融合语义路径与语言模型的元学习知识推理框架
2022-12-28封皓君张碧莹刘江舟刘海潮
段 立 封皓君* 张碧莹 刘江舟 刘海潮②
①(海军工程大学电子工程学院 武汉 430033)
②(中国人民解放军 91202部队 葫芦岛 125004)
1 引言
知识推理是一种通过已有知识排除错例或推断新知识的过程,是计算机获得认知智能的基础[1]。基于知识图谱的推理技术则将图谱作为先验知识,以剔除其中错误3元组、挖掘更多潜在的关联关系,为实体链接、推荐系统、智能问答等场景赋能,具有较高的落地价值[2]。传统基于路径或统计规则的推理方式在人的思维基础上完成推理,顾及了模型层面的可解释性,却存在复杂度高、计算困难等缺陷,例如Lao等人[3]提出的路径排序算法、Yang等人[4]提出逻辑规划框架等。近年来,各类神经网络与表示模型[5]相继被提出,知识推理在效率上取得长足的进步,刘藤等人[6]提出一种基于联合一阶逻辑(First Order Logic, FOL)规则的表示学习框架,通过优化得分函数使之适配大多数推理模型;Zhang等人[7]提出一种基于强化学习的推理方法,将推理问题转化为序列决策问题,取得了不错的效果。总的来说,神经网络凭借其良好性能极大方便推理活动的同时,也带来解释性不足等缺陷,同时无法全局考虑语义、路径等多种影响因素,泛化能力有待提升。随后,众多学者开始利用多种方法建模,混合推理方法逐渐被提出,Wang等人[8]利用长短期记忆网络(Long Short-Term Memory,LSTM)与注意力机制记录过往推理路径完成推理;陈海旭等人[9]提出一种基于嵌入和路径组合的表示模型,利用路径和关系向量相似度联合计算推理概率。总的来说,将图谱路径与深度学习模型结合是兼顾计算能力与可解释性的有效途径之一,但仍难以解决小样本下(few-shot)知识推理问题。文献[10]指出,在维基数据中,大约有10%的关系对应的3元组的数量不超过10个,需要更优秀的设计为推理活动赋能,元学习技术逐渐被用到知识推理中,例如Chen等人[11]提出关系元与梯度元等概念,通过转移元学习器中特定的参数完成小样本下的链接预测。Lü等人[10]提出一种基于长短期记忆网络和元学习的知识推理框架,有较深刻的启发意义。
