基于迁移学习和注意力机制的人脸表情识别
2022-12-22吕洪武
吕洪武
(长春工业大学 计算机科学与工程学院, 吉林 长春 130102)
0 引 言
人脸表情是表达人类情绪状态最直接,也是最常见、最自然的信号之一。近年来,由于计算机视觉领域相关技术的飞速发展,人脸表情识别技术在医疗辅助诊断、刑事侦测、在线教学评价等多个领域具有广泛的应用前景[1]。例如通过专注度表情识别,对学生课堂上课的专注度进行测评[2];应用于咽拭子采集机器人,对采集人进行表情识别,并进行情感交互[3];将表情识别嵌入驾校培训系统,根据学员的情绪状态智能调整培训程序,及时提供个性化学习方案[4]。
人脸表情识别主要分为图片采集和预处理、特征提取和表情分类三个步骤,其中特征提取是决定人脸表情识别效果的关键性部分。特征提取一般分为传统特征提取方法和基于深度学习的特征提取方法。
传统的特征提取方法如局部二值模式(LBP)[5]和Gabor变换[6]等,也有使用光流法[7]和多层感知机[8]的方法来进行人脸表情识别,均存在鲁棒性较弱和准确率较低等问题。因此,基于深度学习的人脸表情特征提取方法开始逐渐获得研究人员的关注。郭昕刚等[9]运用跨层连接方法改进神经网络;殷柯欣等[10]对基于图像重构和基于深度学习的预处理方法进行总结;An F等[11]提出一种结合长短期记忆网络的多层面部表情识别方法,用来缓解梯度消失和梯度爆炸问题;而近年出现的局部二值卷积神经网络[12]和二值集成神经网络[13]均对参数量化的方式进行了创新;也有将生成对抗网络[14-15]应用于人脸表情识别。但深度学习模型经常存在过拟合以及训练时间过长等问题。
针对上述问题,提出一种基于迁移学习和注意力机制的人脸表情识别网络模型,将注意力机制嵌入VGG16模型,减少模型全连接层参数数量,并使用迁移学习方法初始化网络权重,提高了模型训练效率和人脸表情识别准确度。
1 网络模型设计
1.1 整体网络模型
文中网络模型在VGG16最后一层卷积处添加了注意力机制,并将后续两层全连接层的节点数量进行缩减,分别由4 096个节点减少为512和256个节点。具体网络结构如图1所示。
其中,64@3×3、128@3×3和512@3×3分别表示每一个对应的卷积层都是由64个、128个和512个大小为3×3的卷积核组成,池化层使用的池化方法为最大池化。
1.2 注意力机制
由于每一个通道特征图均是由其对应的卷积核卷积而来,因此,不同通道学习到的特征对于最终表情分类的贡献度是不同的,通过注意力机制可以对每一个通道施加不同的权重,使得网络更加偏向于贡献度大的通道。注意力机制模块具体结构如图2所示。

图2 注意力机制
其中,MaxPool和AvgPool分别表示全局最大池化和全局平均池化,32和512表示两个全连接层的节点数量,Relu表示激活函数,1×1×512表示输出权重向量的大小。注意力机制公式为
Mc(F)=σ(MLP(AvgPool(F))+
MLP(MaxPool(F))),
(1)
式中:F----输入特征;
Mc(F)----输入特征经过注意力网络后的权重向量;
AvgPool,MaxPool----分别表示全局平均池化和最大池化;
MLP----通过两个参数共享的全连接层对池化后的特征进行提取;
σ----对经过全连接层后的特征向量通过Sigmoid函数进行归一化,具体公式为

(2)
式中:x----输入的权重向量。
1.3 丢弃层
由于目前人脸表情识别模型过拟合现象较为突出,丢弃层(Dropout)可以使节点随机失活,减少模型过拟合现象,因此在第一和第二个全连接层后添加丢弃层来增加模型的鲁棒性,具体公式为

(3)

(4)
y(l+1)=f(z(l+1)),
(5)
式中:y(l),y(l+1)----分别表示第l层和第l+1层特征;
r(l)----根据第l层特征依据设置概率产生的随机0,1向量;

w(l+1),b(l+1)----分别是第l+1层的权重参数和偏置项;
z(l+1)----未经过激活函数的第l+1层特征;
f(z(l+1))----将特征经过激活函数。
1.4 迁移学习
迁移学习是减少模型训练时间,提高模型鲁棒性的重要方法。其目的是让模型在其他领域训练以获得一定的先验知识(即获得权重参数)再来训练。迁移学习需要保持特征提取模型的卷积层结构不变,载入预训练的权重和参数,设计适用于新任务的全连接层,与原来的卷积层组成新网络模型,再用新数据集训练模型[16]。迁移学习后的模型可以冻结固定层,只训练没有冻结的层,或者全部网络均参加训练,文中将所有层都进行了训练。
2 实验及分析
为分析文中网络性能,选用RAF-DB数据集进行测试,测试环境为Windows10,GPU为NVIDIA GeForce RTX 3090,使用深度学习框架为Pytorch1.10,python3.7。批处理大小设置为128,使用SGD优化器,动量设置为0.9,学习率设置为0.01,每100轮变为原来的十分之一。
2.1 数据集预处理
RAF-DB数据集为真实世界下的人脸表情数据集,标记为7种基本表情,分别为惊讶、害怕、厌恶、快乐、悲伤、愤怒、自然。数据集共有29 672张图片,其中12 271张作为训练集,3 068张作为测试集。为了加强网络的鲁棒性,对数据集进行一定的预处理,将图片进行归一化处理,大小修改为224×224,进行随机水平翻转和角度转动,随机对图像进行部分擦除。
2.2 实验结果与分析
文中算法在RAF-DB数据集的准确率曲线如图3所示。

