基于不同机器学习的农作物遥感分类与精度评价研究
——以新疆维吾尔自治区阜康市为例
2022-12-24张旭辉玉素甫江如素力仇忠丽亚夏尔艾斯克尔阿卜杜热合曼吾斯曼
张旭辉,玉素甫江·如素力,2*,仇忠丽,亚夏尔·艾斯克尔,阿卜杜热合曼·吾斯曼
(1.新疆师范大学 地理科学与旅游学院 流域信息集成与生态安全实验室,新疆 乌鲁木齐 830054;2.新疆干旱区湖泊环境与资源重点实验室,新疆 乌鲁木齐 830054)
中国是一个农业大国,农业问题一直备受关注。及时、准确地获取农作物种植类型和空间分布信息对于农业政策制定及国家粮食安全的准确评估起着重要作用[1-2]。阜康市位于中国新疆东天山山脉北坡,土地利用和土地覆盖变化复杂,农业生产受到干旱缺水、低温高寒、土壤盐渍化和沙漠化等的威胁,生态环境脆弱[3]。因此,在该地区开展土地分类研究,特别是农作物遥感分类研究,对于保障干旱地区农业可持续发展和维护国家粮食安全具有重要意义。
遥感技术因其全天候、动态、综合和成本较低等优势已被运用于许多研究[4]。机器学习算法通过自身启发式学习策略和学习引擎,可以有效提高数据处理的时间效率和分类结果的准确性,成为现阶段大面积农作物遥感识别的主流方法[5]。目前,国内外有See5.0[6]、k均值聚类(k-means)[7]、支持向量机(SVM)[8]、关联规则(Apriori)[9]、期望值最大化(EM)[10]、PageRank[11]、AdaBoost[6]、k最邻近分类(kNN)[12]、朴素贝叶斯(Naive Bayes)[13]、分类与回归树(CART)[14]等十多种数据挖掘算法,在各自研究领域被广泛地引用和使用且取得较好的数据挖掘效果(精度一般大于70%)[15]。近些年,随着遥感大数据自动分析与数据挖掘技术的迅速发展,基于MODIS[16]、Landsat TM/ETM+[17]、高分卫星[18]、GF-1/WFV[19]、SPOT-5[20]等多光谱数据在地物遥感识别领域取得很好的结果[21],突破中低分辨率遥感影像的束缚,利用先进的机器学习算法,选择合适的分类特征,解决地物信息识别精度较低等问题。Neetu等[22]使用Sentinel-2数据探索不同机器学习算法对农作物遥感分类的能力,随机森林(93.30%,0.9178)算法和CART(73.40%,0.6755)算法在总体分类精度和Kappa系数方面优于SVM(74.3%,0.6867)算法;Zheng等[23]利用时间序列Landsat NDVI数据结合SVM算法识别灌溉作物类型,总体分类精度高于86%,表明SVM算法可以有效地进行农作物分类。