面向自动驾驶汽车的三枝路口典型危险场景构建方法
2022-12-09胡越宁牛学军
胡越宁, 赵 丹, 牛学军
(中国人民公安大学交通管理学院,北京 100038)
0 引言
自动驾驶汽车测试主要采用基于场景的测试方法,即通过预先设定的场景,要求被测车辆完成某项特定目标或任务而对其进行测试的方法。相比于里程测试,测试场景的筛选缩减了里程测试过程中大量的“无风险”里程,测试效率高且更有针对性[1]。因此,构建自动驾驶汽车的城市道路平面交叉口测试场景十分重要。平面交叉口包括三枝路口和四枝路口,虽然三枝路口相较于四枝路口冲突点少,但事故发生量并不少[2],因此自动驾驶汽车在三枝路口的安全性能值得研究。
目前,不少学者关于交叉口危险场景的研究集中在四枝路口(主要为十字路口)[3-6]。考虑到四枝路口与三枝路口在运行规则、控制方式、设施设计上存在较大差异,一些研究也开始考虑三枝路口危险场景。Nitsche等[7]基于OTS数据库中1 056起事故案例,采用K-Medoids聚类算法提取出13类三枝路口和6类四枝路口预碰撞场景。徐向阳等[8]基于NAIS数据库中499起事故案例,采用层次聚类算法得到7类四枝路口和1类三枝路口场景。廖静倩等[9]基于NAIS数据库中277起事故案例,采用层次聚类算法得到4类三枝路口危险场景。
综上,国内外关于三枝路口事故场景的研究还比较少,且由于道路交通事故数据来源于传统车辆,因此,大部分学者的研究主要面向辅助驾驶测试[3-6,8-9],测试辅助驾驶系统在面对传统车辆驾驶人的危险场景下是否可以缓解事故伤害甚至避免事故。也有学者的研究面向自动驾驶测试[7],但事故案例中往往包含大量人类驾驶人的违法行为,这些违法行为在自动驾驶汽车运行过程中根本不会出现。因此,为了提高自动驾驶汽车三枝路口测试场景覆盖率和测试效率,本文基于实际道路交通事故数据,依据自动驾驶汽车特点筛选得到碰撞事故案例,提取典型场景要素,旨在得到面向自动驾驶汽车的三枝路口典型危险场景,从而为扩充我国自动驾驶汽车测试场景库提供参考。
1 数据来源与筛选
本文选择国内自动驾驶产业发展较为迅速的地区作为研究对象,选择北京市和宁波市作为典型城市。北京市地处华北平原,常住人口2 189万,机动车保有量685万;宁波市地处东南沿海,常住人口954万,机动车保有量300万。两市的道路交通事故数据完备,能够代表两类地区的交通环境和事故特征。收集两市近3年的道路交通事故数据,共计12 454起,包括70个描述交通事故信息的字段可作为场景要素。本文研究的路口类型选定为三枝路口,事故车辆类型选定为乘用车或商用车。考虑到路口事故的多样性,车辆运动状态仅考虑直行、左转弯和右转弯。此外,还需满足以下3个筛选条件:
(1)剔除数据缺失或者不明的事故案例;
(2)剔除由于路段常见违法行为引发的事故案例(如切入、倒车、追尾等);
(3)剔除存在违反通行规定的违法行为的事故案例(如逆向行驶、不按规定车道行驶等)。
Aydin等[10]认为使用传统道路交通事故数据时,通过剔除人为因素,可以生成更符合自动驾驶汽车的事故场景。本文认为相对于传统车辆驾驶人,自动驾驶汽车具备3个特点:①具备良好的驾驶技能;②不会丧失或部分丧失驾驶能力;③不会主动违反交通规则。表1列出各特点对应的传统车辆驾驶人违法行为。选定的事故为双方事故,若其中一方无以上违法行为,且为乘用车或商用车,则被视为自动驾驶测试车辆,另一方归为交通参与者。

表1 传统车辆驾驶人违法行为
按照上述条件,最终筛选得到378例碰撞事故案例。其中180例发生在公路,138例发生在城市道路,60例发生在其他道路。
筛选案例可以确保测试车辆驾驶人是理性的,但是由于交通参与者存在各种各样的违法行为,即便驾驶人或多或少地做出了应对措施,事故仍不可避免地发生了。因此有必要了解目前驾驶人需要应对的危险情况,因为这些情况同样可能发生在自动驾驶汽车上[7]。
2 数据处理方法
2.1 聚类分析方法
聚类分析的核心思想是将个体或对象分类,使得同一类的对象之间的相似性比与其他类对象的相似性更强。其目的在于使类内对象的同质化最大化和类与类间对象的异质化最大化。层次聚类法(hierarchical clustering method)是聚类分析诸多方法中使用最多的,该算法可以有效避免靠经验或专业知识对分类的影响,且可复用性较高[11]。
2.1.1 算法步骤
首先,将个样本看成n类(一类包含一个样本),然后将性质最接近的两类合并成一个新类,得到n-1类,再从中找出最接近的两类加以合并,变成n-2类,如此下去,最后所有的样本均在一类,将上述并类过程画成一张图(称为聚类图)便可决定分类数,每类各有哪些样本。
2.1.2 样本距离
聚类分析中,常用距离来度量样本之间的接近程度。本文采用欧式距离计算样本之间的距离,第i个样本和第j个样本之间的距离为:
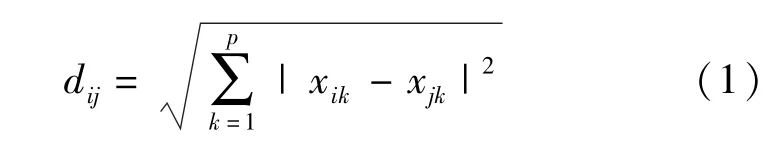
式中:p为样本中含有的变量个数;xik为第i个样本中第j个变量的度量值。
2.1.3 类间距离
离差平方和法(Ward法)是先让n个样本各自成一类,然后每次缩小一类,每缩小一类,离差平方和就要增大,选择使其增加最小的两类合并,直到所有的样本归为一类为止。
类Gp中的样本的离差平方和为:
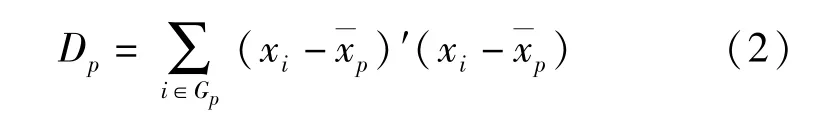
式中:xi为类Gp中的第i个样本,为类Gp的重心。
类Gp和Gq之间的距离平方为:

式中:Dp+q为类Gp与类Gq合并后的新类Gp+q的离差平方和;Dp为类Gp的离差平方和。
2.2 卡方检验
卡方检验(chi-square test)是应用较广的一种假设检验方法,属于非参数检验的一种,目的是通过样本数据的分布来检验总体分布与期望分布是否一致。卡方检验的公式可表示为:
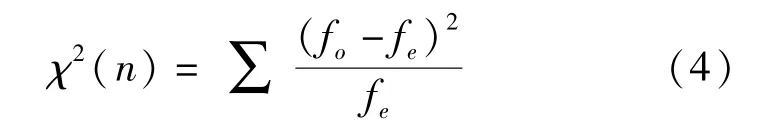
式中:fo表示实际频数,fe代表期望频数,n为卡方检验的自由度。
本文将利用聚类分析和卡方检验挖掘事故的特点,提取典型参数特征。
3 典型危险场景构建与分析
3.1 聚类参数选取
如前所述,描述每起交通事故信息的场景要素多达70个,因此在聚类分析前应对各场景要素进行筛选。筛选原则有3条:一是因测试车辆与交通参与者的类型、运动状态和碰撞角度的组合可以还原碰撞事故场景,将其视为必须保留的场景要素;二是剔除无法对自动驾驶汽车的环境感知或控制执行造成影响的场景要素;三是剔除差异性不明显的场景要素。文献[12]指出,数据中场景要素的某一特征占样本总数的75%以上,差异性将不明显,不能将所有初步选定的场景要素全部用于聚类分析,如图1所示的路表、通行和天气情况。

图1 未选定场景要素的特征分布
综上所述,共选取8个典型场景要素作为聚类参数:照明条件、交通控制方式、道路物理隔离、测试车辆类型、交通参与者类型、测试车辆运动状态、交通参与者运动状态和碰撞角度。
3.2 典型危险场景提取
3.2.1 聚类结果
对378例碰撞事故案例进行聚类分析,得到10类聚类结果。接着对聚类结果进行卡方检验,取置信度为90%,将计算的卡方值与卡方对照表对应的临界值进行比较,若卡方值大于临界值,则说明该参数具有典型参数特征,将依据各参数特征在每一类中所占比例和各参数特征在总体中所占比例,得到每一类的典型参数特征,表2将卡方值大于临界值的数字加粗,将得到的典型参数特征用“*”标出。反之,则说明该参数的各个特征在该类中分布差异性不明显,该参数没有典型参数特征。
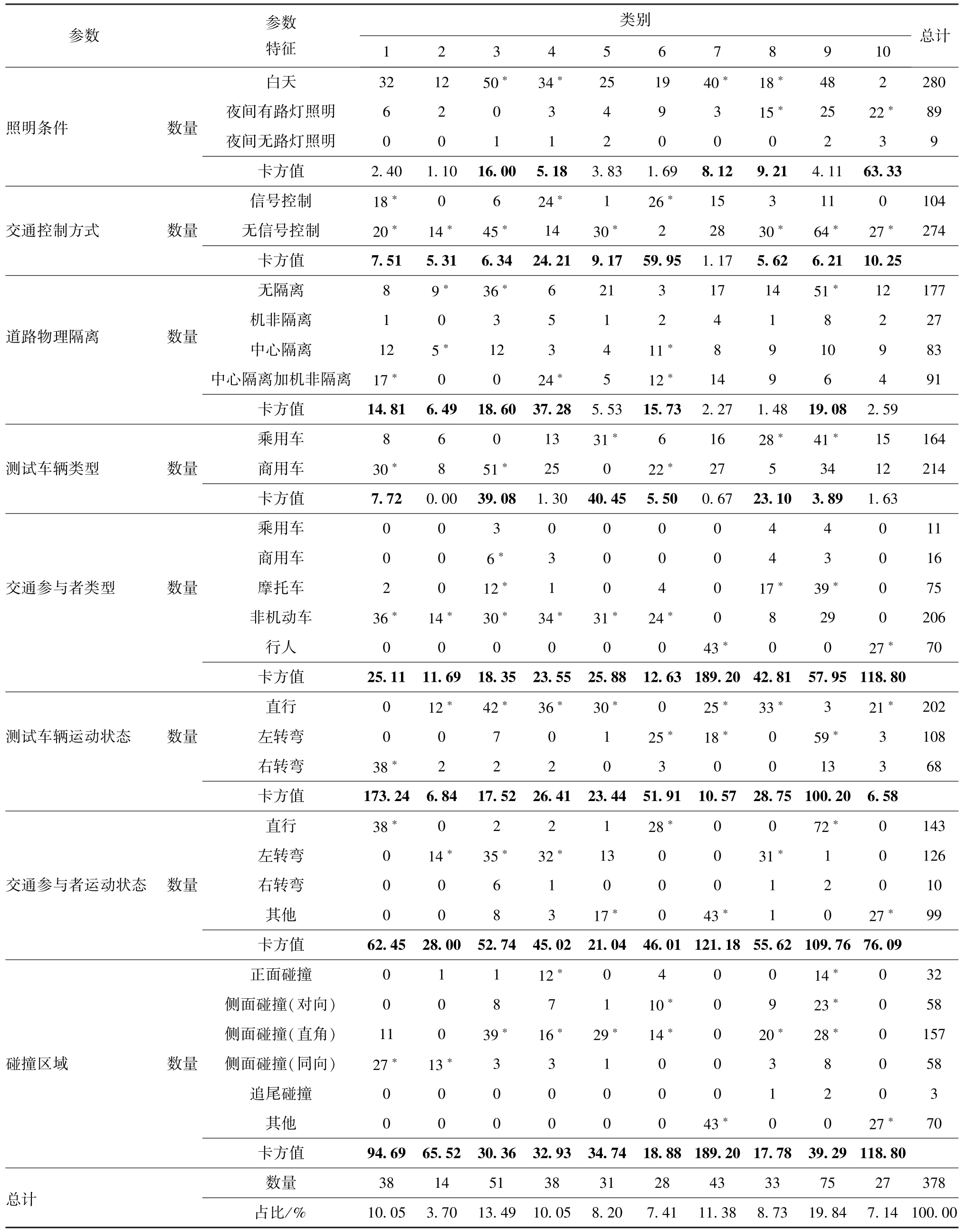
表2 三枝路口典型危险场景聚类结果
当卡方值大于临界值时,以第1类聚类结果为例对典型参数特征的选取原则进行解释:
(1)测试车辆类型的参数特征“商用车”包括30个样本,故在第1类中所占比例为78.9%,大于“乘用车”的21.1%,在总体中所占比例为14.0%,大于“乘用车”的4.9%,故“商用车”的参数特征非常显著,属于第1类的典型参数特征;
