基于系统调用和数据溯源的PDF文档检测模型
2022-12-18雷靖玮
雷靖玮,伊 鹏,陈 祥,王 亮,毛 明
(中国人民解放军战略支援部队信息工程大学,郑州 450001)
0 引言
长期以来,安全人员倾向于认为相比电子邮件和网络链接,PDF 文档作为静态文件难以更改,对围绕其展开的各类攻击疏于防范。事实上,随着时间推移,PDF 规范已产生巨大变化,新增的PDF 脚本功能使其可像可执行文件一样用于开展网络活动、或与其他文件或程序进行交互等,从而给攻击者预留了更多可利用空间,攻击者可以更加方便地将恶意负载隐藏为图像、字体和Flash 内容。与此同时,PDF 规范的变化也增加了与其相适应的文档解释器的复杂性,变相导致各种漏洞的产生。仅Adobe Acrobat Reader(AAR)就在2015年、2016 年相继发布了137 和227 个通用漏洞披露(Common Vulnerabilities and Exposures,CVE)漏 洞。图1 为Adobe Reader 中典型的CVE-2010-2883 漏洞的利用示意图。
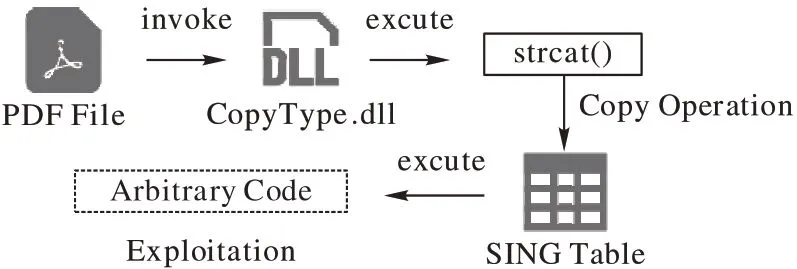
图1 CVE-2010-2883漏洞利用示意图Fig.1 Schematic diagram of exploiting CVE-2010-2883 vulnerability
Adobe Reader 的CopyType.dll 文件中strcat 函数未检查参数src 是否会超过est 定义的数组长度,由此形成栈溢出漏洞。目前遭曝光的Adobe 产品漏洞大多可造成较严重的危害,如任意代码执行和内存泄漏等。
表1 给出了近年来AAR 被曝光的一些典型漏洞信息。AAR 除本身存在大量漏洞易被攻击者利用外,还是目前使用率非常高的PDF 文档解释器,因此已成为攻击者的首要目标之一[1]。根据近年来的数据统计,它受攻击者青睐程度仅次于浏览器和操作系统内核,必须承认,当前恶意文档检测形势严峻。近年来研究者已提出多种解决方案用于检测文档携带的恶意负载,这些技术大致可分为静态分析与动态分析两类。静态分析,即基于签名的检测[2-9]主要是静态解析文档并搜索恶意负载标志,如是否存在恶意代码或与已知恶意软件相似性是否超过阈值。动态分析,即基于执行[10-11]的检测技术,通过运行部分或整个文档寻找可能的恶意行为,如是否存在易受攻击的应用程序编程接口(Application Programming Interface,API)调用或返 回导向编程(Return Oriented Programming,ROP)。Carmony 等[12]的研究表明,这些解决方案中使用的PDF 解析工具可能在设计时过度简化了PDF 规范,即未能充分考虑目前PDF 规范的复杂性,可能导致恶意负载提取不完整或分析失败。另有研究[13-15]表明,基于机器学习的检测可能会被遵照某种规则设计的行为成功规避。此外,许多解决方案只关注PDF 文档中的JavaScript 部分,而忽略了其与其他PDF 组件在发起攻击时的协同作用。部分方案则采用类似于黑名单的方式,即使用已知的恶意行为模式对JavaScript 脚本进行匹配,泛化性较弱,即使是对已知恶意模式进行细微修改都可能逃避检测,更无法有效应对0day 攻击等威胁。
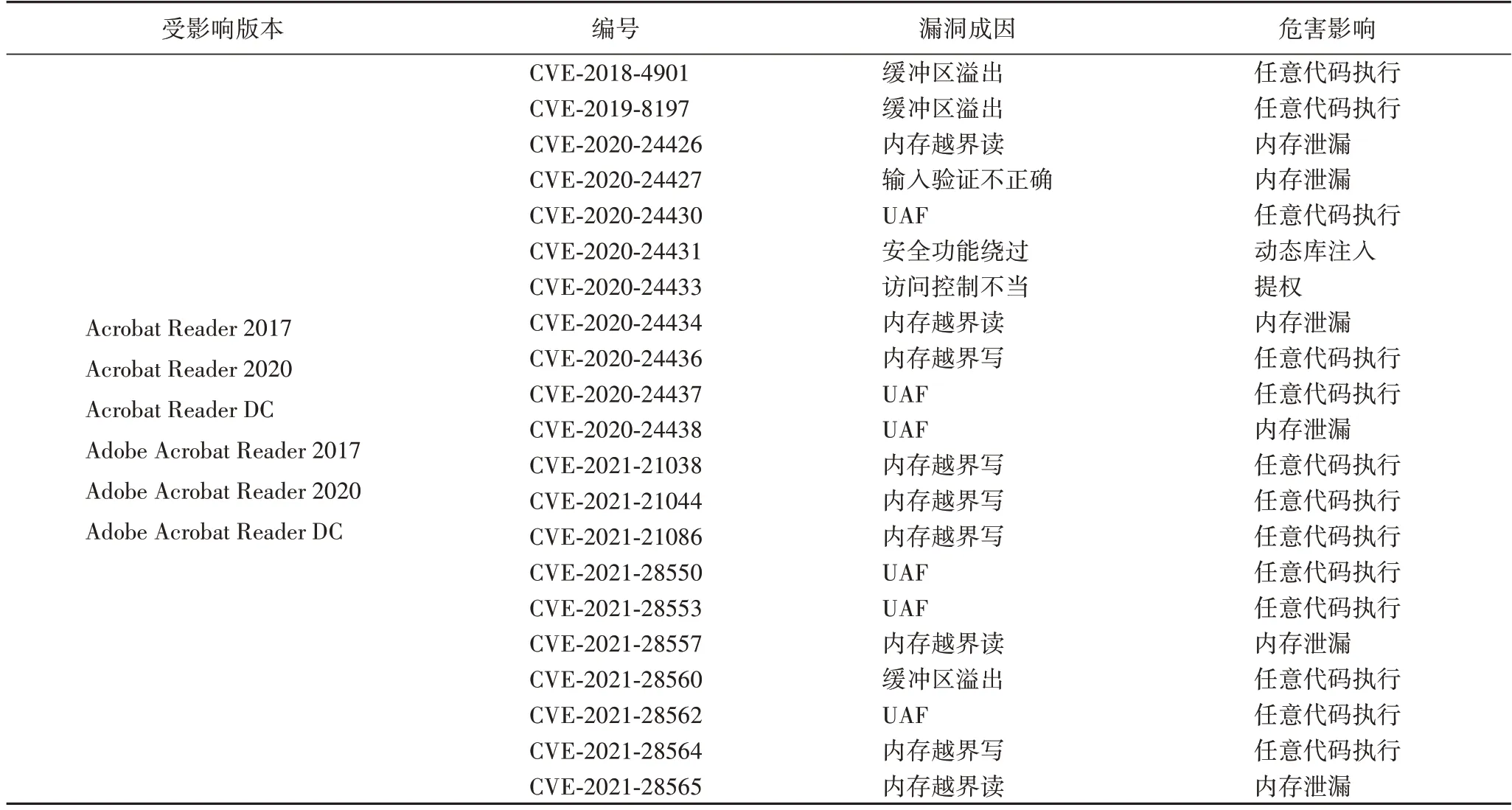
表1 近年AAR漏洞信息列表Tab.1 List of AAR vulnerabilities in recent years
本文提出了一种恶意文档的检测模型NtProvenancer。不同于以往的静态检测和动态检测,该模型未以JavaScript脚本或PDF 元数据作为重点研究对象,而是借鉴基于系统调用的主机异常检测技术,并以数据溯源思想构建系统调用级的数据溯源图,利用溯源图结构特征提取特征序列,而后将它与良性特征库中调用片段进行比对以完成检测。该模型设计主要基于以下的观点:
1)针对恶意软件攻击的异常检测也应能够对目前新规范下的PDF 文档进行检测。
2)数据溯源图的结构特征可用于提取系统调用序列中的特征部分。
