一种改进的融合文本主题特征的情感分析模型
2022-12-22张帅黄勃巨家骥
张帅,黄勃,巨家骥
上海工程技术大学,电子电气工程学院,上海 201620
引 言
随着互联网的飞速发展,大量包含用户意见的短文本数据出现在社交媒体的评论中。通过对这些评价数据进行情感分类,可以有效提取用户的真实想法,有助于对应产品或服务的提升改良,情感分析的大部分工作也都主要集中在产品或服务的评价上。由此可见,针对海量的评论短文本,提取产品或服务公正的用户看法以及对数据进行有效的情感分析,是当前自然语言处理领域研究的重点内容。
随着数据量的不断增加,人工提取有效信息非常耗时且效率低下,为了克服这个问题,自然语言处理中使用了很多模型和方法。主题建模是其中典型的方法,LDA[1](Latent Dirichlet Allocation)主题模型作为一种成熟的技术被广泛应用于文本特征提取。例如,薛等人[2]使用机器学习与LDA模型分析了大约190万条关于新冠病毒的英文评论,旨在了解推特用户对COVID-19的言论和心理反应。Tago等人[3]基于LDA主题模型对工业产品文本进行挖掘,然后利用情感词典对提取的主题词进行情感标注,取得很好的分类效果。
然而LDA在主题语义和情感极性分析上还存在欠缺。随着深度学习的发展进步,LSTM (Long Short Term Memory network)常应用于情感分析领域,以获取文本的上下文依赖关系,结合Word2Vec词嵌入技术来进行实验可取得不错的情感分类效果。如吴彦文等人[4]将LDA模型融合词嵌入法结合LSTM来扩展评论信息的特征表示。Shams M等人[5]通过LDA模型与词共现分析相结合提取方面情感分析。孟仕林等人[6]在词嵌入基础上增加情感向量,并采用Bi-LSTM(Bidirectional Long Short-Term Memory)获取文本的特征信息进行情感分类。Tang等人[7]提出TC-LSTM模型,把主题词向量与句子中的每个词向量进行拼接,用LSTM提取特定对象的前后语境信息获得语义特征用于情感分类。
在神经网络中引入注意力机制[8-9],可使模型关注特定对象的相关信息,有助于提升模型的性能表现。如谢军等人[10]提出了一种具有方面信息的基于自我注意的 Bi-LSTM 模型,用于短文本的细粒度情感极性分类。Wang等人[11]基于隐藏层输出进行注意力学习,提出结合注意力机制的ATAE-LSTM模型,深化了主题对象在文本特征提取和注意力权重计算中的作用。