基于传统推理方法无法兼顾计算能力与可解释性,并在小样本下推理困难的问题,本文提出一种基于语义路径与双向Transformer编码表示(Bidirectional Encoder Representations from Transformers, BERT)[12]的元学习推理框架,由基训练和元训练两个阶段构成,在基训练阶段提出一种路径表示方案保留框架整体可解释性,并利用BERT的自注意力机制更新语义向量,掌握语义间的关联程度,在框架之上继续添加微调层提升推理水平;在元训练阶段融合模型无关元学习(Model-Agnostic Meta-Learning, MAML)框架[13]获得优化后的初始参数,使小样本推理问题更快收敛。最后使用FB15K-237, WN18RR标准数据集以及OpenKG人物关系图谱、CN-DBpedia部分子集对框架进行验证,结果表明,与目前主流推理方法相比,该框架的多项性能指标高于平均水平,同时可以完成小样本推理问题的学习与快速收敛。
2 相关工作
2.1 BERT模型
谷歌在2018年提出一种预处理语言表示模型BERT,旨在通过海量无监督文本中的词语相互关系获得词或句子级别的特征表示,在众多自然语言任务中具有良好表现。虽然XLNet[14]曾短暂超越BERT,但据脸书(Facebook)的相关研究表明,如果增加数据量并且训练更久,BERT依然可以重返最佳水平。其优势在于引入了自注意力方法与Transformers结构,并设置掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)联合预训练任务,取得不错的效果,同时证明了深度模型仍可能继续提升自然语言处理(Natural Language Processing, NLP)任务准确率。基于该模型设计知识推理框架,在提升计算水平同时离线保存推理经验,并将参数量巨大预训练模型快速赋能于推理行为,满足时效性要求。
2.2 MAML框架
