数字图像篡改检测技术综述
2022-12-09朱新同唐云祁耿鹏志
朱新同, 唐云祁, 耿鹏志
(中国人民公安大学侦查学院,北京 100038)
0 引言
随着信息化程度的不断加深与数字成像设备的大规模普及,数字图像逐渐成为现代生活中不可或缺的组成部分,数字图像的真实性与安全性也受到了空前的重视,数字图像取证技术(Digital image forensics,DIF)逐渐成为一大研究热点。数字图像取证技术可分别为主动取证与被动取证两大方向,主动取证技术的代表是数字签名技术和数字水印,此类技术运用的前提是图像经过数字水印处理,应用局限性较大。被动取证技术则可再细分为图像溯源取证技术与对图像篡改行为的检测技术,前者主要聚焦于追溯一张数字图像是由哪台设备拍摄,后者则是本综述所讨论的重点。
图像取证技术起步于主动取证技术,1993年,Friendman基于电子邮件数字签名的思想,提出了可信数码相机(Trustworthy digital camera)的概念。即在数字图片数据的生成过程中同时生成一个对应的唯一编码,可以根据哈希或其他算法生成,作为图像原始性的依据。这种主动添加的图片身份证有许多先天性的不足。比如数字图像在网络传播的过程中会经历多次压缩或格式转换,这些操作会改变图像的哈希值,而图像本身的画面信息除了被某种压缩外没有经过任何修改。这就导致大多数情况下对数字图像的原始性和有效性的证明还是依靠专家的鉴定,对数字图像篡改检测的需求仍然没有得到有效解决。因此,无需事先添加信息的被动盲检测技术成为近年来的研究热点,本文所介绍的各类检测方法均属于被动盲检测技术。
数字图像篡改检测技术在近年来有巨大进步,该领域发布了大量基于深度学习技术的新型算法。因此,本文按照数字图像成像流程梳理了各类可检测特征,对各方向的篡改检测方法所采用的技术路线进行分类和整理,并对其检测结果进行分析。本文在最后对目前数字图像篡改检测相关研究中问题和挑战的解决办法进行深入思考,旨在为该领域提供一些方向性参考。
1 数字图像成像过程中所产生的特征
数码相机在生成一张数字图像的过程中主要涉及光电转换和模拟数字转换两类信息转换(ADC),在此流程中所使用的处理技术则可分为3大类,即光学技术、传感器技术和图像处理技术[1]。3种技术分别对应图1中的镜头(Lens)、传感器(Sensor)、图像信号处理(ISP)3步,3类处理过程对最后的输出图像各施加了不同的影响,从而在图像中留下了具有不同特点的规律。
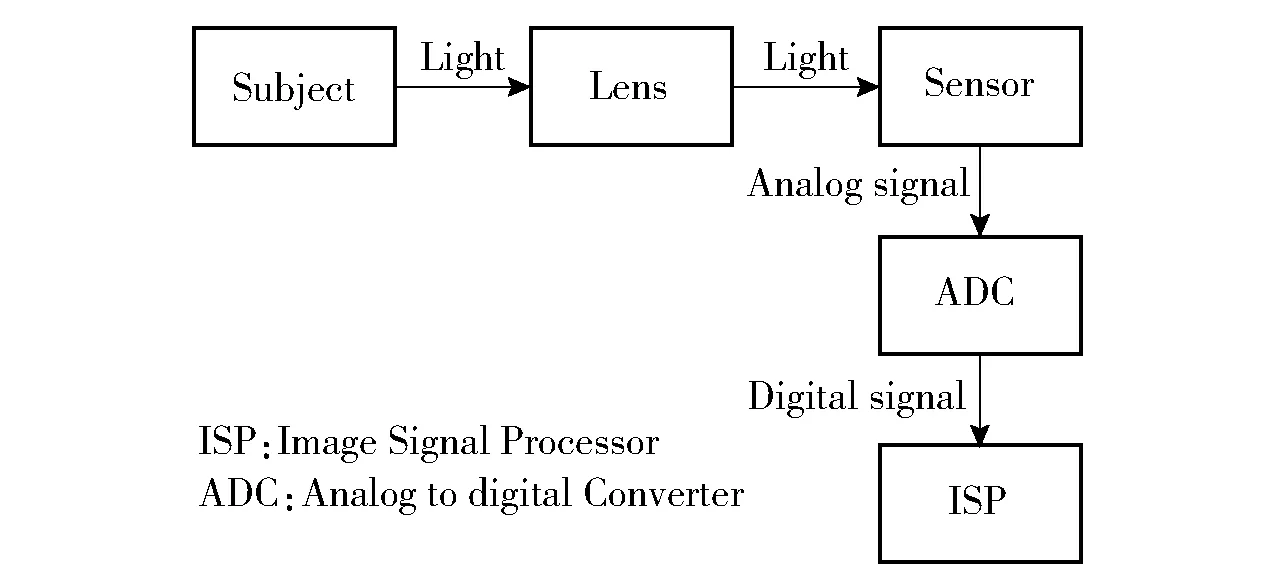
图1 数码相机的视觉处理过程
本文受文献[2]与[3]的启发,根据数码相机拍摄图片所需要的处理过程,按照特征的来源对数字图像成像过程中所产生的特征进行分类介绍。同时,把篡改行为所产生的特征按照特征的来源分类,可以有效地区分出各类图像篡改特征的本质差异,有助于深度学习方法对某种特征进行针对性训练以及对后续研究方向提供指引。
1.1 被拍摄客体的自然特征
相机拍摄的画面会忠实地还原被摄客体的状态,也能记录下客体所具备的物理和几何规则的表现。一些经过伪造的照片会表现出明显违反自然规律的表现,如曾引发舆论热议的“浮空视察”照片。这类特征就是胶卷时代的图像篡改检测技术所关注的特征类型。在文献[4]中Peng等人提出了具体的测算方法来判断画面中的物品或人是否符合自然规律。其他可利用的特征还包括相机中心点、透视关系[5]、光照一致性[6]、阴影方位[7]等。
由于这类特征是拍摄画面中的一部分,属于日常生活中常见规律的表达,所以它易于人脑理解,也是人们主观判断图片是否经过伪造的主要特征依据。比较反常识的是,人眼对这种特征的改变其实并不敏感。有研究表明,在对阴影、透视变形、镜中画面规律是否被篡改的问题上,大多数受试者无法给出正确答案[8]。对于被摄客体的自然特征在图像取证方面的应用,卷积神经网络尚未在这个领域获得较大突破。
1.2 镜头光学特征
相机在记录影像时,会利用透镜等光学器件对被摄客体射向镜头的光线进行一系列的光学处理,使其变成适合被感光原件所记录的形状,此类处理过程中会在入射光线中留下镜头的光学特征。其中有一部分镜头光学特征是拍摄者可在一定范围内定量调节的。如拍摄时所使用的焦距、光圈等镜头参数,这些参数既有联系也有制约,直接影响到相机成像的景深、视场角、透视等效果[9]。
