面向不平衡高光谱遥感分类的SMOTE和旋转森林动态集成算法
2022-12-15童莹萍冯伟宋怡佳全英汇黄文江高连如朱文涛邢孟道
童莹萍,冯伟,宋怡佳,全英汇,黄文江,高连如,朱文涛,邢孟道
1.西安电子科技大学 电子工程学院,西安 710071;
2.西安电子科技大学 先进遥感技术研究院,西安 710071;
3.中国科学院空天信息创新研究院 数字地球重点实验室,北京 100094;
4.西安电子科技大学 前沿交叉研究院,西安 710071
1 引 言
高光谱图像不仅具有较高分辨率,而且包含非常丰富的光谱信息,已在军用和民用领域中获得了广泛应用(Tu 等,2020;杜培军等,2016)。但是,高光谱图像分类经常会遇到类别不平衡的问题(Rodriguez 等,2006;韩竹 等,2020)。所谓的类别不平衡指的是数据中某些类别的样本数量明显少于其他类别(García 等,2018)。通常情况下绝大多数分类器在对类别不平衡数据分类时都会出现一定程度的性能损失(Díez−Pastor 等,2015;张永清等,2020)。或者说分类器虽然获得了较高的总体分类精度OA(Overall Accuracy),却忽略了少数类样本的识别。
不平衡数据一般包括两种类型:二类和多类。类别间样本分布不均、多种类别重叠和样本噪声等问题,使得多类不平衡数据相对二类数据更加难以处理(Krawczyk,2016)。多类不平衡分类问题的理想处理结果是:一个分类器可以在不牺牲多数类别分类准确性的情况下,提高少数类的分类精度(Feng 和Bao,2017;Feng 等,2019a)。目前,研究学者针对以上问题已经提供了很多方法,例如,Jimenez−Castaño 等(2020)优化了孪生支持向量机算法,使用高斯相似度并结合基于中心核比对的方法改善数据可分类性,用于处理不平衡数据;Arshad 等(2019)提出了一种半监督深度模糊C 均值聚类算法,提取新特征以控制冗余;Douzas等(2018)将K均值聚类算法与合成少数类过采样算法SMOTE(Synthetic Minority Oversampling Technique)相结合,克服其他过采样算法的缺点,消除类间不平衡和类内不平衡同时避免产生噪声样本,其中,SMOTE 算法是对少数类别样本进行分析和模拟,并将人工模拟的新样本添加至数据集中,从而调节数据中类别的不平衡比率。但是大多数方法都集中于解决二类不平衡问题,不适用于多类情况(才子昕等,2019)。
