基于改进DeepLabv3+的快速烟雾图像分割方法
2022-12-21何俊康唐李文唐靖杰欧沛钦吴健辉
何 灿,何俊康,唐李文,唐靖杰,欧沛钦,吴健辉,赵 林
(湖南理工学院 a.信息科学与工程学院;b.机器视觉及人工智能研究中心,湖南 岳阳 414006)
在火灾发生早期,由于物体不完全燃烧产生的烟雾往往会先于明火出现,对烟雾进行检测并预警可以为火灾报警和灭火争取更多时间,极大降低火灾发生的可能性[1]。因此,烟雾检测一直是火灾预警中的重要研究内容,而烟雾图像分割作为精度最高、可以预估火灾扩散趋势和蔓延速度的烟雾检测方法具有很大的研究价值和意义。烟雾图像分割的实现有传统方法和深度学习方法2种。传统的烟雾图像分割主要是通过提取图像在不同颜色空间的颜色特征将烟雾目标从图像中分离出来[2]。Filonenko等[3]将烟雾的颜色特征与其外形特征结合来完成烟雾检测。Tian等[4]提出基于大气散射模型的方法将输入图像分割为烟雾前景和非烟雾背景。Lin等[5]使用卡尔曼滤波器对烟雾轮廓进行估计以完成基于无人机的大规模野火监测任务。但传统烟雾分割方法存在模型场景迁移能力差、手工特征选取复杂且需要一定的专业知识等弊端,研究人员开始利用深度学习算法去规避复杂的特征提取过程和提高烟雾分割的性能。
基于深度学习的烟雾图像分割实质上属于语义分割的范畴,这些方法的核心思想是对图像进行逐像素二分类。Li等[6]提出一种用于野火烟雾检测的3D并行全卷积网络来分割视频序列中的烟雾区域。Yuan等[7]提出双路全卷积网络用于烟雾的精细分割,2条不同深度残差网络组成的非对称编码-解码网络提取不同语义层次信息的特征图,特征图通过加法融合策略结合得到烟雾分割结果。
烟雾分割的作用是火灾预警,分割精度和速度是基本要求,然而上述烟雾图像分割方法均无法达到分割精度和速度的平衡。为此,本文提出一种端到端的基于改进DeepLabv3+[8]的快速烟雾图像分割方法,主要包括以下3个方面:1)骨架网络在语义分割模型中起到提取图像信息的作用,分割的速度和质量与其息息相关。本文使用实时语义分割网络(Short-Term Dense Concatenate Network,STDCNet)[9]取得较高准确率的同时大幅缩减网络推断所需的时间和计算消耗。