模型无关元学习(Model-Agnostic Meta-Learning, MAML)框架是一个通用的元学习框架,通常由若干个子任务(Task)构成,每个Task有独立的损失函数。该框架旨在获得一组初始化参数,主要方法是通过对各个Task训练获得梯度经验信息,并针对初始化参数进行调整,从而完成新任务的快速收敛。该框架与传统训练方法对比如图1所示,φ0表示训练的初始化参数,当训练第m个子任务Task#m时,计算其损失函数可以获得其独有的梯度优化参数θm,如图1(a)φ0引出虚线所示;再基于θm计算任务m新的损失函数并得到其在θm上的梯度,此时该梯度会代回初始参数φ0中,在新的学习率下得到φ1,φ0~φ1的直线与θm引出的虚线应是平行的,表示梯度的传递。而传统训练方法摒弃了初始参数更新与梯度传递,导致过往训练信息无法保留。此时再对Task#(m+1)进行训练,经过一步梯度下降得到θn,计算损失函数在θn上的梯度并更新φ1,以此类推,最终提升模型的整体学习能力,快速高效地适应新任务。
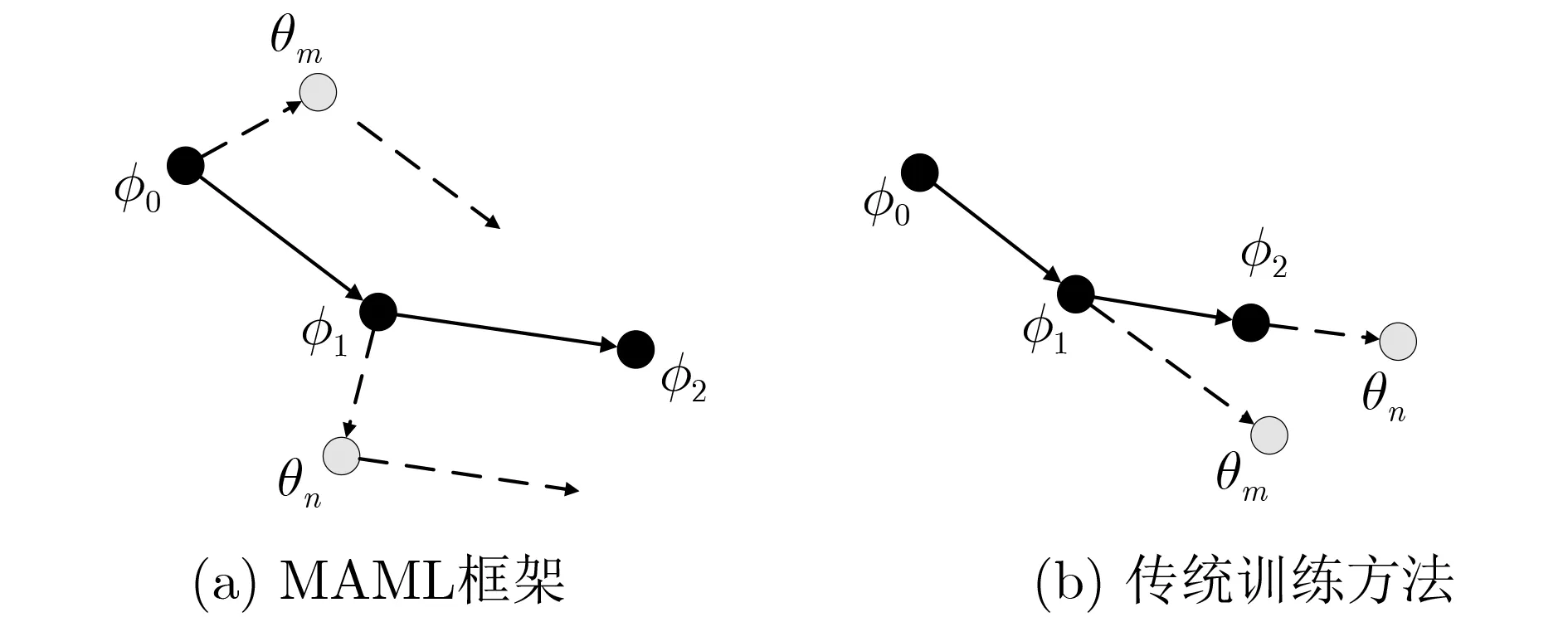
图1 MAML与传统训练方法对比
MAML框架简单实用,能适应多种任务,有效解决小样本问题,本文场景下具有一定的应用价值。
3 框架设计
本文在深入调研基础上,提出一种基于语义路径与BERT语言模型的元学习推理框架,基训练阶段设计基础的知识推理框架,元训练阶段提出一种小样本下的快速学习方案,设计如下。
3.1 基训练阶段
本文将基础的知识推理问题定义为实体间关联关系的判断与预测,由图谱中的已知路径作为依据。因此,首要任务是完成实体间路径挖掘。
框架首先在任意两实体间搜索N跳之内的其他路径获得训练数据。需要注意的是,并不是实体间所有路径都能转化为有效路径,某些核心节点例如“中国”、“美国”等可以延伸出非常多关系结构,同时也有很多实体因涉及国家3元组与这些核心节点产生关联,使得节点之间途径国家产生多跳关系,而实际上节点间的关系一般无法通过相同国家推断出。基于此,首先应剔除部分核心节点,避免产生无效推理。通过搜索得到的路径与实体间直连路径将被看作同义路径,作为一部分训练数据。