基于改进的半监督聚类的不平衡分类算法
2022-12-18赵凌云白斌雯
陆 宇,赵凌云,白斌雯,姜 震
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
0 引言
类别不平衡是指数据集中某些类(少数类)的样本数量与其他类(多数类)的样本数量有很大差距[1]。不平衡数据分类广泛存在于医疗诊断、故障诊断、信用卡欺诈检测[2]等领域。传统的分类算法假设各类别样本的误分代价相等,以最小化总体错误率为目标进行模型优化,这会导致最终决策偏向于多数类样本,造成少数类样本被错分。但是现实任务中少数类样本往往更具有价值。因此如何有效提高少数类样本的识别率、提升不平衡分类算法性能,已经成为近年来机器学习领域的研究重点之一。
当前不平衡分类的算法大致可分为两类:1)算法层面的方法[3]通过对已有分类算法进行修改或者提出新算法以提高对少数类的识别率,这依赖于特定的算法并要求对相关领域有深入的了解。2)数据层面的方法通过削减多数类样本的数量(欠采样)或者增加少数类样本的数量(过采样)来实现训练集的再平衡,从而缓解分类模型的类别倾斜[4]。该类方法独立于具体的分类算法,可扩展性高;但是欠采样容易丢失有效的信息。过采样通过复制原有少数类样本或者根据原有分布合成新的少数类样本;但是过采样具有不确定性,且增加的样本都是基于原有的分布,包含信息量过少,无法揭示更多的数据集分布特征。
本文提出一种利用改进的半监督聚类来辅助不平衡分类的算法。首先,提出一种改进的半监督聚类算法CS-KMeans(Constrained-Seeded-K-Means)来挖掘数据的分布特征,并在聚簇中选择高置信度的无标签样本(伪标签样本)来补充少数类样本。这种新型的过采样方法除了实现数据集的再平衡外,还可以有效引入聚类所获得的分布特征来改善分类模型在不平衡数据集上的性能。其次,将改进的半监督聚类与分类模型相结合进行最终的预测。该算法缓解了单一分类器泛化能力较差的问题,进一步提升了不平衡分类性能。在实验部分,通过将本文算法与经典的Borderline-SMOTE(Borderline Synthetic Minority Oversampling TEchnique)[5]、自适应 综合过 采样技 术(ADAptive SYNthetic sampling approach,ADASYN)[6]和最新 提出的RCSMOTE(Range-Controlled Synthetic Minority Oversampling TEchnique)[7]等算法在10 个数据集上进行对比,实验结果表明本文所提算法有更好的性能,验证了本文算法的可行性和有效性。
1 相关研究
