一种基于网络流量风险数据聚类的APT 攻击溯源方法*
2022-12-12葛维静冯园园刘宗洋许贤龙刘洋
葛维静,冯园园,刘宗洋,许贤龙,张 译,刘洋
(成都深思科技有限公司,四川 成都 610095)
0 引言
高级持续性威胁(Advanced Persistent Threat,APT)攻击是指攻击者使用多种先进手段,对特定目标展开的持续的、高威胁性的网络攻击活动,它有3 个重要特征:(1)攻击能力强,这体现了APT 中的A(既先进性)这一方面;(2)持续时间长,这体现了APT 中的P(即持续性)这一方面;(3)目标特定,危害程度大,这体现了APT中T(即威胁性)这一方面[1]。这种攻击活动的发起者往往具有较强的政治背景,攻击活动具有极强的隐蔽性和针对性,而攻击活动的受害者也往往要承受巨大的损失。
根据奇安信发布的《全球高级持续性威胁(APT)2021 年度报告》披露的数据,2021 年度全球APT攻击的主要目标包括政府、医疗、科技、国防、制造、运输、教育、航空、通信、能源等社会生活的方方面面。攻击手段也有从传统的鱼叉攻击向大量利用0day 漏洞发展的趋势。此外,针对基础设施及供应链攻击的事件愈发泛滥,甚至有越来越多的针对网络安全产品的攻击活动,APT 攻击的发生频率和威胁程度呈持续扩大的态势[2]。
APT 攻击不仅危害性大,而且隐蔽性强。2022年2 月23 日,奇安盘古实验室发布报告,发现隶属于美国国安局的“方程式”组织利用顶级后门,对中国等45 个国家开展了长达十几年的名为“电幕行动”的网络攻击,攻击目标所属的行业涵盖了电信、大学、科研、经济、军事等。
我国是APT 攻击的最大受害国之一。长期以来,“海莲花”“蔓灵花”“虎木槿”“方程式”等APT 组织对我国进行了持续性的网络攻击,使相关领域遭受了极大的损失。而且,针对政府、国防、能源、金融等重点行业的攻击频率在最近几年都有100%以上的涨幅,个别行业甚至有200%以上的涨幅[3]。
APT 攻击的溯源一直都是网络空间攻防中极为重要的一环。做好溯源工作不仅能使相关部门掌握APT 攻击的活动规律,做好应对与防范,有效减少损失,还能使我国在面对敌对势力在网络安全问题上的舆论攻击的时候,拿出确凿的证据进行有力的反驳,有效维护国家尊严。
1 传统的APT 攻击溯源方法
1.1 基于日志记录的溯源
在常见的网络攻击活动中,典型的攻击过程如图1 所示。攻击者通过多个中间节点(路由器),连接到受害者的主机,或者把攻击载荷投送到受害者的主机上。在这个过程中,攻击者到受害者之间的每个节点都会留下日志记录。攻击发生后,追踪者根据掌握到的攻击数据包特征,与获取到的各个路由节点的日志记录进行匹配,如果匹配成功,则可断定攻击的数据流经过这一节点。如此一级一级地追踪,直至发现真正的攻击者。