黄双燕等[24]采用随机森林算法分类农作物,总体分类精度均达到89%以上,在引入地块基元和红边特征后,分类精度分别提高2.39%和1.63%,说明红边特征的使用有助于提高农作物的分类精度。可以看出,用于遥感识别农作物的机器学习算法主要基于CART算法、随机森林算法和SVM算法,缺乏对于复杂种植模式、气候和地形条件的农作物分类方法。See5.0决策树算法是一种自动提取分类规则的数据挖掘工具,具有分类精度高、运算速度快和数据挖掘能力强的特点,然而See5.0算法应用于农作物分类的研究较少,在干旱区农作物的遥感分类研究更是鲜有报道。
为探讨不同机器学习算法应用于干旱区农作物遥感分类研究的适用性,文章利用Sentinel-2影像和野外采样数据,采用See5.0决策树算法、分类与回归树(Classification And Regression Tree,CART)算法和随机森林(Random Forest,RF)算法开展农作物遥感分类研究,充分挖掘农作物光谱信息、植被指数信息和物候信息,并通过破碎度检验和精度评价探讨三种机器学习算法对阜康市农作物遥感分类的适用性。研究结果将对整个天山北坡经济带,甚至整个干旱区农作物遥感识别具有重要的应用价值,以期为干旱地区农作物种植和农业可持续发展提供参考依据。
1 研究区概况
阜康市位于新疆东天山山脉北坡,准噶尔盆地南部,经纬度在87°46ʹ56ʺE~88°27ʹ49ʺE,43°45ʹ27ʺN~45°30ʹ09ʺN之间(图1)。西临乌鲁木齐市米东区,北接阿勒泰地区福海县,东边与吉木萨尔县相邻[25]。阜康市土地总面积为8444.71 km2,境内气候垂直地带性分布特征显著,具有新疆地区典型地理地貌特征(山地-绿洲-荒漠),属于典型的温带大陆性荒漠气候,四季分明、冬季严寒且夏季炎热[26]。
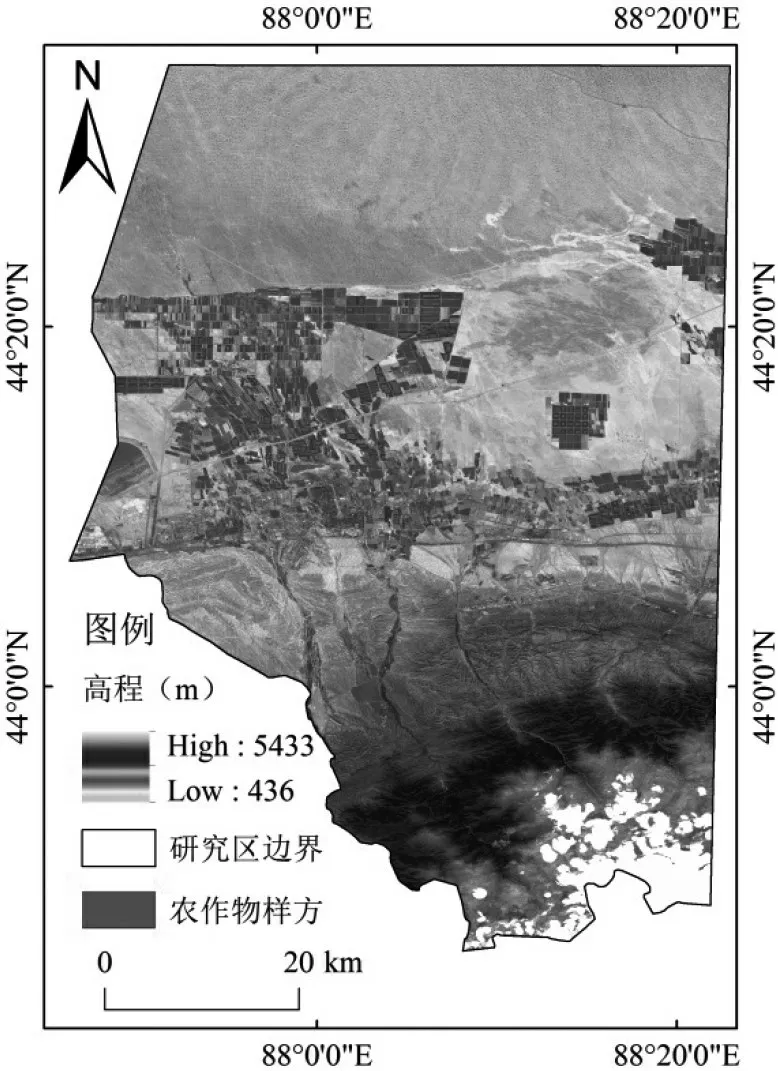
图1 研究区及样本分布示意图
2 数据来源与研究方法
2.1 遥感数据
研究所用遥感影像数据为Sentinel-2数据,下载于欧洲航天局数据中心,数据产品名称为Level-1C.Sentinel-2卫星搭载的有效载荷为多光谱成像仪,数据有13个光谱波段,其中除常见的可见光和近红外波段外,还包含3个红边波段[27]。数据由Sentinel-2A和Sentinel-2B卫星数据组成,具有空间分辨率高、重访周期短、光谱通道多及波段宽度窄的优势[28](表1)。研究选择2020年3月至11月期间的遥感影像数据,使用Sentinel应用平台(SNAP)中实现的Sen2cor算法进行大气校正和辐射定标等预处理,最终生成用于农作物遥感分类研究的Level-2A产品。