跳数N设置越大,包含的路径越多,推理条件更宽松,但难以找到通识规律;N设置越小,推理条件越准确,但后续可供学习的训练数据减少,因此一般设置2~3为宜[15],本文为了简化验证过程取2。此时,这些路径还无法直接与语言模型产生联系,需设计一种路径表示方案,定义部分标识如表1所示。
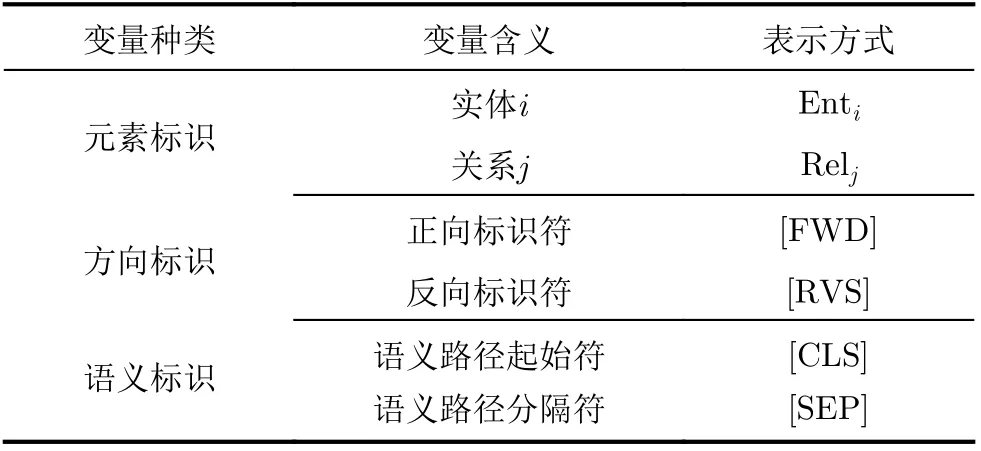
表1 部分变量标识
每条路径用一个短分句表示,以[SEP]分隔,按照<节点/关系的方向标识/关系/节点>的顺序排列。给定节点之间的同义路径构成一条序列,以[CLS]起始,表示多种同义的推理关系,应当包含两条及以上的短分句。最终将各实例的子图结构转化为若干条序列,如图2所示。
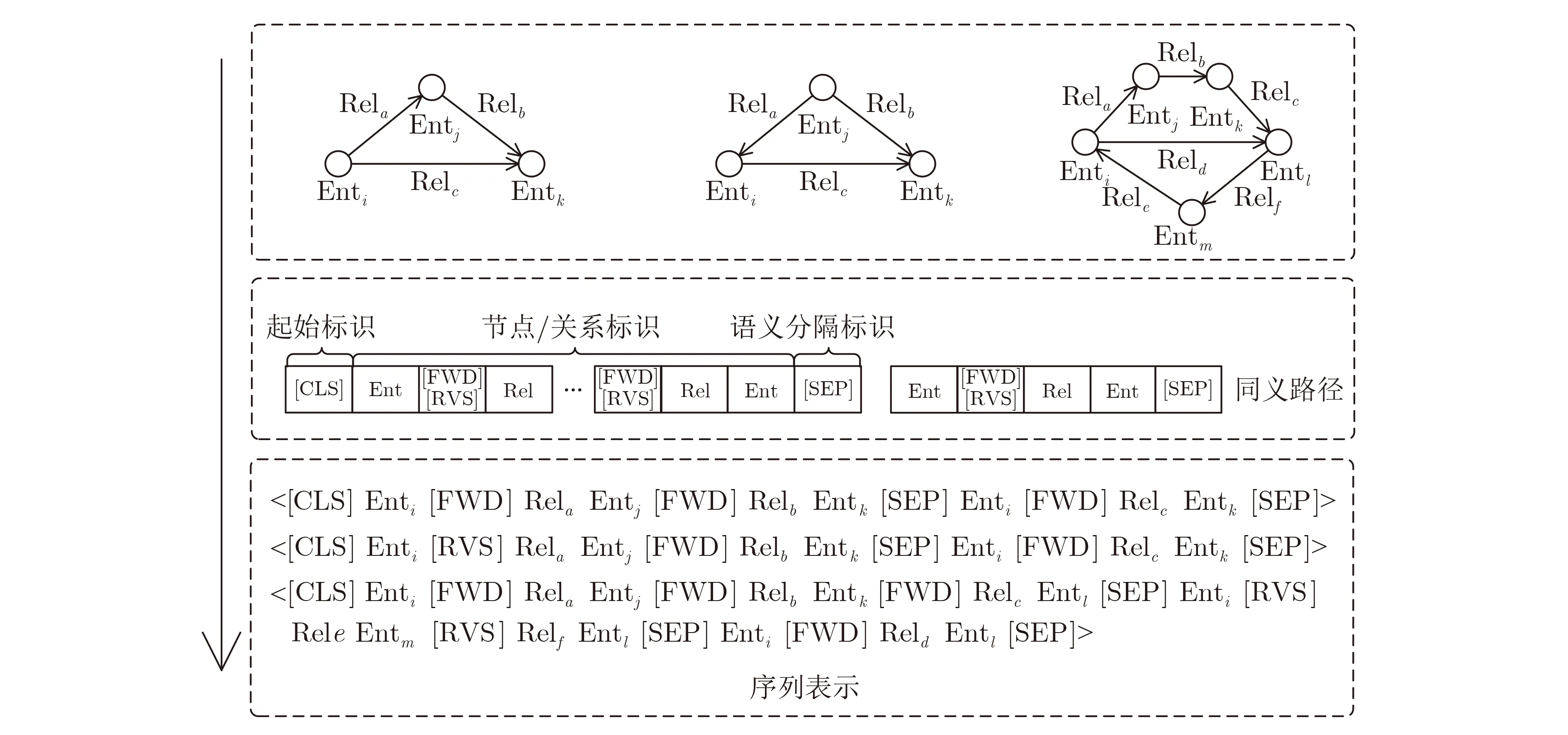
图2 语义路径表示方案
任意推理路径均可利用上述方式构成序列表示的推理实例,作为一部分训练数据传入后续框架中。然而这些推理实例对框架来说都是正例,为了提升学习能力,还需要负采样一部分错误样本。本文参考百度ERNIE模型[15],基于以下策略对正例进行修改构建负例:(1)随机替换语义路径下的1个或多个元素/方向标识;(2)随机替换语义路径下的某个短分句。等概率调用两者,且需要确认新的负例不在推理实例集合中。
将训练数据加入BERT模型中,通过给定的12层Transformer结构并添加一个额外的池化与输出层进行微调[16]以完成推理过程,如图3所示。
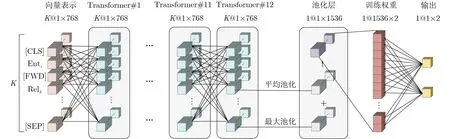
图3 基于BERT微调的推理框架设计
文献[12]提出取[CLS]的最终隐层状态c(c∈RH)作为输出,即最后一个Transformer的结果,H为BERT模型隐层单元数,取768。此时[CLS]的状态c经过自注意力变换可以对整个序列的特征进行表达。然而在实际使用过程中这种方式可能会导致过拟合情况的发生,泛化能力不佳。因此,本文在Transformer后增加一个池化层(Pooling),采用均值-最大池化(Mean-Max-Pool)策略,对所有状态按维度取均值与最大值并进行拼接,以增加非线性特征的表达能力。最终得到整个序列表示记为cp(cp∈R2H)。
