轴承云边协同监测系统
2022-12-10陈文强刘阳丁晓喜邵毅敏黄文彬
陈文强,刘阳,丁晓喜,邵毅敏,黄文彬
(重庆大学 机械传动国家重点实验室,重庆 400044)
近年来,国内机械设备制造水平迅猛发展,滚动轴承作为旋转机械设备的重要零部件,其健康状况对设备的正常运行和工作效率有重大影响,因此对轴承状态进行实时监测和故障识别,保证轴承在故障尚未发展的阶段及时得到处理,对保障设备安全正常运行具有重要意义[1-4]。
随着物联网技术、云计算等的发展[5],无线网络技术实现了近程数据交互和远程数据监测,并且能够灵活地布点和监测[6],使其在机械设备监测系统上具有独特的优势:文献[7]通过运用无线传感器网络技术实现了对电动机故障的远程监测,搭建完整的监测网络和硬件系统实现了对电动机状态的在线监测;文献[8]提出了用于电动机监测和故障诊断的一种新型工业无线传感器网络系统,将数据提取和分析的功能集中于传感器节点中,有效减小了传输数据的载荷和能耗;文献[9]提出了针对旋转机械设备的一种新型工业监测系统,在中央处理单元中提前进行模型训练和参数提取,通过空中编程的方式将参数分配给各个节点,可动态地调整诊断参数和诊断能力,提高了整体算法系统的适应能力;文献[10]设计了一个针对机泵的振动信号监测系统,结合Zigbee网络和WIFI网络构建了多层次网络。
目前并没有一套完善的针对轴承故障诊断的无线网络监测系统,为实现轴承运行状态的无线监测,本文结合现有无线网络监测系统的研究,针对轴承状态监测需求设计了一套完整的轴承云边协同监测方案,提出了一种多层次故障诊断算法,利用云平台强大的资源服务能力和边缘设备数据传输低延时特性,构建了一个智能化的监测系统。
1 多层次故障诊断算法
1.1 多层次故障诊断算法整体框架
神经网络在机械故障诊断中通常利用特征数据进行故障识别和分类,具有较高的识别精度,能够满足机械设备诊断的需求[11]。本文采用以改进BP算法为核心的故障诊断策略,如图1所示。传感器对振动数据进行采集之后,将数据分为训练集和测试集,训练集作为先验数据用于模型训练,测试数据用于验证模型的正确性和故障诊断。终端首先提取特征数据集,然后利用特征选择算法选取辨别能力最高的多维特征并作为基础网络的训练样本。故障决策是综合多个模型的预测结果给出最终判断。
