基于矿石流的选矿生产过程跟踪与监控方法研究
2022-12-14侯卫钢张晓淼
侯卫钢,张晓淼
(鞍钢集团矿业设计研究院有限公司,辽宁 鞍山 114004)
在矿山企业连续生产过程中,经过圆筒仓、U型仓等储料仓后,各批次的物料混在一起。基于企业自身管理需求,为了进行质量配矿,提供选矿工艺流程易选矿石,需对各批次的物料从投料到产出进行批次追踪[1]。选矿生产过程是以矿石作为原料,经过破碎、磨磁、浮选、压滤和精尾等工序,生产出精矿。矿石投料经过破碎后一般需要进入圆筒仓或U型仓缓存,然后通过给矿皮带传输给球磨机。在矿山企业,一般是以班次为单位进行投料和化验,即每班次的原矿石有化验过的原矿品位指标。由于圆筒仓或U型仓存储的是多个班次的投料矿石,不同班次的原矿石在仓内缓存,生产调度需要掌握各个仓内的原矿分布(包括班次、品位),只能凭借经验预估出班次矿石分布。原矿品位是影响后续精矿生产的关键指标,掌握各仓内的矿石分布,精准配矿输送给后续工序,是选矿生产的迫切需求[2-3]。为此,对基于矿石流的选矿生产过程跟踪与监控方法进行了研究,本文对此做一介绍。
1 方法总述
由于原生产管理系统没有对矿石流进行跟踪的方法,因此以铁矿石选矿生产为例,提出了一种面向连续生产的物料流跟踪方法并通过系统进行实现。总体流程包括:
(1)根据选矿生产流程建立排班计划信息;
(2)通过实时数据库对选矿生产流程状态进行数据采集,并配置每班次的配矿信息;
(3)计算圆筒仓的物料分布;
(4)计算U型仓的物料分布;
(5)对圆筒仓的物料分布和U型仓物料分布进行可视化。
2 方法研究
2.1 生产过程跟踪
2.1.1 建立排班计划信息
排班计划信息为根据时间设置的班次序列,根据时间的先后顺序,设置时间最先的班次为底层、时间最末的班次为顶层。排班计划是工厂各班次每天的工作时间,系统存储业务日期、班次、开始工作时间、结束工作时间。如2021年12月24日、白班、8:00、16:00;2021 年 12 月 24 日、晚班、16:00、8:00。排班计划可为其他模块提供当前班次信息。
2.1.2 实时数据采集
实时采集选矿生产流程状态数据的方式有以下两种:
(1)通过实时数据库对控制系统数据进行采集