2)针对空洞金字塔池化模块推理时间长且计算开销巨大的情况,本文提出改进空洞金字塔池化(Simplify-Atrous Spatial Pyramid Pooling,S-ASPP)模块,提高特征图语义信息利用率和烟雾特征的关联性,在减少计算量的前提下保持分割性能。3)针对烟雾图像分割存在的边界拟合粗糙问题,本文对底层特征使用边界监督模块来显式指导网络对于边界的学习,进而强化网络对边界的预测能力。
1 算法设计
本文算法主要由编码器的骨架网络STDCNet、边界监督模块、S-ASPP模块以及解码器部分运算组件构成,如图1所示。首先,骨架网络STDCNet对输入图像进行特征提取,在这个过程中边界监督模块对Layer2输出的特征进行监督以得到更好的边界特征提取并与Layer4的输出一起得到特征图F,之后特征图F输入到S-ASPP模块以增强烟雾特征的表达,最终经过解码器的上采样、1×1卷积等操作得到烟雾分割的结果。
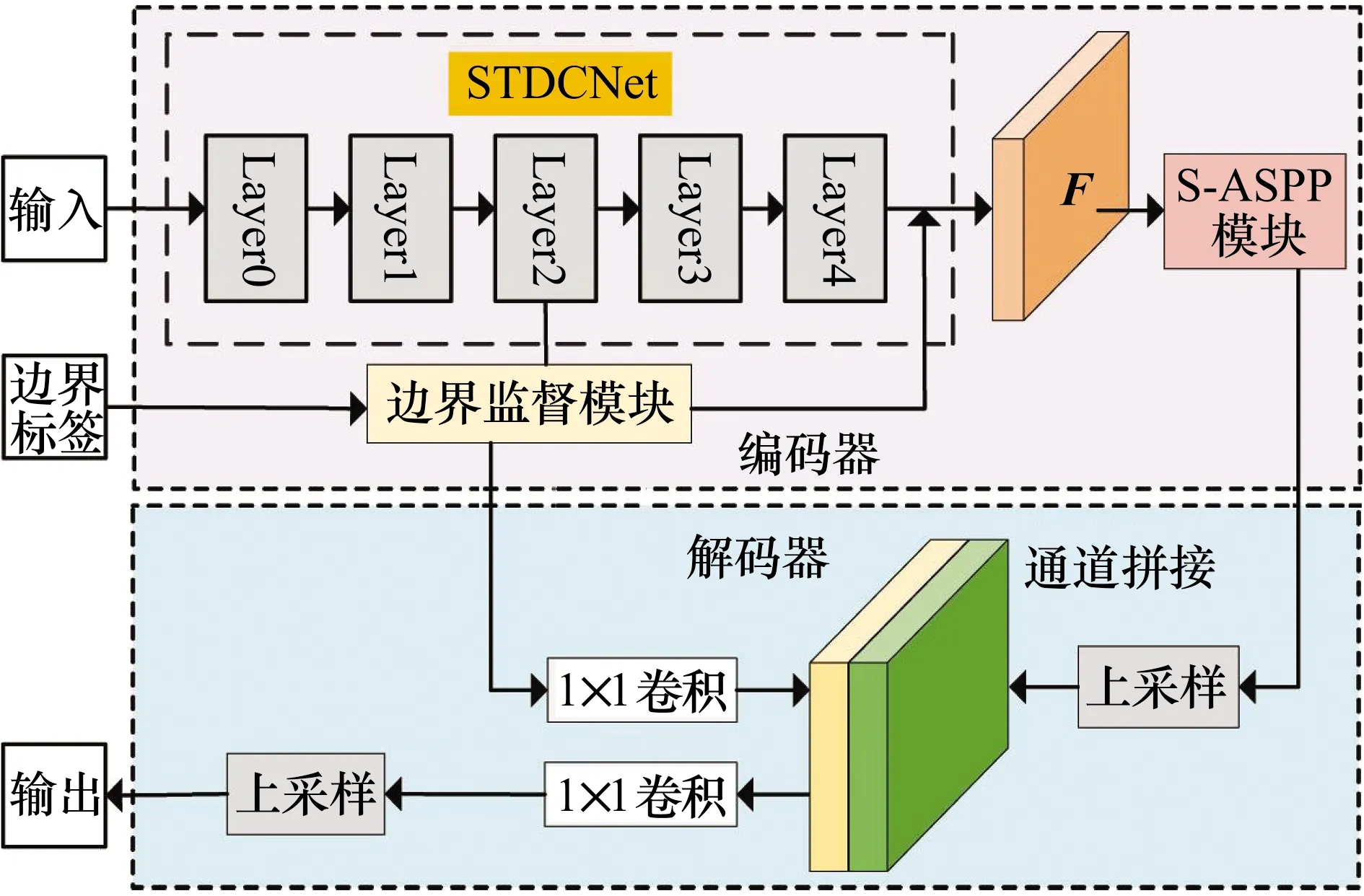
图1 改进的DeepLabv3+整体框图
1.1 骨架网络STDCNet
STDCNet是美团计算机视觉算法组在2021年提出来的兼顾速度和精度的骨架网络,整体结构类似于DenseNet,模型在ImageNet上面预训练并取得了相同计算量的最好综合性能,基于STDCNet的语义分割算法能在NVIDIA GTX 1080Ti显卡上对Cityscapes测试集测试取得76.8%的交并比的同时保持帧率为97.0 Hz。考虑到烟雾分割对速度和性能的需求,在对比分析了许多骨架网络之后选择了STDCNet作为改进DeepLabv3+的骨架网络。STDCNet主要由卷积层、STDC模块构成,图1中Layer0和Layer1为普通卷积层,Layer2、Layer3、Layer4则由多个STDC模块构成。
单个STDC模块如图2所示,主要包括3×3卷积、1×1卷积、步长为2的全局平均池化以及1个特征融合组件。STDC模块通过密集连接不同维度的特征图来提取具有可扩展感受野和多尺度信息的深层特征,并且模块简单、计算量小,实际应用效果相比于其他骨架网络更适合本研究需求。
