基于算力网络的大数据计算资源智能 调度分配方法
2022-12-22金天骄栗蔚
金天骄,栗蔚
1. 中国移动通信集团浙江有限公司,浙江 杭州 310030 2. 中国信息通信研究院,北京 100191
引 言
随着社会信息化和网络化的发展,数据爆炸式增长,全球数据总量正在持续增长,预计2025年将达到163ZB[1]。大数据被誉为是“21世纪的钻石矿”,一方面对国家治理能力、经济运行机制、社会生活方式以及各领域的生产、 流通、分配、消费等活动产生重要影响;另一方面帮助人类通过相关关系重新认识世界[2]。大数据已广泛应用于医疗、生产、城市治理、民生改善等多领域,大幅提高了人们的生产效率和生活水平。合理收集、分析、使用各行业产生的数据,已成为现代化社会的趋势。
数字经济时代,数据已成为企业乃至国家的重要资产,国家之间的核心竞争力将围绕数据、算力和算法展开[3]。信息技术的发展和应用推动数据成为继能源之后的重要战略资源[4]。但数据资源的价值只有经过充分计算、分析后才能够体现其真正的价值。基于大数据计算结果的数据分析、决策分析等已成为各行各业重要的数据依托。而云计算、物联网、大数据等新技术的迅猛发展,引发了数据规模的爆炸式增长和数据模式的高度复杂化,如何对爆发式增长的数据进行有效存储和及时分析已经成为亟待解决的问题。
由数字信息科技引领的“第四次产业革命”已将当代社会推向以“数据+算法+算力”为新型构架的“数权世界”[5]。近年来,随着5G、人工智能等技术的不断普及,数据信息不断增长,算法模型不断更新,新型数据中心开始成为支撑上述产业不断发展的重要基础设施[6]。
根据中国信息通信研究院发布的《数据中心产业发展指数》显示,我国数据中心产业总体规模已接近2,000亿元,一线城市等热点地区指数相对较高。图1体现了2017年至2021年国内数据中心机架规模情况,根据相关数据可以发现总机架数量每年大约以30%的比例稳步增长,其中大型以上数据中心机架规模增长更为迅速,机架规模达到420万架,占比达80%。机架规模不断增长的背后表明我国各企业用户对算力存在海量需求[7]。因此,随着数字时代的发展,国内数据中心总体算力将面临较大的算力缺口。相较于中西部地区的算力需求增长,东部地区由于供电、能耗等指标的影响,算力可扩展空间有限,未来将面临算力短缺的状况[8]。
