受并处理的序列向量。设共有t条评论文本,每条评论文本d由n个字符组成,第i条评论文本可以表示为di={wi1,wi2,…,win}(i=1,2,…,t),其中w代表字符。首先,使用BERT Tokenizer把文本切分成一个字符串序列并转换成模型可以处理的数字ID,第i个字符串序列可以表示为Si={si1,si2,…,sin}(i=1,2,…,t)。然后,Embedding层对字符进行映射处理,映射为128维的字符向量。
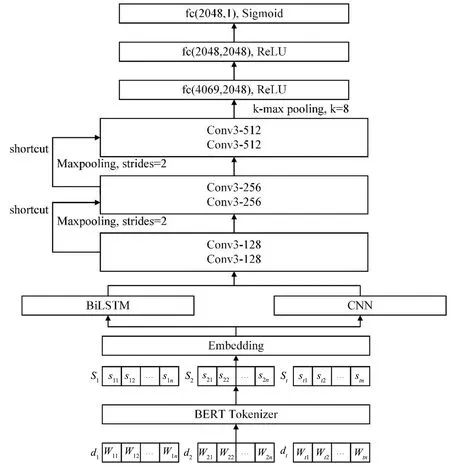
图6 Bi-LSTM-VDCNN模型架构
2. 特征提取和分类预测
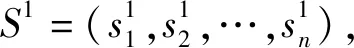
(1)Bi-LSTM对S1进行双向序列信息的提取,得到输出向量Y1,Y1包含了S1的时间序列信息、语义序列信息等其他序列信息。
(2)Conv1对S1执行卷积操作,若卷积核的大小为k,则第j个窗口的输入张量可表示为:
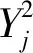
其中,W表示权重,b表示偏置。
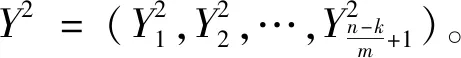
(3)把输出向量Y1和输出向量Y2作向量加法运算得到Y=Y1+Y2,从而将Bi-LSTM捕捉的文本数据中的时序信息、逻辑序列信息等其他序列信息和CNN捕捉到的句子中类似于n-gram的局部相关性信息融合起来。
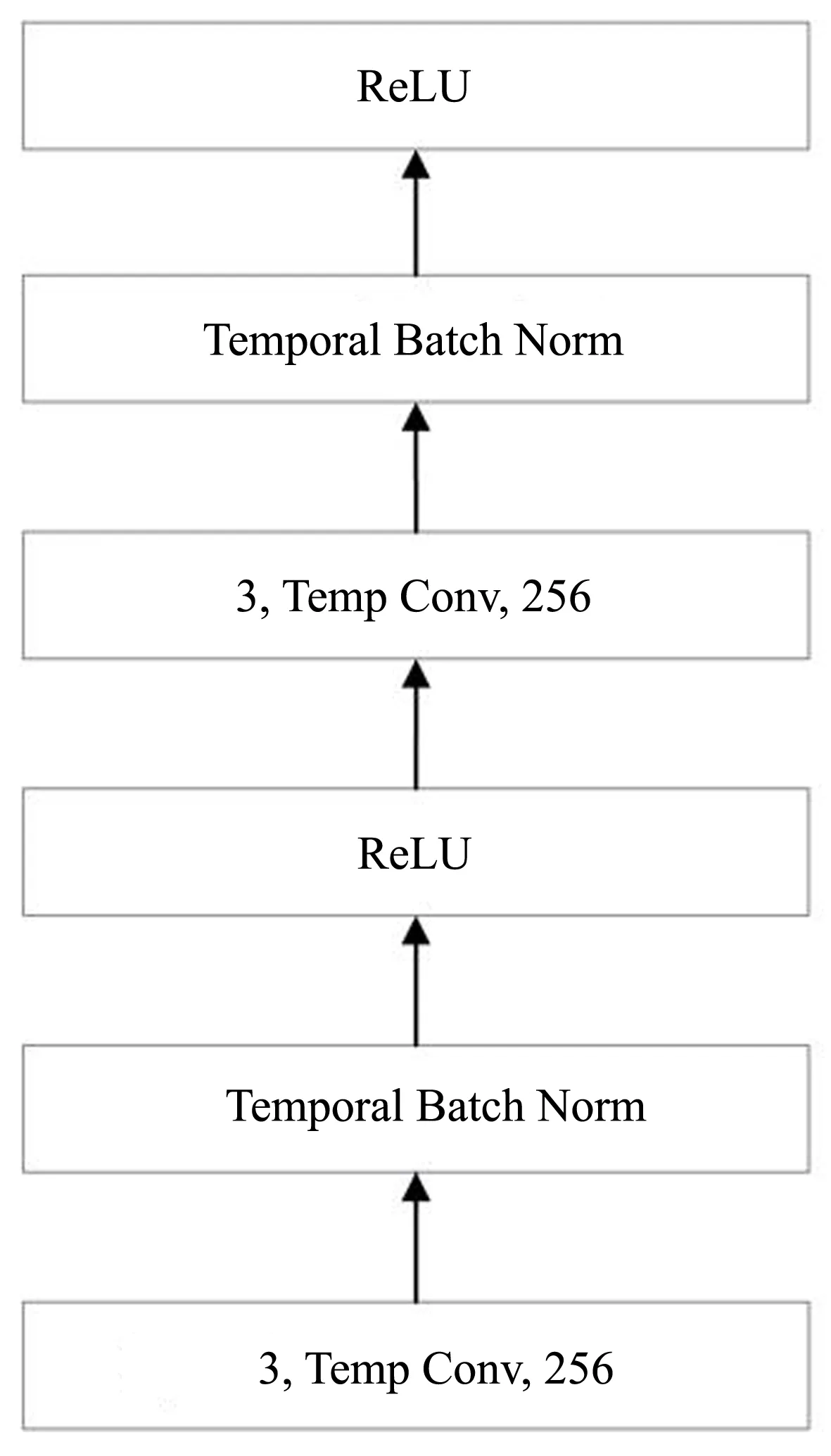
图7 卷积块结构
融合的输出向量Y将会经历3次池化,前2次采用最大值池化。采用最大值池化可以保证特征的位置与旋转不变性,即无论这个强特征在哪个位置出现,都能够不考虑其出现位置把它提取出来。最后1次采用k-max池化,本文中k的大小取值为8。k-max池化是指,取所有特征值中top-k的值,并保留这些特征值的先后顺序。相比于最大值池化丢失了位置信息,k-max池化保留了部分位置信息。如图6所示,每次池化处理之前是两个卷积块,池化之后特征图的大小减半;滤波器的数量增加一倍,以减少内存占用。卷积块的内部结构如图7所示。每个卷积块由两个卷积层构成,每个卷积块后接一个Temporal Batch Normalization和ReLU激活层。捷径(shortcut)的引入是为了解决卷积神经网络随着深度的增加导致的梯度发散问题。
(4)将k-max池化的输出一维化并进行两次全连接,为了减轻模型过拟合的程度,在全连接过程中采用了dropout技术。鉴于线性模型的表达能力不够,本文没有将全连接层直接接入分类器,而是接入relu激活函数,为模型加入非线性因素。relu激活函数具有稀疏激活性的特征,运算速度快,能够有效地解决梯度消失的问题。
