基于TensorFlow的果蔬识别系统的实现
2022-12-23陈恩展
陈恩展
广西师范大学数学与统计学院 广西 桂林 541000
引言
互联网的不断发展和社交平台的广泛普及,人们的生活中充斥着大量的网络数据,诸如文字、图像、视频等。如此海量的网络数据,不可能通过人力去一一识别这些数据中的内容。通过机器学习中的算法框架,可以利用已有的网络数据来训练机器,让机器帮助我们快速识别数据中的内容。也正是机器学习的广泛运用,让生活中的很多实际场景变为无人化成为可能。本文就是基于TensorFlow这一学习框架,通过卷积神经网络捕捉数据中比较抽象的特征,以此来得到一个具备图像识别能力的模型,完成对生活中果蔬种类的识别。在后疫情时代,太多的生活场景需要这样具备识别功能的机器,且无人化的场所也会随着人们对生活品质的不断追求而越来越广泛。
1 TensorFlow介绍
1.1 基本原理
TensorFlow[1]是目前使用最为广泛的机器学习框架,由谷歌开发的一个开源的、基于Python的学习框架。在实际生活场景中有着十分丰富的应用。例如图像识别分类、语音视频数据的处理,以及各式各样的推荐系统。且TensorFlow具有很好的兼容性,它能够将自己的神经网络计算兼容到市面上大多数主流的CPU或GPU的服务器上,甚至是一些其他主流的PC或移动设备,而这些只需要利用一个TensorFlow API即可完成。
1.2 RStudio中的TensorFlow
RStudio是R语言的集成开发环境(IDE),它是一个独立的开源项目,它将许多功能强大的编程工具集成到一个直观、易于学习的界面中。在RStudio中,很多较为复杂的功能的实现,都被大量的使用者们封装在一个简单轻巧的R包中,且这个R包一直都在不断地被后来的使用者们改进着。正是这样大范围的开源使用,让RStudio变得越来越强大,使得本次系统的实现在RStudio上成为可能。
TensorFlow团队十分贴心,在RStudio中开发了专属TensorFlow的R接口,在电脑中已经有了TensorFlow和RStudio的基础上,我们只需在RStudio输入“install.packages(“tensorflow”)”这一命令,便可将“tensorflow”这一R包载入RStudio中,这样就可以在RStudio中运用TensorFlow学习框架进行模型训练。
2 设计卷积神经网络模型[2]
本次实验选用卷积神经网络LeNet-5[3],激活函数选用ReLU函数,并使用softmax 函数做分类器。
2.1 LeNet-5卷积神经网络模型
LeNet-5卷积神经网络模型是Yann Lecun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。LeNet-5卷积神经网络模型共有7层(不包括输入层),每层都包含不同数量的训练参数。
2.2 激活函数-ReLU函数[4]
激活函数就是在原来的线性组合的基础上加上非线性函数,让模型的表达能力更强。因为线性模型的表达能力非常有限,分类时也只能画一条线来划分。
在此次的模型设计中,选用ReLU函数为激活函数。ReLU函数的作用就是增加了神经网络各层之间的非线性关系,由ReLU函数的表达式:及其函数图像,我们可以知道ReLU函数是一个分段的线性函数。通过画出函数图像可以知道,ReLU函数在遇到负值输入时,其输出会都为0。遇到正值输入时,其输出与输入相等。我们把ReLU函数的这种特性称为单侧抑制。ReLU函数的单侧抑制特性,会使得神经网络中的神经元具有了稀疏激活性[5]。通过ReLU函数实现稀疏后的模型能够更好地挖掘数据相关特征,拟合训练数据。
2.3 Softmax分类器[6]
本次系统的设计目的就是识别出图片中果蔬的种类。假如现在有一个任意的输入值x,这个输入值x有可能属于N个种类中任意一个。那么我们的模型,在得到这个输入值时就会进行识别,并对已有的N个类别进行评分,评分最高的那个类别就是输入值x最有可能所属的类别。然而,这样的评分范围很广,此时我们就用到了softmax分类器。它是一个可以将(-∞,+∞)的一组评分转化为一组概率,并让它们的和为1的归一化的函数,而且这个函数是保序的。原来评分高的对应转换后的概率大,评分低的对应转换后的概率小。