在算法层面,根据不平衡数据集的分布特点,通过对已有经典算法进行修改或者提出新算法以提高对不平衡数据集中少数类的识别率,代表算法有代价敏感学习[8]、集成学习[9]等。基于代价敏感学习的方式分别给不同的类别赋予不同的代价因子,以求获得误分代价最小的分类结果[10],或者考虑对决策函数添加不同的权重,使最终的决策更倾向于少数类[11]。基于集成学习的不平衡分类算法分为数据预处理与集成学习相结合的方法[12]和代价敏感的集成学习[13]。为了对所选算法进行适当的修改用于不平衡数据分类,必须对分类算法和相关领域有深入的了解。
在数据层面,通过改变数据集样本的分布或者消除各个类别之间样本数量的差异来平衡数据集,由于其独立于具体的分类算法,可以与任意的分类算法结合使用[14],可扩展性高,这种方法是目前主流的算法,代表算法有SMOTE(Synthetic Minority Oversampling TEchnique)[15],Borderline-SMOTE[5]等。SMOTE通过随机在其K近邻中选择样本进行插值,生成无重复的新的少数类样本,可以在一定程度上解决过拟合的问题;但是新生成的样本也会出现噪声、样本重叠的问题。后续在SMOTE 的基础上又提出了许多改进的方法,Borderline-SMOTE 认为边界附近的样本比远离边界的样本更容易被分错,因此在边界的样本应该更重要。这个设想也符合经典分类器的思想,如支持向量机(Support Vector Machine,SVM)就是为了最大化超平面,而超平面又由其附近的支持向量所构成。RCSMOTE[7]为了解决引入价值量低甚至降低分类性能的噪声样本,将原始数据集分为安全区域、边界区域和噪声区域,在采样过程中首先针对边界区域的样本进行采样,扩充会影响决策平面的样本,若边界区域中样本过少,不足以满足采样需求,那么再对安全区域的样本进行采样,而不会对噪声区域的样本进行采样,有利于引入大量信息量高的样本,同时减少噪声样本的引入。CDSMOTE(Class Decomposition SMOTE)[16]通过K-Means 将多数类分解为多个子簇,并为其赋予新的子标签,然后针对性地对这些簇进行过采样。TU(Trainable Undersampling)[17]通过强化学习方式,将欠采样过程与具体的分类过程相结合,从而有指导地进行欠采样,减少过采样删除过多有价值的样本。
近年来一个值得关注的方向是采用聚类分析发掘数据的分布特征,从而提高采样的质量。K-Means SMOTE(KMeans SMOTE)[18]首先利用聚类寻找“安全区域”,即那些更适合进行过采样的样本簇,然后随机选择这些簇中的样本使用SMOTE 进行过采样,这不仅解决了类间不平衡,而且有效解决了类内不平衡。文献[19]中通过在全体样本上使用聚类算法和过滤的策略很好解决了类内不平衡的问题,该算法首先在整个数据集上使用密度峰值聚类算法,然后根据簇的密度和距离多数类样本的距离为每个簇分配采样比重,最后该算法为了避免过采样带来的重叠的问题,开发了一种启发式过滤策略,以迭代的方式将可能重叠的少数实例从多数类中移除。目前不平衡分类中基本倾向于在各个类内部对有标签样本进行无监督聚类[20]。这种方式难以发掘数据的整体分布规律,此外还有大量的有标签数据未被有效利用。
