基于图排序和最大信息增益的领域实体抽取方法
2022-12-13张晓明郑理欣王会勇
张晓明,郑理欣,王会勇
(河北科技大学信息科学与工程学院,石家庄 050018)
0 概述
随着知识图谱技术的发展,越来越多的研究开始从通用知识图谱转向领域知识图谱,例如医疗知识图谱、金融知识图谱、电商知识图谱、课程知识图谱等。领域知识图谱中的节点是领域实体,因此,领域实体的挖掘是构建领域知识图谱的基础。以课程知识图谱为例,将传统的非结构化文本形式转化为以课程术语实体为核心的知识图谱,更易于学生对学科架构[1]、知识点的学习。教育知识图谱中的节点具有多样性,如节点可以为术语、视频资源、知识点等,而术语是最基础、最细粒度的学习资源。因此,构建课程领域实体集对教育知识图谱的构建起着重要的作用,为教育课程推荐、个性化学习等任务[2-4]奠定了基础。
目前对于实体抽取方法的研究主要采用基于机器学习的方法、基于深度学习的方法和基于关系的方法。垂直领域实体抽取与公开领域实体抽取特点不同,垂直领域的语料较少,标注数据稀缺,因此基于机器学习的方法、基于深度学习的方法在领域实体抽取过程中存在一定的限制。基于关系的实体抽取方法则是先获得候选实体,然后在给定种子的基础上利用实体间关系进行排序筛选,其中对于非结构文本数据源需要先构建相关度等关系再进行排序,对于结构化的知识则通过一定的策略利用已有的结构关系进行实体挖掘。
本文提出一种基于关系的领域实体挖掘方法,基于结构相关度从文本中构建实体图以抽取领域核心实体,根据最大信息增益原理在DBpedia 中对核心实体进行扩展。通过对基于维基百科的TagMe 系统进行实体识别,计算实体间的相关度,并根据图排序算法进行实体抽取获得领域核心实体作为种子实体集,在CSEN、EcoEN 数据集上对实体抽取方法进行评估。基于种子实体集在DBpedia 中计算具有最大信息增益的类,并将其实例经筛选后作为扩展实体,最终在INEX 数据集上对实体扩展方法进行评估。
1 相关工作
早期的实体抽取分为基于规则的方法[5-6]和基于统计的方法[7-8]。基于规则的方法抽取的实体准确率较高,但依赖领域语言特点,且领域移植性较差。基于统计的方法利用术语共现和词频等特征抽取实体,对低频术语不敏感,且依赖目标语料库。因此,基于以上方法的局限性,目前对实体抽取的方法主要采用基于机器学习的方法、基于深度学习的方法和基于关系的方法。
1.1 基于机器学习的实体抽取
该方法一般通过序列标注[9]、术语分布等特征利用分类算法抽取实体,通常需要大量的训练数据训练算法模型,实体抽取的准确率较高。但不同于通用领域的数据,领域的标注数据较为缺乏,由领域专家来标注数据则会消耗大量的时间和人力资源,因此这种方法在构建领域实体集时代价成本较高。
1.2 基于深度学习的实体抽取
该方法通过对文本向量嵌入,将嵌入向量输入到深度学习模型中,经过多个处理层的学习来抽取实体。基于深度学习的实体抽取方法不需要人工特征工程,具有强大的学习能力,也是近年来较好的实体抽取方法,典型的神经网络模型有BiLSTM[10-11]、CNN-LSTM-CRF[12-13]等,但该方法也存在一些限制,例如需要大量的标注数据,训练模型的时间较长,且存在模型复杂、可解释性弱的缺点。
1.3 基于关系的实体抽取
该方法通常在给定少数种子的条件下,利用候选实体间的关系进行排序来抽取领域实体。候选实体间的关系有类别信息[14]、结构路径关系[15]、语义路径[16]、语义距离[17]等。排序过程通常利用图排序算法[18]通过主题信息进行编码或利用候选实体之间的相互加强关系[19]来提高候选词的排名效果。
基于图排序的实体抽取方法较为常用,该方法的来源为PageRank 算法,将实体间关系紧密程度和领域实体的置信度作为衡量领域实体的依据,以此来迭代更新实体节点的置信度。例如利用单词上下文的语义信息[20]、位置信息[21]及图 结构的 主题信息[19]迭代更新图,对候选术语进行排序。基于图排序的实体抽取方法不需要大量的标注数据,不存在低频术语不敏感问题,是效率较高的实体抽取方法。
基于关系的实体抽取方法不需要大量的人工参与,具有普适性及可解释性的优点,因此利用该类方法构建课程领域实体集。首先利用维基百科的信息计算相关度来构建实体间关系,通过排序算法从中抽取领域核心实体,然后在知识图谱中利用最大信息增益进行实体扩展,最后通过计算扩展实体与领域核心实体的相关度进行扩展实体的过滤,提高领域实体集的质量。
2 问题描述
本文研究的问题是如何构建领域实体集。首先从文本中构建候选实体图,并利用图排序算法抽取领域核心实体;然后对DBpedia 中的subject 关系利用最大信息增益原理对核心实体进行扩展;最后通过实体过滤策略进一步提高领域实体集的准确性。任务描述如图1 所示。