此外,镜头还会给画面附加上一类拍摄者无法控制且难以消除的特征。在多色光作为光源的情况下,相机的镜头难以精准地把不同波长的光线聚集到同一个焦平面,此时就会产生色差。镜头的折射还会带来畸变,并且由于凸透镜离中心越远,折射效果越强。镜头在不同的放大或缩小倍率下画面还会产生桶形畸变和枕形畸变,广角镜头通常是枕形畸变,鱼眼镜头通常是桶形畸变[10]。这类本是一种成像缺陷的镜头特征也可以利用在图像篡改检测上,比较具有实用性的特征是紫边失真、镜头色差(Chromatic Aberration)和镜头球面差(Spherical Aberration)。由于色差会导致RGB颜色通道中的3张图像有轻微的偏移效果,文献[11]就利用算法提取RGB三通道中的横向色差来实现图像篡改检测。
1.3 传感器噪声特征
在数码相机中,承担光信号到电信号转换任务的核心原件就是图像传感器(Image Sensor)。目前有两大类被广泛使用的图像传感器,一种是电荷耦合器件CCD(Charge Couple Device);另一种是互补金属氧化物半导体CMOS(Complemen-tary Metal Oxide Semiconductor)。
图像传感器的输出信号是从空间中采样的离散模拟信号,由于各种干扰因素的存在,信号中夹杂着大量噪声,产生的范围包括信号的输入、输出、电荷的存储和转移等。传感器产生的噪声类别有:热噪声、光子散粒噪声、复位噪声等[13]。其中由于暗电流(Dark Current)的差异而产生的固定模式噪声(Fixed Pattern Noise,FPN)和各像素对光的敏感度不同而产生的光感应不均匀(Photo Response Non-Uniformity,PRNU)特征具有较强的稳定性,且PRNU噪声比FPN噪声更难以消除,所以PRNU噪声的实用化较强。这类具有稳定性噪声被称为“CCD的指纹”或“传感器的指纹”[14-15]。传统深度学习方法可以有效地提取和利用此类特征[16-17],而采用了卷积神经网络结构算法的检测性能则更加优异。
1.4 数字图像处理特征
一张数字图片的生成离不开数字图像处理技术,该技术基本可以分为两大类:模拟图像处理(Analog Image Processing)和数字图像处理(Digital Image Processing)。根据文献[18]中的定义:“数字图像处理是使用计算机来合成、变换已有的数字图像,在原有图像上产生一种新的变化,并把加工处理后的图像重新输出”。数字图像处理的功能有几何处理、算数处理、图像编码等。
在数字图像篡改检测领域,图像处理特征是与深度学习技术结合最紧密的特征,现有篡改检验算法基本都依靠提取此类特征来实现篡改检测。在数码相机中,数字图像处理的任务就是对A/D转换器输出的RAW格式原始数字信号进行处理,以还原出更加真实的图像。负责这项任务的是图像信号处理芯片ISP(Image Signal Processor)。ISP在RAW格式的图片上可以实现去噪、CFA插值去马赛克、色调映射、色彩变换、压缩等功能。在电脑上,我们还可以使用各种图像处理软件来进行数字图像后处理。在相机与电脑上的图像处理软件所使用的处理算法本质上是一致的,所以他们会产生同一类特征[19]。
数字图像处理特征遍布在数字图像中的各个方面,国外一般将数字图像处理特征的表现称为“statistical correlation”或“statistical inter-pixel correlation”,文献[20]中将其称为“数字属性特征”。这类特征产生的原因是在图像处理过程中,各类算法的使用使邻近像素之间被人为的添加了某些统计规律,如重采样方法中的CFA插值算法就在像素间引入了加权平均特征[21]。
2 主流数字图像篡改检测方法
2.1 同源复制粘贴特征检测方法
同源复制粘贴(Copy-move)是指复制出同一张图片上的一部分画面,对复制画面进行几何变换、颜色与对比度调整、模糊或锐化等处理来对图片进行修改的方法。在图片伪造实际应用中图片的纹理区域,如桌面、草地、道路、衣物等是复制粘贴的理想选择,因为复制的区域再加上边缘的羽化可以有效地使其与背景混合,人的眼睛难以将其分辨出来。复制粘贴篡改主要特征是图片上会出现两块高度相似的区域,所以如何识别出高度相似区域是复制粘贴检测的一条主要思路[22]。