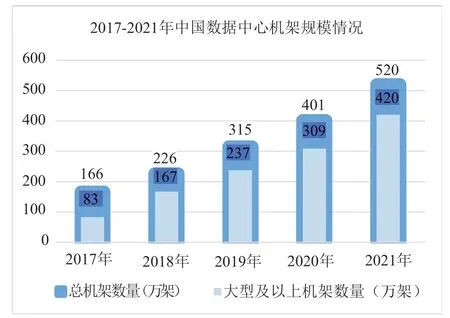
图1 2017-2021年中国数据中心机架规模情况Fig.1 Scale of data center racks in China from 2017 to 2021
1 大数据算力现状分析
1.1 数据量不断增长,需求算力越来越多
当前人类社会进入数智化时代,全球数据总量快速增长,根据国际调研机构IDC发布的《数据时代2025》预测,全球数据总量将从18年的33ZB增至7年后的175ZB[9],增长超过5倍(图2);中国平均增速快于全球3%,预计到2025年将增至48.6ZB,占全球数据圈的比例由23.4%提升至27.8%。其中,中国企业级数据量将从2015年占中国数据量的49%增长到2025年的69%。数据量的不断增长同时意味着算力需求的增长,但受制于CPU晶体管的制造工艺,摩尔定律正在失效,单芯片的算力增长逐渐变缓。在传统大数据计算平台架构模式中,受限于节点计算资源(CPU核数、内存大小等)的限制,算力资源更显得弥足珍贵,数据计算的成本随着数据量的增长不断上升,已成为所有企业乃至国家不得不考虑的问题。
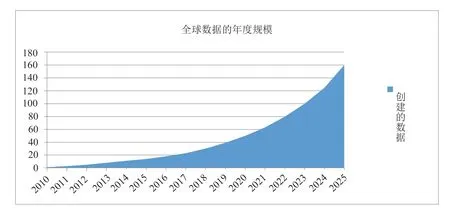
图2 全球数据的年度规模Fig.2 Annual size of global data
1.2 异构算力需求增长明显
应用系统的日益发展对计算芯片提出了更高的要求,而通用处理器由于晶体管集成的限制,单芯片的制造成本不断升高,而算力的增幅比例则开始下降[7]。同时,大数据计算已经向多元化发展,数据量呈现爆炸式的增长[10],数据结构越加多样化,非结构化数据不断涌现。因此,越来越多场景已经引入DPU、DSP、GPU、ASIC、FPGA等多种异构计算单元来进行加速计算。异构算力能力适配当前面临的多元数据形态,满足各种上层应用对基础算力资源多样化的需求[11]。当企业新增异构资源计算需求时,现有计算资源往往不能满足新业务的多元化需求,而当企业自主增加异构算力资源池时,往往带来异构算力与上层应用无法完全适配、应用移植优化难、软件生态少等问题。应用迁移后往往无法发挥硬件资源优势,无法实现算力灵活、高效的调度。
