一种基于图形处理器的高吞吐量SM2数字签名计算方案
2022-12-28黄煜坤王枫为杨晓鹏
朱 辉 黄煜坤 王枫为 杨晓鹏 李 晖
(西安电子科技大学网络与信息安全学院 西安 710126)
1 引言
数字签名技术是实现网络安全的重要机制之一,它常用于通信双方的身份认证和保证数据的不可抵赖性。随着云计算、电子商务等技术的发展和认证信息细粒化程度的提高,数字签名技术的使用也越来越频繁。SM2数字签名方案是基于椭圆曲线密码学(Elliptic Curve Cryptography, ECC)的非对称密码方案,由国家密码管理局(State Cryptography Administration of China, SCA)于2010年出台[1],并在2018年成为国际标准[2]。相较于其他公钥密码方案,椭圆曲线密码方案最大的优势是能在使用较短长度密钥的同时提供较高的安全性。随着人们安全需求的不断提高,SM2这种基于ECC的密码方案将会有着优秀且广泛的应用前景。
然而,由于SM2数字签名算法中存在复杂且计算量大的椭圆曲线运算,频繁海量地签名和验签操作会给服务器带来极大的计算处理压力[3],造成服务质量下降甚至系统崩溃等问题。因此,研究高效的SM2签名与验签计算方法不仅能降低服务商计算成本,而且能够提升用户体验,近年来SM2算法的各类应用研究得到了研究人员的广泛关注,但在对其的优化实现方面的研究工作公开资料较少。围绕上述问题,针对服务商同时处理大量用户签名、验签请求的场景,本文设计并实现了一种图形处理器(Graphics Processing Unit, GPU)平台下的高吞吐量SM2数字签名计算方案。
当前,降低签名、验签计算成本通常从两个层次出发:(1)选择计算能力强同时价格相对低廉的计算平台以降低硬件成本。(2)结合平台特性优化密码算法降低计算开销。
在计算平台选择和优化实现方面。Koppermann等人[4]在现场可编程逻辑门阵列(Field Programmable Gate Array, FPGA)平台上以92 µs的时延实现了基于ECC的X25519协议。Huang等人[5]使用高级矢量扩展(Advanced Vector eXtensions 2,AVX2)指令集并行化椭圆曲线点加运算,分别以24 µ s 和98 µs的时延实现了SM2签名、验签算法。上述文献的研究都侧重于降低算法的时延,由于计算平台本身的特点,他们的实现在吞吐量方面的表现并不突出。随着人工智能领域的发展,通用GPU的计算性能在近几年得到了飞速增长,而且在并行计算领域,GPU更是有着巨大的优势[6]。Pan 等人[7]使用型号为GTX780Ti的GPU加速椭圆曲线运算,实现了签名吞吐量达到8.71×106次/s的数字签名服务器,同时展现了GPU并行计算密码算法的巨大潜力。而且相比于专用的密码机,成熟且可靠的生产链使得GPU在算力上拥有更高的性价比。因此在高并发场景下,GPU相比其他密码计算设备有着更大的优势。
在结合平台特性进行密码算法优化方面,基于ECC的签名与验签计算主要涉及模乘、模加、模减、模逆、椭圆曲线多倍点运算和椭圆曲线点的加法运算(如图1所示),其中模逆和椭圆曲线多倍点运算分别为有限域和椭圆曲线群中开销最大的运算,它们的计算效率将很大程度上影响签名、验签的性能表现。(1)在当前对椭圆曲线多倍点运算的快速计算方法中,基于大数非相邻形式的(Non-Adjacent Form, NAF)算法[8]可以大大减少计算量,但该算法中包含依赖输入值的分支判断,使其容易遭受到侧信道攻击[9,10],并且其算法结构的复杂度较高,因而其并不适合在GPU这种分支预测能力弱的计算设备上运行。相反,一些计算量稍大但结构简单的算法在GPU上的运行表现更好,如二进制展开法。Pan 等人[7]利用椭圆曲线基点G在系统中保持不变的特性,构建了大小为64 MB的预计算表辅助固定点乘的计算,大大减少了固定点乘的计算量,且非常适合GPU这类内存空间充裕的设备,但该方法不适合应用于未知点乘运算。(2)当前模逆运算主要采用基于扩展欧几里得算法和费马小定理两种方法实现,出于计算开销方面考量,大多数倾向采用扩展欧几里得算法计算模逆。然而,尽管基于费马小定理的模逆算法开销较大,但由于其运行过程与输入值无关,因此Huang等人[5]和Zhou等人[11]基于该算法构造出抵抗侧信道攻击的方案。Pan等人[7]指出,由于扩展欧几里得算法会产生严重线程束分化现象,GPU并不是一个计算模逆的理想平台,于是利用同时模逆(simultaneous inversion)算法在CPU上计算模逆,但这种方案需要CPU与GPU间通信交互,且大幅增加了任务调度的复杂度,在实际部署过程中难以优化出理想的效果。