胡朝举等人[12]利用Bi-LSTM将主题特征和文本特征融合,并构建一个基于注意力的深度记忆网络捕获依赖,解决相应主题的情感分类问题。吴小华等人[13]提出character-SATT-BiLSTM模型,对评论文本进行字向量化表示,结合Bi-LSTM与自注意力机制对短文本进行情感分类。陶志勇等人[14]将注意力机制引入 Bi-LSTM 用于短文本分类,通过注意力层对更深层的语义特征进行向量表示,以提取到短文本的关键特征。李磊等人[15]将对象信息与文本信息进行融合,利用注意力机制强化的Bi-LSTM模型得到情感分类结果。
由此可知,扩展文本特征空间与深度学习方法相结合是处理评论短文本分类的有效方法。本文提出了一种基于主题的Bi-LSTM自注意力机制的评论情感分析模型(TSA-BiLSTM)。该方法是对神经网络的一种扩展,利用LDA生成的主题词扩展特征空间,与原评论通过Word2Vec模型对文本输入矩阵进行构建拼接,然后采用Bi-LSTM神经网络模型提取语义特征作为输入,结合自注意力机制可对不同主题进行情感分析,解决了文本稀疏、主题不明确、特征提取困难造成的文本分类准确率不高等问题。
1 相关工作
1.1 Word2Vec
Word2Vec是Google于2013年提出的一种神经网络概率语言模型[16]。与传统方法相比,利用Word2Vec模型创建和训练语义空间向量,能够有效解决语义缺失和高维特征空间稀疏等问题。在Word2Vec中主要基于CBOW与Skip-Gram两种学习算法。CBOW 模型通过中心词的上下文的词向量作为输入,来预测这个中心词本身;Skip-Gram则相反,其根据当前中心词来预测周围的单词。其训练目标就是使式(1)的目标值最大。
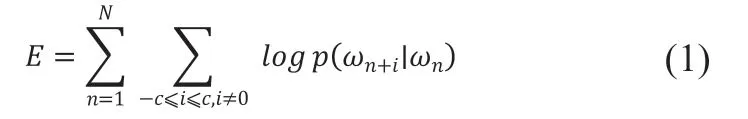
1.2 主题特征(LDA)
主题特征能反映文本的深层语义信息,在文本挖掘和自然语言处理相关工作中具有重要作用。潜在狄利克雷分配 (LDA)主题模型是最受欢迎的主题特征提取方法之一。LDA通过单词概率表示主题,通常可以根据每个主题中概率最高的单词很好地了解主题是什么,同时通过构建文档-主题-词语三层贝叶斯概率模型,用以发现语料库中隐藏的主题信息。如图1所示,其中M为语料库中的文档数量,N表示每篇文档里的单词数量,K为主题数,为的Dirichlet先验参数,是的Dirichlet先验参数。LDA模型可描述如下:
