基于深度提升网络的入侵检测技术研究
2022-12-12张如雪缪祥华
张如雪 缪祥华,b
(昆明理工大学a.信息工程与自动化学院;b.云南省计算机技术应用重点实验室)
基于已知攻击特征的传统静态安全方法在网络入侵检测中已经取得了不错的效果,但是传统静态方法不能有效防御新的攻击, 如0day攻击、后门攻击及高级持续威胁(APT)等,这些攻击者可以发动有针对性的持久渗透攻击,表现出较强的隐蔽性,潜伏期特别长。 针对这些新的攻击需要研究新方法来应对[1,2]。
Logit、KNN、SVM、神经网络、决策树及随机森林[3]等机器学习模型被广泛应用于入侵检测研究,并取得了较好的效果[4]。 2014年,张阳和姚原岗提出的XGBoost算法具有效果好、 速度快及能处理大规模数据等特点[5]。 但是基于单个学习器只能学习到一个假设, 存在泛化能力不强的问题。因此,笔者采用XGBoost和GBDT[6]构成集成学习模型,以期多个假设在同一个训练集上达到较高的性能。
1 相关理论
1.1 自动编码器
自动编码器(AutoEncoder,AE)是一种无监督神经网络模型[7],它可以学习到输入数据的隐含特征, 使用Encoder对输入进行编码, 并使用Decoder对输出进行解码,如图1所示。 AE可以提取到更有效的特征,比传统降维方法主成分分析(Principal Components Analysis,PCA) 效果更好,除了降低函数的维数外,提取的特征还可以整合到一个有监督的学习模型中,这表明自动编码器可以在特征提取中发挥作用。

图1 自动编码器的基本结构
AE对输入X进行编码以获得一个新的函数Y,并希望新的函数Y可以重建初始的输入X。 编码过程如下:

其中,W表示权重,b表示参数。
解码过程为:

其中,X′表示输出,W′表示权重,b′表示参数。
希望X′被重新构建后能尽可能与原来一致,还可以使用损失函数L来训练模型:

通常会对自动编码器的使用增加一些限制,最常见的方法是使W′=WT,即所谓的“绑定权重”,这一限制同样适用于本研究中的自动编码器。
1.2 梯度提升决策树
梯度提升决策树 (Gradient Boost Decision Tree,GBDT)是一种循环重复的决策树算法,由许多决策树构成,所有树的结论聚合而成得到最终答案。 GBDT经过几个循环,会得到若干个弱分类器,由若干个弱分类器构成最终的分类器。
GBDT分类算法主要应用了以下公式:
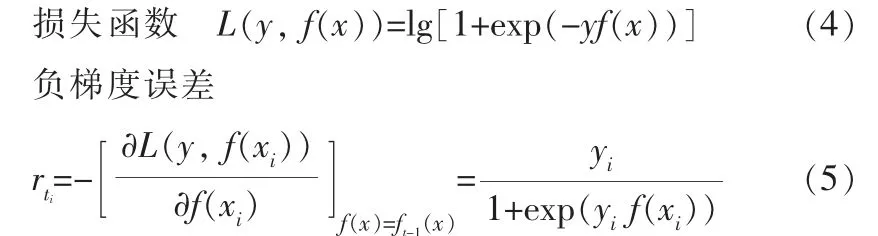
其中,f(x)为预测结果;y为实际结果,y∈{-1,1};ft-1(x)表示前t-1个基学习器的输出结果,yi为第i个实际结果;xi为第i个输入。
对于最终的决策树,每个叶子节点的最佳负梯度Ctj的计算式为:
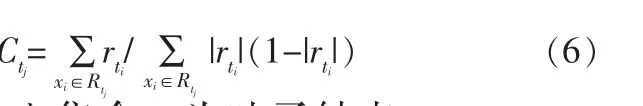
其中,Rtj为输入集合;tj为叶子结点。
1.3 极限梯度提升决策树
极限梯度提升决策树(eXtreme Gradient Boosting,XGBoost)是一种Boosting算法,它将许多弱分类器整合在一起,形成一个强大的分类器。
XGBoost是一个加法模型,它包含了k个基学习器,循环重复第t次迭代的树模型是ft(x),则第t次重复训练后样本i的预测结果y^i(t)的计算式为:
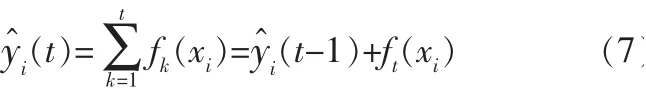
其中,y^i(t-1)表示前t-1棵树的预测结果;ft(xi)表示第t棵树的模型。
XGBoost的损失函数可由预测值y^i和真实值yi表示:其中,n为样本数量。