对于观点1),可利用系统调用追踪工具生成系统调用日志,并利用调用数据构建检测模型进行检测,通过模型最终的检测结果验证其可行性;对于观点2),可在建立系统调用级的数据溯源图的基础上对提取出的特征序列进行分析和验证。事实上,要使模型真正发挥作用,需要解决两个关键问题:一是怎样有效提取特征,文档运行时产生的系统调用数据量过于巨大,并且恶意行为所对应的系统调用往往仅占其中一小部分;二是怎样进行特征部分的提取和比较,以检测文档的恶意负载。需注意,本文模型与当前恶意软件分析工具有本质区别:一是当前分析工具主要采用黑白名单的方法进行检测,黑名单方法适用于检测已知的恶意行为,但难以应对利用0day 漏洞的PDF 攻击,白名单方法则可能导致较高的误报率;二是本文模型基于攻击者无法修改或删除系统调用数据的客观事实,因此这部分数据可为PDF 文档检测提供可靠信息。实验过程使用394 个良性样本进行特征提取,相关样本覆盖了PDF 规范中的各种特征,然后使用134 个良性测试样本进行评估,产生7 例误报;而对于320 个恶意样本,模型能够实现正确检测。
本文主要工作为:使用基于系统调用的异常检测技术,结合数据溯源思想,提出了新的特征提取算法,并且以较低的性能开销完成文档检测。评估证明,NtProvenancer 有着较低的误报率和漏报率,能够有效检测出恶意文档中的行为异常。
1 恶意文档检测相关工作
目前常见的恶意文档检测方法主要是静态分析检测和动态分析检测,本章将围绕这两种检测方案介绍目前常见的一些检测手段与不足之处,同时陈述本文的写作动机。
1.1 静态检测方案
静态分析检测大致可以分为两类。
第一类注重分析PDF 文档中的JavaScript 脚本,原因有二:首先,JavaScript 能够完成许多PDF 高级功能;其次,根据文献[11],超过90%的恶意文档使用JavaScript 完成攻击。PJScan 分析器[3]从词法编码风格出发,利用变量名、括号和运算符的数量来区分良性和恶意的JavaScript 代码。Lux0r[2]分别构建了在良性和恶意文档的API 引用模式,并使用这些模式对恶意文档进行分类。MPScan 分析器[4]与其他JavaScript 静态分析器有着显著不同,它关联AAR 并动态提取JavaScript 代码;然而,因为其代码分析仍然是静态执行的,仍将它视为一种静态分析技术。以上所有方法的一个共同缺点是可以通过大量混淆技术和动态代码加载来规避检测(除了MPScan 分析器[4],因为它在运行时与AAR 进行关联),因为静态解析器根据预定义的规则提取JavaScript,攻击者可以利用这些规则决定JavaScript 代码可以放置或隐藏的位置。鉴于PDF 规范的灵活性,能否成功隐藏代码实际上取决于攻击者的创造力。文献[16-17]中提出了针对JavaScript 代码的反混淆检测方法,但这种方法还需手工才能完成,没有实现自动化检测,并且存在着误报率较高的问题。
另一类检测则是侧重于检查PDF 文件的元数据,而不是其实际内容。这是因为混淆技术倾向于恶意利用PDF 规范的灵活性,并通过改变正常的PDF 结构来隐藏恶意代码。PDF Malware Slayer[5]使用特定PDF 元素(例如,/JS,/Page 等)的线性 化路径 来构建 恶意文 档分类 器。Šrndić 等[9]和Maiorca 等[13]更进一步,也使用分级结构进行分类。PDFrate[8]则囊括了另一组检测指标,如字体数量、流的平均长度等,以提高检测能力。Liu 等[7]利用文件的熵序列并结合机器学习进行文档检测。Maiorca 等[6]则同时利用JavaScript 代码和PDF 元数据,将上述许多启发式方法融合到一个检测过程中,以提高文档检测的规避难度。
1.2 动态检测方案
大多数的动态分析技术只关注嵌入的JavaScript 代码,而不是整个文档。MDScan[11]在定制的SpiderMonkey 解释器上执行提取的JavaScript 代码,解释器在其内存空间上不断扫描已知形式的恶意代码或恶意操作码序列。Jiang 等[18]提出了一种新型字典检测模型NFDD,该模型引入一种基于词嵌入的神经网络,同时与动态分析技术相结合。ShellOS[10]是一个轻量级操作系统,旨在运行JavaScript 代码并记录其内存访问模式。在执行过程中,如果内存访问序列匹配已知的恶意模式(例如返回导向编程(Return-oriented Programming,ROP)、关键系统调用或函数调用等),则该脚本被视为恶意的。