基于提高伪平行句对质量的无监督领域适应机器翻译*
2022-12-22肖妮妮段湘煜
肖妮妮,金 畅,段湘煜
(苏州大学计算机科学与技术学院自然语言处理实验室,江苏 苏州 215006)
1 引言
近年来,随着神经机器翻译NMT(Neural Machine Translation)[1-3]的出现,机器翻译的质量得到了进一步的提升,甚至在一些特定领域,机器翻译几乎达到了人类翻译相当的水平,这得益于神经机器翻译基于编码器-解码器框架的深度神经网络设计和注意力(Attention)[4]机制。相比于传统的统计机器翻译SMT(Statistical Machine Translation)[5-9]系统,这样的框架有许多吸引人的特性,例如较少的人工特征和先验领域知识的需求。但是,尽管神经机器翻译在过去的几年中取得了飞速的发展和进步,大多数神经机器翻译系统仍然存在一个共同的缺点:其性能严重依赖高质量的内领域数据。然而,即使在互联网高度发达的今天,在绝大多数的领域中,通常也难以找到高质量、大规模、覆盖率广的平行语料库,这导致神经机器翻译模型在低资源语言和特定领域上的翻译效果与大众对机器翻译的期望仍然相差甚远。
在所有领域中收集大量平行数据是很昂贵的,并且在许多情况下是不可能的。因此,有必要探索有效的方法来训练能够较好地推广到新领域的模型。为了有效地克服神经机器翻译中的数据稀疏和领域多样性问题,研究人员也探索了很多不同的解决方案。Chu等[10]指出,机器翻译中领域适应主要有2类方法:以数据为中心(Data Centric)和以模型为中心(Model Centric)。以模型为中心的方法对模型架构进行显式的改变,例如Britz等[11]提出了联合学习领域辨别和翻译2个任务、Kobus等[12]提出了通过添加标签和单词特征进行领域控制等方法来提高模型领域适应的能力。但是在许多实际情况下,研究人员是不知道待使用数据的来源或背景的,很多文本没有天然的领域标签,而且一个句子可能被合理地认为属于多个领域,因此基于领域区分的方法存在局限性。以数据为中心的方法主要是使用内领域和外领域平行数据相结合的方法进行有监督领域适应[13,14],或者利用内领域单语数据生成伪平行语料进行无监督学习[15,16]。其中最具有代表性的策略是使用反向翻译[15]创建内领域目标语句的伪平行语料。然而,尽管反向翻译方法使用广泛且有效,其成功的关键在于伪平行数据的质量,但是它不针对领域或语言提供额外的辅助信息,跨领域的翻译中不可避免地包含大量噪声和错误,这些将会在迭代反向翻译的过程中被不断积累和放大,从而影响到神经机器翻译模型的训练。
针对这些问题,本文分别从以数据为中心和以模型为中心2个角度提出2种简单有效的优化策略。(1)以模型为中心,本文提出了更加合理的预训练策略,通过加入一个神经网络辅助模型学习外领域数据更为通用的文本表示,提高模型的通用性和泛化性,缩小不同领域语言间的差异,使得在翻译内领域句子时译文质量更高,从而在跨领域的差异问题上表现更好。(2)以数据为中心,本文通过扩展反向翻译方法,提出了一种融合情感信息作为数据筛选后验的方法,来提高目标领域单语数据反向翻译译文的准确性,缓解伪数据中的噪声问题,进一步提升了翻译质量。
2 相关工作