1.3 边缘计算场景增加
当前的大数据计算业务场景越来越多样化,常见的一种业务场景是计算结果需要快速反馈的低时延应用场景(如实时计算),计算结果要在第一时间返回到目标终端,为达到上述目标,节点之间的通信需要具备高带宽、低时延的特性,而满足这类业务场景需求,需要将计算节点靠近终端侧部署。尤其对于某些银行、金融机构等企业,出于数据安全原因,要求数据不出域,只能调度本地域或本地机房的算力资源,从而避免服务器在处理数据时将数据一次性全部上传至云端,以此保证数据安全,防止数据泄露。
面对以上痛点,传统的解决方法是根据经验或业务实际需求,由集群管理员扩容集群普通计算节点或异构计算节点,增加平台计算资源,以满足突发或新增的业务需求。但此方法扩容周期长,响应慢,灵活性低。并且随着我国数字经济蓬勃发展,东西部算力供需关系的失衡也正在逐渐显现。东部算力缺口大,而西部算力需求少,在物理空间上,算力基础设施与相关产业需平衡发展。新型数据中心的建设不能仅局限于单一节点计算能力的提升,更要着眼全局,实现对各算力中心的统一调度能力。
2 通过算力网络解决大数据算力痛点
面对日益增长的大数据算力需求,传统的大数据架构模式已无法解决当前情形下的痛点问题。而算力网络通过专业、弹性、协作方式完成的高效云-边-端算力的整合,利用其对各级资源灵活调配的特性,可以解决大数据计算分析领域业务场景多元化、算力需求多样性、算力利用率低下的问题。
2.1 调度全网算力,满足算力需求
算力网络的核心便是云-边-端的三级算力架构,是实现云-边-端算力高效利用的有效手段。如今,算力网络通过精准策略调度、灵活算力连接、充分算力协同,整合全网资源池的所有算力(包括异构算力),由算网大脑为客户智能调度分配合适算力资源,通过算力标识和资源感知实现具体应用的计算任务与多样化算力基础设施之间智能调度,从而提升任务计算效率、提高算力资源的利用率[8],为用户实现随取随用、透明无感的使用体验。
