基于图卷积网络的文本分割模型
2022-12-18杜雨奇
杜雨奇,郑 津,王 杨,黄 诚,李 平
(西南石油大学 计算机科学学院,成都 610500)
0 引言
网络时代的信息量呈爆炸性增长,如何从这些资源中提取出有用的信息成为了一项巨大挑战,文本分割任务应运而生。1997 年,Hearst[1]将按照主题或子主题相关的原则把文本划分为若干个文本单元块的任务称为文本分割。其宗旨是识别到文本中的主题过渡,从而可以将文本分割为若干个具有不同主题的文本片段,即文本块。每一个文本块中的内容在语义上都是紧密联系的,属于同一个子主题,而不同文本块之间的语义联系相对较薄弱,主题有所差别。良好的分割结果可增强文本的可读性,任务所得的文本块可应用于众多自然语言处理(Natural Language Processing,NLP)的下游任务,例如自动文本摘要[2-3]、信息检索[4-5]、情感分类[6-7]或对话建模[8-9]等。
目前,文本分割作为一个基础但复杂的自然语言处理任务,面临了诸多挑战。由于其任务的特殊性,文本分割需考虑到3 个方面的内容:1)文本的结构信息,即文本的层次性。文本中包含了多个子主题,并且位置相邻的两个自然段、句子和词之间都有其结构关联。2)文本要素(词、句子或自然段)的语义信息。挖掘语义关系是自然语言处理任务的核心之一。3)文本要素之间的上下文关联。上下文关系可以增强文本要素的嵌入表达,并且符合文本分割任务的定义要求。
针对以上三项主要挑战,本文提出了一种基于图卷积网络(Graph Convolutional Network,GCN)的文本 分割模 型TS-GCN(Text Segmentation-Graph Convolutional Network),利用图的拓扑结构来对这些信息进行融合表达,图的节点为每个自然段,图的边为自然段与自然段之间的关系。受图注意力网络(Graph Attention Network,GAT)[10]工作的启发,在构建逻辑关系时引入了注意力,对邻居节点信息进行有侧重性的聚合。接着借助最近几年热门的图卷积网络来对自然段节点进行高阶邻域的信息传递。通过聚合后的节点表达,判断每一个自然段节点“是/否”为一个文本块的边界。对连续若干个自然段进行标签预测,即可将文本划分为对应的文本块。经过实验分析,该模型可以获得很强的分割性能,在保持运行速度的同时,达到了与目前最好的(State-Of-The-Art,SOTA)模型同级的分割效果。
本文的主要工作包含:
1)提出了一个基于图卷积网络的文本分割模型TS-GCN,对于文本分割任务提出了一个新的解决方向——图卷积网络,并通过实验结果验证了其有效性;
2)提出了一种构建文本邻接矩阵的思路,融合了文本的空间关系与逻辑关系,拓宽了图的边的类型,结合了更多方面的文本信息;
3)在逻辑关系构造方面,引入了语义相似性注意力,从而可以对邻域信息进行有侧重性地聚合。
1 相关工作
在深度学习发展之前,文本分割任务都是通过量化词汇相似性或词的衔接等方式来进行的。例如,1997 年,Hearst[1]提出TextTiling 模型;2000 年,Choi[11]提出C99 模型;2001 年,Utiyama 等[12]提出U00 模型。以上模型只能关注到一些词汇的表层统计信息,很难挖掘到语义信息等深层次的信息。