2 基于改进的半监督聚类的不平衡分类
针对当前的不平衡分类研究中引入聚类技术的局限性,本文提出一种改进的半监督聚类算法来辅助不平衡分类。其基本思想是利用有标签样本的指导,在全体数据上进行聚类,建立簇与类的映射关系。相较于无监督的局部聚类,该算法可以更好地发掘原始数据分布特征以辅助分类。首先,基于半监督聚类的结果,从无标签数据中选择置信度高的部分,作为少数类的伪标签样本加入训练集。这种新型的过采样方法可以更好地发掘数据的分布特征,改善随后分类模型的训练。然后,考虑到类别倾斜的影响,半监督聚类预测结果中的少数类样本可能不足以实现数据集的再平衡。这种情况下,使用SMOTE 作为补充,将伪标签数据集、原始数据集和过采样数据集三者结合得到新的训练集。最后,为了进一步提高模型的泛化性能,将改进的半监督聚类的预测结果和分类方法的预测结果结合得到最终的分类结果。算法原理如图1 所示。
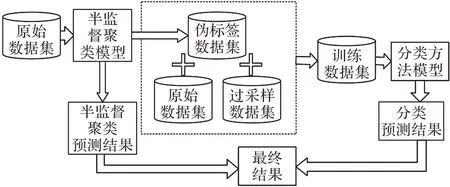
图1 本文算法原理Fig.1 Principle of the proposed algorithm
2.1 Constrained-Seeded-K-Means算法
半监督聚类利用标记数据或成对约束信息来指导聚类,以求得到更好的聚类结果。最常见的约束类型是成对约束,它要求数据在分配过程中满足必连约束或勿连约束[21],其聚类结果会受到约束顺序的影响。相较于成对约束,使用部分有标签样本来指导聚类的划分更为自然,并避免了约束的自相矛盾和顺序的影响。这些有标签样本通常被用于聚类模型的初始化。其中Seeded-K-Means[22]使用标记信息初始化质心,然后采用标准的K-Means 迭代方法来更新质心并完成聚簇划分。值得注意的是,迭代过程中一些预测错误的样本会明显造成聚类性能的下降。本文提出一种目标函数,利用标记信息来指导质心迭代,从而控制噪声影响并改善聚类性能。
2.1.1 初始化
根据训练集中各个样本的标签,把有标签样本依次划分到距离它们最近且标签相同的簇中,最后得到每个簇的初始质心:

其中:Pk表示第k个簇。在不平衡数据集中,由于少数类样本数量少,而且分布可能比较分散,往往会出现少数类样本被错分到多数类的簇中的情况。针对该问题,在计算样本到各个质心的距离时,本文提出了一种结合各个类别的不平衡率作为权重的新型距离公式如下:

其中:|P|代表样本总数。该距离计算公式可以有效降低少数类样本被误分的概率。
2.1.2 目标函数