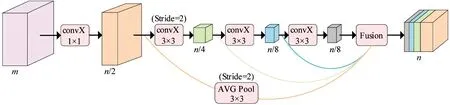
图2 STDC模块
1.2 S-ASPP模块
ASPP模块在DeepLabv3+中,通过设置不同采样率的并行空洞卷积对输入的特征图进行并行采样,进而起到不同感受野捕捉该输入的上下文语义信息的作用。虽然ASPP模块通过对高层语义信息的有效利用来提升语义分割的性能,但是它需要占用庞大的计算量和耗费相对多的推理时间。因此本文将S-ASPP模块用于快速烟雾图像分割,主要包括以下内容:
1)为提高信息利用率和特征图的关联性,将ASPP并行处理输入特征图的方式更替为串行加并行处理的方式。原ASPP模块通过对输入特征图用1×1卷积、不同采样率的空洞卷积、全局平均池化进行特征提取并拼接它们的结果以获得不同感受野的信息。ASPP设置空洞卷积的采样率分别为6,12,18会使得在同等计算量条件下信息量丢失、信息利用率低、特征图关联性差[10]。
本文模型仅使用采样率为6和12的空洞卷积,并把采样率为6的空洞卷积得到的特征图在原来网络结构的基础上与其他特征图串联拼接取得更好的信息利用率和特征图的关联性。实验结果表明,本方法可以增强不同感受野信息的关联,提高烟雾分割性能。
2)在网络模型中,卷积核的个数很大程度影响着模型的计算量和模型大小。通过实验对比发现,将ASPP并行空洞卷积的卷积核个数由256降低为128几乎不会影响本文模型的分割性能,却可以降低模型大小和推理时间的消耗,因此改进的S-ASPP模块设置卷积核个数为128。
综上所述,得到S-ASPP模块如图3所示,特征图F作为S-ASPP模块4个并行支路的共同输入,4支路的输出再通过通道拼接操作以及1个降低特征图维度的1×1卷积得到F′。
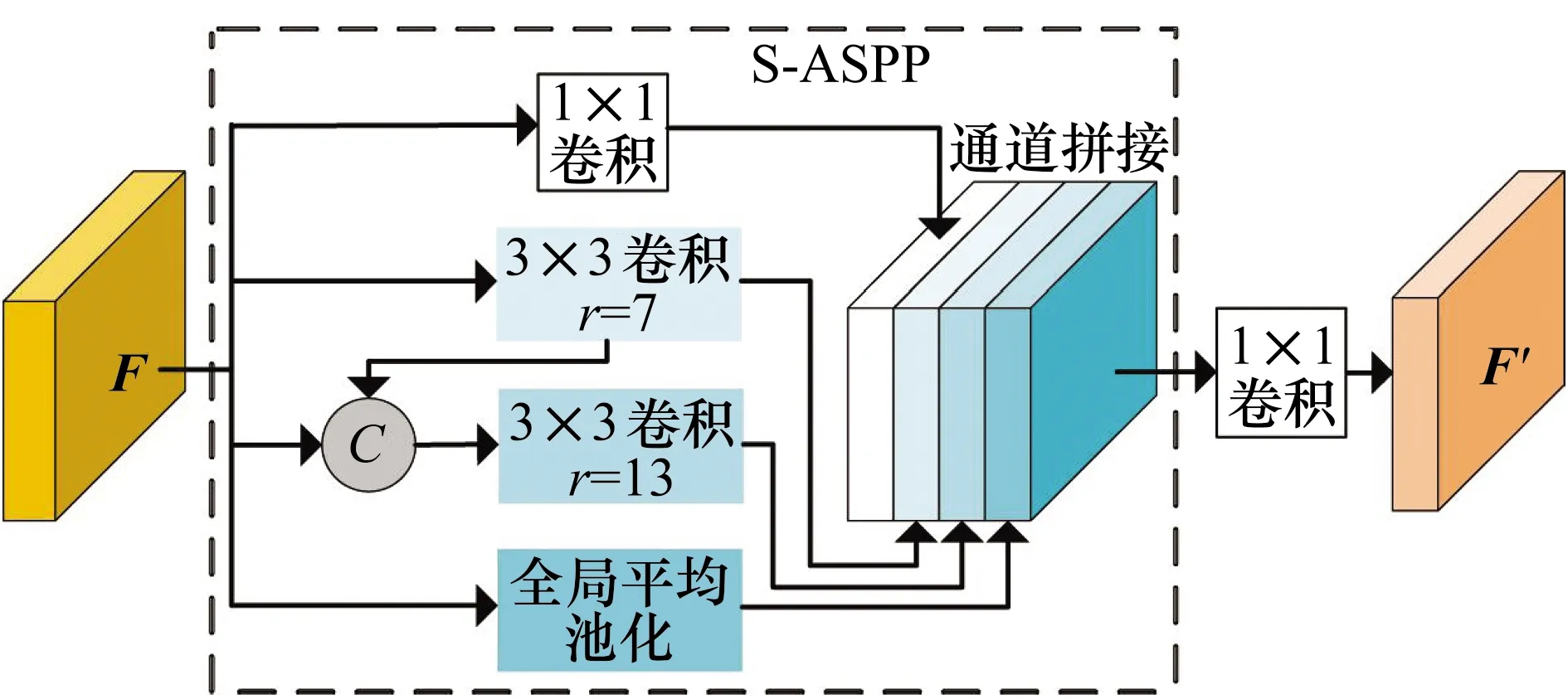
图3 S-ASPP模块
1.3 边界监督模块
在语义分割任务中,额外对边界进行监督和训练在很多文献中已经提到并且证明了其有效性[11-13]。结合卷积神经网络特征提取时的特点,即浅层特征图包含原图像低级语义信息,也就是轮廓、边缘,高层特征图包含图像的高级语义信息,也就是物体的整体信息[14],本文对模型最终输出进行监督的基础上也对浅层特征通过边界监督模块监督,即对骨架网络STDCNet的Layer2的输出构造损失函数进行监督。本文的边界监督模块如图4所示。