例如针对GPU计算场景,基于算力网络,将中心区域企业的GPU计算任务调度至边缘地区的异构资源池的算力中心,提升计算效率、降低计算成本;针对实时计算,基于算力网络,将实时交互类计算任务调度至离用户最佳的边缘节点进行计算分析,实时推送到终端,实现跨终端、可交互、沉浸式的访问。算力网络通过对多样化的算力协同调度处理,消除各算力资源池在应用层使用上的差异,实现全网资源调度并提升用户使用体验[12]。
2.2 利用西部低成本算力,降低离线批处理成本
近年来我国东、中、西部算力资源快速发展。为贯彻落实国家战略部署,统筹引导新型数据中心建设,构建良好的算力生态体系,实现数据中心建设的高质量快速发展,工业和信息化部发布了《新型数据中心发展三年行动计划(2021—2023 年)》,标志着“东数西算”工程正式启动。
“东数西算”是基于算力网络的重点应用场景,其中算力网络实现了在云、边、端等多维度逻辑空间上的统一纳管[13]。算力网络依赖无处不在的弹性网络,通过“联接+计算”实现算网一体。中国移动接连发布《算力感知网络技术白皮书》、《中国移动算力网络白皮书》,全面阐释了面向算力网络发展愿景和规划, 在十四五时期网络演进的背景、核心理念、演进目标、实现路径、具体工作举措等,系统性介绍了五层技术架构和六大关键举措[14],促进以算力为中心的应用规模落地。
同时,降本增效是大多数企业不断追求的目标,而算力网络中弹性伸缩的特性可为企业用户大幅降低硬件成本投入[8]。单一的数据中心在后期运营过程中容易出现资源孤岛现象,算力需求过高或者过低都不利于后期发展,而算力网络的应用则可以联通全网资源节点,统一调度,提升资源池利用率[15]。
2021年5月,国家提出并布局建设全国一体化算力网络国家枢纽节点[16],其中包括能源价格较低地区,如贵州、甘肃、宁夏、内蒙古等地。充分发挥规模化、集约化优势,建设绿色节能的新型算力基础设施,实现“东数西算”整体目标[17]。最终通过全国数据中心统一调度,实现算力需求与算力资源的最佳匹配,从整体上降低算力总成本。
3 基于算力网络的大数据资源调度方法
3.1 基于算力网络的大数据计算体系
为了满足当前多样性的大数据业务场景下的计算资源需求,提高各资源池计算资源利用率,本文提出一种基于算力网络的大数据计算资源智能调度分配方法,结合容器化技术、存算分离技术,对各资源池内的计算资源进行整合,统一规划调度,实现各资源池计算资源的高效利用。