跨域特征融合的端⁃边协同遮挡人脸识别方法
2022-12-26吴大鹏谭磊张普宁杨志刚王汝言
吴大鹏,谭磊,*,张普宁,杨志刚,王汝言
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.先进网络与智能互联技术重庆市高校重点实验室,重庆 400065;3.泛在感知与互联重庆市重点实验室,重庆 400065)
1 引言
人脸识别[1]是计算机领域最热门的研究方向之一。人脸识别在我们的日常生活中起着非常重要的作用。如今,新冠病毒在世界范围内的传播对人们的生产生活造成了巨大的影响。为了阻挡新冠病毒以及可能出现类新冠等呼吸道病毒的传播,许多国家都鼓励非接触性的操作,如在机场、地铁站和地铁站等人员密集的公共区域佩带口罩。在这些人员密集的场所,快速通过安检区域能够减少人与人之间的接触并且避免人员之间的聚集,因而在大流量人群环境下如何降低人脸识别时延是重要的科学与实际应用问题。然而,佩戴口罩会遮挡脸部的大部分区域,导致大量的面部特征无法提取,直接影响人脸检测和识别的性能。由此,研究人员提出面向遮挡人脸的有效识别方法[2]。
人脸识别的精度与图像质量直接相关,带有噪声和低质量图像将引起的人脸识别率降低。因此,研究人员提出可对图像数据进行预处理以获得更好的识别性能。目前的人脸图像预处理技术主要包括:裁剪、调整大小、锐化、去噪、归一化、增强等[3]。主成分分析(PCA)在正常或非遮挡人脸识别中达到了很好的准确率[4]。基于小波变换的图像去噪技术可以用于对人脸图像的噪声处理,可以用于人脸识别的预处理过程[5]。基于局部保持投影(LPP)[6]的方法也被用于人脸识别中,它是一种流形学习方法,在人脸识别中能够产生稳定的高分类精度。但是这些传统方法在遮挡人脸识别中表现的性能较为有限。
遮挡人脸识别的任务旨在将图像与随机部分遮挡进行匹配。解决遮挡人脸识别问题(OFR)的现有方法主要有两种:(1)特征提取方法,首先定位遮挡的面部区域,然后仅从非遮挡的面部提取特征区域;(2)基于图像重建的方法,从被遮挡的人脸中恢复出完整的人脸以提取鲁棒的身份特征。最近,深度卷积神经网络在无约束环境下识别人脸图像取得了很大的进展[7]。第一种方法主要是增强未遮挡部分的特征提取,通过修改深度神经网络架构[8]、[9]、[10]或者设计新颖的损失函数和训练策略[11]、[12]、[13]。第二种主要是图像修复方法,充分利用遮挡部分的特征。Ding等人[14]提出潜在部分检测模型来定位对面具佩带具有鲁棒性的潜在面部部分,利用潜在特征来提取判别特征。Lu等人[15]提出一种口罩遮挡检测和恢复的框架,利用自适应上下文信息和相邻像素的相关性来实现恢复人脸的高度真实感,以此提高遮挡人脸识别和验证的性能。因此,仅仅只是考虑人脸的单一特征势必会丢失大量可用的特征,所以融合显示域和隐式域特征是一种能够保留整体人脸感知的重要方法。
边缘计算[16]是一种新兴的计算架构,它将计算能力从集中式云中心迁移到更靠近用户端和移动设备的边缘,在边缘执行计算相对于云计算而言可以减少延迟,提供实时响应,降低网络带宽负载,并缓解云中心的计算负载。边缘计算在静态目标识别方面取得了显著的成果,但是在识别动态目标时性能有限。传统识别方法由于对计算、与存储资源的要求很高,在终端设备中不再适用。现有的遮挡人脸识别方法没有综合考虑边缘和终端的资源特征,目前尚未出现面向遮挡人脸识别的端边协同识别方法研究成果。为此,本文提出跨域特征融合的端-边协同遮挡人脸识别方法,融合人脸显式域与隐式域特征设计跨域特征融合方法,并结合终端、边缘的资源特点设计端边协同识别方法。
2 端⁃边协同识别架构设计
现有基于边缘计算的人脸识别架构忽略了终端的计算能力,面对人员密集场景下的遮挡人脸识别任务适用性有限。为此,设计了“端-边”协同的遮挡人脸识别架构。该架构包括图像采集终端层和边缘层。图像采集终端层由摄像头等图像采集终端构成,主要采集机场、火车站、高铁站等人员密集区域入口处的海量遮挡人脸图像数据。边缘层主要由部署于该区域的边缘服务器构成,负责遮挡人脸图像的快速识别。系统架构如图1所示。