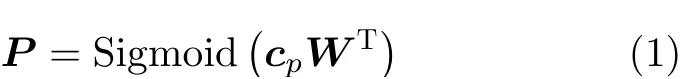
此外,还需要额外训练一层权重W(W∈R2H×K),为了区分路径同义/不同义两种情况,K在此取2。用Sigmoid函数定义关系概率P,如式(1)P是一个2维向量,两个维度分别表示路径同义/不同义的概率,训练时的损失函数设置为交叉熵函数,如式(2),其优势在于易于计算且能较好展示分布差异[17]

将候选关系填入[MASK]中,经Transformer与池化(Pooling)后获得新的特征表示,并将训练好的权重W代入,获得同义概率。定义相信度阈值blv∈[0,1],当概率大于该阈值时,认为填入关系是合理的,该值通过后文实验确定。
3.2 元训练阶段
将MAML框架应用到本文知识推理任务中,目标是获得更好的初始化权重W,使推理训练过程快速收敛,总体设计如图4所示。
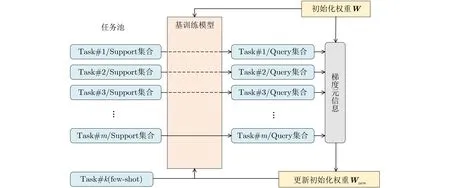
图4 基于MAML的推理框架设计
本框架设计思路如下:沿用上一阶段的训练集,将不同的直连关系划分并依次用Task集合表示,所有Task构成任务池。同时,将每个Task中的序列实例按比例分为Support与Query集合,举例如表2所示。
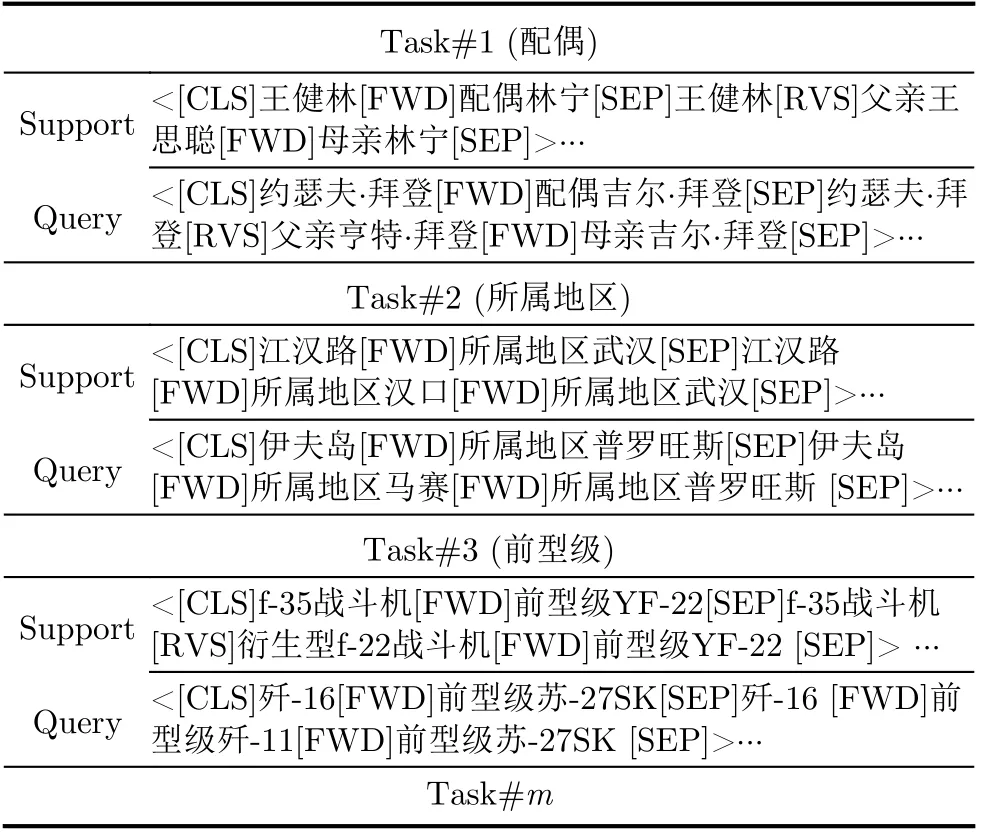
表2 Task举例与表示
设定一个随机初始化参数W,对Support集合进行训练,在Query集合上验证并计算损失函数,得到梯度信息。所有Task上的梯度信息一起构成梯度元信息,基于此不断调整初始化W,具体需要执行两步梯度下降算法,分别设置学习率α, β:
(1)在内层循环中,使m个Task都在W的基础上完成一次独立的梯度更新,得到m个优化后的结果,记为W1,W2,···,Wm,更新公式即为一般的梯度下降公式,如式(5)所示,此时Wi只对应于Task#i较优的权值,并非适用于所有任务。
