基于集成学习的物资采购价格辅助决策方法
2022-12-10程晓晓蒲兵舰张国平丁萌萌
程晓晓, 蒲兵舰, 张国平, 丁萌萌
(国网河南省电力公司 a. 物资部; b. 物资公司, 郑州 450000)
0 引 言
电网公司需要大量采购各类物资, 物资的采购价格是采购过程中的关键因素, 但物资价格受到经济周期、 政府政策、 社会因素等多种因素的影响[1-2]。因此如何制定合理的采购价格, 提高预算的编制水平, 为电网规划和物资投资计划提供更为合理的指导价格, 避免不必要的损失, 是电网公司关注的焦点。
国内外学者针对物资的采购价格预测问题, 目前采用的方法多是通过对历史数据进行预测, 利用自回归积分滑动、 贝叶斯预测模型、 AdaBoost模型、 灰色预测模型、 XGBoost模型、 随机森林模型或基于神经网络等方法进行处理。张昊等[3]利用随机森林和XGBoost模型判断各特征数据对模型的贡献程度, 即选取关键特征。叶倩怡[4]以零售业销售数据作为数据挖掘对象, 对比了XGBoost、 随机森林、 GLMNET(Lasso and Elastic-Net Regularized Generalized Linear Models)、 LM(Linear Model)、 TSLM(Time Series Linear Model)模型在销售额预测上的效果, 得到XGBoost模型相较于其他模型预测效果更好。陈宇韶等[5]利用XGBoost模型结合特征工程处理, 通过选出与价格相关性最高的4个属性, 实现预测股价的走势, 但对关键属性的选取客观性不足。邸浩等[6]利用总经验分解方法、 长短期记忆模型和Adaboost算法结合构建多尺度组合预测模型, 用于预测商品价格, 得到Adaboost算法对复杂任务具有较好的分类效果。柴利达等[7]挖掘相关数据集, 分别从时序分析、 简单回归分析模型和复杂预测模型3个角度建模分析。研究分析得出XGBoost模型的预测效果最佳, 但该模型需实时更新数据信息以保证模型的预测精度。Salmensuu[8]利用贝叶斯模型预测马铃薯价格, 但马铃薯这类商品的价格会受到库存数量、 收成情况及自然气候的影响, 因此在预测时需注意价格的周期性。Babak[9]利用贝叶斯网络首先筛选出与价格结果相关性较大的因素, 但由于石油价格是非线性, 所以通过马尔科夫蒙特卡洛、 随机森林、 神经网络等方法混合构建预测原油价格模型。靳占新等[10]通过构建线性回归和随机时间序列两种预测模型预测物资价格。研究分析得出线性回归预测模型的预测精度相比随机时间序列模型精度更高, 而随机时间序列模型适用于较短时间内的价格预测。杨颜杰[11]采用贝叶斯线性回归预测方法对物资采购价格进行预测, 将贝叶斯思想与线性回归的思想相融合, 该方法的引入防止数据的过度拟合并提高预测的精度。但贝叶斯线性回归预测算法的程序运行时间较长, 随着数据量的逐渐增多, 预测效率明显下降。
基于上述结论, 在实际应用过程中, 可适当将线性回归和随机时间序列两种模型结合使用, 其中随机时间序列模型主要用于预测价格的变动趋势。随着预测物资价格精度需求的提高, 应进一步深入探索电网的物资价格, 制定出合理的采购价格, 降低采购成本, 避免不必要的损失。
笔者将现有的历史物资价格进行整理和处理, 得到影响物资价格的关键特征。此次选用参考价值较大的电缆进行研究, 通过集成学习构建价格预测模型, 针对价格预测模型的选择主要分为3种, 分别是AdaBoost、 XGBoost、 随机森林模型, 最后利用预测评价指标平均绝对百分比误差(MAPE: Mean Absolute Percentage Error)评估预测效果, 选出价格预测效果最佳的模型。由于物资价格受到多种市场因素和政策的影响, 通过本研究得出的预测模型能把控当下电缆物资价格走势, 为电网公司提供合理的采购指导价格, 并可将其指导价格作为采购过程中的一个相对公平的价格参考, 成为公司设置招标底价的依据与采购的决策意见, 帮助电网公司有效的控制采购支出, 精准的价格预测成为物资成本管理的关键, 从而提升公司的收益。