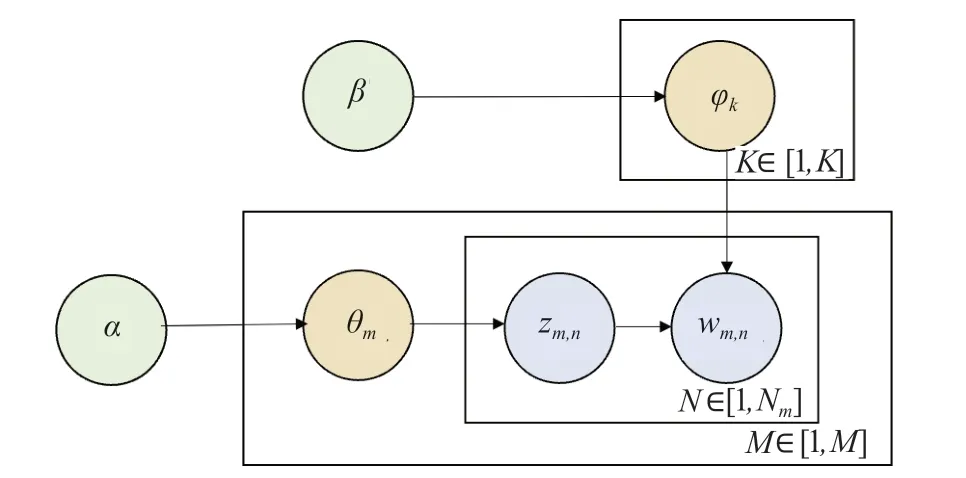
图1 LDA主题模型Fig.1 LDA topic model
(3)对于文档 M中的第 n 个词:
本文通过吉布斯采样算法[17]进行参数估计,主题采样完成后可以学到模型的最终结果。计算公式如式(2)-式(3)所示:

1.3 LSTM情感分析模型
LSTM是循环神经网络(Recurrent Neural Network, RNN)的一个扩展,它善于解决标准RNN中的梯度消失或爆炸问题[18]。LSTM神经网络包含三个门和一个存储单元,其中存储单元负责跟踪输入序列中元素之间的依赖性,输入门控制上一时序流入单元格的过程,遗忘门控制上一时序信息的保留程度,输出门控制当前时序LSTM单元的输出值,LSTM结构如图2所示。研究表明,与RNN相比,LSTM可以很好地表达输入中的长期依赖的信息,更新过程如式(4)-式(9):

图2 LSTM模型Fig.2 LSTM model

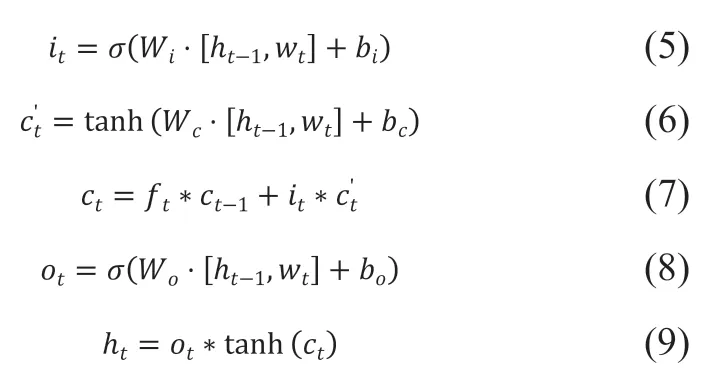
1.4 Self-Attention机制
注意力机制[8]是一种类似于人脑的注意力资源分配机制。通过概率权重分布,计算词向量在不同时刻的概率权重,使一些词能够得到更多的关注,从而提高隐藏层特征提取的质量。传统的注意力机制只能基于某个方面来表达句子的语义,导致部分语义信息丢失。由此,自注意力机制在文献[9]中被首次提出,当K=V=Q时,就是Self-Attention机制。自注意力机制是注意力机制的改进。经过在序列本身中做Attention,它减少了外部信息依赖,更擅长捕捉内部特征的相关性。本文使用了自我注意机制[19]来提取这些更重要的词,赋予它们更高的权重,以提高它们的重要性。其公式为(10)所示:

2 模型描述
2.1 TSA-BILSTM框架
本文基于上述理论基础提出了一种融合主题特征的评论文本情感分析模型(TSA-BiLSTM),特征提取部分融合LDA主题模型扩展评论文本的表示方法,同时引入Bi-LSTM结合自注意力机制对评论短文本进行情感分析,结构如图3所示,模型按照以下五个方面进行构建:
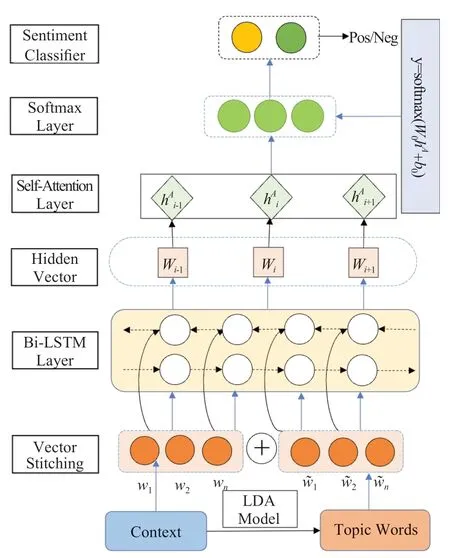
图3 TSA-BiLSTM模型结构图Fig.3 The structure of TSA-BiLSTM model
(2)将上一步提取的主题词和原评论都引入Word2Vec模型中训练获得Topic Vector和Context Vector,然后拼接两者词向量矩阵,作为输入端信息。