数据采样是常用的不平衡高光谱数据处理方法。典型的采样算法包括随机欠采样RUS(Random Undersampling) 和 随 机 过 采 样ROS (Random Oversampling)。RUS 算法通过随机缩小多数类别的样本数量使样本达到平衡,但是RUS 算法会导致重要信息的丢失;ROS 算法的作用则与RUS 完全相反,它是在少数类别中通过随机生成更多样本,直到所有类别达到平衡,然而ROS 算法虽然可以克服RUS 的缺陷,但是会引起算法的过拟合。
SMOTE 是ROS 的升级算法,它可以有效地避免过拟合现象,已被用于解决机器学习中的类别不平衡问题,例如,Bhagat和Patil(2015)首先使用SMOTE 来平衡数据中各类别的样本数量,然后利用随机森林进行分类;Bandara 等(2020)也是先通过SMOTE 算法平衡数据集,然后构建滑坡敏感性模型,最后比较了随机森林与旋转森林算法在平衡数据情况下的性能表现。以上方法都可以在一定程度上提高分类器对小类别样本的分类精度,然而,这些技术仍侧重解决二类不平衡问题,在面临复杂的多类不平衡问题时难以拓展。在高光谱图像分类中,Cai 和Zhang(2019)将SMOTE算法应用于Pavia University 数据集上,有效解决高光谱数据不平衡问题,Zhou等(2020)通过SMOTE合成少数类别的人工样本,解决了多类情况下样本不平衡的问题。但是,大多数研究只将SMOTE算法应用于数据预处理阶段。由于SMOTE 算法在训练样本时具有引入额外噪声的风险(Pan 等,2020;Elreedy 和Atiya,2019),一次性平衡样本可能导致产生的噪声无法修正,进而影响分类模型的训练效果。因此,如何改进SMOTE 算法解决复杂的多类不平衡问题面临着巨大的挑战。
集成学习已经成功应用于高光谱图像分类(Mullick 等,2020;Feng 等,2019b)。旋转森林ROF(Rotation Forest)是一种功能强大的集成分类器(Tu等,2020;Rodriguez等,2006),引起了广泛关注。该算法通过结合多种随机因子来提升自身的学习性能,这些随机因子包括:数据随机选择、特征随机选择和特征空间旋转等。RoF算法的传统构造偏向于对多数类别进行分类,而忽略少数类样本的识别。目前虽然已有很多改进的RoF算法,但是仍然普遍适用于平衡数据集的学习。因此,改进RoF 算法,使之适合不同比例的多类不平衡数据是一个非常有意义的研究方向。