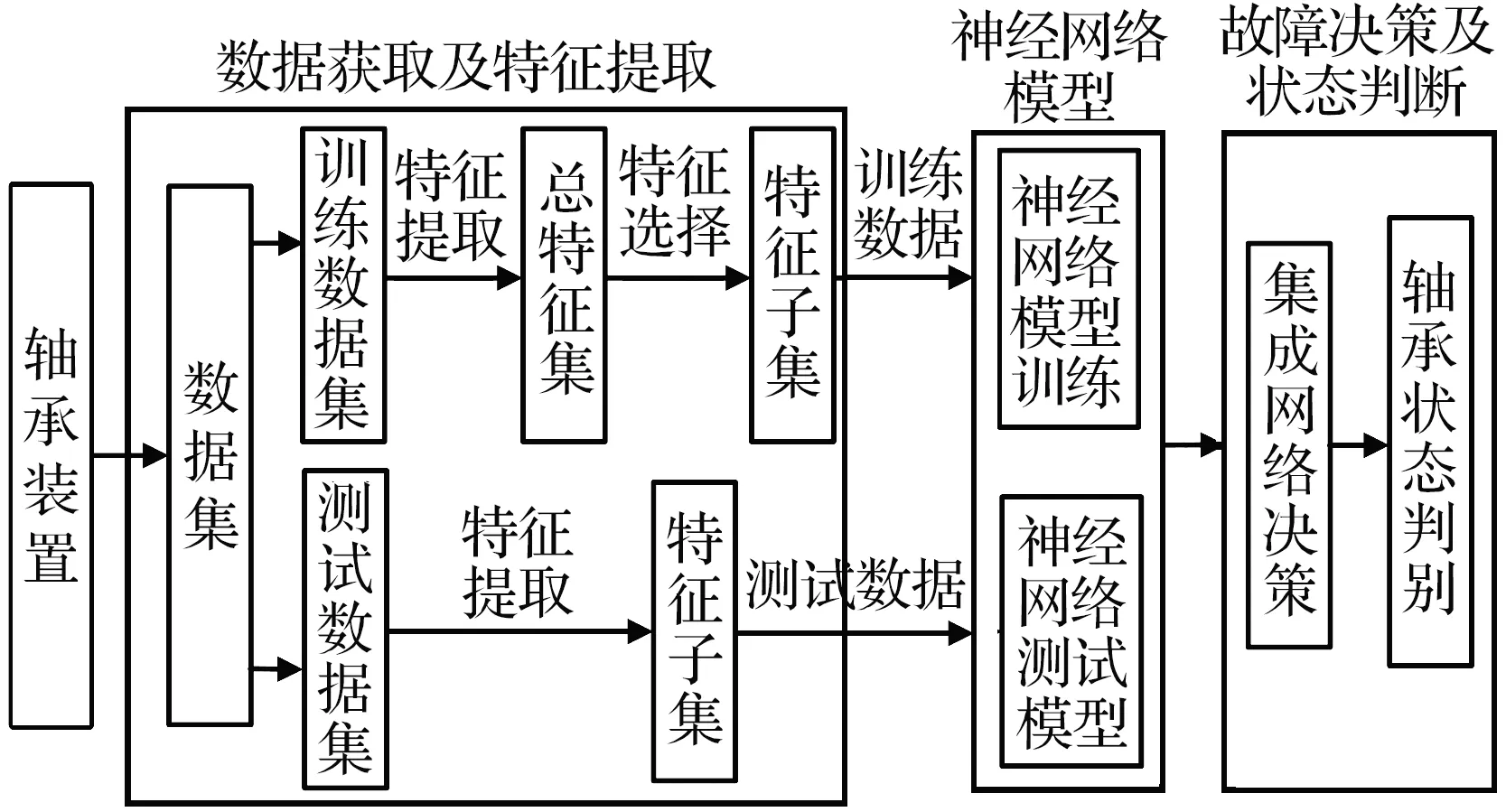
图1 轴承故障诊断网络框架
1.2 多维边缘网络特征提取算法
边缘网络结构流量承受能力有限,而振动信号数据量通常较大,故采用特征提取算法提取信号数据在时域和频域内的特征值,经数据降维后再进行网络传输和后续处理。
1.2.1 边缘特征提取
几种典型的时域特征参数见表1,其中xi为振动信号的时域序列,i=1,2,…,N,N为样本点数,Xmax,Xrms分别为序列的最大值和均方根。

表1 典型的时域特征参数
几种典型频域特征见表2,其中s(k)和fk为频谱序列和频率。频域特征序号1反映了频域振动能量的大小;2~4,6,10~13反映了频谱的分散或集中程度;5,7~9反映主频带位置的变化。

表2 典型的频域特征参数
1.2.2 基于距离的过滤式特征选择算法
特征提取后,大量数据获得了降维,但各类特征对于故障的反映程度不同,且特征之间存在耦合,因此对特征数据进行再次降维和去重复处理,以减小后续神经网络的计算压力。由于轴承故障诊断的问题为连续特征的多分类问题,故在满足准确性的基础上设计改进的Relief-F算法[12]作为特征选择算法,其是基于距离计算的一种过滤算法,在多维特征中的猜错近邻和猜中近邻如图2所示,通过计算每个特征的相对统计量并排序以实现特征选择。
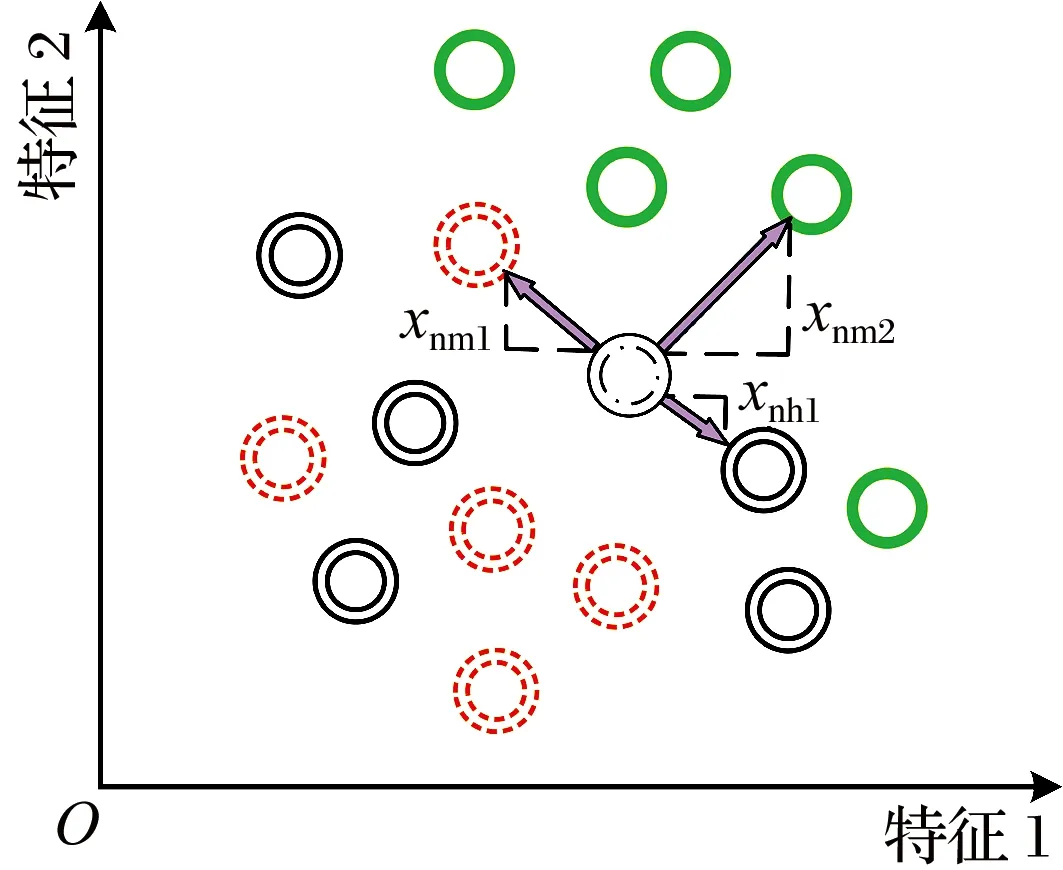
图2 多维特征中的猜错近邻和猜中近邻
获取每个特征维度的相关统计量后,通过多次采样计算提高算法的可靠性,根据统计量获得第j个特征对于数据的区分能力,即
(1)
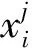
W(j)的值越大说明第j个特征值的分类效果越好,通过比较每一维特征的统计量来评估特征的分类能力,最后将筛选出的包含z个特征的集合作为神经网络分类的输入特征。Releif-F特征选择算法的执行流程如图3所示。
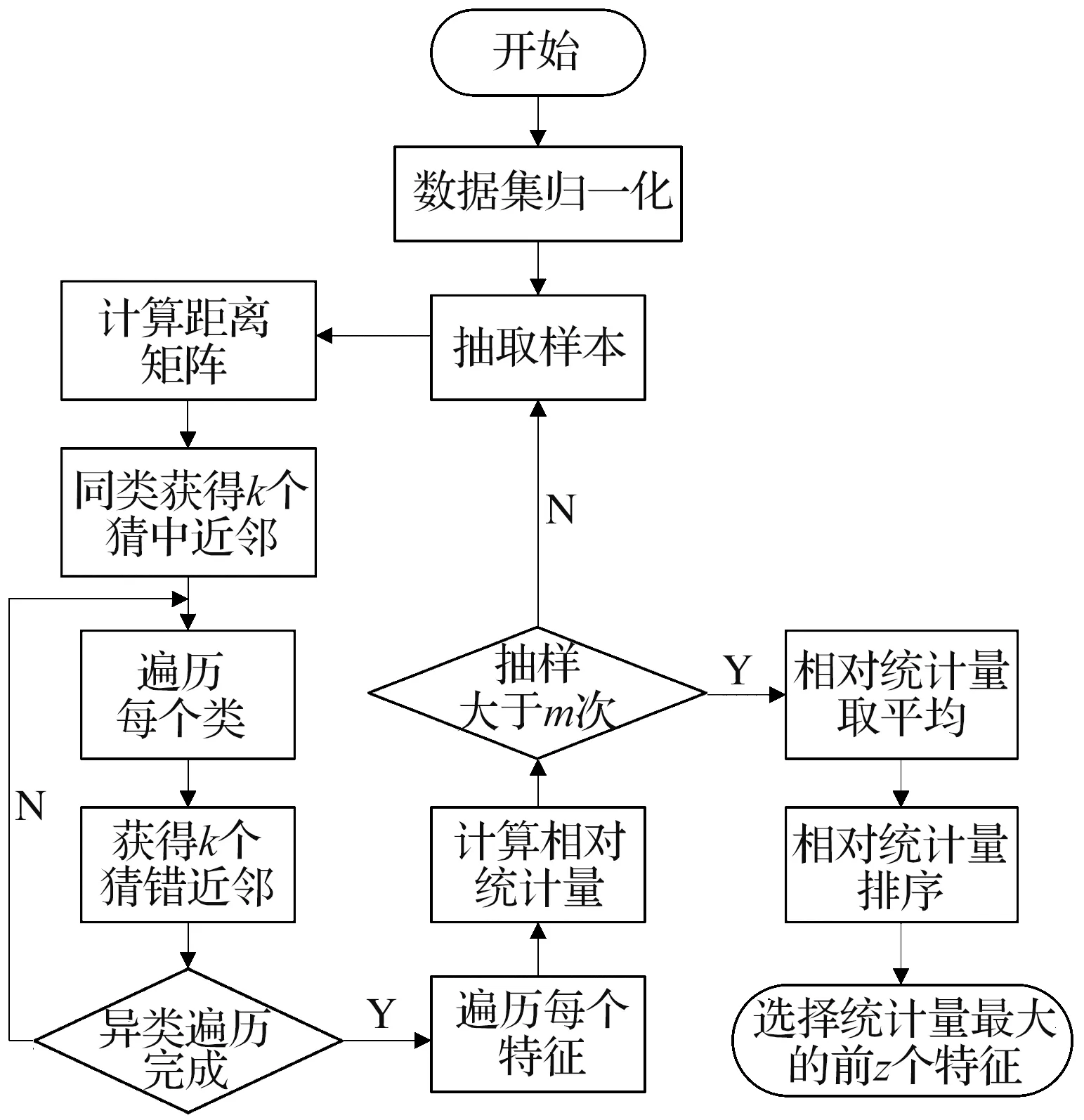
图3 Releif-F特征选择算法具体流程
1.3 交叉验证的神经网络模型