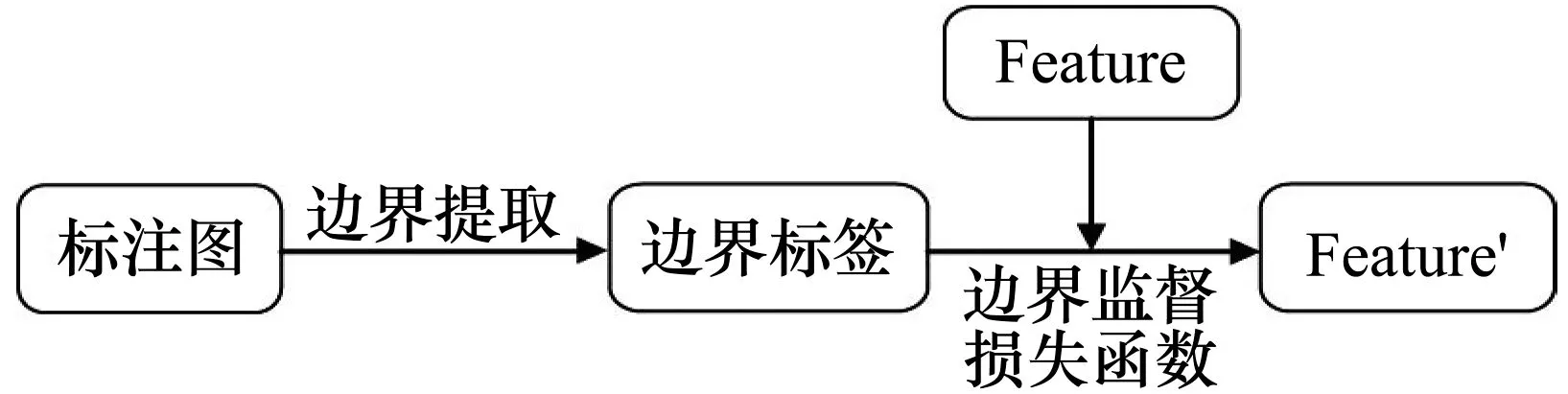
图4 边界监督模块
边界监督模块中损失函数主要由2部分构成,如式(1)和式(2)所示,式(1)实质上是医学图像分割常用的对前景、背景像素数量差异不敏感的dice loss[15],式(2)则是二分类交叉熵损失,此外,式(2)也作为网络整体损失监督网络学习。相比于非边界像素而言,边界像素数量少很多,如果仅使用二分类交叉熵损失去训练的话无法得到精细的边界预测,而添加dice loss可以很好地处理边界、非边界类间不平衡的问题,因此本文将2种损失联合起来使用,以达到更好的分割结果。
(1)
(2)
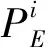
2 实验结果分析
2.1 实验环境设置
本文模型基于Pytorch实现。实验过程采用Apex-Distributed Data parallel的训练方式对模型进行训练,即采用4块显存为11 GB的NVIDIA GTX 2080Ti来并行分发数据和模型,并且做到协调训练。训练的循环次数设置为300,动量为0.9,权重衰减为0.000 1,学习率采用Poly策略,初始学习率设置为0.01,训练随着迭代次数增加而逐渐衰减学习率,采用随机梯度下降法(Stochastic Gradient Descent,SGD)训练模型,batch_size设置为8,但由于4块GPU进行并行训练,实质上每次放入32张图像对网络模型进行训练并更新参数。
2.2 数据集
本文所用的数据集取自公开数据集[7],分为训练集、验证集、测试集3部分,训练集为4 800张图像,验证集为415张图像,测试集为1 000张图像,图像的大小均为256×256,图像对应的样本标签是由纯烟雾图像二值化处理得到的大小同为256×256的图像。对参与训练的图像采用水平翻转、颜色抖动、随机缩放、张量化、归一化等数据预处理操作,部分训练集图像和预处理之后的图像如图5所示,其中第1、2列为原始数据集的图像及其标签,第3、4列为预处理之后的图像及其标签,第5列为由预处理之后的标签得到的二值边界图,该边界通过Canny边缘检测算法得到。