图1 任务描述Fig.1 Tasks description
对使用的符号进行以下定义,候选实体图表示为G=(T,R),其中包括候选实体节点T和候选实体间的相关度R,ti(i=1,2,…,n)表示候选实体,rij(i=1,2,…,n,j=1,2,…,n)表示候选实体ti和tj的相关度,TC为领域核心实体集(TC⊂T),TC的扩展实体集表示为TE,扩展实体集筛选过滤得到的领域全部实体集表示为TD。
领域实体集获取方法主要包括3 个步骤:
步骤1在文本中进行实体识别,计算两两实体间的相关度构建实体图G,并通过基于置信度传播的图排序算法得到领域实体TC。
步骤2将文本抽取的领域实体TC作为种子,利用DBpedia 中的subject 关系进行实体扩展,得到扩展实体集TE。
步骤3通过筛选策略对扩展的实体过滤,以提高领域实体集的准确率,获得领域实体集TD。
3 基于图排序的实体抽取
基于文本的实体抽取主要分为构建候选实体图和对候选实体排序两大步骤。
3.1 候选实体图的构建
构建候选实体图的目的是利用文本中的实体及实体间的关系构建一个图,思想为识别文本中所有的实体作为候选实体集,候选实体之间通过相关度建立相关关系,这样就形成了一个结点为候选实体、边为相关度的候选实体图。
文本中的实体通常以缩读、口语化等形式出现,使得多个名词性短语表达的是同一实体,因此将文本语料中的名词性短语和维基百科中的实体建立映射关系,减少冗余实体。实体映射过程利用TagMe系统[22]对输入的文本自动识别出实体,并返回维基百科对应的实体。
候选实体间通过相关度建立关联,候选实体间的相关度是指两个候选实体存在相关关系的可能性大小,其取值为[0~1],值越大表示两候选实体间的相关性越强。每个实体在维基百科中有详细描述信息,在描述信息中提及次数较多的实体通常与该实体具有较强的相关程度,且每个相关实体都是以超链接形式存在的。因此,利用WML[23]模型,通过比较两个维基百科页面的输入和输出的超链接来衡量其语义相关度。对于两个候选实体ti和tj,I和J是分别链接到ti和tj的维基百科页面的超链接集合,W是维基百科中实体的集合,r(ti,tj)表示两候选实体间的相关度,通过WML 计算,如式(1)所示:

候选实体图G由所有的候选实体T和候选实体间的关系R组成,其中两两候选实体都通过相关度计算建立联系,但由于较低的相关度值r(ti,tj)在接下来的基于置信度传播的图排序算法中可能引入噪声,因此引入了一个相关度阈值α来修剪图,即当候选实体间的相关度r(ti,tj)大于阈值α时才保留在图G中。
3.2 基于置信度传播的图排序算法
对实体图的候选实体按照与领域的相关程度排序得到领域实体。对于实体图G中的每个候选实体ti,将conf(ti)作为领域实体的置信度。与较高置信度候选实体相关度高的实体很大可能也是该领域实体,从而可以发现其他潜在的领域实体。这里利用基于置信度传播的图迭代算法CCP[18]对候选实体进行排序。
首先给图G中的每个候选实体ti分配一个初始置信度,然后通过相邻候选实体的置信度及候选实体间的相关度迭代更新每个候选实体节点的置信度值。初始情况候选实体的置信度值由种子集决定,即将种子实体置信度值设为1,其他候选实体置信度值设为0。实体ti的置信度用conf(ti)表示,ti迭代k次后实体的置信度用confk+1(ti)表示,A(ti)表示与候选实体ti的邻居实体。置信度更新过程则是由A(ti)投票得分的平均值计算而来,即每次置信度的更新受其邻居实体的影响,若邻居置信度较高,则表示该实体是领域实体的可能性也越大。达到迭代停止条件时通过设定截止置信度阈值来选择领域实体,即置信度大于阈值的为领域核心实体TC,小于阈值的为非领域核心实体。图传播算法的迭代过程如式(2)所示:

其中:Z为标准化因子,取值为所有候选实体置信度的最大值;|A(ti)|表示ti邻居节点的个数;vsk(ti,tj)为候选实体tj对候选实体ti的影响,vsk(ti,tj)定义如式(3)所示,即tj的置信度与ti和tj的相关度值乘积。