(3)将数据集送入Bi-LSTM网络模型中,根据公式计算学习隐藏向量,获得句子的上下文情感语义信息。
(4)把获取到的语义信息向量输入Self-Attention层,计算隐藏层向量和情感极性向量的加权平均值,从而学习句子内部的词依赖关系,捕获句子关键特征。
(5)采用步骤4中得到的情感极性向量,作为情感极性分类的情感特征,然后经softmax层输出模型预测值。
2.2 主题词提取
针对评论短文本信息量较少、主题不明确等问题[20],采用LDA模型对评论文本特征进行扩展,通过概率方法来丰富模型数据的语料库。对文本进行BOW编码,输入到LDA模型中,获得每条评论的主题分布,z为主题编号概率,主题词分布为,w为字典中主题词的分布概率。利用LDA模型生成的分布矩阵,主要特征词由公式(11)所示,选取超过阀值的词作为评论短文本的主要特征词。
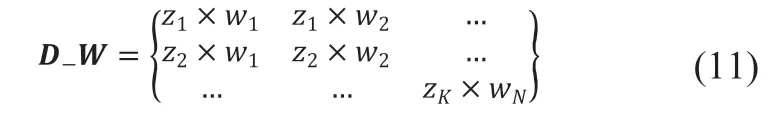
2.3 文本向量拼接
对于每个主题,本文计算关键词向量的平均值,并将此平均值向量作为该主题的向量表示。对于每个输入的单词,得到它对应文档所属的主题。因此,可以将每个输入词向量与其对应的主题向量连接起来,向量拼接的过程可以概括如下:
(1)虽然CBOW模型的速度更快,但是根据比较结果,在小数据集上,skip-gram的表现更好。因此,本文选择使用后者。通过对大量数据进行预训练得到X*Y大小的矩阵,X是输入文档的词汇数量,Y是每个单词训练后向量的维数。
(2)利用LDA获得文档主题分布矩阵,找到文档的主题词,并将其转化为词向量。计算这些词向量的平均值作为主题向量,并将Y维向量扩展到X*Y主题矩阵。将输入矩阵和主题矩阵拼接,得到一个X*(2Y)矩阵。
如图4所示,向量拼接是本文方法的一个重要部分。它代表了对短文本特征空间的扩展,解决了数据稀疏、主题不明确等问题。
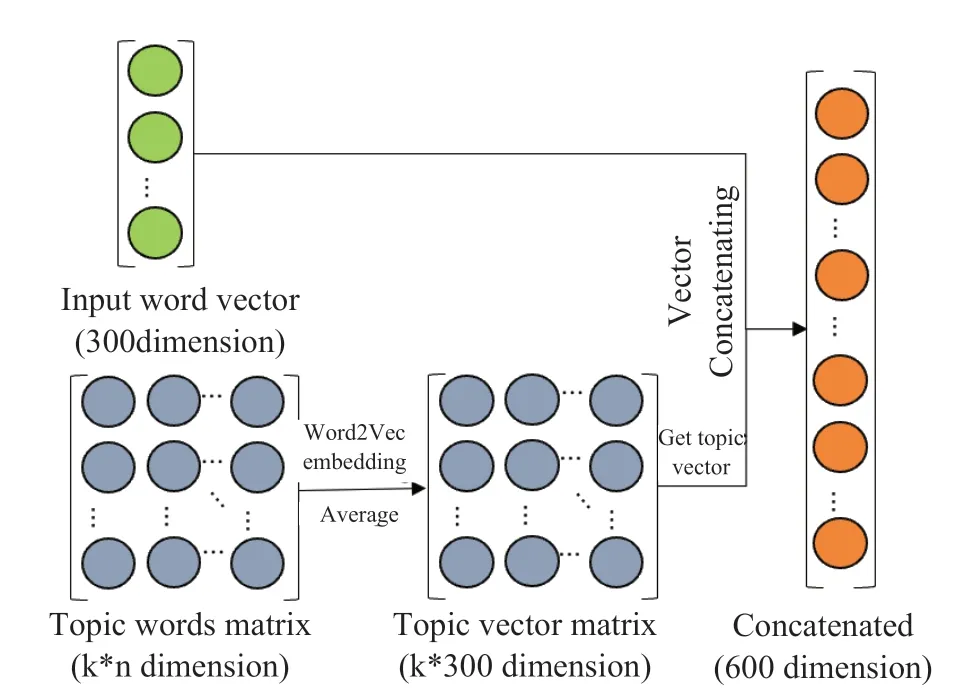
图4 主题向量拼接的过程Fig.4 Process of topic vector concatenating
2.4 情感极性分析
虽然单向LSTM可以包含一个句子的历史信息,但由于每个时间步的隐藏状态无法模拟句子的未来单词,因此它仍然具有限制性。所以本模型采用双向长短时记忆网络提供的一种方法,由前向LSTM和后向LSTM叠加,更准确地获得上下文的语义依赖。
