基于改进YOLO_v3-SPP的无人机图像目标检测系统与实现
2022-12-16刘永峰沈延安李从利
刘永峰,沈延安,韦 哲,李从利
(1 陆军炮兵防空兵学院兵器工程系,合肥 230031;2 陆军炮兵防空兵学院无人机应用系,合肥 230031)
0 引言
当前,军用无人机已成为现代战争中不可忽视的空中力量,世界各国都将其置于优先发展的地位。利用其携带的可见光/红外成像设备对战场目标进行检测与识别,是无人机的主要功能之一。但由于军用无人机飞行的特殊性和战场环境的复杂性,使得无人机图像具有以下特点:无人机飞行高度一般在3~5 km,导致在对地面特定目标(如装甲目标、民用车辆、人员等)进行搜索时,目标在视场中所占的像素比例较小、特征信息少;成像设备在拍摄时会受到低空的云层、烟雾的遮挡,同时成像平台处于抖动状态,造成成像质量较差;无人机飞行高度、角度实时变化,加之成像设备采用变焦技术,使得目标在图像中的尺度变化大;飞行次数有限,造成军事目标样本数据量少。以上特点给无人机图像目标检测带来了一定的挑战。
现阶段,基于深度学习的目标检测技术正蓬勃发展[1-2],可分为两类,一类是两阶段(two-stage)检测算法,此类算法在检测时首先进行区域生成(region proposal,RP),即首先确定一系列可能包含待检物体的候选建议框,再通过卷积神经网络分别对候选框进行分类和定位的回归操作,这类方法检测精度高但处理速度较慢,常见算法有R-CNN,SPP-Net,Fast R-CNN,Faster R-CNN[3-6]等;另一类是单阶段(one-stage)检测算法,这类算法不再使用区域生成,而是直接在网络中同时实现对目标的分类和定位任务,达到端对端的检测,因此检测速度快,但检测精度较低,常见算法有OverFeat,YOLO_v1,YOLO_v2,YOLO_v3,SSD[7-9]等。无人机实施空中侦察时,需快速检测在视场中是否存在军事目标,要求检测算法必须具备实时性,因此后者更适用于实时性较高的无人机图像目标检测问题[10-12]。
黄梓桐等[13]提出了改进SDD的无人机图像行人与车辆目标检测方法,通过减小网络通道与卷积量、提出感受野和上下文模块以提高目标检测的实时性和准确性。郭智超等[14]改进了SDD网络,增加了特征层数量并增强了各层间的关联,从而提高了目标检测精度。于博文等[15]提出了改进YOLO_v3的算法,引入可形变ResNet50-D网络、双注意力机制和特征重构模块以提升目标表征能力,同时改进了损失函数,以提高检测精度和速度,并在自建军事目标数据集上进行了验证。黄文斌等[16]提出类别均衡化和随机场景组合的数据增强训练方法,提升了训练效率和模型精度,并提出了模型压缩方案,在通道剪枝基础上对残差层修剪,提升了目标检测速度。但是,以上方法存在一定的误检率,这对军事目标检测而言影响较大,同时缺乏在嵌入式计算平台上的探索研究。
文中提出了一种基于改进的YOLO_v3-SPP目标检测算法,并在此基础上引入异常检测的思想,剔除误检目标,提高目标检测精度,并将算法移植到嵌入式计算平台。
1 YOLO_v3-SPP目标检测算法
YOLO_v3-SPP网络的具体结构如图1所示。网络使用DarkNet-53对输入图像的特征进行提取,整个结构里没有全连接层。图像在前向传播时,输出特征的尺寸压缩是通过改变卷积操作的步长(stride)来实现的。另外在DarkNet-53中由于引入了residual结构,训练深层网络难度大大减小,同时检测精度也有了明显的提升。DBL模块为检测模型的基本组件,其组成结构为Conv2d+BN+Leaky relu。
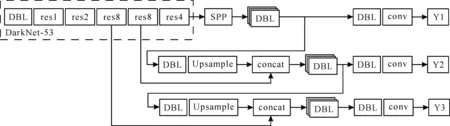
图1 YOLO_v3-SPP网络

图2 SPP模块
特征图经过局部特征与全局特征相融合后,丰富了特征图的表达能力,有利于待检测图像中目标大小差异较大的情况,尤其是对于复杂的多目标检测,对检测精度有很大的提升。
该网络结构中,损失函数定义为:
(1)