基于文本的实体抽取具体实例如图2 所示。以数据结构课程中的部分文本内容为例,通过TagMe 系统识别出候选实体“Huffman coding,Binary expression tree,Data compression,Binary tree,Binary code,AA tree,Red-black tree”。计算两两候选实体间的相关度,并将相关度值小于阈值α的边r(Huffman coding,Binary code)、r(Data compression,Binary expression tree)、r(Binary tree,Binary code)等剪枝。给定种子实体为“Binary tree,Red-black tree”,则conf0(Binary tree)=1,conf0(Red-black tree)=1,其余候选实体初始置信度为0,第1 次迭代后各候选实体的置信度更新。迭代达到停止条件后取大于置信度阈值实体TC(“Huffman coding,Binary expression tree,Binary tree,AA tree,Redblack tree”)为数据结构课程实体。

图2 实体抽取实例Fig.2 Entity extraction example
4 基于最大信息增益的实体扩展
4.1 方法步骤
由于从文本中抽取的领域实体不够全面,因此需要进行实体扩展。下文对使用的概念进行定义,类表示实体在DBpedia 中通过subject 关系相连的抽象概念。每个实体有多个类,例如Red-black tree 的类有Binary trees、1972 in computing 等。
利用DBpedia 的subject 关系获得种子的类,在类中利用最大信息增益获得与种子相关程度较高的类,称为共性类,然后将共性类的实例作为扩展实体TE,最后通过计算扩展实体与种子的相关程度进行筛选过滤得到领域实体TD。该方法主要包括以下3 个步骤:
步骤1生成共性类。实体从不同的角度来看属于不同的类,会划分到不同的类下,共性类则是与种子集相关的类,即共性类能尽可能多地涵盖种子集中的实体。
步骤2共性类实例扩展。共性类通过subject的逆关系Is subject of 得到共性类的所有实例作为扩展实体TE。
步骤3扩展实体过滤。通过计算扩展实体与种子的相关性对扩展实体进一步筛选,以提高领域实体集的准确率。
4.2 共性类生成
共性类利用种子集与类的相关性和类的抽象程度两个因素衡量。当类的抽象程度较高时,其包含的实例通常越多,与种子集有较强相关性的概率越大,但抽象程度较高的类包含的实例也就越杂,即非领域实体就越多,因此当类同时满足种子集与该类的相关性较高且类的抽象程度较低2 个条件时才为种子集的共性类。为平衡这两方面因素的影响,采用最大信息增益原理将2 个条件相结合,如式(4)所示:

其中:c(t)表示实体t的所有类;ci表示其中一个类;p表示实体t的类ci与种子集TC具有共同特性的程度,取值范围为[0,1],值越大,表示类ci与TC的共性程度越高;I表示类的抽象程度,通过类的实例个数来计算。
式(4)参考了文献[15]实体扩展方法,其方法是在DBpedia 的DBO 体系中,根据关系路径的抽象程度和该路径上的实体与种子的相关程度来选择合适的关系路径,并对路径上的实体进行相关度排序得到扩展实体。本文则是在DBpedia 的SKOS 体系中,通过计算subject关系对应的类与种子的相关程度及其抽象程度选择合适的类,并对其实例进行过滤筛选,其中根据类的实例集与种子集的共现情况来计算类的相关性,通过类包含的实例个数评判其抽象程度。
最大信息增益是用来描述一个属性区分数据样本的能力,在这里最大信息增益是用来衡量类与种子集的共性程度,判断是否为共性类是从该类的相关性和抽象程度两个方面确定的。因为相关性高的类通常抽象程度较高,抽象程度低的类与种子的相关性通常较低,而生成共性类的目标是高相关性与低抽象程度,所以要平衡存在矛盾的相关程度和抽象程度方面因素,采用I(cj)-I(cj|ci)来衡量,该公式表示在计算类ci的共性值情况下,周围类cj对ci的影响,cj的抽象程度越低且与ci的相关程度越高,对ci共性值的计算影响就越大。ci(t)值越大表示类ci与种子的相关度高,并且周边的类也与种子相关度高,同时周边类的抽象程度低。c*(t)表示实例t的类中最大的共性值,最大共性值对应的类作为共性类。
4.2.1 种子集与类的相关性的计算
种子集与类的相关性由种子集与类实例的交集个数判断。判别方法如图3 所示,对于种子集t1、t2、t3中t1的类:类1 和类2,类1 的实例包括t1、t2、t4、t5、t6,类2 的实例包括t1、t7、t8、t9,类1 的实例与种子集有t1、t2两个相同的实例,类2 的实例与种子集有t1一个相同的实例。类的实例与种子集交集个数越多,该类与种子集的相关性越高,所以类1 比类2 具有更高的相关性。

图3 种子集与类相关性示意图Fig.3 Schematic diagram of correlation between seed sets and classes
通过式(5)计算类与种子集的相关性程度,将两者的交集个数作为衡量相关性的标准。

