融合双向依存自注意力机制的神经机器翻译
2022-12-18李治瑾文永华高盛祥
李治瑾,赖 华*,文永华,高盛祥
(1.昆明理工大学 信息工程与自动化学院,昆明 650504;2.云南省人工智能重点实验室(昆明理工大学),昆明 650504)
0 引言
近年来神经机器翻译方法取得了重要的进展,在主要语种间的翻译质量已经接近人工翻译水平。神经机器翻译主要依赖大规模的语料,在低资源情况下,神经机器翻译模型的翻译质量会出现明显下降。为解决资源稀缺的问题,神经机器翻译一般采用融合句法信息的方法。Eriguchi 等[1]率先提出了一种端到端的语法神经机器翻译模型,该模型是基于注意力机制的编解码模型并融合了成分句法信息,使解码器生成的单词与短语以及源句子的单词进行软对齐。Aharoni等[2]提出了一种融合目标语言成分句法的方法,通过翻译得到线性化或词汇化的成分句法结构,将目标语言的句法信息融入神经机器翻译模型;但该方法不针对低资源神经机器翻译。Gū 等[3]提出在神经机器翻译模型中增加具有语法识别解码的成分句法结构,利用具有语法感知的注意力模型和对句子结构敏感的语言模型,提升翻译质量,该方法在句子语义流畅度上取得了较好的效果。以上研究主要基于循环神经网络(Recurrent Neural Network,RNN)[4]和长短期记忆(Long Short-Term Memory,LSTM)[5]模型框 架。目 前Transformer 模型已经成为了基线模型,因此本文的研究基于Transformer 模型。目前在依存句法融合方面一般只融合依存句法中的父词信息,利用子词到父词的方向能够确定句子中父词的位置信息,得到父词位置向量,增强句子中父词对机器翻译的影响;而父词到子词的方向较少被融合到机器翻译模型中。本文认为父词到子词方向能够提供句子中子词的位置信息,通过遍历得到句子中的全部子词位置信息,构建子词权重矩阵,增强子词对机器翻译的影响。这种明确的父词到子词和子词到父词的双向关联关系对机器翻译可能更加有效。由此本文提出了将这两种双向信息融合到翻译模型中的方法,通过更全面的结构信息融合提升机器翻译的性能。参照Bugliarello 等[6]的方法,本文提出了双向依存自注意力机制(Bidirectional-Dependency self-attention mechanism,Bi-Dependency),将双向依存知识融合到Transformer 编码器的多头注意力机制中,不仅利用了依存句法中子词到父词的信息也利用了父词到子词的信息,利用双向依存知识指导神经机器翻译。
本文的主要工作包括以下两个方面:
1)提出了基于双向依存自注意力机制的神经机器翻译模型,通过融合子词到父词和父词到子词的双向依存信息,提升了神经机器翻译的翻译效果。
2)提出了双向依存自注意力机制,将双向依存信息融合到Transformer 模型编码器的多头注意力机制中;将句法结构信息有效地融入到了Transformer 模型中。
1 相关工作
1.1 依存信息融合方法
针对神经机器翻译任务中资源稀缺的问题,目前的解决方法主要分为融合成分句法和融合依存句法两种方式,本文主要讨论融合依存句法的方式。融合依存句法知识利用句子中的词生成依存句法树,得到句子中词与词间的关系,这种明确的句法信息的引入有助于翻译模型更好地学习句子中的句法结构,缓解资源稀缺的问题。
