基于改进域对抗迁移学习的电力系统暂态稳定自适应评估
2022-12-13申锦鹏王飞跃
申锦鹏,杨 军,李 蕊,张 俊,王 晓,王飞跃
(1. 武汉大学电气与自动化学院,湖北省武汉市 430072;2. 中国科学院自动化研究所复杂系统管理与控制国家重点实验室,北京市 100190)
0 引言
随着新能源和电力电子设备大量接入[1],电力系统规模不断扩大,电网运行工况日益复杂,给电力系统暂态稳定评估(transient stability assessment,TSA)带来了新的挑战[2]。随着人工智能技术的发展,以及广域测量系统(wide area measurement system,WAMS) 、同 步 相 量 测 量 单 元(synchrophasor measurement unit,PMU)的普及,基于数据驱动的稳定评估方法受到了广泛关注[3]。
目前,已提出多种基于数据驱动的暂态稳定评估算法,如决策树[4]、支持向量机(support vector machine,SVM)[5]、集成学习[6]、深度学习[7]等。同时,生成对抗网络(generative adversarial network,GAN)、增量学习、代理模型等机器学习方法也分别应用于解决数据不平衡、样本更新、模型可解释性等问题。但机器学习模型均有很强的领域垂直特性[3],即所应用的领域越垂直、越细致,其效果越好,但模型的通用性也随之降低。
为解决以上问题,近年来有学者采用迁移学习方法,将原始场景中获得的知识迁移至当前评估模型的构建中,以实现电力系统暂态稳定性的自适应评估。目前,迁移学习方法主要分为样本迁移[8-9]、特征迁移[10-11]和模型迁移[12-13]。文献[8]对源域和目标域样本间的欧氏距离进行排序,根据样本相似度选择迁移样本。文献[9]基于关键故障持续时间和关键故障位置选择迁移样本,将选取的源域样本和目标域少量样本融合起来训练模型,解决了新场景下训练样本不足的问题。文献[10]基于迁移成分分析(transfer component analysis,TCA)算法,将源域和目标域映射到相似度更高的再生核希尔伯特空间以减少其边缘概率分布的距离,使得对源域知识的筛选更加精细。但该方法仍需经过特征提取、模型训练等步骤,更新过程复杂。文献[11]融合以上2 种方法,在原数据集中预先筛选关键特征,再用迁移样本训练模型,使模型评估速度和准确度得到进一步提高。文献[12]基于模型迁移中的微调(finetuning)算法,冻结原模型输入层、特征提取层,仅训练更新全连接层,有效利用了原模型的特征挖掘能力,更新速度快、评估精度高。然而,使用新任务更新训练模型会使其遗忘已经学到的知识,即存在“灾难性遗忘”问题[14]。
针对当前电力系统暂态稳定自适应评估中存在的知识利用率低、更新过程复杂、无法兼顾样本量和准确率、可持续学习能力差等问题,本文提出了一种基于改进域对抗神经网络(domain adversarial neural network,DANN)的端到端迁移学习方法。通过合理迁移原始数据以及模型,减少了所需训练样本规模,提高了模型更新速度和通用性,改善了“灾难性遗忘”问题,实现了暂态稳定的自适应评估。
1 基于域自适应的对抗迁移学习