其中:TC表示种子集;‖‖TC表示种子集的个数;E(ci(t))表示实例t的类ci的实例。
种子集与类的相关性计算具体实例如图4 所示。以种子集TC={AVL tree,B-tree,Red black tree}中AVL tree为例,其类为Soviet inventions,Binary trees,Search trees,AVL tree 与3 个类的实例交集个数分别为1、2、2,相关度分别为1/3、2/3、2/3,则与TC相关度高的类为Binary trees、Search trees。
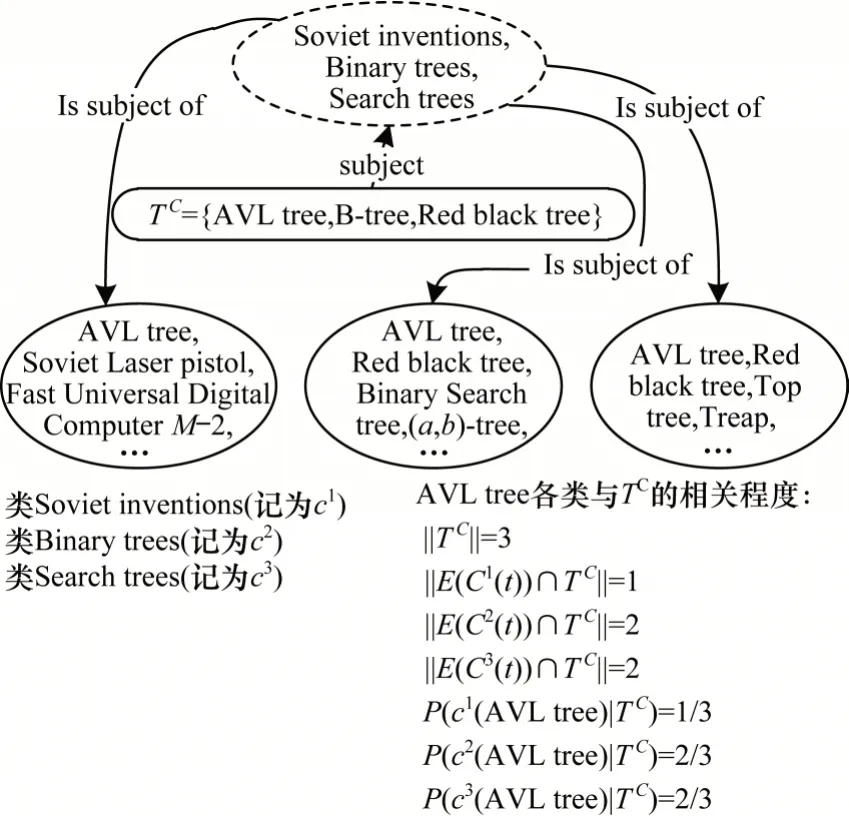
图4 种子集与类相关性实例Fig.4 Correlation between seed sets and classes example
4.2.2 类的抽象程度计算
类的抽象程度是指对实体描述的粗细程度,对实体描述的越抽象,抽象程度越高,即该类的实例涵盖范围越广,实体集间的相关性越小。实体扩展过程的目标则是生成抽象程度较低的类。通常抽象程度高的类,其实例数量一般也越多,抽象程度越低的类,其实例数量越少。因此,通过类的实例数量来判断其抽象程度,计算公式如式(6)所示:其中:N为t的类中实例个数最大的值;I值越大表示类的抽象程度越低,即该类的表达粒度越细。目标是获得抽象程度低的类,即I值越大越好。

通过式(7)探究类和周边的类之间的相关性,其值越小表示各个类之间的关联强度越强。类cj与类ci的相关性越强,则表明类cj对类ci的影响越重要,该值越小越好。

由于取共性类时仅将共性值最大的一个类用来扩展,使得扩展的实例较少,因此为提高领域实体的召回率,采用松弛机制适当放松生成类的条件,即为每个实体生成多个共性类,使得在保证一定查准率的同时提高扩展实体的查全率。当类ci的共性值ci(t)与最大共性类值c*(t)比值大于阈值θ时,类ci也作为实体的共性类。如图4 中AVL tree 的类中Search trees、Binary trees 都和数据结构课程的关联性较强,若仅选择其中一个类来扩展,则扩展的实例较少,因此在使用松弛机制后生成了多个类,会进一步提高领域实体的召回率。
4.3 实例扩展和过滤
通过以上步骤获取共性类,在DBpedia 中,共性类与其实例之间通过关系(Is subject of)相连,因此通过该关系提取共性类的实例作为扩展实体。例如AVL tree的类Search trees 包含的实例:Red black tree,Binary Search tree,(a,b)-tree,…均为AVL tree的扩展实体。
扩展过程也会引入噪声,例如类Binary trees 的实例中除Binary search tree、Top tree 外,还有Interleave lower bound、Rotation distance 这样的非数据结构的实体,因此需要对扩展实体再进行筛选。
领域实体中许多实体是由单词拼接而成的,以数据结构课程为例统计了术语实体中由词缀拼接而成的情况,如图5 所示,这对判别术语实体间相似度有着很大的参考价值。