图1 SM2数字签名算法运算层次图
本文针对GPU平台特性,对SM2算法中的关键运算进行优化改进,显著提升了SM2签名与验签算法的吞吐量,主要贡献点如下:
(1) 构建了基于底层指令优化的模加、减、乘运算模块。通过使用GPU底层指令构建高效的模加、减运算,优化了模乘约减算法的计算过程,并设计预计算表减少了模乘约减运算所需的模减次数。
(2) 提出了结合GPU特性的高效模逆计算方法。考虑GPU 乘法计算能力强但分支预测能力弱的特性,利用加法链加速基于费马小定理的模逆计算方法,同时缩短了SM2推荐素数的加法链,极大提升模逆处理速度。
(3) 提出了面向未知点乘运算的优化机制。利用倍点运算比点加运算开销更低的特性进行预计算表构造,不仅减少了未知点乘运算预计算环节的计算量,并且消除了主循环计算环节的条件判断,并利用重复倍点算法提高了主循环计算环节的计算效率。
(4) GPU平台实测证明所提的SM2算法优化方案可以极大地提升签名与验签算法的吞吐量。在RTX 3090 GPU卡上,其签名和验签吞吐量分别达到7.609×107次/s和3.46×106次/s,显著优于已有公开成果。
2 预备知识
2.1 SM2数字签名算法
SM2数字签名算法[1]分为密钥生成、签名和验签算法。密钥生成算法用于生成用户的公私钥对(dA,PA) , 其中私钥dA为范围在[ 1,n −2]的大整数,用于产生对数据的签名,公钥PA= [dA]G是椭圆曲线上的点,用于验证签名。
SM2签名算法输入摘要e和私钥dA,输出签名(r,s) , 其中输入的摘要e=h(m)为 签名消息m的杂凑值,且杂凑函数h(m)需要使用SCA批准的密码杂凑算法,如SM3密码杂凑算法[12]。具体计算过程如下。其中G,n的定义可参见2.2节:

2.2 SM2方案推荐椭圆曲线参数及定义
SM2方案推荐的椭圆曲线由素数域FP上的Weierstrass方程所定义,如式(1)所示

其中,p是大于3的素数,a,b ∈FP,且满足(4a3+27b2)modp ̸=0。椭圆曲线上的点按照点加运算规则构成阿贝尔群。椭圆曲线上的多倍点运算定义为同一个点的多次点加,如式(2)所示
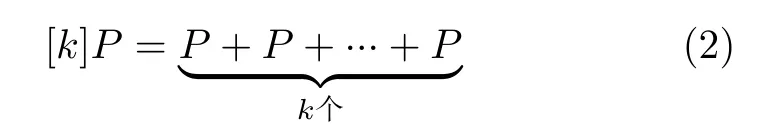
此外,SM2方案推荐使用的256位椭圆曲线参数[13]还包括伪梅森素数PSCA-256[14]、椭圆曲线的基点G、基点G的阶n和 系数a,b。其中,素数PSCA-256可表示为PSCA-256=2256−2224−296+264−1。文献[15]给出了针对此素数的快速模约算法,如表1算法所示。