目前,有很多关于有监督领域适应的相关研究,其中的数据设置大多是有大量的外领域平行数据和很少量的内领域平行数据。Luong等[13]提出在外领域语料库上训练模型,并用小规模内领域平行数据进行微调(Fine-Tuning),以此缩小领域间的差异。Britz等[11]没有直接将外领域数据和内领域数据进行混合,而是通过联合学习区分域任务和翻译任务,以此来规避跨领域问题。Joty等[17,18]通过在外领域平行语料中选择出与内领域语句更接近的语句,并给予更高的权重,来解决领域适应问题。本文提出的方法主要解决完全没有内领域平行语句的领域适应问题,这是一个严格的无监督设置。
无监督机器翻译领域适应也可以分为以数据为中心和以模型为中心2类方法。在先前的工作中,以数据为中心的策略吸引了众多研究人员的关注,并取得了颇丰的成效。早期以数据为中心的研究有Schwenk等[19,20]使用SMT系统翻译源语言单语句子,并使用合成的伪平行数据继续训练翻译系统。近年来最具有代表性且使用广泛的方法莫过于反向翻译[15]和基于复制的方法[16]。在领域适应中,反向翻译是使用外领域的平行数据训练基础的目标语言到源语言的反向翻译系统;然后使用该系统对目标端的单语数据进行翻译,以此构建伪平行数据。基于复制的方法是由Currey等[16]提出的,其主要思想是将目标端内领域的单语语料复制一份作为源端数据,与其构成伪平行数据。然而,这些方法都没有考虑语言的特性,在跨领域翻译时伪平行语料的质量堪忧,导致使用伪平行句对微调后的模型的翻译结果仍差强人意。
以模型为中心的方法侧重于对 NMT 模型架构特征进行改进,目前较主流的方向是将语言模型等多任务学习集成到 NMT 模型中。Gulcehre等[21]提出融合语言模型 LM(Language Modeling)和NMT模型,但该方法在推理过程中需要查询2个模型,效率低且已被证明其效果不如以数据为中心的方法。Dou等[22]提出了基于领域感知特征嵌入的无监督领域适应方法,通过将特定领域的特征嵌入到神经机器翻译编码端的每一层中,并结合语言模型进行多任务学习来训练特定领域的特征。这些方法通常需要消耗较多的计算资源和训练时间,参数庞多而冗余。
本文结合模型和数据2个方面,致力于更好地处理NMT无监督适应任务。具体而言,为了使模型更好地进行领域自适应,本文设计了一种新型联合训练框架,提出了更加合理的预训练策略,通过加入一个辅助的特征学习网络,学习外领域中更通用的文本抽象信息;同时引入KL(Kullback-Leibler)正则项,使模型的稳定性和鲁棒性得到增强,以更好地适应跨领域间的差异问题。同时,结合语句的情感特征进行后验筛选,利用情感信息对伪训练数据进行降噪,帮助训练神经机器翻译模型,使模型在目标领域的翻译性能得以优化。本文方法充分利用了外领域的平行数据和目标领域的单语数据,且提出的基于数据的方法不依赖于具体的模型架构,这使得本文提出的2种改进策略是正交的,可以相互结合进一步提高翻译的效果。
3 基准模型
Transformer模型架构是由Vaswani等[4]首先提出的,属于编码器-解码器结构,完全基于注意力机制进行序列建模。它是机器翻译中最成功且典型的NMT系统之一,同时具有代表性和一般性。
Transformer的编码器端和解码器端分别是由N层(N默认为6)相同的网络层组成。编码器端的每一层都包含2个子层:多头自注意力层和全连接的前馈网络层,对每一个子层的输出都进行残差连接(Residual Connection)[23],然后是层正则化(Layer Normalization)[24]处理。因此,每一个子层的输出可以表达为layernorm(x+sublayer(x)),其中,layernorm(*)表示层正则化函数的输出,sublayer(x)表示子层的输出,x表示当前子层输入的隐藏层状态。相同地,解码器也堆叠N层相同的网络层,同样包含自注意力子层、前馈网络、残差连接及层正则化模块,此外解码器又引入编码-解码注意力,该子层用于对编码器最后一层的输出进行注意力权重计算。