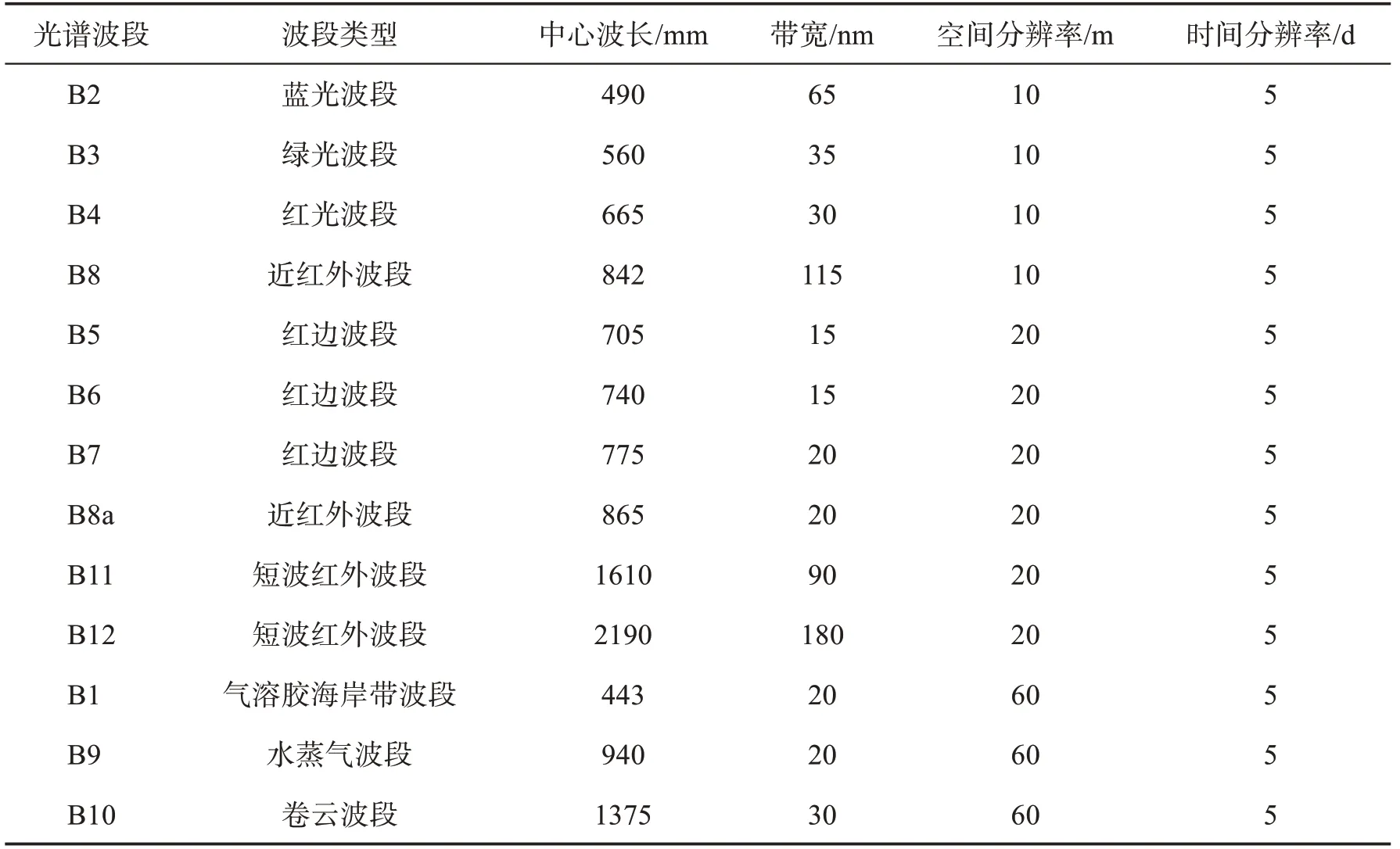
表1 Sentinel-2卫星波段参数
2.2 野外调查数据
数据获取时间为2020年6月9日至2020年7月10日。为得到更高精度和符合实际的分类结果,采样过程中使用GPS记录农作物的经纬度,并对农作物的种类、生长状况及灌溉方式进行记录,以此更加准确地掌握各农作物的特征。由于人力、物力和实际调查状况的局限性,在野外采样时未能遵循采样点均匀分布的原则,而是根据可获取性进行采样。采样得到359个典型农作物样方,其中包含44块玉米地、32块小麦地、38块葫芦地、25块冬瓜地、26块番茄地、40块棉花地、20块打瓜地、29块葵花地和30块番薯地等。在样方内随机生成间隔大于20 m的样本点,共21066个。研究随机选取70%的样本数据作为训练样本,其余30%作为验证样本用于评估分类结果的准确性(表2)。

表2 研究区农作物分类样本统计表

作物类型 训练样本 检验样本 样本总数 作物类型 训练样本 检验样本 样本总数黄蒿胡萝卜番茄打瓜267 683 643 194 114 293 276 83 381 976 919 277葫芦番薯冬瓜草莓2955 137 143 41 1267 58 61 17 4222 195 204 58
2.3 研究方法
2.3.1 分类特征构建
(1)光谱特征:选择Sentinel-2卫星波段(共13个)中的10个可用于土地覆被变化监测、植被监测、陆表监测和环境监测的波段,包括B2、B3、B4、B5、B6、B7、B8、B8a、B11和B12波段。
(2)时序植被指数特征:选择的植被指数是归一化植被指数(Normalized Difference Vegetation Index,NDVI),因为它是文献中使用最广泛的植被指数,可以反映作物的生长状况,在作物物候监测中较为准确[29],且根据Sentinel-2数据特有的三个红边波段构建红边归一化植被指数。计算公式如下:

式(1)~(4)中:B4和B8分别表示Sentinel-2卫星的红光波段和近红外波段;B5、B6和B7分别表示Sentinel-2卫星的红边705波段、红边740波段和红边775波段;NDVI705、NDVI740和NDVI775分别表示三种红边归一化植被指数,即用红边波段替换近红外波段后所得的结果。