表1 针对素数SCA-256的快速模约算法
2.3 Jacobi加重射影坐标系下的点加运算
在Jacobi加重射影坐标系(下文简称Jacobi坐标系)下进行点加运算可减少模逆带来的计算开销。若Z̸=0 , 令X=xZ2,Y=yZ3则可将2.2节中式(1)的仿射坐标系表示转化为Jacobi坐标系表示,如式(3)所示

椭圆曲线点的加法运算根据两输入点是否相同分为点加运算和倍点运算,这两种运算有着不同的计算方式。Jacobi坐标下椭圆曲线点的加法运算的底层算法可参见文献[16]。
2.4 CUDA编程
Nvidia的统一计算设备架构(Compute Unified Device Architecture, CUDA)提供了并行线程执行模型(Parallel Thread eXecution, PTX)和指令集架构(Instruction Set Architecture, ISA)[17]。PTX ISA指令集(下文简称PTX指令集)包含带进位的加、减和移位等运算,可以利用这些指令构建底层大数运算来减少不必要的运算开销。本文所使用的指令及其含义如表2所示。其中指令 add , a ddc,sub 和s ubc等可指定是否使用条件代码(Condition Code, CC)寄存器,该寄存器包含一个进位标志位CC.CF(Carry Flag bit)。在指令中指定使用条件代码寄存器会将计算产生的进位或借位写入CC.CF中。例如,指令 add.cc(c,a,b) 计算c=a+b并将产生的进位写入到C C.C F 中,而指令 add(c,a,b)只计算c=a+b。 指令s hf所执行的是漏斗移位(funnel shift)操作[17],该操作需连接两个操作数后进行移位,并在左移的情况下取结果的最高32 bit,在右移的情况下取结果的最低32 bit。

表2 PTX ISA指令及其含义
3 有限域基础运算的构建与优化
本节将介绍面向GPU的有限域基础运算构建及其优化方法,包括如何使用底层指令构建高效的大整数移位、模加、减、乘运算,以及结合GPU的特性优化实现模逆运算。
3.1 大整数移位运算优化

漏斗移位指令s hf从底层整合了连接和移位操作,这使得传播的比特位被自然地移动到下一个字中,因此,使用该指令可高效地实现大整数的移位。图2给出了一个包含5个字的大整数a(a0,a1,...,a4) bit左移得到c(c0,c1,...,c4)的运算示例,该运算从大整数的低位字开始分别计算各个字的漏斗移位结果和最高位字的普通移位结果。同理,大整数的右移运算可以从数的高位字开始计算各个数的漏斗移位结果和最低位字的普通移位结果。

图2 大整数左移运算示意图
3.2 模加、减运算优化
模加、减运算可分解为加、减运算和模约运算,本文将以加法运算为例介绍如何使用PTX指令集处理进位传播问题,并在最后归纳模约运算的实现过程。
CUDA的PTX指令集对进位处理的支持使得大整数的加减运算可被高效地实现。图3为包含5个字的大整数加法运算示意图。当计算大整数最低位字时,无需考虑进位的计算,因此使用不考虑进位的a dd指 令,但需要使用. cc将计算产生的进位写入CC.CF中。在后续的 a ddc.cc加法指令中,进位将通过CC.CF寄存器传播到下一个字中。需要注意的是,CUDA没有提供对CC寄存器的设置、清除和测试操作[17]。因此,需要额外使用一次 addc或subc指令来得到最终的进位,同时可以利用最终的进位来完成剩下的模约操作。同理,减法运算也可以使用s ub和 s ubc指令来实现。[0,p)条件,因此,a−b运 算的取值范围在(−p,p)之间且最多需要一次加法使结果归约到[0,p)之间,即c=a −b或c=a −b+p。与模加运算不同的是,模减运算只需在a−b产生借位时进行一次加法运算即可将结果归约至[0,p)之间。