Wu 等[7]率先在基于RNN 的翻译模型中引入了依存句法知识并提出了一种具有语法知识融合的方法,该方法有3 个编码器和两个解码器同时需要提供目标语言的依存句法信息。该方法在解码端融合目标语言的依存句法信息,通过依存句法知识的指导,得到解码端的输出,但该方法不针对低资源条件下的神经机器翻译。Zhang 等[8]通过将依存解析器的中间表示与单词嵌入进行级联,从而集成源语言端的语法,该方法由解析模型和神经机器翻译模型构成,将解析模型编码器生成的隐状态作为翻译模型的输入,在翻译的同时可以得到源语言句子的依存解析结果;但该方法不允许在源语言端学习字词单元。Saunders 等[9]利用语法表示法对单词进行交织,提出了一种基于派生的表示形式,可以从序列中直接复制原始树,从而保持结构信息;但这样会导致更长的序列出现,且需要利用梯度累计的方式才能进行有效的训练。Choshen 等[10]提出了一种基于生成转换序列的基于Transformer 的树和图解码的通用方法,实验表明该方法的性能优于标准Transformer 解码器。安静[11]利用依存句法将英文长句分割并证明了基于长句分割机器翻译的有效性。王振晗等[12]将源语言句法解析树融合到卷积神经网络中,在汉-越翻译中取得了很好的效果。
以上融合依存句法知识的研究主要基于RNN 和LSTM模型框架进行研究,只有少量的研究是在Transformer 模型框架下进行的。目前Transformer 模型框架在许多双语的翻译上都取得了最佳的翻译效果,因此,本文将双向依存知识融合到Transformer 模型中,以提升翻译质量。
1.2 基于Transformer模型的句法信息融合方法
Wang等[13]提出了一种隐式的集成源端语法的方法,使用端到端依存解析器的中间隐藏表示,将其隐藏为具有语法感知的单词表示。之后,将具有语法感知的单词表示形式与普通的词嵌入连接起来,以增强基本的神经机器翻译模型。该方法无需外部解析工具,但该方法并不针对低资源情况。Nguyen 等[14]提出了一种具有层级累积的树结构注意力机制,将源语言句子序列解析为成分树结构后,先利用自下向上的检索累积,再进行自左向右的权重累积得到4 个向量,输入到Transformer 模型中,将叶子节点和非终端节点分别编码并输入到解码端。Zhang 等[15]提出了通过基于互信息最大化的自监督神经深度建模的源-目标双语对齐的方法,基于神经机器翻译的词对齐,对齐源句和目标句的句法结构,通过互信息最大化源句和目标句的相互依赖性,结果显示了句法对齐的有效性和通用性。Slobodkin 等[16]利用通用概念认知注解(Universal Conceptual Cognitive Annotation,UCCA)解析的方式获取源语言的解析数据,分别融入编码器或解码器并取得了较好的结果,证明了融合语义知识的有效性。张海玲等[17]提出利用句法层次化分析识别短语及句子框架并在中-英翻译上取得了较好的效果。Bugliarello 等[6]提出了父母规模自注意力(Parent-scaled self-attention,Pascal)机制和一种将语法知识融入Transformer 模型的方法,将依存信息中子词到父词的信息融合到多头注意力机制中,该方法是一种新颖的、无需参数的、具有依赖性的自注意力机制,可提高翻译质量。
以上基于Transformer 模型的句法信息融合方法大多只融合子词到父词方向的信息,并未融合父词到子词方向的信息。本文提出了融合双向信息的方法,通过更全面的结构信息融合提升神经机器翻译的性能。
2 融合双向依存知识的神经机器翻译