Transformer模型采用的注意力机制为多头注意力机制,即是将所有查询(Query)构成的矩阵Q、所有键值(Key)构成的矩阵K和所有值(Values)构成的矩阵V按照嵌入维度切分为h个注意力头(h默认为8),分别计算每个头的注意力结果,计算公式如式(1)和式(2)所示。最后把每一个注意力头产生的输出再进行拼接,计算公式如式(3)所示,通过多头注意力机制可以获得多个视角空间的不同表征信息。
(1)
(2)
MultiHead=Concat(head1,…,headh)Wo
(3)
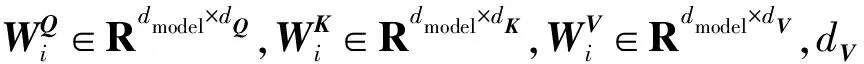
Transformer中使用 Adam[25]作为优化器,使用添加平滑标签的交叉熵[26]作为损失函数,通过最小化损失函数,使得模型的输出概率分布更接近于真实值。
4 提高伪平行句对质量方法
由于各个领域的表达风格和语言特点有差异,如何让神经网络翻译模型在领域间更好地自适应是一个关键问题。无监督领域适应方法通过使用目标领域的单语数据构建伪平行语料训练模型,该方法因具有较少的局限性而得到广泛应用,但伪数据质量较差,导致实际学习到的模型效果仍不理想。本文在Transformer的基础上,添加一个神经网络获取语言中更丰富的表征信息,并引入KL散度正则项增强信息的一致性,使得模型的鲁棒性得到提升,同时提高内领域翻译的准确性。随后使用情感信息作为数据后验筛选,进一步提高伪平行语料的质量,改善模型的翻译效果。
4.1 加入特征学习网络
本文在Transformer基础上加入了一个新的网络模块,对基础模型中源端和目标端的网络隐藏状态采用加入的特征学习网络进一步提取文本特征,学习到更为通用的抽象信息,在模型学习其他基础文本信息的同时与之相结合,提高模型的泛化能力,为模型更好地学习提供支持。
与此同时,所提取出的源端和目标端的抽象特征通过Softmax层后分别得到其概率分布,再在模型的损失函数中加入KL正则项计算,这样可以增加源端和目标端特征概率分布的一致性,拉近双语语义特征相似度,使得模型的鲁棒性和泛化能力得以提高,从而在面对跨领域的差异问题时可以有更好的表现。改进后的模型结构如图1所示。
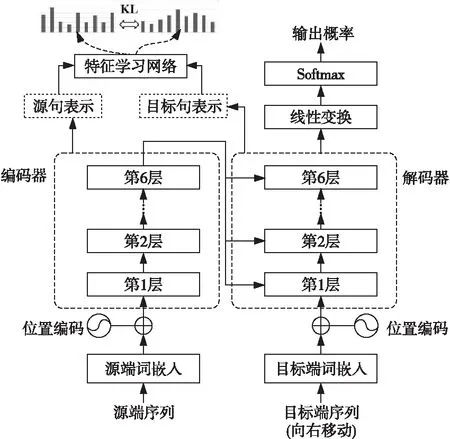
Figure 1 Overall structure of the improved model
具体来说,给定源端序列X=(x1,…,xTx),Tx为源端序列长度,源端序列经过编码器可以被编码为H=(h1,…,hTx),hi表示源端第i个词对应的嵌入向量。同样地,目标端序列Y=(y1,…,yTy),Ty为目标序列长度,目标端序列经过解码器后可以表达为Z=(z1,…,zTy),zi表示目标端第i个词对应的嵌入向量。通过编码后,每个隐藏状态都包含了整句中上下文的相关信息,本文采用平均池化将每个句子的隐藏状态转换成一个固定长度的嵌入向量,再共享一个线性网络层来映射此嵌入向量,得到更为抽象的特征向量,所获取的源句和目标句的特征向量分别记作hout和zout,如式(4)和式(5)所示:
(4)
(5)
其中,W、b是所添加的特征学习网络的参数,在训练过程中不断学习优化。
在引入KL散度计算后,模型的训练目标表达如式(6)所示:
(6)
其中,第1项是标准的训练双语数据的目标函数,第2项是本文引入的提升模型鲁棒性的正则项,θ是模型中的所有参数。具体计算公式如式(7)~式(9)所示:
lossKL=KL(S(x)‖T(y))=
EX~S(x),Y~T(y)(logS(x)-logT(y))
(7)
S(x)=softmax(hout)
(8)
T(y)=softmax(zout)
(9)
其中,S(x)是源端经过特征提取的概率分布,T(y)代表目标端的概率分布,hout是表征源句的特征隐藏状态向量,zout是代表目标句的特征隐藏状态向量。计算二者的KL散度的意义就是希望源端的分布可以向理想的目标端靠拢,最终通过并行融合的方式提升模型的训练效果,增强模型的稳定性和泛化力。
4.2 情感特征后验筛选
语言通常同时带有2种不同类型的信息:显性的语义信息和副隐性的情绪信息。基础Transformer模型缺少对语言情感表征的挖掘,而关注语言中的情感信息可以为模型更好地学习提供支持。在现有的基础模型中,有很多翻译的结果与源句意思大相径庭,这样的翻译必然是难以接受的。产生此现象的一大原因是句子的情感倾向相差甚远,如表1所示。

Table 1 Example of translation
受此启发,本文使用情感信息作为数据后验筛选,以提高回译数据的质量,进一步改善翻译效果。具体来说,本文使用情感分析对伪平行的源句和目标句进行情感倾向打分,当源句与目标句的情感倾向差距较大时认为是翻译质量差的语句,从而不使用该句进行训练,避免错误在训练过程中被不断积累和放大,缓解伪数据中的噪声问题。
算法1针对无监督神经机器翻译的领域适应算法
输出:神经机器翻译的参数模型Mx→y,My→x。
步骤1procedure 预训练
步骤2分别用随机参数θx→y和θy→x初始化翻译模型Mx→y和My→x;
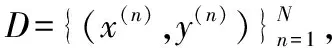
步骤4end procedure
步骤5procedure 领域适应
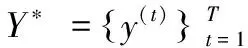
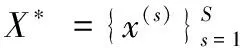
步骤8用情感分类器分别对X′和Y′进行筛选;
步骤9将筛选后的Y′与外领域平行语料D进行混合来微调模型Mx→y;
步骤10将筛选后的X′与外领域平行语料D进行混合来微调模型My→x;
步骤11end procedure
5 实验与结果分析
5.1 数据集
基础的源语言到目标语言和目标语言到源语言的翻译系统使用的训练数据集是从 LDC(Linguistic Data Consortium)里抽取的125万句中英平行语句对,测试集是采用美国国家标准与技术研究院2002年的数据集NIST02、NIST03、NIST04、NIST05和NIST08,验证集是NIST06。内领域单语数据选择中英的TED2020数据,包含39.9万个语句,本文将其划分为包含39.3万句的训练集(分别当作单语使用),以及分别包含3 000句的测试集和3 000句的验证集。对所有的中英语料,都分别进行了BPE(Byte Pair Encoding)[27]编码处理,BPE长度为32 000次合并操作,中文词表长度为4.2万,英文词表长度为3.1万,使用“〈UNK〉”对不在词表中的低频词进行替换。