(5)对relu激活函数的输出进行全连接,接入sigmoid分类器输出分类结果。
四、实验设置与结果分析
(一)实验环境和评价标准
本实验采用keras深度学习框架,底层为TensorFlow,使用Python语言编程实现;实验运行环境为VScode软件、Win10系统、内存8GB等;实验设置迭代次数为20。

表2 混淆矩阵
本实验采用准确率和损失率作为实验的评价指标。针对分类体系中的任意类别 X 构建混淆矩阵(CM,Confusion Matrix),如表2所示。
混淆矩阵中TP(True Positive)代表被模型预测为正的正样本,TN(True Negative)代表被模型预测为负的负样本,FP(False Positive)代表被模型预测为正的负样本,FN(False Negative)代表被模型预测为负的正样本。
准确率(Accuracy)是所有预测正确的正类和负类,占所有样本的比例,准确率A定义为:
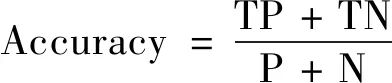
(8)
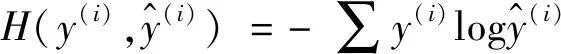
(9)
当训练样本为n时,损失函数为:
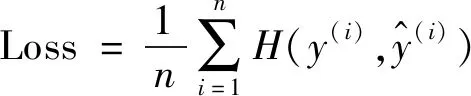
(10)
(二)实验结果对比与分析
为了评估数据集在Bi-LSTM-VDCNN上的实验效果,本文将Bi-LSTM-VDCNN与以下3类模型进行对比:(1)单一VDCNN模型,单一Bi-LSTM模型;(2)其他Bi-LSTM和VDCNN的混合模型;(3)目前常用的基于深度学习的文本分类器,包括RNN、循环卷积神经网络(RCNN)、深层金字塔卷积网络(DPCNN)、FastText、Transformer。采用与Bi-LSTM-VDCNN相同的数据集、实验环境和参数训练模型,并将训练结果与Bi-LSTM-VDCNN进行比较。评价指标为测试集的准确率(TA, Test Accuracy)和损失值(TL, Test Loss)。如表3所示。
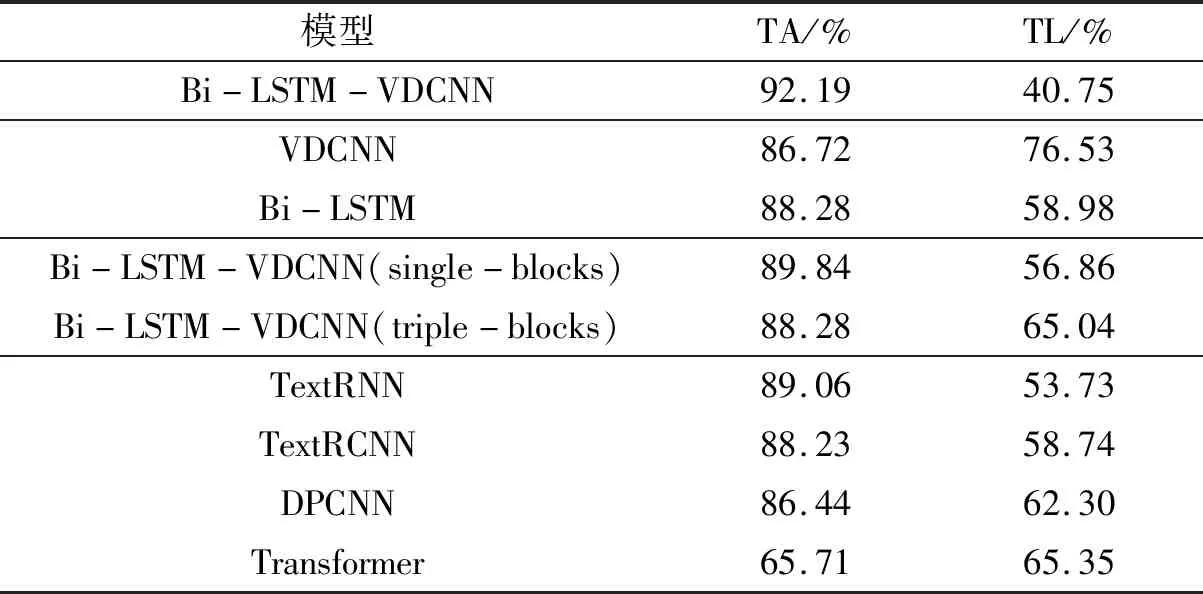
表3 不同模型实验效果对比
1. Bi-LSTM-VDCNN和单一VDCNN模型、单一Bi-LSTM模型的对比