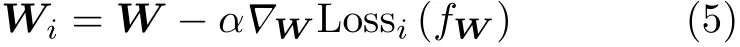
(2)在外层循环中,以W1,W2,···,Wm为参数,在原始W上再进行1次梯度更新,得到优化后的权值Wnew,如式(6)所示,该参数可以适配更多训练任务
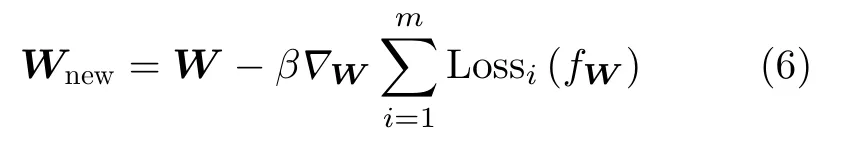
在实际使用过程中,使用改进的早停法(early stopping)防止过拟合情况的发生,即训练一定的周期后,在随后的每一个周期当中都计算框架在验证集上的误差,在误差变大时停止训练,取上一步的结果作为最终参数。
该元学习知识推理框架可有效赋能于图谱补全,基于碎片化知识中可能蕴含新关系类,该框架可以实现其快速学习并泛化到整个知识图谱中,如图5所示。当某文本中产生<歼20,中国代号,威龙>3元组,且“中国代号”关系在图谱中从未出现过时,该框架可以结合任务池中大量推理经验,对该任务进行学习并获得权重参数。随后通过遍历图谱预测出更多包含“中国代号”的3元组,例如<歼31,中国代号,鹘鹰>、<歼轰7,中国代号,飞豹>等。这些预测出的3元组经人工确认后方可以加入图谱,完成动态补全过程。该任务也将被加入任务池中,继续赋能于接下来的小样本新任务,实现“1生2,2生3”的知识完善过程。

图5 基于图谱补全过程
4 实验与分析
验证推理框架的有效性往往利用链接预测(Link Prediction, LP)与事实预测(Fact Prediction,FP)任务。链接预测旨在预测3元组中缺失的部分,主要评价指标包括平均排名(Mean Rank,MR)、平均排名倒数(Mean Reciprocal Rank,MRR)与正确3元组所在前K百分比(Hits@K)。其中MR越低,Hits@K越高,则推理方法表现越好。事实预测旨在判断3元组是否为真,利用平均精度均值(Mean Average Precision, MAP),如式(7)所示,其中n是样本总和,ti为测试集,rank(true)与rank(false)为正、负样本的排名,该值越高则框架表现越好