1 物资价格预测模型设计
笔者通过皮尔逊系数和随机森林两种评估指标, 度量各特征与待预测价格间的相关程度, 过滤出相关性较高的特征。将电缆的原材料价格与通过特征选择保留的全部关键特征相结合, 构成待训练价格数据集。将待训练数据集拆分为训练集和测试集两部分, 训练数据集作为预测模型的输入, 分别利用Adaboost、 XGBoost、 随机森林模型进行训练, 预测电缆的不含税单价, 测试集作为检测预测结果正确性的标准。通过预测效果评价指标平均绝对百分比误差(MAPE)从3种预测模型中选出预测结果精确度最高的模型, 物资价格预测模型研究框架如图1所示。
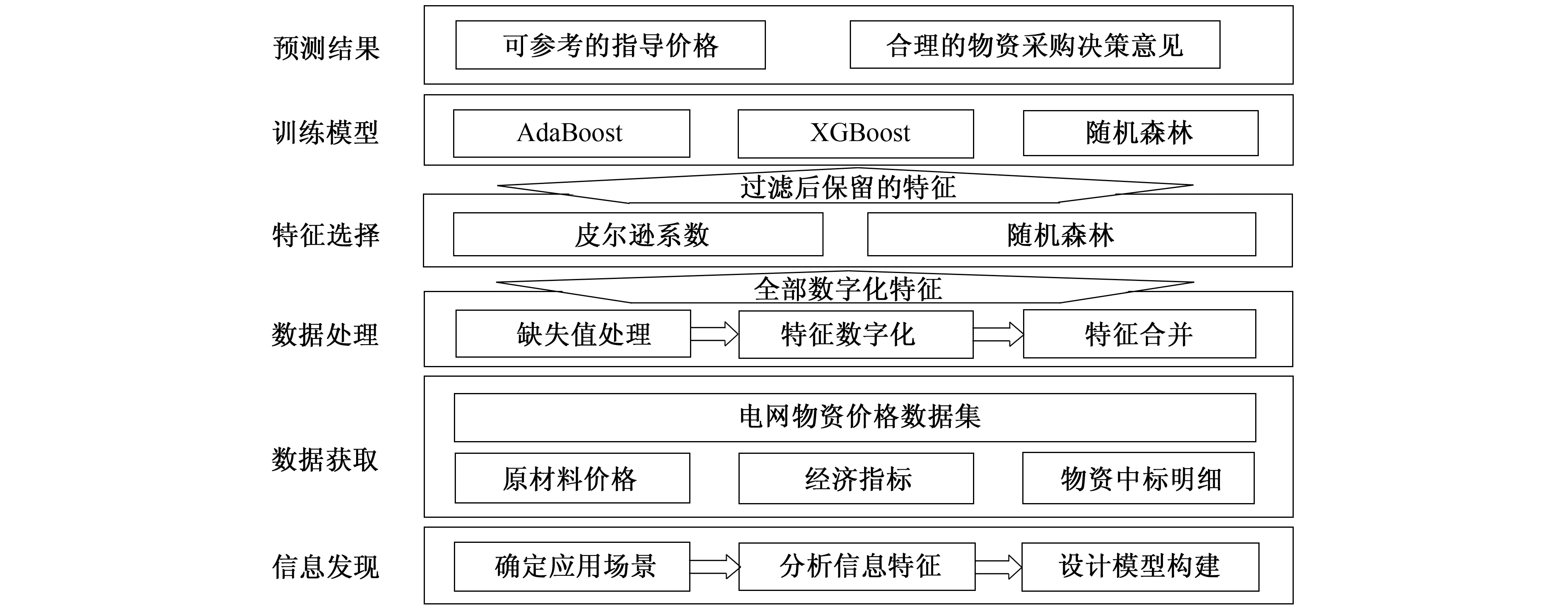
图1 物资价格预测模型研究框架Fig.1 Research framework of material price prediction model
1.1 数据标准化处理
对收集到的初始物资价格数据集, 可能存在着数据缺失、 数据格式错误、 需要执行预处理操作生成可用于训练模型的数据类型。
1.1.1 缺失值处理
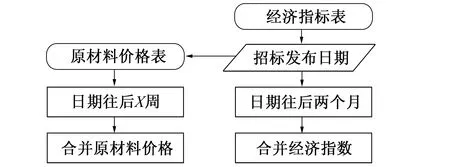
图2 表格合并原则Fig.2 Table consolidation principle
由于电缆所需原材料种类多样, 且采集的时间不尽相同, 为使数据特征不缺失, 笔者以时间戳为基准, 将特征因素依次向前填充。如原材料的周价格在获取过程中, 出现个别日期缺失对应的价格数据, 对这种缺失, 根据已知价格数据, 利用等差数列将缺失价格数据进行填充。最后将全部相关数据表进行合并, 生成新的物资表。根据客观规律可知原材料价格会受经济指标影响发生波动, 但这种影响不会立即体现在原材料价格上, 而是会存在时间延迟。在合并表格的过程中, 应以原材料价格所在的周为时间基准延迟两个月, 将经济指标相关数据合并, 形成新的数据表。表格合并原则如图2所示。
1.1.2 数据标准化
为确保模型的生成, 另一个重要的处理技术就是规范化数据。由于影响电缆价格的相关特征较多, 首先可通过观察删除无用数据。例如年份与日期特征的意义相同为重复列; 物料编码特征中含有大量空值为无效列; 表格的序号列为单位列, 不具有实际意义。针对保留的特征数据进行规范化处理, 对其进行特征数字化, 利用独热码表示特征中的特征值。
由于不同模型可处理的数据类型存在差异, 例如AdaBoost模型要求数据类型为数值型或标称型数据、 XGBoost模型要求数据类型为数值型, 则利用独热码可有效解决分类器不便于处理离散数据的问题。
1.1.3 时序延迟
电缆所需原材料种类多样, 当某一原材料价格发生变化时并不会立即导致电缆的不含税单价发生变化, 而是随着原材料库存的消耗、 供需关系的调整、 政府政策的发布、 市场价格的变动等因素共同影响, 经过一定的时间间隔最终作用于电缆的不含税单价, 导致该电缆价格发生调整。因此在表格合并过程中, 电缆的不含税单价和原材料价格不能根据时间戳直接进行合并, 需要先计算出电缆的不含税单价和原材料价格间的时间延迟。
通过动态时间规整方法对电缆的原材料价格与不含税单价两条时间序列进行规整计算。动态时间规整方法可解决时间序列非对齐问题, 通过一种拉伸拟合的策略, 获得最小化两条序列之间变形路径的距离。序列间距离计算公式如下