同源篡改时虽然会对复制区域进行一系列处理,但其处理后的两片区域中仍带有大量的尺度不变特征变换(Scale Invariant Feature Transform,SIFT)特征。SIFT特征指的是可以利用SIFT算法思路来提取到的特征,这类特征的共同点是物体上局部外观的兴趣点,SIFT特征对于光线变化、图片噪声、视角改变等也有很高的容忍度。利用SIFT算法提取特征也是同源复制粘贴篡改检测的主流思路。David Lowe于1999年提出并于2004年完善检测SIFT特征的算法[23],这种方法基于尺度空间,提取图像平移、旋转、缩放等映射变换后保持不变的关键点描述向量,一般为一个长度为128的一维向量。
图像金字塔是数字图像处理中的常见算法,通过多分辨率尺度的叠加来更高效地解释整张图像的信息,其结构如图2所示。下层高分辨率图片体现细节信息,上层低分辨率体现整体结构信息,一般下层图片经过步长为2的滤波器的下采样处理得到上层图像。图像金字塔的概念被广泛应用于计算机视觉的各类算法中,包括最新的YOLO[24]算法结构,在RPN(Feature Pyramid Network)层中也大量运用了多尺度图像信息叠加的概念。
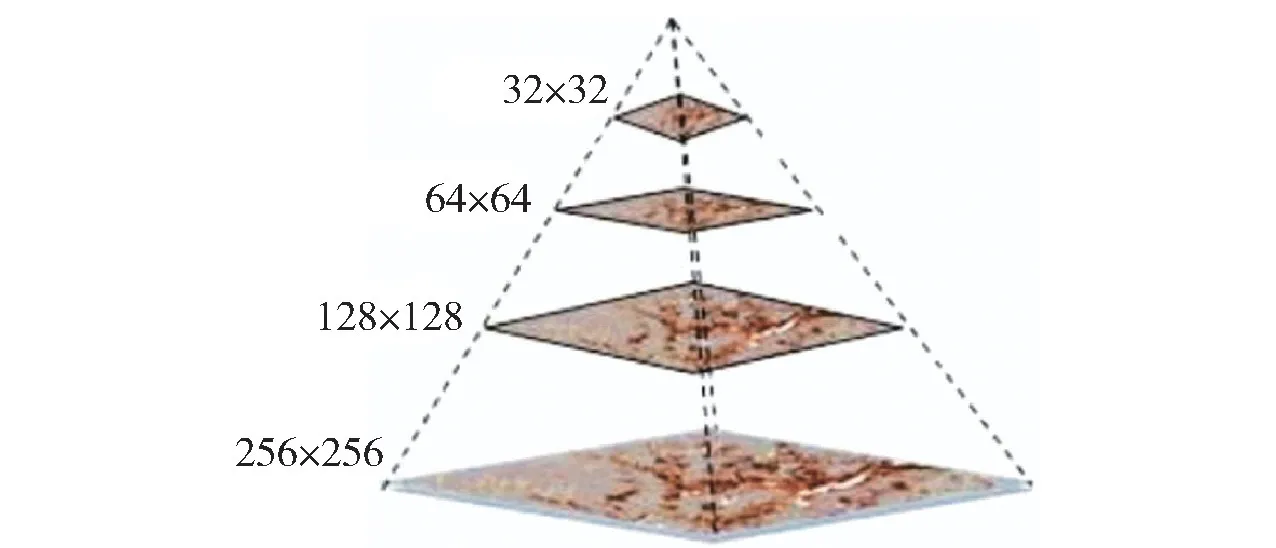
图2 图像金字塔
高斯金字塔就是使用高斯低通滤波作为滤波器的图像金字塔,SIFT方法就使用高斯金字塔来提取特征点。使用不同的尺度空间因子(高斯正态分布的标准差σ)对图像进行逐级下采样,形成一个从突出丰富细节特征到突出个别显著特征的图片金字塔。高斯差分金字塔(Difference of Gaussian,DOG)则又增加一步,把上下图片逐级相减,使用这种办法来提取差分图像所蕴含的稳定特征[25]。
SIFT算子会把剩下的每个特征点用一个128维的特征向量进行描述,进而进行特征比对,识别出篡改区域。这种思路与时下许多目标检测模型类似,图3展示了文献[26]中提出的一种利用SIFT特征进行同源复制粘贴篡改的检测实例。基于SIFT思路,目前研究人员开发出诸如SURF算法的大量特征提取新算法。

图3 使用SIFT算法识别同源篡改示例[26]
通过SIFT特征与其他算法的结合,可以做到针对同源复制粘贴篡改的检测与定位。文献[27]中,XiuLi Bi等人使用新型多尺度特征提取算法,舍弃了传统以方块滑动划分特征提取区域的方法,而是使用简单线性迭代聚类(Simple Linear Iterative Clustering,SLIC)完成图像分割,再把分割好的图像送入SIFT算法中提取特征。在实验中XiuLi Bi等人设计了包含48张复制粘贴篡改图片和48张原始图片的篡改检测实验。实验结果显示,XiuLi Bi等人的深度学习新型算法在两种尺度的测试中均取得了90%以上的篡改区域定位精确度,而传统SIFT算法和SURF算法的篡改区域定位精确度与其相比均有明显差距。
2.2 光响应非均匀性特征检测方法
光响应非均匀性(PRNU)特征指的是相机感光原件所带有的噪声特征,其主要来源是由于感光原件在制造过程中,硅涂层的厚度不同导致各像素对光的敏感度不同[28]。
图片的噪声有两个主要来源,首先是在图像的获取过程中,由于CCD或CMOS受材料属性、工作环境、电路结构等影响,影响光电转换的电流稳定性,会引入各种噪声。其次在信号传输过程中,信号受传输介质和外界环境影响。利用此特征可以实现图片来源和真伪的检验,即确定图片是否由某一相机拍摄,或者图片是否被篡改[29]。
光响应非均匀性特征的提取可分为滤波和增强两个阶段,其中滤波阶段使用小波变换滤波器、维纳滤波器等手段提取图片背景噪声特征,计算原始图像与经过滤波器后所得图像的差值,从而得到感光原件的噪声残差。在增强阶段可以使用多个来自同一相机的图片进行噪声的矫正和提纯,并且还可以去除图像在重采样过程中产生的其他特征。增强阶段可以使用稀疏编码[30]等机器学习方式来获得更好的效果[31]。
使用卷积神经网络结构的算法同样可以做到利用光响应非均匀性特征的图像来源识别和篡改识别,即使是单像素的偏移也会对残差的局部统计产生很大的影响。文献[32]中,文章作者利用两个并联的BP神经网络,同时计算两张图片的背景噪声残差,用均方误差计算两张图每个像素点的噪声距离。如果两张图是来自于同一个相机就鼓励网络缩小噪声距离,如果两张图拍摄的相机不同,则扩大噪声距离。