实时数据库通过OPC协议采集PLC、控制系统数据,然后数据采集模块再从实时数据库将数据采集并保存到关系数据库。为计算圆筒仓物料分布,通过OPC协议采集的数据包括圆筒仓内四个点位的料位高度、给矿皮带的瞬时流量、累计流量。为计算U型仓物料分布,通过OPC协议采集的数据包括布料皮带的瞬时流量、累计流量、料仓号、各个U型仓内的料位高度、给料器开启状态、给料器报警状态、集矿皮带频率、集矿皮带电流、给矿皮带的瞬时流量、给矿皮带的累计流量。实时数据库每1 s采集一次控制系统数据,如果采集失败,数据采集模块以上一次的采集结果作为本次的采集结果。
(2)通过生产管理系统录入数据
通过生产管理系统录入每个班次的配矿信息,系统存储班次、采出量、车数、地质品位、亚铁品位、采出品位、碳酸铁品位、比例、产率、管精(磁选管精矿品位)、磨矿时间、班组、计划时间、创建人、备注等信息。
2.2 监控方法
2.2.1 计算圆筒仓物料分布
一般情况下,圆筒仓底部为多开孔下料,上部安装多台雷达料位计,分别分布在不同位置。可通过雷达料位计平均值估算圆筒仓料位。在实际生产过程中,通常会开启对称位置的2个下料口以保证下料均匀,且由于圆筒仓一般体积较小,中破机产能较大,圆筒仓内的矿石消耗较快。按照班组进行矿石跟踪,一般只能储存1~2个班的矿石。因此,可通过从底至上的顺序计算矿石消耗量,出现的计算误差在可接受范围内。
圆筒仓的物料分布计算包括以下流程:
(1)查询系统存储的最新每一层班次矿石量信息,包括顺序号、班次、业务日期、矿石量,即上一时刻的圆筒仓矿石分布。
(2)根据当前时刻与上一时刻采集的给矿皮带累计流量,得到当前时刻的矿石输出量,即每次圆筒仓底部给予给矿皮带的矿量,矿石输出量=采集的给矿皮带累计流量-上一次采集的给矿皮带累计流量。
(3)从底层班次至顶层班次,将矿石输出量依次从每层减掉,得到更新后的每层矿石量。在圆筒仓底部的矿石会先被用掉,如果某一层的矿石量为0,则表示此层矿石量已用尽,系统不再进行存储。从底层至顶层,如果本层矿石量大于矿石输出量,表明本层矿石量足够矿石输出,则用本层矿石量减去矿石输出量作为本层新的矿石量,即新的本层矿石量=本层矿石量-矿石输出量。如果本层矿石量小于矿石输出量,则本层矿石量全部输入,剩余为0,矿石输出量减去本层矿石量作为新的矿石输出量,新的矿石输出量继续和上一层的矿石量比较,直到新的矿石输出量在某一层被减掉。圆筒仓仓位计算流程示例如图1所示。

图1 圆筒仓仓位计算流程示例图Fig.1 Example Diagram for Calculation Flow Procedures for Cylinder Bin Space