将双向提取的特征向量拼接组合后,用自注意力机制调整权重再输入softmax 进行分类计算。实验结果也验证了其有效性。Bi-LSTM模型如图5所示,将上一步n维向量矩阵中w词向量作为输入,其前向隐藏层的输出为,后向隐藏层的输出为,Bi-LSTM 隐藏层的输出。计算过程如式(12)-式(14)所示:
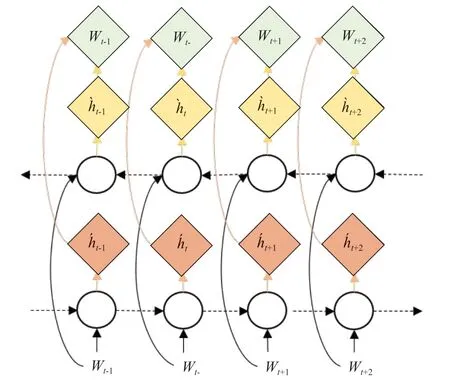
图5 Bi-LSTM模型Fig.5 Bi-LSTM model
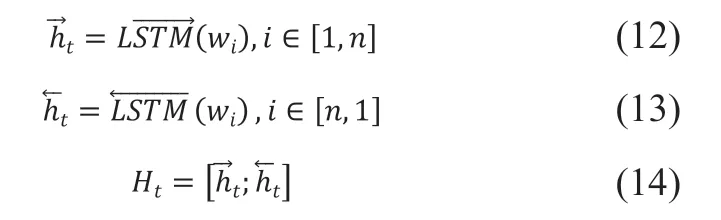
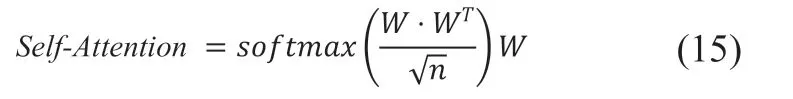

在模型训练过程中,采用反向传播法,通过反向计算每个神经元的误差项值。Bi-LSTM误差项的反向传播包括两个方向:一个是沿时间的反向传播,即从当前的t时间开始,每个时刻的误差项被计算出来;另一个是将误差项向上移动一层传播。每个权重的梯度是根据相应的误差项计算得到。参数通过随机梯度下降算法进行更新。误差交叉熵被用作对象函数(损失函数),并通过Adam优化器训练模型参数,损失函数如公式 (17) 所示:
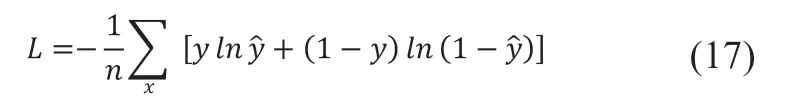
3 实验结果分析
3.1 实验数据选取
在本文中,实验在两类数据集上进行:(1)选取中国科学院谭松波老师整理的酒店评论数据集,共6,000条,包含已标注的正负情感各3,000条。(2)爬取某外卖平台评论作为本次实验的数据集并进行人工标注。其中外卖评论数据集正负情感评论分别为4,000条,共8,000条数据。并将上述两个数据集各分为两份,数据集80%作为训练集,20%作为测试验证集。其中0 表示负向评论,1 表示正向评论。且外卖数据集评论内容长度相对更短,其长度统计如图6所示,借以比较在短文档组成的评论数据集上的性能,表明该模型在短评论文本具有更好的鲁棒性。对数据进行去停用词、分词后,“服务”、“房间”等成为酒店评论热点词汇;“味道”、“好吃”等为外卖评论的热点词汇,其词云图如图7、图8所示。
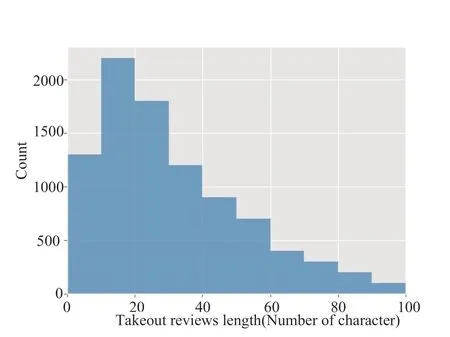
图6 外卖数据集长度分布 Fig.6 Length distribution of takeout dataset

图7 酒店评论词云图 Fig.7 Hotel reviews word cloud illustration