1.1 迁移学习与对抗训练
基于数据驱动的电力系统暂态稳定评估,本质上是寻找量测数据与暂态稳定性之间的映射关系,利用数学模型加以表征并实时应用。为在保证评估效果的前提下寻找不同映射间的联系以增强模型通用性,减弱领域垂直特性带来的影响,本文采用迁移学习方法。迁移学习是指将在解决一个问题时获取的知识应用到解决另一个不同但相关的问题,以获得更好的学习效果。其中,特征空间和特征空间边缘概率分布共同构成领域;已获得的知识称为源域;要学习的新知识称为目标域[15];知识包括数据知识和模型知识;任务为解决问题需要构建的模型。
在基于数据驱动的电力系统暂态稳定评估方法中,特征空间就是高维电网量测数据空间。电力系统原始运行场景样本充足,并已通过训练获得高质量评估模型,故设定为源域;运行方式或拓扑结构改变后,新运行场景下的特征空间没有改变,而特征空间的边缘概率分布不再满足独立同分布条件,领域发生变化,需要通过学习重新获取评估结果,故设定为目标域。其中,源域和目标域的学习任务相同,均为实现电力系统暂态稳定性的快速、准确判别。
GAN 是通过相互对抗完成模型训练的深度学习框架(见附录A 图A1),广泛应用于解决电力系统数据合成问题[8]。其目标函数为:
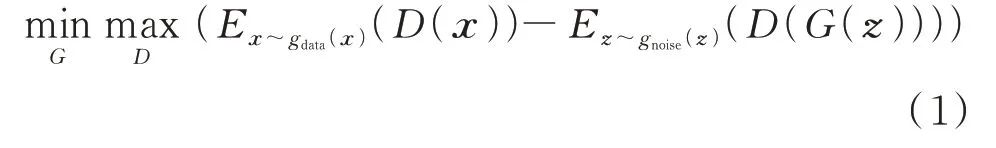
式中:E(·)为期望值函数;gdata(x)为真实样本分布;gnoise(z)为噪声分布;x为真实的输入样本;z为随机噪声;G为生成器;D为判别器。
GAN 利用相悖的目标函数优化网络参数、减少损失:生成器不断提高样本生成能力,减小生成样本和真实样本之间差距,以此获得逼真的样本;判别器不断提高判别能力,提升生成效果。
1.2 对抗迁移学习
不同于样本迁移或特征迁移方法,文献[16]将对抗思想融入迁移学习中,提出了DANN。该网络由特征提取器、标签分类器和域分类器组成,如图1所示。图中:M为电网量测数据空间;N为特征空间;Gf、Gl、Gd分别为特征提取器、标签分类器、域分类器;θf、θl、θd分别为Gf、Gl、Gd的参数;Ll为标签分类损失;Ld为域分类损失;λ为平衡系数。
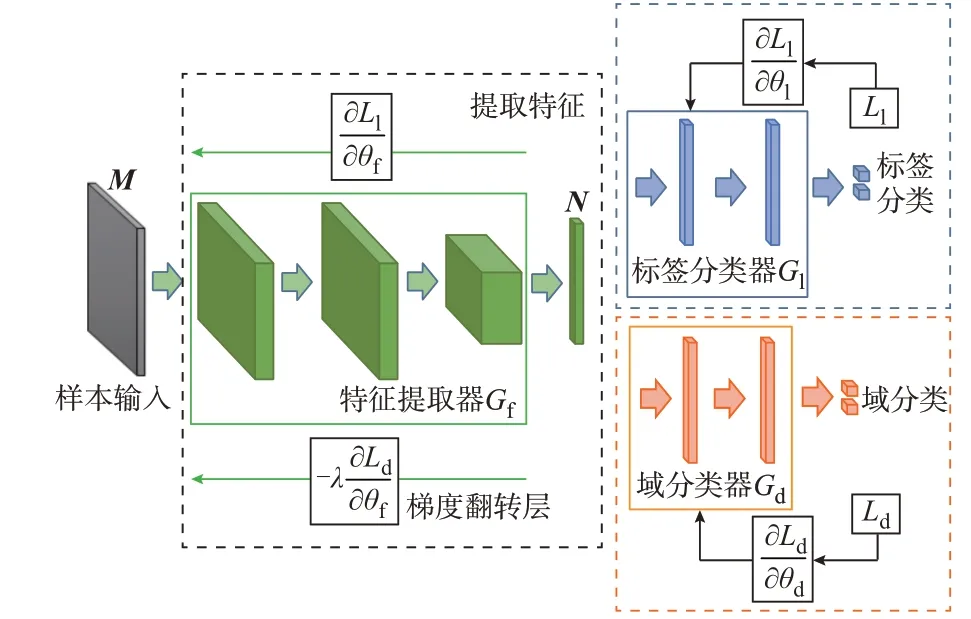
图1 DANN 结构Fig.1 Structure of DANN
其中,源域和目标域的特征空间均为电网量测数据空间M,特征提取器Gf将输入特征映射到一个新的特征空间N中,并和标签分类器Gl共同构成深度前馈神经网络用于标签分类。
其损失函数为:
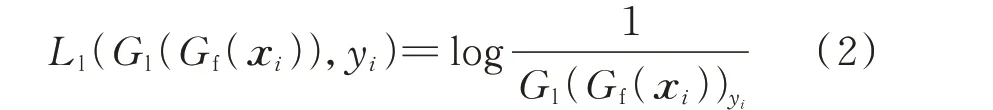
式中:xi和yi分别为输入的第i个样本及标签。
为利用源域数据补充新场景下的训练样本,需要对齐源域和目标域在特征空间N中的边缘概率分布。为此,DANN 算法基于对抗思想分别构建了域分类器Gd和梯度翻转层(gradient reversal layer,GRL)。域分类器与标签分类器共享输入特征,域分类器的输出为样本来源(源域或目标域),其结果用于领域分类,损失函数为:

式中:di为第i个样本的域类别标签。
在误差反向传播的过程中,梯度翻转层将特征提取器参数的梯度乘以平衡系数,使得特征提取器的目标变为增大域分类损失,进而缩小特征空间N中源域和目标域之间的边缘分布距离。DANN 的总优化目标Λ(θf,θl,θd)为:
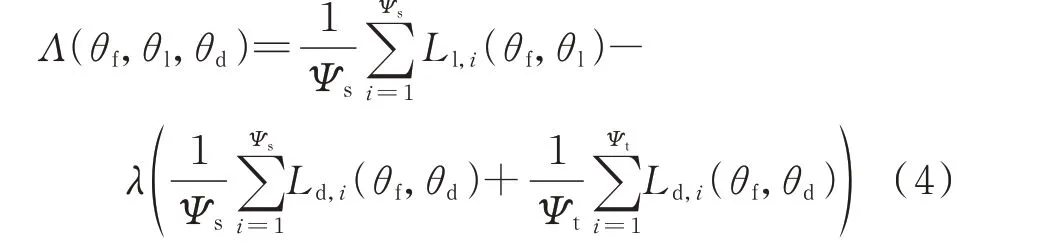
式中:Ψs和Ψt分别为源域和目标域的样本数量;Ld,i和Ll,i分别为第i个样本的标签分类损失和域分类损失。
标签分类损失和域分类损失协同优化特征提取器,提取源域和目标域公共特征的同时不断提高模型分类性能,保证通用性。网络各部分训练目标分别为:

经过迭代更新,最终计算求得的参数即为DANN 参数。
2 基于改进DANN 的自适应暂态稳定评估
2.1 评估模型框架
不同于图像识别,电力系统模式识别的样本组成、数据结构、评价指标、场景变化均有特殊性,需要根据其特点设计模型结构、损失函数以及训练方式,对DANN 算法做出调整改进。
2.1.1 输入特征与训练样本构建
基于数据驱动的暂态稳定评估中输入特征选择方法主要分为3 类:1)利用稳态特征,虽然不存在采样时间过长无法保证实时性的问题[17],但无法区分故障位置、持续时间、故障方式等反映扰动的信息,从而导致准确性不足;2)利用故障清除后的瞬时特征,在只考虑单重故障的情况下,故障清除后的系统不会再受到外来因素干扰,能够充分考虑扰动信息[18];3)采集故障切除后一定周期内的时序数据,在时间递归神经网络中取得了良好的效果[19]。
随着系统中PMU 的广泛安装,可利用PMU 实时上传的信息对电网中的故障进行在线识别。在此基础上,选取故障发生前、故障发生时、故障清除后的三段式特征数据,既可包含时间维度信息又能减少信息冗余。本文选择各发电机有功及无功功率、母线电压幅值及相角、负荷有功及无功功率、线路有功及无功功率等物理量作为输入特征[20],构建三段式输入特征,如附录A 图A2 所示,由此将数据集转化 为 1 维 卷 积 神 经 网 络(one-dimensional convolutional neural network,1D-CNN)的 输 入形式。
与DANN 原始的无监督训练应用场景不同,暂态稳定评估中目标域为含标签数据,利用少量含标签数据,一方面,可以进行数据和模型知识的迁移;另一方面,可以用于更新判断稳定(简称判稳)模型。因此,改进原DANN 模型,由源域和目标域标签数据共同组成训练样本。
2.1.2 网络搭建与参数设置
本文搭建的DANN 模型结构如表1 所示。其中,特征提取器由卷积层构成,标签分类器和域分类器由多层隐藏层构成。

表1 改进DANN 的模型结构Table 1 Model structure of improved DANN
表1 中,卷积层(k1,k2)进行1 维卷积计算,其中,k1表示卷积核数目,k2表示感受野,即神经网络中神经元的三段式数据输入区域的大小。为加快网络训练和收敛的速度、控制梯度、防止过拟合,加入批规范化(batch normalization)层;输出(flatten)层连接卷积输出和分类器;池化层的窗口和滑动步长均为3;全连接层为2 层,激活函数为softmax,其余层激活函数均为ReLU;输入层元素为100。不同于传统DANN,为充分利用源域模型知识,在目标域训练中保留了特征提取器和标签分类器的结构参数以加快模型更新速度。同时,对训练过程做出如下改进。