以图1为例,上一时刻的圆筒仓矿石分布从底层至顶层分别为,白班20211223的矿量200 t,晚班20211223的矿量900 t,白班20211224的矿量500 t,本次矿石输出量为1 000 t。若先从底层开始处理,白班20211223上次剩余的200 t,则白班20211223本次剩余为0,还有1 000-200=800 t未分配。再向上处理,晚班20211223上次剩余的矿量900 t,则本次剩余900-800=100 t。处理完毕后,原来的底层白班20211223的矿量已用完,晚班20211223的矿量剩余100 t,白班20211224的矿量未变化仍是500 t。
(4)计算采集的料位高度的平均值,用最新料位修正最顶层矿石量。在矿石生产过程中,会有投料矿石跌落、矿石间隙压实等实际情况,因此计算后,仍要以采集的料位高度作为最新的圆筒仓总矿量,即圆筒仓总矿量=采集料位高度的平均值×圆筒仓截面积×比重。从底层至顶层,圆筒仓总矿量减去每层矿量,当计算到最顶层时,用剩余矿量作为最顶层矿量。
(5)根据排班计划信息,判断当前时间所属班次。如果发生换班即当前时间的班次不等于最顶层矿石的班次,则生成一条新班次的数据,以第三步中结果作为晚班班次新数据。
以图1为例,如果发生换班,当前班次为晚班20211224。根据计算结果,如果采集料位高度的平均值转换的U型仓总矿量为700 t,底层晚班20211223矿量剩余100 t,顶层白班20211224剩余 500t,则 700-100-500=100 t数据作为晚班20211224的矿石量,系统存储晚班20211224的矿量100 t作为新数据。
(6)系统存储每一层的班次、业务日期、矿石量、顺序号作为本次的计算结果。
2.2.2 计算U型仓物料分布
U型仓的物料分布计算包括以下流程:
(1)根据当前时刻与上一时刻采集的给矿皮带累计流量,得到当前给矿皮带矿石输出量,即给矿皮带矿石输出量=采集给矿皮带累计流量-上一次采集给矿皮带累计流量,进而得到集矿皮带矿石输出量、U型仓皮带矿石输出量。
①向上反推集矿皮带矿石输出量。因为多条集矿皮带给一条给矿皮带供矿,在自动化应用层集矿皮带速度与给矿皮带瞬时流量 (t/h)联动控制,当给矿皮带瞬时流量升高时,集矿皮带速度提高,反之亦然。由于皮带频率与皮带速度成正比,因此可以认为给矿皮带瞬时流量与集矿皮带频率成正比,通过不同集矿皮带之间的频率比例,计算每条集矿皮带的矿石输出量。例如,给矿皮带矿石输出量 1 000 t,1#集矿皮带频率为 10 Hz,2#集矿皮带频率为15 Hz,则按2:3的比例,1#集矿皮带矿石输出量为400 t,2#集矿皮带矿石输出量为600 t。