深度学习的出现为这个问题带来了转机,随着深度学习的发展,逐渐出现了一些利用深度模型进行文本分割任务的研究。例如,Li 等[13]提出用循环神经网络(Recurrent Neural Network,RNN)结合指针网络来判定分割边界;2018 年,Koshorek 等[14]通过两层双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)来对句子进行分割判定;2019年,Arnold 等[15]提出了SECTOR 模型,使用LSTM 预测句子主题和文本块边界;2020 年,S-LSTM(Segment pooling LSTM)[16]结合了以前的模型思想进一步提高了分割性能;同年,Lukasik 等[17]利用BERT(Bidirectional Encoder Representation from Transformers)和LSTM 实现了3 种新型分割模型;Xing等[18]提出一个分层注意力Bi-LSTM 模型用于主题分割;Wu等[19]将文本分割建模为使用带有条件随机场(Conditional Random Field,CRF)分类层的LSTM 序列标记任务。这一类型的模型利用RNN 以序列的方式来构建单词或句子的表示,可以获取到不同程度上的语义表达,但在上下文信息挖掘方面仍有所欠缺。
受以上所列的研究工作启发,部分研究人员意识到利用图的拓扑结构来表达文本数据的分布更佳。2016 年,Glavaš等[20]提出了GraphSeg 模型,GraphSeg 利用句子的语义相似度构造句子之间的无向图,并通过Bron-Kerbosch 算法计算最大团来划分文本块。通过这种方式构造出的图只考虑到句子之间的语义相似度,并且通过无监督算法来划分文本块的方式很难处理特定的任务和多尺度问题。2018 年,Yao 等[21]提出基于图神经网络的文本分类(Graph Convolutional Network for Text classification,TextGCN)模型,其实验结果有力证明了图卷积网络(GCN)在处理图结构信息方面的有效性。而Kipf 等[22]的原始GCN 在构建邻接矩阵时仅仅是对邻接关系进行累加,并没有考虑到节点之间的关系应该有侧重性。根据文本分割任务的特殊性,应当在不同邻域节点之间加以区分,可以在邻接关系的权重方面得以体现。例如,在一个文本块中,各自然段虽属于同一个子主题,但它们两两之间的相关度都有所不同,节点之间的影响力也有很大差别。
综上,为了解决文本数据的结构信息、语义信息以及上下文信息的挖掘问题,本文模型TS-GCN 能够提取到文本数据的空间性与逻辑性。如图1 所示,以P5 节点为例,TS-GCN引入了注意力,对其邻域信息进行有侧重性的聚合,邻居节点的大小与边缘厚度代表了目标节点对邻居节点的注意力强度,再通过图卷积网络结构聚合邻域信息,从而对节点信息进行有效表达。值得注意的是,TS-GCN 与TextGCN 所针对的任务有一定程度上的相似性,但两者在场景上区别较大。首先,TS-GCN 基于文本的结构信息和语义逻辑,在同一篇文本内进行自然段之间的分类;而TextGCN 是在不同的独立文档之间进行主题分类。从这一层面上来看,TS-GCN 需要更多地考虑到文本的细粒度特征,而TextGCN 作为对独立文档进行分类的模型,更重要的是挖掘到文本的整体特征表达。其次,相较于TextGCN,TS-GCN 在细节的处理上更加需要加强节点自身与节点之间的关系的表达,并且大量的注意力放在了对于邻接关系的表达上,TS-GCN 需要结合节点和边来进行特征汇聚;而在TextGCN 所针对的独立文档分类任务中,最后的融合表达并没有它在TS-GCN 的解决方案中那么重要。