在GAN 中,通常会对分类器进行预训练以提升对抗效果。对于DANN,采用固定的损失函数无法灵活控制域分类器和特征提取器的训练水平。因此,本文采用变梯度翻转平衡系数λp:

式中:χ为系数,通常设置为常数10;p为当前训练迭代次数与总迭代次数的比值,代表从0 到1 的训练进程。
随着对抗训练的进行,平衡系数λp会自适应地从0 逐渐增加,最终变为1。通过改变损失函数,令模型在训练初期更加重视域分类器性能,使其具有一定判别能力,避免了域分类器在训练初期对噪声信号过于敏感而致使对抗效果不理想。
选用Adam 优化器,并为优化器绑定一个学习率μp的指数衰减控制器:
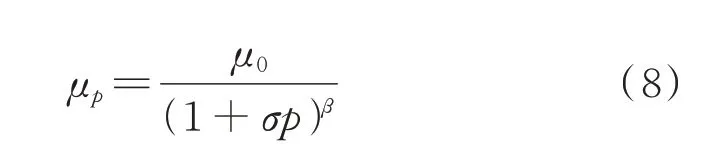
式中:μ0=0.01,为初始学习率;σ和β为参数,分别取10 和0.75。
学习率μp随着迭代训练次数的增加自动降低:在训练初期,学习率较大,网络可以迅速收敛;在训练后期,学习率较小,网络能更好地收敛到最优解。梯度翻转平衡系数和学习率与迭代训练进程的关系如附录A 图A3 所示。
2.1.3 焦点损失函数
基于数据驱动的暂态稳定评估方法存在样本不平衡的问题,即大量的稳定训练样本使模型更倾向于将未知样本判断为稳定。为解决这一问题,一方面,通过欠采样、过采样、线性插值[21]、样本生成[8]等方法可以得到平衡数据集用于训练,但原始数据分布也随之发生改变;另一方面,可以调整损失函数[22],提高失稳判别准确率的同时保持原始数据分布。
本文对损失函数进行改进,采用焦点损失(focal loss,FL)函数,如式(9)所示:

式中:Lfl为焦点损失函数;y为标签;y'∈[0,1],为预测结果;α>0.5,为平衡因子,通过参数α增加训练过程中失稳样本的分类损失以提高失稳样本正确分类的重要性,解决样本不平衡问题,取为稳定样本数占样本总数的比例;γ>1,为调制因子,通过调制因子γ增加难分类样本的损失,并增强模型在失稳边界上的样本判别能力,如附录A 图A4 所示,通过仿真实验最终取值γ=2。
2.1.4 判稳依据及评价指标
利用受扰后各台发电机的功角值计算暂态稳定指标(transient stability index,TSI):

式中:Δδmax为任意时刻2 台发电机功角差的最大值;ηTSI为暂态稳定指标。
若ηTSI>0,则将样本标注为0,代表系统稳定;若ηTSI<0,则将样本标注为1,代表系统失稳。
表2 中,ξTP、ξTN、ξFP、ξFN分别为真稳定、真失稳、假稳定、假失稳样本数。定义评价指标如下:
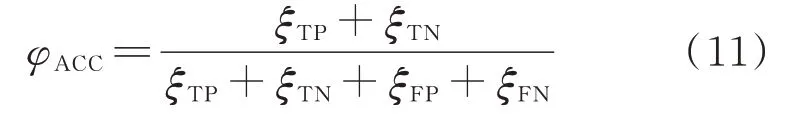
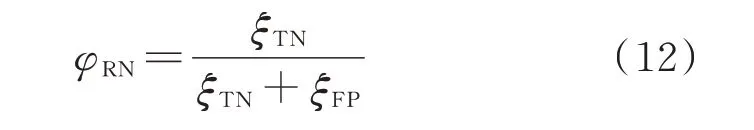
式中:φACC为准确率,代表模型总体评估效果;φRN为召回率,代表失稳样本被正确分类的比率,φRN越高,漏警率就越低。
2.2 迁移学习方法原理对比