使用存算分离技术,可将计算和存储分别弹性扩展、按需分配,降低了系统部署和扩展成本,同时将CPU和磁盘充分调度起来,解决了资源利用不均衡的问题,提高了资源利用率,降低运营成本,并有助于实现全国算力网络统一布局;基于容器化技术,利用其可移植性、可伸缩性、高效性、安全性及快速响应性的特点,根据业务繁忙程度,灵活快速地扩缩容计算资源,提高数据计算单元的创建速度。同时可利用各类算力资源的多样性特征,提升整体服务能力。例如对时延敏感型的应用可调度端侧算力;对精度敏感型应用可调度中心算力;对价格敏感型用户可调度西部算力;对时效敏感型用户可调度异构算力。
基于算力网络的大数据计算体系总体架构从逻辑上分为业务应用层、平台层、资源编排层、基础算力层,如图3所示。
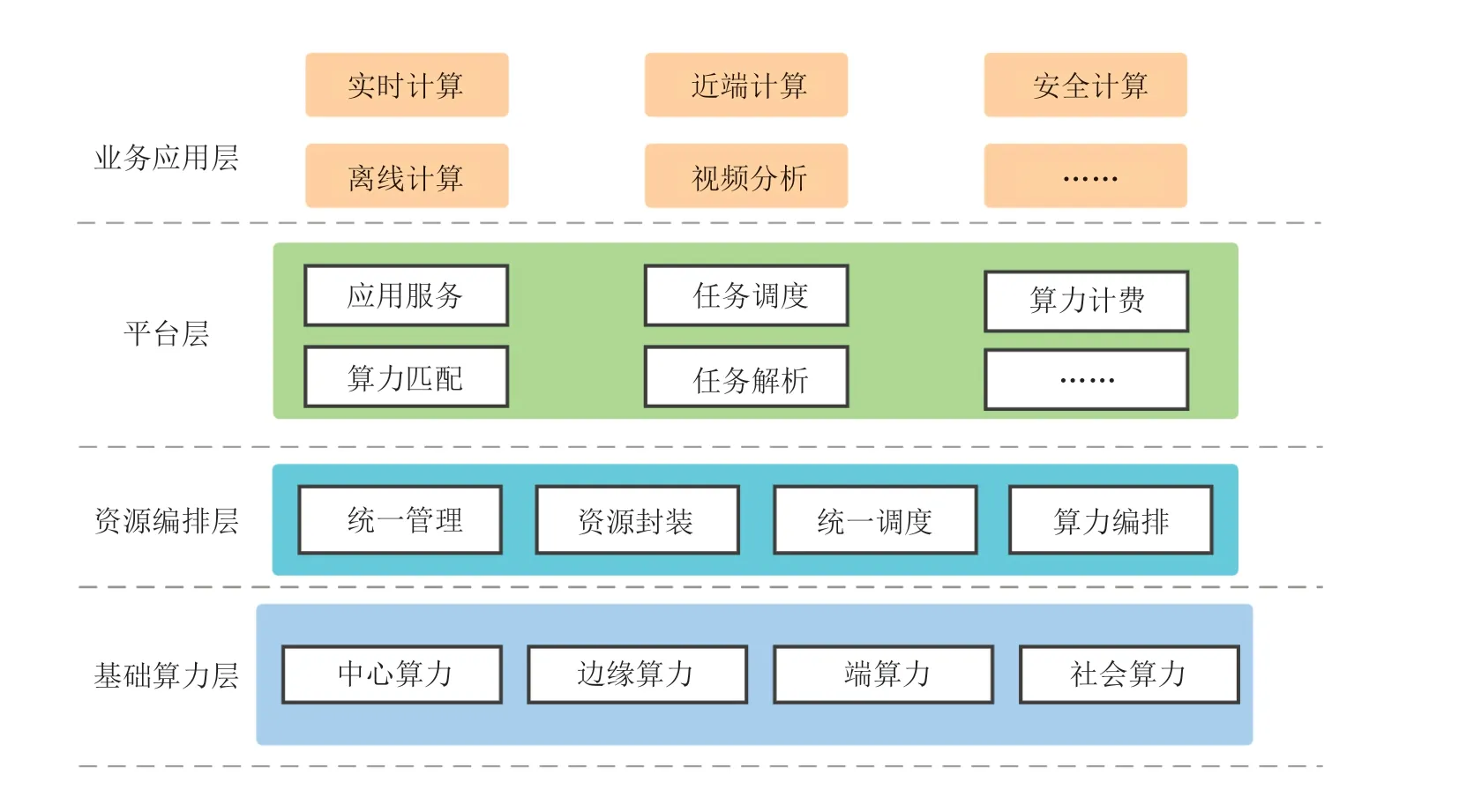
图3 基于算力网络的大数据计算体系架构图Fig.3 Architecture diagram of big data computing system based on computing force network
(1)业务应用层为不同业务场景提供丰富的个性化服务,提供适用于各种个性化大数据场景的优化解决方案,支持主流大数据计算相关软件及 框 架,如Spark、Flink、HBase、Hive、Presto、Elasticsearch等。用户通过平台提供的统一可视化界面和接口,根据自身业务特性及计算类型,选择适配的计算方案后,即可一键提交计算任务。
(2)平台层用于用户任务需求解析,将用户提交的任务进行算力分解,将业务需求换成为资源需求并添加相关标识,该标识可用于划分业务等级并根据优先级进行排列。资源需求信息确定后,会根据用户所选算力类型、用户任务预估运行时间等情况进行任务计费以及调度工作,将用户任务所需的计算资源需求提交至算网大脑,由整个算力网络分配最优解的算力资源。
(3)资源编排层对外提供算力编排、统一调度、资源封装、统一管理能力,是算力网络最重要的核心能力。对于云、边、端等多模式、多层次的算力网络架构,算力的管理和分配至关重要,资源编排层首先将分散的计算、网络等基础设施资源进行抽象、聚合、池化和分组,将不同资源池内的硬件资源、软件资源进行封装,统一注册到算网大脑,形成弹性的组网服务和算力资源调度,从而实现跨地域、跨数据中心的操作算力,使不同资源池算力间可以相互协同,统一调度,数据也可以在不同资源池间安全传递。
