基于Kubernetes的医疗领域机器学习节点部署优化
2022-12-08广州医科大学附属第五医院信息科广东高校生物靶向诊治与康复重点实验室李斌高振宇
文 | 广州医科大学附属第五医院信息科,广东高校生物靶向诊治与康复重点实验室 李斌 高振宇
随着大数据应用的普及以及深度学习的快速发展,深度神经网络模型依靠海量数据的学习和极深的网络深度,在很多领域取得了不亚于人类的结果。而在医疗行业中,模型计算的准确率是其能否应用到临床的一个非常重要的指标。当前很多深度神经网络模型为了提高计算精确度,其模型的大小正在变得越来越大,从几十GB到上百GB不等。这些大模型相对小模型具有更高的准确度,但是在部署,特别是在分布式的环境下,常常遇到难以升级迭代的问题。
一、问题分析
容器技术目前已经相当成熟,相比传统虚拟化技术构建的虚拟机,容器的性能和部署便捷性要远远优于虚拟机。特别是在需要异构计算的人工智能领域中,为了能更好利用GPU的性能来进行模型训练和推理,采用容器方案可以更好地适配训练和推理中对性能和扩展性的需求。Kubernetes目前已经成为了私有云容器集群编排管理的事实标准,通过Kubernetes可以非常便捷管理容器的整个生命周期。但是目前Kubernetes对于深度学习的场景支持还是不充分的,Kubernetes的架构对于stateless容器和使用共享存储的state-ful场景有比较好的支持,但是对于深度学习节点,因其所依赖的数据十分庞大,而且对性能的苛刻要求,所以共享存储的性能是不能满足实际生产环境要求的。另一方面,Kubernetes对于容器使用本地持久化存储的支持有限,它难以管理容器的依赖数据的生命周期。在实际生产环境中,医学方面的模型往往是非常大的,例如一个多模态的从DR图片生成检查报告的模型的大小往往在十几GB,其训练过程中所需要的数据会达到数TB。由于Kubernetes的特殊机制,Pod的描述信息一旦发生变化就必须重建。所以这种深度神经网络模型容器哪怕只是更新了一个简单的配置也会引发容器销毁,新建的容器需要耗费大量的时间把依赖数据通过网络拉取到本地,最后造成新启动的容器往往迟迟不能提供服务,时间成本较高。
二、现有方法
为了降低时间成本,尽快让销毁重建的容器重新提供服务,常见的解决方案是添加更多的硬件资源或者采用并行拉取的方式来提升网络拉取数据速度,这需要投入更多的设备用于提高整个网络的数据链路传输性能。另一种方案是限定Pod(Kubernetes 中创建和管理的、最小的可部署的计算单元)的调度范围,使Pod只能调度到指定的一批Kubernetes工作节点上,提高Pod调度回原来节点或者相似节点的概率,以减少拉取数据的工作,这种方法利用了Kubernetes的自身的调度策略,需要人工筛选特定机器后再去进行绑定。但是即使利用该方式也难以保证Pod可以调度到理想的节点上。
(一)建立多个数据服务集群
一个容器的模型或其依赖的数据量如果很大,一般会选择将其存储在一个方便远程拉取的集群中,常见的方式是将容器依赖的数据上传到HDFS(Hadoop Distributed File System)集群上,由HDFS集群充当数据服务集群,Pod启动后其sidecar容器从数据服务集群将所依赖的数据拉取下来。但是在多IDC机房环境中,单一数据服务集群的网络速率往往在跨IDC的数据传输中变得很慢。建立多数据服务集群可以有效解决这个问题,不同的IDC的数据服务集群利用IDC之间的网络同步数据,Pod的sidecar从所属IDC的数据服务集群拉取数据,避免出现跨IDC交互。该方案的缺点是需要投入大量的服务器和网络改造成本在每个IDC机房建立同质化的数据服务集群。
(二)限定容器部署