作者从Dresden dataset[33]、VISION[34]等数据集中收集了19个品牌、70个型号、125个相机拍摄的图片进行CNN的训练和测试。在对25个不同相机组成的测试集进行分类验证的表现为,像素定位(Pixel-Level Localization)的AUC值可达0.967。
光响应非均匀性特征还可以用来定位图像篡改区域,其检测效果如图4所示。根据上文提取的图片噪声距离,以同一相机拍摄的一张已知原始图片为样本,与待检测图片比对噪声距离大小,形成噪声距离热力图。距离小的区域为冷色,距离大的区域为暖色,根据噪声距离可以判断出可能的篡改区域。
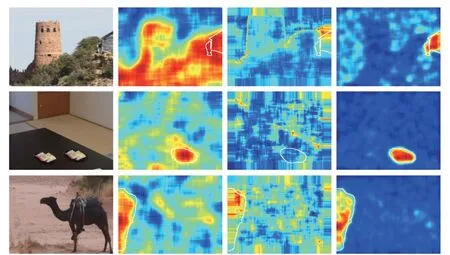
图4 文献[32]中基于PRNU的噪声热力图的的识别效果
2.3 重采样特征检测方法
这种特征主要来自于非同源复制粘贴篡改(Splicing)行为,对非同源复制粘贴篡改行为的检验鉴定也是公安实战中最常出现的需求。根据公安部某物证鉴定中心2012~2016年受理案件的统计数据,涉及图像取证类案例中,90%以上的鉴定要求是对单幅图像是否存在拼接篡改的检验[35]。非同源复制粘贴是指从其他图片中复制一定区域的图像,覆盖或改变目标图片的一部分区域的处理方法,由于篡改区域的图片重采样算法与原始图像不同,被篡改区域的像素排列逻辑与未篡改区域就会存在差异。
重采样是指根据采样后形成的由离散数据组成的数字图像,按一定算法重新采样的处理方法,主要分为增加分辨率的“上采样”和减少分辨率的“下采样”两类。重采样一般用在改变图片的像素大小上,比如重新生成一张不同像素尺寸的图片。不同于后期处理时的重采样操作,绝大多数数字图片在生成时都会经过一次色彩上的重采样,这就是CFA(Color filter array)插值[36]。这种插值方法图片使数字图像像素的排列方式存在特定规律,早在2003年,Kirchner等人就提出此类特征可应用在数字图像篡改检测中[37]。
数码相机为了捕捉3种波长光线的强度,在感光原件前面设置了一个滤光层,滤光层使感光元件上的每一个感光像素都只能感受特定波长的光线强度。目前最常见的排列方式是拜耳排列(Bayer Array)。但这种记录方式使得一个像素点只有一个色彩的亮度信息,要使拜耳排列得出的图像变得平滑,就要进行CFA插值处理。使用这种方法获得的彩色图像的各个像素之间存在着算法联系,如果非同源图片覆盖了一个区域,那么这片区域中的CFA特征就会被破坏,可以使用特定算法将篡改区域检测出来,这种不同插值方式的细微特征也可以被神经网络所捕捉并加以区分。
传统的CFA插值检测法为估算出图片的CFA插值噪声特征,需要利用后验概率法对3个颜色通道进行建模,利用高斯滤波器对图片进行滤波并提取CFA插值特征,标识出CFA插值规律被破坏的区域,根据提取出的区域大小来计算该区域被篡改的可能性。最大期望算法(Expectation-Maximization Algorithm,E-M算法)指在模型中寻找参数最大似然估计或者最大后验估计的算法[38],E-M算法计算方法的一次迭代分可分为两个步骤,分别为期望步(E步)和极大步(M步)。根据前次迭代计算出的数值来估算未知数据的值,再根据估计出的未知数据与已观测到的数据重新再对参数值进行修正,通过反复迭代,直至最后收敛时迭代结束。图5为警视通软件的CFA插值检测效果,图6则为MATLAB环境下基于EM算法的CFA插值检测效果。

图5 警视通软件CFA插值检测功能的识别效果
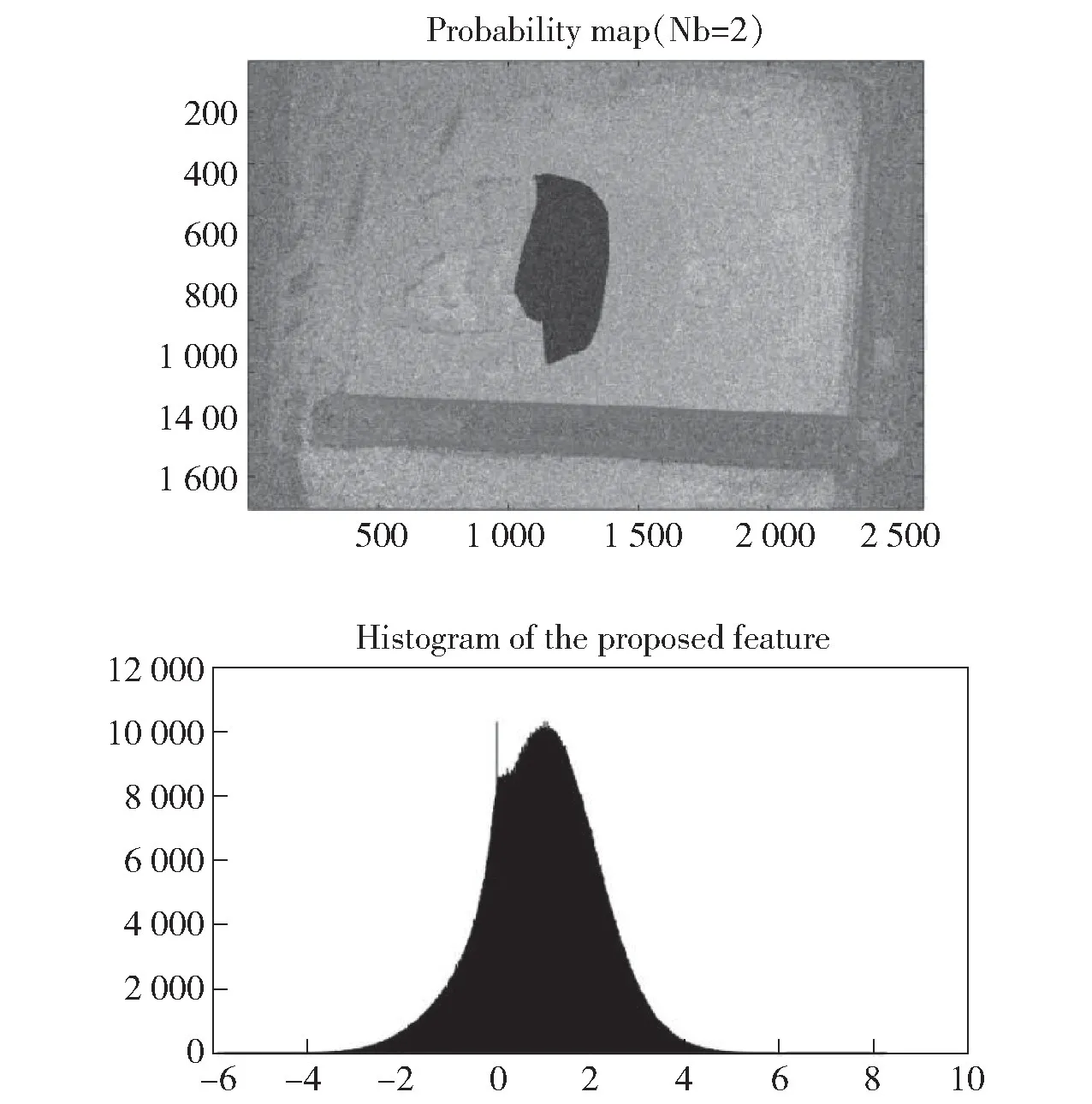
图6 EM算法的CFA插值检测的识别效果
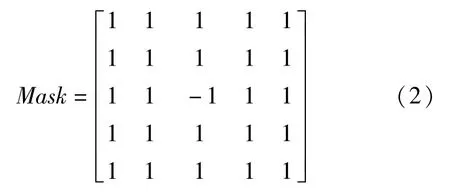
在卷积神经网络中使用特殊设计的卷积核就可以做到代替传统CFA插值检测法的效果,通过算法对比可以发现,两种方法在提取图像CFA插值特征时其实都用到了卷积计算。基于E-M算法的CFA插值检测法的卷积核如下式所示:

传统方法中使用的E-M算法也是一种拟合算法,在文献[38]中,其拟合的对象是图像绿色分量的预测误差,E-M算法拟合的过程和神经网络类似,损失函数都需要找到其似然函数的最小值。在文献[39]中,作者用BP神经网络实现了利用红色通道,取固定面积内图像实际颜色值与估算值误差的平均值对比来实现篡改区域检测。在文献[40]中,苏文煊等人使用支持向量机(SVM)进行CFA插值检测。作者表示,这种算法对LC数据集[41]和Dresden数据集[33]的篡改图片判断平均准确率均在96%以上。
但这类传统算法也有很大的局限性,如在“警视通”等警用图像处理软件中,由于算法泛化能力的限制,CFA插值检测就被限制到了非同源篡改检测中,如果放入同源篡改图片会导致算法失效。与传统算法不同的是,卷积神经网络本身可以学习图片除CFA插值以外的其他重采样特征,这类特征的来源不限于非同源篡改,运用简单的BP神经网络输出概率密度统计[39]就可以反应不同的图像插值算法所插值出图像的差别。
在文献[42]中,Belhassen Baya和Matthew C Stam等人对CFA插值特征的提取做了进一步研究,对CNN的卷积核进行了针对性设计。文章作者提出,在输入层使用这种特殊设计过的卷积核,就可以利用传统的神经网络结构提取出图片的CFA插值重采样特征。这种根据CFA插值本身计算方法提出的卷积核结构使神经网络对图像边界纹理不再敏感,而更专注于像素排列规律,从而使神经网络把学习重点放在重采样特征规律上。同时,Belhassen Baya等人还对训练集和测试集的图片进行了处理,其所用图片均为由原始图片绿色通道亮度信息形成的灰度图片,实现了对绿色通道的CFA插值篡改特征提取。
数字图片的像素在生成阶段会经过CFA插值的处理,在之后则可能会经历各类滤波器的后处理,从而在图像的某些区域上留下对应滤波器的特征。滤波器是数字图像处理的重要工具,经过滤波器重采样的区域中可能会出现异常噪声特征,如高斯滤波、中值滤波等。与CFA插值产生遍布整张图片的本底重采样特征不同的是,经过滤波器处理的图片区域带有的是特定滤波算法的后处理重采样特征,二者同属于重采样算法特征,在提取方式上也较为相似。
图片的背景噪声原本具有强随机性并随机分布,但由于上采样、下采样、插值3个重要后处理步骤的基本运作过程是由线性滤波器完成的,所以线性滤波器处理后的像素和噪声背景就会带有强烈的线性特征。除此之外,篡改区域往往经过了数次旋转、拉伸的重采样处理,这就使得篡改区域的噪声特征也附加了其他各类滤波特征。
从传统算法角度出发,提取噪声特征使用的也是E-M算法。文献[43]中Alin C Popescu和Hany Farid把重采样特征按照数字隐写的角度思考并提出了使用E-M算法来提取各种滤波器处理后的像素规律,以确定图像是否被修改过。
卷积神经网络由于具有学习功能,能取得比EM算法更好的效果,文献[44]中陈建生等人提出利用卷积神经网络来提取中值滤波特征,他们发现特定的卷积结构可以捕获相邻像素点之间的依赖关系,可以有针对性地设计不同的卷积核来识别不同的滤波器。
2.4 异常边缘特征检测方法
异常边缘特征检测算法在人工篡改检测与深度伪造篡改检测中都表现出了优异的性能。异常边缘在篡改图片中普遍存在,这种特征的产生也来源于重采样图像处理,与重采样特征主要关注篡改区域内部像素排列规律不同的是,异常边缘特征把目光放在了篡改区域与原始区域的交界处上。在对图片进行篡改处理的过程中,由于人的操作能力有限和软件算法的限制,篡改者很难完全按照物体边缘进行框选,并使新的图层边缘融入原图背景中,这就使得剪切下来的图片边缘产生不同于正常物体边缘的异常。
文献[45]中,王俊文等研究人员提出了一种基于SVM的人工篡改真锐化边缘点标记算法,通过对图像进行非下采样轮廓波变换[46](NonSubampled Contourlet Transform,NSCT)来提取图像中的边缘轮廓特征,该文作者提出了强、次强、弱3种边缘点分类模型,并通过实验证明原始图像与经过锐化处理的图像边缘点在Contourlet变换域上具有可分性。文献[47]中,王波等研究人员提出了异常色调率检测模糊处理的算法。该文作者认为,正常图片中不同物理的边缘颜色过渡特点在整张图片中呈现出稳定的规律,并且图片中物体边缘的过渡有一定的锐利性,而在受过模糊处理的图片中,这种特征会被严重破坏。该文作者首先定义了异常色调值与异常色调率的概念,文中提出异常色调值是在某一像素的8×8邻域中单独出现,并与邻域内像素色调差的最大值不超过某一阈值的色调值。而异常色调率指具有异常色调值像素的总数占图像像素总数的百分比。受过模糊操作的图像,其全局异常色调率通常为正常图像的10倍以上。