5.2 实验设置
基准模型采用开源代码 Fairseq[28]实现,将模型设置为Transformer,编码器和解码器层数均设置为6,每层中模块的输出维度和词嵌入向量的维度均设置为 512,神经元的随机失活率dropout设置为 0.3,学习率设置为0.000 5,注意力层中多头注意力机制的头数设置为 8,所有的实验均使用了标签平滑且值为0.1,全采用Adam优化器和逆平方根学习率优化,在解码时采用波束搜索(Beam Search)的解码方式,搜索宽度设置为5,其他未提及的基本超参数均与文献[4]的默认参数选项相同。所有实验均保持相同的参数设置,所加入的KL项中超参数均默认为1,模型的训练和测试均基于NVIDIA GeForce GTX 1080Ti GPU。关于数据后验筛选,本文基于Stanford(https:github.com/stanfordnlp/CoreNLP)提供的情感分析工具获取句子的情感倾向。
由于该方法涉及到源语言到目标语言和目标语言到源语言2个翻译方向的模型,因此实验表格将会同时报告这2个模型的实验结果。在所有实验中,使用BLEU作为翻译质量的评测指标,并使用multi-bleu.perl(https://github.com/mo-ses-smt/mosesdecoder/blob/master/scripts/ge-neric/multi-bleu.perl)脚本进行评测。
5.3 实验结果与分析
5.3.1 模型改进方法结果分析
表2中列出了在新闻领域 LDC 平行数据集上基准模型和本文改进模型的实验结果比较。“基准模型”是本文第3节所介绍的基础Transformer,使用LDC数据训练得到;“加入特征学习网络模型”是依据本文4.1节方法对基础模型进行了改进所训练的。对于每个测试集,中-英方向包含 4 个参考译文,英-中方向只有 1 个参考译文。
根据表2可知,在中-英和英-中2个方向上,翻译质量在各个测试集上均有不同程度的提升,中-英和英-中方向的平均BLEU分数分别提升了0.62和0.51,这表明增强源端和目标端的概率分布的一致性,学习语义中更通用抽象的特征有利于提高模型的泛化能力,改善翻译模型的性能。
5.3.2 数据后验筛选方法结果分析
为了验证本文提出的基于情感信息的数据后验筛选的有效性,在实验中与不使用情感后验筛选的方法进行对比。反向翻译方法已被证明是一种非常有效、稳定的数据增强策略,能够充分开发目标语言的单语语料。本文把反向翻译方法应用到领域适应中,并作为强基线来验证本文改进模型的有效性。在反向翻译的对内领域的伪平行数据和外领域的真实平行语料的拼接实验中,混合比例遵循文献[15]的结论,使用数据比例为1∶1的混合策略。实验结果如表3所示。
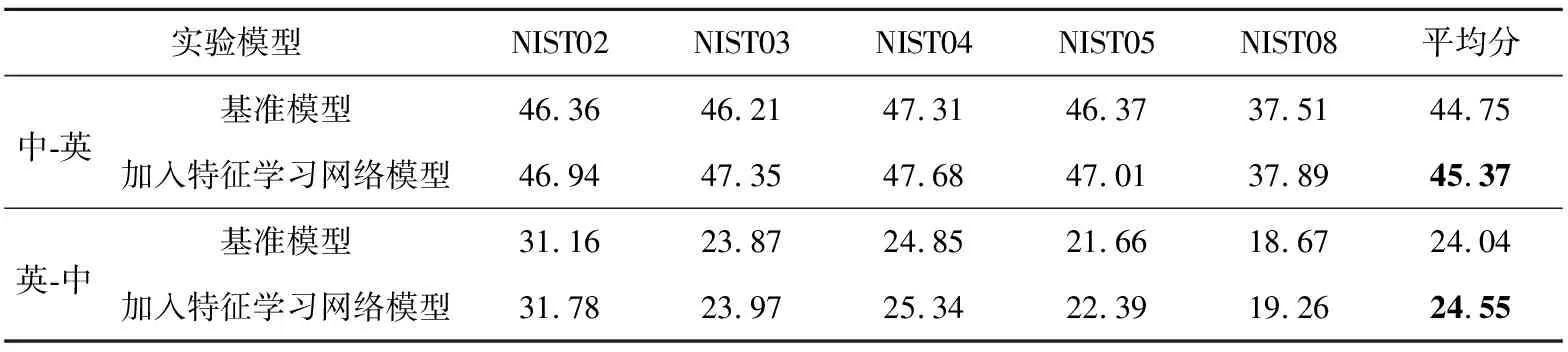
Table 2 BLEU scores of different models on LDC dataset
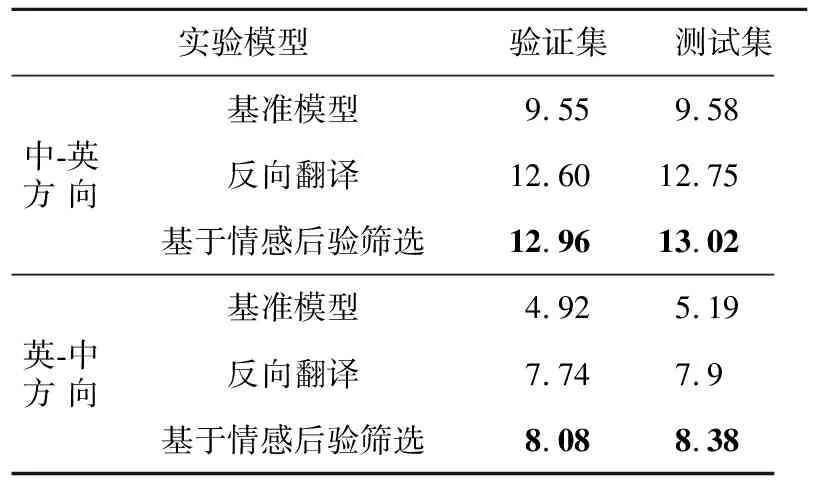
Table 3 Comparsion with other models in TED field
表3中,“基准模型”是使用外领域平行语料训练的基础Transformer模型,直接对内领域语料进行翻译;“反向翻译”是Sennrich等[15]提出的利用单语语料的方法,在基础模型上使用内领域伪平行语料进行微调,目标端是真实数据,源端是伪数据。