由于本系统主要针对轴承故障状态及程度进行判断,故在保证性能可靠的情况下,选择了单隐层BP神经网络[13]作为基本的故障分类模型,以减小底层处理器的计算量,提高整体系统的实时性和处理效率。
1.3.1 单模型多层神经网络结构
神经网络的输入为经过特征选择算法提取的特征值,输出为分类结果。根据监测需求和数据来源将轴承状态类型分为4种,即健康、轻度故障、中度故障和重度故障。通过训练和反馈不断改进和修正模型,在测试数据集中验证正确率后作为最终的诊断模型。BP神经网络模型如图4所示。
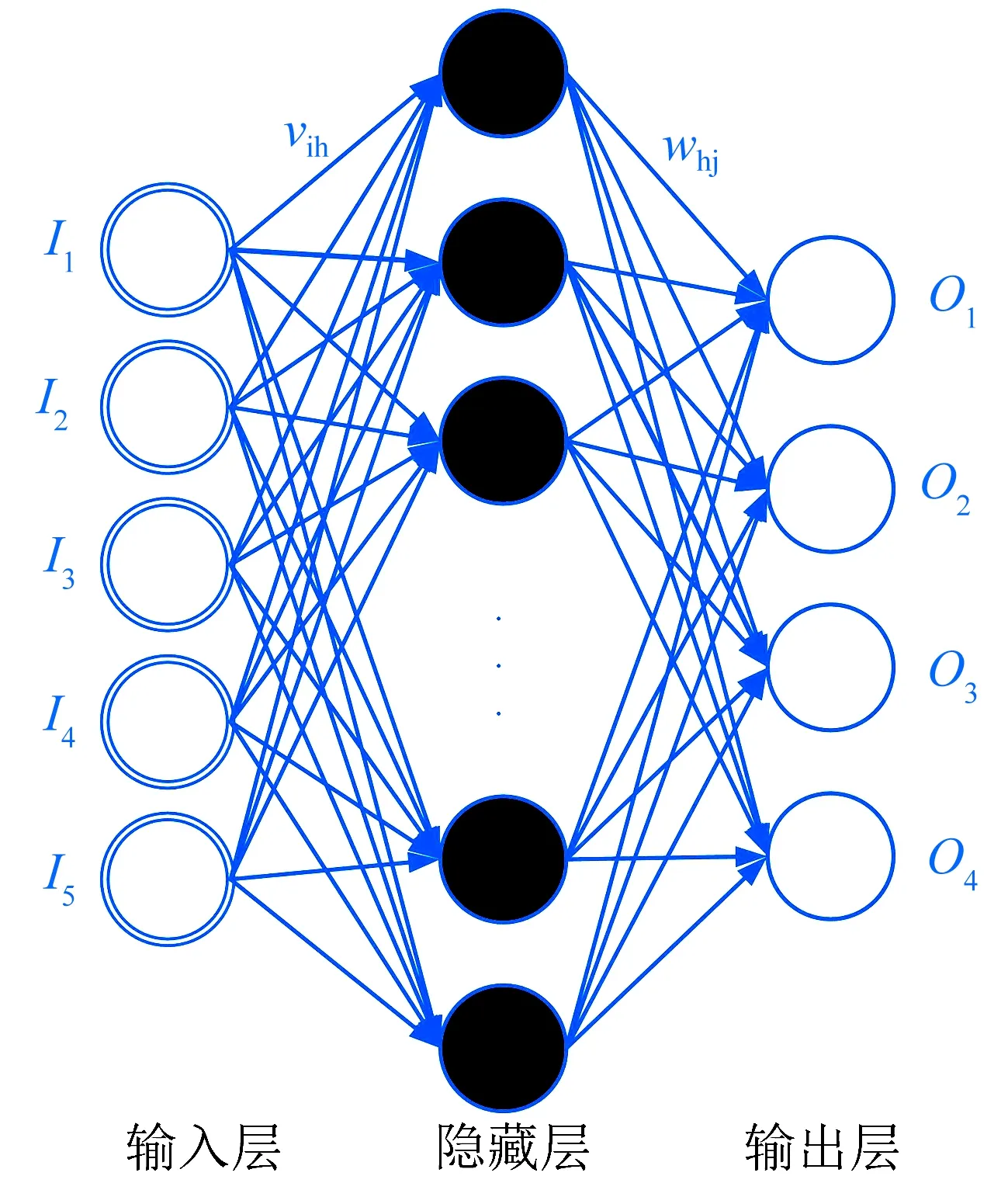
图4 BP神经网络模型
多层网络模型分为3层,分别是输入层、隐藏层和输出层。输入层输入样本的d维特征(本文d=5),输出层输出一个4维向量,其中一个值为1,其他为0,代表对故障的判断,即神经网络对输入数据的分类结果,隐藏层神经元个数为满足泛化能力通常取
(2)
式中:a为输入层神经元个数;b为输出层神经元个数;e为调制参数,本文e=8。
1.3.2 交叉验证集成训练网络
单个神经网络的训练模型准确性会随训练集的不同、训练方法的差异和一些超参数变化而受到影响,为强化模型的泛化能力,采用多模型集成的方法联合多个学习器强化整体的测试性能,减小单个学习器的测试误差。本系统采用改进的交叉验证的策略[14]对模型进行集成,如图5所示。
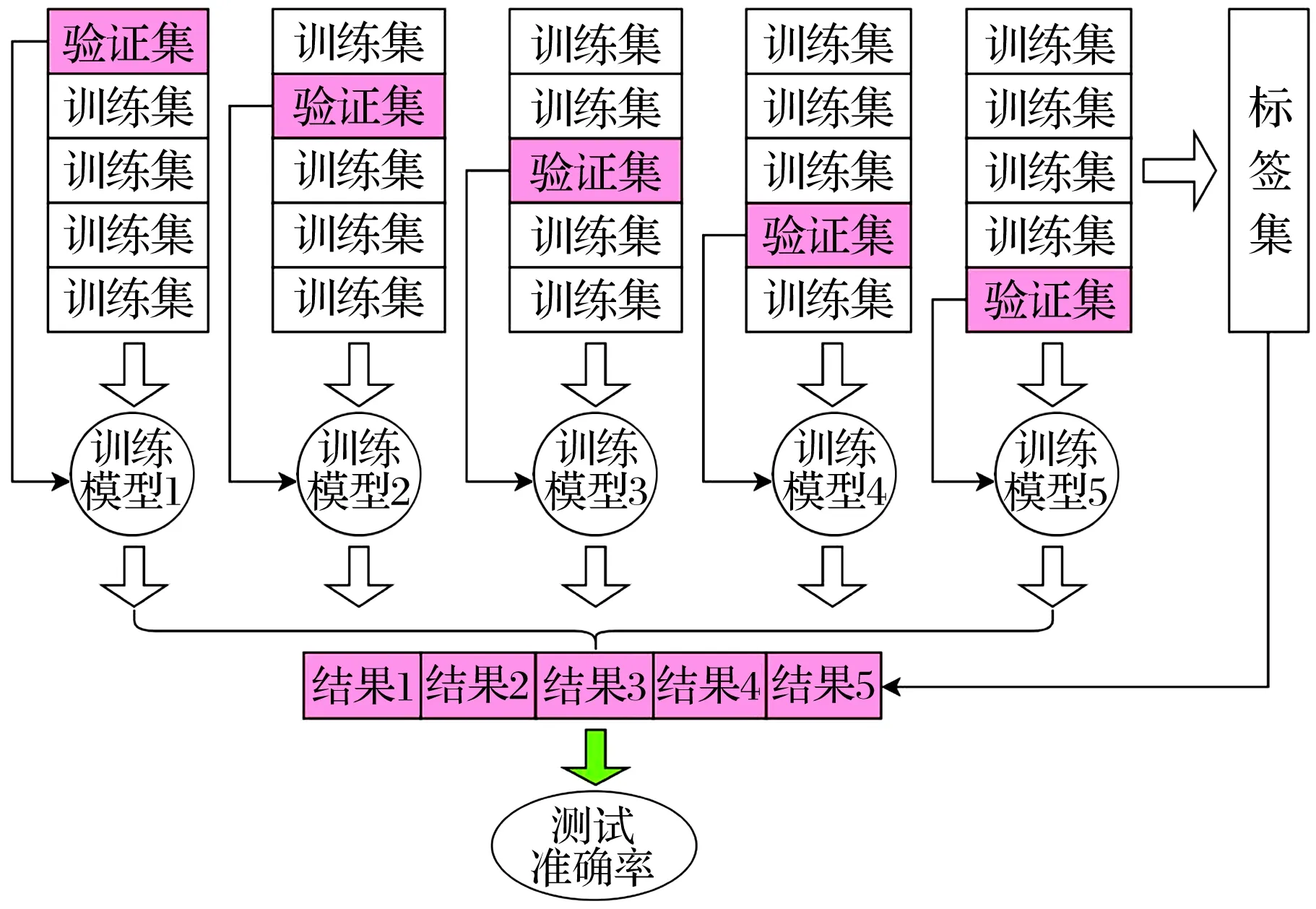
图5 交叉验证模型
1)对带有标签的x个样本平均分为y份(本文y=5),其中一份作为验证集,其余为训练集,对训练集的数据进行训练后获得训练模型。
2)y份样本集轮流作为验证集,其余为训练集,共进行y次训练,获得y个训练模型及其训练结果。
3)按照样本分割顺序将y个结果通过投票法进行集成,以获得某个样本的最终分类结果。
4)从样本数据中提取出标签集,与前一步获取的分类结果进行对比,统计与标签一致的数量与总数量的比值,获得融合模型的测试准确率。
2 云边协同监测系统
2.1 云边协同架构
本系统的上位机以云服务器为核心,并为监测系统提供一个数据可视化显示、存储管理中心和控制的平台,同时结合边缘设备对振动信号的采集、特征计算和故障诊断共同构成云边协同的整体架构,如图6所示。云端通过远程控制系统对中继设备进行程序更新和系统升级,中继设备和终端设备通过指定的无线网络协议进行指令交互,对终端设备的采集和处理方案进行逻辑控制,从而达到整体远程控制的目的。