2.3.2 植被指数时序曲线及可分性
将植被指数按时间顺序进行排列叠加,以时间(月)为横坐标,植被指数为纵坐标,构建农作物植被指数变化曲线,结果如图2所示。从图2可以看出作物植被指数的变化特征:同种作物在不同时期具有不同的植被指数,不同作物在同一时期植被指数也有所不同,折线间的差别代表每种作物的植被指数在不同时期的变化趋势。在4~5月,冬小麦的植被指数与其他作物的植被指数有明显差异,地表特征明显,辨识度极高;在7~8月,各个作物的植被指数间有明显的区别,辨识度较高;此外不同农作物植被指数上升期、下降期和峰值期亦不相同,容易识别。综上,由于不同农作物类型的物候特征存在差异,利用多时相Sentinel-2遥感影像提供的植被物候信息,结合不同农作物生长发育时期的季节性光谱差异,可用于农作物遥感识别[30]。
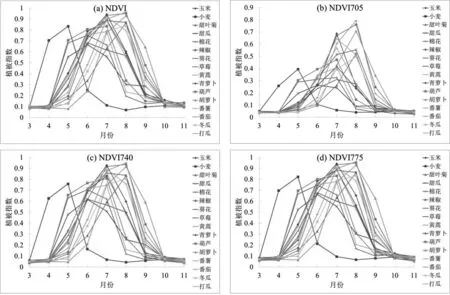
图2 农作物植被指数时序曲线
2.3.3 分类方法
为减少样本数量和样本分布对分类精度的影响,每种机器学习算法迭代运行50次,得到每个算法的平均分类精度以供进一步研究。
(1)See5.0决策树算法。See5.0是自动提取分类规则的数据挖掘工具,一种新的自上而下的决策树算法[31]。通常,构建决策树不需要花费很多时间,且易于分析生成的决策树。See5.0通过Boosting算法来提高分类准确性,重点关注那些在后来建立的决策树之前被错误分类和丢失的数据,确定不同农作物的分类特征,最终生成更准确的决策树,研究借助R语言中的C50包实现See5.0决策树算法。
(2)分类与回归树算法。分类和回归树(CART)具有原理简单、易懂、速度快等优点[32]。其原理是以基尼指数作为阈值分割度量标准,采用二分递归分割技术对样本集进行逐步划分和细化,使生成的每个非叶节点有两个分支,研究采用R语言中的caret包实现CART算法。
(3)随机森林算法。随机森林(RF)是Bagging算法和Random Subspace算法的结合[33],后者由大量的决策树组成且是强大的分类器,并且通过对成员决策树的结果求平均来获得分类结果。研究利用R语言中的Random Forest包实现RF算法,通过多次实验得知,当决策树数量ntree大于120时,分类精度趋于稳定,因此在模型运行时将ntree设为120.