本文模型基于Transformer 框架,利用双向依存自注意力机制对Transformer 编码器的多头注意力机制进行改进。双向依存自注意力机制的输入由源语言句子的嵌入矩阵、源语言父词位置向量P∈RL和源语言子词权重矩阵C∈RL×L构成,输出为双向依存自注意力机制的最终表示Mh。图1 展示了双向依存自注意力机制的结构。
2.1 双向依存信息
对于源语言中的父词信息,本模型利用外部解析工具得到父词位置序列,对于子词,本模型无需提供额外的依存解析工具,仅使用父词位置向量即可构建子词权重矩阵。对于根词,本文将其父词和子词定义为根词本身。
本文首先利用外部依存解析工具得到依存解析中的父词位置标记序列,从而得到句子序列中的父词位置向量P∈RL,根据图1 中的句子依存关系图可知句子中词与词间关系,箭头指向的词为子词,箭尾指向的词为父词,由此可知每个子词所属的父词在句子中的位置,从而得到父词位置向量P∈RL。如图1 中的句子,“两者”的父词为“出现”,“出现”在句子中的第3 个位置,因此父词位置向量中第1 个位置为3。以此类推,可得到图中的父词位置向量P∈RL。
根据父词位置向量P∈RL可得到源语言句子中的子词权重矩阵C∈RL×L。式(1)给出了子词权重矩阵C的定义,假设xi是可能的父词,则当xj是xi的子词时,元素Cij为1;否则为0。对于每个句子,使句子中的每个词与其本身对应。由于每个句子中的父词可能存在多个子词,因此本文将这些子词进行权重平均。对于根词,将其子词作为它本身并记录权重。通过这种方式,每个单词都会被告知其修饰语。

其中:ni是xi的子词个数。同样根据图1 中的依存关系图可知,每个父词拥有几个子词,例如,句子中的“出现”拥有包括其本身在内的4 个子词,在子词权重平均后,子词权重矩阵第3 行中的每个子词所在的位置均为1/4,其余没有子词的词语所在的行均为0,即可得到图1中的子词权重矩阵C∈RL×L。

图1 双向依存自注意力机制的结构Fig.1 Structure of bidirectional-dependency self-attention mechanism
2.2 双向依存自注意力机制
在图1 中,对于长度为L的源语言句子序列,双向依存自注意力机制中每个头的输入分别是嵌入矩阵、源语言句子的父词位置向量P∈RL和源语言句子的子词权重矩阵C∈RL×L。根据Vaswani 等[18]的研究,在每一个注意力机制的头中,为每个标记进行计算可得到3 个向量,分别是查 询、键和值,从而得 到3 个矩阵Kh∈RL×d、Qh∈RL×d和Vh∈RL×d,其中d=dmodel/H,H为注意力机制中头的数量。之后计算每个查询、键和值,给出在给定位置编码时,要在输入的其他位置上设定的焦点分数,再将分数除以可以缓解点积较大时出现的梯度消失问题,如式(2)所示:

其中:T 表示矩阵的转置。根据每个标记与位置t的依存父词位置pt之间的距离,得到在位置t处的标记得分st:

其中:是父词融合矩阵Nh∈RL×L的第t行,代表与第t个父词接近度的归一化分数;是父词距离矩阵DP∈RL×L的第(t,j)个位置,其中dtj包含每个标记j与依存知识中每个父词位置间的距离关系,此距离计算定义为以pt为中心且方差为σ2、正态分布为N(pt,σ2)的概率密度值:
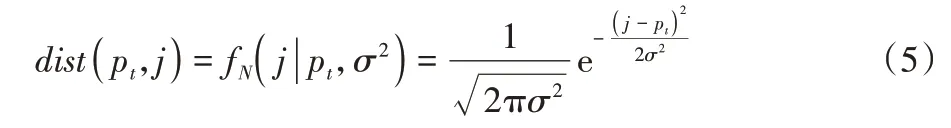
根据分数矩阵Sh∈RL×L和父词距离矩阵Dp∈RL×L可得到父词融合矩阵Nh∈RL×L:

利用解析完成的父词信息,构建子词权重矩阵C∈RL×L,此权重矩阵根据输入序列中每个词拥有子词的数量构建,式(1)给出了子词权重矩阵C的定义。