Kubernetes的默认scheduler可以支持通过设定tag亲和性来调度Pod到特定节点上,该方法通过人工在特定的Kubernetes工作节点打上特定的tag,随后创建Pod的时候指定Pod只能调度到打了特定的tag的Kubernetes工作节点,以此来进行Pod和机器的绑定。这些打上了tag的工作节点要提前建立好本地持久化存储,并下载好依赖的数据。这种方式需要大量人工介入,难以扩容和缩容符合亲和性的机器。除此之外,这种方式不能很好的管理依赖数据在本地存储的生命周期,可能会出现节点存储剩余空间不足导致容器被驱逐的情况。
三、优化
目前Kubernetes默认调度机制没有考虑拉取容器依赖所产生的影响,默认的调度策略会优先将Pod调度到计算资源较充足的节点。而计算资源较充足的节点往往是新加入集群的节点,新节点是没有在本地缓存任何依赖数据的,它需要从远端通过网络拉取大量依赖数据。虽然Pod的原节点已经有了大部分依赖数据,但是由于调度策略的影响,重建的Pod往往不能被调度回原节点。所以为了能解决Pod中的业务容器长期等待依赖数据问题,本文提出通过改造Kubernetes的调度器来将依赖数据缺失部分、本地存储、网络实时状况等因素纳入定制化的调度器考虑范围中,当出现Pod需要调度时候,如图1流程,定制化调度器会实时计算出所有符合部署的节点的得分情况,优先调度Pod到能快速完成数据依赖加载的节点上。此外,Pod启动后的sidecar容器可以支持使用P2P的方式来从别的节点拉取依赖数据,进一步降低业务容器数据加载时间。

图1 定制调度策略调度Pod流程
(一)定制调度策略
定制化调度器策略包含2个部分,分别是Agent和custom-scheduler(cu-sch)。Agent以Daemonset的方式部署在每个Kubernetes工作节点上。custom-scheduler作为定制化调度器用于接收Agent上报数据和处理Pod的调度等事务。
Agent负责实时获取当前节点中如表1中所列的节点缓存数据、镜像列表、网络环境等信息并上报给Kubernetes的定制化调度器cu-sch。cu-sch收集到节点上报的信息后可以计算出Pod从调度完成到可以正常服务所需消耗的时间,这个时间将作为重要参考因素用于计算各个节点部署该Pod的优先级分数。通过该流程,cu-sch可以大概率把容器优先放置在已经存在镜像和依赖数据的节点上,以避免重复从远端拉取数据,或是调度Pod到网络条件好的节点上,以最大程度节省拉取数据的时间。此外,Agent还负责管理节点上已经拉取的依赖数据的生命周期,会采用LRU方式将长期不使用的数据清理掉。
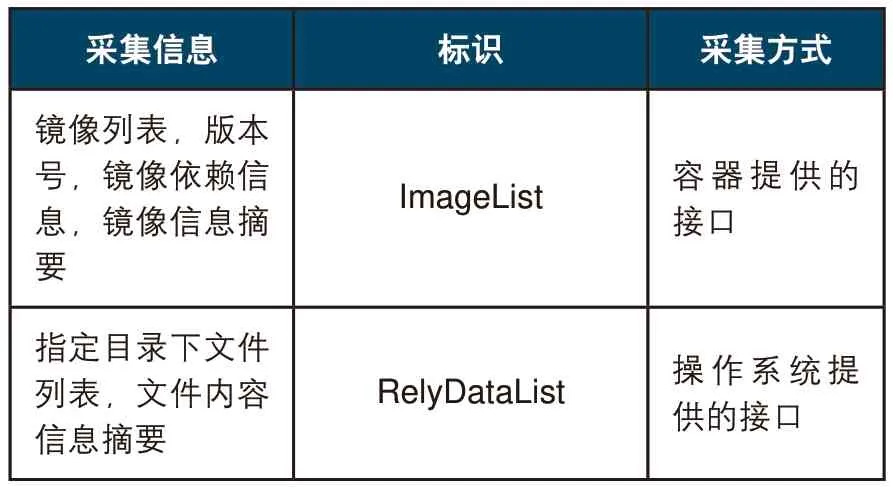
表1 Agent所需采集上报信息

存储依赖数据的磁盘剩余空间 RemainDataRoom 操作系统提供的接口拉取镜像的传输速率 PullImageRate拉取远端测试镜像计算拉取效率拉取依赖数据的传输速率 PullRelyDataRate拉取远端测试数据计算拉取效率存储镜像数据的磁盘剩余空间 RemainImageRoom 操作系统提供的接口
Kubernetes 的custom-scheduler是Kubernetes控制平面的核心组件之一。其主要功能是将Pod分配给节点,同时平衡各节点的资源利用率。custom-scheduler具有Kubernetes所有的默认调度策略,而且该调度器会将镜像,依赖的存储等信息考虑进去,进行过滤和打分。如图2所示,Agent轮询检测节点上已经缓存的依赖数据,镜像数据。由于每个节点配置和所处网络环境是不一致的,Agent会从数据服务集群中定时拉取测试文件,用于检测节点和数据服务集群之间的网络情况,用于后续customscheduler准确计算每个节点的得分。