2.3.4 精度评价方法
(1)传统精度评价方法。使用机器学习算法分类农作物后,利用误差矩阵和目视解译对分类结果进行精度评价。精度评价指标有:表示正确分类像元数占参与分类总像元数比例的总体精度(Overall Accuracy);表示分类结果与实际数据一致性的Kappa系数;表示分类结果与地面实际类型相同概率的用户精度(User's Accuracy);表示同一地点分类图的结果与实际地面类型相一致概率的制图精度(Producer's Accuracy)。计算公式如下:

式(5)~(8)中:n为类别数量;N为验证样本总数;Pii是每类中正确分类样本的数量,是i行i列上的值;Pi+为分类器将验证样本分为某一类别的总数;P+i为某一类别验证样本总数。
(2)破碎度检验。随着机器学习算法在遥感动态监测中的应用,使得数据处理更高效,同时也提升了分类精度,但农作物分类结果也会出现不同程度的破碎化现象。为了全面准确地评价不同机器学习算法的分类结果,本研究将破碎度这一指标应用于农作物分类精度评价。计算公式如下:

式(9)中,Cj表示分类后样方内农作物j的破碎度,Nj表示分类后样方内农作物j的斑块数,Aj表示分类后样方内农作物j的总面积。
3 结果与分析
3.1 精度验证
为准确评价不同机器学习算法在农作物遥感分类方面的精度,研究利用验证数据,对See5.0、RF和CART的分类结果进行精度验证,精度统计见表3.在总体精度方面,三种机器学习算法的关系为See5.0(93.15%)>RF(84.35%)>CART(78.26%),其中See5.0的总体精度最高,比RF和CART分别高出8.8%和14.89%,说明See5.0算法可以有效提高农作物遥感分类精度。在Kappa系数方面,See5.0的Kappa系数最高,为0.8856;其次是RF的Kappa系数,为0.8020;CART的Kappa系数最低,为0.7441.其中See5.0和RF的Kappa系数均大于0.8,表明这二者的分类结果与实际作物的分布状况具有较好的一致性[34]。

表3 分类精度统计