此外,这类异常边缘会影响图片的噪声流积神经网路和SRM滤波(Steganalysis Rich Model)[48]可以在盲检测的情况下识别,而使用卷积结构可以有效提取出这些异常。文献[49]中提出了一种双流Fast-R-CNN网络,在RPN(RegionProposal Network)网络中加入SRM滤波后的噪声流辅助预测框(bounding box)的调整,通过RGB流与SRM流的结合的异常边缘噪声实现了篡改图片的篡改区域定位,图7展示了其检测效果。

图7 文献[49]中图片噪声特征在Fast-R-CNN中的识别效果
文献[50]提出了一种基于YCbCr色域的篡改图片检测算法,该网络首先把图片从RGB色域转换为YCbCr色域,提取Cb和Cr通道的纹理图片,之后再生成纹理图片的灰度共生矩阵(Gray Level Cooccurrence Matrix,GLCM),最后把灰度共生矩阵送入神经网络中完成处理。该算法的结构如图8所示,这种算法构型具有很强的泛用性,能完成人工篡改图片检测和深度伪造篡改图片检测两类任务,在CAISA2.0这种人工篡改数据集与StyleGAN[51]这类深度伪造篡改图片数据集上都能达到98%左右的分类准确率。同时,使用灰度共生矩阵的处理方法能以很小的信息损失完成图像大小归一化,让不同分辨率的图像都能以共同的矩阵大小输入到神经网络中。该文献作者总结了异常边缘特征适用于深度伪造篡改图片检测的原因,虽然深度伪造图片可以达到以假乱真的效果,但在毛发细节、衣物纹理、阴影等要素的边缘仍会与真实图片有较大的区别。

图8 文献[50]中提出的算法结构
文献[52]中提出了一种基于多色域融合的异常边缘特征篡改检测算法,该算法利用YCbCr色域中Cb与Cr色度分量和RGB色域中G值分量,用不同滤波算子提取纹理图片。对色度分量使用了Scharr滤波算子,亮度分量则使用了Laplacian滤波算子,生成出3个分量纹理图片的灰度共生矩阵后通过矩阵拼接完成特征融合,最后连接EfficientNet进行篡改检测。这种利用多色域特征融合的异常纹理检测算法具有比单一特征算法更好的准确度与泛用性,在CAISA2.0数据集的准确率为98.03%,在Realistic Tampering Dataset 2.0高清人工篡改数据集的准确率为90.43%。
2.5 JPEG重压缩特征检测算法
基于JPEG压缩的篡改区域检测方法常用在非同源拼接篡改检测中,这种方法具有方便定位篡改区域的特性。JPEG压缩是一种基于像素区块的有损压缩算法,算法中的核心是离散余弦变换DCT(Discrete Cosine Transform)算法,1974年由Ahmed和Rao提出,它是一种图像二维离散变换,可以看成傅里叶变换的一种变体。其常见用途是对音视频进行压缩,DCT算法是JPEG、H.26X等多种音视频编码的核心[53]。
数字图像本身也可以看成是一个二维的信号,像素点灰度值的大小代表亮度信号的强弱。高频区域就是图像中灰度变化剧烈的点,一般是图像轮廓、物体边缘或噪点;低频区域是图像中灰度变化平缓的区域,图像中的大部分区域都属于低频。DCT算法就是计算出图像由哪些二维余弦波构成,得出一个与输入图像同样大小的矩阵。经过对浮点数的量化(Quantization)后舍弃高频信息,保留低频信息[54]。DCT变换常用8×8像素作为区块大小,在一个经过了DCT变换的8×8频域能量分布矩阵中,64个点所对应的数字组成了DCT系数矩阵,矩阵低频信息集中在左上角,高频信息则在右下角。
JPEG压缩算法的流程如图9所示,先把一张图片的色彩空间转换到YCbCr中再进行DCT变换,每一个8×8的图像块都变成了3个8×8的浮点数矩阵,经历了这两个步骤的图片信息仍处于可逆的状态。JPEG有损压缩的原因是量化处理,量化的目的是牺牲浮点数精度换来更小的存储体积,其操作方法是把浮点数除以一个量化系数再取整。JPEG压缩的量化操作信息损失量由量化系数矩阵(Quantization matrices)控制,量化系数矩阵的大小对应DCT系数矩阵,不同的量化系数矩阵也对应不同的压缩率。