图1 端⁃边协同识别架构
在终端侧,需要对人脸数据进行采集以及对图像中的人脸边界进行定位,通过人脸检测模型提取人脸区域,去除无关背景区域,然后把人脸区域的图像上传到边缘服务器,以达到有效压缩传输图像数据量的作用,降低图像传输时延。
在边缘服务器上,采用所提跨域特征融合方法,通过注意力机制对未遮挡区域进行特征提取,模糊掉遮挡区域的部分,然后基于图像补全方法来对遮挡区域进行人脸补全,获取人脸的全局特征,通过对人脸的特征进行融合,最后使用人脸识别网络模型识别人脸的身份信息。由于机场、火车站、高铁站等人员密集区域,边缘服务器需对海量人脸图像进行实时识别,当高峰期出现遮挡人脸识别任务聚集时,边缘服务器采用所提时延优化的边缘识别任务调度方法进行调度,从而避免在此类区域出现大面积人群聚集和安全问题。
3 跨域人脸特征融合方法
3.1 显式域特征增强方法
遮挡人脸识别(MFR)旨在将遮挡人脸与未遮挡或遮挡整体人脸进行匹配。为了研究掩模遮挡对模型特征提取能力的影响,引入了文献[17]中提出的中值相对变化率(MED)的标准,以捕获每个特征元素在掩码遮挡下远离其非遮挡的程度。以一对无遮挡的人脸图像Ino-mask及其对应的遮挡人脸图像Imask作为输入,使用以下公式计算顶层卷积层特征的神经元激活值的相对变化率:

其中f i(∙)是顶部卷积特征图,ri是特征图的第i个元素的相对变化率。
有研究表明,遮挡对通道元素的变化影响分布不均[18],下半部分人脸区域的MED值较大,这表明遮挡给从人脸下半部分得到的特征图带来了较大的噪声,影响了FR性能。本文设计基于注意力机制设计显式域特征提取模块(EFE),以增强有效通道和空间位置的权重,它们对掩模遮挡不敏感,并且有助于学习遮挡鲁棒的身份特征,以指导人脸识别模型中的骨干网络为非遮挡面部分配更高的权重,以便在训练中侧重学习更加稳健的特征。为了增加特征图上有效通道和空间位置的权重,以提高对掩模遮挡的鲁棒性,本文提出的架构同时利用空间和通道注意。通道注意图是利用特征图的通道间关系生成的,为了有效地计算它,有必要分别通过平均池化操作和最大池化操作来压缩特征图的空间维度,因为特征图的空间统计信息(空间上下文描述符)聚合空间信息。显式特征增强模块如图2所示,两个空间上下文描述符被转发到主干网络并且使用元素求和,将相应的输出特征向量连接起来以生成通道注意图Mc∈RC×1×1,并且网络使用了一个内核大小为K的通道一维卷积,它交换了空间上下文描述符的本地跨通道信息。权重提取部分使用一维卷积,不仅增强了跨通道交互,而且避免了降维并降低了复杂度,定义如下:

图2 显式域特征增强模块

其中δ表示矩形函数,E1K表示具有内核尺寸K的一维卷积操作。本文提出的网络是一个轻量级的自注意力模块,它计算通道和空间位置之间的相关性以增加有效通道和空间位置的权重,对人脸图像的掩模遮挡具有鲁棒性。
3.2 隐式域特征预测方法
若仅对人脸图像的未遮挡部分进行特征提取,丢掉遮挡人脸部分的特征,会造成大量的特征损失。因此,本文设计隐式域特征增强模块(IFE),采用补全方法来进行图像重建,利用图像重建的方法修复人脸,以获取人脸的隐式域特征,从而保留人脸的整体感知,基于深度生成网络的隐式域特征增强模块构建一个由成对判别器和一个生成器组成的网络。
生成器网络:网络的生成器采用编码器、转换器和解码器结构。编码器由6层卷积层组成,依次逐渐提取更加高级的特征,解码器由5层卷积层组成。转换器由6个残差块组成,由编码器输出图像的不同通道组合了图像的不同特征,根据这些特征将图像的特征向量即编码由带遮挡转换到无遮挡。每个残差块由两个卷积层组成,为了确保先前图层的输入属性也可以用于后面的图层,将输入残差添加到输出中。解码使用反卷积层进行上采样,解码器的作用是从特征向量重新构建低级特征,在编码层使用卷积算法,为下采样,将高维图像转换为低维图像的过程。该网络可以使编解码具有优异的性能,从而使网络生成高质量的图像数据。
双判别器网络:为得到更真实的结果,使用双判别器分别判断局部生成部分图像和全局生成图像。在人脸修复过程中,生成器对缺失区域进行修复,并将结果发送给判别器,判断其是否足够真实。由于判别器是二分模型,在模型训练的初始阶段,不同类型的图像输入到判别器中会造成不稳定,本文使用交叉熵损失来优化生成器,然后计算真实图像特征与生成特征之间的MSE(均方误差损失),以优化生成器。因此,交叉熵损失不
损失函数:会损失更多的信息,从而在很大程度上保证了模型训练的稳定性。
局部判别器:提出了一个局部判别器网络,它确定掩码中产生的内容的真实性。局部鉴别器开始帮助生成具有合理边界的掩码内容的细节。为了便于计算特征匹配MSE(均方误差损失),在判别网络中添加了一个输出。在网络的中间层,使用池化操作来降低转化为特征向量的特征的维数。首先,局部损失不能正则化人脸的全局结构,也不能保证遮挡区域与外部的一致性。因此,本文还引入了全局鉴别器来确定全局图像。
全局鉴别器:引入另一个全局鉴别器来判断整个完成图像的真实性,新生成的内容不仅要真实,还要与周围的语义一致。全局判别网络极大地缓解了真实区域与掩蔽区域的不一致,进一步增强了生成内容的真实性。与局部鉴别器一样,本文将输出添加到全局鉴别器网络。在网络的中间层,使用池化操作来降低特征的维数,这些特征也被转化为特征向量。
通过回归到缺失(退出)区域的真实内容来训练本文的上下文编码器。为了填补大量的缺失区域,在图像修复过程中引入L2图像重建损失是一个通用的思路。然而,通常有多种同样合理的方法来填充与上下文一致的缺失图像区域。本文通过解耦联合损失函数来模拟这种行为,以处理上下文中的连续性和输出中的多种模式。重建(L2)损失负责捕获缺失区域的整体结构和与其上下文相关的连贯性。同样,将重建损失Lre引入到生成器中,即网络输出与原始图像之间的L2距离。所以,本文使用掩码L2距离作为重建损失函数Lre:

对于每个真实图像x,上下文编码器F产生一个输出F(x)。设̂是对应于被丢弃的图像区域的二进制掩码,在任何一个像素被丢弃的地方,其值为1,对于输入像素,其值为0。其中∙是元素乘积运算。
本文的人脸修复网络有两个鉴别器,因此有两个对抗性损失来优化网络。在训练成对判别器时,局部和全局判别器分别返回局部和全局损失,使得恢复的人脸图像与从训练集中提取的样本相似。局部判别器有助于生成具有更清晰边界的掩蔽内容的细节,而全局判别器大大缓解了真实区域与掩蔽区域之间的不一致性,进一步增强了生成人脸图像的真实性。传统的判别器提供的信息太少,这不可避免地导致生成器的训练过程相当不稳定的问题,尤其是在输入大量训练样本时。因此,设计了一个成对的特征匹配损失,使训练过程更加稳定。让和代表设计的配对特征匹配损失。这样可以从判别器网络中学习到尽可能多的人脸特征,从而使训练更加稳定:

其中D是预训练的VGG特征提取器,G表示生成器,z表示输入网络的损坏图像,x表示真实图像。因此,联合损失可以有如下式子表示:设α1和α2代表权重,以平衡设计的损失类型。

如图3所示,跨域特征融合模块由显示域特征增强模块和隐式域特征挖掘模块组成。这个模块是嵌入在主干卷积神经网络中,可以是任何深度的卷积神经网络架构。人脸图像数据通过骨干网络会提取特征,对于人脸的显式域特征使用IFE模块进行增强;对于人脸的隐式域特征使用EFE模块进行挖掘。当人脸识别模型把这两种特征提取之后,最后,使用全连接(FC)层将高维特征转换为与全局嵌入特征具有相同维度的嵌入特征。学习到的人脸全局特征嵌入作为分类器的输出,并且网络以端到端的形式进行训练。在边缘服务器上,人脸识别模型会对人脸特征进行编码输出,再与人脸数据库中进行对比,最后输出最符合的人员身份信息。

图3 跨域特征融合方法
4 时延优化的边缘识别任务调度方法
4.1 问题建模
如机场、火车站和高铁站等人员密集场所中,进出人员的排队时间过长易增加疫情传播风险,已有研究致力于缓解计算资源的限制,未考虑遮挡人脸识别任务的时延优化。为避免人员长时间聚集而带来的安全风险,本部分设计基于边缘计算的识别任务调度方式,利用端-边协作的架构来进行任务调度,以此来减少人脸识别任务的整体时延。
用V={V1,V2,...,Vm}表示视觉终端的集合E={E1,E2,...,Em}表示边缘节点的集合。假设一个集合中的视觉终端与一个边缘节点直接连接。在时隙t∈T中,人脸识别任务图像数据随机达到,并且正确调度到目的位置。人脸识别任务调度算法在每个时间步选择一个或多个等待任务调度到边缘或者协作边缘。假设每个人脸识别任务的资源需求在它们到达时是已知的;每个人脸识别任务α的资源需求为α={α1,α2,...,αn},其中αn为第n个人脸识别任务所需的资源(例如,内存、带宽,计算资源)。为简单起见,假设没有抢占和固定分配配置文件,这意味着必须从任务执行开始到完成连续分配α。本文设置在预先知道人脸识别任务处理请求的前提下,尝试最小化延迟。任务分配中的卸载问题由二进制变量xfα决定,表明任务α的卸载目标地点,若为本区域边缘节点(E1),则xfα=0;若为协作边缘节点(Em),则xfα=1:

其中α是人脸识别任务,Tαdet是人脸检测的时间,T αtrans是指任务传输到边缘节点的时间;T αrec表示任务α进行人脸识别的时间;T αwait为人脸识别任务α的等待时间。用公式(7)表示优化函数:

式(8)表示人脸图像数据在给定时间卸载到边缘的时间最大为θ,式(9)表示任务在给定时间卸载到协作边缘的时间最大为σ,式(10)表示任务计算总时间不应超过任务α的时间阈值τα。最后,式(11)表示整个时间内可用带宽。公式(7)是一个混合整数非线性过程,它是一个NP-hard问题,不能以有效的方式直接解决。在下文中提出一种基于深度学习的算法来解决优化问题,使用持续学习来实现低延迟的识别任务。
4.2 边缘协作决策
在上述问题中,具有不同资源需求的人脸识别任务在每个时隙动态到达,根据相应的边缘节点的可用资源来为每个任务分配带宽和计算资源,每个资源可以用n+m个选项进行调度。但是我们注意到对当前识别任务进行调度会改变对应的目的位置的可用资源,资源的变化情况会影响下一次的调度,这具有马尔可夫性质。因此我们通过马尔可夫过程(MDP)求解问题(7)。一个MDP可以由一个元组组成S,A,R来描述,S表示系统状态的集合,A表示动作的集合,R表示奖励函数。本部分制定了MDP的系统状态、动作和奖励函数。
本文用一种基于边缘协调的深度强化学习(RL)[19]算法来决定任务调度,如图4所示。Agen(t边缘节点)学习反馈的奖励,并确定增加奖励的调度策略。使用近端策略优化(Proximal Policy Optimization,PPO)[20]算法来优化目标,其具有更快的收敛速度和更好的性能。PPO由一个行动者网络Actor和一个批评者网络Critic组成,它们共同决定动作和状态。
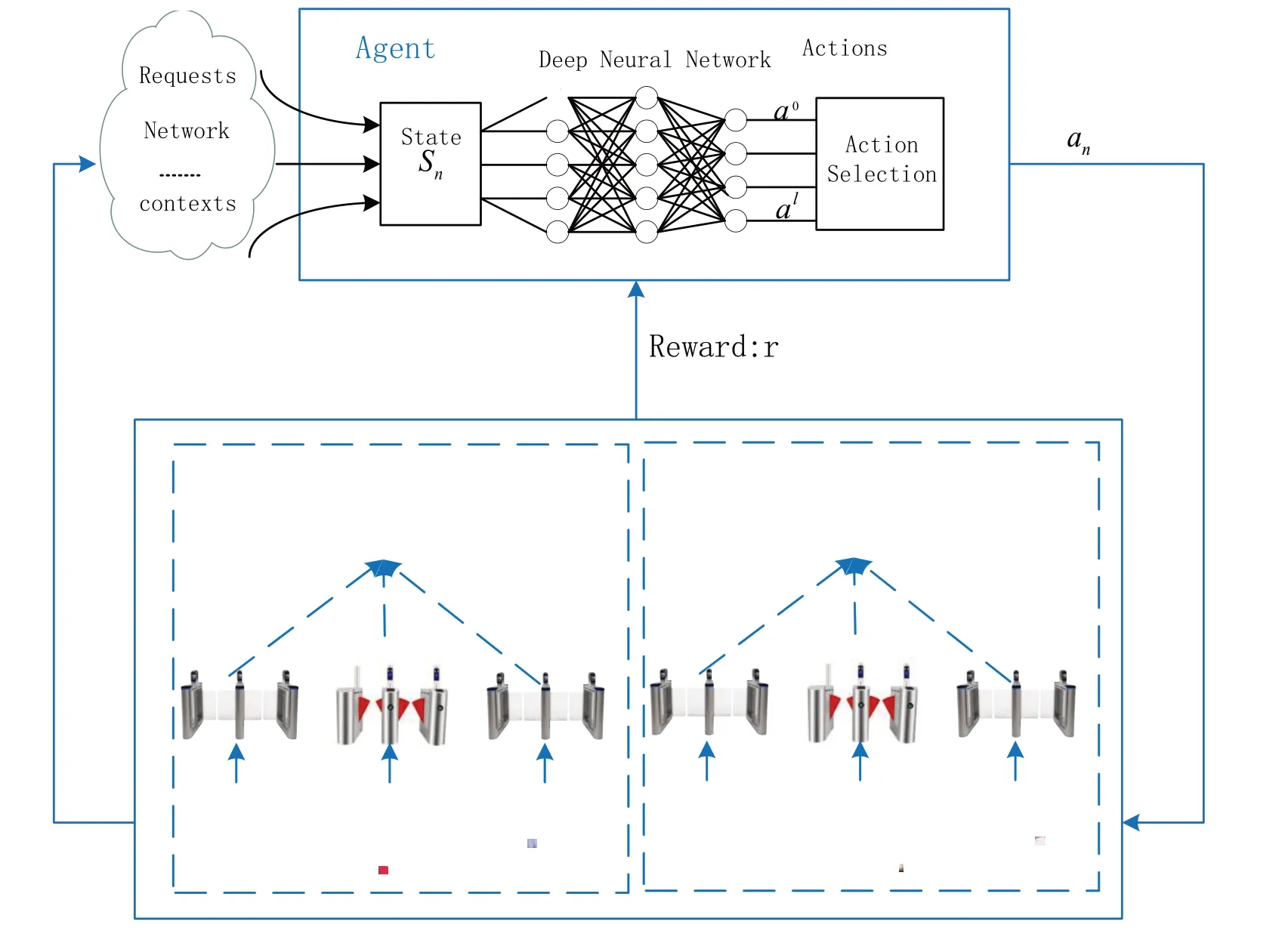
图4 识别任务调度
状态:在每个时隙t∈T,人脸识别系统的状态将被捕获。假设所有人脸识别任务都将在时隙t内处理。让Sα,t={bα,t,cα,t,Lα,t}表示每个识别任务在时隙t中的状态,其中bα,t表示带宽,cα,t表示计算能力,Lα,t表示处理的总延迟。由于每个时隙t都有不同的识别任务,并且有些检测是在几个时隙上处理的,因此每个时隙中的每个检测有三种情况:开始处理检测、正在处理检测和已经处理检测。当检测任务开始被处理或已被处理时,可用资源将被更新。
动作:在每个时隙t,主边缘节点决定人脸识别任务调度,由RL代理根据当前状态为每个任务选择动作表示,状态在第一个时隙重置。在每个持续时隙,调度程序可能想要确认任务α的任何子集。在每个时隙,代理然后观察状态转换,任务α已被卸载到边缘节点(xfα=0)或者协作边缘节点(xfα=1),人脸识别任务将传输到系统中的合适目标位置。
奖励:使用奖励信息来监督代理来找到本文目标的最佳解决方案:目标是在保证T周期内最小化平均延迟。在每个决策时期之后,代理接受来自奖励函数的反馈信号并计算奖励函数的累积和,以达到最小化延迟的最佳目标。
考虑到在MDP中对每个任务的决策是独立的,本文将通过累积奖励实现对每个任务的低延迟和保证准确性,并给出了通过MDP的最终目标。