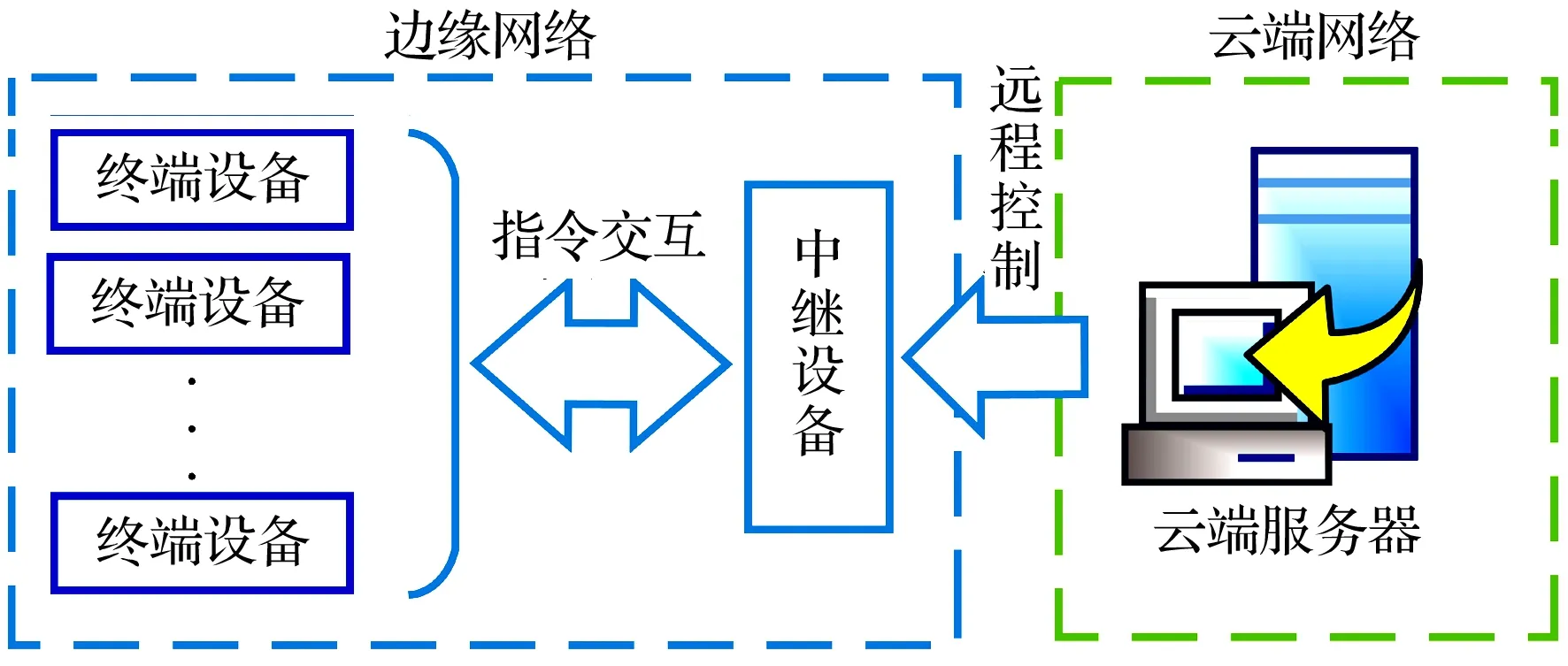
图6 云边协同架构
2.2 分布式算法结构
在实现网络架构和采集系统搭建的同时,采用分布式算法结构,通过网络数据传输和逻辑控制系统的配合实现多层故障诊断,如图7所示,分布式算法结构减轻了单个设备计算的负担,提高了计算效率和监测报警系统的实时性。

图7 云边协同监测系统分布式算法结构
在云端中对算法做前期参数准备工作,包含特征筛选和神经网络模型的参数训练;终端设备根据筛选出的特征序号激活相应的特征提取算法,对数据进行降维处理并将特征值上传给中继设备;中继设备内嵌了2个算法,先根据云端的神经网络参数建立神经网络测试模型进行信号分类,之后通过故障决策算法对结果进行判断,完成监测故障和报警的功能。
2.3 边缘层
2.3.1 终端
终端硬件架构如图8所示,包含振动传感器、ARM内核芯片、Flash内存、SD卡、CC2530等硬件模块,完成轴承振动信号的采集、存储和降维处理,最终通过Zigbee无线传输通道传输特征值。
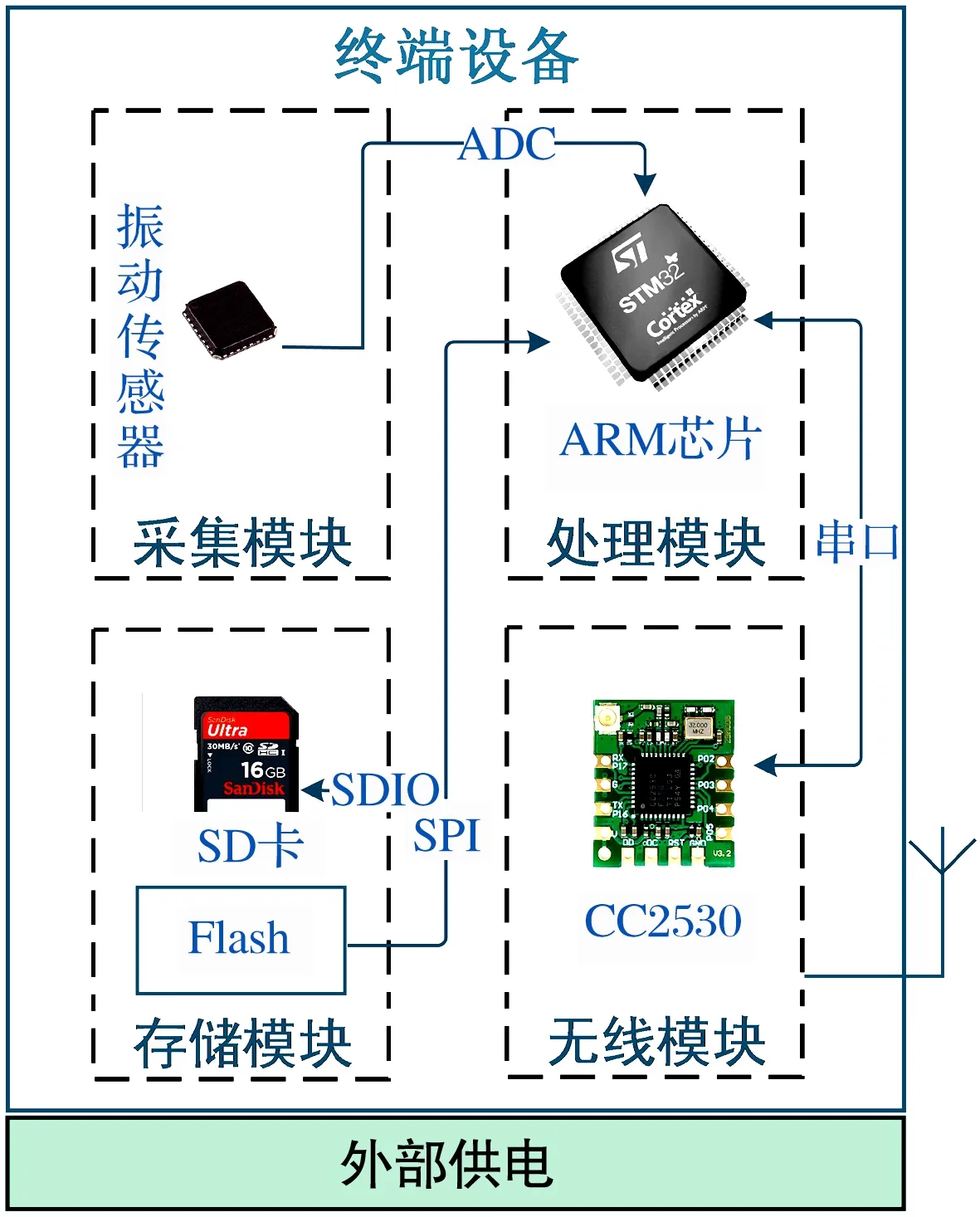
图8 终端硬件架构
2.3.2 中继
中继硬件架构如图9所示,由ARM内核芯片、CC2530、Flash内存、SD卡以及4G网络模块等组成,主要实现算法判断、网络控制和数据中转等功能。该设备嵌入了神经网络算法和故障诊断策略,能够接收终端设备上传的特征数据并使用建立的模型算法实现故障识别,进而实现设备故障的预警报警功能;同时,可通过网络协议配合网络模块进行数据的打包和上传,还可使用Bootloader程序与远程服务器配合实现远程更新和实时配置的功能[15]。包含故障识别诊断系统和故障预报警系统的中继整体框架如图10所示。
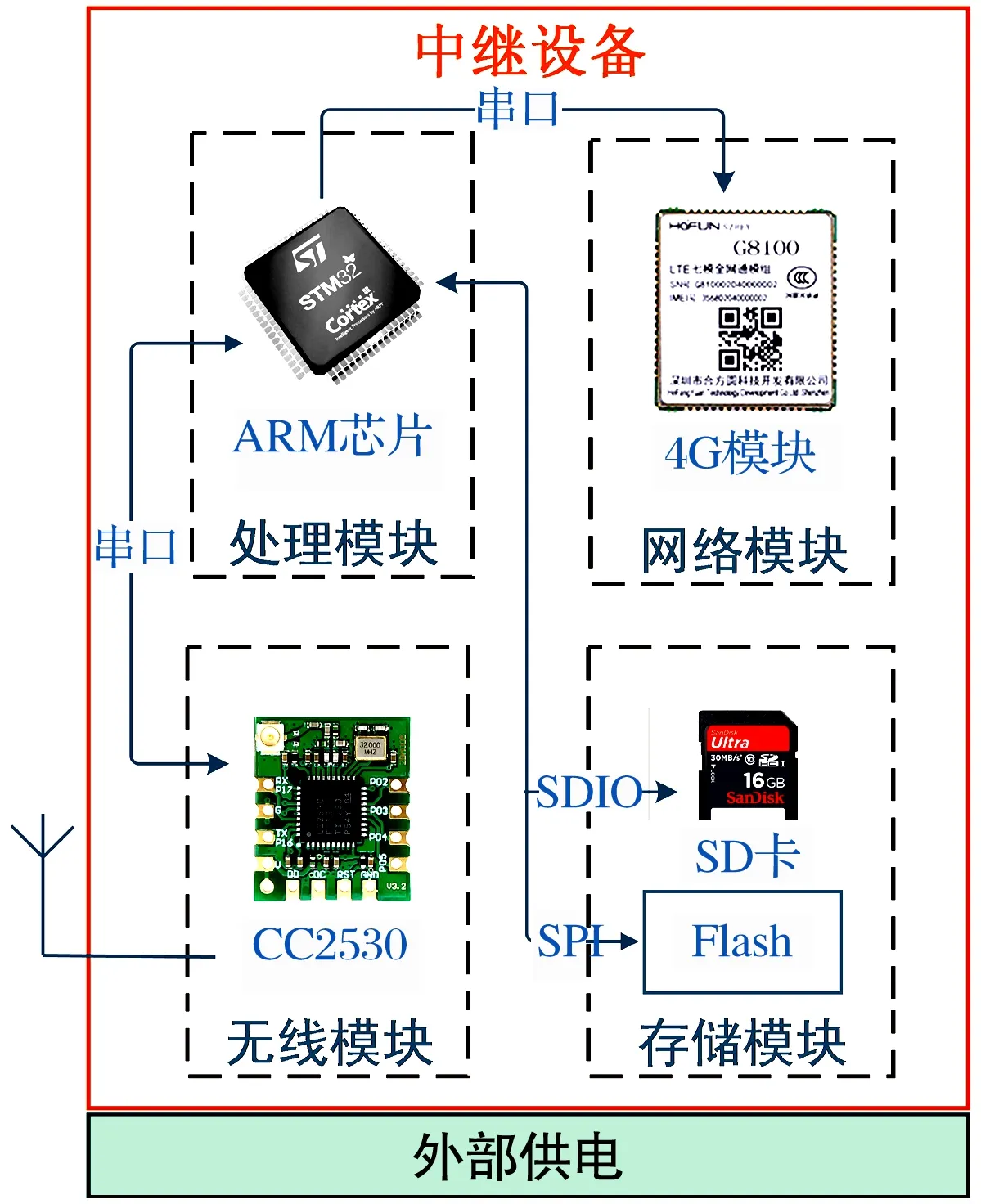
图9 中继硬件架构
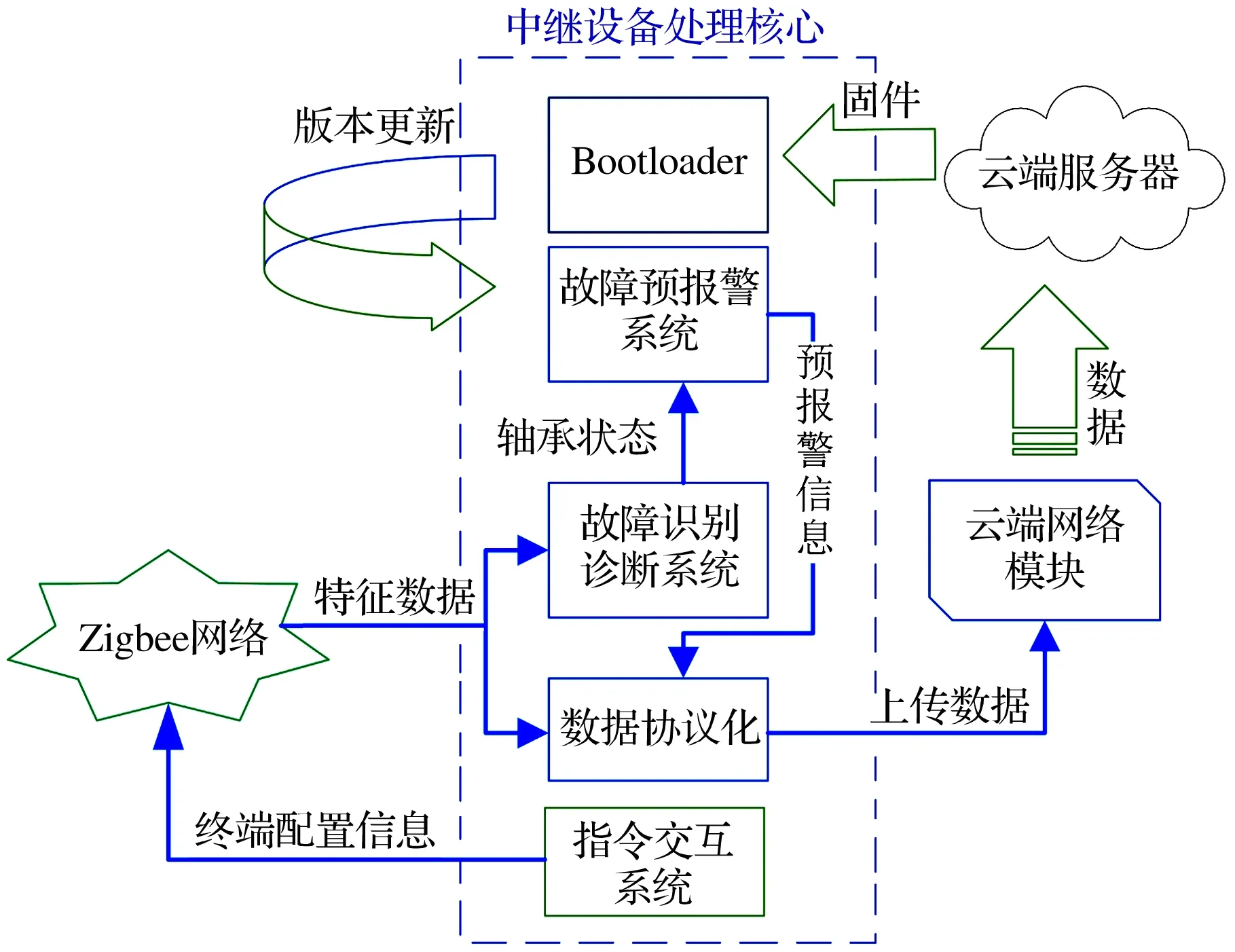
图10 中继整体框架
1)故障识别诊断系统