图5 领域实体特点分析Fig.5 Analysis of domain entities characteristics
但基于字符串相似的特征具有局限性,没有考虑到实体间结构语义相关性,因此在计算扩展实体tj与种子集TC相关度时,将基于字符串的相似度Comm(ti,tj)和基于结构的相关度r(ti,tj)进行相加作为实例与种子集的相关度Sim,如式(8)所示:
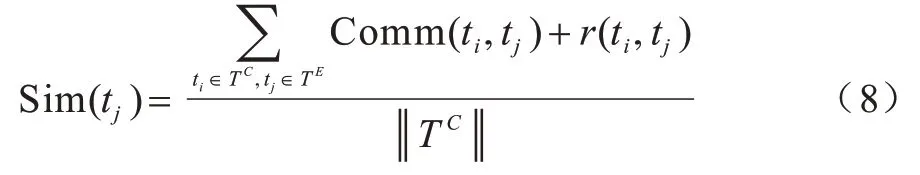
字符串相似度计算采用SMOA 算法[24]的Comm方法,如式(9)所示:

其中:分子为两个字符串的最大公共子串长度的两倍;分母为两字符串的长度之和。
基于结构的相关度r(ti,tj)利 用TagMe 系统实现,原理如式(1)所示。
扩展实体筛选过程首先计算扩展实体与每个种子的相关度,然后将该扩展实体与种子集相关度均值作为该扩展实体的相关程度,最后将扩展实体按相关度值由大到小排序,取topN 为领域实体TD。
5 实验结果与分析
5.1 实体抽取实验分析
本节首先分析实体间相关度阈值α和图传播算法迭代次数两个参数的影响,然后在最佳参数条件下与实体抽取基线方法分别在公开数据集和领域数据集上进行对比。
5.1.1 数据集和评价指标
在数据集CSEN、EcoEN[18]上进行实体抽取实验对比。数据集CSEN、EcoEN 是从MOOC 平台的Coursera 和XuetangX 上收集计算机科学和经济学英文版本的课程资源,其中从8 个计算机科学课程中收集视频字幕来形成CSEN 数据集,从5 个经济学课程中选取视频字幕来构建EcoEN 数据集。
实验评测指标选择精确率P、召回率R、F1 值、R-precision(Rp)、mean Average Precision(mAP)。精确率P是指扩展结果中领域实体个数与扩展实体个数的比值。召回率R是指扩展结果中领域实体个数与领域实体个数之比。F1 值是对精确率P和召回率R的综合评价。Rp 是一个关注排名的信息检索指标,给定一个包含n个种子的排名列表,它计算排序后的前n个实体中领域实体的精确率。平均精度均值(mAP)是信息检索中评价排名列表的重要评价指标,AP 指的是在不同召回率上的准确率,mAP 是AP的平均值,如式(10)所示:

其中:n为种子的个数;Ri为n个召回率;P(Ri)表示在召回率为Ri时的准确率。
5.1.2 实体抽取实验参数设置
实体相关度阈值α这一参数控制着实体图中边的建立。当α过小时,一方面使得实体图中的边较多,计算复杂度大,另一方面使得置信度传播过程噪声增大。当α过大时,会使得存在相关性的实体间因未建立边而造成召回率较低。如图6 所示,当α取0.2 时Rp、mAP 取得最高值,因此实体图构建时候选实体间相关度阈值设为0.2。