(1)
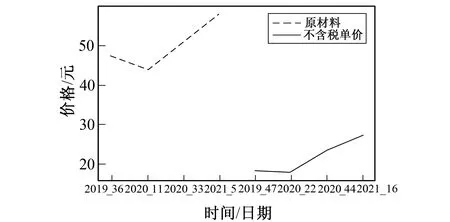
图3 动态时间规整结果图Fig.3 Dynamic time warping results
其中W为变形路径W={w1,w2,w3,…,wk,…,wp};wk为在此条路径上的第k个点;δ为定义两条时间序列距离的度量函数。通过式(1)获得规整路径长度最短的路径, 即可以该结果衡量两条时间序列的相似程度, 也就是电缆的原材料价格和不含税单价在走势上的相似度。选取相似度最高的一对原材料价格序列和不含税单价序列, 通过观察两条价格序列, 找到二者之间相似度最高的一对时间点, 这对时间点的间隔时间即为电缆的原材料价格和不含税单价之间的时间延迟。由实验得出, 原材料价格与延迟9周后的不含税单价相似度最高, 图3是动态时间规整结果图。因此在表格合并过程中, 可将市场价格数据与延迟9周后的不含税单价数据进行合并, 形成新的数据集。
1.2 特征选择
影响物资价格的因素很多, 如需求量、 季节、 储存、 生产量和GDP(Gross Domestic Product)等。避免训练得到的模型只关注某一类因素对物资价格预测产生影响, 或关注的因素过多, 防止训练过程中出现不必要的干扰, 本研究最终选择了对模型训练结果影响较大的特征[12]。
1.2.1 基于皮尔逊系数的特征选择
皮尔逊相关系数主要用于度量两个特征间的相关程度, 这个相关程度则由两特征间的协方差和标准差的商表示。若得出的皮尔逊相关系数的值越趋于0意味着两个特征之间的线性关系越小, 即两个特征之间相似程度越低。若相似系数越趋近于1意味着两个特征的相关性越高, 越相似[13]。皮尔逊系数表达式如下