图9 JPEG压缩算法流程
JPEG重压缩特征所提取的就是图像多次经过不同量化系数矩阵处理后所留下的差异,经过单次JPEG压缩后的图片,其DCT系数的直方图近似服从高斯分布,经历过JPEG二重压缩的图片会在由DCT系数矩阵得到的直方图中留下周期性的波峰和波谷。文献[55]中Lukáš和Fridrich提出了一种估测第一量化系数矩阵(Primary Quantization Matrix)的方法。文献[56]中,Niu等人提出一种CNN结构为基础的量化系数矩阵估计算法,从而更准确地检测图片是否经过重压缩处理。
原始图像与篡改区通常会经历不同的JPEG压缩次数,每次压缩时的压缩系数也不同,从而携带不同的重压缩特征。文献[57]中Lin等人提出了构建DCT AC系数与SVM结合的算法来判断区块是否为篡改区域,并提出图片经过重压缩后在DCT AC系数直方图会出现双峰的统计特性。实现了JPEG重压缩特征的篡改检测。在文献[58]中则直接把每个区块的DCT系数矩阵中Y分量的AC系数变为一维向量送入人工神经网络中进行训练并输出结果,从而判断各个区块的JPEG压缩特征,实现了非同源拼接图片的篡改区域定位,图10展示了该算法的检测效果。

图10 文献[58]中展示的JPEG重压缩检测效果
2.6 深度伪造篡改检测算法
数字图像篡改检测与深度伪造生成图片检测是当前热门研究方向,现阶段的检测算法主要集中于机器学习领域。图像篡改被动篡改检测主要经历了人工测量、算法检测、深度学习3个发展阶段。而深度伪造技术诞生时间不久,深度伪造检测技术从一开始就大量运用了深度学习技术。同时,用于深度伪造图片检测的特征与图像篡改检测所提取的特征大多是同一类特征或有密切联系,有些算法会有明显的思路继承。
深度伪造技术的发展和深度学习有密切联系,在图像内容生成层面使用的深度学习技术主要有生成对抗网络(Generative Adversarial Networks,GAN)[59]、卷积神经网络(Convolutional Neural Network,CNN)[60]、循环神经网络(Recurrent Neural Network,RNN)[61]等,这3类网络结构在生成深度伪造内容上都需要数据集构建和模型训练两个步骤。深度伪造内容的检测方法也同样依赖于深度学习,检测思路是使用深度伪造数据集与真实内容数据集训练模型,实现特征的提取并进行分类。在深度伪造内容检测中所使用的方法主要可分为3大类:基于传统图像篡改取证方法、基于GAN图像特征方法和基于生理信号特征方法。
使用传统图像篡改检测方法来检测深度伪造图片的思路与上文所描述的比较相近,除了上文提到的利用异常纹理检测的方法外,还有许多可供检测的特征与专门设计的检测算法。RAO[62]等人通过固定第一层卷积层中卷积核的权重权值,提SRM中的残差映射来完成换脸篡改识别。Nataraj等人[63]使用提取灰度共生矩阵的思路,直接将RGB三通道的灰度图片特转换为灰度共生矩阵,最后送入神经网络中进行篡改检测。Zhou等人设计了一种双流网络[64],其中一条为基于GoogLeNet结构的人脸分类网络,另一条为背景噪声提取网络,用人脸分类网络框定人脸位置减少背景影响,再使用背景噪声判断人脸是否被篡改。Li等人[65]提出Deepfake算法所生成的假脸和原图像有分辨率不匹配的问题,故通过构建经过高斯模糊、旋转缩放的样本数据集引导神经网络学习此类特征,进而进行真假判别。
深度伪造算法的生成过程中也改变了图像的像素和色度空间统计特征,有研究指出这类特征可以通过共生矩阵等方法提取到并用于深度伪造检测,文献[66]中提出了一种基于深度伪造生成图片在光谱波段之间的不一致性的检测方法,文中作者提出GAN生成的图像在RGB三通道中的灰度图像中会存在不一致性,除了利用每个色彩通道的灰度共生矩阵提取特征外,还可以跨通道地进行共生矩阵的计算来进一步突出光谱不一致性。在算法中增加RG、GB、RB的灰度共生矩阵输入可以提高深度伪造篡改检测准确率。文献[67]提出深度伪造生成图片与真实图片在色度分量上有更明显的区别,则通过高通滤波抑制图像内容,再提取残差进行检测,该算法的结构如图19所示。不同的GAN生成器所生成的图片具有不同的特征,研究人员将其称为“GAN的指纹”,文献[68]和[69]利用这类特征,可以通过生成出来的图片反推其使用的GAN类型。
