基于YOLOv5s的施工人员安全防护设备佩戴检测研究
2022-12-21赵恩铭刘光宇朱晓亮
赵恩铭,杨 松,罗 创,刘光宇,朱晓亮
(1.大理大学工程学院,云南大理 671003;2.浙江工商大学信息与电子工程学院,杭州 310018)
目前我国正处在高速发展阶段,人们生活水平的提高与工业基础建设息息相关,工业建设无疑需要更多的施工人员。施工人员的工作环境通常较为复杂,具有很多潜在的安全隐患。在疫情期间施工,安全帽能有效抵御外来物体的撞击,一定程度上减少物体撞击的力度,口罩能够有效降低疫情传播的风险与施工作业时灰尘的吸入〔1〕。以人工的方式对施工人员进行监管耗时耗力,且长时间的监管可能会出现一定程度上的纰漏,因此采用深度学习技术辅助人工进行安全帽与口罩佩戴检测,实现安全防护自动化,对保障施工单位安全生产具有重要意义。
口罩与安全帽检测属于目标检测范畴,从2013年开始,随着图形处理器(graphics processing unit,GPU)和大数据的不断发展〔2〕,迎来了基于深度学习的目标检测时代。在深度学习中,摒弃了手工设计特征的方式,采用卷积神经网络(convolutional neural networks,CNN)〔3〕自主学习目标更深层次的特征,获得了更好的目标分类效果,此时典型目标检测算法有YOLO(You Only Look Once)系列〔4〕。截至目前,深度学习技术在安全帽与口罩的佩戴检测方面已经取得了许多的成功,但将深度学习应用在具体施工作业现场辅助人工进行实时安全帽、口罩佩戴检测的研究还比较少。为实现施工场所安全监管自动化,本研究首先采用基于YOLOv5s算法的施工人员安全帽、口罩佩戴检测方法,辅助监管人员进行施工安全保障,达到了保障施工人员生命安全的目的;其次完成算法在嵌入式平台Jetson Nano上的部署,方便设备在不同需求场合下进行安装;最后通过TensorRT技术有效提升算法在嵌入式平台上的检测帧率。
1 基础理论
1.1 YOLOv5s算法原理 本研究通过Netron工具进行YOLOv5s算法网络架构可视化,其结构见图1。按照算法的网络架构可以分为输入端(Input)、Back Bone、Neck和预测(Prediction)4个部分〔5〕,主要组成模块包含卷积层、池化层、BN层、激活层和全连接层。

图1 YOLOv5s结构
1.1.1 输入端 输入端主要进行以下数据处理:(1)采用Mosaic4数据增强方法,丰富了数据集场景,同时加强模型对小目标检测的能力;(2)添加自适应锚框计算,用来预测不同尺寸目标;(3)图像自适应缩放,在模型推理时使用图像自适应缩放减少图像空白区域色调填充量,提高目标推理效率〔6〕。
1.1.2 Back Bone模块与Neck模块Focus结构是YOLOv5算法的独有结构,会将图像进行切片,在保留原信息的情况下进行下采样,起到了减小尺寸、增加网络深度和降低计算量的作用〔7〕。
Neck部分主要由CSP2_X、FPN(feature pyramid networks)和PAN(path agreegation network)结构组合而成。FPN与PAN构成了双重特征金字塔结构〔8-9〕,加强网络对不同尺寸特征的检测。自上而下的特征金字塔是FPN结构的特色,通过上采样的方式将高层信息向下传递,进行特征融合。
1.1.3 输出端 预测部分主要包含激活函数、非极大抑制、优化器和损失函数的设置。YOLOv5s算法中间层和分类层的激活函数采用Leaky ReLU函数和Sigmoid函数,非极大抑制阶段采用DIOU_nms代替传统的NMS(non-maximum suppression)算法,优化器选择SGD(stochastic gradient descent),损失函数使用GIOU_Loss函数。
YOLOv5算法包含YOLOv5x、YOLOv5l、YOLOv5m、YOLOv5s 4个版本,各版本的区别是网络的深度和宽度依次递减,其不同算法的深度与宽度见表1。