输入 标签 预处理输入 预处理标签 预处理边界
2.3 定量评估指标与定量评估
本文采用交并比(Intersection over Union,IoU)、模型的参数量(Params)、帧率3个评估指标来衡量模型的性能、大小和速度。
IoU是语义分割领域衡量算法分割效果的重要指标,它计算目标类别的交并比,计算公式为:
(3)
式中:k为语义类别的数量,在本文中k取1;i为像素点的真实值;j为网络的预测像素值;Pij表示将类别i错误地预测为类别j的像素数量;pji以及pii的含义以此类推。
模型的参数量P反映模型的空间复杂度,即占用显存大小。由于本文提出的模型为全卷积模型,因此所有卷积层参数量的和即为模型参数量。单个卷积层参数量计算公式为:
P=(kω×kh×Cin)×Cout+Cout。
(4)
帧率是模型每秒完成推理的图像数量,它反映的是用训练得到的模型去做推理预测的速度,计算方式为测试图像数除以测试时间。
设基于含空洞卷积的ResNet50的基础DeepLabv3+模型为A,以STDCNet为骨架网络的DeepLabv3+模型为B,STDCNet和S-ASPP模块同时存在的DeepLabv3+模型为C,STDCNet、S-ASPP模块以及边界监督模块共同作用的DeepLabv3+模型为D,4种模型的烟雾分割量化结果对比如表1所示。
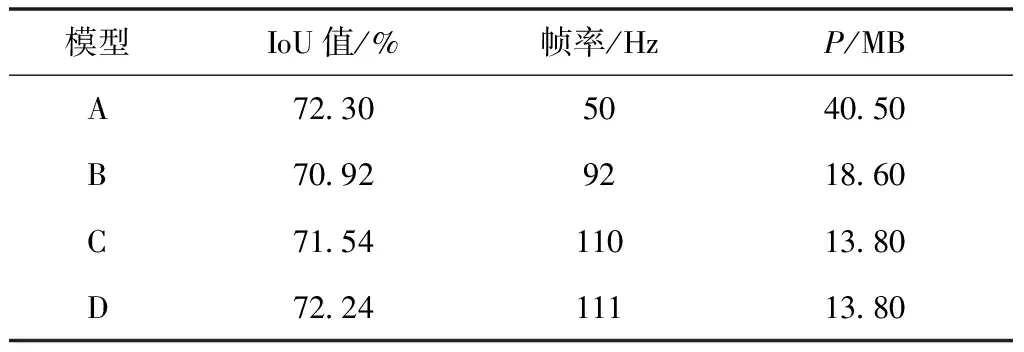
表1 测试集分割结果对比
由表1可知,本文算法保持分割性能的前提下极大地提高了模型推理速度和减小了模型大小。对比模型A、B的实验结果可知,参数量为40.50 MB的模型A在测试集上以50 Hz的帧率取得IoU值为72.30的结果,虽然将骨架网络换为STDCNet之后分割精度降低了1.38%,但是模型B的测试速度快了184%,模型参数量减少45.93%,说明STDCNet比ResNet特征提取的效果变差而提取的速度以及占用的计算资源要小得多;对比模型B、C的实验结果可知,虽然降低了一点模型分割性能,但模型 C 减少了更多的计算量和推理时间,同时也反映了 ASPP 与 S-ASPP 的性能差异;对比模型C、D的实验结果可知,边界监督模块可以提高模型0.76%的精度。