本文提出了一个新的SMOTE 和RoF 的自适应内部集成算法。该算法利用动态采样因子技术,将类别分布优化和基分类器过程进行融合,并可以有效地解决高光谱数据中的多类不平衡问题。
2 RoF分类算法
RoF算法是一种随机森林算法衍生而来的集成分类器,它通过特征空间变换,可以更加有效地提高基分类器的多样性(Feng 等,2019a)。设{X,Y}={(x1,y1),…,(xN,yN)}为训练样本集,其中xi=[xi,1,…,xi,n]∈Rn为特征为F的训练样本,Y为带有样本类别的向量,yj为类别标签ω={ω1,…,ωL}的集合中的元素(L为样本的类别总数)。设D1,…,DT为集成算法中的基分类器,其中T为分类器的数量。
为构造分类器Di,首先将具有n个特征的F随机分成H个互不相交的子集。假设H是n的因数,每个特征子集都包含M=n/H个特征,用Fi,j表示用于训练分类器Di的第j个特征子集,由Fi,j组成的样本集合表示为Z。其次,对Z执行75%的样本随机采样,并对选中的样本集合进行主成分分析PCA(Principal Component Analysis);然后保存主成分分析的系数a(1)i,j,…,a(Mj)i,j,每个系数的大小为M× 1;最后将主成分分析的系数组成旋转矩阵Ri。Ri可以表示为
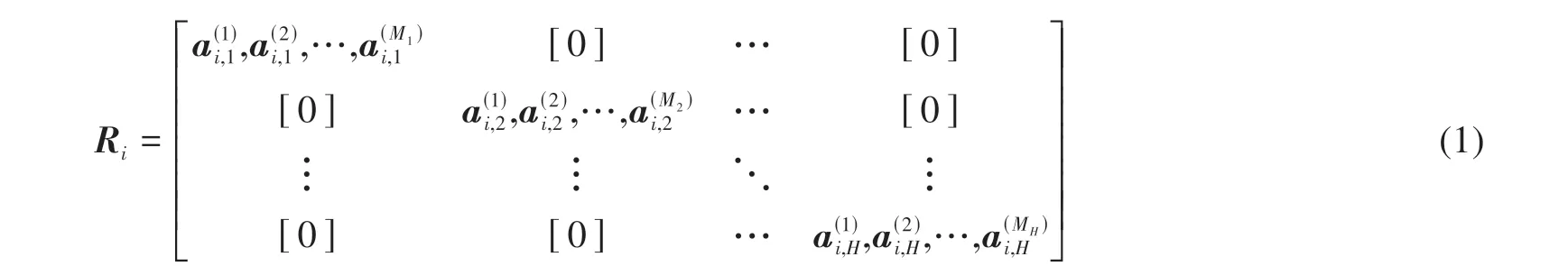
式中,旋转矩阵的维度为n×∑jMj。RoF 算法根据原始数据的特征F对Ri的列进行重新排序,获得 新的 旋转 矩阵Ria,其 大 小 为N×n。然后 由XRia生成一个新的训练样本集合,并训练一个分类器Di。
3 SMOTE采样算法
SMOTE 算法(Rodríguez 等,2020)是处理不平衡数据问题比较常用的算法。该算法步骤如图1所示,主要包括以下过程:对于少数类的样本xi,选择其K个最近邻的少数类样本xˉ,在xi与xˉ的连接线上插入新的合成少数类样本xsym,新的合成样本xsym可以表示为

图1 SMOTE算法示意图Fig.1 SMOTE algorithm diagram
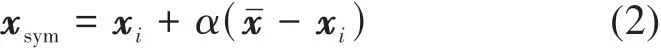
式中,α是[0,1]范围内的随机变量。
为了研究SMOTE 算法产生的人工样本与真实样本之间的区别,以下对这两种样本的均值和协方差矩阵进行比较分析。首先令Δ =xˉ−xi,新的合成样本xsym=xi+αΔ,其中α是在[0,α∗]中随机生成的,参数α∗的值通常大于或等于1,这使得算法能够在连接样本xi和其随机选择的最近邻xˉ的连线上进行外推或内插。