(2)交通控制方式的参数特征,包括“信号控制”和“无信号控制”,虽然“无信号控制”在第1类中所占比例为47.4%,小于“信号控制”的52.8%,但是“无信号控制”在总体中所占比例为17.3%,大于“信号控制”的7.3%,故两个参数特征共同作为第1类的典型参数特征。
当卡方值小于临界值时,也就是某一类中某个参数的各个参数特征均不具有显著的统计学特性,说明在提取典型危险场景时需要考虑所有的参数特征。另外,考虑到典型危险场景设计的合理性,当某参数特征在某一类中所占比例过小时,需要在选取参数特征时设定阈值[9],本文取10%,即选定为典型参数特征后,该参数特征在某一类中所占比例应大于10%,如第5类中照明条件中的参数特征“夜间无路灯照明”在总体中所占比例为11.1%,大于“白天”的8.9%和“夜间有路灯照明”的4.5%,故可以归为典型参数特征,但是“夜间无路灯照明”在第5类中所占比例为6.5%,小于10%,故不选取为典型参数特征。
3.2.2 基于事故类型进一步提取典型参数特征
为了对未区分出来的典型参数特征做进一步的提取,使每一个参数只有唯一的典型参数特征(如第1类中的“交通控制方式”两个参数特征共同作为第1类的典型参数特征),本文根据三枝路口碰撞事故案例中的场景要素“事故类型”对聚类分析得到的10类聚类结果作进一步的分析。事故类型分为财产损失事故、伤人事故、死亡事故,按照各种事故类型的占比乘以权重得到危险程度,权重分别取为0.6、0.3、0.1,最终选取危险程度最大的参数特征作为唯一的典型参数特征,危险程度的计算公式可以表示为:
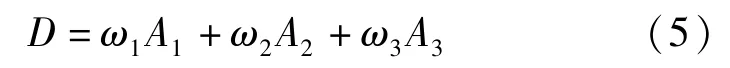
式中:D表示危险程度,ω1、ω2、ω3分别表示财产损失事故、伤人事故、死亡事故的权重,A1、A2、A3分别表示为财产损失事故、伤人事故、死亡事故在总事故中的占比。
如确定第3类中的交通参与者类型,交通参与者类型中的参数特征“商用车”“摩托车”和“非机动车”在聚类分析时均被归为典型参数特征,但通过事故类型分析可知“摩托车”的危险程度最高,故最终选定“摩托车”作为第3类的典型参数特征,如表3所示。

表3 交通参与者类型确定
3.3 典型危险场景分析
经过提取的典型参数特征,最终得到10类典型危险场景,如表4所示。

表4 三枝路口典型危险场景