(4)基础算力层主要包括网络基础设施,边缘/核心计算节点基础设施(例如数据中心和多接入边缘计算节点),用于异构算力资源的生成与连接。基础算力层通过基础设施的连接,将中心云核心算力、边缘算力以及端算力融合在一起,构筑成跨区域、跨层级的云边端立体泛在的算力体系,能够满足低时延、数据不出域、异构算力等丰富的业务需求,是算力网络大数据服务的坚实底座。
3.2 大数据计算资源智能调度分配方法
为更清晰阐述本方案,本章节通过基于算力网络的大数据体系业务流程进行说明。在本实施例中,平台层根据用户提交的任务属性(任务优先级、任务类型、作业时间等)将多个用户提交的任务进行解析,并将解析后的资源需求提交至资源编排层,由资源编排层根据任务属性,分配/调度最合适的算力资源进行数据的计算。业务流程如图4所示。
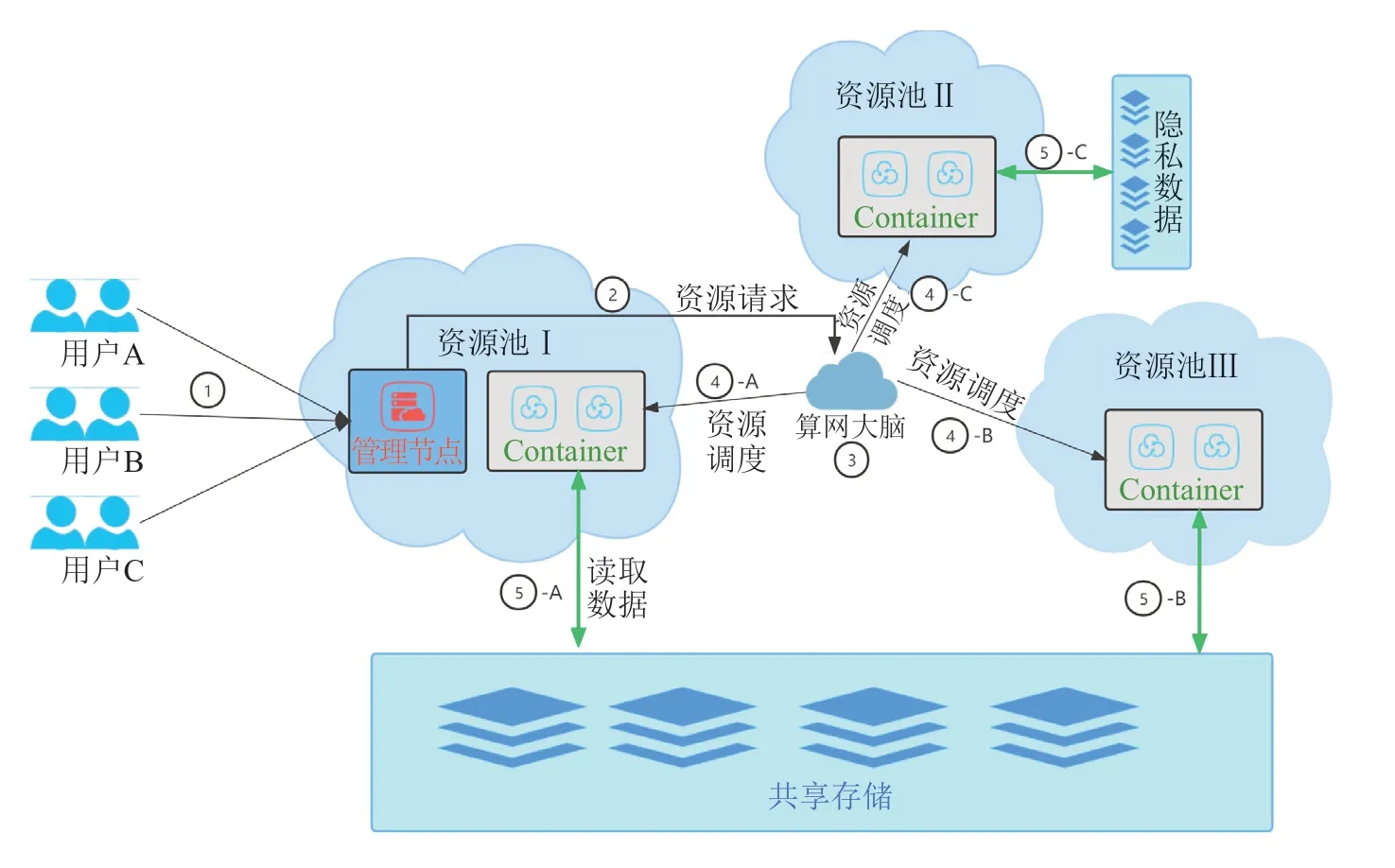
图4 基于算力网络的大数据计算体系业务流程图Fig.4 Business flow chart of big data computing system based on computing force network
(1)在流程①中,用户A、B、C在用户界面提交任务后,平台层解析用户任务,解析结果为用户A为实时计算/快速计算任务,需要100C、500G高性能计算资源;用户B为低时延视频分析任务,需要50C、200G近端计算资源,并且需要使用到异构计算资源GPU;用户C为安全计算任务,数据不出特定域,计算资源也需要在指定域内,需要100C、300G计算资源。平台层将用户提交的任务解析完成后,根据计算任务的需要,向算网大脑(资源编排层)请求实际的算力资源(流程②)。
(2)流程③中,算网大脑在收到算力资源请求后,使用混合群优化算法中的粒子群算法(PSO)[18],寻找、计算最符合各任务计算需求的算力资源。利用粒子群算法,算网大脑可以计算出资源调度分配的最优节点,使资源分配达到最优平衡,基于粒子间的相互工作来完成整个算力网络中计算节点的搜索。