由于无人机图像的特点和战场环境的特殊性,运用该网络进行目标检测时,会存在一定的漏检和误判概率,对作战指挥、侦察等产生不良影响。
2 算法改进
为解决漏检及误判问题,在原网络结构上针对侦察无人机图像的特点进行了相应的改进。
2.1 基于多尺度特征融合的YOLO_v3-SPP网络
为提高目标多尺度检测的准确度,在网络结构上选择了更多特征尺度上的信息融合,使得网络在检测时可以提取到更多尺度信息。将DarkNet-53中的第3、第4卷积层的信息经下采样后,送入网络中进行融合,可更多提取到局部和全局特征,有利于对目标差异较大时的检测,如图3所示。
大数据最典型的特征是多源异构。原始数据中会包含一些“脏数据”,比如离群点,值缺失等状况。因此首先需要进行数据的预处理和集成,为将来的数据分析和挖掘提供方便处理的数据集。目前市面上常见的方法大体可分为4类:基于物化或ETL引擎方法、基于联邦数据库或中间件方法、基于数据流引擎方法以及基于搜索引擎方法。
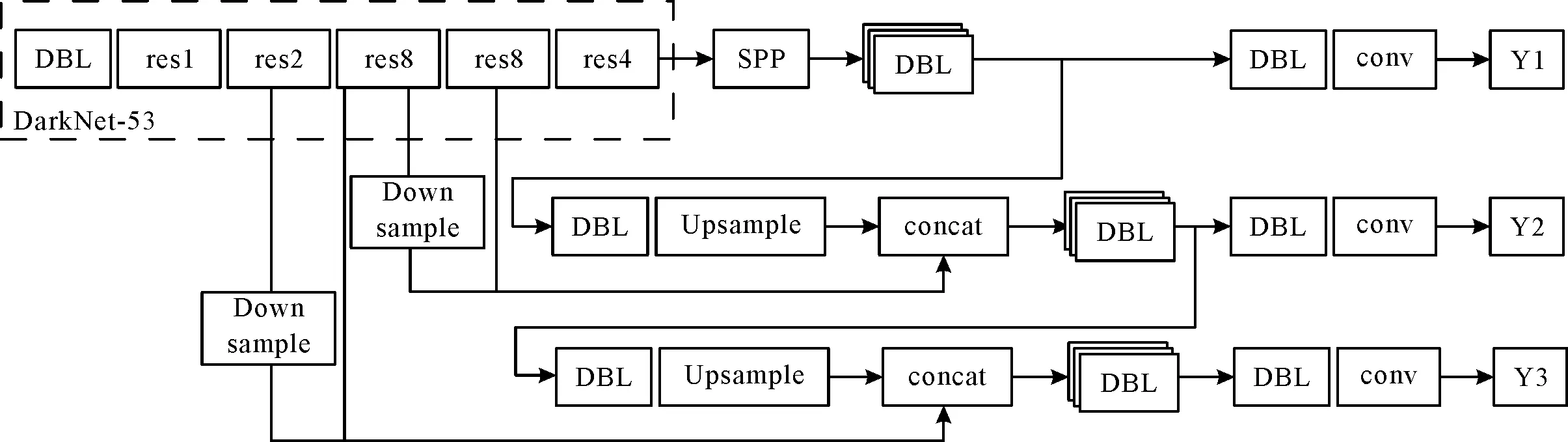
图3 基于YOLO_v3-SPP改进的网络结构
另外,在损失函数部分修改了YOLO_v3-SPP中采用IoU计算边界框损失的方法,将其替换为CIoU的损失计算方法。CIoU的表达式为:
(2)
式中:b,bgt分别代表预测边界框和目标框的中心点;ρ代表计算预测框与真实框的中心点间的欧式距离;c代表能够同时覆盖两个框的最小矩形的对角线距离;参数α和v的表达式为:
(3)
(4)
式中:α用于平衡比例的参数;v用来衡量anchor框和目标框之间的比例一致性。
2.2 增加深度异常检测的目标检测网络
为解决检测过程中的误判问题,在检测网络输出前增加了异常检测网络模块,通过预先训练网络的模型,对检测网络输出的结果进行二次判定,判断其是否属于检测目标或背景,经过阈值筛选,降低网络的误判率。
深度单类分类通过学习神经网络映射输出空间中心c附近的标称样本来进行异常检测,从而导致异常被映射出去。这里使用超球面分类器(HSC)为损失函数[17]:

(5)
式中:yi为对应的标签,yi=0表示正常样本,yi=1为异常样本;Xi为第i个样本;c∈Rd为预先设定的中心,这里简单地置0;φ(·):Rc×h×w→Rd为单类分类网络,权值为ω;c,h,w分别为输入图像的通道数、高、宽;d为输出特征向量的维度。
(6)
当输入正常样本时,损失函数第二项为0,φ(·)倾向于将其映射到c附近,从而使第一项趋于0;当输入异常样本时,损失函数第一项为0,φ(·)倾向于将其映射到远离c,h(a)→∞,从而使第二项趋于0。
设计的异常检测网络φ(·)结构如图4(a)所示,输入图像经过一层7×7的卷积层,进入以ResNet-50为主干网的卷积层,得到特征。其中,ResBlock模块结构如图4(b)所示,C表示通道数。训练时,通过标签计算损失,并以梯度下降更新网络参数。