中继层对各节点的故障识别主要基于嵌入的神经网络模型。中继层处理器首先读取存储在Flash中的神经网络参数用于模型初始化,再读取终端发送来的特征数据包并提取其中的特征信息,然后使用交叉神经网络模型进行计算,并根据多个模型的融合计算结果对轴承状态进行判断,最终将结果处理成故障标志,为后续的预报警系统提供输入信息。
2)故障预报警系统
多维报警算法从以下角度对当前轴承状态进行评估。
(1)状态队列评估
在中继设备中会为每个节点保存一个固定长度的历史状态队列和故障计数器,历史队列中保存着每个节点最近的状态信息,中继根据历史状态信息计算出队列的故障期望,以在一个较长的时间维度上做出判断,从而避免偶然性错误信号对整体判断的影响。
中继通过神经网络模型获取相应的轴承状态后,生成状态标志si(取0,1,2,3,分别代表健康、轻微故障、中度故障、严重故障)放入相应节点的状态队列中,故障程度越高则对故障期望的影响越大。状态队列通常维护有c倍采样间隔时间内轴承节点的状态,过期的状态信息会自动清除。将故障标志累加后取平均作为故障期望E,即
(3)
本系统设置的故障预警及报警期望阈值分别为Fp和Fw,故障计数器的预警及报警阈值分别为Cp和Cw,具体判断策略见表3。为避免系统启动时的信号波动或偶然故障信号的影响,预报警系统设置一个热机阈值K,状态队列预报警机制在队列填充数据量c>K时才会启动。
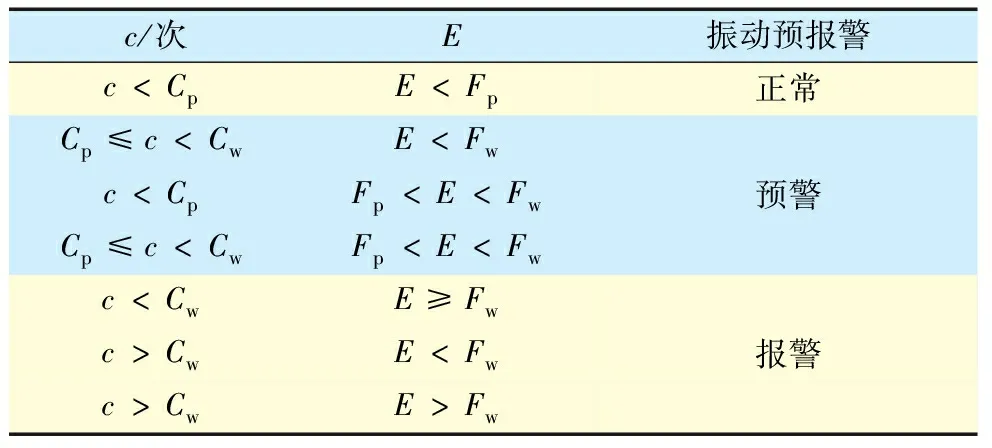
表3 振动预报警判断策略
(2)故障计数器判断
如果判断为故障则对应的故障计数器自增,自增值与状态标志相同(轻微故障自增1,中度故障自增2,严重故障自增3)。如果故障计数器值超过相应的报警或者预警阈值便触发振动预报警系统,其中连续的故障判断表示存在突发性紧急故障。
如果上传的判断状态为健康,则故障计数器清零后重新计数,并将状态标志加入状态队列;同时再次计算此时的故障期望,根据故障期望值对预报警系统进行重置,若低于振动预报警阈值则对预报警进行清除,具体流程如图11所示。
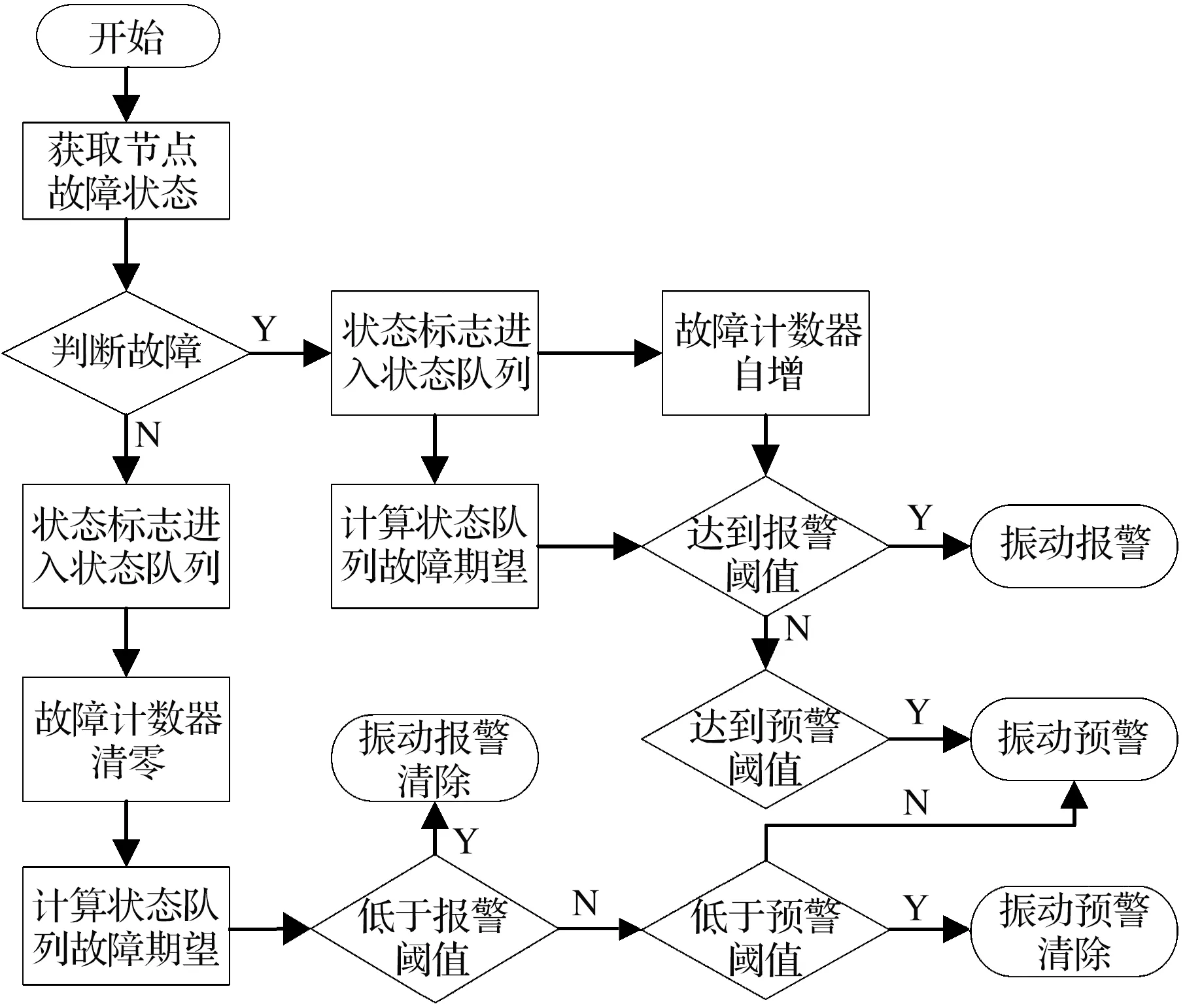
图11 监测系统预报警逻辑图
2.4 用户层