图6 不同阈值的Rp 和mAP值Fig.6 Rp and mAP values of different thresholds
迭代次数决定图迭代何时结束,迭代次数过少会使得置信度不能充分传播到每个实体上,导致领域实体的实体置信度值较低而被过滤掉,从而使召回率较低。迭代次数过多则会使置信度值趋于一致,从而引入非领域实体且浪费计算资源。图7 所示为在不同迭代次数的条件下Rp 和mAP 值。迭代次数过少则无法扩展更多的领域实体,例如当初始条件时(即迭代次数为0)领域实体仅为种子,迭代次数过多则在扩展实体中引入非领域实体,例如当迭代次数过多时,高置信度的实体会被邻居节点的投票得分拉低,导致领域实体与非领域实体置信度值趋于一致。从图7 可以看出,迭代次数从6 到11 时尚有下降趋势,说明迭代过程中扩展了领域实体,导致种子实体排名下降。第11 次迭代后基本不变,说明基本不再扩展更多的领域实体,所以种子实体排名也基本不变,如果继续迭代则会使得所有实体置信度值的差值越来越小,不利于根据置信度值判定是否为领域实体,因此最佳迭代次数为11。
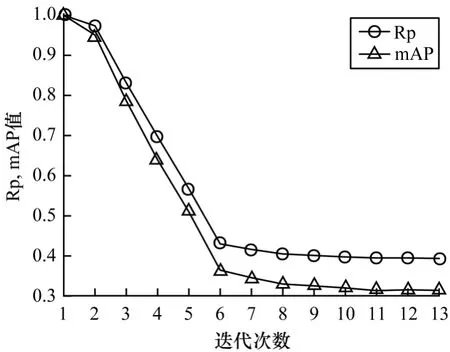
图7 不同迭代次数的Rp 和mAP值Fig.7 Rp and mAP values of different iterations
5.1.3 与基线实验的对比
实体抽取的实验基线选取了两个基于统计的方法TF-IDF 和PMI,两个基于图的方法TextRank、topic PageRank(TPR)与CCP,基线结果来自文献[18]。从表1 可以看出(粗体数字为最优结果),在CSEN 数据集上的Rp 和mAP 评价指标仅次于最优的CCP 方法,在EcoEN 数据集上Rp 指标达到最优效果,mAP指标仅次于TPR 方法。总体分析可以看出,本文实验效果与CCP 接近,但本文实验不需要搜集大量的领域资料与嵌入过程,相比而言,本文实验的操作更加便捷。
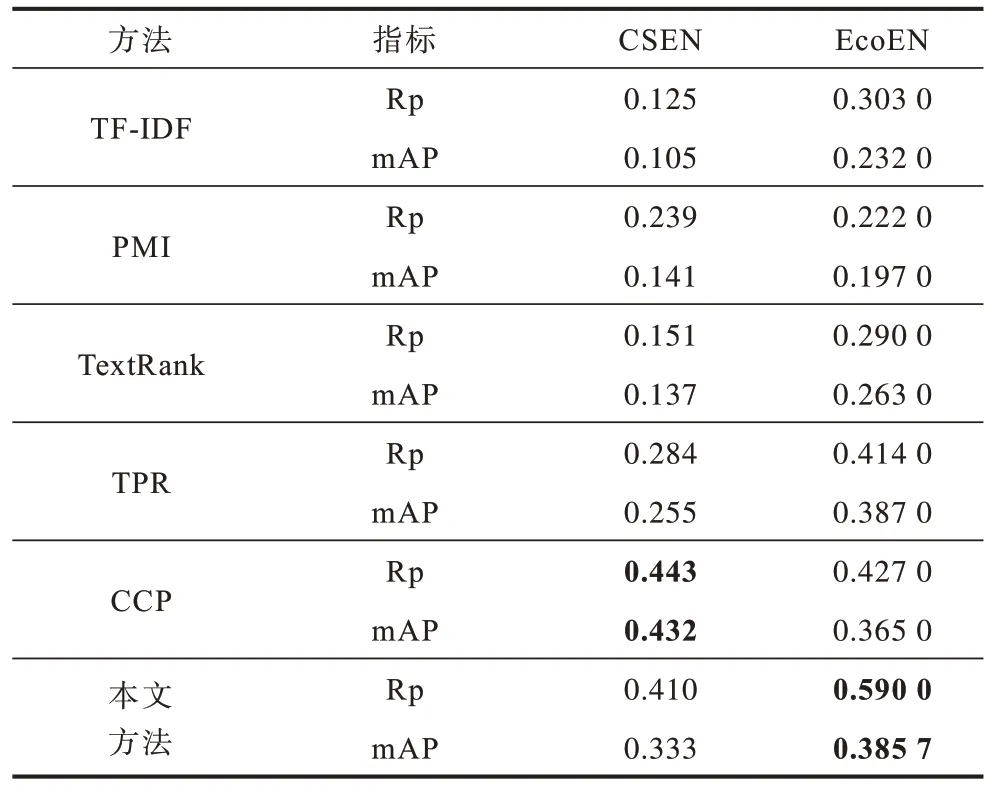
表1 实体抽取结果Table 1 Results of entity extraction
5.1.4 领域数据集的实体抽取实验结果
数据结构领域实体抽取数据源为数据结构教材,以每章中的节为单位进行实体抽取,评价结果为各节评测值的平均值。实验对比基线为TextRank、TF-IDF,评价指标采用P@n、Rp 和mAP,在P@n中n分别取值5、10、20,结果如表2 所示(粗体数字为最优结果)。

