仿生假体视觉人脸图像语义翻译研究与实现
2022-12-23陈继刚冯璐
陈继刚 冯璐
1. 西安交通大学第二附属医院信息网络部 陕西 西安 710076;2. 联咏电子科技(西安)有限公司 陕西 西安 710076
引言
基于视网膜假体植入的仿生假体视觉技术(SPV)是视力障碍患者视力改善的一种解决方案,其信息表达方式直接、全面,具有良好的研究前景。SPV重建了一条新的信息传递通路,利用外部摄像头替代眼睛去捕获视觉信息,通过移植在视网膜上的假体电极阵列,将视觉信息以电刺激的形式传递给视网膜,大脑视觉皮层即可产生相应的光感影像信息(称为光幻视)。
当前电极阵列制造技术有限,仅可产生低分辨率(有限像素)的光幻视,缺失大量的关键语义信息,无法满足患者大脑视觉皮层进行深层次的感知、理解的需求。为解决该问题,需要对摄像头获取的“物理真实”信息进行算法的特征提取与模式识别,抽象出其中的关键语义,翻译为“感官真实”信息传递给假体电极阵列以产生光幻视,用少量的像素即可实现有效表达,缓解了假体功能缺陷引发的语义缺失问题的影响。
本文旨在从算法层面弥补SPV硬件性能的不足,在低分辨率工况下高效表示人脸语义的关键信息,使视力障碍患者能够通过光幻视有效了解沟通对象的面部信息,知晓其面部外形、理解其表情,提升患者的社交能力和幸福指数,使其更好地融入社会生活中。
1 相关工作
本研究的主要难点在于提升低像素光幻视的表达能力,即解决图像翻译中因分辨率缩减带来的语义信息缺失的问题。人脸图像语义信息的缺失主要包括两点:
空间语义信息缺失:空间语义关系到人脸面部轮廓信息,缺失将导致输出结果无法确定人物身份。
频谱语义信息缺失:频谱语义关系到人物的面部表情等关键信息,缺失将导致无法应用传统的循环一致性[1]和感知损失[2]训练策略。
1.1 构建漫画人脸数据集
研究表明[3],漫画风格的人脸图像在表征面部语义方面具有高效性,其特征表达能力更强,可以更好地传递人脸图像的内在信息。鉴于视网膜假体电极阵列提供的电刺激等级有限,产生的光幻视的像素等级及灰度等级极低[4],本任务中考虑极端情况,完全使用分辨率为25×23的二值化(即像素化)的漫画风格人脸图像(简称为像素人脸图像)来表达人脸图像的空间、频谱语义。
针对SPV人脸语义翻译任务,当前仍缺乏相关的用于部署的低像素数据集。为便于后续工作的开展,本次研究构建了漫画风格的像素人脸数据集Pixel Face Dataset(PFD)。
PFD由1278张像素人脸图像组成,所有样本均为二值化图像,并且尺寸符合视网膜假体的显示需求,可方便部署于视网膜假体之上。
1.2 弱监督间接循环重构训练策略

1.2.1 空间语义信息的引入。通过语义分割模块MU(MaskingUnit),将分割得到其对应的:

MU模块可任意选用成熟的人脸掩模分割方法予以实现。
1.2.2 空间及频谱语义的循环重构保持。空间及频谱语义的维持是通过引入信息,完成与间循环重构生成过程,指导的生成实现的。为实现该循环重构生成策略,需构建一个特殊的GAN结构模块,该结构中包含传统意义上GAN所需的生成器及判别器D,同时也包含实现与间的循环重构生成策略的两个生成器与:



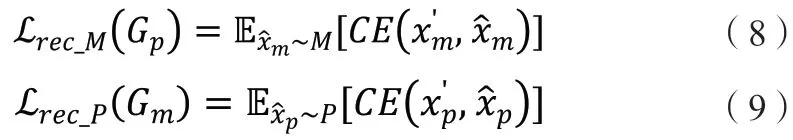
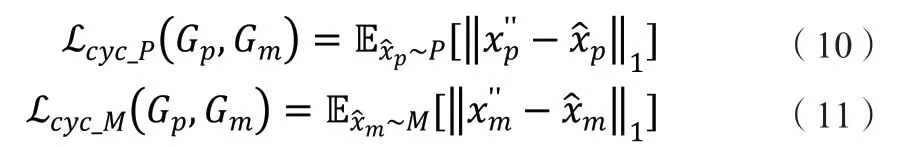
1.2.5 标签分类损失。频谱语义主要由面部表情这类抽象信息构成,因此可添加标签分类任务用以约束生成的像素人脸图像具有与原真实人脸图像相同的表情,确保两者的频谱语义的一致性。此标签分类任务可交由判别器完成,为其添加标签分类头予以实现。在判别器D的训练阶段有:
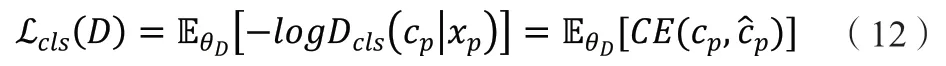
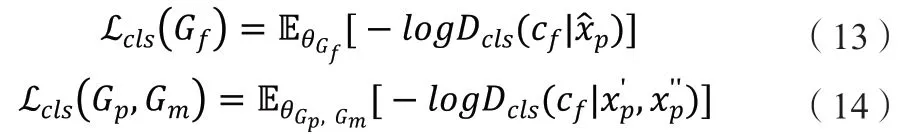
1.2.6D的对抗损失。D的对抗损失项具体表达公式如下:

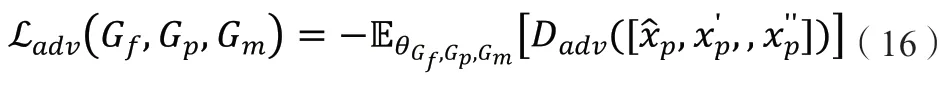
2 实验与分析
2.1 定性对比分析
本次研究将本文的F2Pnet模型与多个图像语义翻译的经典SOTA(state-of-the-art)模型进行了性能比对,具体涉及CycleGAN、U-GAT-IT、photo2cartoon、GNR,见图1。

图1 各模型生成的像素人脸图像及其光幻视
分析结果可知,CycleGAN人脸图像翻译结果中存在大量生成缺陷,而且缺陷位置多集中于关键的面部区域,对人脸关键信息影响较大,而且CycleGAN的翻译结果的语义特征与原始人脸图像存在较大差异,进一步验证了上文仅使用循环一致性损失无法保证翻译前后的图像间语义对应关系这一结论。
值得注意的是,U-GAT-IT在本实验中表现较好,其图像翻译结果轮廓清晰、缺陷较少。但对人物发型与面部表情信息未能做到正确保留,且翻译结果中仍保留了部分背景信息,会对前景信息内容存在干扰。
Photo2cartoon在本实验中表现较差,只能简单勾勒出人物的面部外轮廓线条,缺失了大量的面部器官信息,导致人脸关键语义的大幅丢失,且翻译结果中保留了大量的背景信息,严重影响对人脸语义的表达。
GNR有较强的频谱语义表征能力,但仍存在生成缺陷,且丢失部分面部信息;仔细观察可发现其结果与原始图像在空间位置上存在一定偏差,即存在空间语义表征能力缺陷。
F2Pnet模型的图像翻译结果轮廓清晰、锐利,基本无肉眼可见缺陷,且与原始人脸图像的语义信息(例如面部外形、发型、表情等)存在强对应关系,是图像翻译效果最好的一个。
2.2 定量度量
F2Pnet与人类基准对比实验结果见表1。可以得出以下结论:

表1 F2Pnet与人类基准对比
F2Pnet的图像翻译结果在语义相似度、表情辨识度及身份辨识度方面略逊于人类基准,但在单一表情,特别是“愤怒”、“恐惧”、“高兴”、“惊讶”中的表征能力已优于人类基准,在“高兴”表情辨识度(即正确率)上已高达0.96,证明F2Pnet可以为视障患者提供较为可靠的人脸语义信息。
F2Pnet的图像翻译结果在转换成光幻视点阵图像(考虑30%电极失效)后表征能力的下降幅度低于人类画师绘制的图像,并且除了在“中性”、“悲伤”表情中,F2Pnet的光幻视点阵图像评分略低于人类基准外,其余表情的得分均高于人类基准。这一结果进一步论证了F2Pnet的语义表征能力,并且说明了使用PFD数据集进行转换这一思路的正确性。
F2Pnet与其他图像语义翻译方法对比实验结果见表2,多数志愿者认为F2Pnet翻译结果更符合原始人脸图像,F2Pnet得票率高于次优方法(GNR)31.29%。实验结果表明F2Pnet具有更强的空间语义及频谱语义保持能力,更符合人类感知,比现有图像语义翻译方法具有更强的语义表征性能。

表2 不同模型图像翻译质量的用户调研统计结果
3 模型部署与实现
本次研究选用树莓派作为模型部署的硬件设备,型号为当前最新的Raspberry Pi 4B,由于嵌入式设备的运算性能有限,为保证模型具有足够的推理速度,需对其进行下述的网络结构简化操作:将中间层的所有常规卷积操作替换为深度可分离卷积,并将其通道数大于64的层均缩减至64。去除所有实例归一化的参数,仅使用均值与方差对各特征图进行归一化操作。
通过实测发现,人脸检测算法的运行效率为37pfs(单帧耗时27ms),F2Pnet在嵌入式设备上的转换速率为17.7fps(单帧耗时56.5ms),单帧总耗时为83.5ms。翻译后的效果见图2。

图2 F2Pnet模型简化前、后的翻译效果
模型简化后,提升推理效率的同时,不可避免地会降低图像的语义翻译质量,部署模型最终在CelebA测试集中的FID与KID指标见表3。由表可知,语义翻译质量的确存在小幅下降,但光幻视点阵图像仍可正确表示人脸信息;同时,考虑30%点阵失效下的光幻视也依然能够为患者提供较为可靠的语义特征。

表3 F2Pnet简化前、后翻译结果的FID、KID值
4 结束语
为有效解决有限像素下表征人脸信息时的语义丢失问题,本文给出了将“物理真实”转换为“感官真实”的研究思路,使用具有强抽象表征能力的、漫画形式的像素人脸图像去表示人脸语义。(缩进)为了规范生成低像素、富语义信息、可直接在视网膜假体上部署的漫画形式图像,本文构建了像素人脸数据集PFD。为解决人脸图像翻译过程中的语义信息丢失问题,本文给出了间接循环重构的对抗训练策略。基于上述策略,本文构建了F2Pnet网络。
经实验论证,F2Pnet的人脸语义翻译结果在语义相似度、表情辨识度、身份辨识度方面已接近人类基准,其在面部特征、表情等方面的表达能力优于现有其他人脸图像翻译方法。