合成样本xsym的方差由以下公式给出:

式中,K为少数类样本的最近邻样本数,Γ 为伽马函数。
合成样本xsym的协方差矩阵由以下公式给出:
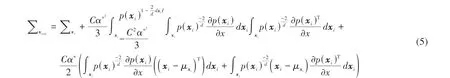


上述证明了SMOTE 生成的样本均值接近于真实样本的均值,两者的协方差矩阵之间存在一些差异。
4 SMOTE和RoF动态集成算法
本文提出了一种新的SMOTE 和RoF 动态集成算法。该算法使用样本权重和动态采样因子来降低SMOTE 算法引入人工噪声的风险,并与RoF 算法进行内部结合,最终用于多类不平衡高光谱数据学习问题。
4.1 样本重要性权重函数
本文提出一个新的样本重要性权重函数,来缓存SMOTE 产生额外噪声的影响。该权重函数的概念源于集成间隔理论。在间隔理论中,对于给定的样本,它的间隔值越低,说明它包含的信息量越多,越容易获得更多分类器的关注(Zhou 和Guo,2019)。


式中,v(xi,yi)是真实类别y的投票数,v(xi,c)是其他类别c的投票数。样本具有较大的权重值W(xi),表明这个样本越接近于当前的分类决策边界,并且具有较高的概率被选中参与SMOTE 算法,为下一个分类器的训练提供新的类别平衡的训练样本集。因此,随着基分类器数量的增加,分布在决策边界的样本权重会迭代增加。
4.2 SMOTE和RoF动态集成算法
本文提出的SMOTE 和RoF 动态集成算法是一种数据采样与集成框架内部结合的算法,它不仅可以降低初始数据的不平衡率IR (Imbalance Ratio),还能保证训练集中样本的数量和质量。假设数据集S中有L个类别,第i个类别的样本大小为Ni,将每个类别包含的样本集根据其样本数量Ni进行降序排列,则N1为最大类的训练样本的数量,NL为最小类别L的样本数。将S的每个样本权重值W初始化为1N。在每次迭代t中,以NL为标准,对其他所有类别c(c= 2,…,L)利用重采样率ω%执行有放回随机采样,选取ω%⋅N1个样本,然后通过SMOTE 算法生成剩下的(1 −ω%) ⋅N1个样本。最后通过将NL、采样样本以及SMOTE 产生的样本进行组合,获得各类别数量平衡的训练样本集St。然后与传统RoF算法一样,对数据集St进行特征空间旋转,以获得最终的训练数据集S't,并训练一个分类器Dt。根据式(9)更新所有初始训练样本的权重值W,并更新重采样率ω%。重复以上步骤,直到t达到最大迭代次数。最终的预测结果通过利用最大投票规则将所有的分类器结果进行融合获得。本文算法的伪代码描述如下:

本文提出的算法利用动态采样为不同的基分类器提供具有多样性特征的训练样本集合。在使用SMOTE 算法之前,以不同的采样率ω%对所有少数类样本进行随机采样。以下示例用于详细说明ω%的更新过程。
若设置采样ω%的范围为10%至100%,对于第一个分类器,ω%等于10%;第二个分类器ω%更新为20%,然后以此类推。当ω%等于100%时,对于类别ω%执行是完全的随机过采样;若集成模型尺寸ω%为30,那么每10个分类器,ω%执行3次从10%至100%的迭代更新。
5 实验结果
5.1 实验设计
由于过采样算法在解决不平衡问题时应用更为广泛,本实验主要选择ROS 和SMOTE 这两种过采样算法作为对比。为了验证本文算法在不平衡数据集上的分类优势,本文选用4种对比算法,分别是随机森林RF(Random Forest)、传统的RoF、ROS 预处理与RoF 结合的算法(记为ROSRoF)以及SMOTE 预处理与RoF 结合的算法(记为SMOTERoF)。
实验利用分类回归树CART(Classification and Regression Tree,)作为基分类器,所有集成模型由30 个决策树组成。对于所有的RoF 算法,参数H都设置为30;数据采样率ω%的范围设置为10%至100%;实验部分所有值均为将算法独立运行10次所得的结果均值。
5.2 评价指标
遥感图像有侧重于不同方面的评估指标(高连如等,2007),本实验使用8 种不同的比较方法对分类结果进行评估。利用平均分类精度AA(Average Accuracy)、总体分类精度OA (Overall Accuracy)、F−measure、Gmean 和 最 小 召 回 率(Minimum Recall)以及运算时间对算法进行测试。为了验证算法在集成框架提升方面的优势,集成分类器多样性(Feng 等,2018)被用来作为集成算法的评估方法;另外,本实验使用McNemar 非参数成对检验来比较本文算法与其他算法在统计意义上的性能差异;最后,为了直观地对比各个算法的分类表现,绘制各算法在高光谱图像上的分类结果,并将其与地面参考数据作对比。
5.3 实验数据
为了评估本文算法的有效性,本实验选用3个公开的高光谱图像作为测试数据,它们分别是Indian Pines、Salinas 以及Pavia University,数据集参数如表1所示。其中,Indian Pines图像具有20 m空间分辨率;Salinas 图像空间分辨率为3.7 m,包含16个不同的类别;Pavia University图像波长范围为0.43—0.86 μm,空间分辨率高达1.3 m。