用户层是基于浏览器/服务器(Browser/Server,B/S)架构进行设计和开发的,为技术人员提供一个交互接口和界面显示的云平台。云平台后端采用Springboot与Netty结合的复合端口设计,提供TCP数据上传和web数据访问功能,数据库使用MySQL数据库的JPA(Java Persistence API,JPA),前端界面和图表显示主要使用bootStrap和Echart框架实现,并通过thymeleaf引擎进行渲染,加入了相关的交互功能,包括监测系统更新固件上传下载、数据统计分析等。
轴承云边协同监测系统云平台前端浏览器页面如图12所示,导航栏中包含有首页、数据分析、设备总览、远程控制以及数据选择4个菜单选项。首页主要展示的是设备总览信息,右侧状态信息栏包括设备总数、监测点数、在线设备数量、以及各状态监测点数量等,并可通过详情链接到设备总览视图,中部以饼图的形式展示所有监测点的总体报警状态(绿色代表正常监测点,黄色代表预警监测点,红色代表报警监测点)。
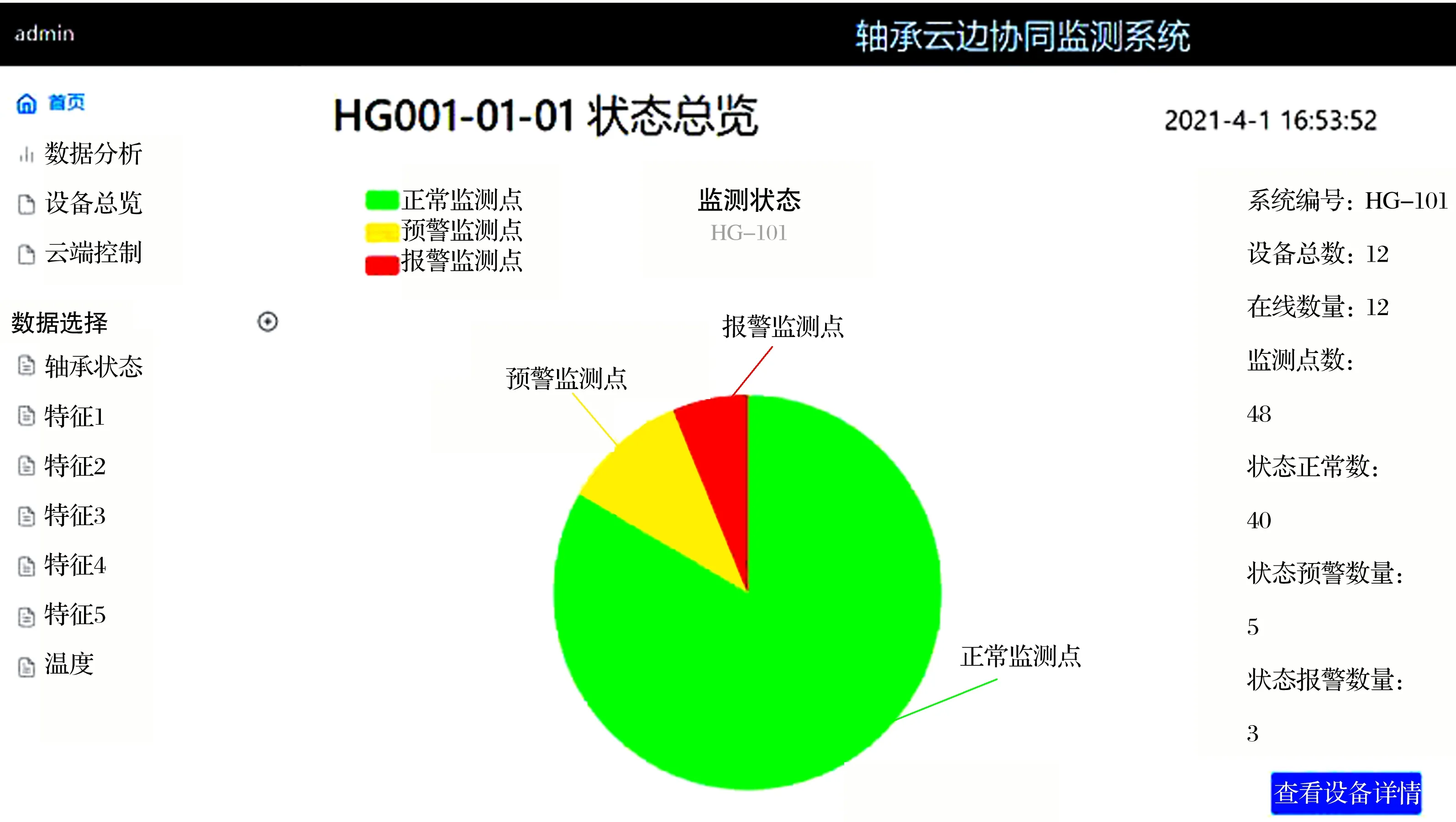
图12 轴承云边协同监测系统云服务平台主界面
3 试验验证及数据分析
3.1 算法可靠性验证
3.1.1 数据采集
为了验证算法的正确性,在6308滚动轴承(外径90 mm,内径40 mm,宽度23 mm)外圈加工不同尺寸缺口以模拟不同的故障状态(图13),不同状态轴承数据见表4。在1 800 r/min的振动台上以12 kHz采样频率进行数据采集,截取到的不同状态轴承的部分振动信号如图14所示。

图13 不同故障程度的轴承
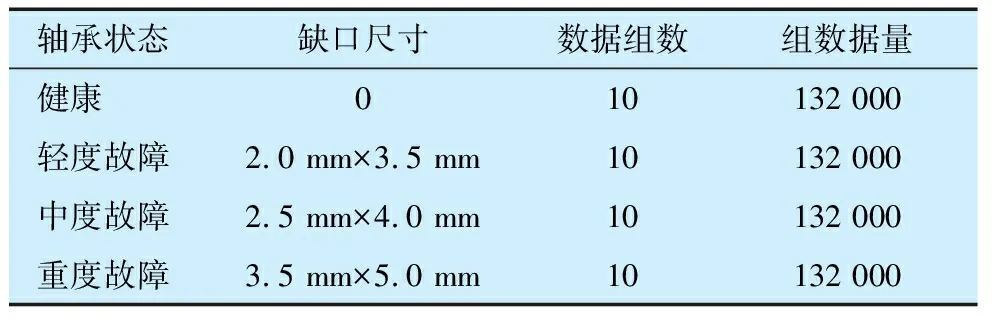
表4 不同故障程度轴承数据
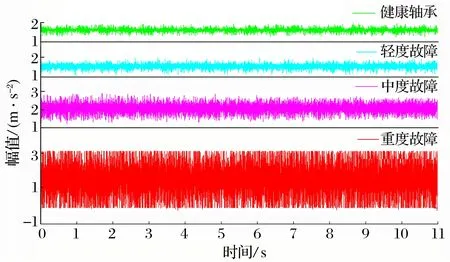
图14 不同状态轴承的振动信号
3.1.2 特征选择
通过数据采集装置获取振动数据,将节点采集获取的训练数据根据轴承状况进行标签化处理后,对数据集进行均分并提取11个时域特征和13个频域特征。共采集4组轴承数据,使用特征选择算法获得特征距离的相关统计量,并进行平均后从大到小进行排序,见表5。
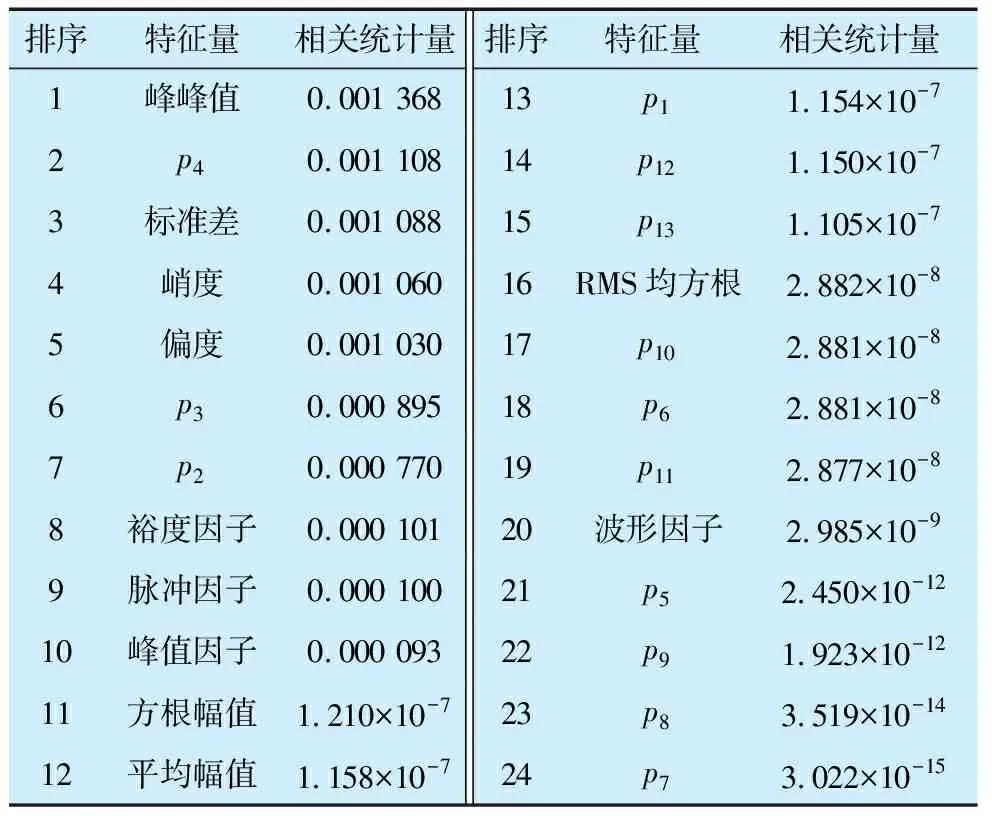
表5 轴承节点特征距离的相关统计量