在传统的K-Means 算法中,其目标函数是最小化各个数据点到质心的距离和,即误差平方和(Sum of Square Error,SSE)。
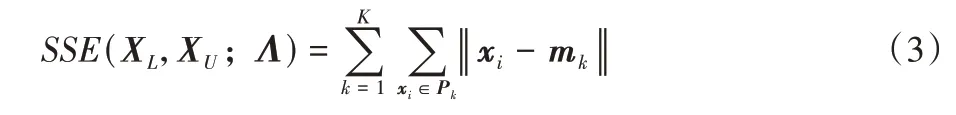
其中:Pk是第k个簇,mk是第k个簇的质心,Λ为聚类模型。Seeded-K-Means 利用有标签样本初始化簇的个数以及对应的质心,通过标准的质心迭代来最小化SSE 并获得聚簇结果;但是质心迭代过程中有些不属于该类(簇)的数据可能会被错误划分进来,进而影响质心和簇的质量。这种问题在不平衡数据集中更加突出,由于少数类样本数量少且分布分散,聚类往往为了得到最小化误差,会将少数类样本划分到多数类的簇中,造成聚类性能严重下降。
传统质心迭代的终止条件常用的有两种方式:方式一是设置最大迭代次数;方式二是计算前后两次迭代的差值,若小于指定的阈值,则终止迭代。这两种终止方式都有一个缺点,迭代过程中极有可能错过最优的划分结果,导致聚类性能下降。
本文提出了一种新的目标函数用来控制质心迭代过程:利用有标签样本XL来评估聚类模型的性能,进而指导质心的迭代。具体做法是将训练集上计算的准确率(Accuracy,Acc)与少数类的查全率(Recall,Rec)相结合来判断是否停止迭代。

其中Rec的计算方式为:

其中:|Y|表示数据集类别个数,tpi是预测为i类且实际上属于i类的样本的数量,fni是未预测为i类但实际上属于i类的样本的数量。在保证SSE 下降的前提下,该目标函数同时考虑了簇的预测准确度以及少数类的查全率。在多数类不被误分的情况下,最大化将少数类样本划分到对应的少数类簇中。当目标函数下降时,表明如果继续迭代会降低聚类算法性能,应该停止迭代,并恢复上轮聚类结果。
2.1.3 簇的划分
测试样本x属于所在簇的概率的计算方式为:
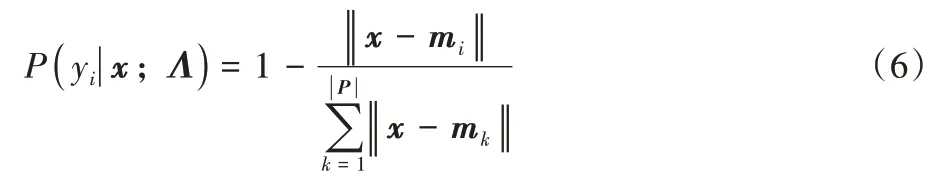
其中:mi为簇Pi的质心,‖x-mi‖是样本x到质心mi的距离,|P|表示簇的数量,Λ为聚类模型。在不平衡数据集中,少数类样本数量过少且分布分散,这样属于少数类的簇的直径可能过小,而多数类样本数量较多且分布集中,这有可能造成属于多数类的簇直径过大,二者的差距会导致最终对于不同类别样本预测概率计算存在误差。因此通过式(6)可发现,本文算法不仅考虑了无标签样本x到其所属簇的质心的距离,还综合考虑了其到所有具有相同标签的簇质心的距离,这有利于避免因为簇的直径影响不同样本的置信度,提高了预测置信度的准确性。
Constrained-Seeded-K-Means 算法的具体步骤如下。
算法1 Constrained-Seeded-K-Means 算法。

2.2 基于CS-K-Means的不平衡分类算法