图1 网络攻击过程模型
这种溯源的方法可以看作对攻击过程的一种逆向追踪,但使用这种方法进行溯源具有如下困难:
(1)需要获取并存储大量中间路由节点的日志数据[4],而这往往需要使用行政手段得到网络运营商(Internet Service Provider,ISP)的支持[5],对于一般的企业或单位来说具有较大的难度。
(2)中间环节易中断。跟踪者往往无法获取到境外运营商的路由节点日志数据,对于来自境外的网络攻击,追踪链就会中断。而一旦追踪链中断,往往会导致前期的追踪工作前功尽弃[6]。
(3)如今的网络攻击大量使用僵尸网络,即使费尽周折找到了发起攻击的IP,最终也往往是僵尸网络,还是难以确定攻击者的身份。
综合以上原因,这种溯源的方式在面对有组织的APT 攻击的时候成功率会大大降低,而成本则会大大增加。
1.2 基于包标记技术的溯源
所谓的包标记是指在网络节点(如路由器)中以特定的概率对通过的数据包进行标记,并将路径信息标记在IP 数据包的预留字段中[7]。在受害者接收到数据包后,通过解析其中的标记信息,即可重构数据包的路径。包标记过程如图2 所示。
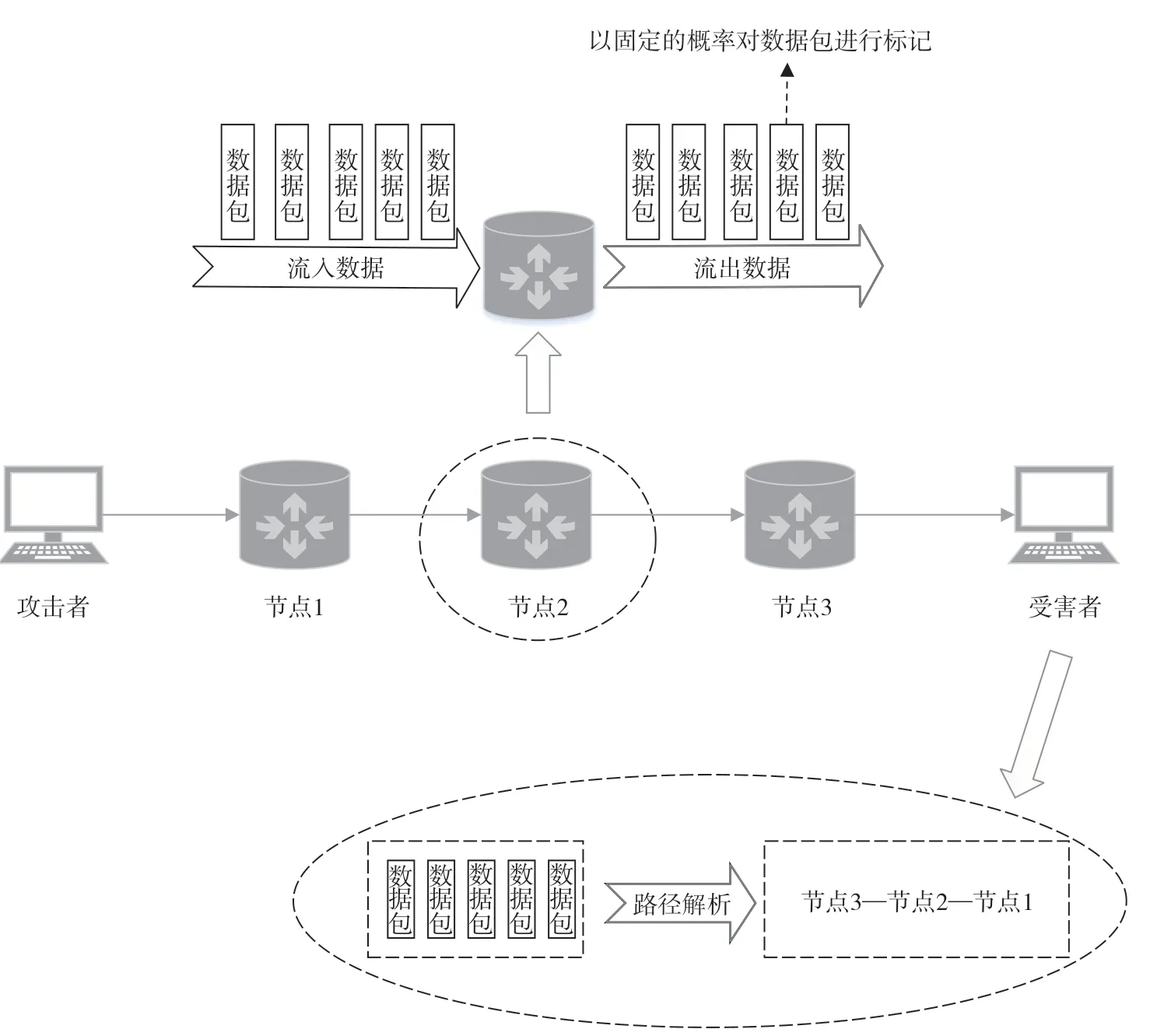
图2 包标记技术[7]
使用包标记技术进行溯源,无须再存储海量的中间节点产生的日志数据,然而还是需要运营商对中间节点进行特殊的改造和设置。同时,上文所述的基于日志数据的溯源方法中存在的中间环节易中断且无法对使用僵尸网络的攻击者进行溯源的问题依然存在。
1.3 基于主动感知数据的溯源方法
为了解决以上两种方法的数据获取难的问题,陈周国等人[7]提出了一种基于主动感知数据的溯源技术框架,其架构如图3 所示。