根据得到的统计量信息判断各特征对故障诊断的识别能力,选择识别能力最强的5个特征用于后续的神经网络模型,分别为峰峰值、p4、标准差、峭度、偏度。
3.1.3 模型训练及测试
将Releif-F特征提取算法得到的特征集作为训练融合神经网络模型的样本,损失函数大小设置为0.001,训练步长为0.1。
测试集对于训练出的网络模型的测试结果及分类效果用t-sne聚类图和混淆矩阵进行可视化,分别如图15、图16所示。
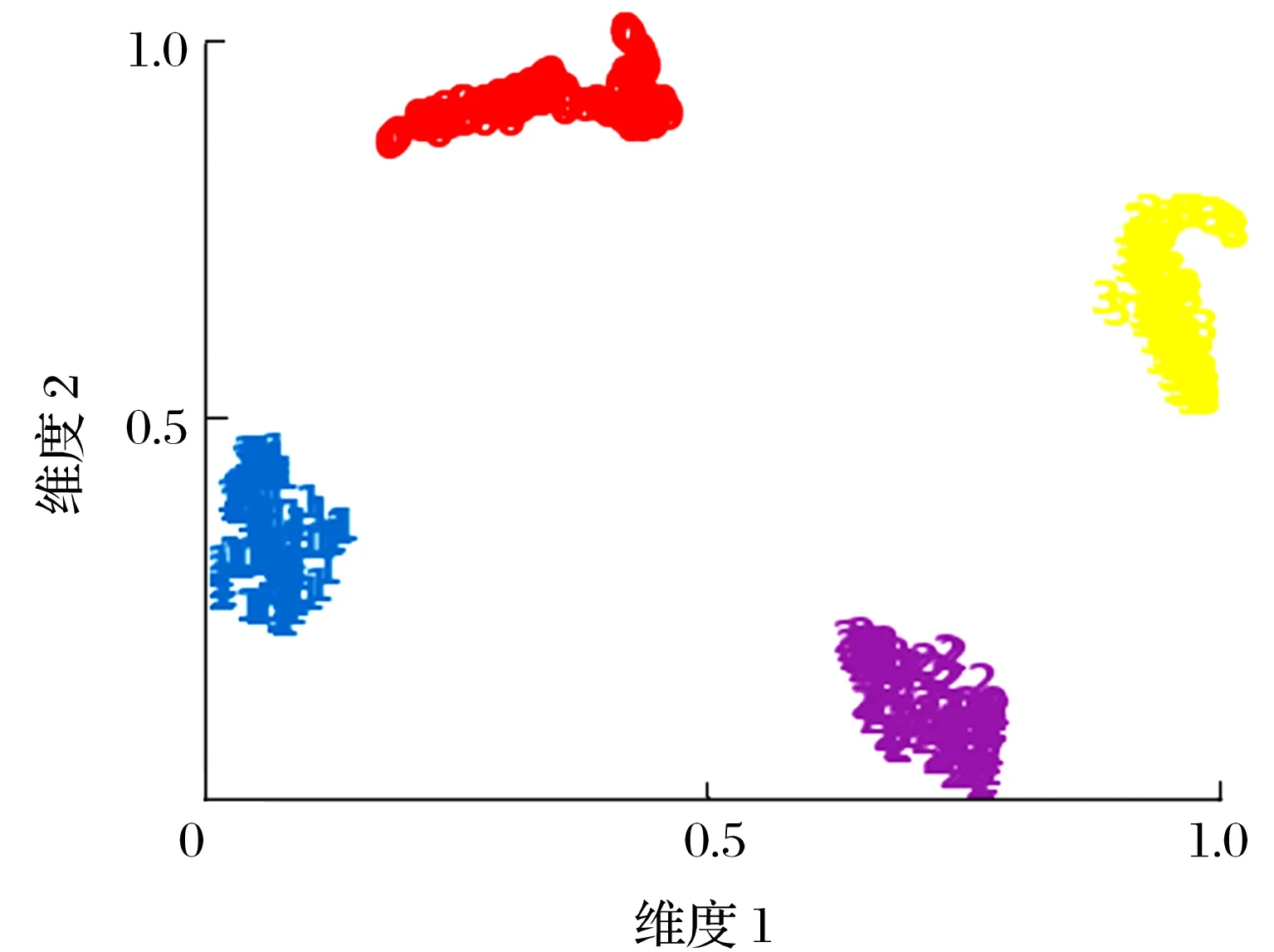
图15 隐层t-sne聚类图
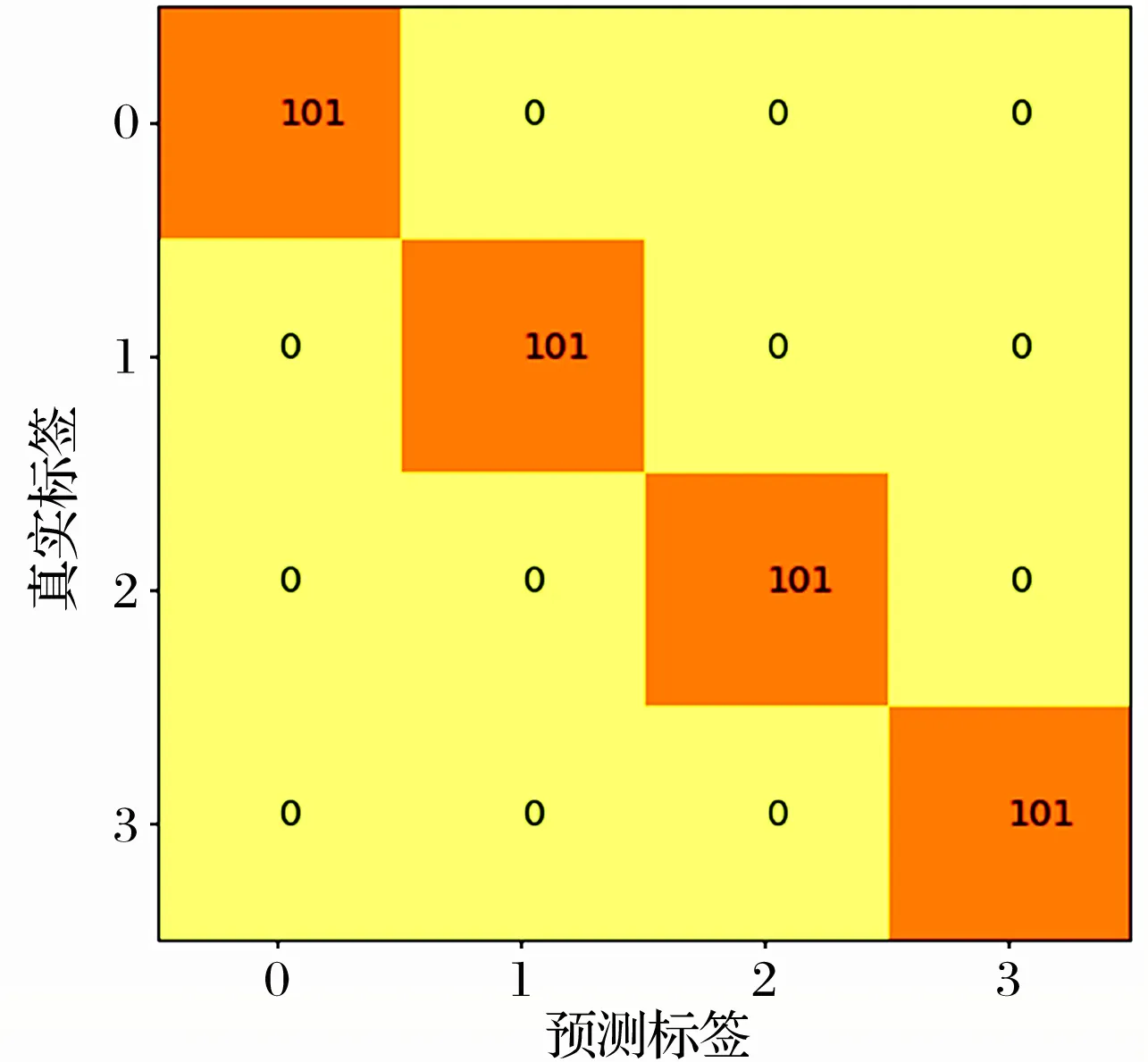
图16 混淆矩阵
由t-sne聚类图可以看到提出的神经网络算法模型有较好的分类能力,在混淆矩阵中,预测结果和真实结果一致,表示神经网络算法有较好的识别性能。
3.2 监测系统试验验证
3.2.1 轴承试验台的搭建
基于BVT-5型轴承振动测量仪搭建试验台,基本原理图如图17所示,轴承试验台的布置如图18所示,将试验轴承安装在BVT-5轴承振动测试台上,施加150 N的径向力,终端的加速度传感器安装于轴承外圈采集加速度信号,通过无线网络将处理数据传送到中继设备,中继设备将数据处理之后传送到云端进行显示。
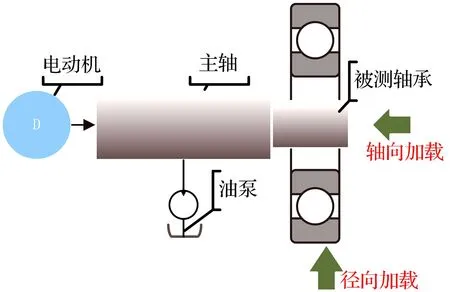
图17 BVT-5型轴承振动测量仪基本原理图

图18 试验台布置图
3.2.2 轴承云边协同监测系统试验
试验台、终端及中继的相关配置见表6,特征选择参数按照Relief-F算法所得的结果,监测系统的相关参数通过OTA远程固件更新进行配置,使用不同故障轴承进行试验的流程见表7,云平台轴承故障期望曲线监测结果如图19所示。
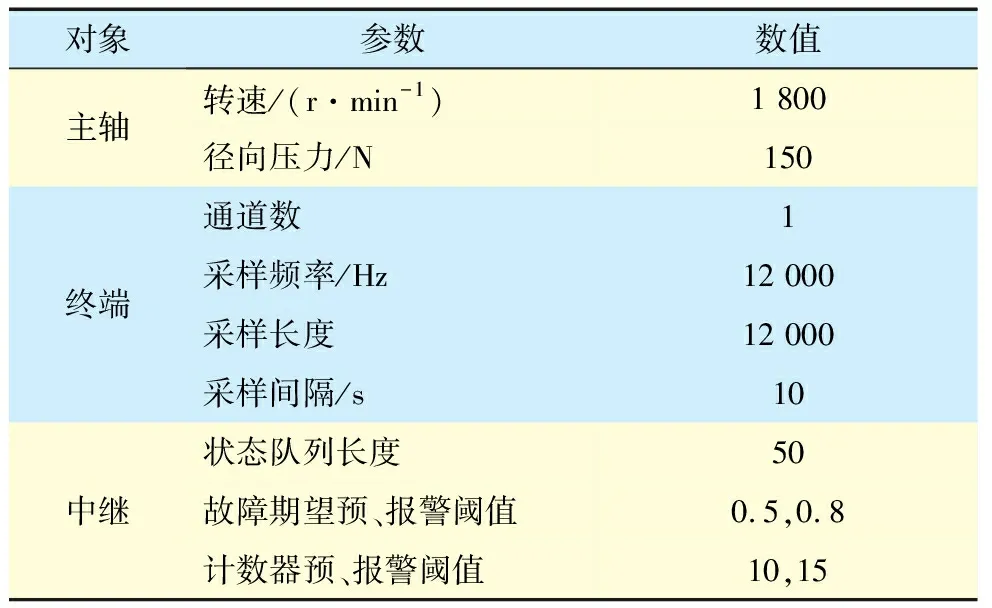
表6 试验设备参数配置

表7 试验流程表
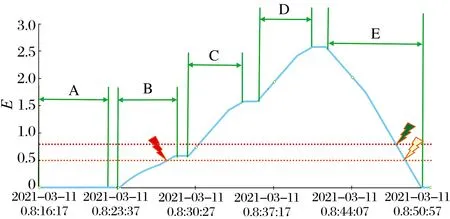
图19 云平台轴承故障期望变化曲线
由云平台轴承故障期望变化曲线可知,不同故障轴承试验流程共分为5个阶段:
1)阶段A。安装健康轴承作为被测轴承,通过云平台观察到轴承故障期望曲线一直处于0位置,显示为轴承无故障。