(2)
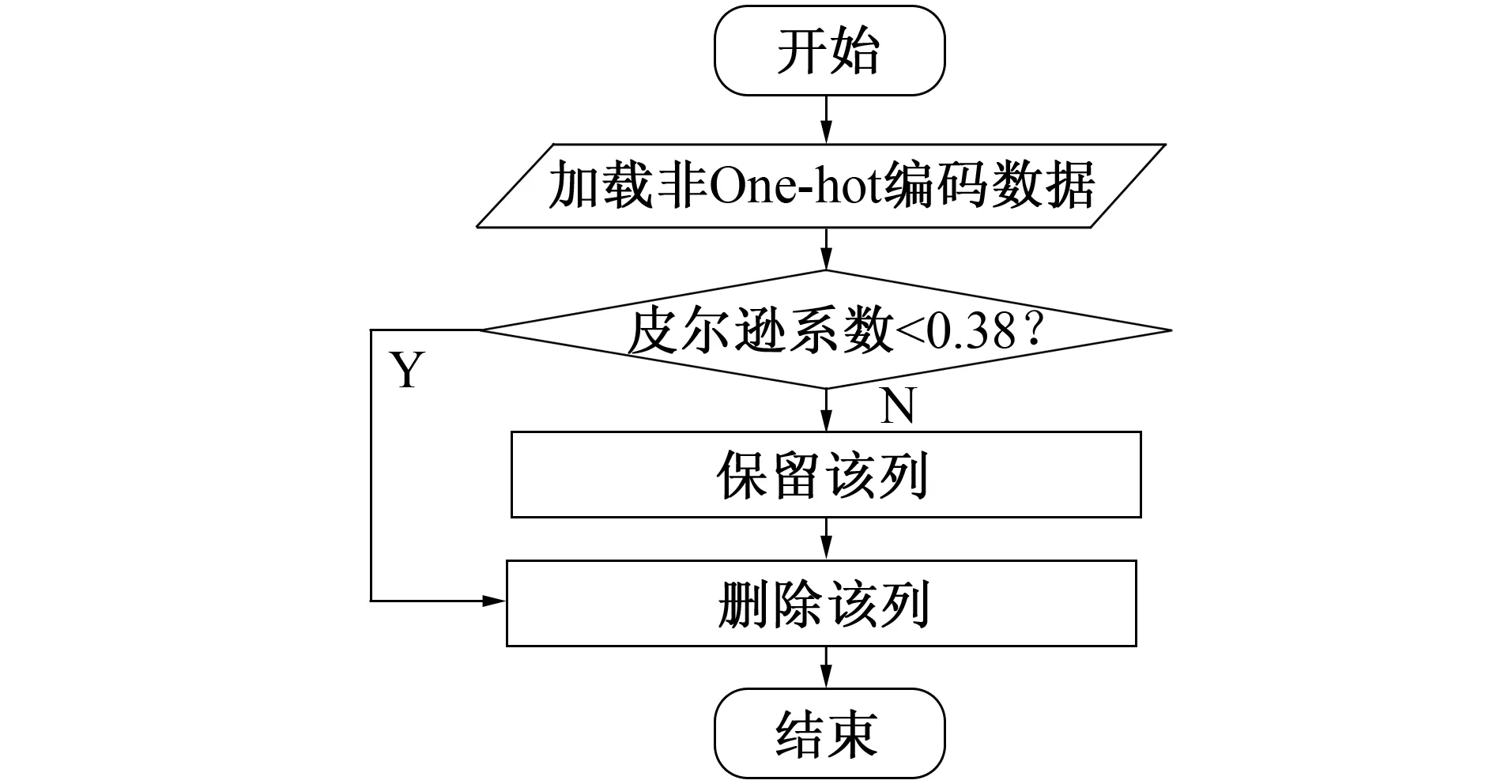
图4 皮尔逊系数过滤特征流程图Fig.4 Pearson coefficient filtering characteristics
其中cov为计算两个特征之间的协方差,σ为计算两个特征之间的标准差, 其中X、Y为两个待计算相似程度的特征。
本研究通过大量实验发现皮尔逊系数值为0.35左右时, 该特征对预测价格的影响符合实验要求, 因此根据经验依次设置过滤系数为0.35、0.37、0.38, 当特征与待预测价格间的皮尔逊系数小于过滤系数时该特征将被删除。然后对保留的特征再次重复上述操作, 两两进行皮尔逊线性相关性的评估。利用皮尔逊系数过滤特征的操作流程如图4所示。最终通过皮尔逊系数保留的特征如表1所示。