②向上反推U型仓皮带矿石输出量。因为多个U型仓可以给一条集矿皮带供矿,但多个U型仓只能同时开启一个,因此按照采集U型仓给料器开关状态判断是哪一个U型仓的输出矿量。例如,1#集矿皮带矿石输出量为400 t,如果1#U型仓的给料器开关状态为开启,那么1#U型仓的矿石输出量为400 t。
(2)按照从底层至顶层,将矿石输出量依次从每层减掉,得到更新后的每层矿石量。在U型仓底部的矿石会先被用掉,如果某一层的矿石量为0,那么表示此层矿石量已用尽,系统不再进行存储。从底层至顶层遍历每一个班次,如果本层矿石量大于矿石输出量,表明本层矿石量足够矿石输出,则用本层矿石量减去矿石输出量作为本层新的矿石量,即新的本层矿石量=本层矿石量-矿石输出量;如果本层矿石量小于矿石输出量,表明本层矿石量不足够矿石输入,那么本层矿石量全部输入,剩余为0,矿石输出量减去本层矿石量作为新的矿石输出量,新的矿石输出量继续和上一层的矿石量比较,直到新的矿石输出量在某一层被减掉。U型仓仓位计算流程示例如图2所示。
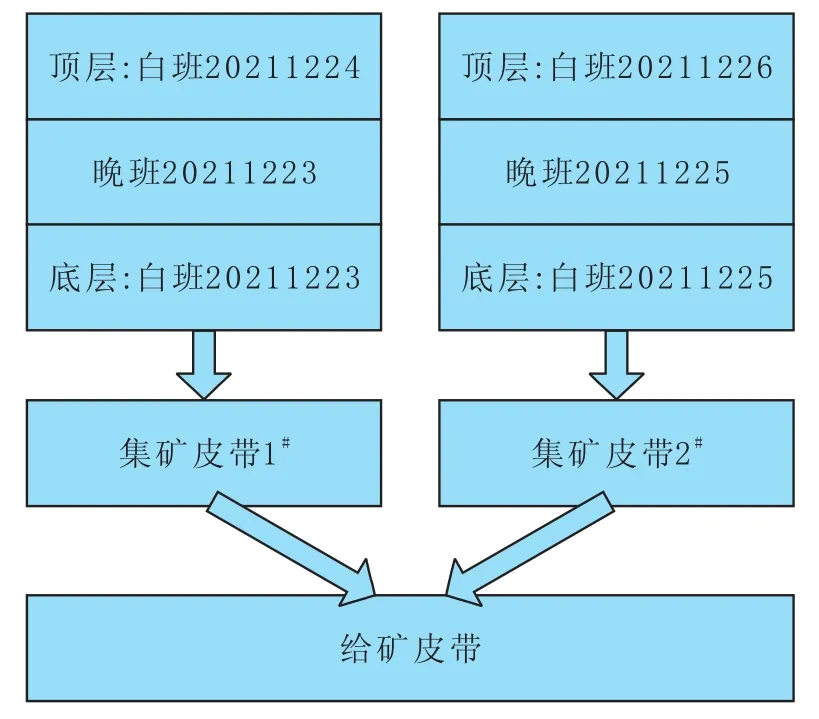
图2 U型仓仓位计算流程示例图Fig.2 Example Diagram for Calculation Flow Procedures for U-shaped Warehouse Space
以图2为例,左侧U型仓矿石分布从底层至顶层分别为,白班20211223的矿量 200 t,晚班20211223的矿量900 t,白班 20211224的矿量500 t。如果矿石输出量为1 000 t,那么先从底层白班20211223开始处理,处理完毕后,原来的底层白班20211223的矿量已耗尽,晚班20211223的矿量剩余100 t,白班20211224的矿量未变化仍是 500 t。
(3)计算采集的料位高度的平均值,用最新料位修正最顶层矿石量。在矿石生产过程中,会有投料矿石跌落、矿石间隙压实等实际情况,因此第二步计算后,仍要以采集的料位高度作为最新的U型仓总矿量。U型仓总矿量=采集料位高度的平均值×U型仓截面积×比重。从底层至顶层,U型仓总矿量减去每层矿量,当计算到最顶层时,用剩余矿量作为最顶层矿量。
以图2为例,根据第二步的计算结果,左边的U型仓矿石分布从底层至顶层分别为白班20211223矿量剩余100 t,白班20211224的矿量未变化仍是500 t。采集料位高度的平均值转换的U型仓总矿量为590 t,底层晚班20211223矿量剩余 100 t,则 590-100=490 t为最顶层白班20211224的矿量。