由图1 可知,子词权重矩阵C∈RL×L中存在过多的零元素,本文利用加入高斯噪声的方式处理这些零元素。为子词权重矩阵C∈RL×L中的元素添加高斯噪声,此高斯噪声是以ct为中心且方差为σ2、正态分布为N(ct,σ2)的概率密度的公式,(t,j)表示子词权重矩阵中的每个元素,利用这种方式可得到子词高斯权重矩阵Cg∈RL×L:
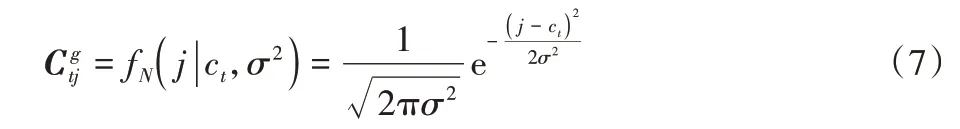
得到子词高斯权重矩阵Cg∈RL×L后,为提高模型的收敛速度,利用Softmax 函数对矩阵进行归一化处理,得到子词依存矩阵Cs∈RL×L:

根据父 词融合矩阵Nh∈RL×L和子词 依存矩 阵Cs∈RL×L,可得到子词融合矩阵Zh∈RL×L:

最后,应用Softmax 函数为句子中的每个标记生成权重分配,再将得到的子词融合矩阵Zh∈RL×L与值矩阵Vh∈RL×d相乘,获得双向依存自注意力机制头的最终表示Mh。
由于本文模型将依存标记融合到了翻译模型中,因此在计算损失L时,使用交叉熵损失函数,如式(10)所示:

其中:li表示第i个父词的标记,正类为1,负类为0;pi表示第i个样本为正的概率。
本文同时利用子词到父词和父词到子词方向的信息且无需配置其他额外的训练参数。Dp∈RL×L的距离仅取决于父词的位置向量,子词权重矩阵Cs∈RL×L只取决于每个词在句子中拥有的子词数量。本文模型在构建子词权重矩阵时,无需使用外部解析器,可以在训练模型前节省大量对源语言进行解析的时间。双向依存自注意力机制模型是Bugliarello 等[6]的父母规模自注意力机制的扩展,本文加入了父词到子词方向的依存信息,增强神经机器翻译中子词对机器翻译的影响。
2.3 多头注意力机制
双向依存自注意力机制是对多头注意力机制中点积注意力机制的扩展,图2 展示了双向依存自注意力机制在多头注意力机制中的融合方法。本文在多头注意力机制中的融合方法进行了设计上的选择,实验结果将在3.5.2 节介绍。本文的双向依存自注意力机制仅在多头注意力机制的第1层的8 个头中进行融合,如图2 所示,编码器的整体结构并未更改,输入句子x进行词嵌入和位置编码后输入到多头注意力机制中,在多头注意力机制中,经过线性化的查询Q、键K、值V,父词位置向量P∈RL和子词权重矩阵C∈RL×L作为输入,输入到双向依存自注意力机制中,得到每个头的最终表示Mh。其余处理过程与基本的Transformer 模型相同,未对编码器其他位置进行改变。双向依存自注意力机制融合到了多头注意力机制的8 个头中,且只在第1 层融合双向依存自注意力机制取得最好的效果,这在本文随后的实验中得以验证,证明了双向依存自注意力机制的有效性。

图2 多头注意力机制Fig.2 Multi-head attention mechanism
2.4 双向依存信息忽略
根据Bugliarello 等[6]的方法,由于缺乏与标准解析工具平行的语料库,因此本模型的父词依存知识依赖于外部依存解析工具的结果;但根据Dredze 等[19]的研究,对域外数据进行评估时,依存解析工具的性能会下降。为防止本文模型过度拟合到嘈杂的依赖性,本文为双向依存自注意力机制引入了两种正则化的技术,分别是父词信息忽略和子词信息忽略的方法。这种方法与Srivastava 等[20]的dropout 方法类似,会在模型训练阶段忽略一定的父词和子词信息。通过以一定的概率q,将父词 距离矩 阵DP∈RL×L和子词 依存矩 阵Cs∈RL×L中的每一行随机设置为1 ∈RL来忽略父词的位置信息和子词的依存信息。这两种正则化技术的引入可以生成不同父词距离矩阵和子词依存矩阵,使模型学习不同的矩阵形式,最终通过取平均的策略,防止过拟合的问题。