虽然这些技术检测恶意负载较为准确,但其共性问题在于脚本环境不兼容。此外,恶意负载可以被编码为文档中的字体或图像等对象[19],既不会被提取也不会被检测到。文献[20]中提出了一种基于JavaScript 的动态污点跟踪技术,但此技术建立在能够获取源代码的基础上,获取难度较大。某些攻击还可能利用内存布局知识,例如在AAR 及其相关库中存在某些函数和ROP gadget 工具,这部分情况很难通过外部手段进行模拟和分析。Liu 等[21]没有模拟JavaScript 执行环境,而是用上下文监控代码来检测PDF 文档,并使用AAR 自己的执行环境来执行JavaScript 代码,因此不受兼容性问题的影响;然而,该方法只会监控较为常见且已知的恶意行为模式,如网络访问、堆喷和动态链接库(Dynamic Link Library,DLL)注入等,这些模式不是完全通用的,当出现新的反恶意代码检测手段时,必须对检测模型进行扩展。
1.3 写作动机
鉴于以上两类检测方法的不足,试图找到满足以下三点要求的检测方法。
1)能够在不需要恶意行为的先验知识的基础上有效应对未知攻击。
2)使用不依赖于机器学习的检测方法。
3)对恶意文档检测技术进行进一步补充,提高攻击者的攻击难度。
本文提出了一种新的解决策略,即利用主机异常检测中的检测技术对恶意文档进行检测。目前来说,主机异常检测的一个热点研究方向是利用系统调用数据进行检测。系统调用数据之所以会是主机异常检测研究的重点选择,是因为它是操作系统内核级活动的主要产物。换言之,系统调用数据是没有经过过滤、解释或处理的,攻击者无法进行修改或删除等操作,由此可确保所收集数据的完整性。通常来说,基于系统调用的检测方法有不同的研究方向,包括利用系统调用的顺序特征、频率特征等进行建模从而完成异常检测。本文试图在保证检测的准确性同时尽量降低检测的性能开销,综合利用系统调用的顺序和频率特征。另外,鉴于依靠机器学习的检测可能会被攻击者按某些规则进行规避[13-15],且检测开销巨大,所以本文使用不依赖于机器学习的检测方法。
根据以上需求,受Wang 等[22]研究的启发,本文提出了NtProvenancer 模型。该模型使用了基于系统调用的异常检测技术。文献[22]中,数据溯源图是用于表示进程间交互行为的一种有向图,目的是检测隐藏的恶意软件攻击。NtProvenancer 模型将此溯源图的结构用于内核级的系统调用,用于描述系统调用间的行为特征,以检测恶意文档的攻击行为。
2 本文模型设计与问题陈述
本章主要介绍本文模型的有关定义及设计思路。
2.1 模型基本假设
首先,本文模型利用文档执行时产生的系统调用进行恶意文档检测,故不考虑使用隐式流(侧信道)执行的攻击手段。这类攻击绕过了系统调用接口,无法被系统调用追踪工具捕获进而生成有效的系统调用日志。
此外,由于本文检测模型需要部署在主机上,实验中认定执行PDF 程序的Adobe Reader 以及收集系统调用信息NtTracer 均为良性且可信的,且攻击者无法对系统调用日志进行操作,收集的系统调用数据具备良好的完整性。
2.2 相关定义
2.2.1 系统调用
系统调用v∈A,其中A是系统调用的集合。
2.2.2 调用事件
调用事件e=(src,dst,time)是由源调用号(src)、目的调用号(dst)、目的调用产生时间(time)所组成的三元组,并且src,dst∈A,源调用及目的调用用于表明相邻两个系统调用的前后文关系,time则记录此次事件的时间。需要注意的是,由于系统调用可能会出现重复情况,源、目的调用所组成的二元组也会产生大量重复,故需加入时间属性对不同事件进行区分。
2.2.3 线程调用序列
对系统调用日志中的数据按照线程进行划分,提取各线程相对应的系统调用序列。对于某线程,其线程调用序列l=(v1,v2,…,vn),其中vi表示该线程的第i个系统调用;并且l∈T_Entity_Seq,其中T_Entity_Seq表示l所属文档下各线程调用序列的集合。
2.2.4 线程事件序列
线程调用序列中,相邻两系统调用间的调用事件组成线程事件序列。对于某线程调用序列l=(v1,v2,…,vn),其对应线程事 件序列H=(e1,2,e2,3,…,en,n+1),其中ei,i+1=表示由vi,vi+1以及vi+1所发生的时刻组成的调用事件;并且H∈T_Event_Seq,其中T_Event_Seq表示H所属文档下各线程事件序列的集合。