本文算法首先在数据集上使用改进的半监督聚类得到若干簇,这些簇揭示了原数据的底层分布特征;然后根据各个簇的属性对这些多数类簇进一步处理,弱化多数类样本的影响;接着基于聚类结果选择高置信度伪标签样本加入训练集并使用分类算法训练分类模型;最后为了提高算法的泛化性能,融合分类算法和改进的半监督聚类结果得到最终的分类结果。算法描述如下。
算法2 基于CS-K-Means 的不平衡分类算法。

在步骤1)结束后,可能会存在一些不纯的或者规模过小的多数类的簇,即重叠区域或小集群,这可能会误导分类模型的训练;因此通过步骤2),删除在重叠区域中可能降低少数类识别率的过小多数类簇。该做法有助于最终的决策偏向于少数类,进一步提高少数类的识别率。
在步骤3)中,有别于其他重采样算法引入大量人工生成的样本,本文算法筛选高置信度的伪标签样本补充少数类样本,不会破坏原始的数据分布。CS-K-Means对于样本x的置信度预测计算方式如式(6)所示,本文将用式(6)作为置信度计算的标准——置信度越高,被选为伪标签样本的概率就越大。
最终通过步骤5),将CS-K-Means 与传统的分类算法相结合,得到最终分类结果,进一步提升算法的泛化能力;理论上可以使用任意具有概率输出的分类算法,本文采用经典的支持向量机(SVM)算法,结合方式如式(7)所示:
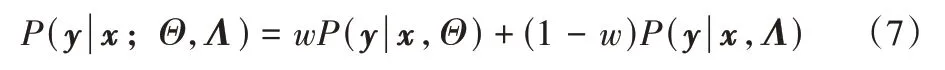
其中:P(y|x;Λ) 为CS-K-Means 的预测概率结果,根据式(6)计算;P(y|x;Θ)为分类器的预测概率结果,根据具体分类器计算所得。式(7)通过权重参数w调节CS-K-Means 和分类器对最终结果的影响,为了更好地融合二者预测概率,本文算法利用数据集的先验知识不平衡率(Imbalance Ratio,IR)结合模型在训练集上的表现,自适应地确定w,如式(8)所示:
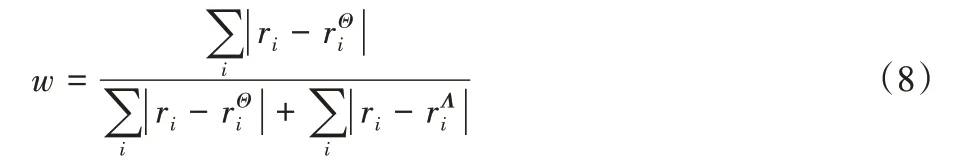
其中:ri为先验知识IR,分别为分类器和改进的半监督聚类在测试集上预测结果的不同类标签比例。因此,分类表现更好的模型对于最终的决策影响更大。
3 实验分析
3.1 数据集介绍
为了衡量本文算法的性能,本文使用keel 和UCI 中10 组数据集训练分类器并对结果进行分析。其中部分数据为多分类数据集,本文实验将某些类合并成二分类数据集:规模较小的类标记为少数类,其余类合并为多数类。数据集详情如表1 所示,其中IR 代表数据集的不平衡率。
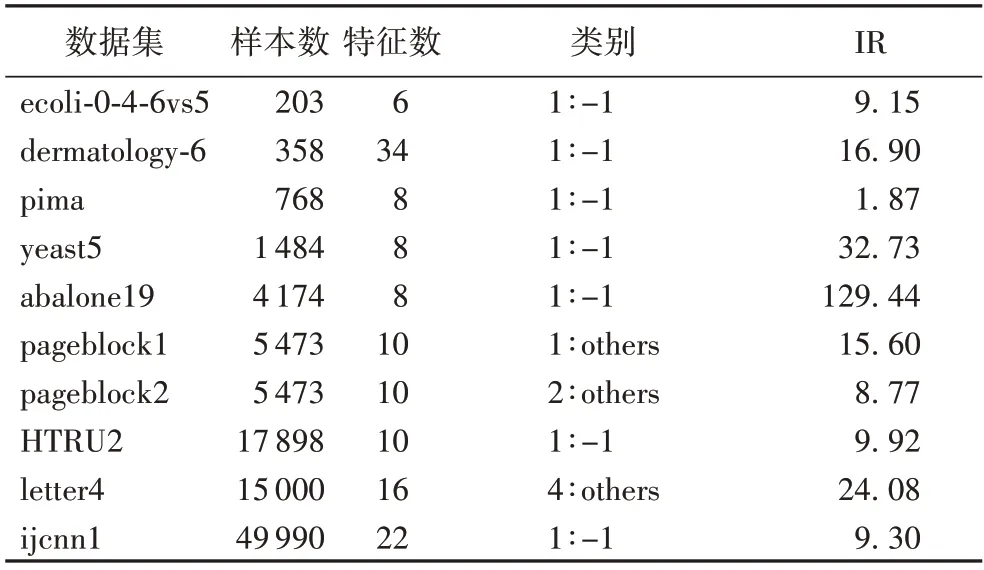
表1 数据集的基本信息Tab.1 Basic information of datasets
3.2 评估指标