图1 原始GCN与TS-GCN的对比Fig.1 Comparison between original GCN and TS-GCN
2 基于图卷积网络的文本分割模型
本文提出的基于图卷积网络的文本分割模型TS-GCN 包含3 个模块,结构如图2 所示。3 个模块分别为:1)图的构建。将自然段表示为节点,融合自然段之间的空间关系与逻辑关系来构建文本图的边,并且在逻辑关系表达方面引入了基于语义相似性的注意力。2)基于图的特征聚合。利用两个堆叠的GCN 层来对邻居节点特征和边特征进行聚合进而提高中心节点表达的准确性。3)分割预测。输出每个自然段是否作为分割边界的概率,并选择最大概率对应的标签作为其预测结果。
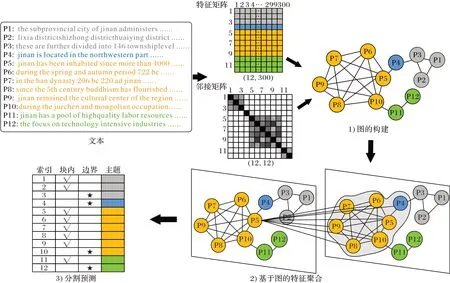
图2 TS-GCN整体流程Fig.2 Overall process of TS-GCN
2.1 图的构建
将自然段作为图的节点,自然段之间的关系作为图的边,文本图可记为Graph=(Vertices,Edges),Vertices代表自然段节点的集合,Edges代表节点与节点间的所有边的集合。构建文本图包括自然段节点特征初始化与边的构建两个部分。
2.1.1 节点特征初始化
将自然段作为节点,节点特征可通过自身初始化后的表征以及聚合邻居节点特征和边特征来融合表达。因此,首先需要对节点的特征进行初始化。通过引入fastText 在Wikipedia 2017、UMBC webbase 语料库和statmt.org 新闻数据集上训练的100 万个300 维词向量来表示每个自然段中的单词,再将一个自然段中所有单词的向量求平均来表示该自然段的嵌入,最终可以得到特征矩阵X。自然段嵌入表达的向量化处理过程如式(1)(2)所示:

其中:si为自然段中每个单词的300 维词向量,w代表该自然段中的单词总数,E为该自然段的嵌入表达,p为数据集中自然段总数,⊕表示拼接操作。
2.1.2 边的构建
在GCN 中,邻接矩阵代表着图结构信息,图结构特征也会对节点特征有一定的影响,因此边的构建至关重要。由于大部分文本分割模型在文本结构信息、语义信息和上下文信息挖掘方面存在不足,因此本文在构建边时对文本的空间关系与逻辑关系进行了融合,如图3 所示。

图3 边的构建Fig.3 Construction of edges
1)空间关系。空间关系的范围为整个文本数据集。由于选取的数据是多篇完整的文本,相邻的两个自然段之间有其整体结构和语义表达上的联系。空间关系又具体分为两种:第一种是两个自然段空间相邻并处在同一文本块中,存在这种关系的两个自然段的语义一定是紧密相关的;第二种是两个自然段空间相邻,但其中一个自然段是一个文本块的结束段,而另一个自然段是另一个文本块的起始段。由于分别属于两个不同的子主题,可以将存在这种关系的两个自然段看作主题过渡段,有其过渡语义的体现。空间关系的邻接矩阵SAij可用式(3)表示为:

2)逻辑关系。逻辑关系的范围为若干个文本块内。同一个文本块中的自然段在语义上应该紧密相关,并且属于同一个子主题,但它们之间也存在一些紧密性的区别,某两个自然段的联系可能会比其他自然段更强;因此,为了满足模型对文本块内关系的挖掘能力,本文在逻辑关系方面引入了语义相似性注意力,旨在捕获同一个文本块中自然段之间的不同相关度。逻辑关系的邻接矩阵LAij可用式(4)表示为:

其中α(i,j)为自然段i与自然段j之间的注意力值,计算方式如式(5):
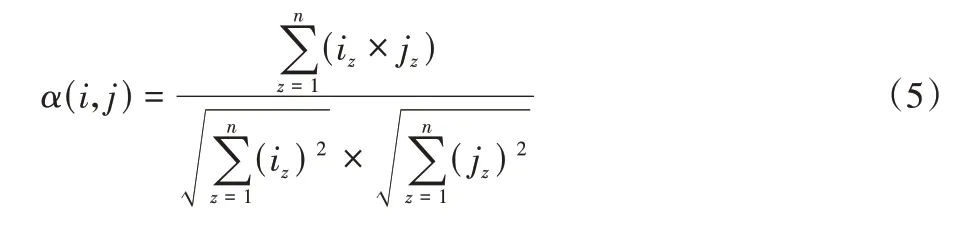
其中:n为节点的特征维度,iz和jz代表节点特征向量在每一个第z个维度上的数值。
3)融合表达。综合空间关系与逻辑关系,节点i与节点j之间的边的权值Aij可如式(6)定义为:

其中:μ(·)与ν(·)为指示函数,若i和j是空间相邻的,则μ(i,j)=1,反之为0;若i和j属于同一个文本块,则ν(i,j)=1,反之为0。
通过以上两种邻接矩阵的构建,文本的空间关系和逻辑关系可以得到有效的表达,应对了文本分割任务所面临的结构信息、语义信息和上下文关联挖掘的三项主要挑战。
2.2 基于图的特征聚合
在图的特征聚合方面,通过聚合邻居节点信息和边的信息来表达中心节点的信息,以此来对节点进行更准确的嵌入表达。通过图Graph=(Vertices,Edges),可以构造出:1)特征矩阵X。假设共有p个节点,每个节点用一个m维向量表示,则X矩阵的维度大小为p*m。2)邻接矩阵A。邻接矩阵汇聚了节点间的边的信息,由于每一个节点与其自身联系最紧密,因此设置了自环(self-loops)机制,且矩阵对角线上的元素均大于等于1。
本文模型采用了两个堆叠的GCN 层来对特征矩阵和邻接矩阵进行处理进而提取图的特征。节点接收聚合其邻域信息并对自身的嵌入进行表达,其中,激活函数分别采用修正线性单元(Rectified Linear Unit,ReLU)和Softmax,则整体的正向传播如式(7):
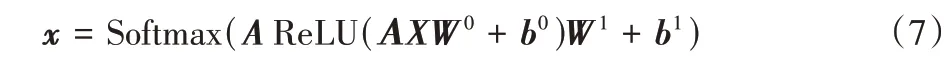
其中:X为特征矩阵,A为邻接矩阵,W和b是可学习的参数。
2.3 分割预测
类似于图2 中的P5 节点,通过GCN 层可以得到所有节点聚合后的特征表示,再经过一个Softmax 操作后,可以得到每个自然段是否作为分割边界的概率,计算如式(8)所示:

其中:xt为第t维的输出值;m为节点特征向量的维度,也是分类的类别个数。Softmax(xt)可以将输出值转换为取值在(0,1)范围内且和为1 的概率分布,选择最大概率对应的标签即可作为节点的预测结果。
3 实验与结果分析
3.1 数据集
实验中一共采用两个数据集:Wikicities 和Wikielements。这两个数据集均是在2009 年由Chen 等[23]制作完成。Wikicities 包括100 个关于主要城市的描述文档,主题大致包括历史、文化和人口信息等;Wikielements 包括118 个化学元素的描述文档,主题包括元素的生物学作用和同位素等。这两个数据集后来被广泛应用于文本分割任务,具体信息如表1 所示。