2.2.5 调用溯源图
在Wang 等[22]的溯源模型PROVDETECTOR 中,溯源数据以溯源图的形式用以标识不同进程间的交互信息,通过分析进程与交互信息组成的序列以完成检测。受此启发,针对每一个需要分析的PDF 样本生成其相应的系统调用溯源图。对于某个样本p,其对应的调用溯源图定义为其中V={v1,v2,…,vm}是系统调用的集合,E={e1,e2,…,em}是调用事件的集合。对于调用溯源图而言,V表示图中节点的集合,集合E表示图中有向边的集合。
2.2.6 特征序列
根据溯源图结构特征,结合特征提取算法从某线程调用序列l中提取出特征序列{SpSeq1,SpSeq2,…,SpSeqn},对于任意特征序列SpSeqi均有SpSeqi⊆l。特征序列在训练阶段用以构造良性特征库,在检测阶段用以完成文档检测。
2.3 问题陈述
结合以上定义,本文将对文档的检测转化为对其相应调用溯源图的检测,即检测文档p所对应的溯源图G(p)是否包含恶意特征序列。为便于后文论述,本文将不含恶意特征序列的调用溯源图称为良性溯源图,把包含恶意特征序列的调用溯源图称为恶意溯源图。
2.4 模型设计
本文模型如图2 所示,主要包含3 个部分。
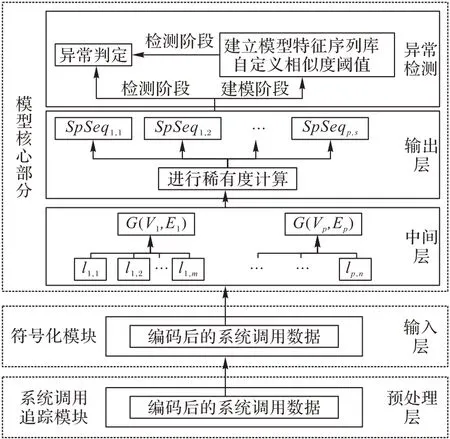
图2 本文检测模型架构Fig.2 Framework of the proposed detection model
1)系统调用追踪模块:完成系统调用的追踪与收集工作。包括收集系统调用名称、产生时间以及对应的线程号等信息。
2)符号化模块:负责将收集的系统调用数据进行符号化处理。这一步主要是便于核心部分进行溯源图构造与特征片段提取等处理工作。
3)模型核心部分:将符号化的系统调用数据进行溯源图的构造和特征片段提取,并完成良性特征库的构造与异常检测。
3 模型介绍
3.1 模型概要
本文模型的特征如下:
1)采用基于异常检测的技术,即只学习良性样本特征。
2)利用调用溯源图中的特征序列进行检测。
分别解释对模型进行以上设计的原因:首先,本文模型基于异常检测技术,通过收集良性文档执行时的系统调用特征构建特征库,能较为有效地应对利用未知技术的恶意文档攻击。其次,仅使用溯源图中的特征序列完成检测,这是因为恶意文档在执行过程中各线程产生的调用序列并非都是恶意的,且对于某个产生恶意行为的线程,其相应的线程调用序列也并非完全恶意的;因此需要找到其中的特征部分,用以区分良性文档和恶意文档。再者,仅使用长度较短的特征序列进行学习和检测能够有效提高模型的检测性能,避免因粒度过细影响模型的检测效果。
检测工作的主要流程如图3 所示。流程主要包括5 个部分:数据收集与预处理、线程调用序列提取、图构建、特征序列提取、异常检测。

图3 文档检测流程Fig.3 Flow chart of document detection
3.2 数据收集与预处理
数据收集过程中使用爬虫程序爬取良性PDF 文档,这部分文档均上传至VirusTotal 经由各家反病毒软件进行检测筛查,确定为良性文档。而后从VirusTotal 中下载恶意PDF 文档作为实验使用的恶意样本,同时从PDF 学习网站选择一些使用PDF 高级功能的样本作为良性样本的补充,使收集的样本足以覆盖PDF 规范中的各项功能。完成收集工作后在Adobe Reader 阅读器上运行并使用NtTracer 追踪系统调用并记录,而后编写数据符号化的处理程序结束预处理工作。
3.3 线程调用序列提取
对于每一个文档来说,其运行时每分钟都会产生数十万次的系统调用记录,且其中产生的系统调用存在大量重复的情况。另外需要注意的是,使用Adobe Reader 运行文档时会创建多个线程,分别负责字体加载、渲染等各项工作。如果不按照线程将这些系统调用进行划分,则可能会出现因线程间的并行导致记录中前后系统调用的行为特征不一致的情况,所以应当对这些系统调用按线程进行区分。由于NtTracer 在收集系统调用数据时能够根据输入选项标识出每一系统调用所对应的线程号,通过将收集到的系统调用数据根据线程号进行整理,可生成各线程相应的调用序列。
3.4 溯源图构建
对于文档p,通过利用其线程调用序列集合T_Entity_Seq中的数据,可以构建文档相应的调用溯源图其中集合V是系统调用的集合,集合E是调用事件集合。调用事件e=(src,dst,time)用以表示相邻两次系统调用的前后关系及产生后一调用的时刻。调用溯源图G(p)=构建的算法设计如下。