表1 利用皮尔逊系数保留的特征
1.2.2 基于随机森林的特征选择
第2种特征选择的方法是随机森林, 通过随机森林可从与不含税单价相关的全部特征中随机抽取部分特征, 利用抽取到的特征构建决策树, 进而由决策树形成决策森林。当决策树进行节点分裂时, 选取随机生成的特征子集中的最优特征进行分裂[12,14]。利用随机森林过滤特征的操作流程如图5所示。通过计算所有决策树的投票, 选出得票数较高的特征, 表2所示为选取的全部特征。

图5 随机森林过滤特征流程图Fig.5 Random forest filtering characteristics

表2 利用随机森林保留的特征
2 实 验
2.1 实验设置
笔者收集了8 006条电网物资中标明细数据作为实验数据集, 其中2018年电网物资中标明细662条, 2019年电网物资中标明细1 390条、 2020年电网物资中标明细802条、 2021年电网物资中标明细5 152条、 经济指标数据56条、 电缆原材料价格数据628条。电网物资招标明细包含如下属性: 中标批次年度、 批次名称、 未含税单价、 含税单价、 物资描述、 小类、 招标公告发布日期。
2.2 预测结果可视化
2.2.1 Adaboost
Adaboost模型主要用于解决分类问题, 在特征分类领域方面占据特别重要的地位。该模型的主要思想是对一个相同的训练集, 经过实验分析出不同的分类器, 然后把这些分类器聚集, 构成一个强分类器[15-16]。

以皮尔逊系数作为特征选择的方法时Adaboost模型的实验结果如图6a所示; 以随机森林作为特征选择的方法时Adaboost模型的实验结果如图6b所示。通过观察可看出, 利用随机森林作为特征选择的方法时, 预测结果的准确性高于以皮尔逊系数作为特征选择的方法。

图6 Adaboost模型的实验结果Fig.6 Experimental results of Adaboost model
2.2.2 XGBoost
XGBoost模型主要用于解决分类问题和回归问题。该模型借助树这种数据结构的思想, 在本研究中通过XGBoost将实际价格和训练集共同训练一棵树, 利用这棵树得到训练集的预测结果, 实际价格与预测价格之间存在差值, 相减算出一个“残差”[17]。然后训练第2棵树, 用残差作为标准答案。接着训练第3棵树, 以此类推, 完成全部树的训练后可得到每个价格的残差, 使预测价格逐渐趋近于实际价格。
笔者采用XGBoost模型进行预测, 首先设置弱评估器为gbtree, 学习率默认为1。然后根据输出数据样本进行迭代, 得到最终的模型。同样, 使用最终的模型进行预测, 计算与实际值之间的平均绝对百分比误差以评判模型训练效果。
以皮尔逊系数作为特征选择的方法时XGBoost模型的实验结果如图7a所示; 以随机森林作为特征选择的方法时XGBoost模型的实验结果如图7b所示。 通过观察可发现, XGBoost模型的预测值大部分均可与真值达到一致, 因此XGBoost模型相较于Adaboost模型的预测结果的准确性更好。

图7 XGBoost模型的实验结果Fig.7 Experimental results of XGBoost model
2.2.3 随机森林
随机森林算法主要用于解决分类、 回归以及集成学习等问题。在训练时间内构建多个决策树并输出作为类的标签或个体树预测的平均值[18]。随机森林可修正过拟合现象, 从而提高预测精度。
笔者采用随机森林模型进行预测,首先将模型初始化,设置决策树数量为100, 并采用有放回的采样策略。与XGBoost和Adaboost两种方法相同, 模型训练结束后使用测试集进行预测, 计算与实际值之间的平均绝对百分比误差。
以皮尔逊系数作为特征选择的方法时, 随机森林算法的实验结果如图8a所示; 以随机森林做特征选择和预测的实验结果如图8b所示。通过观察实验结果可看出, 利用随机森林进行特征选择的方法时预测结果准确性更高, 但利用随机森林模型与XGBoost模型进行预测后的结果准确性通过观察难以判断。
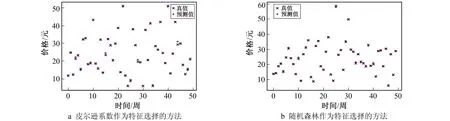
图8 随机森林模型的实验结果Fig.8 Experimental results of Random forest model
2.3 预测结果评价指标
本研究为评价模型的预测效果引入了预测评价指标平均绝对百分比误差, 利用平均绝对百分比误差衡量3种预测模型的预测准确性。当平均绝对百分比误差值越接近于0表示模型越接近于完美模型, 若平均绝对百分比误差值大于100%则表示该模型为劣质模型。平均绝对百分比误差值计算公式如下