图3 基于主动感知数据的溯源框架
在此方法中,网络感知是基础,可以通过拓扑主动发现、网络扫描和渗透等多种主动感知技术进行信息获取。追踪溯源模块则对感知到的数据进行分析处理,重构数据传输路径,并将结果与感知及策略管理模块进行交互,以动态调整系统运行策略和感知内容。
2 基于网络流量风险数据的溯源方法
2.1 溯源框架
在上述溯源方法中,溯源过程需要巨大的人力成本。在面对愈发频繁和复杂的APT 攻击的情况下,这种溯源方式的效率日益低下。
近几年,基于流量还原的网络空间态势感知技术不断发展,相关产品也已在市场上取得了不错的反响。通过对流量还原数据的分析和挖掘,可以发现网络流量中的攻击行为,并将其作为风险数据存储到单独的风险数据库中。本文基于这些挖掘出的风险数据,提出了一种APT 攻击溯源的新思路。其整体框架和溯源流程分别如图4、图5 所示。
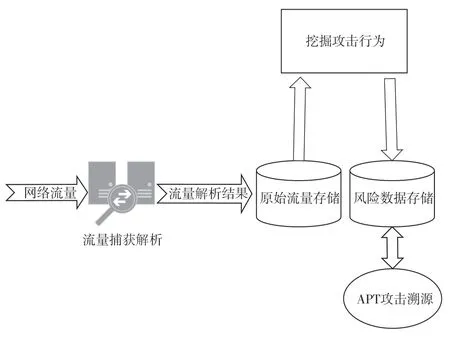
图4 基于网络流量风险数据的溯源方法整体框架
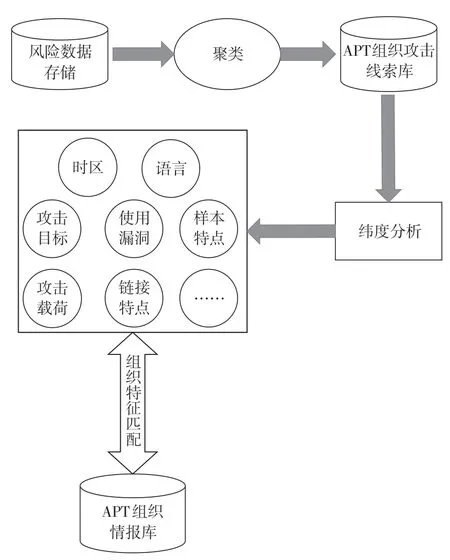
图5 基于网络流量风险数据的溯源流程
APT 攻击溯源的最终目的是定位到发起攻击的组织或个人[8]。APT 组织往往都与特定的政治实体有关联,在一段时间内具有较为固定的攻击目标、武器库、漏洞库等,这些特征就可以成为确定一个组织的不同的维度。因此,溯源的过程可以分解成确定这些特征维度的过程。确定了维度之后,再与已有的APT 组织情报库[9]进行匹配,就可以定位到某个具体的组织[10]。
在图5 所示的溯源流程中,先基于风险数据进行聚类分析,把具有相似特征的多种类型的风险数据聚合在一起;然后再基于这些聚类的结果进行维度分析,得到APT 组织的攻击目标、时区、语言等维度的数据;最后基于分析得到的各个维度的结果,与APT 组织情报库中的组织特征进行匹配,确定该组织是否是某个已知的APT 组织,或者是一个未知的组织。
本文重点研究在此方法中对风险数据进行聚类的过程。
2.2 聚类算法模型
2.2.1 定义
定义1:聚类(P)。把一批风险数据划分成不同的数据集的过程。
定义2:线索(C)。一条风险数据就是一个线索,如一封钓鱼邮件、一个木马样本等。
定义3:维度(D)。为方便对数据进行数学表示,而对数据进行拆分描述的不同的侧面。
定义4:元素(E)。从风险数据中提取出来的各个维度的值。
定义5:线索集(S)。一批风险数据的集合。
线索与元素的关系如图6 所示。
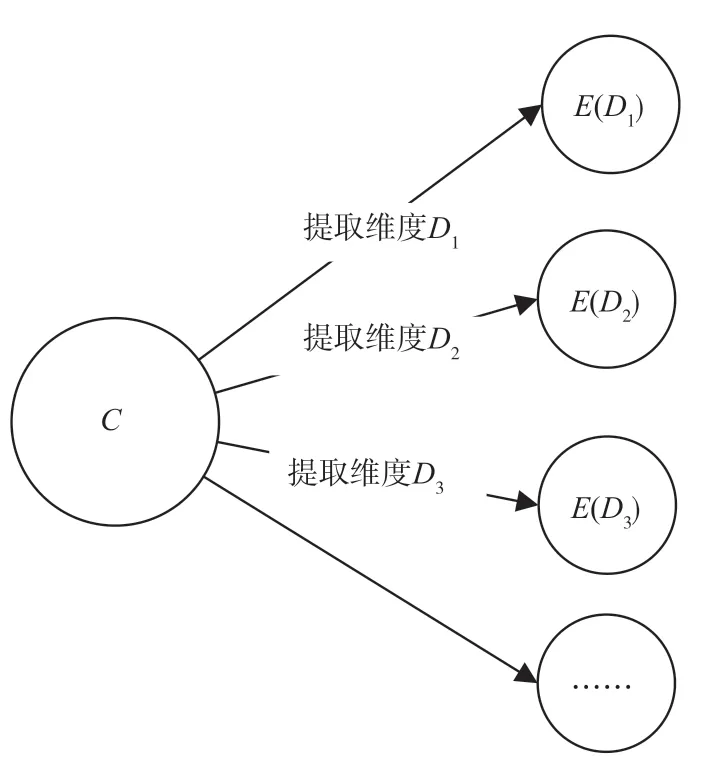
图6 线索与元素的关系
2.2.2 数学模型
根据以上定义,整个聚类的过程如图7 所示。