图3 加法运算示意图
3.3 模乘运算优化
本文将模乘运算分解为乘法运算和模约运算,并分别讨论乘法和模约运算的优化方法。
平方是一种特殊的乘法运算,考虑到其中含有重复的乘法指令(如ai×aj与aj×ai),这使得平方运算可比通用乘法运算更快地执行[19],因此我们将乘法运算分为通用乘法和平方运算,并对平方运算做特殊优化处理。如图4所示,对大整数a=(a4,...,a1,a0) 进行的平方运算可拆分为25次子乘法ai×aj,i,j=0,1,...,4,图4中黄色方格代表平方运算中重复的子乘法,其结果与灰色方格所代表的子乘法结果相同。因此,平方运算可通过先计算所有灰色方格中子乘法的值,再将结果扩大两倍(即结果左移1 bit),最后加上所有蓝色方格中子乘法的值来实现。
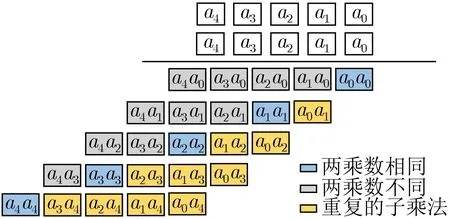
图4 平方运算示意图
由于SM2算法中绝大部分的模乘运算都是在素数域中进行的,而该素数域下存在极其高效的模约算法,本文将使用该算法来优化模乘运算。2.2节中表1算法为针对模数PSCA-256的高层模约算法,其需要14个临时值计算得到范围在[ 0,14PSCA-256)的结果Z,最后再将Z约减至范围[ 0,PSCA-256)内。本文通过使用PTX指令集对高层算法进行优化,以省略高层算法需要的赋值操作并减少该算法使用的临时变量,接着提出进一步约减算法,通过最多两次模加减操作即可将结果约减至[ 0,PSCA-256)内,具体说明如下。
令Z=(Z8,...,Z1,Z0)为288 bit大数,包含9个字,用于存储范围在[ 0,14PSCA-256)的结果,则表1算法中步骤s1+s2的底层指令可表示为式(4)–式(9)
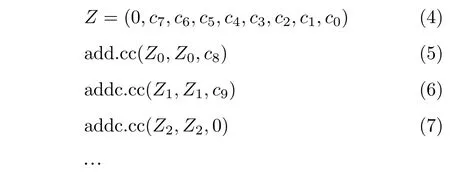

同理,可使用PTX指令集完成剩下的加减操作得到结果Z ∈[0,14PSCA-256),而对结果Z的进一步约减可通过重复减去PSCA-256来实现。值得注意的是PSCA-256的大小非常接近2256, 因此根据Z8的值推断重复减去PSCA-256的次数。并且根据式(10)构 建 表T[14]={0,t,2t,...,13t},其 中,t=2256−PSCA-256,可将n次 减去PSCA-256的重复减法转化为一次加nt的加法,而式(10)中减去2256n的操作可通过忽略最高位字实现。
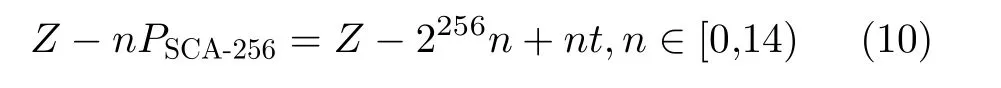
因此,对结果Z的进一步约减算法如表3所示。其中, ADD(X,Y,Z) 和S UB(X,Y,Z)分别为大整数加减函数,其功能分别为计算大整数之间的加法X=Y+Z和减法X=Y −Z,并返回最终的进位或借位。表3算法的核心思想是根据PSCA-256的大小非常接近 2256的性质,将式(10)中的n近似地看作Z8来 确定n的 值,但由于PSCA-256与 2256之间存在误差,所以若加法计算产生了进位则需要再减去PSCA-256。

表3 进一步约减算法
3.4 模逆运算优化
模逆运算是椭圆曲线素数域中开销最大的运算,同时也是制约SM2算法运行效率的瓶颈之一。考虑到GPU拥有强大的乘法计算能力但分支预测能力较弱,且线程束分化现象会严重降低GPU处理效率,因此本文选择基于费马小定理来对GPU环境下的模逆运算进行实现和优化。
为了减少模逆运算带来的计算开销,本文选择在Jacobi坐标系下计算椭圆曲线点加。通过分析SM2算法可以发现,签名过程中需要进行两次模逆运算,分别是Jacobi-仿射坐标转换过程所需的模逆运算和签名算法步骤4所要求的模逆运算,同时验签过程只需进行一次坐标转换的求逆。而签名算法步骤4中的dA是签名方已知的私钥,这意味着(1+dA)模n的逆可以被提前计算好从而省去本次模逆运算。因此整个签名、验签算法都只需要进行一次坐标转换的模逆计算,即素数域下的模逆。在使用费马小定理计算模逆时,运算幂次为p−2,如式(11)所示