本文将使用不平衡分类常用的G-mean 和曲线下面积(Area Under Curve,AUC)作为分类模型的评估指标(本文将少数类定义为正类,多数类定义为负类)。令TP(True Positive)表示预测为正类的正样本;TN(True Negative)为预测为负类的负样本;FP(False Positive)为预测为正类的负样本;FN(False Negative)为预测为负类的正样本。可以计算出灵敏度(Sensitivity,Sens)和特异度(Specificity,Spec):

根据这两项指标,可以得到G-mean:

受试者工作特征(Receiver Operating Characteristic,ROC)是一个二维平面上的曲线,以假阳率为横轴,以真阳率为纵轴。最佳的分类器应当尽可能处于左上方。当一个分类器的ROC 曲线完全覆盖另一个分类器的ROC 曲线,则说明前者的分类性能优于后者;若两分类器的ROC 曲线发生交叉则无法断言哪个分类器性能更好。因此引入了ROC 曲线下的面积,即AUC 进行对比。
3.3 结果分析
本文将所提算法与6 个过采样算法Borderline-SMOTE(B-SMOTE)、SVM-SMOTE(Support Vector Machines Synthetic Minority Oversampling TEchnique)[23]、K-Means SMOTE、ADASYN[6]、RCSMOTE 和CDSMOTE 以及1 种欠采样算法TU进行比较,其中前4 个算法使用Python 下的Imbalance-learn包实现,参数均使用默认参数,RCSMOTE、CDSMOTE 和TU使用与相应文献相同的参数设置。基础分类器使用的都是SVM,均采用径向基核函数(Radial Basis Function,RBF)。表2、3 同时列出了基础分类器SVM 和改进的半监督聚类算法的结果。最终结果为5 折交叉验证的平均值。
表2、3分别给出了10种不同算法在10个不平衡数据集上的AUC 和G-mean 指标的实验结果,最优结果加粗表示,其中CS-K-Means 表示改进的半监督聚类的结果,SVM 表示基分类器SVM的结果,C_SVM表示SVM在CS-K-Means处理过后的数据集上的结果。从结果可以看出,在AUC和G-mean的平均结果上本文算法都达到了最优。这表明了本文算法对于不平衡数据分类的有效性。与基分类器SVM 相比,所有的不平衡分类算法在AUC和G-mean上都有了明显的提升,这表明了这些算法在处理不平衡数据分类上的优越性能。
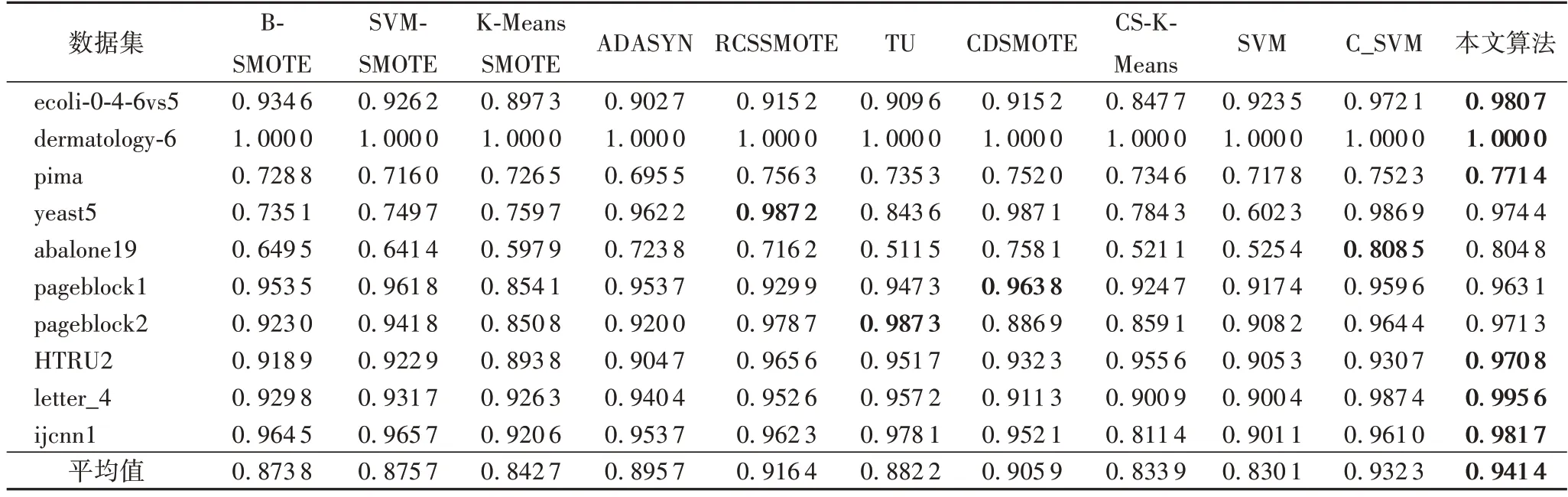
表2 不同算法的AUC对比Tab.2 AUC comparison of different algorithms
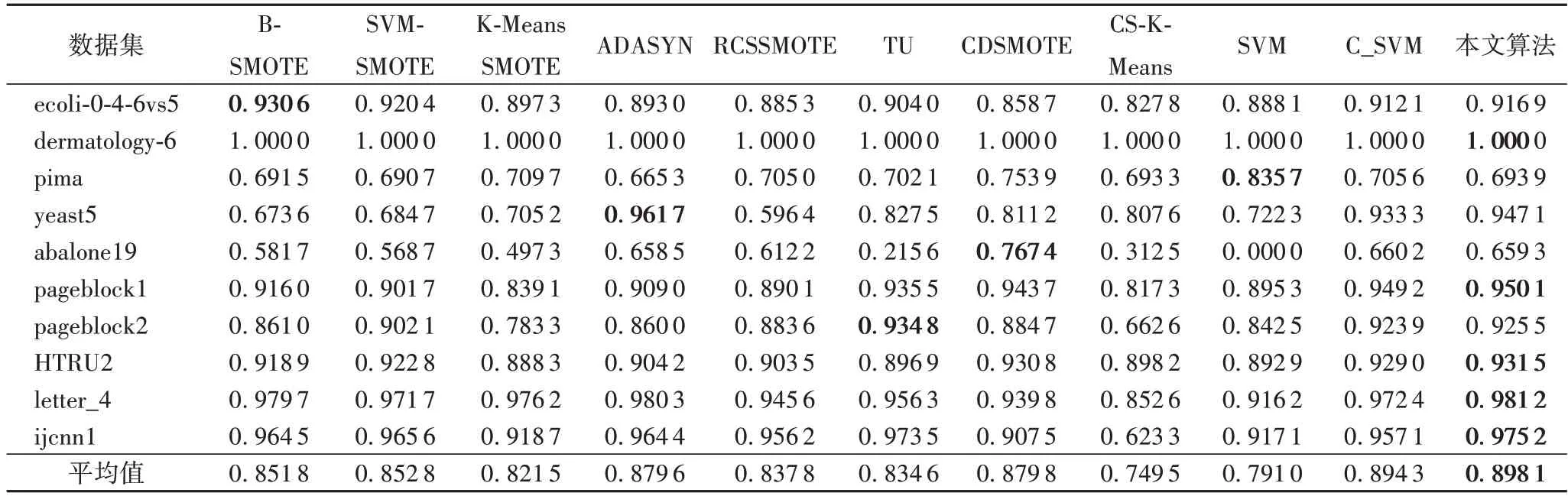
表3 不同算法的G-mean对比Tab.3 G-mean comparison of different algorithms