3 实验与结果分析
3.1 实验数据
为验证本文提出的基于双向依存自注意力机制的神经机器翻译融合方法,本文分别在汉-泰、汉-英,英-德上进行了双向翻译实验,并压缩了汉-泰和汉-英的训练数据进行了双向翻译实验,其中:汉-泰语料是通过互联网爬取的106万的平行语料,分成训练集、验证集和测试集;汉-英语料为CWMT 语料库,该语料库由801 万个句子对组成,作为训练集,使用newsdev2017 作为验证集,使用newstest2017 作为测试集;英-德语料为IWSLT14 的英德语料库,该语料库由17.4 万个句子对组成,作为训练集和验证集,使用newstest2015 作为测试集。压缩后的汉-泰和汉-英训练数据为20 万的平行语料,用汉-泰小和汉-英小表示,如表1 所示。
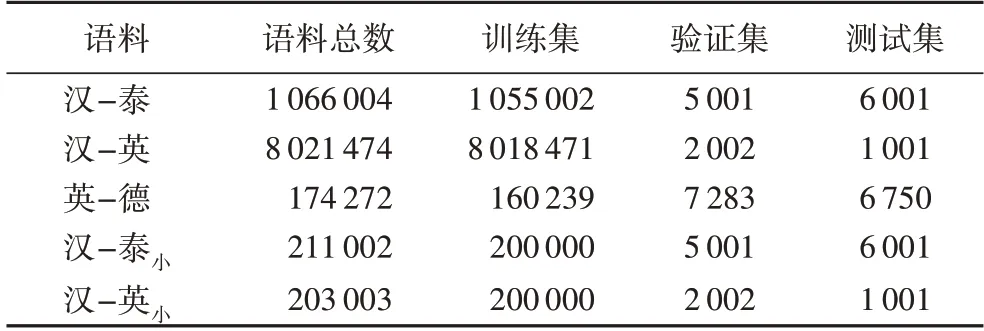
表1 数据集详情Tab.1 Details of datasets
3.2 数据预处理
本文模型采用和Vaswani 等[18]相同的预处理步骤,使用Koehn 等[21]提出的Moses 模型对数据进行标记,并从源语言端和目标语言端删除了超过80 个标记的句子,步骤如下:
1)数据筛选。首先删除超过80 个标记的句子,之后删除存在乱码的数据,最后通过人工筛选删除存在错误的句子。
2)分词。对于汉语本文使用jieba 分词,对于泰语使用JointCut 进行分词,对于英语和德语,本文不将其分为字符级。
3)依存句法解析。汉语使用LTP 语言云平台进行分词和依存解析,泰语利用spaCy-Thai 进行分词和依存解析,英语和德语使用Stanford CoreNLP 进行依存解析。为保证分词结果与依存解析的结果可以一一对应,本文在进行依存解析前,不对源语言句子进行分词,直接利用依存解析工具的分词结果来保证模型的输入不会发生错误。
4)字节对编码(Byte Pair Encoding,BPE)。本文采用BPE 大小均为1.6 万的词表。
3.3 模型参数设置
本文模型是基于Transformer 模型的扩展,使用Fairseq 工具包中的PyTorch0.4.1 实现本文的模型。根据Papineni等[22]提出的通过小格网络搜索的方法,利用BLEU 值作为本文的评价指标。本文选择Transformer 和Pascal 作为对比实验的基准模型,实验分别基于Transformer 架构。所有实验均在单个NVIDIA RTX 2070 SUPER GPU 上进行。本文使用Vaswani 等[18]最新的Tensor2Tensor 中的超 参数设 置,按 照Vaswani 等[18]的学习时间表进行了4 000 个warm-up 优化。类似于Szegedy 等[23]的研究,在训练过程中使用的标签平滑率为0.1。在验证时使用和Wu 等[24]类似的波束大小为4 且长度罚分为0.6 的波束搜索。本文采用的学习率为0.000 7,批次大小max-tokens 为4 096,dropout 为0.3。在压缩数据的实验中,本文采用了8 000 个warm-up 优化。
3.4 实验结果
本文分别在汉泰数据集、CWMT 汉英数据集、IWSLT14英德数据集和压缩后的汉泰、汉英数据集上进行了实验,实验结果如表2 所示。

表2 不同模型双向翻译的BLEU结果Tab.2 BLEU results of bidirectional translation among different models