农作物类别 指标 分类算法See5.0 RF CART青萝卜甜瓜甜叶菊小麦玉米制图精度(PA)用户精度(UA)制图精度(PA)用户精度(UA)制图精度(PA)用户精度(UA)制图精度(PA)用户精度(UA)制图精度(PA)用户精度(UA)总体精度(OA)Kappa系数93.75%94.13%85.71%87.96%93.30%93.68%99.86%99.42%97.91%97.63%93.15%0.8856 92.50%92.53%75.51%74.11%83.01%83.04%95.35%95.11%91.42%91.67%84.35%0.8020 86.25%86.32%79.59%80.08%75.60%75.66%90.14%90.14%86.08%85.75%78.26%0.7441
在See5.0的混淆矩阵(表4)中,小麦的制图精度(99.86%)和用户精度(99.42%)均是农作物中最高的,其次是葵花,其制图精度和用户精度分别是98.36%和98.98%,而玉米(97.91%和97.63%)、番茄(96.15%和96.69%)、葫芦(96.59%和96.12%)、棉花(96.76%和96.40%)和打瓜(91.94%和92.93%)均有较高的制图精度和较高的用户精度。由图2可知,玉米和番茄存在“异物同谱”现象,很难直接区分两者。See5.0对玉米和番茄的制图精度和用户精度分别达到97.91%、97.63%和96.15%、96.69%,比RF的制图精度和用户精度分别高出6.49%、5.96%和4.8%、5.34%,比CART的制图精度和用户精度分别高出11.83%、11.88%和12.5%、12.92%,这说明See5.0能够有效提高识别“异物同谱”农作物的能力,如识别玉米和番茄的能力。See5.0对阜康市农作物的制图精度均超过85%,制图结果清晰,地块内均匀一致,没有明显的“椒盐”噪声,说明See5.0算法可以完成高精度遥感作物制图,具有实际的应用价值。
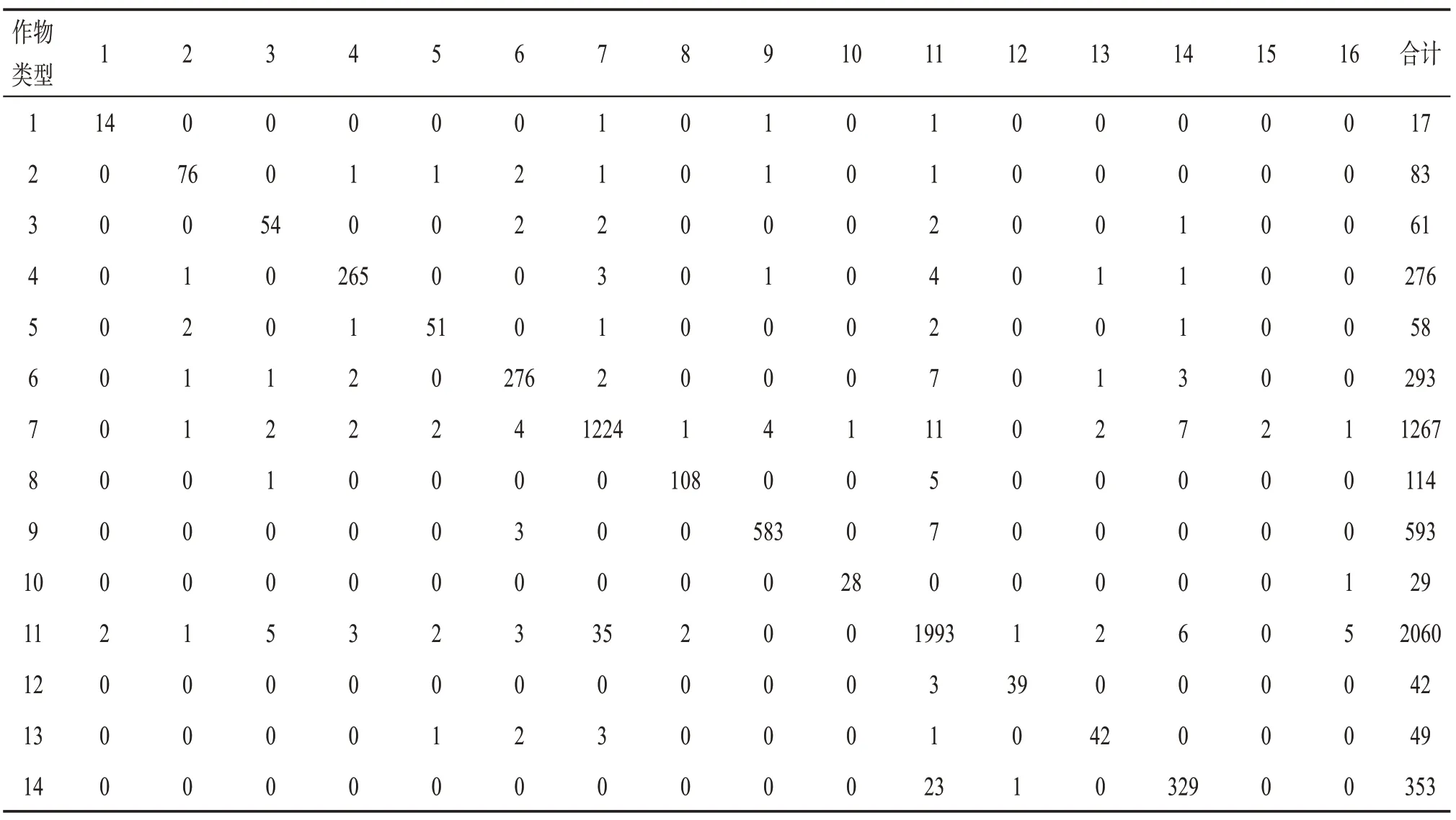
表4 See5.0算法混淆矩阵
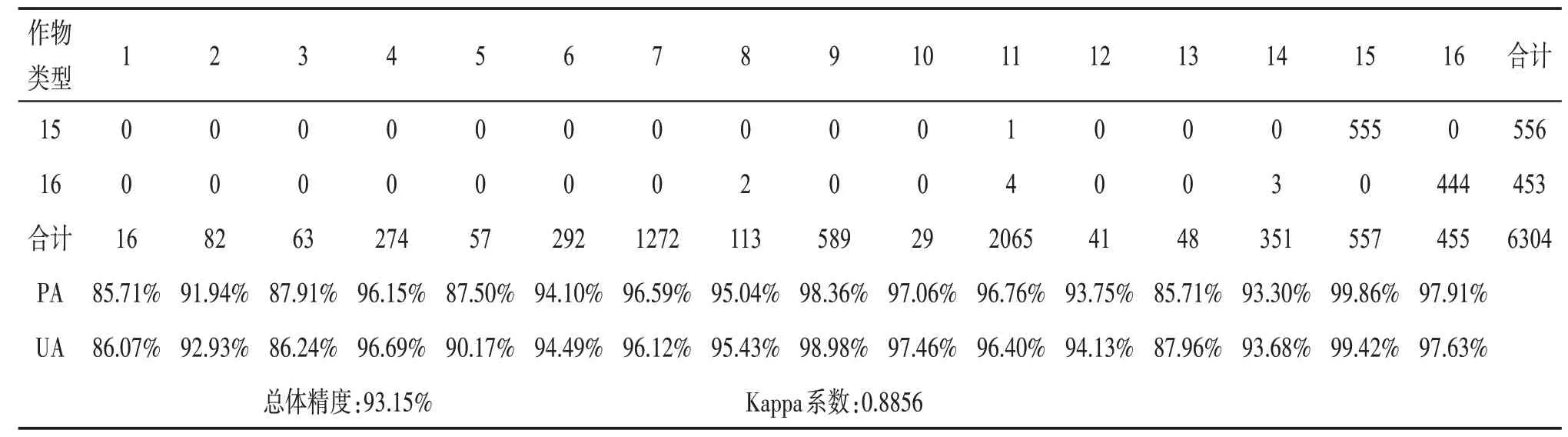