和单一VDCNN模型以及单一Bi-LSTM模型相比,Bi-LSTM-VDCNN在测试集准确率方面分别提升了约4.4%和6.3%。VDCNN和 Bi-LSTM的混合模型的识别效果要优于单一的VDCNN和Bi-LSTM模型,表明Bi-LSTM捕捉的序列信息和VDCNN捕捉到局部相关性信息的融合能够提取更多的句子特征,从而提升模型的识别准确率。
2. Bi-LSTM-VDCNN和其他Bi-LSTM和VDCNN混合模型的对比
第二组对比实验中,Bi-LSTM-VDCNN(single-blocks)和Bi-LSTM-VDCNN(triple-blocks)都是VDCNN和 Bi-LSTM的混合模型,和Bi-LSTM-VDCNN每次池化处理前经历两个卷积块不同,Bi-LSTM-VDCNN(single-blocks)和Bi-LSTM-VDCNN(triple-blocks)在每次池化处理处理前分别经历一个和三个卷积块。表3的实验结果显示,Bi-LSTM-VDCNN在社交网络语言攻击性言论识别任务上的表现要优于Bi-LSTM-VDCNN(single-blocks)和Bi-LSTM-VDCNN(triple-blocks),所以,浅层网络的特征提取能力不一定优于深层网络,当然网络的层数也不是越深越好,过深的网络会带来梯度的消失、爆炸以及网络退化等问题。
3. Bi-LSTM-VDCNN和常用文本分类器的对比
单一VDCNN模型的准确率和损失都要劣于常用的RNN模型TextRNN和TextRCNN,但是融合了Bi-LSTM的Bi-LSTM-VDCNN在NLP任务上的表现要优于RNN模型,证实了序列信息和局部信息的融合在社交网络语言攻击性言论识别任务上的有效性。Transformer模型在此次任务上的表现并不理想,一是普通Transformer中的正弦位置编码不能捕捉到方向信息和相对位置信息,对于“我好讨厌他”和“他好讨厌我”两句话来说,前者包含了更多的厌恶情绪,更可能被划分到社交网络语言攻击相关的评论中,而后者和社交网络语言攻击的相关性不大;二是传统的Transformer的分布被缩放了,从而变得平滑,这意味着对于句子中的所有单词的关注程度是一样的,显然,对于一个和社交网络语言攻击相关的评论“你可别太疯”“疯”应该得到更多的关注。
五、结论
本文使用BERT文本嵌入作为输入来训练文本分类模型,基于VDCNN结构引入Bi-LSTM,在字符级对社交网络语言攻击相关的评论进行识别。建立的Bi-LSTM-VDCNN模型融合了Bi-LSTM捕捉到的序列信息和CNN捕捉到的句子中类似于n-gram的局部相关性信息,有效地提高了分类准确率。后续可对数据集进一步扩充进行大规模的实验,也可以考虑建立Transformer混合模型,或者对Transformer进行相关的优化,以进一步提升模型的分类效果。