共设置4个实验数据集,包含两个通用基准图谱数据FB15K-237与WN18RR,还加入了中文人物关系图谱以及从CN-DBpedia中抽取的部分子集。FB15K-237是大型知识库Freebase的子集,包含237种关系和14k种实体,其关系种类较多,实体之间的联系较频繁;WN18RR是大型知识库Word-Net的子集,包含18种关系和40k种实体。相较于FB15K-237数据集,WN18RR有更多的实体,但关系种类非常少,展现较为稀疏;OpenKG中文人物关系图谱包含近100k条关系数据,可支撑多项应用尝试和科学研究工作,涉及人物71243个,大类关系102个,小类关系266条;CN-DBpedia是中文全领域知识图谱,从中抽取军事、体育、科技等部分领域3元组继续进行实验,约含有5K个3元组。同时,本文还继续对小样本下模型的学习能力进行验证。
4.1 参数设置
框架需要设定的参数除了部分已在模型设计中阐释外,还包括一些模型训练的基础参数与相信度阈值blv等,其中部分训练基础参数参考文献[12, 13],采用给定的参数,如表3所示。

表3 基础参数设定
相信度阈值blv需要通过实验进行设定。本文在CN-DBpedia子集上进行小范围的监督训练,结果如图6所示,blv设置为0.92时准确率最高,达到95.24%,后文均以0.92为标准。
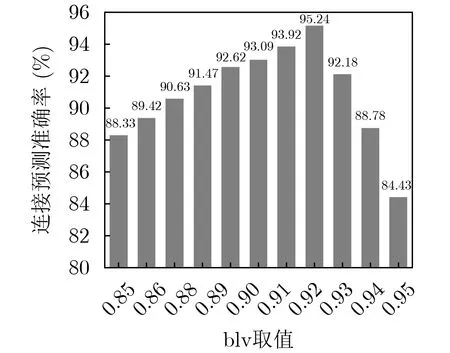
图6 blv与准确率的关系
4.2 链接预测验证
本文利用链接预测任务验证基训练推理框架的特征表达能力,并与传统的联合表示学习方案进行比较,结果如表4所示,表4的部分数据取自先前论文,存在部分缺失值。在中文人物关系图谱上进行关系预测任务,剩下图谱上则等比例地完成关系与实体预测。
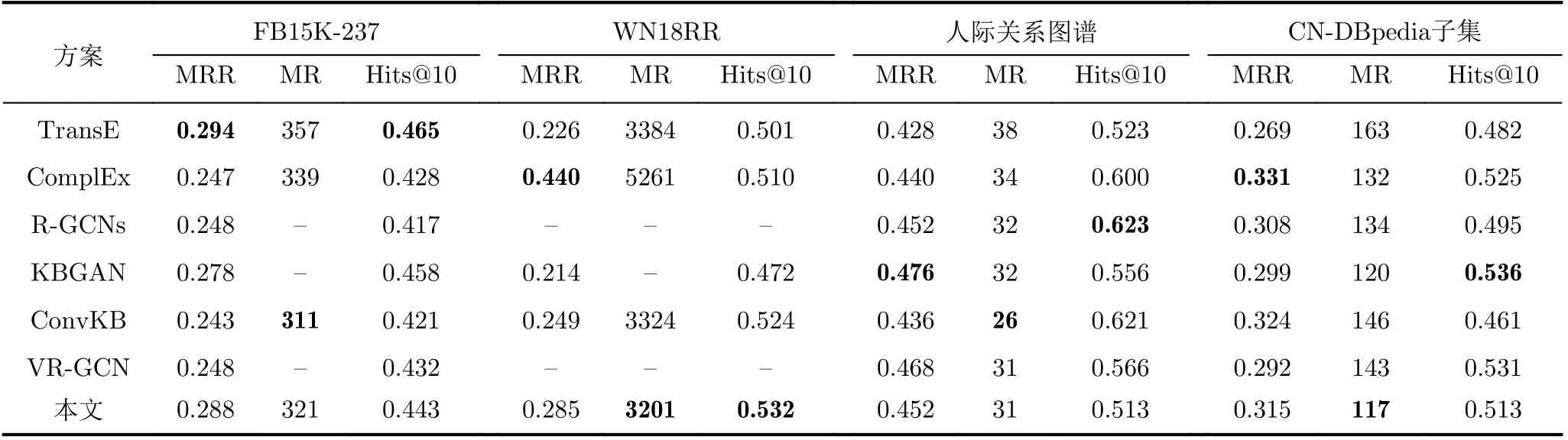
表4 不同方案链接预测效果比较
通过结果可知,本推理框架有3个指标达到最佳。同时,框架在WN18RR数据集上表现最好,在人际关系图谱上表现则相对平庸,但均在几种常见推理方案的平均水准之上。
4.3 事实预测验证
事实预测任务旨在验证框架识别3元组的能力,结果如表5所示。