注:1~16分别表示草莓、打瓜、冬瓜、番茄、番薯、胡萝卜、葫芦、黄蒿、葵花、辣椒、棉花、青萝卜、甜瓜、甜叶菊、小麦和玉米。
3.2 破碎度评价
为了更全面、直观、准确地评价不同机器学习算法的分类效果,从分类后农作物样方破碎程度这一角度出发对农作物分类结果进行评价。利用实地采样的359个样方,计算分类后样方内每种作物的斑块数与样方内每种作物总面积的比值如下(表5)。

表5 农作物破碎度验证
从表5可以看出,See5.0、RF和CART的平均破碎度分别为5.54%、10.25%和17.40%,三者关系为See5.0 基于三种不同机器学习算法可以实现阜康市农作物遥感分类,从分类结果(图3)中发现,研究区内农作物以小麦、棉花、玉米和葫芦为主,主要集中分布在土壤肥沃且灌溉设施较为完善的洪积扇区和冲积平原区,种植面积较大且在研究区内连续分布;其他农作物如番薯、黄蒿、冬瓜、番茄和草莓等,呈镶嵌式分布,面积较小且地块不连续;在一些居民用地和建设用地周围存在着小块农田,主要种植番茄和葵花等农作物。 图3 分类结果 文章利用具有红边波段的Sentinel-2影像和野外调查数据,根据农作物物候特征建立植被指数时序变化曲线,使用三种不同机器学习算法(See5.0、RF和CART)开展阜康市绿洲区农作物遥感分类研究,从破碎度指标和传统精度评价指标出发对作物分类结果进行探讨,为干旱区农作物遥感分类和精度评价研究提供了参考依据。研究表明,See5.0决策树算法明显提高了农作物遥感分类的精度,可为及时准确地获取干旱区农作物种植类型和空间分布信息提供有效帮助,并为保障国家粮食安全和维护农业可持续发展提供支撑。虽然本研究采用See5.0机器学习算法在干旱区农作物遥感分类中取得了不错的分类效果,但该机器学习算法仍存在一定的缺陷,且研究仅使用Sentinel-2数据和野外调查数据进行农作物遥感分类,数据源较为单一。当前,多源遥感数据的融合和综合利用是遥感分类研究的重要内容之一[18,35-36]。在将来的研究中,可将不同数据源的多光谱时间序列构建为特征参数,使See5.0机器学习算法在干旱区农作物遥感分类领域得到进一步应用。 