图8 外卖评论词云图 Fig.8 Takeout reviews word cloud illustration
3.2 实验环境
本文模型建模过程建立在TensorFlow和Keras框架上。用jieba作为分词工具,实验环境配置如表1所示。

表1 实验环境配置Table 1 Experimental environment configuration
3.3 主题提取与参数估计
对评论文本数据预处理后,在LDA模型中需要自行设置很多参数,其中主题(Topic)数尤为重要。主题数有很多方法可以计算,困惑度常用来度量一个概率分布或概率模型预测样本的好坏程度,困惑度越低,意味着更好的LDA模型,最小值对应的主题数即为最优数。本文采用困惑度(Perplexity)为指标确定模型的最佳主题数。困惑度计算如公式(18)所示:
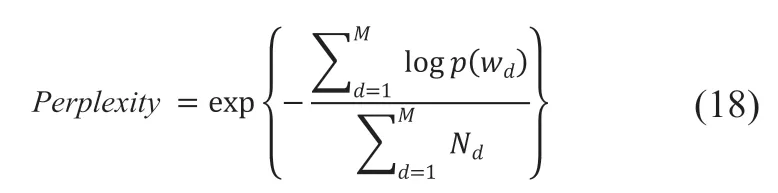

图9 困惑度随主题数目变化曲线Fig. 9 The curve of perplexity-topic
基于Python学习包gensim对评论数据进行LDA主题建模,从而得到语义划分及其隐含主题的分布情况。这里只展示酒店数据集的其中3个主题和每个主题的前10个词汇的分布情况,如表2所示。
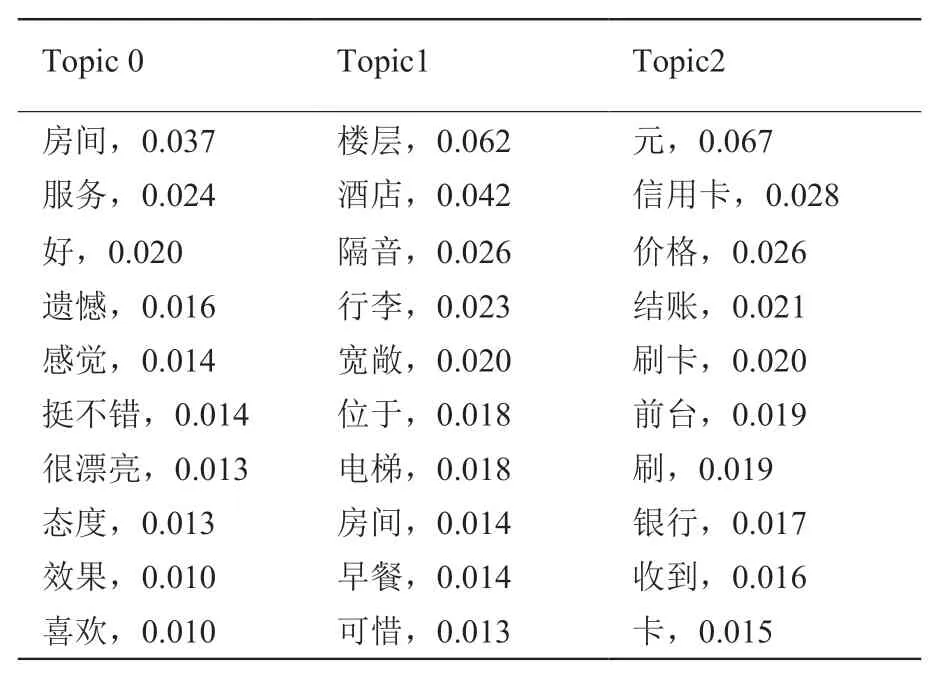
表2 主题挖掘结果Table 2 Topic mining results
在确定文本语料所需的主题数后,还需要对其他参数进行设置。首先将主题概率分布最小阈值设置为0.01,以排除冷门主题,具体参数如表3所示。而后通过测试集F1值确定最佳迭代次数为25,F1值迭代次数关系如图10所示。

表3 模型参数设置Table 3 Model parameter settings
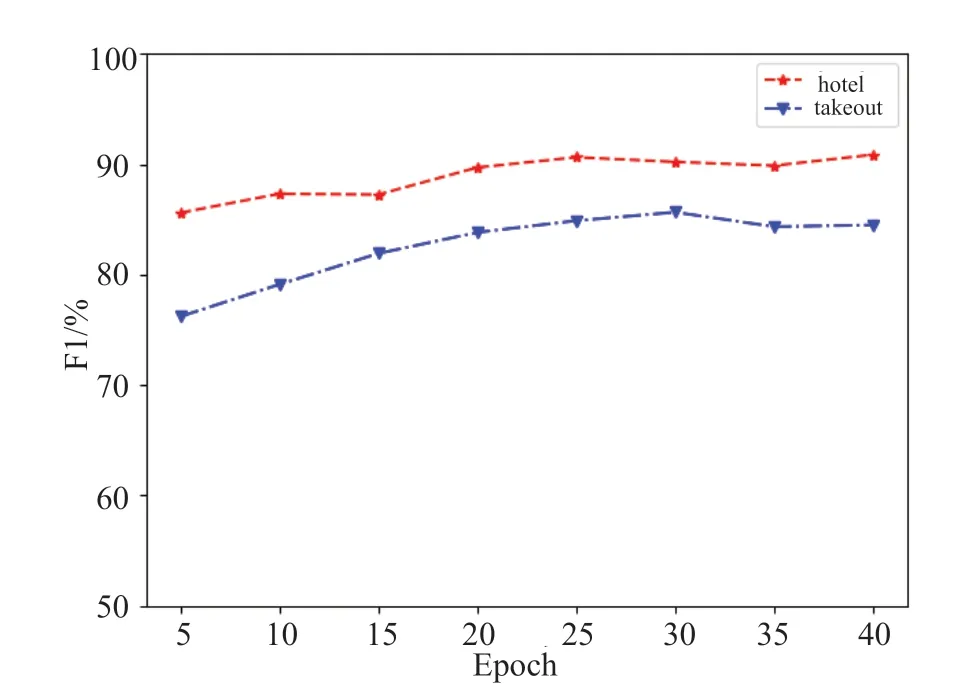
图10 迭代次数在两个数据集上对F1值的影响Fig.10 The effect of the number of iterations on F1 values on both datasets
3.4 评价指标
本文使用一个常用的混淆矩阵来评估模型的效果。用三个指标描述数据分类性能:准确率(precision)、召回率(recall)和 F1-score 值。混淆矩阵如表4所示,其相关计算如式(19)-式(21)所示:


表4 混淆矩阵Table 4 Confused matrix