2)阶段B。更换被测轴承为轻度故障轴承,更换轴承期间,故障期望仍保持原有水平,更换后可以看到轴承故障期望开始上升,原因是监测系统诊断出的轻度故障结果进入状态队列导致故障期望升高,通过计算可知状态队列中约有20个0标志和30个1标志,根据(3)式,理论上故障期望为(30×1+20×0)/50=0.6,监测故障轴承300 s后,故障期望值为0.58,基本与预期一致。此时触发了报警,由于此时未达报警的故障期望值,此处报警是连续报警计数器触发的。
3)阶段C。更换被测轴承为中度故障轴承,故障期望值继续上升,且斜率较阶段B中曲线更大,此阶段的曲线分2段,前半段状态队列中仍然有0状态标志,后半段0状态标志已完全离开状态队列,斜率减小。监测时间结束后状态队列中应有30个2状态标志和20个1状态标志,理论故障期望值为(30×2+20×1)/50=1.6,实际为1.58与理论基本一致,此时已超过故障期望报警阈值,显示为报警。
4)阶段D。更换被测轴承为重度故障轴承,此阶段的曲线也分为2段,前半段队列中存在状态1标志,后半段1状态标志离开队列。监测时间结束后状态队列中应有30个3状态标志和20个2状态标志,理论故障期望值为(30×3+20×2)/50=2.6,实际监测值为2.58,与理论基本相符,此时已超过故障期望报警阈值,显示为报警。
5)阶段E。最后将被测轴承更换为健康轴承,从云平台监测图可知,更换监测轴承后,故障期望值开始下降,当下降到预警阈值和报警阈值时报警解除。监测结束之后,轴承期望值恢复为0,轴承状态恢复。
经过试验验证,监测系统数据传输正常,有可靠的故障识别和报警能力,满足功能需求,少量误差可能来自于轴承更换时带来的试验误差。
4 结束语
本文以轴承监测系统为设计对象,针对现有监测系统的不足和局限,设计了一种云边协同的轴承监测系统。该系统具有传统无线监测系统远程监控能力,还可以通过云端功能实现远程控制,针对不同的运用环境进行相应的配置更新,实现了监测系统的灵活性和通用性;采用的多核心多层网络架构具有特征提取、分类算法、故障决策和预报警功能,实现了监测系统的智能化和实时性,解决了传统监测系统采集量大,网络传输延迟导致的监测滞后问题等;采用的神经网络故障诊断模型嵌入到边缘网络,经过试验证明具有良好的性能。