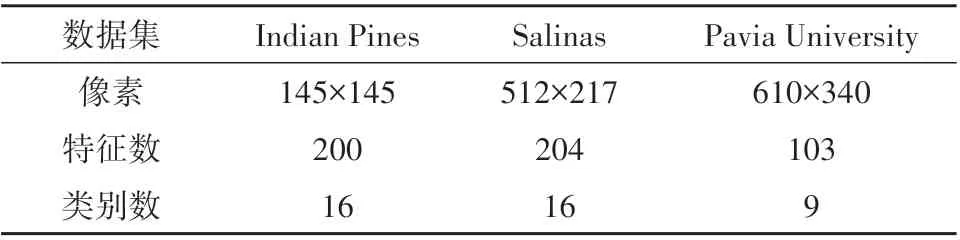
表1 实验数据集Table 1 Experimental data set
为了验证本文算法的分类表现,本实验采用了IR 值不同的数据集。在Salinas 图像数据以及Pavia University 图像数据中,本实验采用无放回随机抽取方法,选择5%的原始数据构成训练样本,其余95%作为测试样本;而Indian Pines 图像数据由于不平衡比率高,更有利于本实验设计,进而生成不同IR值的样本。
在Indian Pines 图像数据中,构造4 个数据集,方法是:对于多数类别样本,分别随机抽取原始数据的5%、10%、15%和20%以构造训练数据集,其它未被选择的样本作为测试样本;对于少数类别1、7、9、16,由于样本量过少,从每类中选取50%样本作为训练样本,剩下的作为测试样本。训练集的IR 通过N1/NL计算得到;6 个数据集的IR分别为12.20、17.50、36.80、49.10、12.51和19.83;本实验中所有训练样本及测试样本的具体信息由表2给出。

表2 训练样本与测试样本Table 2 Training sets and test sets
5.4 结果分析
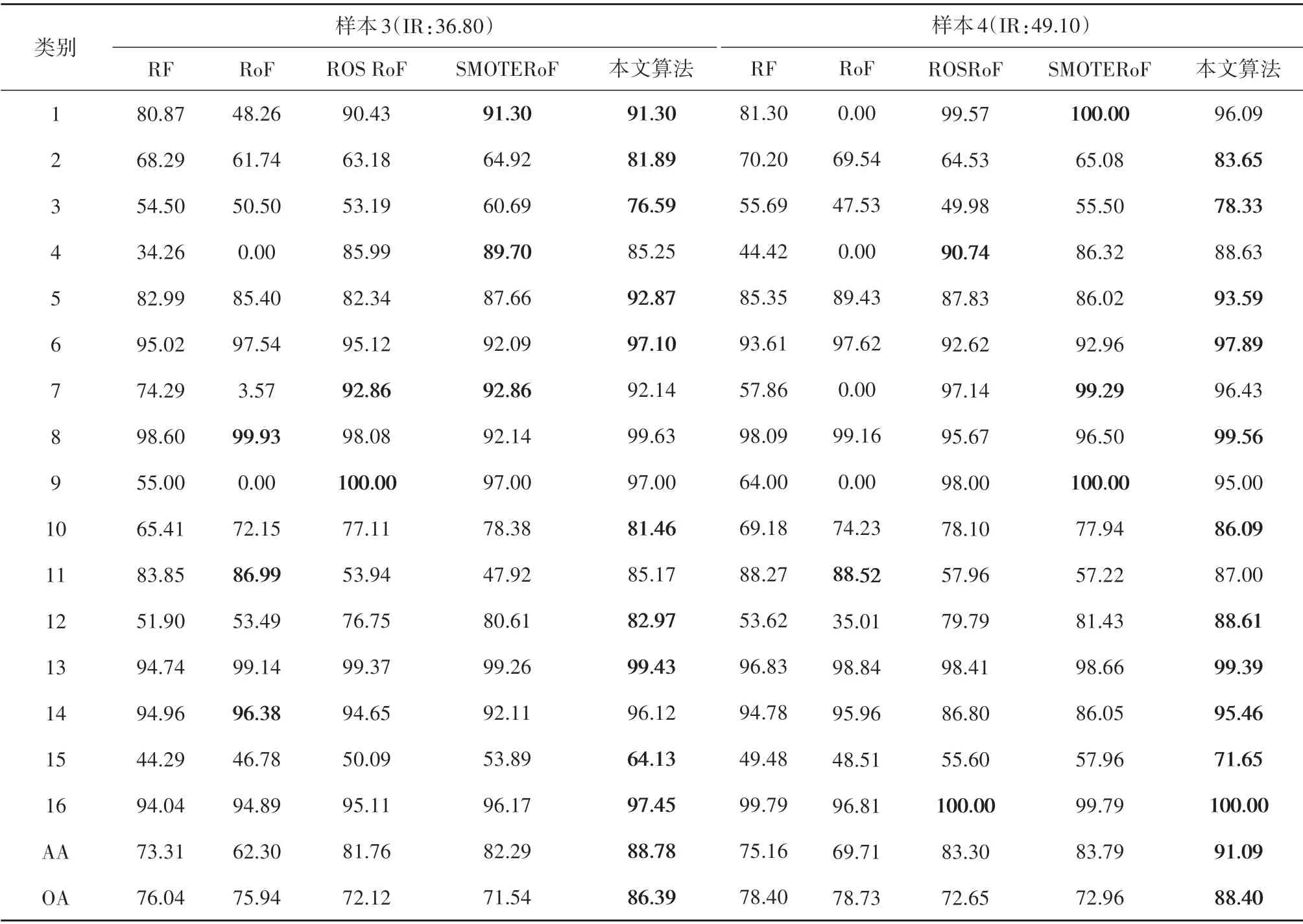
本文算法与对比算法在6个不平衡高光谱图像数据上的分类结果如表3 和表4 所示,F−measure、Gmean 和最小召回率结果如表5所示。每组数据中性能最佳的结果已用粗体标出。
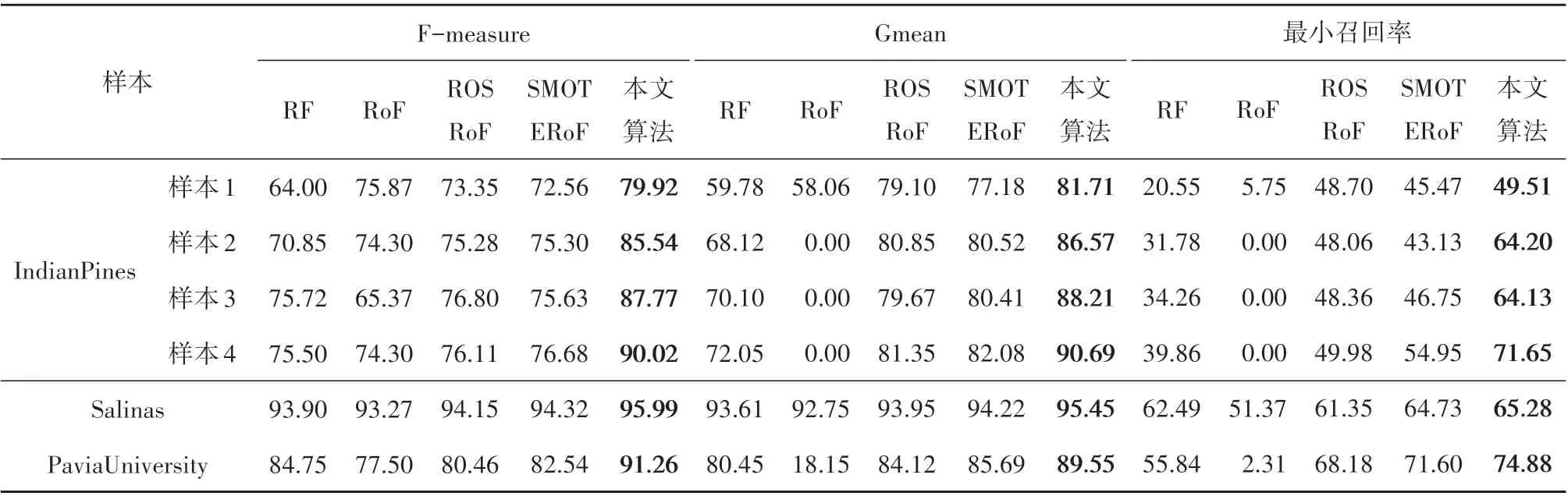
表5 不同算法的F-measure、Gmean和最小召回率Table 5 F-measure,Gmean and minimum recall of each algorithm
由表3 和表4 可以看出,与大多数现有文献的结论不同的是,RF 的高光谱图像分类结果在统计意义上优于传统RoF的分类结果。传统的RoF侧重于多类样本的分类,而牺牲少数类样本的分类准确率(Breiman,2001);尤其是当样本不平衡率增加时,传统RoF 算法完全忽略了少数类样本的分类精度(Ghosh 和Cabrera,2021)。此外,针对不平衡数据,本文算法与这两种未经数据预处理的分类算法相比始终可以达到最佳的分类结果。