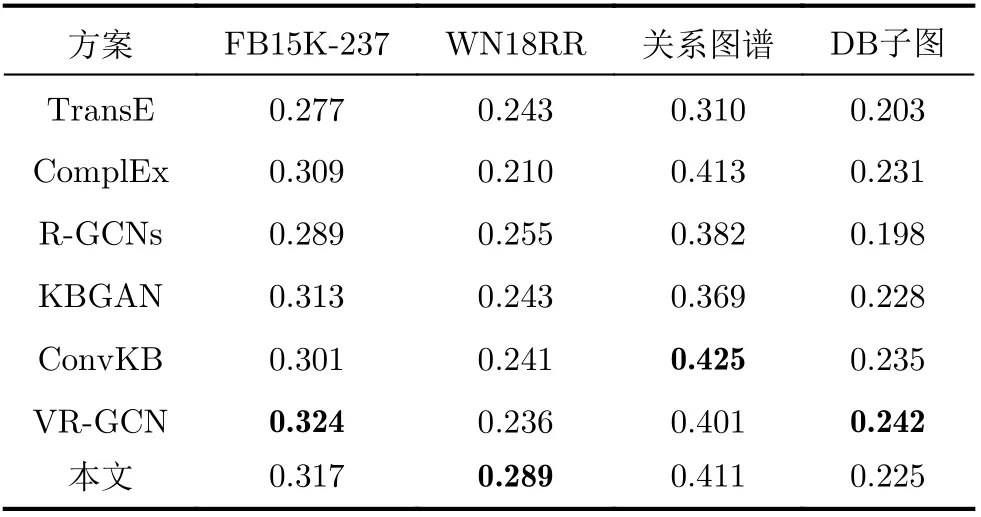
表5 不同方案事实预测效果对比
本框架在事实预测任务中表现相对稳定,在WN18RR仍然表现最佳。总体而言,在两个实验共计16个评价指标中,该框架有4项排名第1,共计14项指标排名前3。同时,不同的推理方法往往适用于不同图谱,例如TransE方法[18]在FB15K-237数据集中表现最佳、R-GCNs[19]更适合人际关系图谱等。该框架在WN18RR总共4项评价指标中有3项位于第1,优于其他推理方案。
4.4 小样本学习能力验证
为了验证框架在小样本下的推理能力,本文在CN-DBpedia子集中人工标注6种小样本关系(配偶、所属地区、前型级、具备能力、队友、合作),分别记为关系1~6,并将其直接代入推理框架进行200代训练,记录训练过程中的损失变化曲线(如图7红线所示)。再依次将某关系看作小样本Task,其余关系代入MAML框架,获得优化后的初始W。将W作为初始化参数代入小样本推理框架中,同样进行200代训练并记录损失变化曲线(如图7蓝线所示),结果如下。
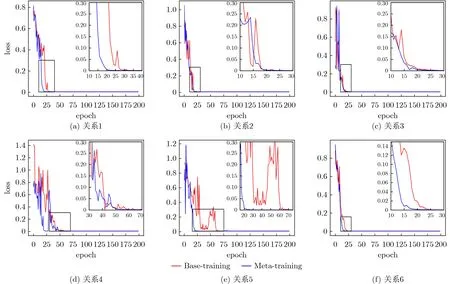
图7 不同方式下的损失变化曲线
由结果可知,在MAML框架赋能下,有3种关系获得了更快的收敛能力(关系1、关系5、关系6)。除此之外,关系4获得了损失更少的起始点,关系2、关系3在训练中的跳变程度更小,训练更稳定。总体上看,MAML框架使小样本推理问题平均提前收敛近10代,有效提升了学习能力。
5 结论
本文提出一种基于语义路径与BERT的元学习推理框架,在基训练阶段通过语义路径表示方案获得图谱推理路径,保留整个框架的可解释性;再利用BERT微调建模,基于语义特征进行训练并保留预训练模型,继而判定推理关系。元训练阶段利用MAML框架对若干子任务进行训练并保留元信息,获得更优的初始化参数,为小样本下的推理问题赋能。实验表明,该文推理框架在16个指标中均高于平均水平,并有4个达到最优。同时,引入MAML框架可以使部分任务更快收敛,在本文数据集下平均提前约10代,满足智能化解决推理问题的需求。