图7 聚类过程的数学表示
在图7 中,S0表示风险数据库中的一批线索的集合,P表示聚类的过程,S1,S2,S3,…,Sn表示聚类得到的线索集,其中,
2.2.3 聚类算法
在本算法中,前置条件是需要有一批可以进行维度拆分的网络流量风险数据。首先对数据的各个维度进行特征提取,然后转换得到每个维度的元素值与线索集的映射。若用E(Dn)i表示此映射中任意一个键值对的key,Si表示映射中任意一个键值对的value,则此键值对的含义就是Si中的每一条线索都可以在维度Dn上提取出相同的元素值E(Dn)i。
得到以上映射之后,把映射中所有键值对中的值两两之间取交集,得到多个新的线索集。这些新的线索集中的线索,彼此之间都有至少2 个维度的元素值是相同的。然后在这些取交集得到的结果线索集中,过滤出线索数量超过阈值的线索集,作为后续聚类操作的聚类中心。
对每一个聚类中心的线索进行特征提取,然后针对原始线索集中不在任何一个聚类中心的线索,分别计算其与每一个聚类中心的归属度。归属度的具体算法:聚类中心在每个维度上的所有元素值都与线索对应维度的元素值计算相似度,如果有多个值,就对计算出来的相似度求和,即得到在此维度上的分数;然后把各个纬度的分数按照对应维度的权重计算加权平均值,得到一个线索归属于某个聚类中心的归属度。得到任意一个不在聚类中心的线索归属于任意一个聚类中心的归属度后,把线索加入到归属度超过阈值且分数最高的聚类中心。在此过程中,每个聚类中心又吸收到了与之归属度超过阈值且分数最高的线索。
最后计算不同的聚类中心两两之间的相似度。相似度的具体算法:首先,对两个聚类中心在同一维度的元素值计算彼此之间的相似度,如果有多个值,就把多个值求和,得到的结果即为在此维度上的分数;其次,把各个纬度的分数按照对应维度的权重计算加权平均值,就得到两个聚类中心的相似度。求得所有聚类中心两两之间的相似度之后,把相似度分数超过阈值的两个聚类中心进行合并,从而得到最终的聚类结果。
上述聚类算法的过程可以用如下的数学方法进行描述:
步骤1:如图8 所示,遍历线索集S0,对于每一条线索C,提取维度特征E(D1),E(D2),E(D3),…,得到线索对应特征向量的映射M1。
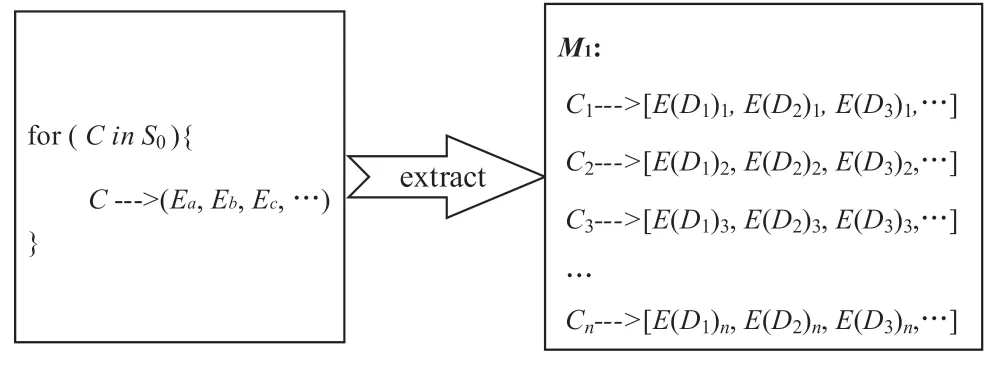
图8 聚类算法步骤1
步骤2:如图9 所示,转换映射M1,得到的元素值对应线索列表的映射M2。
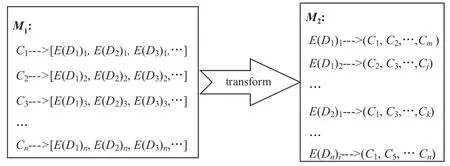
图9 聚类算法步骤2
步骤3:如图10 所示,对映射M2中的线索列表两两之间取交集,得到线索集
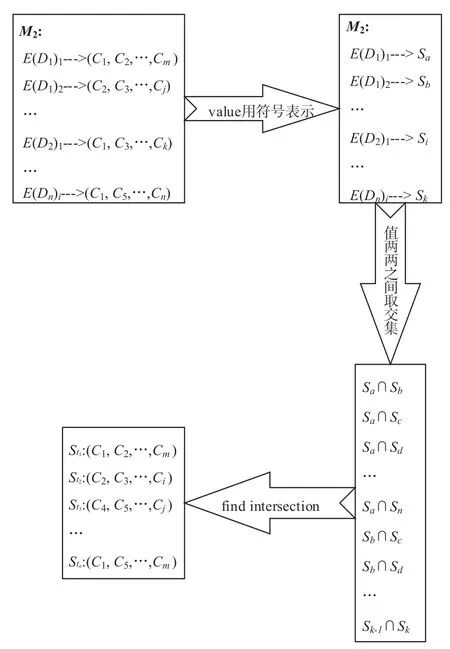
图10 聚类算法步骤3
步骤4:如图11 所示,对上述结果进行过滤,选出线索数量超过阈值的线索集。