(4)因为圆筒仓的矿石流到U型仓需要30 min时间,则将计算后最顶层的数据班次与当前时间30 min以前的圆筒仓最底层班次进行比较,如果不相等,说明发生了换班,则用当前时间30 min以前的圆筒仓最底层班次作为U型仓最顶层的班次。
以图2为例,经过第三步计算,U型仓最顶层为白班20211224,再用当前时间减去30 min,查询圆筒仓最底层数据为晚班20211225,说明发生了换班,用晚班20211225更新白班20211224作为U型仓最顶层数据。
(5)系统存储每一层的班次、业务日期、矿石量、顺序号作为本次的计算结果。
2.3 分布可视化
通过JAVA语言开发系统服务端,使用ECHARTS作为前端HTML5组件,图形化显示仓位不同层的矿石班次、业务日期、矿石量。U型仓矿石流跟踪如图3所示。
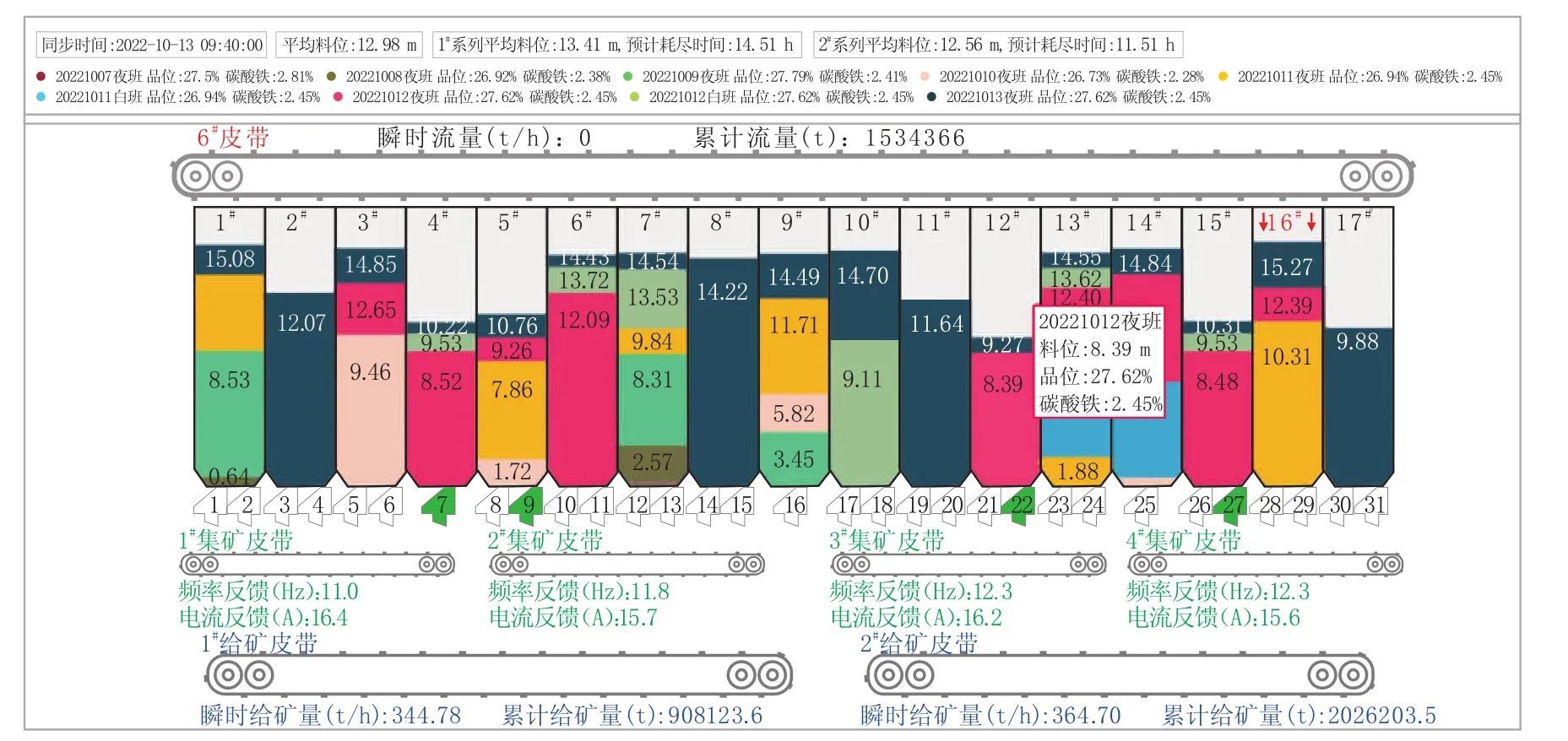
图3 U型仓矿石流跟踪Fig.3 Ore Flow Tracking for U-shaped Warehouse
使用E-CHARTS中的柱状图作为图形化仓位的控件,横坐标为不同仓的仓号,纵坐标为不同层的矿量,给E-CHARTS中的柱状图赋值后,柱状图显示的不同颜色阶段即代表不同层的矿量。可在系统中进行灵活配置矿仓数量、集矿皮带和给矿皮带数量和关系以及不同矿仓与给料器的对应关系。系统与自动化控制系统紧密集成,可实时显示每个料仓料位、集矿皮带频率、电流、给矿皮带瞬时流量、累计流量以及31个给料器的开关状态,并且针对矿仓堵料、断料、异常等情况进行报警和自动消除报警。另外,可根据不同系列的料仓料位和矿石消耗量估算预计矿石耗尽时间并给出提醒,为生产调度人员提供决策支持。
3 结语
基于矿石流的选矿生产过程跟踪与监控方法,实现了在矿石连续投料情况下实时计算矿石分布并可视化展示,以入选矿石性质为依据,从铁矿石原料进入选矿流程开始,对生产工艺流程中“圆筒仓-破碎机-U型仓(或粉矿仓)-球磨机”等关键储料仓和设备运转信息进行采集,把矿石的品位、碳酸铁含量、运输量、破矿量、料仓储量等数据以可视化的方式进行展示,有效支撑选矿生产环节对铁矿石原料综合信息的掌控,提高生产实时跟踪透明度。辅助生产管理人员进行配矿决策,为稳质、提效创造了有效抓手,创新选矿生产智慧化新模式。