对于深度伪造换脸视频,人脸的生理信号特征也可被用于检测中,Amerini等人提出了光流场+CNN来捕捉面部五官运动信息的鉴别方法[70],Guera等人提出了LSTM+CNN的算法框架[71]。韩语晨等人使用Inception3D卷积提取口部与眼部特征运动信息进行深度伪造视频的检测[72]。此类算法大多基于动态视频,对静态图像的检测能力有限。
3 总结与展望
3.1 建立高品质的篡改图片数据集
与在实战条件下面对的篡改图像相比,目前数字图像篡改检测算法所用的训练与测试数据集表现出了篡改痕迹明显、分辨率较低、篡改区域偏大等特点,有算法在某个数据集有较好的检测准确度,但如果用自己制作的篡改图片去检验则会发现算法几乎失效。建立一个覆盖多种分辨率的高品质篡改图像数据集是很有必要的,一方面可以引导篡改检测算法向着更贴近实际情况的情景中学习检测方向,另一方面也可以让各类篡改检测算法有统一的性能衡量指标。
在深度伪造视频检测领域,有几乎通用的Face-Forensics++和DeepfakeTIMIT等视频数据集,也有Deepfake Detection Challenge等大型比赛,各类算法也会列出在大型数据集上的检测效果,能得出较为直观且通用的评价。在深度伪造生成图片篡改检测领域,有FFHQ这种超大型真实人脸数据集和由PGGAN、StyleGAN、BigGAN等深度伪造算法生成的假脸图片数据集。但在数字图像人工篡改检测领域则缺乏相同量级的数据集,许多数据集在图片数量上仅为百余张的水平,CAISA2.0等较大型数据集的质量则偏低,自动生成的篡改图片数据集无法反映实际篡改情况。目前学界需要一种贴合现实场景、区分开不同篡改手段,包含人工篡改图像与深度伪造篡改图像,覆盖多种不同分辨率的篡改图像数据集。
3.2 着力应对深度伪造篡改技术的挑战
深度伪造篡改技术影响深远,目前应用最广的是“换脸”操作,由这种技术篡改出的图像非常逼真,篡改痕迹隐蔽。篡改技术的进步给篡改检测算法提出了更高要求,对于传统篡改痕迹要有更有效的提取方式的同时也要有效提取深度伪造生成区域的特征。深度伪造算法可以生成一张现实中不存在的人像图片,在换脸的场景下其边缘仍需模糊锐化等重采样处理,会留下与人工篡改相近的特征模式。但深度伪造算法的生成器还可以生成出一张完全虚构的伪造图片,这类图片是整体生成,不具有SIFT特征或JPEG重压缩特征,其他传统篡改检测算法对其是否有效也有待检验。这就要求图像篡改检测算法最好能在有效完成传统篡改检测的基础上,具有对深度伪造生成内容的检测能力。目前来看,文献[50]与文献[52]所使用的基于异常纹理的篡改算法可以有效完成对深度伪造生成人脸图像的检测,更完善、高效的检测技术方法还有待进一步研究。
3.3 探究更有效的特征提取与融合方式
在目标识别领域,以YCbCr色域进行纹理信息增强已成为新的研究方向,这种从RGB转换到YCbCr色域的思路已应用于图像数字水印[73]、手势识别[74]、肤色分割[75]等领域。Cb、Cr色度分量比Y亮度分量对拼接引入的异常边缘信息更加敏感,在对数字图像进行篡改的过程中,即使图像在RGB色域看起来很自然,也会在色度通道中留下一些不自然的线索。而大多数拼接检测方法只使用图像在RGB色域的亮度分量,色度分量是被去除掉的。Wang提出图像色度对于彩色图像拼接检测非常有效[76]。这指引我们需要跳出单一的RGB色彩空间,从其他色彩空间中寻找更多的篡改痕迹。
多特征融合也是数字图像篡改检测的研究热点,图像篡改检测关注的并不是一张图片的表层信息,而是人眼难以发现的像素分布规律,按照原本图像分类和目标检测的思路去设计神经网络,会导致算法的注意力过分集中在大量图像表层无用信息中。这些隐含规律的成因与来源各不相同,仅凭训练卷积神经网络难以做到准确提取,还需要通过许多不同的特征提取算法来做到针对性提取。如双流Faster R-CNN网络构型[49]、双流FCN网络构型[77]、三相流Faster R-CNN结构[78],均采用了不同特征的融合来提高算法性能。文献众多研究成果也证明:直接输入RGB图像或仅靠调整卷积核构型的篡改检测网络性能已被多特征融合构型拉开较大差距,应加强特征融合方式和网络结构的创新,探索泛用性更好的篡改特征提取方法。