Rs是在时间段T内某一事件的累计奖励,Qα,t是T中所有人脸识别任务的总和。由于Qα,t和T在一个时期内是常量,定义奖励Rs为:

其中ε∈{0,1},Rα,t表示人脸识别任务在时隙t处的奖励,Rs表示一段时间内人脸识别任务的总奖励。在人脸识别系统中假设N个时期,让gn=表示在T的时隙中第n个时期的人脸识别系统状态和动作的集合,其中=和,另外有t∈{1,2,...,T}和n={1,2,...,N},让θ表示行动者网络参数。然后有在第n个时期采取gn的概率为:

然后可以得到N个时期内的人脸识别任务带来的奖励期望和梯度:

行动者网络利用梯度更新策略以最大化奖励。由于有N个时期,因此可通过以下方式获得平均梯度:

如果θ值发生变化,将通过新的策略收集更多数据进行进一步训练。令表示当前θ策略优于旧θ'策略的重要性权重,并且行动者网络通过以下方式更新:
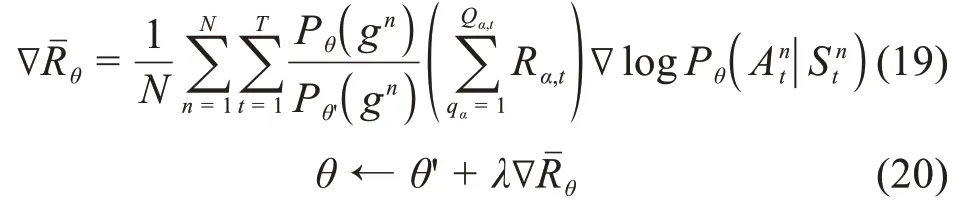
其中折扣因子用λ表示并且λ<1,θ的更新如上式所示。批评者网络利用时间差异(TD)错误来更新:

其中r是当前奖励,V(∙)表示状态值函数,V'(∙)是先前的状态值函数。批评者网络评估是否应采取当前行动,把人脸图像数据传输到目标位置。如果时间差异(TD)误差为正,则表明未来应该加强选择当前动作的趋势,而TD误差为负时趋势相反,批评者网络的参数η通过以下更新:

其中η'是批评者旧的网络参数,并且V(∙)由具有参数η的神经网络近似。最后,本文有了目标函数(23):