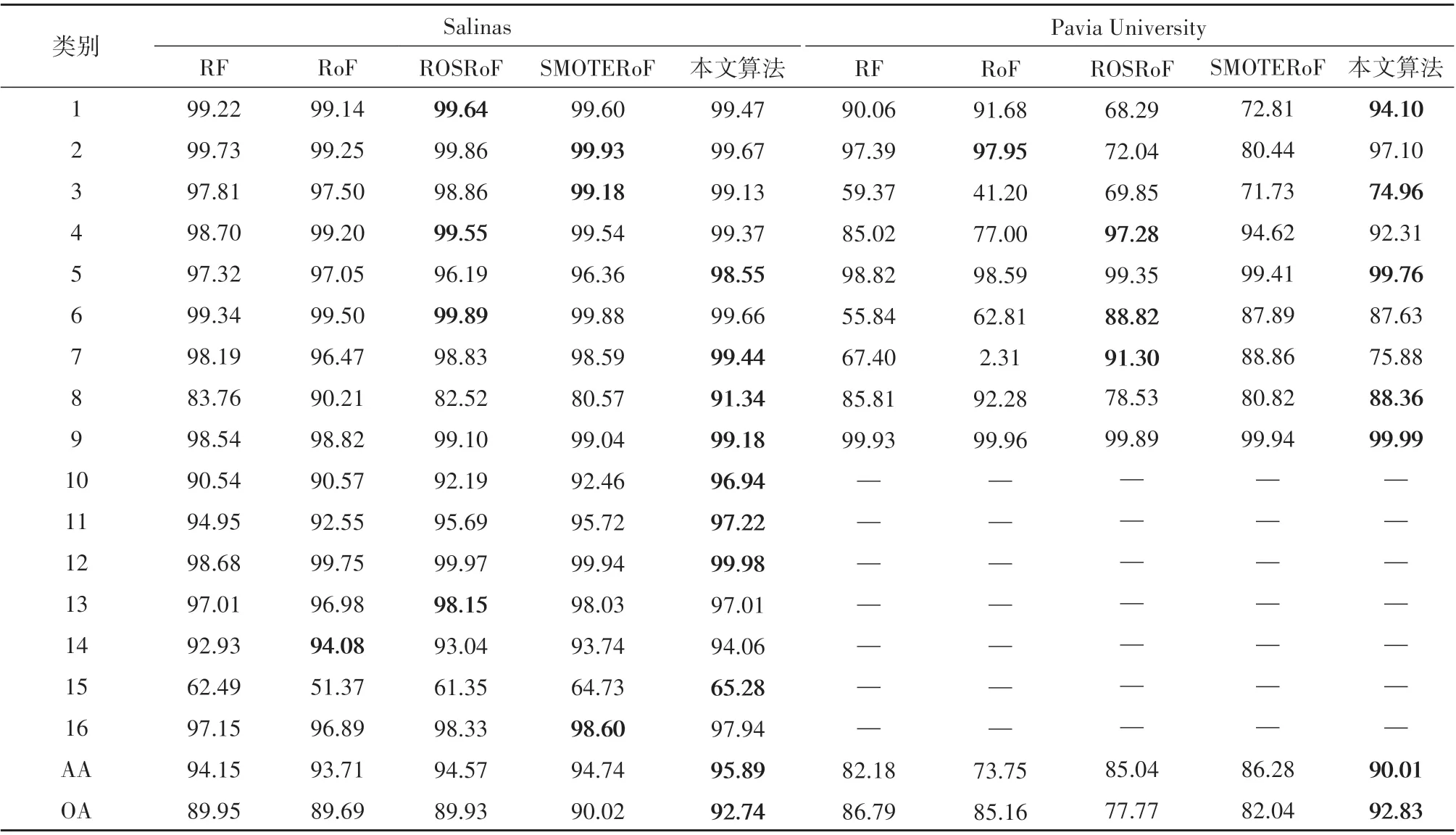
表3 Salinas与Pavia University分类精度Table 3 Salinas and Pavia University classification accuracy/%
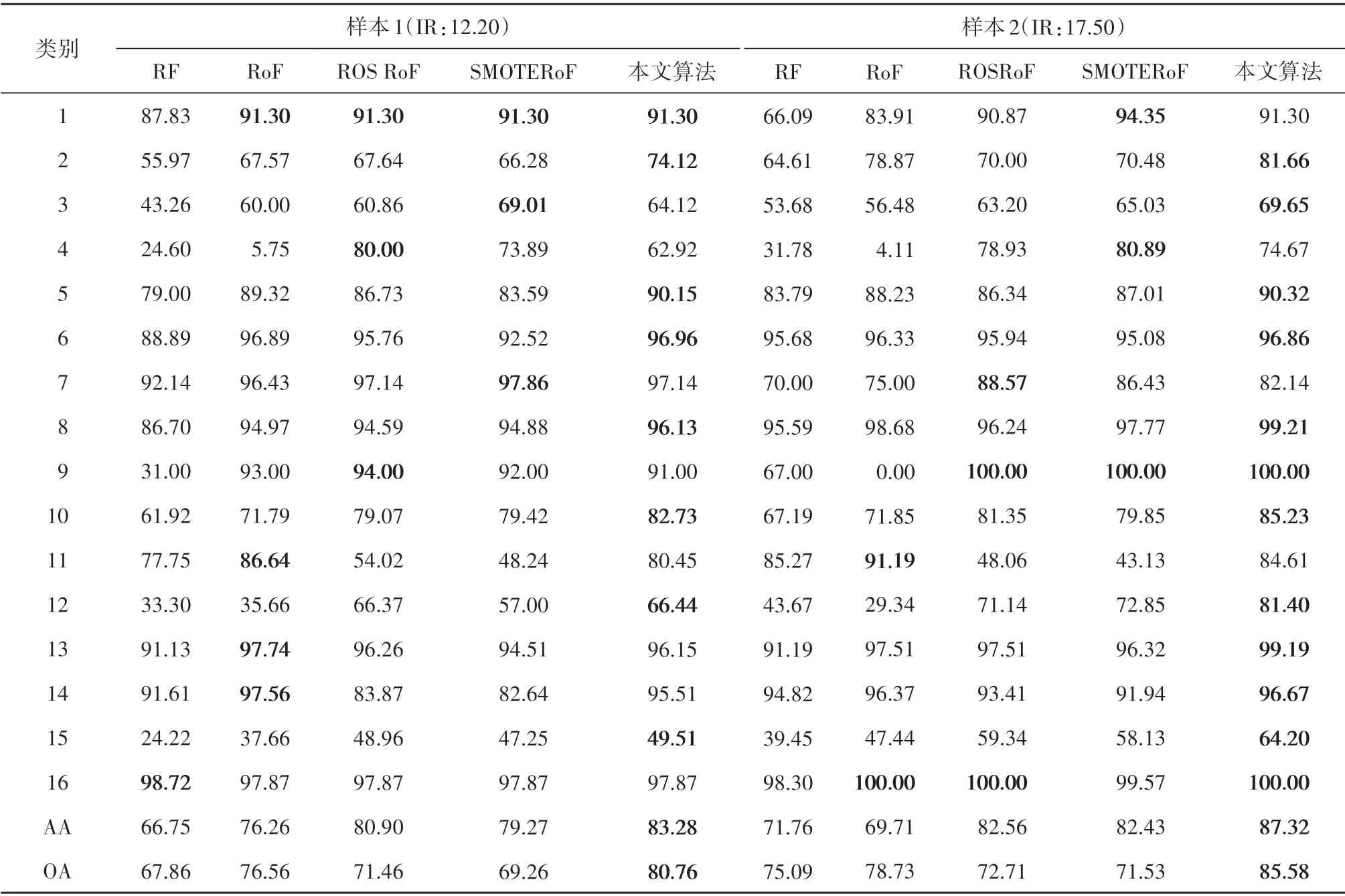
表4 Indian Pines分类精度Table 4 Indian Pines classification accuracy/%
续表
通过ROS 或SMOTE 算法对数据预处理,能起到平衡数据集的效果,在不同样本上ROSRoF 与SMOTERoF 在AA 方面较传统RoF 都有明显的提升。由于本文算法将类别平衡融合于分类过程中,本文算法取得的分类结果与SMOTE 算法作为预处理的分类结果相比更有优势。
本文算法不仅对少数类样本的分类有帮助,而且在很大程度上提高了总体分类精度。对于Indian Pines数据,在不平衡率较低的样本1中,本文所提出的算法与RF 和传统RoF 相比在AA 方面分别提高了16.53%和7.02%,在OA 方面分别提升了12.90%和4.20%,与ROSRoF和SMOTERoF相比在AA 上分别提高了2.38%和4.01%,在OA 上分别提高了9.3%和11.5%。
而在不平衡率较高的样本4中,本文算法与其他算法相比分类精度也有明显提升,说明本文算法在不平衡率改变的情况下同样具有很好的性能。另外对于F−measure、Gmean 和最小召回率这3 个评价指标,本文算法的分类结果明显优于其他分类算法。各算法的样本多样性和运行时间分别由表6和表7给出。本文算法利用动态采样技术,因此在集成分类器多样性上本文算法的性能显著提升。

表6 算法的样本多样性Table 6 Sample diversity of each algorithm

表7 算法运行时间Table 7 Run time of each algorithm/s
在p< 0.05 的情况下,McNemar 的测试值超过1.96,就意味着两种算法之间存在显著差异性。McNemar 的测试结果如表8 所示。从表8 中可以看出,本文算法与其他算法的McNemar 测试结果均大于1.96,也就是说,与其他算法相比,本文算法的性能提升十分显著。
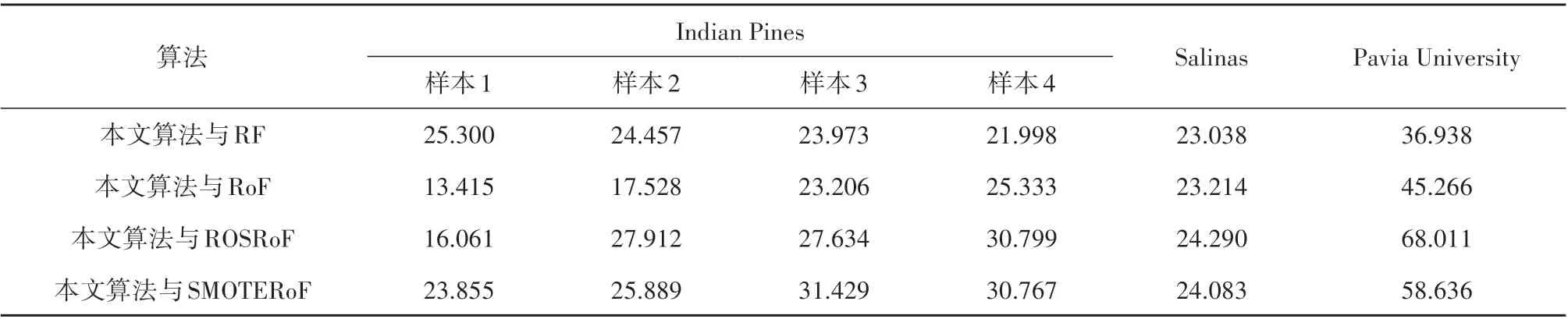