算法1 溯源图构造算法。

通过算法1 将同一文档下的多个线程调用序列进行整合,生成调用溯源图,为后文寻找线程调用序列中的特征片段,即特征序列做准备。
3.5 特征序列提取
Wang 等[22]从操作系统原生的事件跟踪日志中收集系统事件序列用以构建溯源图,而后结合其提出的路径稀有度算法选取稀有度较高的系统事件序列作为图的特征部分。参考其思路,本文对系统调用序列构建溯源图,并给出图中节点的稀有度定义。对于某文档运行时生成的线程调用序列中的系统调用v,其稀有度定义为:
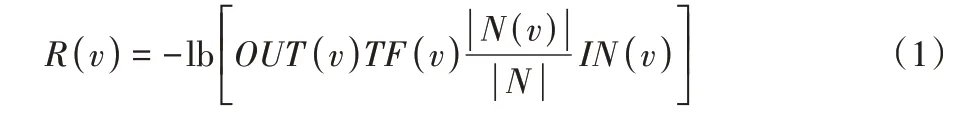
其中:N(v)表示该文档下所有包含系统调用v的线程调用序列的集合,N则是该文档下所有线程调用序列的集合,因此|N(v)|/|N|表示包含系统调用v的线程调用序列占该文档全部线程调用序列的比例。
而TF(v)定义为:

其中:n(v)表示系统调用v在此线程调用序列中出现的次数,L表示此线程调用序列的长度,其值等于该线程调用序列包含的系统调用数。TF(v)的实际含义是系统调用v在此线程调用序列内出现的频率。
进一步地,OUT(v)定义为:
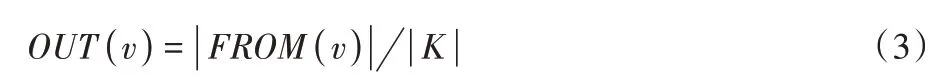
其中FROM(v)定义为:
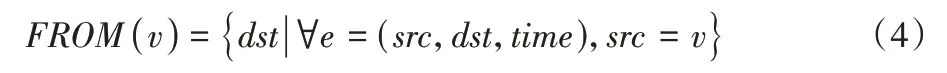
FROM(v)表示对于任意以系统调用v为源调用的调用事件中,目的调用的集合。对于调用溯源图|FROM(v)|即为图中节点v的出度。K表示该文档下所有线程调用序列中包含的系统调用的集合。
类似地,给出IN(v)的定义:

其中TO(v)定义为:
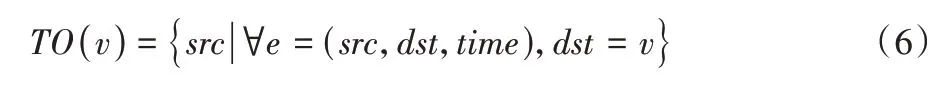
IN(v)表示对于任意以系统调用v为目的调用的调用事件中,源调用的集合。对于调用溯源图|IN(v)|即为图中节点v的入度。
与文献[22]中提出的稀有度定义相比,本文的定义中额外引入了系统调用的局部频率TF(v)。本文认为,频率本身作为一项能够直观反映稀有性的指标符合本文稀有度的定义要求,并且TF(v)的计算不依赖于图结构,能够为溯源图中节点本身赋予一定的稀有度权重;另一方面,系统调用频率在传统入侵检测领域中发挥的作用已得到充分验证,研究表明,目前已提出的诸多基于系统调用频率设计的检测模型均有良好的检测效果。
通过以上定义完成系统调用v的稀有度的计算,之后根据线程调用序列中各系统调用的稀有度进行排序,寻找稀有度数值最大的系统调用。根据Bridges 等[23]的研究,传统入侵检测领域中使用由6~8 个系统调用组成的短序列进行训练和检测的N-Gram 模型往往能取得较优的检测结果。受此启发,本文实验中选择各个线程调用序列中稀有度值最大的K个系统调用及其前后文组成长度为7 的K条短序列作为特征序列,用以后续的检测。由于各线程调用序列长度不同,K的取值根据记录线程调用序列的文件大小Size进行设定,对应关系如表2 所示。

表2 K值选取方法Tab.2 Selection method of K-value
3.6 异常检测
在完成对线程调用序列的特征片段提取后,利用特征片段中各系统调用的稀有度值进行检测。定义P(SpSeqtest)为特征序列SpSeqtest的测试结果,计算方式为:
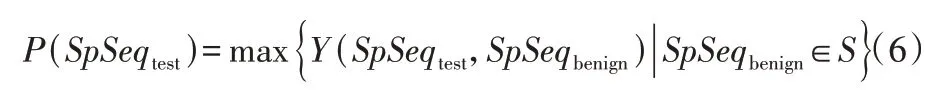
其中:S是所有良性特征库中特征序列的集合,Y(SpSeqtest,SpSeqbenign)表示计算待测序列SpSeqtest与良性特征序列SpSeqbenign的余弦相似度。计算方法为:

具体地,使用待测样本的特征片段的稀有度值依次与所有良性特征库中的特征片段稀有度值计算余弦相似度(实验中n=7),并将计算的最大值作为检测指标值。选取最大值作为检测指标值,是因为只需待测样本与某一良性特征序列有较高相似度,即可认为其为良性的。最终通过设置阈值,最终判断待测样本是否为恶意文档。
4 实验与结果分析
4.1 实验设置