2 深度提升网络模型
2.1 集成学习
集成方法是一种元算法,把不同的机器学习算法组合到一个预测模型中, 能减小系统方差、系统误差或提高系统预测精度,其特点如下:
a. 将多种相同或不同的分类方法相结合,以提高分类精度;
b. 集成学习方法是从训练数据中构建一组基分类器,然后将预测数据应用到每个基分类器进行分类;
c. 集成学习不是一种分类,而是一种将分类器结合的方法。
2.2 深度提升网络
深度提升网络(Deep Boosting Network,DBN)拥有基于梯度增量策略中仍然存在的关键决策的深度耦合结构[8~10]。 以XGBoost和GBDT为基学习器创建深度提升网络, 在第1层输入中对特征向量进行整合和改进,从第2层开始,每层接收来自前一层处理后的数据,允许进一步改进,并将结果传递到下一层,以此类推,流程如图2所示。为了减少过度拟合风险,每次创建一个新的隐含层, 都计算出当前类输出的预测精度C和每个基学习器输出的准确预测矩阵的收敛性η。 将η与自适应因子α(α是学习结果变化的参数)做比较,如果有η<α或者当前平均准确率低于前一级别的平均准确率,则训练结束。
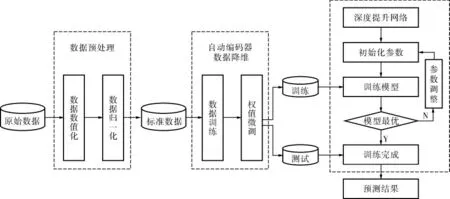
图2 深度提升网络流程
设N为样本数量,H是基学习器在隐含层的数量, 第i层的第r个基学习器的输出和预测精度分别为Air和Ci,则收敛性η和当前层预测精度Ci的计算式为:

2.3 相对多数投票策略
由于本研究将GBDT和XGBoost基学习器整合应用到集成学习中,这些基学习器都会有自己的结果,那么输出层的结果就必须通过对这些结果进行投票得出。 本研究选择的是相对多数投票策略,该策略的思想是少数服从多数,只要基学习器中有某一个结果所占比例与其他结果相比是多的,那么就选择该结果。
2.4 算法流程
2.4.1 自动编码器降维算法
为了满足深度提升网络中一个输入向量维数的要求,AE网络的隐含层神经元数m=n×n。 为了最大限度地保留数据中的信息,m可以被赋值为64、81、100及121等。 当m=64时,自动编码器的结构模型如图3所示。

图3 自动编码器的结构模型
为评价AE网络的降维效果,引入重构误差的概念。 重构误差是特征重构的输出值和输入值降维后得到的误差。 在AE网络降维中,需确定降维后的数据能否很好地恢复到原始输入数据,重构误差用均方误差MSE表示:
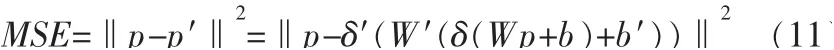
其中,p表示输入变量,p′表示输出变量。
为了优化自动编码器网络的结构, 通过调整GBDT和XGBoost模型个数、优化函数等参数,观察自动编码器网络在迭代过程中重构误差的变化,最后确定自动编码器网络的最优结构。 在不同维度下, 利用自动编码器结构重构误差的结果如图4所示。