从表2 可以看出,改进的半监督聚类算法在AUC 指标上,在pima 数据集上表现接近其他不平衡分类算法,其原因可能为CS-K-Means 利用式(2)重点将样本划分到少数类簇,因此提高了少数类的预测概率;同时利用改进的目标函数控制簇的迭代过程,使算法适时收敛,得到了相对最优簇划分。C_SVM 在2 个指标上的平均结果表现也要优于SVM,这表明了改进的半监督聚类算法提供的伪标签样本对于发掘数据底层分布特征的作用。本文算法通过式(7)融合SVM 和改进的半监督聚类算法,平均结果优于CS-K-Means 和C_SVM,算法的不平衡分类性能得到进一步提高,充分体现了融合算法的效果。
在AUC 指标上,本文算法在6 个数据集上得到了最优结果,并取得最高的平均结果,在ecoli-0-4-6vs5 上优势更加明显。分析其原因为得益于半监督聚类得到了该数据集的原始分布特征,并补充伪标签样本和引入符合原始分布的人造样本,在减少了不平衡的情况下很少引入噪声数据,这充分说明本文利用伪标签样本,有助于发现更多的少数类边缘样本分布特征,从而推动决策面向有利于少数类的方向移动。
在G-mean 指标上,本文算法在5 个数据集上得到了最优结果,同时也取得了最高的平均结果。在ijcnn1 数据集上,由于该数据集所含样本数很大,CS-K-Means 在G-mean 指标上表现较差,分析其原因可能是该样本多数类样本数量远多于少数类样本,可能存在样本重叠的情况,导致CS-K-Means无法得到有效的簇。但是本文算法最终的结果却未严重受到其影响,这说明通过式(8)可以综合基分类器的性能,提高算法的鲁棒性。在数据集abalone19 上,SVM 无法识别出少数类样本;而欠采样算法TU 相较于其他过采样算法在AUC和G-mean 上都表现较差。可能由于该数据集不平衡率非常大,通过大批量删除多数类样本取得数据集的平衡,很容易删除掉大批信息丰富的样本,造成性能的下降;而过采样避免了这一问题,通过补充少数类样本数量,大部分还是取得了不错的表现。
4 结语
本文提出一种改进的半监督聚类算法,并利用该算法来辅助不平衡分类。首先,针对传统的半监督聚类算法在质心迭代中由于噪声引起的性能下降问题,本文提出一种改进的目标函数来约束质心迭代。其次,提出一种新型的重采样方法:利用改进的半监督聚类来补充少数类的伪标签样本。最后,结合半监督聚类与分类的结果进行最终预测,以进一步提升模型的不平衡分类性能。在与6 个基于过采样和1 个基于欠采样的不平衡分类算法的实验对比中,本文算法在AUC和G-mean 指标上均获得了最优的平均结果。这些实验结果表明,基于改进的半监督聚类的不平衡分类算法有助于提高少数类样本的识别率。考虑到伪标签样本中可能存在的噪声问题,计划在下一步的研究中结合自步学习(Self-Paced Learning,SPL)技术来降低伪标签样本中的噪声影响,从而进一步提高不平衡分类性能。