“基于情感后验筛选”是本文提出的方法。可以看出,使用情感后验筛选的确可以改善翻译模型的性能,在2个语言方向上都有一定程度的提升。相比未经过筛选的39万对训练数据,利用经过情感后验筛选得到的15万对训练数据进行训练的效果更好,这表明挖掘并利用语句的情感信息能够有效地去除伪数据中质量过差的翻译,从而降低噪声,帮助模型更好地训练。
5.3.3 综合策略实验结果分析
最后综合本文提出的以模型为中心和以数据为中心这2个方面的方法,与基础模型和其他模型进行实验对比,结果如表4所示。“基准预训练模型”即表3中的基准模型;“加入特征网络预训练模型”是使用本文提出的以模型为中心方法所改进训练的模型,也即表2 中加入特征网络学习的模型;“加入特征网络预训练+反向翻译”是在本文改进的模型基础上使用基础反向翻译的方法;“加入特征网络预训练+情感筛选”是按照算法1,将本文以模型为中心和以数据为中心的方法融合在一起。

Table 4 BLEU scores of different models in TED field
从表4中可以看出,加入了特征学习网络的预训练模型在中-英方向比基础模型的BLEU分数提高了1.32,在此基础上使用反向翻译的方法也比在基础模型上反向翻译的BLEU值提升了1.06。在模型改进的基础上,结合情感后验筛选,使模型不仅在预训练阶段获得了更好的泛化能力,同时在反向翻译中的伪数据质量也得到了进一步改善。
结合表3和表4可以看出,本文方法的最终效果比基线系统在中-英和英-中上BLEU值分别提升了4.42和4.09;与强基线反向翻译相比,BLEU值分别提升了1.25和 1.38。可见,本文方法相比于其他方法获得了较大的提升,有效地提高了模型领域自适应能力,改善了在目标领域的翻译性能。
5.4 案例研究
为了进一步证明本文方法的有效性,从内领域测试集的翻译结果中选择了一些案例,比较不同训练方法的模型所产生的翻译结果,如表5所示。

Table 5 Cases of translation results from TED test
从表5可以看出,基础模型对跨领域的翻译效果欠佳,其用词、语言风格与目标相差甚远,并且存在错翻、漏翻的情况。经过反向翻译后,可以看出,相比基础模型结果有所进步,但其效果仍不够理想。案例中的第1句,关于“对于彼此的认知”,本文方法翻译为“our perception of each other”,翻译准确无误且与参考译文完全相符。案例中的第2句,对于基础模型漏掉的“生存”,反向翻译译为“存活”且存在语序不当的问题,而本文方法可以有效地纠正这些错误,将“生存”准确地翻译出来了且语义合理。这表明使用本文方法更有益于提升翻译质量。
6 结束语
对于NMT任务中的领域适应任务,本文从以模型为中心和以数据为中心2个方面提出了简单而有效的无监督领域适应方法。通过更加合理地预训练策略来学习外领域数据更通用的文本特征表示,从而在增强模型的泛化力的同时提高了生成的伪平行数据质量,辅助后序工作更好地进行领域适应。再从数据方面,结合情感信息对数据进行后验筛选,进一步提高反向翻译译文的质量。实验结果表明,本文方法能够有效提升模型的泛化能力,改善跨领域的翻译质量。在未来的工作中,将进一步挖掘利用文本的情感信息和其他自然语言处理方法,探索更加复杂的联合方式,以进一步提升翻译模型在领域适应的效果。