以下是粒子群算法基本实现:若算力网络已接入R个算力节点,D维空间中有N个粒子,D维表示算力网络平台上提交的任务个数,粒子i位置,表示在粒子群个数范围内。将x代入中求适应值,粒子i速度, 最终在第d(1<=d<=D)维的位置变化范围通常限定在之间,而速度变化范围一般限定在之间。 表示粒子距离目标最近的解;则表示整个种群中离目标最近的解。粒子i的第d维速度更新公式:
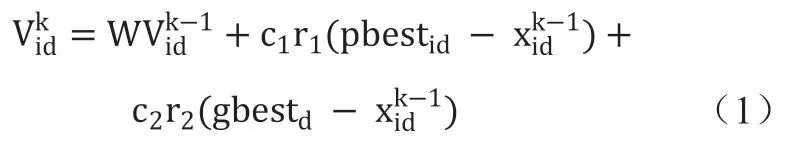
粒子i的第d维位置更新公式为:

取值范围在[0,1]内;w为惯性权重,用于调节对解空间的搜索范围。影响权重的因素包括集群信息、计算信息、网络信息、存储信息、价格信息等属性信息。
算法流程如图5所示。
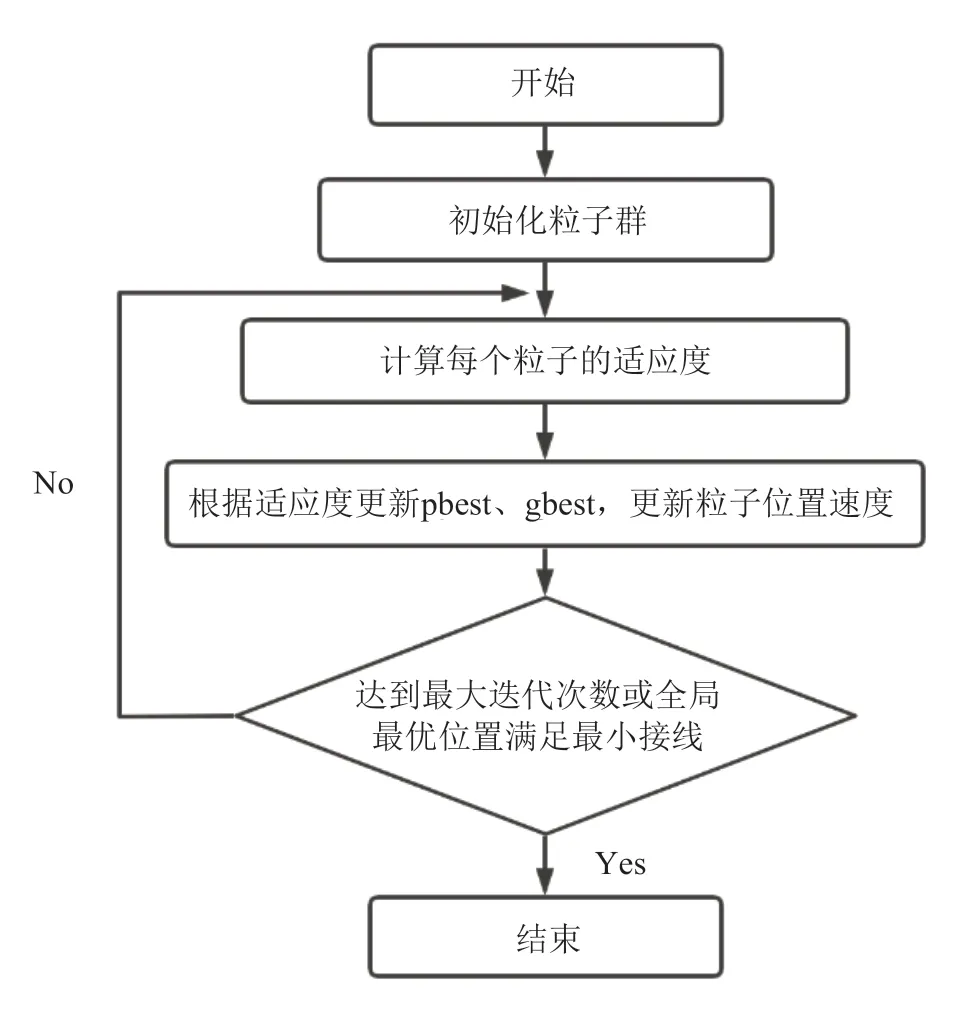
图5 粒子群优化算法流程图Fig.5 Particle Swarm Optimization Algorithm Flowchart
具体实验将任务集设置100个调度任务,实验结果发现该粒子群算法在迭代24次后收敛;任务集有200个任务的情况下,迭代次数与100个任务时相差不大。
实验过程中为了使任务能够跳出局部解,因此当粒子陷入局部最优的情况下,进一步利用混沌搜索来优化粒子的速度和位置。混沌是一种非线性系统现象,具有随机性、遍历性和规律性等特点。本文是利用混沌搜索在一定局部范围内,不重复遍历所有状态的特性,使粒子跳出局部最优解,以避免粒子群算法早熟。原理是在当某个粒子陷入局部最优解时,就随机生成一个与粒子群搜索空间同维的空间,并利用映射关系得到一个混沌粒子序列,然后通过适应度计算出序列中的最优粒子与局部早熟的粒子哪个更优,若序列中的粒子优于早熟粒子,则使用序列中的粒子替换掉早熟粒子使粒子跳出局部解。
实验后发现当任务集有100个任务时,优化后粒子群算法迭代了58次后收敛,但是总体调度时间比优化前要短,节省了大约23秒。当任务集再次设置200个任务时,优化后的迭代次数与设置100次时仍相差不大,但总调度时间节省了106秒。
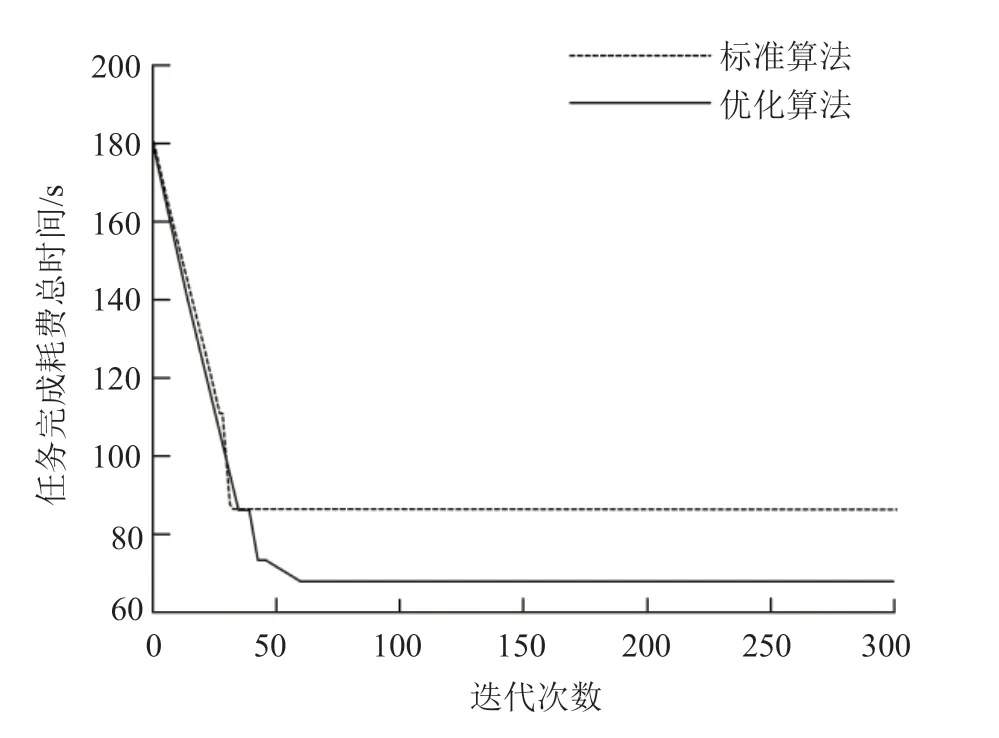
图6 任务数为100时的完成时间Fig.6 Finish time that the task numberis 100