实验机器搭载了Intel Core i7-2.30 GHz 的CPU 与16 GB RAM 存储器,系统为Windows 7 专业版SP1。每个样本在执行2 min 后关闭。所有样本均使用版本号为11.0.0 的Adobe Reader XI 阅读器运行,同时使用NtTracer 追踪并收集系统调用数据。
4.2 样本收集
4.2.1 良性样本
良性样本收集方面首先利用Bing 搜索引擎,通过指定文件类型为PDF 格式,使用爬虫程序爬取了511 个良性样本。然而这类并没有常见恶意样本的特性,比如包含JavaScript脚本和在文档中嵌入字体等;因此从PDF 学习网站上收集了17 个使用了PDF 高级功能的样本,所有样本都提交VirusTotal 并经过扫描,均被识别为良性文档。
4.2.2 恶意样本
从VirusTotal 收集了320 个PDF 文档并放进沙箱执行,确定其均有恶意行为产生。
4.3 实验方法
首先,在Adobe Reader 阅读器上执行文档,同时运行NtTracer 追踪系统调用,将数据存入SQL Server 2008 数据库中。然后,编写符号化程序提取系统调用相关信息,并按所属线程进行划分,生成线程调用序列。进一步地,使用线程调用序列完成调用溯源图的构建,并依据所提稀有度算法提取特征片段。最后,通过特征片段相应的稀有度值进行余弦相似度计算,并采用设置阈值的方法判断文档性质。实验中的爬虫程序、符号化程序、溯源图构建程序以及实现稀有度计算与异常检测的检测程序均使用Python 编写,代码量约为12 000 行。在性能方面,记录了从数据采集到完成异常检测各部分的用时,并进行了性能评估。
4.4 实验结果与分析
对于基于系统调用频率的异常检测而言,一种较为常见的特征提取方法是使用词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法,即将每个系统调用视为一个单词,统计各个系统调用的词频和逆文本频率来筛选特征片段用于检测。在实验的第4 步,即特征序列的提取过程中,使用TF-IDF 以及PROVDETECTOR 中的稀有度算法作为本文算法的代替算法来进行对照实验。
此外,本文实验采用精确率(precision,pre)、召回率(recall,rec)和F1 分数(F1)这3 个指标衡量模型的检测效果。F1 分数是精确率和召回率的调和平均值,即:

其中:TP(True Positives)表示样本标签为真,模型预测也为真的样本数,这里表示样本标签为恶意,模型预测也为恶意的样本数量。FP(False Positives)表示样本标签为假,模型预测为真的样本数,即被错误预测为恶意的样本数量。TN(True Negetives)表示样本标签为假,模型预测也为假的样本数,这里表示样本标签为良性,模型预测也为良性的样本数量。FN(False Negetives)表示样本标签为真,模型预测为假的样本数,即被错误预测为良性的样本数量。表3 为这4 个评价指标的直观具体含义。
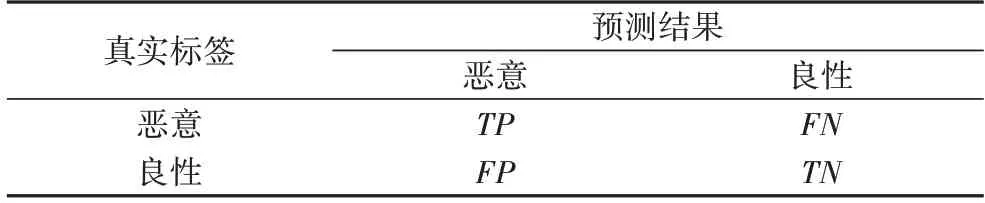
表3 评价指标具体含义Tab.3 Specific meanings of evaluation indicators
4.4.1 TF-IDF算法检测结果
1)良性样本检测结果。实验中使用Adobe Reader 执行待测的良性样本,并使用TF-IDF 算法作为模型第4 步中稀有度算法的代替策略进行实验。在阈值设定为0.98 时F1 分数最高,此时134 个良性待测样本(其中17 个为利用了PDF 高级功能的样本)里有42 个被认定为恶意样本(包括10 个利用了PDF 高级功能的样本)。
2)恶意样本检测结果。实验共有320 个恶意样本,在阈值为0.98 时F1 分数最高,此时311 个恶意文档被认定为恶意样本。
4.4.2 PROVDETECTOR 中稀有度算法检测结果
1)良性样本检测结果。使用Wang 等[22]模型中的稀有度算法作为模型第4 步中稀有度算法的代替策略进行实验。在阈值设定为0.96 时F1 分数最高,此时134 个良性待测样本(其中17 个为利用了PDF 高级功能的样本)里有15 个被认定为恶意样本(包括6 个利用了PDF 高级功能的样本)。
2)恶意样本检测结果。实验共有320 个恶意样本,在F1分数最高即阈值设定为0.96 时,此时318 个恶意文档被认定为恶意样本。
4.4.3 NtProvenancer模型检测结果