2.4 定性分析
为验证本文方法的有效性和模型性能,采用定性可视化的方式对改进的网络模型以及一些经典语义分割模型进行分析,测试用的图像与定量评估所用一致,仅经过图像张量化、标准化处理,分割结果如图6所示,其中第1列为输入的测试图像,第2列为标注图,第3~6列分别为DSS[7]、LinkNet[16]、DeepLabv3+算法以及本文算法的烟雾分割结果。

(a) (b) (c) (d) (e) (f)
为更简洁明了地对不同分割算法的结果进行对比分析,在图6中用红色方框大致标出过分割的情况,用蓝色方框大致标出欠分割的情况。第1,2,4,5行的图像背景相对简单,4种分割算法都取得了较好的分割效果。第1行,4种算法都存在小部分区域欠分割;第2行,4种算法也都存在较小部分的过分割或者欠分割的情况;第4行,DSS算法有较大面积的欠分割的情况;第5行,仅LinkNet算法出现了较大面积过分割的情况。而由于图像背景相对复杂,干扰分割的因素较多,第3、6行分割结果则相对较差。在第3行,DSS算法、DeepLabv3+算法都存在较大面积的欠分割的情况,本文算法虽然也存在部分错分割,但分割结果的总体轮廓与标签很接近。在第6行,4种算法都出现较严重的错误分割,但本文算法取得了最好的分割结果,错误分割面积最小并且绝大部分轮廓正确分割。总的来说,本文算法对不同复杂程度背景下的图像都可以较好地对烟雾进行分割。与DeepLabv3+算法相比,本文算法取得了近似的分割结果甚至避免了部分明显的错误分割,并且烟雾分割结果的轮廓更为平滑,说明底层加入的边界监督模块可以起到边界注意的作用。
3 结论
在本文模型中,替换骨架网络为STDCNet以提高推理速度和减少模型参数量,提出S-ASPP模块以起到增强特征利用的同时减少计算开销的作用,使用边界监督模块引导模型对边界的预测。在测试集上进行的实验结果表明,本文模型的烟雾IoU值为71.54%,与基于含空洞卷积的ResNet50的DeepLabv3+基本持平,但本文模型所占用的计算资源仅为其34.07%,推理速度也比其快220%,可以用极快的速度和相对高的精度完成烟雾图像分割,具有一定的研究意义和应用价值。