图4 利用自动编码器结构重构误差
自动编码器的结构确定后,通过输入预处理后的数据,计算出网络的重构误差。 通过BP算法调整网络参数,最终通过隐含层获得降维数据。
精准医疗是针对于患者医疗保健和健康的个性化医学模式,它通过医生的医疗决策和实践制定出适合不同疾病人群的治疗方案。随着对CRSwNP的发病机制的不断深入了解,精准医疗分析整合疾病的诊断和治疗并能制定出最优化的治疗方案[28]。而实现精准医疗的基础必须具备的要素有:患者参与治疗方案的决定;预判初始治疗的成功率;防治疾病进展的有效策略和疾病内在型为驱动的个性化治疗[29]。为了实现疾病内在型为驱动的治疗目的,必须对疾病的内在型有着充分且标准化的认识,而且能够洞察用于评估或预测疗效、指导完善临床策略的生物标记物[10]。
2.4.2 深度提升网络算法
深度提升网络的结构如图5所示。
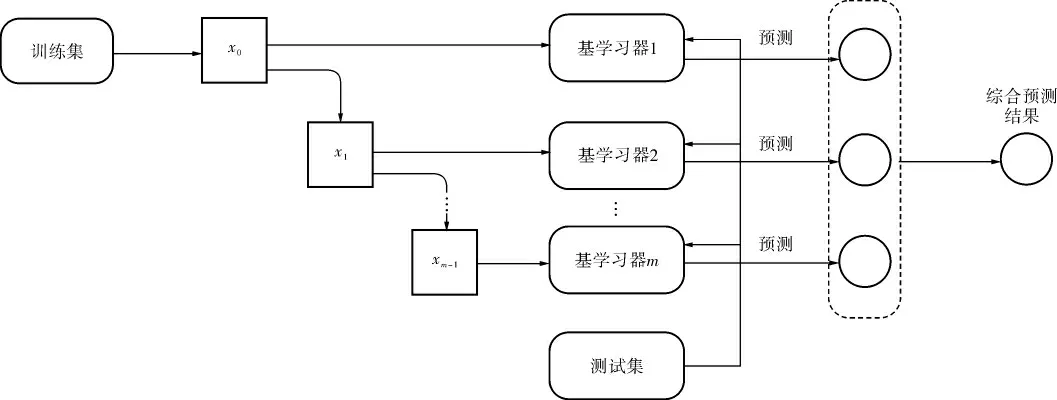
图5 深度提升网络结构框图
深度提升网络的算法步骤如下:
a. x0、x1、 …、xm分别代表GBDT和XGBoost模型,对其输入训练集形成m个基学习器(前一个的输出是下一个的输入);
b. 输入测试集,m个基学习器分别得出m个预测结果;
c. 对步骤b中的m个预测结果使用投票策略,得出综合预测结果。
深度提升网络在第1层输入中对特征向量进行整合和改进;从第2层开始,每层接收来自前一层处理后的数据,允许进一步进行改进,并将结果传递到下一层,以此类推。


3 实验分析
3.1 实验环境
实验所用的主机处理器为Intel(R)Core(TM)i5-7200U CPU@2.50 GHz,内存16 GB,操作系统Win10专业版,在Pycharm环境下使用pytorch框架完成仿真实验。
3.2 评价指标
分类问题常用的评价指标是精确率和召回率。 正常类被标记为正类,所有攻击类被标记为负类。 分类器对数据集的预测是正确的还是错误的,结果存在4种情况:
a. TP(True Positive),把正类预测为正类;
b. FP(False Positive),把负类预测为正类;
c. TN(True Negative),把负类预测为负类;
d. FN(False Negative),把正类预测为负类。
评价指标的计算式如下:

F1分数为精确率和召回率的调和平均,即有:

3.3 实验数据
CICIDS2017是一种入侵检测数据集,由加拿大网络安全研究所收集,包含良性攻击网络流和7 种公开可用的常见攻击类型。 它包括使用CICFlowMeter的网络流量分析结果, 使用基于时间戳、源和目的IP地址、源和目的端口、协议和攻击(CSV文件)的标记流。因此,CICIDS2017数据集更具代表性[6]。
CICIDS2017数据集中共有15种类别的数据,其中包含1种正常类别和14种攻击,详见表1。
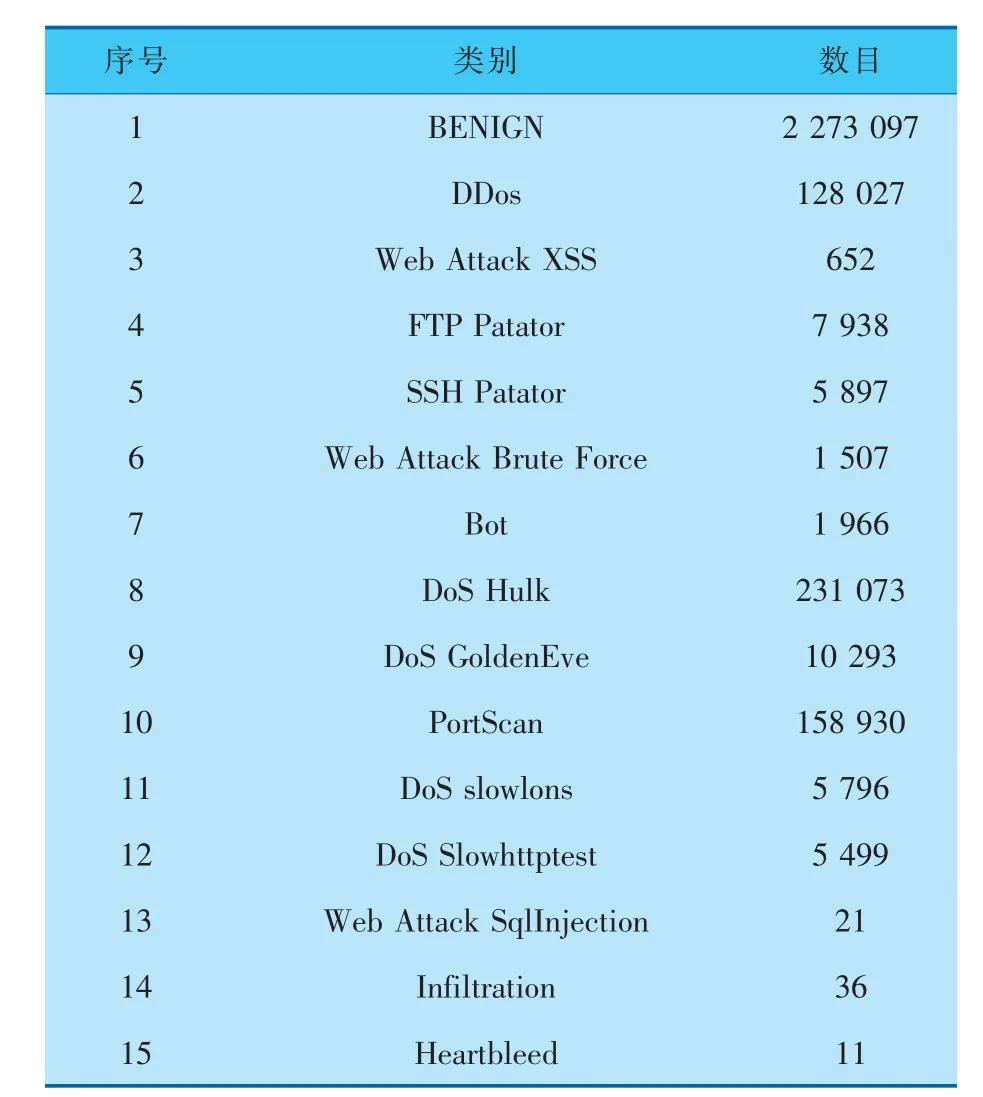
表1 数据集类别和数目
3.4 结果分析
为了提高模型的准确性,加快模型的收敛速度,对所创建的数据集进行数据预处理,具体步骤如下:
a. 检测数据集中的空值。因为本研究中的一些算法对缺失的值很敏感,所以将数据集中元素列的平均值替换为空值。
b. 将处理后的数据集分为两部分, 分别为80%的训练集和20%的测试集, 其中正常流量和攻击流量在数据集和测试集中的占比见表2、3。