3.5 结果分析
为了证明模型的有效性,本节在主题提取和情感分析方面将TSA-BiLSTM的性能与以下基线模型在相同环境下进行比较:
(1)Bi-LSTM:标准的双向LSTM模型,用隐藏状态的平均值用作分类特征。
(2)TC-LSTM:Tang等[7]提出的方法,利用主题词和文本中的词构成文本的特征表示,用LSTM提取特定对象的语境信息。
(3)ATAE-LSTM:Wang等[11]在AE-LSTM的基础上进行了改进,把主题词向量与每个单词的输入向量相关联,结合注意力机制,更好地利用主题信息。
(4)AE-DATT-LSTM:胡朝举等[12]利用Bi-LSTM训练词向量,将主题特征和文本特征进行特征融合,经深层注意力机制处理,得到相应主题的情感分类结果。
(5)C-SATT-BiLSTM:吴小华等[13]提出对评论文本进行字向量化表示,结合自注意力与Bi-LSTM对短文本进行情感分类。
(6)SAAE-BiLSTM-SA:李磊等[15]提出的短文本情感分析模型,将关键对象识别、深层自注意力机制与Bi-LSTM神经网络相结合。
表5和表6显示了本文方法和其他模型之间的比较结果。模型TC-LSTM加入target word向量后,与单一的Bi-LSTM模型比较效果提升了3%-5%,说明target word对于丰富数据信息有一定作用,但其模型没有引入注意力机制所以情感极性会受到不相关词的影响。在融合主题提取方面,本文模型与ATT-BiLSTM、AE-DATT-LSTM两个融合主题向量的模型对比,在数据集上效果均有提升。对比C-SATT-BiLSTM通过在字级别上构建文本输入序列,本文模型通过LDA扩展主题特征信息,在酒店数据集上准确率、召回率、F1值分别提高了1.01%、0.55%、0.78%。并且本文使用的Self-Attention机制较普通注意力机制可以更加准确地捕获句子内部关键特征,最终的F1值在两数据集上分别提高了3.47%、1.7%。
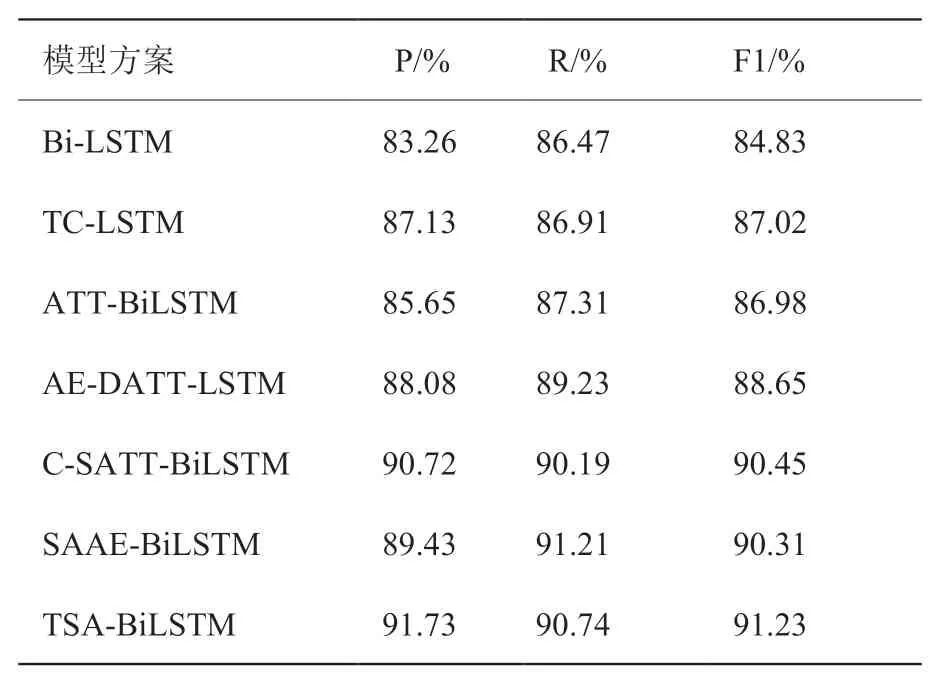
表5 酒店数据集实验结果Table 5 Experimental results of hotel dataset
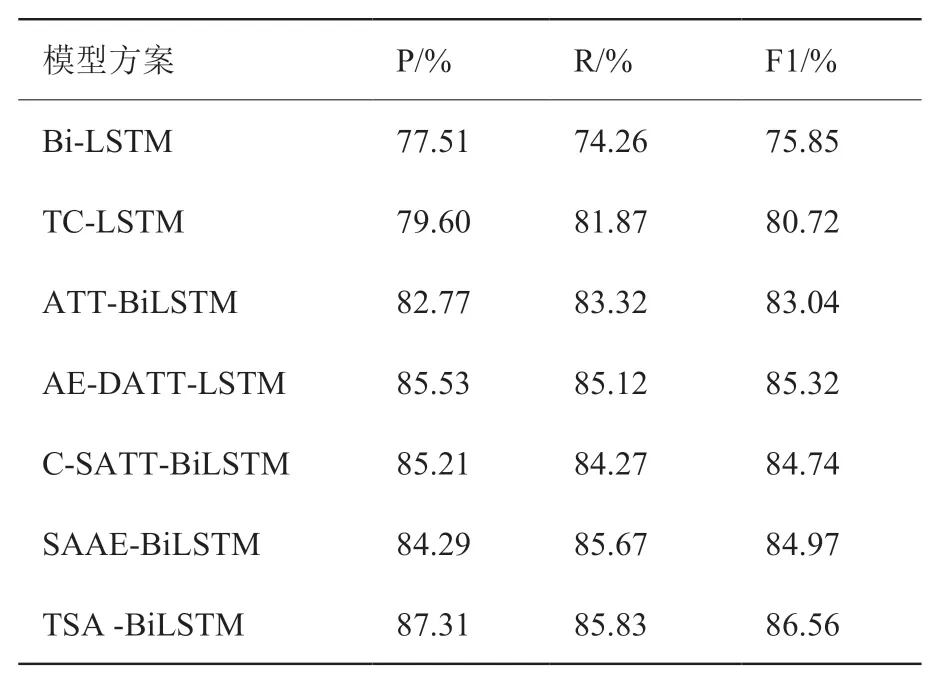
表6 外卖数据集实验结果Table 6 Experimental results of takeout dataset