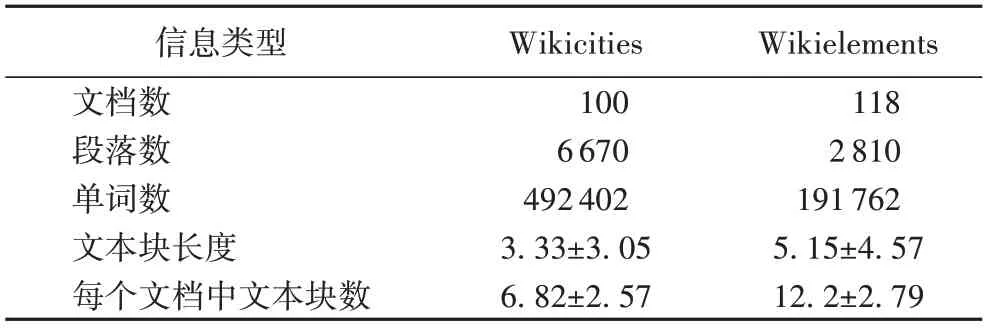
表1 文本分割数据集的统计信息Tab.1 Statistics of text segmentation datasets
3.2 评估指标
正如文本分割任务的定义所示,一个好的分割模型可以准确识别出数据集文本中连续自然段的分割边界,因此,本文研究的目标就是优化两个自然段被正确标记为相关或不相关的概率。图4 展示了文本分割的3 种结果。
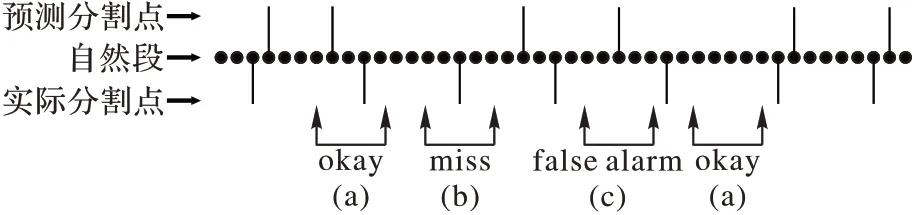
图4 文本分割的3种结果Fig.4 Three results of text segmentation
本文实验采用了文本分割任务的标准量化指标Pk值。1999 年,Beeferman 等[24]对Pk值进行了定义。设PD为从语料库中随机抽取的两个自然段被错判为属于不同或同一文本块的概率,其计算方式如式(9):
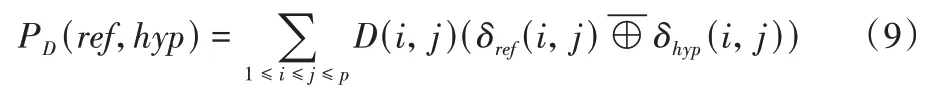
其中:p为数据集中的自然段总数量;ref为实际分割;hyp为预测分割;δref和δhyp代表指示函数,若自然段i与自然段j同属于一个文本块,则δref或δhyp为1,反之为0;代表同或门(eXclusive-NOR gate,XNOR)。D(i,j)代表距离概率分布,用来表示随机抽取的两个自然段之间的距离,距离越远,D值越小。由于距离的概率分布D(i,j)很难确定,Beeferman等[24]提出将D简化为Dk。取固定值k作为距离,一般将k设置为文本块平均长度的一半,即可得到间隔k个自然段的自然段对被错判为属于不同或同一文本块的概率值Pk。因此,由定义可知,Pk取值在0~1,Pk值越小,分割效果越佳。在本文实验中,通过调用SEGEVAL 包来计算Pk值。
3.3 实验设置
本文模型采用通过fastText 在Wikipedia 2017、UMBC webbase 语料库和statmt.org 新闻数据集上训练的300 维词向量作为单词的初始特征,并通过向量相加平均的方式来对自然段进行嵌入表达,词表外(Out Of Vocabulary,OOV)的单词通过从均匀分布中随机采样生成,隐藏层维度为64。
生成所需的特征矩阵与邻接矩阵后,通过两层堆叠的GCN 来对矩阵信息进行处理。在每层GCN 后接一层Dropout并设其为0.5。实验硬件为显存为16 GB 的Tesla T4,优化器选择Adam 且权重衰减系数为0.007,epoch 数设置为1 000,损失函数使用交叉熵,计算过程如式(10):

其中:x为经过Softmax 操作后的输出,c、h代表标签的索引值。
3.4 结果及分析
3.4.1 文本分割任务结果及分析
为了验证本文所提出的TS-GCN 的有效性,将TS-GCN 与其他文本分割基线模型进行对比。