10类三枝路口典型危险场景可描述为:第1类场景为白天,右转的商用车与直行的非机动车发生同向侧面碰撞,事故发生地点无信号控制,附近有中心隔离和机非隔离设施。第2类场景为白天,直行商用车与左转非机动车发生同向侧面碰撞,事故发生地点无信号控制,附近无隔离设施。第3类场景为白天,直行的商用车与左转的摩托车发生直角侧面碰撞,事故发生地点无信号控制,附近无隔离设施。第4类场景为白天,直行的商用车与左转的非机动车发生直角侧面碰撞,事故发生地点为信号控制,附近有中心隔离和机非隔离设施。第5类场景为白天,直行的乘用车与通过人行横道的非机动车发生直角侧面碰撞,事故发生地点无信号控制,附近有中心隔离设施。第6类场景为白天,左转的商用车与直行的非机动车发生直角侧面碰撞,事故发生地点为信号控制,附近有中心隔离和机非隔离设施。第7类场景为白天,直行的商用车与通过人行横道的行人发生碰撞,事故发生地点无信号控制,附近有中心隔离和机非隔离设施。第8类场景为白天,直行的乘用车与左转的摩托车发生直角侧面碰撞,事故发生地点无信号控制,附近无隔离设施。第9类场景为白天,左转的乘用车与直行的摩托车发生对向侧面碰撞,事故发生地点无信号控制,附近无隔离设施。第10类场景为夜间,直行的乘用车与通过人行横道的行人发生碰撞,事故发生地点无信号控制,附近有路灯、中心隔离和机非隔离设施。
上述10类三枝路口典型危险场景,可根据其涉及的要素特征进一步归类:①从照明条件角度而言,第10类涉及夜间有路灯照明的场景;②从交通参与者角度而言,第1、2、4、5、6类为非机动车参与场景,其中第1、2、4、6类为商用车和非机动车工况,占样本总数的31%,另外,第3、8、9类为摩托车参与场景,第7和10类为行人参与场景;③从运动状态角度而言,第1类场景为直行与右转弯冲突,第2、3、4、6、8、9类为直行与左转弯冲突,占样本总数的63%,第5、7、10类为非机动车、行人通过人行横道时的场景。
4 结论
本文筛选得到378例碰撞事故案例,根据案例中的场景要素分析确定聚类参数,通过聚类分析、卡方检验和事故类型分析,提取典型参数特征,最终得到10类三枝路口典型危险场景。
(1)筛选得到的碰撞事故案例可以了解目前测试车辆驾驶人需要应对的危险情况,这对于研究自动驾驶汽车需要面对的危险情况具有一定的参考价值。
(2)通过聚类分析和卡方检验提取典型参数特征,并基于事故类型进一步提取典型参数特征,得到10类符合中国交通实际的三枝路口典型危险场景,其各具有代表性和典型性。其中,商用车和非机动车工况场景,以及直行与左转弯的冲突是需要重点关注的三枝路口典型危险场景。
本文只收集了两个城市的道路交通事故数据,并不能完全代表国内实际,未来可以收集更多典型城市的事故数据。事故案例中没有详细的事故发生过程信息,无法了解双方在发生碰撞前的具体运动状态(如减速、转向等),从而无法构建较为完备的场景,未来将寻找内容更丰富的深度事故数据开展研究。