图4 异常检测网络结构
训练的正样本为数据集标注的军事目标子图,负样本包含两部分:数据集中人工选取的背景子图,以及在外部航拍数据集中随机采样的子图,保证正负样本数量均衡。使用SGD作为优化算法,批量为512,进行40轮训练。结束后,由于h(·)预测越大,表示负例的可能性越大,但判断的阈值并未确定,因此需对预测的正负样本阈值进行遍历,选取使判断正确率最大的阈值thresh。测试时,当对样本的预测大于thresh时则认为是误检,并在最终结果中去除。
图5即为改进后的目标检测网络结构。输入图像经过改进的YOLO_v3-SPP网络后,输出检测到的输入图片的目标信息及边界框信息,即中间结果,该信息送入异常检测网络后,网络根据标注的边界框信息,提取出目标区域,对该区域进行特征提取,并计算出异常得分,算出得分后与选定的阈值进行对比,如果得分大于阈值,就证明该边界框中包围的是背景而非目标,如果得分小于阈值,就证明该边界框内确为检测目标,经过全部判定以后,最终输出检测结果。

图5 文中方法框图
3 实验结果与分析
3.1 数据集与实验条件
由于军事侦察图像样本的特殊性,基本没有公开的含有大量军事目标的侦察图像数据集。因此,首先在公开的航拍图像数据集DOTA[18]上对网络进行预训练。在训练前首先对图像进行裁剪,从而提升读取和写入速度,便于模型快速迭代。为提升算法的鲁棒性和推广泛化能力,采用了镜像、缩放、旋转等数据增广策略。模型收敛后,在自建的小样本军事目标数据集上进行迁移学习,共搜集了约2 000张含装甲目标的航拍图像,主要取自侦察无人机、民用无人机及军事仿真软件平台上所获取的图像,并将标注好的图像按8∶2的比例划分为训练集和验证集。
对于异常检测网络训练集,应区分正负样本,正样本根据DOTA数据集中的标注信息,截取了约2万张目标实例样本做正样本,同时截取2万张背景做负样本。
实验用设备为超微工作站,GeForce RTX 2080Ti GPU,20核intel Xeon E5-2630v4 CPU。
3.2 模型训练
训练改进的YOLO_v3-SPP网络时,在预训练后,利用自建小样本数据集进行微调,设置学习率为0.000 1,最大迭代轮次(epoch)为100,学习率分别在25个epoch、50个epoch、75个epoch时衰减10倍。
训练异常检测网络时,经过40轮训练,获得了收敛网络模型。在验证集上对阈值thresh进行遍历,发现当thresh取0.81时,异常检测网络的判定准确度最高(90.833%),故选择该值为最终测试的阈值。当应用于其他场合时,需根据训练数据调整。
3.3 实验结果分析
由于文献[13-16]没有公开源码,这里仅与YOLO_v3-SPP网络进行对比实验。
在DOTA数据集上的检测结果对比如表1所示。可以看出,改进后的网络的平均精度(mean average precision, mAP)相对于原网络有了一定的提升。

表1 DOTA数据集上的检测结果对比 单位:%
在真实数据上的检测效果如图6所示。测试发现,当无人机上成像设备的焦距发生较大变化时,原网络存在漏检和误判行为,而文中方法改进了YOLO_v3-SPP网络,增加了更多尺度特征融合,降低了目标漏检率,同时增加了异常检测网络,一定程度剔除了误检样本,从而有效提高了目标检测率。

图6 真实数据实验结果
4 系统实现与测试
4.1 系统实现
选用华为Hi3559AV100作为硬件计算平台,该平台集成了两个神经网络推理机(neural network inference engine,NNIE),可实现并行计算。系统外形尺寸为185 mm×150 mm×30 mm,平均功耗6 W。将文中算法以caffe工具为模型框架,转为wk模型并运行在该平台上,实现目标检测功能。
为提高平台计算速度,当输入图像大小为1 920像素×1 080像素时,首先在Image Subsystem中被压缩为740像素×416像素,随后被分切为两幅416像素×416像素尺寸图像并交给两个NNIE开始并行计算,由此将每一帧数据处理耗时降低到40 ms以下,满足视频检测需求。
4.2 系统测试
为检验系统效果,自建了目标检测测试集。测试集由1 000幅图像组成,图像成像高度2 500~4 500 m,距离目标3~6 km,包含民用车辆、装甲车、人员3类目标,标注约4 500个目标样本,如图7所示。

图7 测试集示例
利用自建测试集对系统进行测试,对民用车辆、人和装甲车的检测准确率分别为92.7%、83.2%和96.3%,平均交并比为84.4%。对3类目标的平均漏检率和误检率分别为0.2%和1.3%,与YOLO_v3-SPP网络(硬件条件相同)相比,分别降低了1.1%和4.5%。
同时,系统对视频中的目标检测效果良好,移动目标检测框与实际位置像素偏移平均值为9.6行(列)。系统测试效果如图8所示。

图8 系统测试效果
5 结论
针对无人机图像的特点,在YOLO_v3-SPP网络的基础上进行了改进,主要包括多级特征融合、损失函数,在检测网络后增加异常检测网络进行二次筛查等。经过改进后,在公开DOTA数据集上进行验证,对比结果发现,检测算法的mAP较原有算法有了一定提高。最后,对所设计的算法进行了移植,取得了较好的效果。
大量的图像数据是基于深度学习的目标检测的基础,目前的数据样本较少,同时还应该考虑背景、光线、气候、遮挡、伪装、目标大小、姿态等因素。因此,需要有针对性的实验测试数据集,进行模型的训练和完善,以进一步提高检测效果。