表2 显示了TS-GCN 与其他基线模型在Wikicities 和Wikielements 两个数据集上的分割效果。Random 代表随机划定文本块;GraphSeg 模型通过Bron-Kerbosch 算法计算最大团来划分文本块;WIKI-727K 模型采用了两层Bi-LSTM 来对句子进行分割判定;TLT-TS(Two-Level Transformer model for Text Segmentation)[25]为一个双层Transformer 结构;CATS(Coherence-Aware Text Segmentation)模型是在TLT-TS 的基础上增加了一个文本连贯性辅助任务模块,即对模型预测的分割结果进行“破坏”(随机打乱顺序或替换其中的句子),再对正确的文本序列和“破坏”后的文本序列进行回归运算,进而通过损失优化得到可预测出更具备连贯性的分割结果的模型。表2 数据显示,在Wikicities 数据集上,仅相较于CATS(增加了文本连贯性辅助任务)而言,TS-GCN(未增加任何辅助模块)的表现稍有不足,但仍比CATS 的基础模型TLT-TS的分割指标低0.08 个百分点,原因在于Wikicities 数据集能够更好地适配该文本连贯性辅助任务模块;而在Wikielements 数据集上,相较于CATS 和TLT-TS,TS-GCN 的评价指标分别下降了0.38 个百分点和2.30 个百分点,优于其他所有基线模型,达到了SOTA 的效果,这也说明了该文本连贯性辅助任务在Wikielements 数据集上的作用不够明显。表2 数据表明,无监督模型的分割效果普遍弱于有监督模型。4 个有监督模型在Wikicities 数据集上的分割效果几乎持平;但WIKI-727K 模型在Wikielements 数据集上的结果与其他3 个监督模型的差距较大;而TS-GCN 在两个数据集上的表现比其他有监督模型更为稳定。这表明TS-GCN 提供了比其他对比有监督模型更稳健的域转移能力,具有应对更多主题类型的文本分割任务的实力。
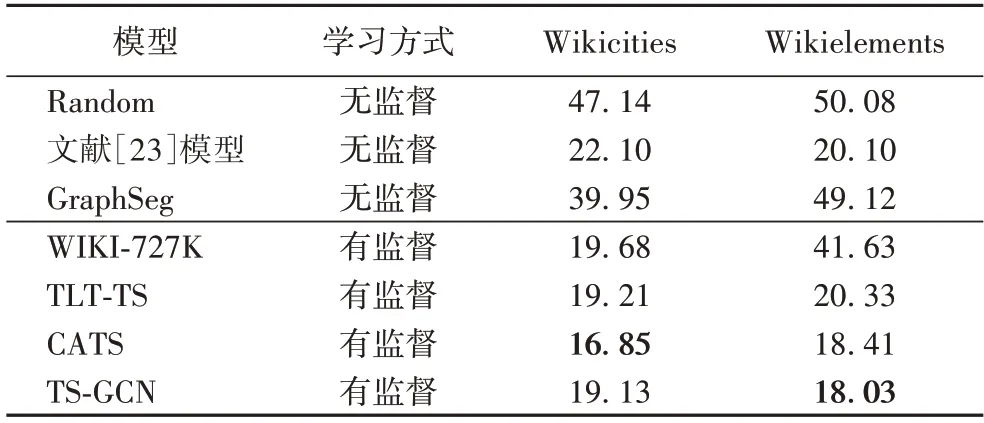
表2 文本分割任务中不同模型的Pk值对比 单位:%Tab.2 Comparison of Pk value among different models for text segmentation task unit:%
3.4.2 案例分析
本节将分割结果可视化来对模型效果进行评估分析。从Wikicities 的测试集中随机选取第42 篇文档中关于济南市的样本文本段来进行案例研究,人工标注与模型预测结果如图5 所示。其中:ref 指人工标注的分割结果,hyp(TS-GCN)与hyp(WIKI-727K)指分别通过TS-GCN 和WIKI-727K 模型获得的预测分割结果。
图5 显示,hyp(TS-GCN)与ref 并不完全一致,具体原因分析如下。
1)当文本中的自然段之间有很强的依赖性时,文本分割较为棘手,如图5 中第3 段与第4 段之间的边界丢失问题。图6 中展示的第3 段内容是“济南市被划分为146 个镇级分区,包括65 个镇、27 个乡和54 个街道”,第4 段讲述的是地理信息,而第5 段开始讲述济南市的历史。第4 段与第3 段之间的关联度高于与第5 段的关联度,因此模型更容易把第4段和第3 段划分到同一文本块中,而非将其单独作为一个文本块。

图5 Wikicities文本片段的TS-GCN和WIKI-727K模型的分割结果与人工标注结果的对比Fig.5 Comparison of segmentation results among TS-GCN and WIKI-727K models with manual annotation results for Wikicities text fragments