表2 训练集占比情况
c. 对多分类标签进行one-hot编码。
d. 为了消除不同特征尺度对模型精度的影响,对数据集的特征进行正则化处理。

表3 测试集占比情况
本研究的模型在分类过程中设置GBDT和XGBoost的总数目后的损失值如图6所示。
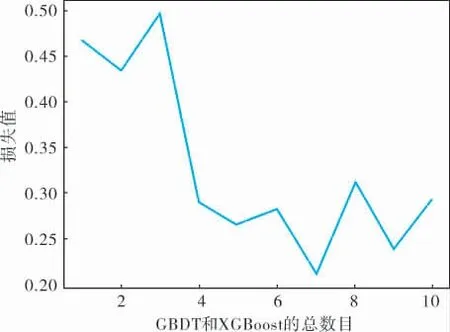
图6 GBDT和XGBoost的总数目对损失值的影响
为了证明GBDT-XGBoost模型在相同实验环境下与其他模型相比的优越性, 选择KNN、DT、RF、GBDT和确定结果较好的XGBoost进行比较,检测结果见表4、5。
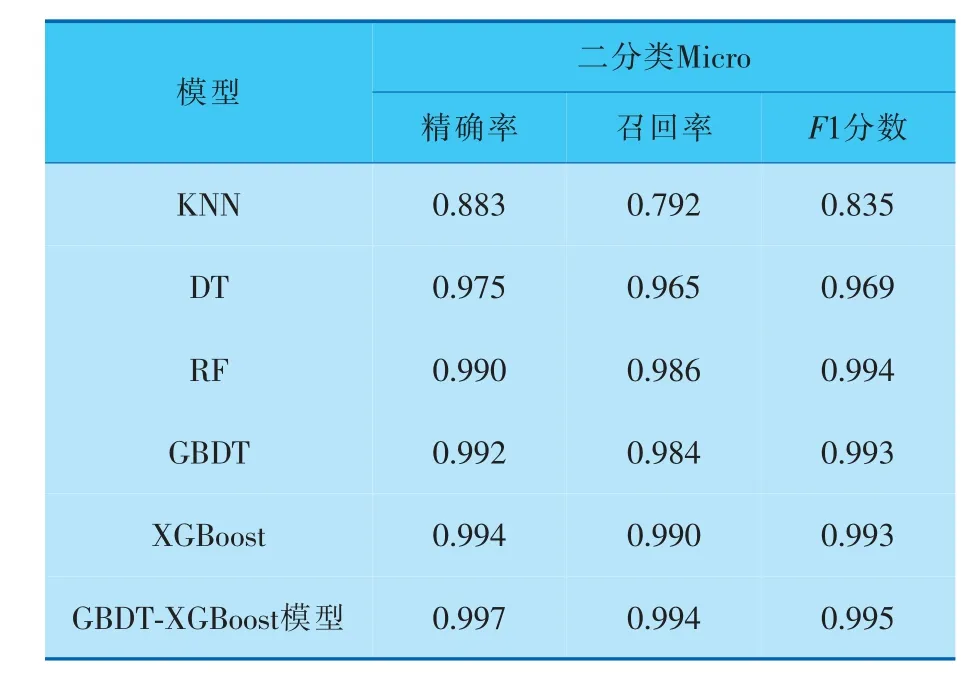
表4 二分类任务下模型的对比结果

表5 多分类任务下模型的对比结果
从表4、5可以看出,KNN在二分类和多分类任务下的分类效果较弱,DT其次,RF、单独GBDT和单独XGBoost在精确率和F1分数的结果上不相上下, 但在召回率上有出入。 笔者提出的GBDTXGBoost模型在所有3个指标上,无论是二分类还是多分类,都高于其他模型,证实该模型分类的整体效果优于其他算法。
4 结束语
笔者提出基于GBDT-XGBoost的网络入侵检测算法, 获得了入侵检测的强分类器。 与传统KNN、DT、RF、GBDT、XGBoost算法对比的结果可知,GBDT-XGBoost算法在精确率、 召回率和F1分数上都有所提升。 但该方法对于未知攻击的检测还存在精确率不高的问题, 下一步计划改进该方法,提高该方法在未知攻击检测方面的精确率。