表1 YOLOv5不同算法的网络结构
1.2 TensorRT加速算法原理TensorRT加速算法原理主要是利用层间融合与数据精度校准来实现,其默认精度为FP32。TensorRT首先会将没有用到的输出层删除,随后进行垂直优化与水平优化。在垂直优化阶段,将卷积层、激活层等经常使用的层合并为CBR(convolution,bias and ReLu);在水平优化阶段,原理与垂直优化相同,同层同时运行的架构则直接合并,在输出时做分割,输出到不同层去。本研究使用参数为:网络批次处理量设置为2,转换精度设置为FP16,类别总数设置为3,输入图像尺寸设置为640×640。
2 安全帽与口罩检测
2.1 总体结构 本研究包括数据集处理、检测模型的构建、嵌入式计算平台的搭建3个部分,总体结构见图2。数据集的质量对模型训练起到主导作用,本研究通过自建数据集获得更好的目标检测效果,并按照8∶2互斥拆分得到训练集和验证集。模型构建阶段用来构建安全帽、口罩佩戴检测算法,同时采用标签平滑训练技巧。嵌入式计算平台的搭建阶段方便设备在不同的地点进行部署,并同时采用TensorRT技术对模型进行优化,优化后的模型具有更高的目标检测帧率,能够更好地完成视频流检测任务。

图2 总体结构
2.2 硬件平台 嵌入式平台能够方便安全帽、口罩佩戴检测算法在多种实际场景下进行部署,具有成本低廉和实用性高等特点。硬件平台见图3,其中包含Jetson Nano开发板、免驱USB摄像头和7寸显示器各1个。安全帽、口罩佩戴检测算法在Jetson Nano开发板上部署,通过对摄像头采集的视频流进行目标检测,并将检测结果反馈在小型显示器上。

图3 硬件平台
2.3 数据集的构建 大量的数据样本能够帮助神经网络进行更好的训练,本研究使用人工拍摄和互联网下载等方式收集并筛选得到10 798张目标图像,包含佩戴安全帽、佩戴口罩和无安全防护设备佩戴情况。使用LabelImg工具对每张图像进行标签标定后,获得安全帽与口罩自建数据集,部分数据集可视化见图4。在本研究自建数据集中,安全帽防护类别共3 241张图像,占比为30.0%;口罩防护类别共3 217张图像,占比为29.8%;无安全防护类别共4 340张图像,占比为40.2%。

图4 部分数据集可视化
3 实证研究
3.1 实验条件Jetson Nano定制系统为Ubuntu 18.04,选择Python 3.6作为编译器,采用Pytorch框架。GPU为NVIDIA Maxwell,拥有128个CUDA(compute unified device architecture)核心,处理器为四核Cortex-A57 64位处理器,并采用TensorRT技术对算法进行优化。
3.2 评价方法 查准率用来描述数据集被预测为正样本数据中实际预测正确的数据量占比。查全率又被称为召回率,用来描述数据集所有正类别中被正确检测出来的比率。
查准率的表达式如下:
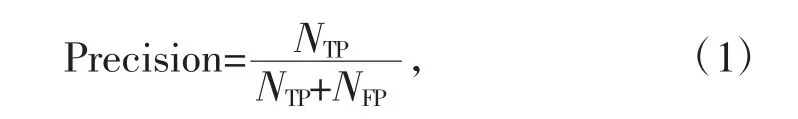
其中,NTP是被判定为正确的个数;NFP是被判定为错误的个数。
查全率一般指的是某类目标对应的识别率,其表达式为:

其中,NFN为漏检的个数。
平均精度(average precision,AP)属于综合类指标,它综合了查准率和查全率两项指标,是多分类模型中较为常用的评价指标。mAP为AP的平均值,表征一系列查全率下查准率的均值。
AP的表达式如下:
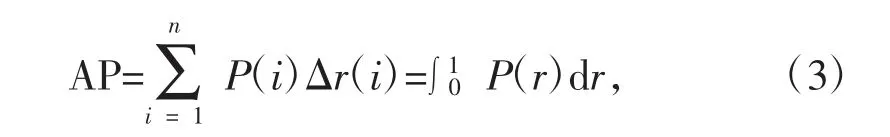
其中,P、r代表查准率和查全率。mAP的表达式如下:
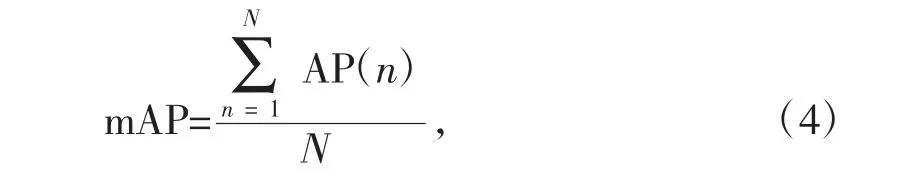
其中n表示类别,N表示实验总类别数。
F1分数的含义是查准率与查全率的调和平均值,其表达式为:
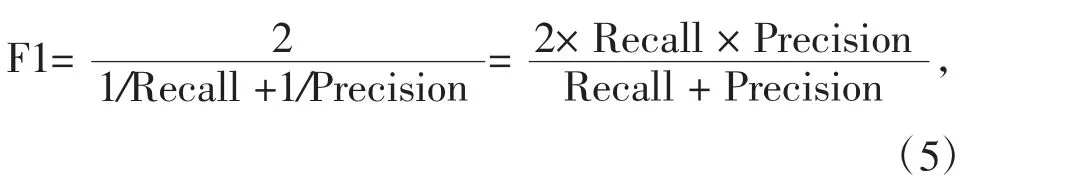
其中Precision、Recall分别表征查准率与查全率。
3.3 实验结果与分析 图5为模型的AP值和F1分数随置信度变化曲线,能够详细展示数据集中各类别的分类效果。图5(a)反映的是数据集中各类别的AP值和模型的mAP值,可以看出当交并比(intersection over union,IOU)被设置为0.5时,佩戴安全帽类别的AP值为0.950、佩戴口罩类别的AP值为0.922、无任何防护设备佩戴类别的AP值为0.967,模型的mAP值为0.946。图5(b)反映的是模型F1分数值与置信度的关系,当置信度被设置为0.426时,模型取得最高的F1分数值为0.92。综合上述指标可以得出,本次训练的模型能够很好地完成安全帽、口罩佩戴检测任务。

图5 数据集的AP值与F1分数
YOLOv5s算法使用TensorRT技术加速后在简单背景下对目标进行多组实验的检测效果见图6。转换得到的TensorRT模型采用FP16精度,置信度的值同样设置为0.426,其中数字0代表正确佩戴安全帽,数字1代表无任何防护设备佩戴,数字2代表正确佩戴口罩。可以看出TensorRT技术加速后算法在简单背景下的目标检测效果较好,包括将图6中左下角的遮挡目标图像检测出来,使用TensorRT技术加速后算法的检测帧率有大幅度提升,综合帧率为12.83 FPS,满足本次研究针对视频流实时检测需求。

图6 使用TensorRT技术加速后模型简单背景下检测效果
本研究进一步验证YOLOv5s算法使用TensorRT技术加速后在复杂背景下的检测效果,结果见图7。从图7可以看出,当目标处在非虚化背景中,算法依旧能够很好地检测出目标,检测帧率为12.08 FPS。当目标处在虚化背景中,可能会出现部分目标漏检的情况,根本原因是背景虚化严重识别难度较大且图像中出现的目标数过多,算法可能会出现部分漏检的情况。由于实际场景拍摄中的虚化情况并不多见,所以模型满足本研究对安全帽和口罩的检测需求。

图7 使用TensorRT加速后模型复杂背景下检测效果
表2为不同结构的YOLOv5算法在同一数据集上的识别效果,帧率为算法在Jetson Nano平台上测得的近似值。从表2中可以看出,YOLOv5x算法具有最高的mAP值为0.956,帧率为0.52 FPS,权重大小为175.1兆,不利于后续算法的实时信息读取。YOLOv5s算法mAP值为0.946,与其他算法非常接近,帧率为4.04 FPS,权重大小为13.8兆,算法的读取速度最快,更加适合本研究对目标检测算法实时性的需求。

表2 不同算法在同一数据集上的识别效果
4 结论
本研究基于YOLOv5s算法实现安全帽、口罩佩戴检测并采用标签平滑训练技巧。通过实验验证,YOLOv5s算法能够很好地满足安全帽、口罩佩戴检测任务,mAP值达到0.946,使用TensorRT技术能够有效提高算法在Jetson Nano上的检测帧率,将算法检测帧率从4.04 FPS提升至12.83 FPS,对实际应用中的安全保护检测具有重要意义。