图6 Wikicities中济南文档的第3、4和5自然段Fig.6 The third,fourth and fifth paragraphs of Jinan document in Wikicities
2)当自然段属于同一文本块但子主题关联性不强时,也会造成一些误判情况。如图7 所示,虽然第11 段与第12 段都属于经济模块,但第11 段描述的是济南市的劳动力资源,且着重介绍了市内学校和学生的情况,而第12 段是济南市的生产业情况。由于这两个自然段内的词汇语义等信息距离较远,模型很容易判断两个自然段之间含有1 个分割边界。

图7 Wikicities中济南文档的第11和12自然段Fig.7 The eleventh and twelfth paragraphs of Jinan document in Wikicities
虽然上述两种现象未能涵盖所有的问题案例,但作为分割的难点,这些现象在文本分割任务中普遍存在,也是未来文本分割任务的重点研究内容。就目前的研究进展而言,TS-GCN 已经达到了较高的分割水平。如图5 所示,对相同的一段文本进行分割,TS-GCN 的分割结果比WIKI-727K 更为精准,miss 和false alarm 情况更少。
3.4.3 不同预训练词向量结果分析
表3 展示了TS-GCN 模型在3 种预训练词向量下的分割结果,以验证不同词向量对于模型效果的影响。

表3 不同预训练词向量下的分割结果 单位:%Tab.3 Segmentation results under different pre-training word vectors unit:%
表3 中的数据表明,针对本文中所采用的Wikicities 和Wikielements 数据集,wiki-news-300d 词向量在TS-GCN 模型上的效果优于GloVe-300d 与crawl-300d。其原因在于:1)相较于包含了fastText 在Common Crawl(超过7 年的网络爬虫数据集)上训练的200 万个词向量的crawl-300d,wiki-news-300d 是基于2017 年维基百科、UMBC webbase 语料库和statmt.org 新闻数据集训练的词向量,因此更多地获取到了关于维基百科的语义关系;2)相较于GloVe-300d,wiki-news-300d 使用了16B 个单词来进行训练,而GloVe-300d 只使用了6B,因此wiki-news-300d 能对Wikicities 和Wikielements 数据集中的词汇进行更为准确的表征。
因此,本文实验采用了wiki-news-300d 预训练词向量以达到更准确的分割效果。
3.4.4 GCN层数对比分析
由于GCN 只能聚合一阶邻居的特征,但较少的GCN 层数会导致模型无法获取到远距离的节点特征,无法获得更为宏观的图信息,所以通常会采用多层GCN 的结构来进行信息汇聚。然而,随着网络层数和迭代次数的增加,同一连通分量内的节点表征会趋向于收敛到同一个值。因此,本文通过实验验证了GCN 层数对模型的分割性能的影响。
图8 展示了不同GCN 层数下的TS-GCN 模型所产生的Pk值。从图8 中可以看出:
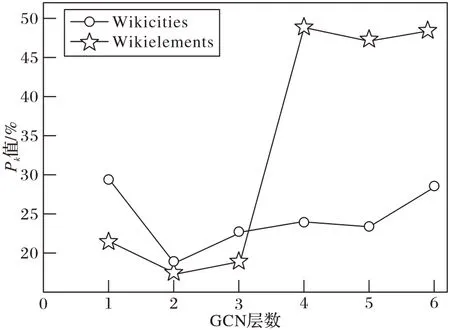
图8 不同GCN层数的分割结果对比Fig.8 Comparison of segmentation results with different GCN layers
1)最小的Pk值对应的是两层堆叠的GCN,Pk值随着层数的增加而增加。当只有1 层GCN 时,模型只能聚合到一阶邻居特征,导致节点聚合的信息量不足,不能对节点进行有效地聚合和分类。当GCN 层数增加到2 时,第1 层用于将节点特征映射为节点隐层状态,第2 层用于将节点隐层状态映射为相应的输出,Pk值达到最低点。随着层数不断增加,节点特征不断聚合直至收敛,而不能表示出所需要的局部结构特征,导致模型无法对节点进行有效区分。
2)层数不超过3 时,Wikielements 数据集上的Pk值低于Wikicities;当层数大于3 时,Wikielements 的Pk值陡增至接近50,Wikicities 的Pk值虽有上升趋势,但整体上升幅度并不大。原因在于Wikielements 的数据量比Wikicities 小很多,更容易产生过拟合现象,因此层数越多更容易加快节点表征的收敛。
3.4.5 注意力可解释性分析
TS-GCN 模型在构建文本的逻辑关系时引入了语义相似性注意力,取得了较好的分割效果。表4 展示了不采用注意力和采用不同注意力计算方法后的分割结果,以验证它对于TS-GCN 的作用效果。
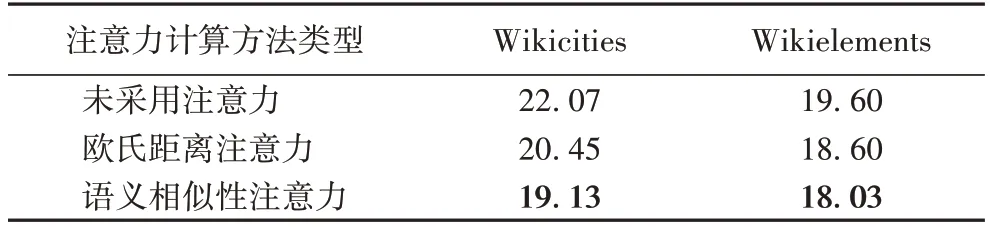
表4 不同注意力计算方法下的分割结果 单位:%Tab.4 Segmentation results of different attention calculation methods unit:%
为了证明在本文模型中引入注意力的重要性和有效性,进行了未采用注意力的对比实验,将文本块中的每两个自然段之间的权重记为1,即可直接加强文本块内两两自然段间的相关度。并且,在不同注意力的效果对比方面,引入了基于欧氏距离的注意力,计算过程如式(11)所示。其中:dist(i,j)为自然段i和自然段j之间的欧氏距离,计算过程如式(12);dist_sum(i)为自然段i与其对应文本块中所有自然段之间的欧氏距离总和。语义相似性注意力计算过程见式(5)。

实验结果表明:1)采用不同的注意力计算方法下的分割效果均优于不采用注意力,证明了注意力在文本分割任务中的重要性;2)在向量空间中,欧氏距离注意力侧重于向量的大小,而本文所采用的语义相似性注意力更关注向量的方向。在同样引入注意力的情况下,语义相似性注意力取得的分割效果最佳。
4 结语
本文结合文本分割任务的定义和特点,针对现有分割模型提取文本段落结构信息、语义相关性及上下文交互等细粒度特征的不足,提出了一种基于图卷积网络的文本分割模型TS-GCN。该模型融合了文本的结构信息和语义逻辑,利用图卷积网络来对文本进行分割预测;通过在Wikicities 和Wikielements 两个数据集上的实验结果表明了TS-GCN 模型的有效性;但同时也存在一些可进行延伸研究的方面,例如对于更细粒度层面的分割还需要进行进一步的研究。在接下来的研究中,将会引入更适用于文本分割任务的注意力,进而提高模型提取节点表征的能力。