由表2 可见,Bi-Dependency 在汉-泰双向翻译中,BLEU相较于Transformer 的翻译结果提升了1.07 和0.86;在汉-英翻译任务上,Bi-Dependency 的BLEU 也显著提升了0.79 和0.68;在英-德上,Bi-Dependency 的翻译结果与Transformer相比虽有提升但不显著。在压缩数据集后,Bi-Dependency在汉-泰双向翻译中,BLEU 与Transformer 模型相比分别有0.51 和1.06 的提升。在汉-英翻译任务中,BLEU 分别提升了1.04 和0.40。从表2 可进一步分析出,汉-泰的翻译整体效果较差,这可能是由于在泰语和汉语进行分词时,汉语和泰语的词无法较好地对应,使得模型在学习时存在较大的偏差;而英-德上,Bi-Dependency 的翻译结果提升并不明显,这可能由于目前的Transformer 模型在英德上的翻译比较成熟,Transformer 模型可以较好地学习到英语和德语的句法结构,从而使得融合双向依存知识的方式翻译效果不显著。本文通过融合双向依存知识,在富资源和低资源情况下的翻译质量均有一定的提升,说明本文提出的双向依存自注意力机制是有效的。
3.5 实验分析
为验证本文提出的基于双向依存自注意力机制的汉泰神经机器翻译方法的合理性,分别设计了双向依存信息、多头注意力机制不同的层中融合双向依存信息和高斯权重函数对模型翻译效果的影响实验。
3.5.1 双向依存信息对翻译结果的影响分析
为验证融合源语言双向依存信息的作用,本文在汉-英数据集上进行了融合双向依存信息的有效性实验。定义“Transformer+CWord(Child Word)”表示只融合依存知识中父词到子词方向的信息;定义“Pascal”表示只融合依存知识中子词到父词方向的信息;定义“Bi-Dependency”表示本文模型框架,实验结果如表3 所示。
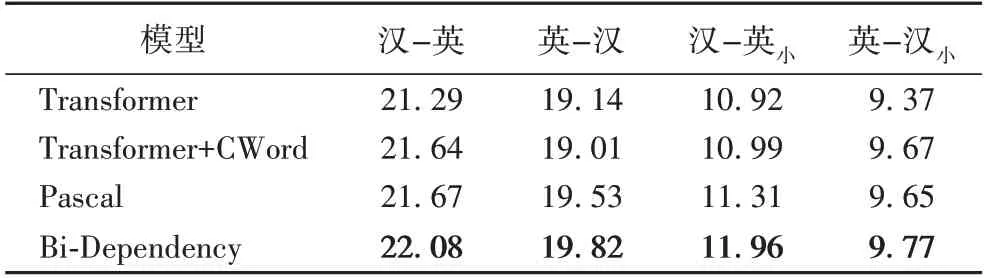
表3 融合单/双向依存信息的BLEU值对比Tab.3 BLEU values comparison of fusing with unidirectional-/bidirectional-dependency information
由表3 的实验结果可以看出,Bi-Dependency 取得了最好的结果:在汉-英的翻译任务上,与Transformer+CWord 模型相比,BLEU 分别提升了0.44 和0.81,与Pascal 模型相比,BLEU 分别提升了0.41 和0.29。在压缩数据集上,Bi-Dependency 的BLEU 值同样有较大的提升。根据以上的结果可以看出,在源语言端融合依存知识与基本的Transformer模型相比均有显著的提升,说明在源语言端融合依存句法知识对翻译任务是有帮助的。Transformer+CWord 和Pascal 的BLEU 值差距很小,说明在源语言端融合依存知识中的父词或子词的翻译效果无明显差距。这可能是由于在机器翻译任务中,融合子词到父词的单向信息和父词到子词的单向信息属于相同类型的融合方式;因此,在源语言端,只融合子词到父词信息与只融合父词到子词信息的效果大致相同。本文提出的Bi-Dependency 翻译模型在汉-英的双向翻译任务上取得了最高BLEU 值,获得了最好的翻译效果,说明在源语言端融合双向依存知识对神经机器翻译任务具有较大的帮助。
3.5.2 多头注意力机制不同的层中融合双向依存信息对翻译结果的影响分析