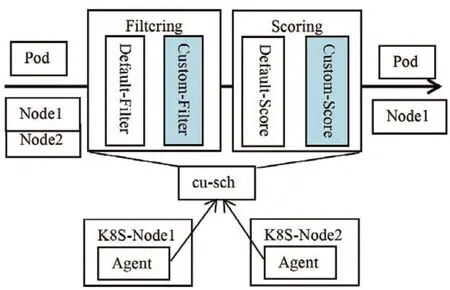
图2 定制调度架构示意图
Custom-scheduler具备访问镜像服务和依赖数据存储服务的能力,可以取得特定相关镜像和容器依赖的数据的metadata信息,metadata信息中包含镜像名字,版本,数字摘要,镜像层信息,容器依赖的数据名字,唯一标示号,大小,信息摘要等信息。随后和Agent已经提交的信息进行比对,可以知道缺少的镜像层和缺少的依赖数据。例如调度Pod时候,该Pod需要镜像M,其依赖的数据为集合{a,b,c}。镜像M实际上是由三层构成,为{X,Y,Z}。从Agent提交的数据中得知某节点已经存在了Y和Z层镜像以及依赖数据{a,b},计算出Pod部署到该节点只需要拉取{X,c},最后通过该节点Agent提供的PullImageRate和PullRelyDataRate可以计算出拉取依赖数据的预计时间。这个计算过程会对所有符合的节点进行计算以筛选出可以最快部署好Pod并提供服务的节点。
(二)P2P-sidecar
P2P-sidecar以sidecar的方式和业务容器一起部署和运行。P2P-sidecar基于BitTorrent协议实现,可以通过P2P的方式从多个不同的节点拉取所需的依赖数据和模型,同时其也支持S3协议和HDFS协议用于从数据服务集群拉取数据。P2P的引入在不增加数据服务集群的情况下可以很好地提升依赖数据拉取的效率,并且很好地缓解数据服务集群压力,减少网络拥塞情况。如图3所示,P2P-sidecar可以与同个IDC内的节点通信,分块获取所需要的数据。
四、实验
实验过程中使用了20台物理服务器,每个物理服务器都配置了万兆双网卡,每个物理服务器上虚拟5个虚拟机。实验针对custom-scheduler方案和P2P-sidecar进行了100Pod-150Pod规模的Deployment部署、Deployment扩容、Deployment升级、Deployment缩容再扩容等常见场景测试。实验中用于测试的虚拟模型大小为4GB,8GB,16GB,32GB这4种类型,Deployment会随机选择模型的组合用于测试。实验中设定Deployment的滚动升级中保证其80%的实例Pod是正常运行的。
整个测试进行了三次重复实验,实验结果如图4,其结果表明定制化的调度策略可以极大优化Pod变更后重新部署的耗时,另外,引入的P2P-sidecar可加速依赖数据和模型的下载,进一步降低时间成本。
实验的结果表明,Kubernetes的Deployment部署的Pod在使用了文本提出的定制化调度策略后,其在变更过程中可以大概率调度到已经有依赖数据的节点上,Kubelet可以快速拉起容器并恢复服务。对比原生Kubernetes的方式,因为减少了重复数据拉取过程,使得整个变更时间降低到原有的5%。另外,P2P-sidecar的引入可以优化节点第一次拉取依赖数据的时间,将初次部署的整体时间降低了25%。
五、结语

图4 Kubernetes Deployment多场景耗时测试
Kubernetes托管的容器在实际生产环境中会经常因为各种变更而导致重建,重建过程的耗时常常会影响业务的迭代效率。本文针对目前Kubernetes托管的医学领域机器学习容器的数据依赖过重导致变更时间成本较高的问题进行分析并提出了使用定制化调度的方式以及P2P-sidecar来进行优化,该方法降低了变更期间容器不能提供服务的时间。从实验结果可以看到该方法对于容器升级这类场景有较大的效率提升,可以很好满足容器频繁变更的需求。