1)良性样本检测结果。使用Adobe Reader 执行待测样本,在模型的第4 步中使用本文所提出的稀有度算法进行实验。在阈值设定为0.96 时F1 分数最高,此时134 个良性待测样本里有7 个被认定为恶意样本(包括5 个利用了PDF 高级功能的样本)。
2)恶意样本检测结果。当阈值设定为0.96 时F1 分数最高,为0.989,此时320 个恶意文档均被识别为恶意样本。详细的检测结果如图4 所示。
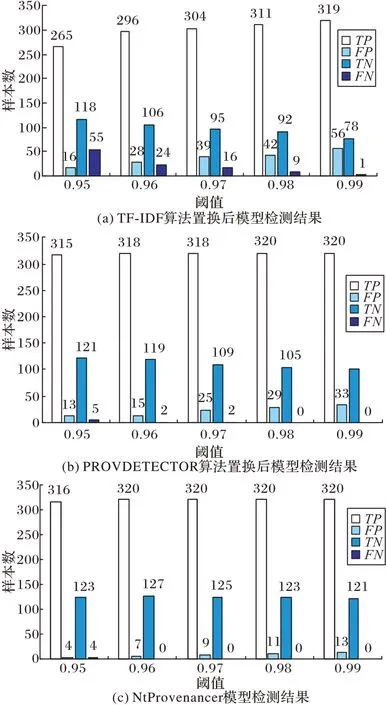
图4 三种算法的模型检测结果比较Fig.4 Model detection result comparison of three algorithms
实验中三种方式下测试结果的精确率、召回率和F1 分数详细结果如表4 所示。为便于描述,表中PROVDETECTOR 及NtProvenancer 代表各自模型的路径筛选算法。
由表4 可以看到,NtProvenancer 模型在阈值为0.96 时取得最大F1 分数0.989,而TF-IDF 算法置换后的模型在阈值为0.98 时取得最大值0.924,PROVDETECTOR 中的稀有度算法置换后的模型在阈值为0.96 时取得最大值0.974。从结果来看本文模型明的检测结果明显优于TF-IDF 算法置换后的模型,略优于PROVDETECTOR 中算法置换后的模型。取得这一结果的原因是TF-IDF 算法在进行特征提取时,只是基于系统调用的频率来挑选更加具有类别区分能力的系统调用;而本文模型的特征提取算法则综合考虑了系统调用的频率、出现类别所占比例,并加入了图论领域的入度与出度等概念对特征提取算法进行了进一步优化,引入了系统调用的上下文信息。这一方式同时结合了系统调用的频率特征和顺序特征,所以能够取得更好的检测效果。相较于本文所提出的稀有度定义而言,PROVDETECTOR 中的定义由于缺少了系统调用在同一线程中出现的频率,对系统调用序列中频率特征提取不够完备,由此导致检测效果上略有不足。
表4 三种评价指标的对比结果Tab.4 Comparison results of three evaluation indicators
实验过程中发现,可考虑直接使用稀有度的值作为评判标准,通过识别包含较低稀有度的系统调用序列,进而完成恶意文档检测。为此展开进一步实验。
在根据稀有度提取特征序列后,计算序列中各系统调用稀有度的均值,并设定阈值用以判断序列恶意与否。此时恶意序列判断标准为:稀有度均值低于设定阈值的特征序列视为恶意的,生成恶意序列的对应文档也同样认定为恶意的。同样在320 例恶意样本和134 例良性样本上进行实验,并计算不同阈值下该方法的精确率、召回率和F1 分数,生成如图5 所示的曲线图。
图5 稀有度均值法下模型的检测结果Fig.5 Model detection results under rarity mean method
从图5 中可以看到,阈值在0.001 5 之后的测试中,召回率不断提高,但是精确率却降低了。后经分析发现随着阈值的不断增大,产生误报的良性样本数在模型识别出的恶意样本中所占比例也不断提高,导致检测效果并不理想。
为探究误报数量增多的原因,对实验所使用的所有良性样本和恶意样本线程调用序列中的系统调用的稀有度值进行了调查,结果如图6 所示。
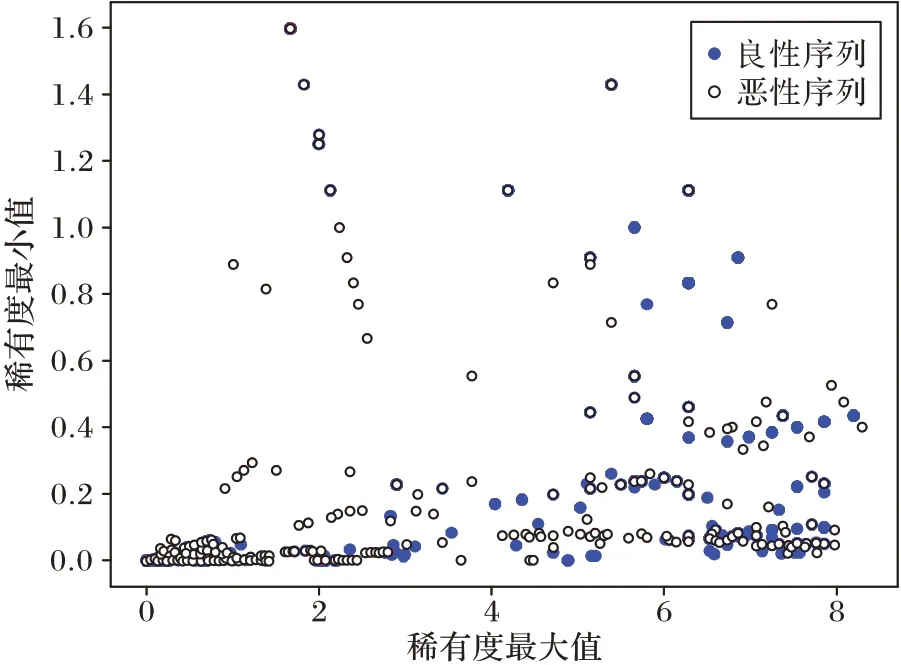
图6 线程调用序列中的系统调用稀有度分布Fig.6 System call rarity distribution in sequences of thread calls
通过将各线程调用序列中系统调用的最大稀有度值和最小稀有度值组成二元组绘制出图6 所示的散点图。从图6中点的分布情况可以看出,无论是对于良性测试文档还是恶意测试文档的线程调用序列,其序列中系统调用的最大稀有度和最小稀有度的分布情况均较为相似;虽然总体上恶意序列中的系统调用在低稀有度处的分布会更加集中,当然这里只是用最大值-最小值近似表示各线程调用序列中稀有度数据的分布,近似地认为各序列稀有度在极值相近时其序列中的稀有度值分布情况也应是相近的。由图6 可知,无法根据稀有度均值设定阈值将图6 中两类点进行有效分离,即无法根据特征序列的稀有度值有效区分恶意序列和良性序列。实际上,无论是恶意文档还是良性文档,都会存在稀有度很低的系统调用,也都会存在稀有度较高的系统调用。换言之,单纯使用稀有度值无法有效地进行恶意文档检测,所以必须考虑结合上下文特征进行改进,这与本文模型的设计思想是一致的。