softmax函数的表达式为:
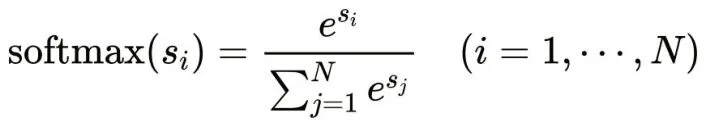
3 系统设计流程与分析
在设计好本次系统所需要的卷积神经网络模型后,接下来就是为这一设计好的模型找寻训练数据。合适且规范的训练数据就像必需的营养品,可以使得神经网络模型拥有更好的学习识别能力。
3.1 数据采集
拥有高质量的数据集是获得良好分类器的必要条件。大多数带有图像的现有数据集同时包含对象和噪声背景,这可能会导致改变背景会导致对象的错误分类。在Kaggle网站上,有一个名为“Fruits-360”的果蔬数据集,共131多类果蔬,约9万多张图片。
该数据集中的每一张图像的背景都进行白化处理,避免了图像的背景对后期的模型训练产生一定的干扰性。
3.2 数据预处理
对于图像识别这类型的模型训练,对于训练所需的图像数据进行预处理是很有必要的。在现实生活中,有些系统对于用户上传的图像有时就会有一些格式上的要求,这其实就是对图像数据的一个简单的预处理。因此在搭建卷积神经网络前需要对输入图像进行预处理。一般图像预处理包括以下3个步骤:①图像灰度化[7];②图像的几何变换即平移、旋转、镜像、裁剪等;③图像增强,增强图像中的有用信息。
在模型的训练初期,可能是由于数据集的迭代训练次数较少,也可能是由于数据集带有一定的干扰信息,模型的识别准确率较低。通过检查发现,数据集中一部分的图像的背景具有较多干扰信息,即所识别的对象在图像中的位置不够凸显。那么针对这类图像,在预处理时就要进行一些必要的处理。这也说明了,在图像识别领域中的数据预处理阶段,应根据实际的识别场景出发,来决定我们要如何对数据进行预处理。
3.3 数据集网络训练
经过以上数据集的采集以及数据集的预处理,在卷积神经网络模型设计完成后,即可对搭建好的卷积神经网络进行训练,在RStudio中加载TensorFlow相关的R包,并设置好数据集在本地的路径,方便模型训练时可以读取到对应的图像数据集,最后将训练好的模型存储下来。根据所使用的电脑硬件,这个过程可能需要几分钟到一个小时。在RStudio中,我们将数据集网络训练的迭代次数(epochs)设置为6次。如果识别准确率会在 6 次迭代之后增加,便将 “epochs ”设置为一个更高的值。如果模型已经过度拟合,即识别准确率下降而训练准确率进一步增加,我们可以减少 “epochs” 的数量。在本次模拟当中,在6次迭代之后,数据集的识别率达到了大约97%的准确率,如图1所示。
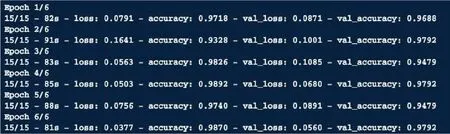
图1 准确率图
3.4 模型测试
在完成数据集网络训练之后,即可利用训练好的网络模型进行测试。从测试数据集中随机抽取果蔬图片进行识别测试,查看模型的识别准确率。测试结果显示,模型识别的准确率达到99%。
3.5 系统测试结果分析
在对模型经过6次的数据训练迭代之后,其准确率已经达到了97% 的水准。通过随机上传本地数据集中的图像,系统均能准确地识别出图像内容。当然,若上传的图像背景干扰信息较多,我们的模型有可能就无法进行准确的识别。对于这个问题的解决,从模型自身出发解决的话,可以优化模型中的相关参数或者加入一些带有干扰信息的数据集对模型进行训练,同时增加训练的迭代次数。也可以在上传带有干扰信息数据集的时候,对这类数据集进行处理,利用一定的技术将干扰信息去除掉。
4 结束语
进入后疫情时代,我们生活还要继续,也就意味着越来越多的无人化场景将成为刚需。机器学习及智能化时代的发展迭代,让无人化的场景能够很好地服务于大众。本文所设计的果蔬识别系统正是从生活日常需要的角度出发,运用卷积网络中的LeNet-5卷积神经网络模型对大量网络数据集进行多次的迭代训练,来达到一个较高的识别准确率。但仍存在一些问题,在面对带有干扰信息的数据集时,模型可能无法给出准确的判断,这个问题还需要进一步解决。