总体来说,若粒子群算法存在局部早熟,在算力调度过程中,会使算力资源池出现资源利用率较低等问题,通过该优化算法可有效提高任务调度效率。
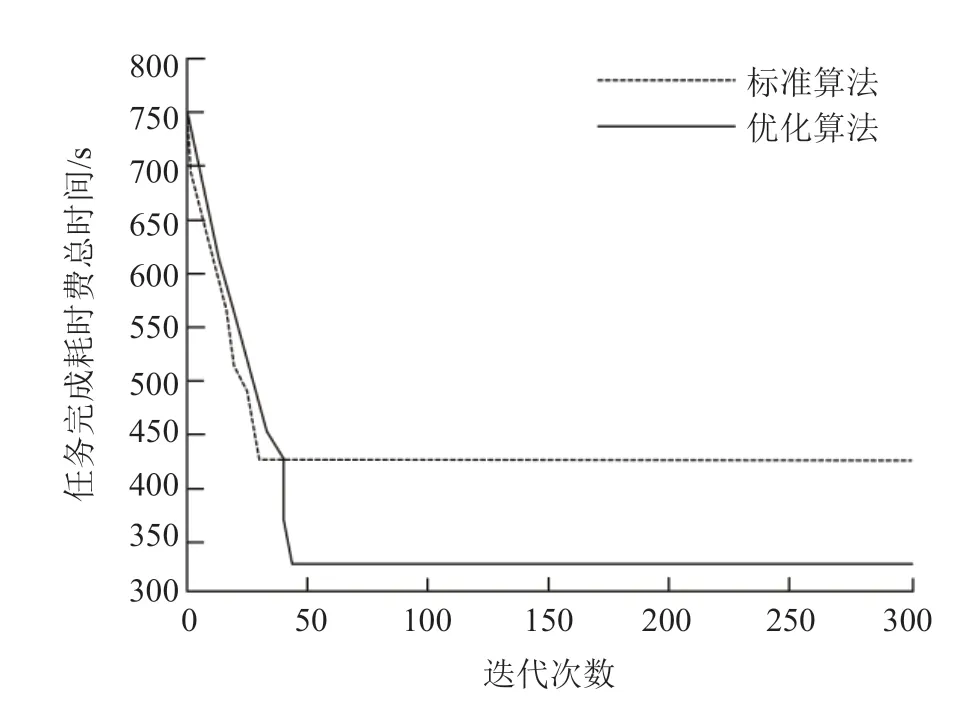
图7 任务数为200时的完成时间Fig.7 Finish time that the task numberis 200
(3)任务在获得由算网大脑分配的最优计算资源后,开始任务的执行。A任务需要高性能的实时计算资源,算网大脑在经过计算后,将资源分配在了资源池Ⅰ中,A任务在获取实时计算资源后,使用容器化技术,直接启动所需大数据组件(流程④-A),并以存算分离方式访问共享存储上的数据(流程⑤-A),进行实时计算分析。B任务需要低时延、近端的计算资源,且需要用到GPU设备。算网大脑将资源分配在了资源池Ⅲ中。B任务在获取近端计算资源后,使用容器化技术,直接启动所需大数据组件(流程④-B),并以存算分离方式访问共享存储上的数据(流程⑤-B),进行低时延近端计算分析。C任务出于业务数据主权的原因,计算数据不能出域,因此算网大脑将计算资源分配在数据所在域的资源池Ⅱ(④-C)。C任务在获取计算资源后,使用容器化技术,直接启动所需大数据组件,并以存算分离方式访问域内隐私数据(⑤-C),进行数据的安全计算。
(4)用户完成计算任务后,任务节点释放算力资源,这些被释放出来的算力资源会被算网大脑重新统一封装注册,再次参与算力的匹配调度。在匹配到合适的新计算任务时,算网大脑会将这些计算资源重新分配用于新任务的计算工作。
4 结束语
本文提出了基于算力网络的大数据计算资源智能调度分配方法,依靠算网大脑的智能调度分配资源特性,解决了计算环境下资源分配过程中的资源调度时效性、资源利用率以及负载均衡等问题。用户只需要通过业务应用层,提交大数据业务场景对应的计算需求,算网大脑就会根据用户任务的算力需求自动匹配整个算力网络中最合适的算力资源,用户无须关注算力提供节点的真实物理位置,只需关注数据计算业务本身的资源需求,所有合理匹配算力资源的工作都由算力网络完成,帮助业务真正实现了按需在全网范围内第一时间获取所需的大数据资源。
利益冲突声明
所有作者声明不存在利益冲突关系。