根据Bugliarello 等[6]的研究,本文也在汉-英数据集上,在多头注意力机制不同的层上进行了双向依存自注意力机制层实验,以验证在第几层融合双向依存知识是更加有效的,实验结果如表4 所示。
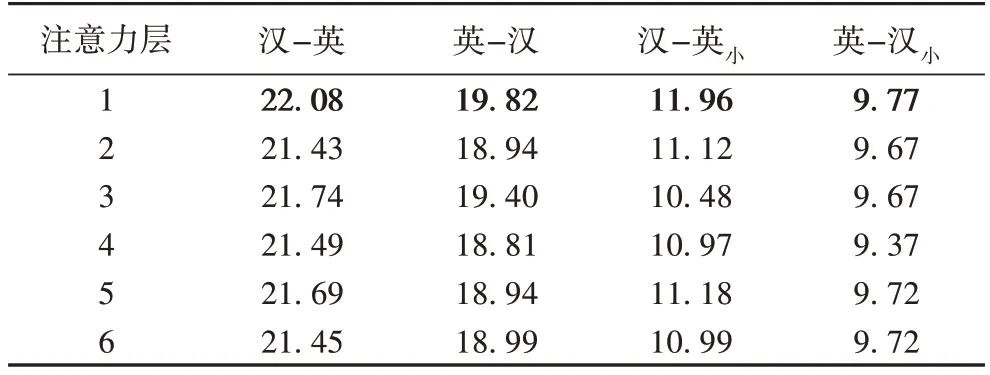
表4 不同注意力层中融合双向依存信息的BLEU值对比Tab.4 BLEU values comparison of fusing bidirectional-dependency information in different attention layers
表4 展示了双向依存自注意力机制在多头注意力机制不同层上的实验结果。通过表4 可知,Bi-Denpendency 模型在多头注意力机制的第一层融合双向依存句法知识取得了最好的效果。与最低的结果相比,在汉-英的翻译任务上,分别提升了0.65 和1.01 个BLEU 值。压缩数据后,分别提升了1.48 和0.40 个BLEU 值。当Bi-Dependency 放置在较 低层时,模型在测试集上的性能会明显降低。这样的结果证实了Raganato 等[25]的发现:在第一层中更多的注意力仅集中在需要翻译的单词本身上,而不是其上下文。由此可以推断出,在第一层融合句法相关性可以有效地学习单词表示,从而进一步提高Transformer 模型的翻译准确性。
3.5.3 高斯权重矩阵对翻译结果的影响分析
为了验证在子词权重矩阵中添加高斯噪声的作用,本文在汉-英数据集上进行了高斯权重矩阵实验,定义“Bi-Dependency-GWF(Gaussian Weight Function)”表示子词权重矩阵中不添加高斯权重函数,实验结果如表5 所示。

表5 添加高斯噪声前后的BLEU值对比Tab.5 Comparison of BLEU values before and after adding Gaussian noise
根据表5 可知,Bi-Dependency 取得了最好的效果。在汉-英的翻译任务上,与Bi-Dependency-GWF 相比,分别提高了1.26 和0.87 个BLEU 值。在压缩数据集上,分别提高了2.01 和1.37 个BLEU 值。而Bi-Dependency-GWF 模型与 基本的Transformer 模型相比同样存在较大的差距,分别下降了0.47 和0.19 个BLEU 值,压缩数据集后同样出现了明显的下降。因此在双向依存自注意力机制中不添加高斯噪声的翻译结果有明显的下降,结果低于Bi-Dependency 和Transformer模型。由此可以证明高斯噪声的添加是必要且有效的。不添加高斯噪声时,翻译结果出现下降,本文认为这可能是由于子词权重矩阵中过多的0 元素在与父词融合矩阵Nh∈RL×L进行点乘时,使得生成的子词融合矩阵Zh∈RL×L中出现了过多的0 元素,从而对原本的父词融合矩阵产生了大量的噪声,使得翻译效果出现了明显的下降。
4 结语
本文针对神经机器翻译任务,提出了双向依存自注意力机制(Bi-Dependency)。实验结果表明,通过在多头注意力机制中融合双向依存知识的方式,对神经机器翻译任务的质量有一定的提升;通过对比实验证明,利用双向依存知识可以给翻译模型提供更丰富的依存信息,同时这种方式对低资源翻译任务同样是有效的。通过实验结果也可看出,目前汉泰神经机器翻译的总体效果较差,这可能是由于泰语分词效果较差和实验设备限制导致的,因此,如何更好地针对汉语和泰语的特性将会是未来的研究重点。