为说明进行特征片段提取的必要性,选择了两组良性与恶意的线程调用序列进行比较实验。利用滑动窗口,将每个系统调用及其后6 个调用组成长度为7 的系统调用片段,而后对每一片段计算其与良性特征库中特征片段的相似度。图7 是两组序列中的片段与良性特征库中片段的相似度情况。
从图7 中可以发现,恶意线程调用序列相较于良性线程会出现更多的低相似度片段;但即使是恶意线程,其大部分的短序列与良性特征库中的特征序列都有较高的相似度。这说明对于文档攻击而言,大部分恶意行为都是隐藏在大量良性行为活动中;同时也说明了挑选具有代表性的短序列片段,即特征片段进行检测的合理性。通过检测特征序列可以有效减少恶意良性行为被掩盖导致无法正确检测的情况出现,并且能够降低性能开销。值得注意的是,部分良性线程也会出现一些相似度较低的片段,这可能是因为用以采集良性特征的良性样本数量稍有不足,没有完全覆盖所有的良性行为特征,需要进一步地增加用以采集良性特征的良性样本数量。
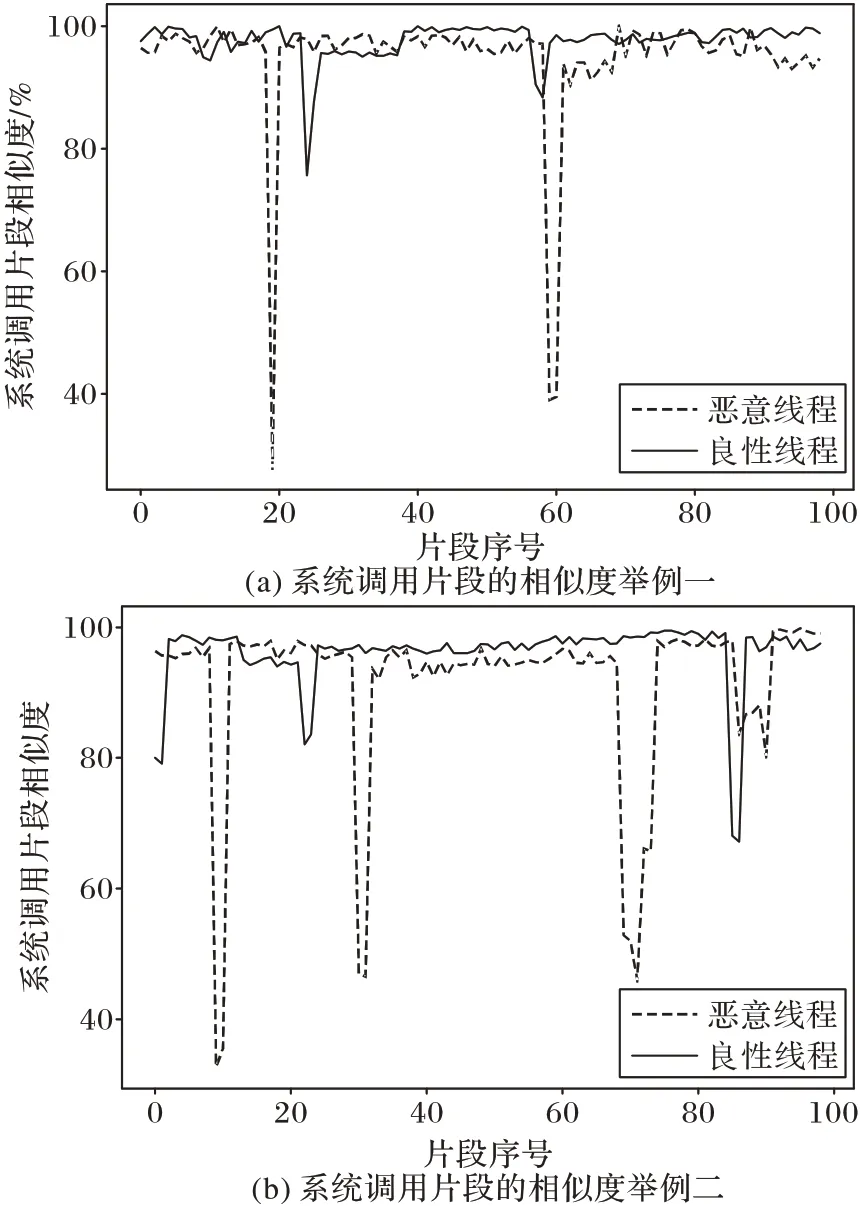
图7 两例恶意线程与良性线程的系统调用片段相似度比较Fig.7 Two examples of similarity among system call fragments between malicious thread and benign one
4.5 性能分析
在最佳参数设置下进行性能测试,此时系统调用短序列长度设置为7,模型阈值设置为0.96。分别测试了模型在训练和检测两种模式下的用时情况。
4.5.1 训练用时
训练用时主要包括以下几部分:提取线程调用序列用时、构建调用溯源图用时、提取特征序列用时、构建良性的特征序列库用时。在实验中,对于394 个文档共计45 733 138条系统调用记录进行线程调用序列的提取,共提取线程调用序列6 880 条,提取特征序列15 493 条,提取单个线程调用序列的平均用时为19.11 ms;对每一个训练样本而言构建调用溯源图的平均用时为7.93 ms,平均每个调用溯源图包含17.46 条线程调用序列的信息;对于一个线程调用序列,提取其特征序列的平均用时为26.50 ms,最终构建良性特征库并存入15 493 条特征序列信息总用时104 s。
4.5.2 检测用时
检测用时主要包括以下几部分:提取线程调用序列用时、构建调用溯源图用时、提取特征序列用时、异常检测用时。在检测时,对于454 个文档(包含134 个良性文档与320个恶意文档)共计50 776 144 条系统调用记录进行线程调用序列的提取,共提取线程调用序列7 778 条,提取单个线程调用序列的平均用时为17.83 ms。对每一个待测样本而言构建调用溯源图的平均用时为5.84 ms,平均每个系统调用溯源图包含17.13 条线程调用序列的信息。在第4 步的提取特征序列阶段中,提取单个线程调用序列的特征序列的平均用时为23.57 ms。最终文档的异常检测平均用时为13.31 ms。训练与检测用时具体情况如表5 所示。
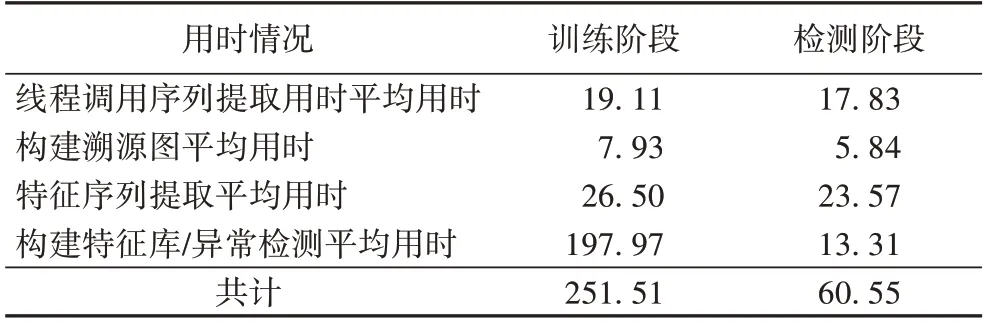
表5 训练与检测阶段的用时情况 单位:msTab.5 Time cost of training and detection stages unit:ms
此外,由于本模型只需要单线程的执行方式即可完成全部工作,后续可以采取多核并行的方式进一步减少检测用时。
5 结语
本文设计了一种基于系统调用与数据溯源技术的恶意文档检测模型。该模型结合基于系统调用频率与顺序特征的异常检测技术特点,同时利用溯源技术完成系统调用级溯源图的构造,并提出一种基于图的特征提取算法用于筛选特征片段完成检测。与其他检测系统相比,本文提出的检测模型漏报率、误报率较低,能够有效全面地完成恶意文档检测。但该模型也存在着一定的提升空间,如攻击者可能会根据稀有度算法设计出稀有度很高的攻击序列来规避检测,后续还应在此方面进行改进。
未来可能会考虑利用异构技术对模型检测效果进行进一步完善,如利用不同文档阅读器下堆栈、库依赖项、文件系统语义以及系统调用及其参数的差异性来进一步完善模型的检测机制,提高系统的检测性能。