表2 数据结构领域实体的抽取结果Table 2 Extraction results of data structure domain entity
由于基于图的TextRank方法和基于词频统计的TFIDF 方法均受到语料规模及质量的影响,因此在语料相对较少的情况下实验效果较差,而本文所提出的方法则是利用维基百科作为背景知识进行实体抽取,因此受语料影响较小,从而具有较好的实验结果。
从表2 中可以看出,在评测指标P@n中,随着n的增大,P@n呈下降趋势,这是合理的现象。因为实体按领域性相关性排序后,在领域相关性越强的部分领域实体越密集,随着领域性的减弱,领域实体越稀疏,所以会出现在P@n中随着n的增大,P@n减小的趋势。
5.2 实体扩展实验分析
本节首先分析实体扩展实验中参数的影响,然后将扩展方法与基线在公共数据集INEX 上进行对比,最后分析在数据结构课程领域数据集上的扩展结果。
5.2.1 数据集和评价指标
公共数据集采用INEX-XER2009[25](INEX),领域数据集采用本文构建的数据结构领域术语实体集。INEX 是一个包含60 个主题的数据集,其中每个主题包含一个问题描述和若干个种子,按每个话题给出种子个数(seed=2、3、4、5),INEX 分为4 组数据。该数据集常被用来评估实体检索相关任务,如实体排名、实体扩展任务。数据结构领域实体由5 名计算机专业研究生手动标注,取其公认的领域实体作为数据结构领域实体集。
评估测度采用召回率R、准确率P、F1 值和前n个结果的准确率P@n,本文取P@5、P@10和P@20。
5.2.2 松弛机制参数的影响
为研究松弛机制对扩展实验的影响,在INEX 的4 组数据上评估松弛阈值θ的影响。松弛机制的目的是获得较高的召回率,因此这里的评测指标仅为R,结果如表3 所示。从表3 可以看出,随着θ的减小,召回率R不断增大。当考虑种子数量seed 的影响时,在seed 取值为2、3、4 时,随着种子个数的增加,召回率也在提升,这表明种子越多,实体扩展方法的性能越好。当seed 取值为5 时,召回率较小,这是因为种子越多,其共性会减弱,使得召回率较低。当考虑松弛阈值θ的影响时,随着θ的减小,召回率R不断提高,当θ取0.6 时,R值最大,但当θ从0.7 减小到0.6 时,R的增幅较小,但每降低较小的阈值,得到的扩展实体个数会增加很多,扩展结果中有很多的非领域实体,使得实体筛选的时间较长。因此,松弛阈值取0.7。
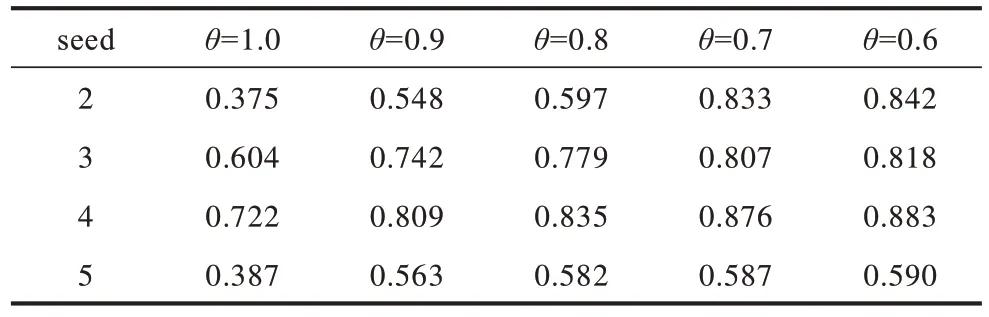
表3 松弛机制参数θ对R 的影响Table 3 Influence of relaxation mechanism parameters θ on R
5.2.3 实体扩展与基线实验的对比
本文实验将与已有的7 个基线进行比较,基线和基线间的实验结果来自文献[18]。基线包括LDSD、BBR、ARM、QBEES、SEAL、ESER。其中,LDSD 是基于链接的实体扩展方法,BBR、SEAL 为基于非结构化文本的实体扩展方法,ARM 为基于关联规则挖掘的方法,以及基于种子共同特征的QBEES、ESER 实体扩展方法。
在INEX 的4 组数据上评测P@5、P@10和P@20,将4 组结果的均值作为评测结果,如图8 所示。
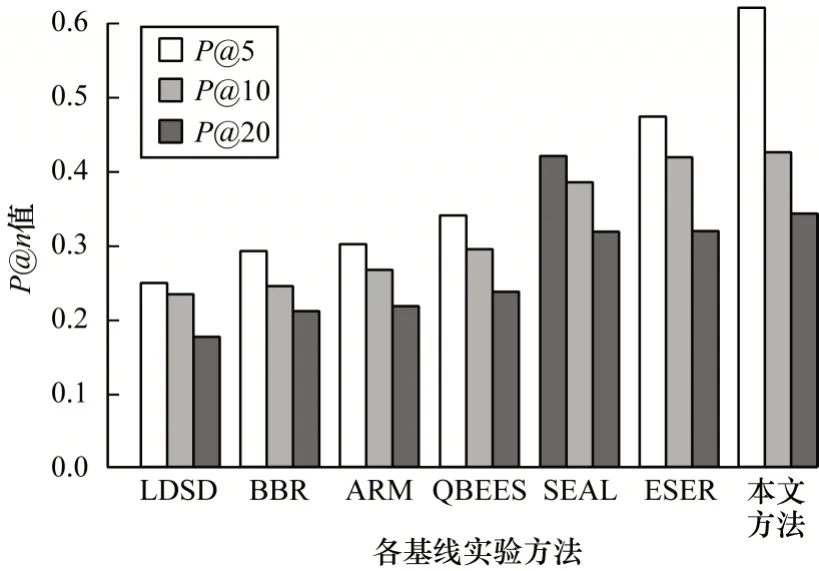
图8 不同基线的对比结果Fig.8 Comparison results of different baselines
基于知识图谱的扩展方法LDSD 表现较差,这是因为其利用的是文本描述中出现的带有超链接的相关实体来评估实体间的相似性,没有考虑种子的语义相关性。基于自然语言处理模型的实体扩展方法表现优于LDSD,但相较于本文基于语义结构的方法扩展效果相对较差,这也表明了基于自然语言处理模型从非结构化文本中扩展实体有一定的局限性。ARM 应用关联规则挖掘来发现频繁模式,利用种子间的共性提高了召回率,但其排序模型不足以达到良好的准确性。由于知识图谱是不完整的,QBEES 应用严格的模式检索类似的实体会导致召回率较低。SEAL 从搜索引擎的强大功能中收益良多,使得检索到的网页与种子相关度较高,然而在某些情况下很难从非结构化文本中发现和提取种子的共性。ESER 在结构化知识图谱中通过挖掘种子的公共语义路径扩展实体有着良好的表现,但随着种子个数的增加,挖掘的路径越多,导致扩展的实体精度降低。本文方法在INEX 上综合表现最好,因为在扩展过程中仅利用了知识图谱中的一跳路径,即类与实例的关系,避免路径过长出现语义漂移,再利用扩展实体与种子实体的字符串相似性和结构距离相关性对扩展实体排序,使得扩展实验在拥有较高召回率的基础上提高TopN的准确率。
排序后的扩展实体在相关度越高的部分领域实体越密集,随着相关度的降低,领域实体越稀疏,所以P@n随着n增大而减小。
5.2.4 领域数据集的实体扩展实验结果
在数据结构领域数据集上按章节进行实体扩展,即以每章节的核心术语实体为种子在DBpedia中扩展。在实验评价中随机选取了3 个章节P、R和F1 值的平均值作为领域实体扩展的评测结果。不同松弛机制阈值下的实体扩展结果如表4 所示。