为分析不同模块在分类模型的贡献,本文将完整模型的两个变量进行消融实验。(1)w/o LDA:去除融合主题模块即LDA,直接对评论文本提取词向量。(2)w/o Self-Attention:去除自注意力机制模块,直接将Bi-LSTM得到的语义向量信息发送到分类器。在两个数据集的表现如图11所示,主题向量的提取增强了语料库,特别是针对短评论文本而言有较大提高。利用注意力机制可以获得关于上下文主题词的丰富语义信息,为更直观地说明自注意力能够捕获文本中的情感词、主题词之间的依赖关系,本文将句子中词向量注意力权重分配情况可视化展示,显示文本中的重要情感特征。如表7所示,以酒店数据集中的正负样本为例,分别对主题是“酒店”和主题是“服务”的正负面文本情感特征进行标注,其中颜色较深部分权重较大,而颜色较浅部分权重较小。由此可以证明,融合LDA主题模型可有效地扩展评论短文本中的关键特征,引入Bi-LSTM结合自注意力机制有助于动态查找特定主题的情感词对文本进行情感分析。

表7 注意力权重可视化Table 7 Attention weight visualization
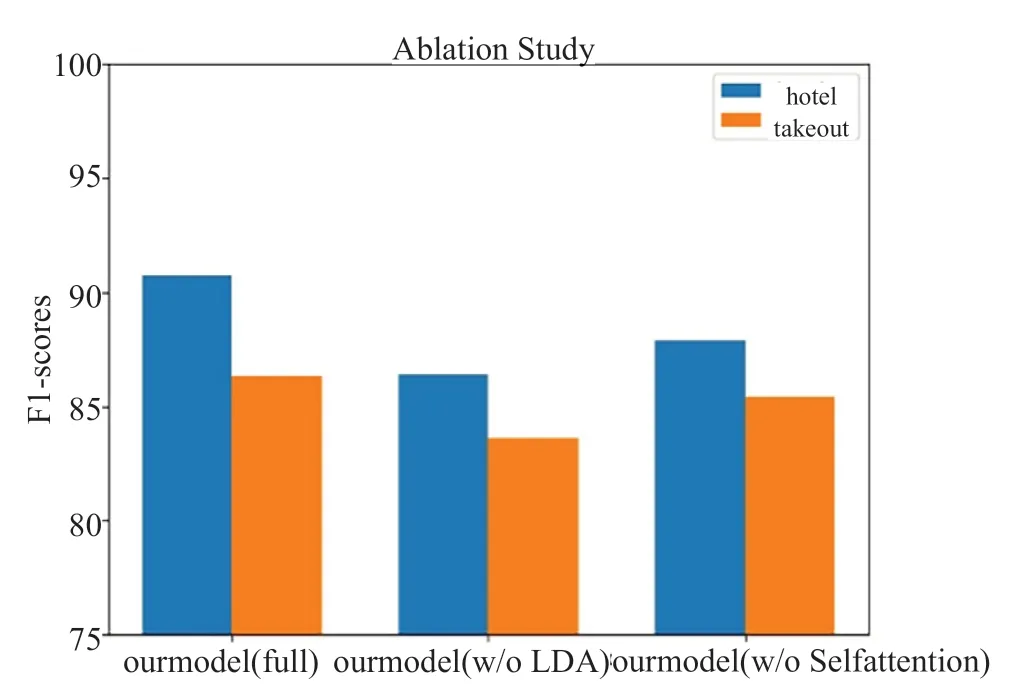
图11 模型在数据集上两个消融变体的F值结果Fig.11 The F value results of the two ablation variants of the model on the datasets
4 结束语
本文设计了一种改进的融合主题特征的评论短文本情感分类模型,主要工作如下:使用LDA主题模型获得评论的主题词分布,扩充了原短评论文本的特征空间,学习文本潜在的主题信息,克服短文本数据稀疏、主题不明确等问题。然后采用Bi-LSTM网络将评论短文本的上下文信息充分提取,捕获更多语义信息,将复合向量作为Self-Attention的输入,不仅可以动态调整特征重要度权重,降低情感分类的复杂度,还可以针对特定主题提取情感特征。将本文模型在谭松波酒店数据集和外卖数据集上进行了实验,与ATT-BiLSTM、character-SATTBiLSTM等模型相比,所提出的模型在情感极性分类方面有较好的表现。
今后的工作是研究如何生成更高质量的主题向量,改用更先进的预训练模型来表达词向量如Bert,以期在评论文本情感分析中得到进一步的效果提升。此外,将考虑通过知识图谱[21]引入额外的情感特征信息构建模型,或通过胶囊网络[22]进一步提升整体性能。
利益冲突声明
所有作者声明不存在利益冲突关系。