根据域间距离提取数据知识的迁移学习方法,可能产生过拟合,需要对大矩阵进行求解并重新训练模型,精度和实时性难以保证(见附录A 图A5)。微调迁移学习方法在更新训练过程中可能会遗忘已学知识,模型通用性和可持续学习能力较差。改进DANN 通过标签分类损失和域分类损失协同优化特征提取器。一方面,将源域和目标域映射到满足同分布的特征空间中,获取可迁移数据知识,补充新场景下电力系统运行数据;另一方面,不断提高模型分类性能并保证通用性,获取可迁移模型知识,在源域和目标域中均有良好的评估性能,无需复杂的迁移步骤,即可实现端到端的迁移学习。输入原始数据就可直接得到可用结果,而不必关心复杂的中间过程。
2.3 暂态稳定自适应评估流程
基于改进DANN 的暂态稳定自适应评估框架如图2 所示,主要包括源域离线训练、目标域迁移学习、在线暂态稳定评估3 个环节。
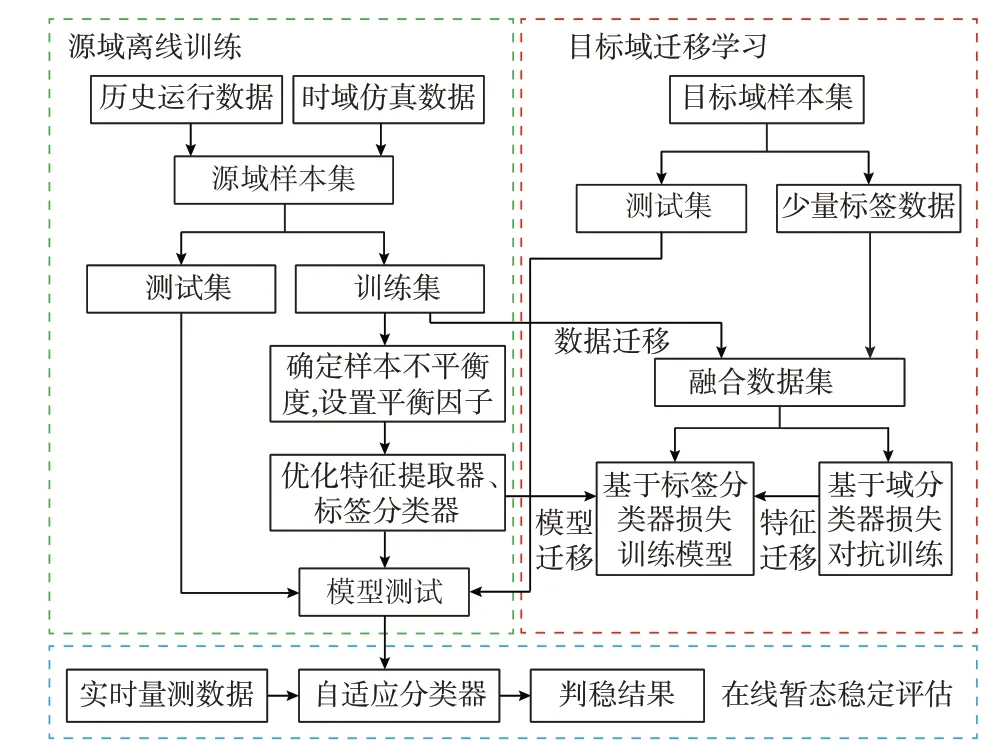
图2 基于改进DANN 的自适应暂态稳定评估框架Fig.2 Framework of self-adaptive transient stability assessment based on improved DANN
1)根据历史运行数据和时域仿真数据构建源域样本数据集,划分训练集和测试集并确定平衡因子α,利用标签分类器焦点损失优化前馈神经网络,并训练源域判稳模型;
2)当电网运行场景变化时,融合源域训练集以及目标域少量带标签数据,在改进DANN 中,一方面,基于域分类器损失和梯度翻转层对抗训练特征提取器,对齐源域及目标域数据,另一方面,基于标签分类器损失更新训练源域判稳模型;
3)实时采集在线运行数据,用训练好的模型进行快速、准确的暂态稳定自适应评估。
3 算例分析
3.1 仿真场景及数据集
为验证本文所提自适应评估方法的有效性,基于深度学习框架Tensorflow2.4 和Keras 构建改进的DANN,仿真硬件为Intel Core i5-6400 CPU、12 GB内存的计算机。
首先,选取IEEE 39 节点典型电力系统为源域系统,使用PSS/E 和Python 进行时域仿真,批量构建样本空间:仿真步长为0.008 3 s、总时长为20 s,故障类型均为三相短路故障,设置故障点位于各条线路首末端以及距首端20%、40%、60%、80%处,以5%为步长设置80%~120%范围内共9 种负荷水平,故障持续时间分别设置为0.1、0.2、0.3 s。除原始运行场景外,新增如下几种目标域运行场景[9,11]。
场景T1:在80%~120%标准负荷水平下,切除2 台发电机G7、G8 以及3 个负荷L16、L25、L29。
场景T2:在130%标准负荷水平下,发电机按105%标准出力,系统拓扑结构保持不变。
场景T3:负荷在80%~120% 标准负荷水平下,切除2 条线路B26-B27、B26-B28。
为对比迁移学习方案效果,批量时域仿真构建目标域样本集,并按3∶1∶1 划分训练集、验证集、测试集,如附录B 表B1 所示。各场景系统拓扑结构如附录B 图B1 所示。
3.2 分类器性能测试