(3)

2.4 基线对比
通过对训练数据集进行实验分析, 得到以皮尔逊系数作为特征选择的方法时模型的实验结果如表3所示。

表3 基于皮尔逊系数过滤得到的特征训练模型的实验结果
通过表3中的数据对比观察可知, 在使用皮尔逊系数作为特征选择的方法时, XGBoost模型的平均绝对百分比误差值最小, 因此XGBoost模型的预测效果最好。
以随机森林作为特征选择的方法时, 实验结果如表4所示。
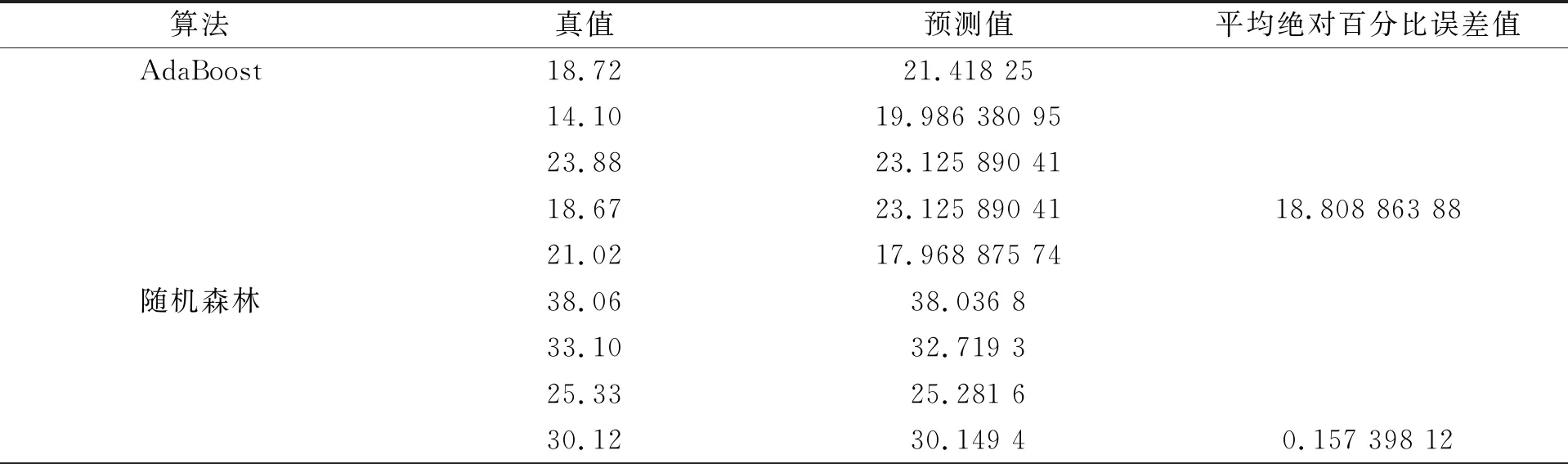
表4 基于随机森林方法过滤得到的特征训练模型的试验结果

(续表4)
通过表4中的数据对比观察可知, 在使用随机森林作为特征选择的方法时, XGBoost模型的平均绝对百分比误差值最小, 因此XGBoost模型的预测效果最好。
3 结 语
电网物资价格的高低决定了电网物资的成本, 制定出合理的预测价格可降低成本, 减少不必要的损失, 所以对物资价格的预测在电网企业中起到非常重要的作用。笔者选用参考价值较大的电缆价格作为预测对象, 首先利用随机森林和皮尔逊系数分别从历史物资价格数据中得到影响物资价格的关键特征, 根据关键特征和数据分别建立AdaBoost、 XGBoost、 随机森林3种模型对物资价格进行预测, 得到预测效果图。利用预测评价指标平均绝对百分比误差评估预测结果, 得出XGBoost模型的预测精度最好, 可获得较为理想的结果。但当采购过程进行到后期阶段, XGBoost模型要保持动态地更新信息, 采集到最新的采购信息以保证模型的预测精度, 同时希望通过笔者的对比实验分析得出的结论, 可对今后的电网企业的物资价格预测起到一定参考作用。