Actor和Critic网络的收敛性已在文献[20]中得到证明,它通过基于边缘协调的RL算法获得了低延迟性能。在边缘节点上部署时延优化的人脸识别任务调度算法,在这个过程中,在多个终端工作的情况下,会有大量图像上传,主边缘服务器上的基于深度强化学习识别任务调度策略会根据约束条件对任务进行调度,从而确定最佳的识别任务调度方案,决策上传到主边缘节点还是协作边缘节点上进行遮挡人脸图像的识别。
5 实验
选择RMFD[13]数据集中的RMFRD、LFW[21]和MFR2[22]。RMFRD数据集是从海量互联网资源中获取公众人物的正面图像及其对应遮挡人脸图像,收集人员对收集的数据中由于错误对应导致的不合理的人脸图像进行删除。过滤的过程中采用半自动注释工具裁剪准确的面部区域。该数据集包括525名戴口罩人员的5000张照片,以及相同的525名不带口罩人员的90000张照片。本文的训练集是一个混合数据集,包含遮挡和未遮挡的人脸图像。其中LFW数据库主要是互联网上的手机图像。LFW数据集主要测试人脸识别的准确率,该数据库从中随机选择了6000对人脸组成了人脸辨识图片对,其中3000对属于同一个人2张人脸照片,3000对属于不同的人每人1张人脸照片。为了验证本文模型在真实遮挡人脸数据集,MFR2上进行了实验,MFR2是一个小型数据集,共有来自53个不同身份的269张人脸图像。为了评估MFR2数据集,随机生成800个图像对(400个正对和400个负对)。为了对所提出解决方案的性能进行深入评估,如前所述,使用ResNet作为trunk-CNN模型。在实验中,定义了两个基线模型以进行公平的比较分析。ResNet[23]是广泛使用的卷积神经网络(CNN)架构之一,被多种人脸识别模型使用。
本文应用Pycharm,Pytorch v1.2.0实验库在Ubuntu16.04操作系统上进行了实验,在Intel I9 3.7GHz CPU卡和32GB内存GTX2080 Ti的GPU服务器上运行。通过计算识别测试图像对的精度来评估本文提出的模型在一个真实数据集和两个合成数据集上的性能。在三种不同的测试用例场景下评估了本文提出的模型的性能:(1)Unmasked-to-Unmasked,一个通用的FR任务,评估模型的泛化性;(2)Unmasked-to-Masked,在识别系统中注册未遮挡的人脸图像,以验证戴口罩的人的身份;(3)Masked-to-Masked人脸匹配,确定两个被遮挡人脸的身份相同或不同。
为了进行全面的评估,对真实遮挡人脸数据集RMFRD和MFR2进行了实验。表1显示了识别的准确度的验证结果,表2是AUC的验证结果。对于MFR2数据集上的1:N人脸识别实验,本文将所有未遮挡的人脸图像包含在图库集中,而所有遮挡的人脸图像都包含在验证集中。本文提出的方法对合成和真实掩模遮挡都表现出很高的鲁棒性。这是因为本文的注意力模块利用了面罩遮挡通常固定在人脸下半部分的先验知识,并引导模型关注特征图的上半部分,而不是强制模型以适应任何特定的面具风格。而且本方法充分利用了人脸的隐式特征,不依赖于人脸区域上半部分的裁剪来进行鲁棒的特征学习。
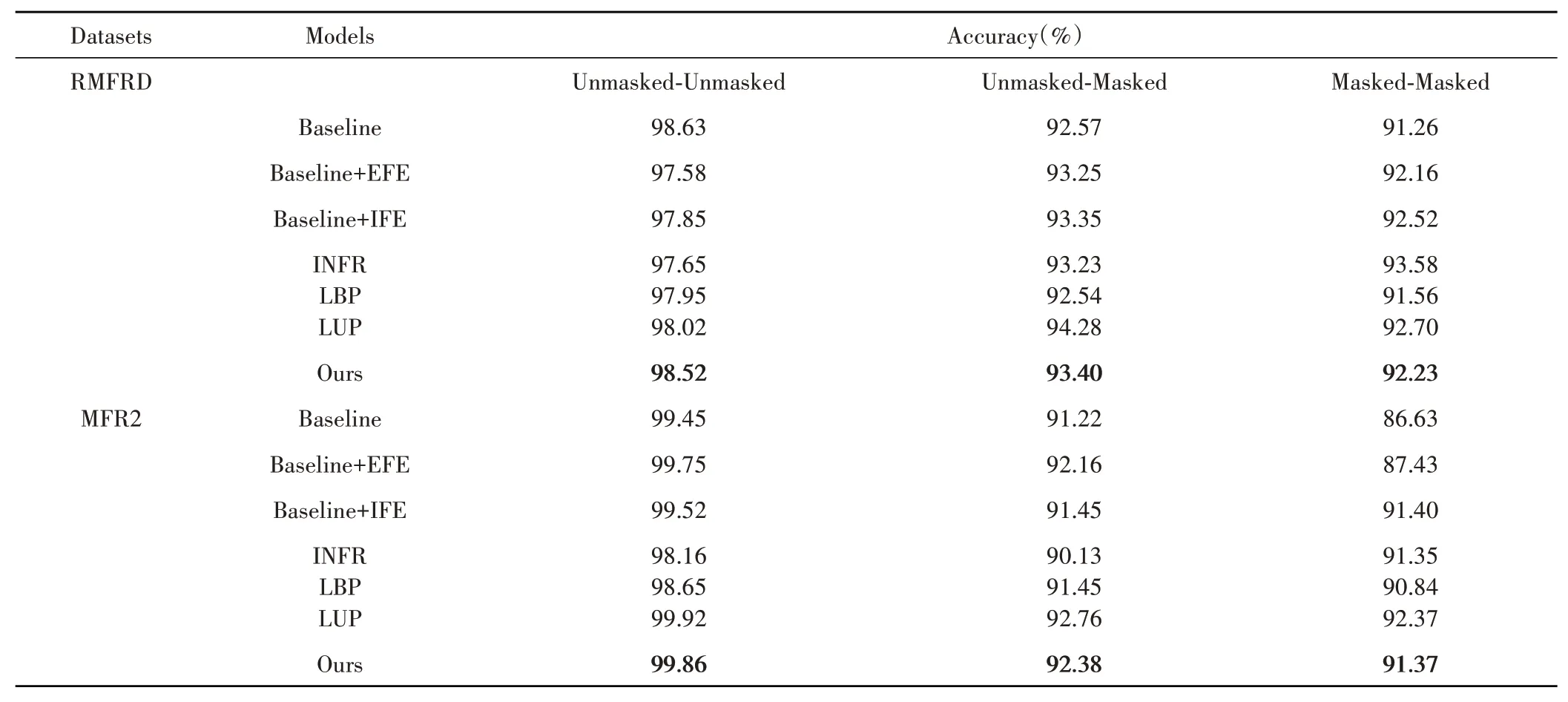
表1 评估结果