首先测试改进DANN 的分类器性能,使用源域数据训练的同时闭锁域分类器对抗训练过程,并与SVM、轻度提升机(light gradient boosting machine,LightGBM)等浅层模型,以及人工神经网络(artificial neutral network,ANN)、CNN 等深度学习模型对比评估效果。分类器采用网格搜索和交叉验证寻得最优参数,其中SVM 采用径向基核函数,惩罚因子c的取值范围为{0.1,1,10,100,1 000},核参数υ的取值范围为{0.005,0.01,0.1,1},最终得到超参数c=100,υ=0.005;LightGBM 基分类器数量Wc的取值范围为{50,100,150,200,250},叶子树Wl的取 值 范 围 为{3,4,5},最 终 得 到Wc=250,Wl=4;ANN 采用5 层隐藏层结构,优化器为Adam,与DANN 绑定相同的学习率指数衰减控制器,激活函数 为ReLU 和softmax;CNN 结 构 分 为2 种,其 中,1D-CNN 使用故障切除时刻的一段式数据以及对数损失函数;采用焦点损失函数的CNN(focal loss-CNN,FL-CNN)与DANN 结构相同,均为三段式数据输入,包含2 层卷积网络、批规范层、隐藏层以及全连接层,采用焦点损失函数,训练的批大小取153。各分类器在源域及目标域T1 测试集上的评估效果如表3 所示,其中,φACC,s、φACC,T1、φRN,s、φRN,T1分别为源域原始场景S 和目标域场景T1 的准确率及召回率。
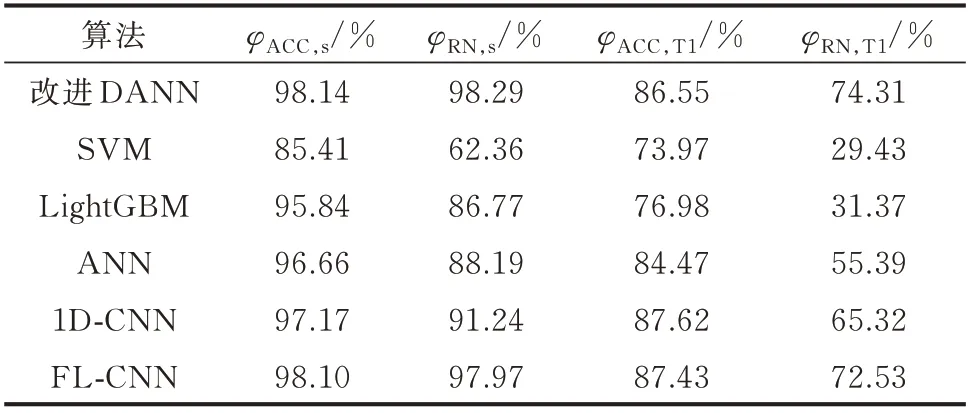
表3 不同算法性能测试结果Table 3 Performance test results of different algorithms
由表3 可知:1)相较于浅层模型,由于深度学习模型采用了更复杂的隐藏层结构,其评估效果以及在目标域上的泛化能力均有提升;2)改进DANN 与FL-CNN 评估效果接近,通过构造三段式数据和焦点损失函数,在增加时间维度信息的同时提升了对失稳样本和临界样本的敏感程度,保证了总体准确率和召回率,相较其他模型效果更优;3)由于运行方式和拓扑结构的改变,原始判稳模型在新场景下评估效果不佳,无法直接使用,需要通过迁移学习改善。
3.3 迁移学习训练
为改善新场景下的评估性能,减弱或消除领域垂直特性的影响,基于改进DANN 自适应更新模型。迁移原始场景中已通过训练得到的特征提取器Gf和标签分类器Gl构成初始分类器框架,参数及学习率与2.1.2 节一致。
以51 例样本为一组,随机生成多组目标域含标签数据,并与全部源域训练集样本一起构成融合训练集作为模型输入,测试不同规模的目标域数据对评估效果的影响,结果如附录B 图B2 所示。可见,随着目标域样本积累,评估准确率不断升高,8 组样本就可以获得较高的准确率和召回率,均衡考虑样本生成耗时和评估效果,最终确定样本量为408。模型自适应训练过程如图3 所示。
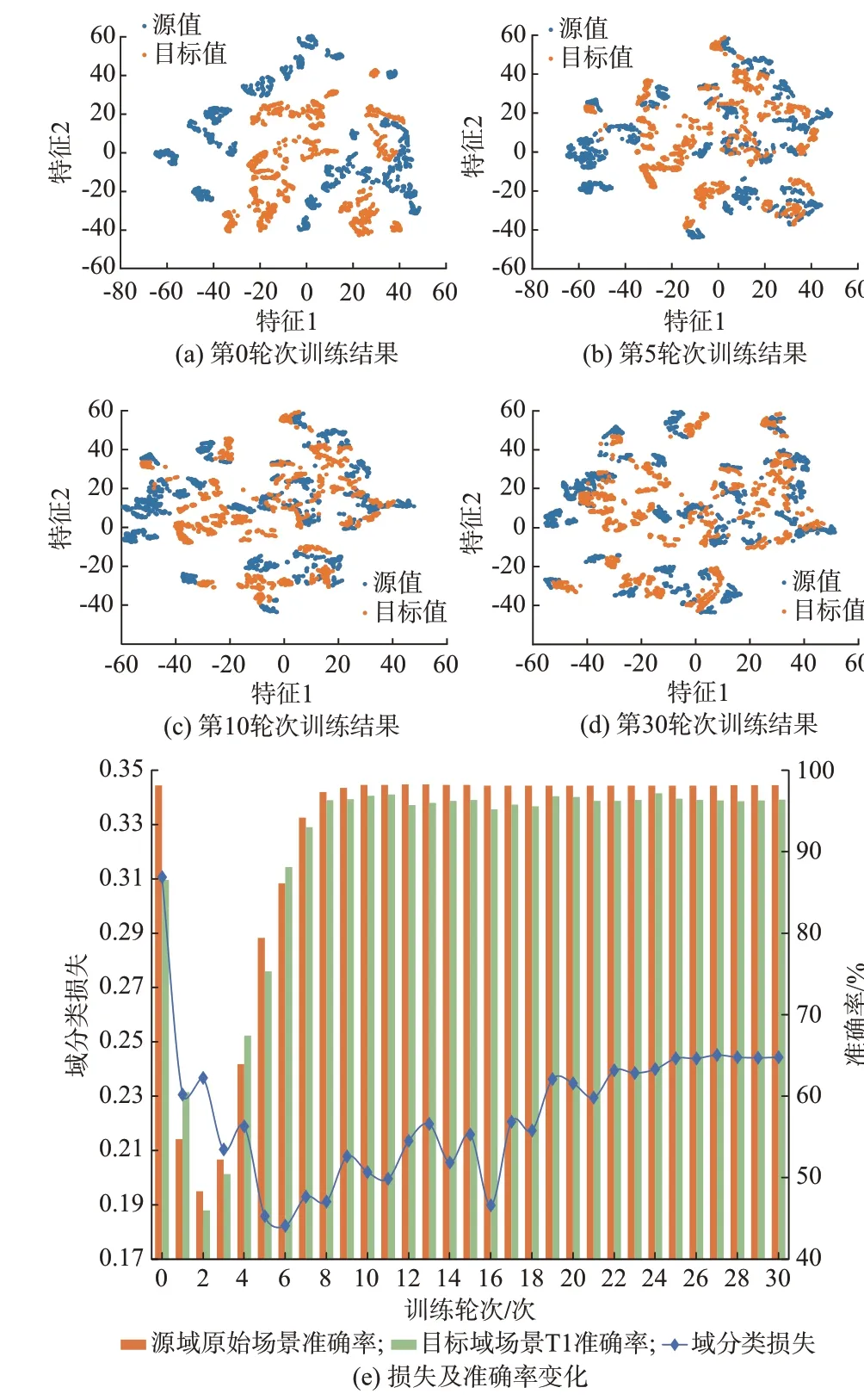
图3 迁移学习训练结果Fig.3 Training results of transfer learning
使用 t 分布随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)工具将特征提取的可视化结果映射到二维平面,如图3(a)至图3(d)所示。可见,训练开始前源域和目标域特征分布差异较大,经过30 轮次的Gf和Gd同步对抗训练后,特征分布逐渐接近,类似于特征迁移,Gf最终提取到了公共特征。