图3 准确率曲线
文中算法在RAF-DB数据集的损失函数曲线如图4所示。

图4 损失函数曲线
两图中,A表示训练集曲线,B表示测试集曲线。从图中可以看到,使用迁移学习后的模型在初始学习阶段准确率上升较快,且初始准确率已经较高,150轮左右已经接近训练完成,并在终段训练中有较好的稳定性,最终准确率可以达到86.05%。
文中算法在RAF-DB数据集测试集下的混淆矩阵如图5所示。
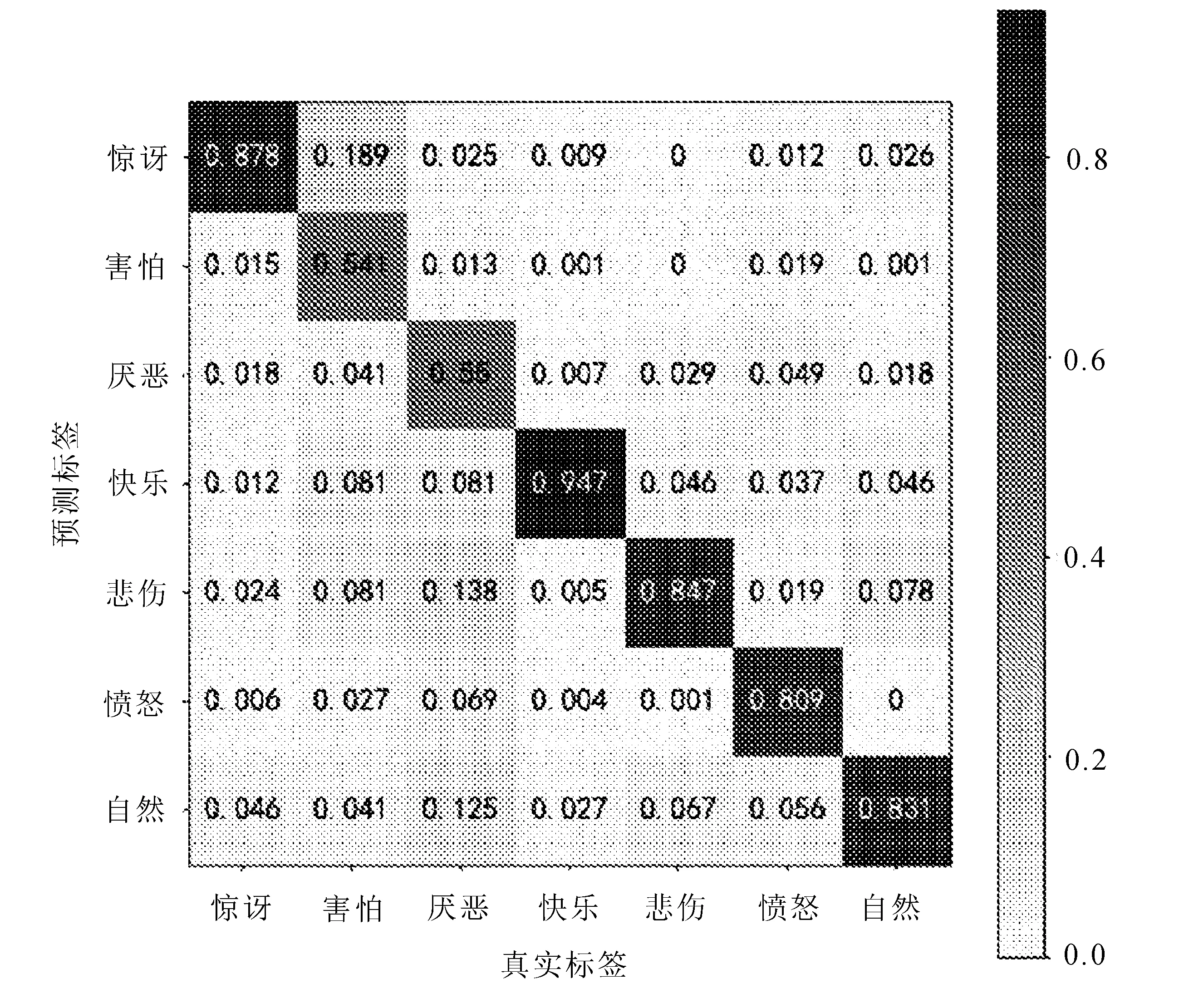
图5 混淆矩阵
从图中可以看出,快乐表情识别准确率最高,可以达到94.7%,害怕和厌恶表情识别率最低,分别只有54.1%和55.0%,惊讶表情识别率为87.8%,悲伤表情识别率为84.7%,愤怒表情识别率为80.9%,自然表情识别率为83.1%。
文中算法与其他算法在RAF-DB数据集上的准确率对比见表1。

表1 准确率对比
可以看到,文中算法比VGG16网络、ResNet18网络、ResNet34网络、Dens121网络的准确率分别高3.98%、3.87%、3.81%、3.14%,参数数量虽然高于其他网络结构,但远低于改进前的主干网络。
3 结 语
删减全连接层节点数,添加丢弃层并对数据集进行预处理,降低了模型的过拟合程度,添加了注意力机制,使得网络更加关注有用的通道特征,使用迁移学习初始化训练权重,缩减了网络训练时间。最终在RAF-DB数据集得到86.05%的准确率,证明了文中算法的有效性。