表4 数据结构领域实体的扩展结果Table 4 Extension results of data structure domain entity
从表4 可以看出,阈值越低召回的领域实体越多,因此将松弛机制阈值θ为0.7 时的扩展实体进行标注获得领域实体。随着松弛阈值的减小,P值降低,R提高,这是因为阈值越小,扩展得到的实体越多,使得R提高,同时也因为引入了更多的非领域实体使得P降低。从综合评价指标F1 可知,当阈值θ取0.8 时,扩展的数据结构领域实体效果最佳。
5.3 结果展示
从数据结构课程文本中分别抽出各章节的核心实体,例如从讲解Heap的章节中抽取出实体Binary heap、Heap(data structure)、Binomial heap,在DBpedia 中利用实体的subject 关系(Is subject of 的逆关系)选择类Heaps,类通过Is subject of 获得其实例,最后通过实体筛选过滤,得到扩展实体Fibonacci heap、Breadth first traversal、Treap 等。通过挖掘课程领域核心实体和从DBpedia中扩展实体共获得数据结构领域实体1 115个,结果如图9 所示。

图9 实体扩展示例Fig.9 Entity expansion example
6 结束语
本文利用候选实体间结构相关度构建概念图,通过基于置信度传播的图排序算法抽取核心实体,在DBpedia 中计算关系路径的最大信息增益选择实体的共性类,并将共性类下的实例作为扩展实体,最后通过基于字符串相似和结构相关度的排序方法对扩展概念进行过滤。实验结果表明,实体抽取方法在CSEN 数据集上仅次于CCP 方法,在EcoEN 数据集上达到最优,实体扩展方法在INEX 数据集上的P@n均优于基线实验。本文对领域实体相关度的计算以及扩展实体的筛选排序过程均未考虑语义上的相似度,这可能影响实体挖掘方法的鲁棒性,下一步通过将文本嵌入计算实体向量的语义相似度,从而使实体间相似性的计算更加可靠全面,并利用实体间关系信息挖掘领域实体,根据图像等多模态信息进行实体挖掘。