训练过程中损失及准确率的变化如图3(e)所示。从图中可以看出,域分类损失越大代表特征分布的差距越小、越易“混淆”域分类器的判断。域分类损失先降低后升高,经过25 轮次训练后稳定于0.24,代表在对抗过程中,受2 个分类器损失共同作用,源域和目标域特征分布先分离后趋于相似,最终达到了最接近水平;模型训练前源域和目标域判稳准确率分别为98.14%和86.55%,域分类器和梯度翻转层将域分类器损失传递至特征分类器,使准确率分别暂时下降到48.37%和45.96%;同时,Gl将标签分类损失传递至Gf,使其在提取公共特征的同时不断提高分类准确率,Gf在2 种损失之间寻求均衡,最终将准确率分别提升至98.16%和96.38%。
3.4 迁移学习方案对比
为验证所提出域对抗迁移学习方法的有效性,本节从样本量需求、模型更新速度、可持续学习能力等方面比较基于迁移学习的自适应暂态稳定评估方案。
3.4.1 评估性能比较
在迁移学习过程中,随目标域样本的积累,模型评估效果不断逼近上限[23]。而在电力系统实时运行过程中,新场景下的暂态稳定数据积累不足,如何利用最少的样本、最短的更新时间达到最优评估效果更加受到运行调度人员的关注。比较TCA[10]、微调算法[12]、改进DANN 等迁移学习方法的自适应评估效果,测试在目标系统中达到96%的相同判稳准确率时不同迁移学习模型所需T1 场景的样本量、样本生成耗时和模型训练用时,结果如表4 所示。
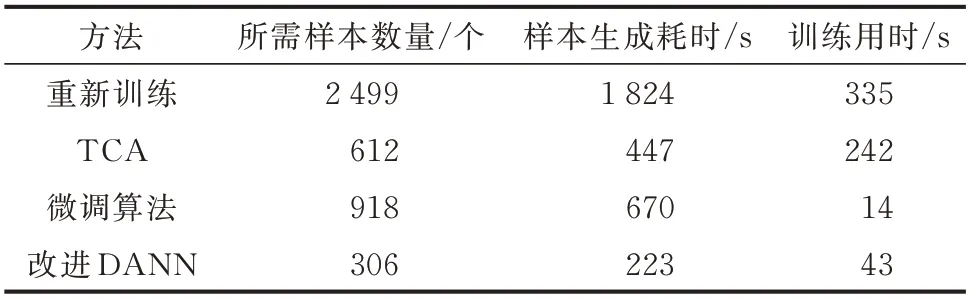
表4 不同迁移学习方法的对比Fig.4 Comparison of different transfer learning methods
由表4 可知:1)相比重新训练模型,TCA 通过特征映射利用了源域的数据知识,对目标域数据的需求量较低。但由于该方法在提取特征时仅关注样本间距离而未考虑判稳准确性,同时需要对大矩阵进行求解并重新训练模型,准确率仅达到93.11%,且训练用时较长,适用于样本缺少的过渡阶段[10];2)微调算法保留了原模型的特征提取结构,更新用时大幅缩短,但由于缺少对源域数据的有效利用,所需目标域数据量较大,适用于样本有所积累后的阶段;3)本文采用的改进DANN 可同时迁移模型知识和数据知识,提高了对源域知识的利用率,在对抗训练中寻找公共特征的同时能保证所提取的特征有益于准确率的升高,无需复杂的更新过程,真正做到了端到端的迁移学习,因此,所需目标域样本量最少且更新用时最短,能够满足在线调度需求,适用于模型更新的各个阶段。
3.4.2 可持续学习能力比较
电力系统运行场景实时更新,如定期维护与发电调度、负荷的季节性波动、故障切除系统状态恢复等变化可能反复发生,通过微调算法更新后的模型难以保证在原始运行场景中的判稳性能,存在“灾难性遗忘”问题。
为进一步比较迁移学习方法的持续学习能力,构建附录B 表B2 所示的数据集。基于目标域训练集连续更新模型,使用同时包含源域和目标域的融合测试集对比判稳准确率,如图4 所示。
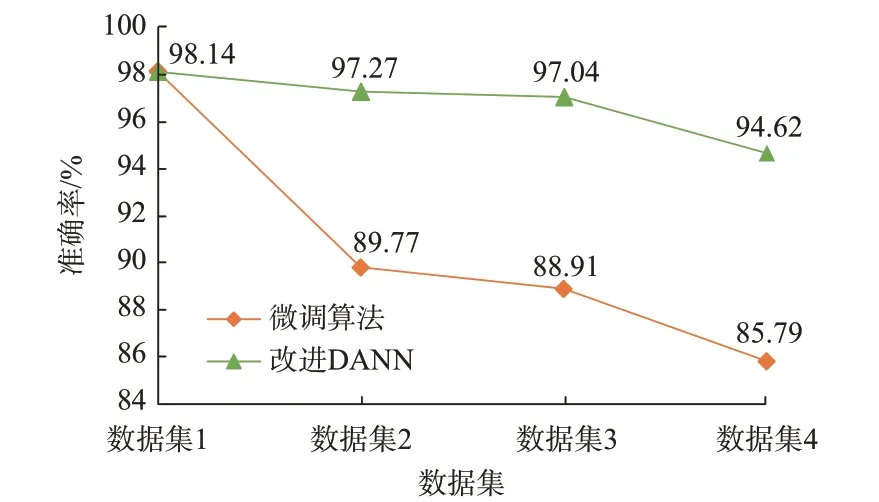
图4 持续学习能力对比Fig.4 Comparison of continuous learning ability