表8 McNemar的测试结果Table 8 Results on Mcnemar’s test
不同算法的高光谱图像分类结果如图2—图4所示,其中图2 显示的是Indian Pines 数据在IR 为49.1 时的分类结果。不同数据上的分类结果表明本文提出的算法性能明显优于RF 算法与传统RoF算法,在少数类别的样本分类精度高的同时,多数类样本同样能被更好地识别出来。


图2 Indian Pines分类结果Fig.2 Indian Pines classification results
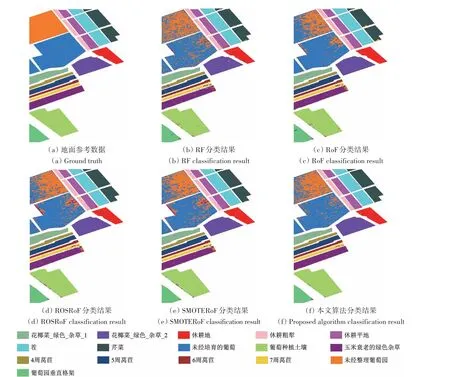
图4 Salinas分类结果Fig.4 Salinas classification results
6 结 论
本文提出了一种基于SMOTE 和RoF 动态集成算法来解决多类高光谱数据不平衡分类问题。该算法是一种基于内部不平衡采样的集成方法,使用样本重要性函数确定样本的权重,以降低SMOTE 算法引入人工噪声的风险,并利用动态采样来增加样本多样性。本文使用Indian Pines、Salinas 和Pavia University 高光谱数据对提出的算法进行多类不平衡的分类实验,选用4 种对比算法,分别是RF、传统RoF 算法,以及ROS和SMOTE 预处理后再使用RoF 分类的算法相比较,采用多种评价方法对算法的分类性能进行评价,包括总体分类精度、平均分类精度、F−measure、Gmean、最小召回率、样本多样性、模型训练时间以及McNemar 测试。实验结果表明,与未经数据平衡处理的分类算法相比,本文算法具有优异的表现。
通过对比实验可以看出,在Salinas 以及Pavia这类数据不平衡度较低的数据集中,本文算法在提高少数类样本分类精度的同时,仍旧在很大程度上提高了总体分类精度。而且,本文算法在不平衡率较高的Indian Pines数据集上的分类精度表明,本文算法在不平衡率该表的情况下同样拥有很好的性能。本文算法的评价参数例如McNemar 的结果均大于1.96 可以说明,与同类算法相比性能有十分显著的提升。同时,对比SMOTE 只作为数据预处理的方法,本文算法将数据采样与分类过程内部结合,不仅在多数类别上保持高分类精度,而且能很好地识别少数类样本。同时,本文算法采用动态采样技术,能有效提高样本的多样性。
在下一步工作中,可以将本文算法与一些特征提取算法相结合,例如奇异谱分析和稀疏表示,从而进一步提升样本多样性。