素数PSCA-256在整个SM2签名系统中固定不变,因此,我们可以提前计算好素数PSCA-256的加法链,并利用加法链来减少模幂运算过程中的模乘次数。 Zhou 等人[11]采用此方法,通过255次模平方运算(S)和15次模乘运算(M)完成了模逆的计算。本文进一步缩短素数PSCA-256的加法链,使模逆的计算开销降至255S+14M,模逆的具体计算过程如表4所示。

表4 针对素数P SCA-256的快速模逆算法
4 椭圆曲线多倍点运算的优化


本文将窗口法拆分为预计算环节和主循环环节,如表5所示,分别优化两个环节的计算过程。在预计算环节,需计算Pi=[i]P,i ∈{0,1,...,2w −1},我们利用倍点运算比点加运算开销更小的特性,在预计算时多使用倍点运算来减少计算开销,即通过先计算所有奇数倍的点,之后使用倍点运算求出剩下的点。值得注意的是,预计算表的P0设置为无穷远点,这虽然会占用一定的存储空间,但可在主循环中省去对kj是否等于0的条件判断,从而减少线程束分化现象对计算效率的影响。在主循环环节,使用文献[20]中的重复倍点(repeated doubling)算法计算[ 2w]Q,该算法比多次使用倍点运算更加高效。此外,预计算表的大小也需适当选取,若预计算表过小,则加速效果不明显,若预计算表过大,则建表时间长且占用的缓存空间大,会降低整体的吞吐量。经过实验测试验证,表内存储16个点最为合适,即w=4。