在评价指标方面(表6),本研究提出的破碎度评价指标很少应用于农作物分类精度评价,其精度评价结果与传统精度评价指标的评价结果一致,均表明See5.0机器学习算法可以有效地提高农作物遥感分类精度,相较于RF算法和CART算法,See5.0算法更适合在绿洲区进行农作物遥感分类与动态监测研究,也说明破碎度这一指标应用于农作物分类精度评价的可行性较高。在未来研究中可将破碎度评价指标应用于其他研究区农作物分类精度评价,使其进一步服务于农作物遥感动态监测。 表6 评价指标 此外,在农作物遥感分类研究中,野外调查采样是不可或缺的研究环节[37]。本次在对农作物进行野外调查时,所调查的农作物样方未能均匀分布在研究区内,这可能会对分类精度产生一定的影响。在未来的研究工作中,在实际条件允许的情况下,适当增加农作物样方数量和农作物样方分布范围,将会在一定程度上增加农作物样本的多样性、可靠性和连续性,进一步提高农作物遥感分类的精确性和有效性。 (1)See5.0的分类总体精度最高,为93.15%;高于RF(84.35%)和CART(78.26%)。Kappa系数方面,See5.0的Kappa系数最高,为0.8856,比RF和CART分别高出0.0836和0.1415,表明See5.0算法的分类结果与实际农作物类型及分布状况具有较好的一致性,说明See5.0机器学习算法对于利用遥感技术提取阜康市农作物种植信息具有一定的适应性和可行性。 (2)使用See5.0算法对阜康市农作物的制图精度均超过85%,制图结果清晰,地块内均匀一致,没有明显的“椒盐”噪声,说明See5.0算法可以完成高精度遥感作物制图,具有实际的应用价值。 (3)See5.0算法分类的农作物样方破碎度仅为5.54%,低于CART算法(17.40%)和RF算法(10.25%),See5.0算法的分类效果最好,这一指标进一步证实See5.0机器学习算法更适合在绿洲区进行农作物遥感分类与动态监测研究。3.3 分类结果展示
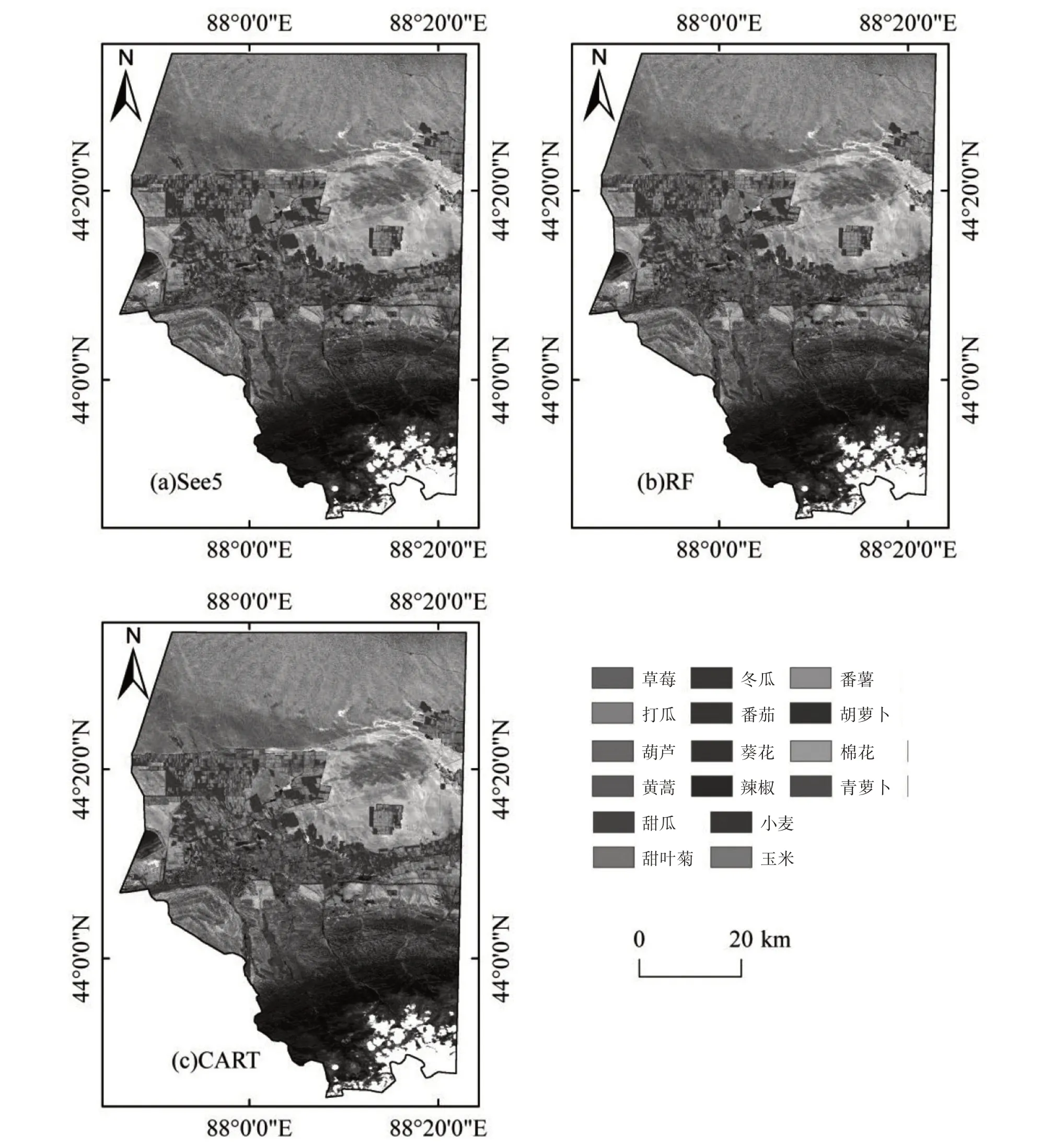
4 结语
4.1 讨论

4.2 结论