可见,由于模型结构参数有限,随着运行场景不断更新,传统迁移学习方法在模型更新过程中遗忘了所学知识,在已学系统中的表现不佳。而改进DANN 最大限度地利用了模型的知识容纳量,保留了在源域中的评估性能,具有较好的持续学习能力。
3.5 对大规模电网的适用性分析
为进一步验证所提方法在应对大电网场景变化时的有效性,采用美国南卡罗莱纳州500 节点电网算例进行测试,如附录B 图B3 所示。目标域场景TL1 设置为线路B87-B143、B388-B440、B464-B471断开;目标域场景TL2 设置为负荷水平为130%标准负荷,发电机相应调整出力;目标域场景TL3 设置为切除B17 上的SENECA 和B224 上的UNION发电机以及B4、B321、B491 上的负荷。故障点设置为各条线路首末端以及距首端20%、40%、60%、80%处;负荷水平设置为标准负荷的90%、100%、110%这3 种水平;故障持续时间分别设置为0.1、0.2、0.3 s。批量仿真构造10 835 个样本的源域和各800 个样本的目标域数据集。
设计模型结构参数与2.1.2 节一致,经过测试将训练的批大小调整为64。由于该系统节点数目较多,输入特征维数和判稳复杂度也相应提升,经过自适应训练,模型在源域和目标域上的测试结果如表5 所示。其中,目标域测试数据集与表5 所示的融合测试集结构相同。可以看出,由于大型电力系统网架结构更加坚强,样本不平衡更加严重,对召回率产生了一定影响;同时,源域系统训练得到的模型泛化能力较强,经过迁移学习,模型性能可以基本提升至原水平;在大规模电网中,本文所提方法保留了在原始运行场景中的评估性能,具有较强的持续学习能力。结果表明,基于改进DANN 的判稳方法在大型电力系统实时运行中具有较强的适应性。
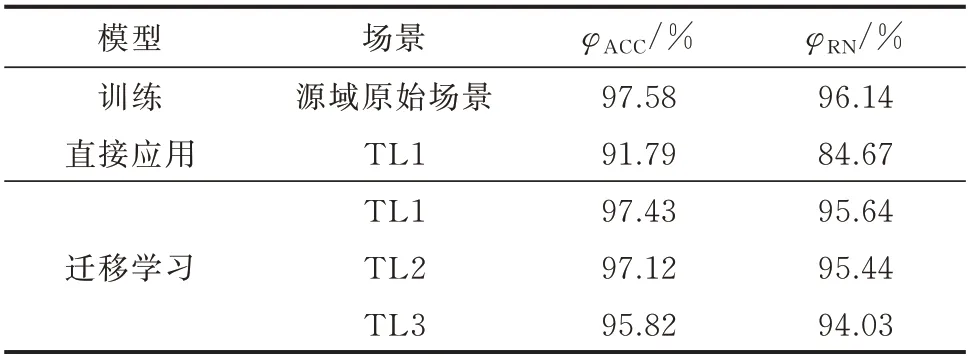
表5 美国南卡罗莱纳州500 节点电网测试结果Table 5 Test results of South Carolina 500-bus power grid in USA
4 结语
针对实际电力系统场景变化后判断稳定模型的更新问题,本文基于改进DANN 提出了一种端到端的暂态稳定自适应评估方法。在IEEE 39 节点及美国南卡罗莱纳州500 节点电网的测试结果表明:1)在增加时间维度信息的同时提升了对失稳样本和临界样本的敏感程度,保证了总体准确率和召回率;2)通过对抗训练缩小了域间分布差异,对源域数据的有效迁移使其对目标域训练样本的需求量降低,提升了更新速度;3)所提方法充分利用了模型的知识容纳量,与传统迁移学习方法相比有更好的可持续学习能力。
本文通过固定输入特征结构的方式保证各领域间模型迁移的有效性。为在更复杂的运行场景中应用改进域对抗迁移学习方法,后续研究将对电网量测数据进行处理,寻找具有明确物理意义且不受电网形态规模约束的特征量,拓展所提方法的应用范围。同时,如何结合样本方法提高模型在大型电力系统稳定评估中的召回率以及结合知识驱动方法与图神经网络进一步减少样本更新时间并提高样本积累期的稳定评估效果,也是值得研究的方向。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