表5 优化的窗口未知点乘法
5 实验分析
目前,学术界通常以吞吐量和时延作为主要评价指标来衡量GPU上算法的性能表现[21,22],其中,吞吐量代表计算设备每秒能够进行计算操作的次数,时延用于衡量计算请求处理时间的长短。本文以吞吐量为评价指标分别测试所提的未知点乘算法和模逆算法的性能表现,并与其他方案作对比;最后测试签名、验签算法的吞吐量和时延,以评估本文所提SM2数字签名计算优化方案的整体性能。GPU测试平台为RTX 3090,软件开发环境为CUDA 11.1,操作系统为Ubuntu 18.04。
在GPU中,线程以线程块的形式被组织,线程块大小表示其中包含线程的数量。GPU上运行线程的总数为线程块大小与线程块数量的乘积。当GPU上运行线程数较少时,GPU处于低负载状态下运行。同理,当GPU上运行线程数足够多时,GPU处于高负载状态下运行,此时GPU的计算能力可得到充分发挥。由于GPU的计算资源是固定的,当GPU处于高负载状态下时,线程块大小决定了每个线程所能分配到的计算资源,从而影响算法的运行效果。因此,合理配置线程块大小是达到算法最优运行效果不可或缺的一步。为探究线程块大小的最优配置,设置线程块大小size为64,128, 256, 512,分别测试不同算法在GPU高负载运行时的吞吐量结果。实验结果如表6所示,本文所提快速模逆算法、基于扩展欧几里得的模逆算法、快速未知点乘算法、SM2签名和验签算法分别在线程块大小为64, 512, 512, 128和128时达到最高吞吐量。
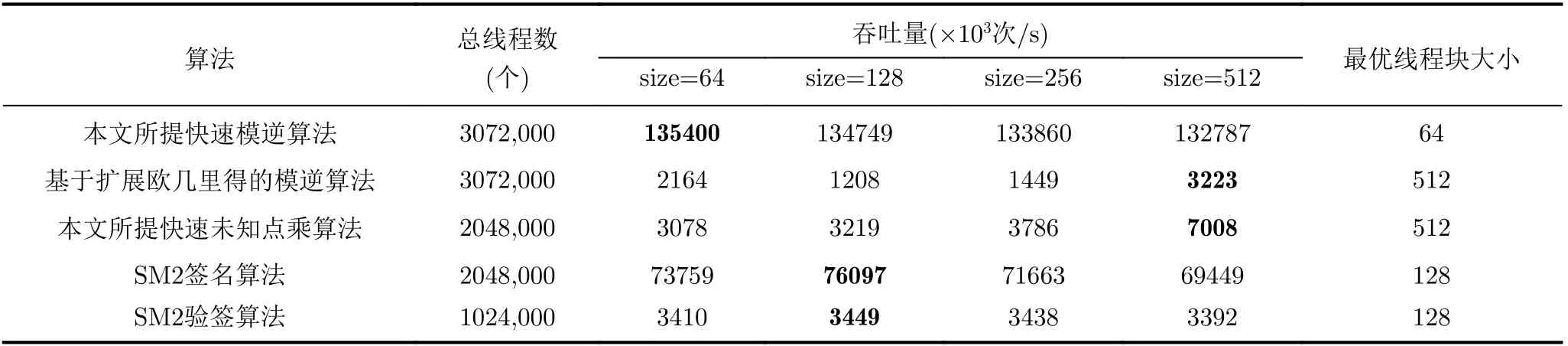
表6 GPU高负载运行时不同算法的吞吐量结果
根据上述实验结果,分别设置线程块大小为64与512,测试本文基于费马小定理优化实现的模逆运算与基于扩展欧几里得的模逆运算的性能表现。经过测试发现,本文基于费马小定理优化实现的模逆运算吞吐量可达到1.33×108次/s,而基于扩展欧几里得算法的模逆运算吞吐量最高只有3.21×106次/s。而且无论GPU负载如何,本文所提快速模逆算法吞吐量远大于基于扩展欧几里得的模逆算法,测试结果如图5所示。这说明尽管扩展欧几里得算法的计算开销更小,但其复杂的逻辑结构导致其极不适合在GPU这种分支预测能力弱的设备上运行。而计算开销更大的基于费马小定理的模逆算法,由于其算法结构简单且只含有GPU擅长的模乘计算,导致该算法在GPU上的性能表现极其优秀。更重要的是,由于本文对底层模乘算法进行了优化,并且通过加法链优化了模幂的计算过程,也使得模逆运算效率大大提升。

图5 模逆运算吞吐量测试结果
在未知点乘运算性能测试方面,为了评估本文所提算法的实际性能表现,本文选取Pan等人[7]提出的未知点乘优化算法,并在相同计算环境下与其做性能对比测试。设置线程块大小为512,分别测试本文与Pan等人[7]提出的未知点乘优化算法在不同GPU负载下的吞吐量表现情况,测试结果如图6所示。从实验结果来看,本文所提未知点乘优化算法在GPU高、低负载下吞吐量都超过了文献[7]提出的算法,可达到7.04×106次/s。

图6 未知点乘运算吞吐量测试结果
最后,设置线程块大小为128,测试本文所提的SM2签名、验签计算方案整体性能表现。图7、图8分别显示了签名、验签算法的吞吐量和时延在不同线程块数量下的表现情况。从实验结果可以看出,算法吞吐量随着GPU运行线程数量的增长而增长,最终吞吐量趋于稳定,算法时延随着GPU运行线程数量的增长而增大。其中,签名和验签算法吞吐量分别可达到7.609× 107次/s和3.46× 106次/s,此时的算法时延分别为26.9 ms和150.4 ms。此外,本文提出的优化方案分别在3.1 ms和6.9 ms的低时延状态下也能达到2.04× 107次 /s和1.85× 106次/s的吞吐量。