表2 AUC验证结果
本文还探讨了模型结构的修改并评估两种不同模型配置下的性能。在第一个配置中,即Baseline+EFE,从本文提出的框架中删除了隐式特征增强方法,仅将显式特征嵌入到主干CNN模型中以进行性能评估。在第二个配置中,即Baseline+IFE,删除了显式特征,只使用了提出的框架中的隐式特征增强方法进行评估。
为了比较本文的方法与基线的计算复杂度,测试了每秒浮点运算(FLOPs)并计算了网络参数的数量,如表3所示。本文的模型没有增加复杂度,并且降低了30%的识别时延,所提方法在减少人脸识别整体时延中的平均增益比例为57%。

表3 不同方法在网络参数、每秒浮点运算数(FLOPs)方面的比较(其中M表示以百万为单位的单位)
6 总结
本文提出了一种端-边协作的人脸识别架构,并结合新颖的注意力和人脸全局特征增强的引导深度CNN模型,用于解决遮挡人脸识别问题。本文提出了一种跨域特征融合的方法,在增强显式人脸特征的同时,尽可能挖掘到人脸的隐式特征,保留整个人脸的整体感知。此外,通过对大规模的识别任务的分析,通过深度强化学习的方法对任务进行调度,以实现识别的最优时延。在多个合成和真实遮挡人脸数据集上进行的大量实验表明,本文提出的方法在处理遮挡问题方面具有优越性,同时在一般人脸识别任务上保持高性能。未来,将把研究工作扩展到一般的遮挡人脸识别任务。