图11 聚类算法步骤4
步骤5:如图12 所示,对上述得到的线索集中的线索进行元素提取。

图12 聚类算法步骤5
步骤6:把原始的线索集S0与步骤4 得到的所有线索集的并集取差集,得到线索集Sr,即S0-
步骤7:对于Sr中的每一条线索Ci,分别计算与线索集Stj的归属度。
步骤8:如图14 所示,对上述结果进行过滤,把线索加入到归属度超过阈值且分数最高的线索集中。

图13 聚类算法步骤7
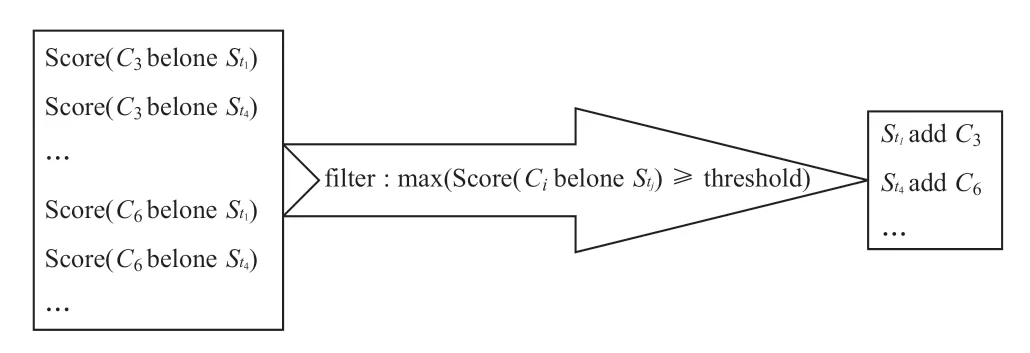
图14 聚类算法步骤8
步骤9:如图15 所示,计算上述结果线索集中彼此之间的相似度。
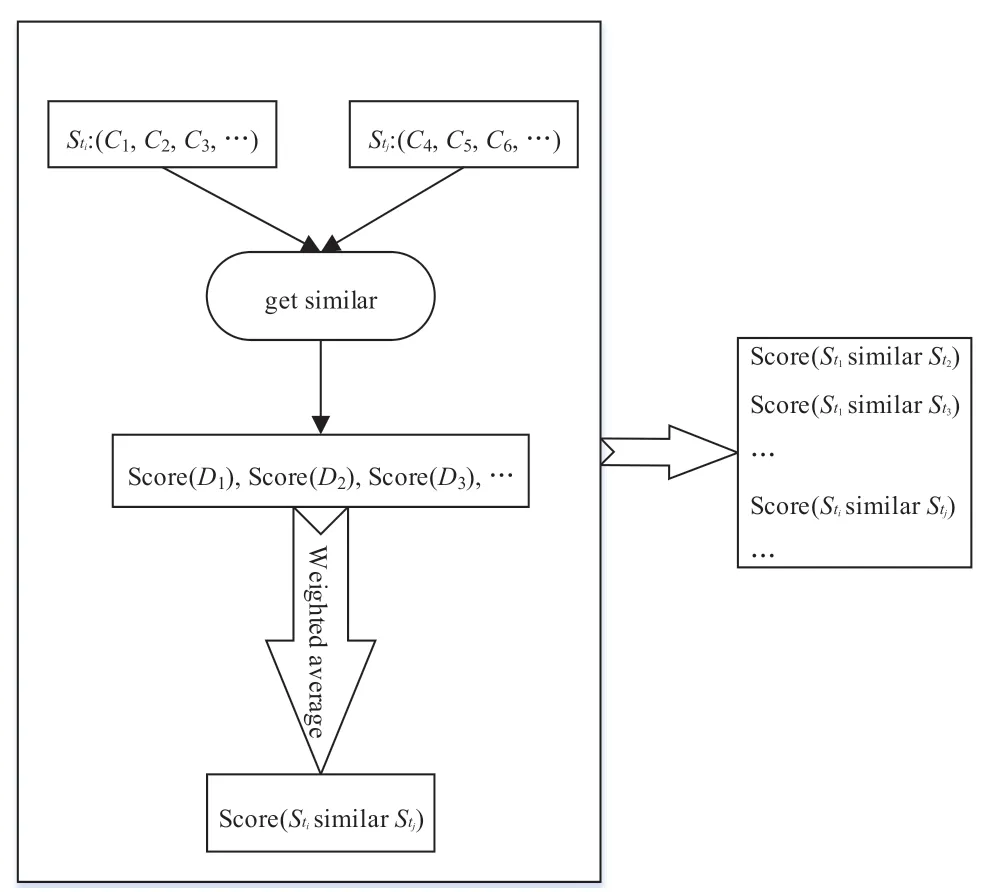
图15 聚类算法步骤9
步骤10:如图16 所示,合并上述结果中相似度超过阈值的线索集,得到最终的聚类结果。

图16 聚类算法步骤10
2.3 实验
2.3.1 场景设计
实验场景:获取一批邮件数据,对其进行解析,把解析的结果存储到库中。使用某种编程语言实现上述聚类算法,读取存储的邮件数据,并进行聚类,最后对聚类的结果进行分析。
数据准备:1 000 条邮件数据
数据样例:


2.3.2 结果评判标准
为了对一批数据的聚合程度进行量化,本文提出了同源度、聚合度与密集度的概念。
同源度用于衡量两个线索是同一个组织产生的程度,其结果是一个大于0 的数字。用符号F(Ci,Cj)表示线索Ci和Cj的同源度,similar(E(Dk)i,E(Dk)j)表示线索Ci和Cj在维度Dk上的值的相似度分数,P(Dk)表示在维度Dk上的权重,每条线索能提取出n个维度,则有如下公式:

聚合度用于衡量线索集中任意一个线索与整个线索集之间的归属程度。用符号A(Ci)表示线索集S中任意一条线索Ci的聚合度,线索集S中的线索数量为n,则有如下公式:

密集度用于衡量线索集中不同线索之间的平均聚合度,其值越大,表示此线索集中的线索彼此之间的同源度越高,聚类的效果就越好。用符号f(Si)表示线索集Si的密集度,线索集Si中的线索数量为n,则有如下公式:

2.3.3 结果分析
本节使用Java 语言实现上述聚类算法。线索的纬度划分及权重如表1 所示。

表1 邮件数据维度划分及权重
实验共得到42 个聚类结果,其中数据条数超过20 的聚类结果有7 个。原始线索集及聚类结果的线索数量分布如图17 所示。

图17 原始线索集及聚类结果线索数量分布
计算原始数据和聚类结果中每个线索的聚合度,从每个线索集中随机获取10 条数据,得出其每个线索的聚合度分布如图18 所示。
从图18 可以看出,最下面的一条折线是原始数据的聚合度分布,其分数较低,说明原始线索集中的数据的聚类程度较低。在图18 的聚类结果中,所有线索的聚合度分数都要高于原始数据,说明这些聚类结果的聚类程度都要高于原始线索集。

图18 原始线索集及聚类结果线索聚合度分布
对原始线索集和聚类结果分别计算密集度,得到的结果如表2 所示。
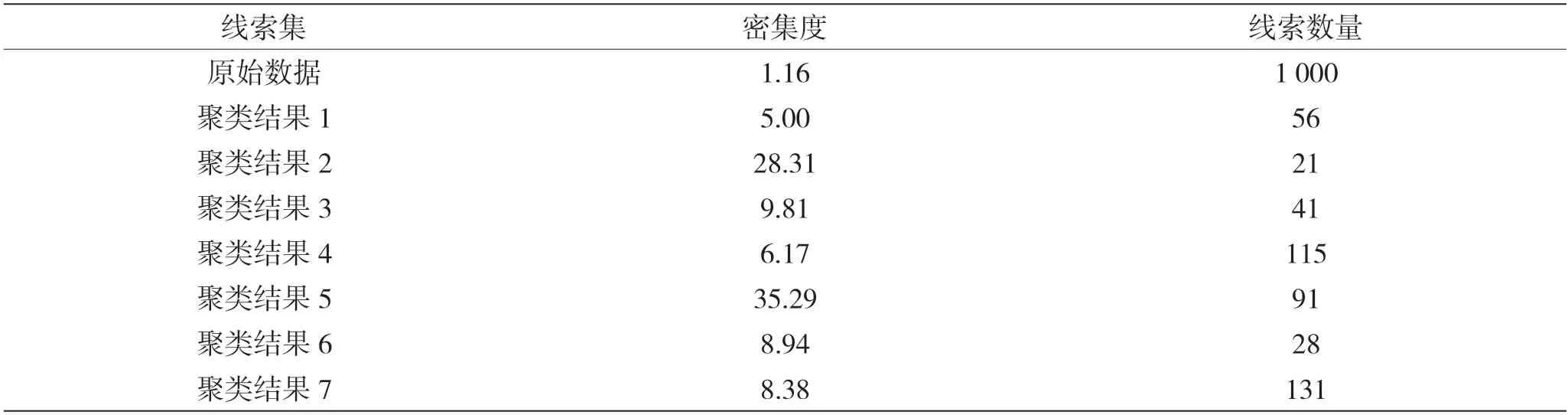
表2 聚类结果密集度及线索数量
把上述密集度分布用柱状图表示,如图19 所示。从图19 中也能很直观地看出,所有的聚类结果较原始数据的密集度都有了数倍的提升,进一步说明了此算法的有效性。

图19 原始线索集及聚类结果密集度
3 结语
本文介绍了传统的APT 攻击溯源的方法,分析了传统溯源方法的局限性,提出了一种基于网络流量风险数据的溯源方法,建立了此方法的溯源框架,然后重点分析了此框架中基于风险数据产生APT 组织攻击线索库的过程,提出了一种自动聚类的算法。该算法把风险数据自动划分成多个不同的线索集,并使用Java 语言实现了此算法,在测试数据上验证了算法的有效性。
在上述实验中,每条数据的维度划分以及权重和阈值的设置对聚类的结果会有较大的影响,这些参数都需要具有一定相关经验的人员进行测试和验证。
后续的研究内容包括对数据拆分的维度和权重以及阈值等参数,使用机器学习的方法进行训练,增加最终聚类结果的准确度;对聚类得到的线索集进行维度分析;根据APT 组织的维度匹配到具体的APT 组织的方法进行深入研究。