图7 签名算法吞吐量和时延测试结果

图8 验签算法吞吐量和时延测试结果
为了评估本文所提签名、验签优化方案的性能表现,本文与GPU平台上已有的ECC优化成果进行了对比(如表7所示)。由于各个研究成果所使用的GPU设备不同,本文给出了GPU的整数/浮点性能作为GPU性能参考。从表7可以看出,本文使用GPU性能大约为Pan等人[7]的3.3倍,所实现签名、验签算法吞吐量大约为其8.7倍和3.7倍,其中签名运算性能提升尤为突出,这是主要是因为采用预计算表对固定点乘加速后,模逆运算成为影响签名效率的最大瓶颈。而本文选择了基于费马小定理的模逆算法,避免了线程束分化现象,并细致优化底层模乘运算,使模逆运算效率得到极大提升,从而提高签名性能。此外,考虑到本文优化的SM2算法开销略大于Pan等人[7]优化的ECDSA算法,因此,可以得出结论,本文的SM2算法优化效果优于Pan等人[7],和其他优化方案[21–23]相比,本文优化效果也处于领先地位。

表7 GPU平台各个ECC优化方案性能对比
此外,本文还在普通家用GPU设备T1000上进行了同样的测试,以验证在不同计算能力的GPU设备上能否得到相同的实验结论。表8为普通家用GPU设备T1000上各个算法的运行情况。从表中可以看出,在T1000设备上,签名、验签算法吞吐量分别达到6.34×106次/s和3.45×105次/s。同时,可以看出本文所提模逆优化算法在T1000上性能同样远超扩展欧几里得算法,且提出的未知点乘优化算法吞吐量在T1000上的吞吐量也超过了文献[7]提出的算法。因此,本文所提各个优化算法能够适应不同的GPU设备,具有良好的通用性。
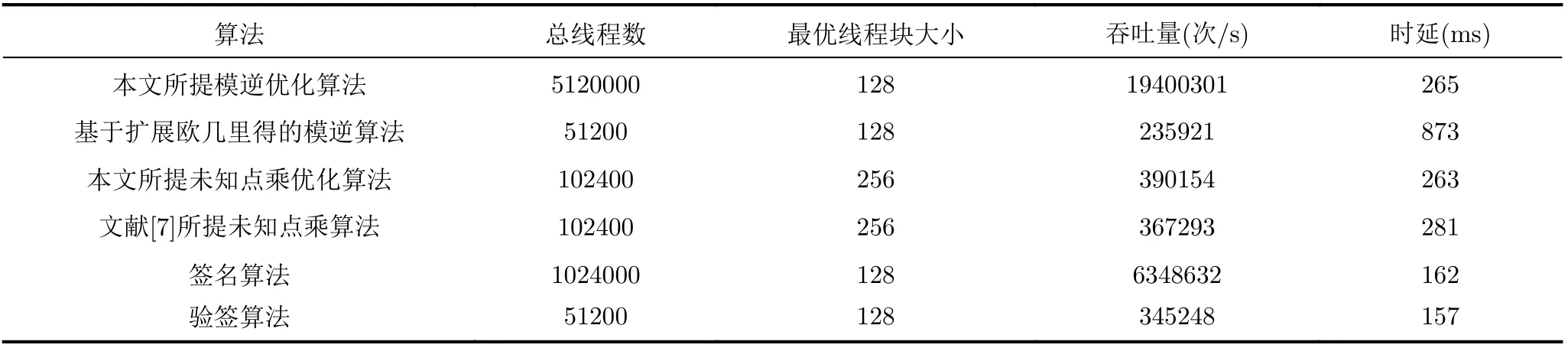
表8 T1000上各个算法的性能表现
6 结束语
本文选择了GPU作为SM2算法的优化平台,提出了一种基于GPU加速的高吞吐量SM2数字签名计算方案。通过使用GPU底层指令构建了高效的基础运算,为上层运算提供效率上的支持;同时,结合GPU乘法计算能力强的特性,基于费马小定理优化实现了高效的模逆计算模块,提升模逆处理速度;而且利用倍点运算比点加运算开销更低的特性,构造预计算表,提高计算效率;最后在GPU上实际实现了所提SM2签名和验签的计算方案。实验结果表明,所提计算方案在RTX3090单卡上可以达到7.609×107次/s的签名吞吐量和3.46×106次/s的验签吞吐量。
