基于多关系结构图神经网络的代码漏洞检测*
2022-12-07潘禺涵舒远仲聂云峰
潘禺涵,舒远仲,洪 晟,罗 斌,聂云峰
(1.南昌航空大学 信息工程学院,江西 南昌 330000;2.北京航空航天大学 网络安全空间学院,北京 100191)
0 引言
软件漏洞是许多系统攻击[1]和数据泄露事件[2]的原因。在软件产品开发中,源代码静态分析技术[3]被广泛用于检测漏洞。传统的检测方法主要通过一些由人类专家定义的度量标准所实现。这些方法目前取得的成果非常有限,因为它们无法避免人类专家在特征提取方面的繁重工作[4],而且用手工制作的特征来覆盖所有漏洞是不切实际的。深度学习由于具有处理大量软件代码和漏洞数据的强大能力,被引入到代码漏洞检测领域。然而,现有基于深度学习的方法中不同形式的代码表示方式只能保留部分语法或语义信息,这样就不能覆盖到每种漏洞并会限制模型检测的效果。其次这些方法所使用的网络模型仍存在一些局限性:例如,卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)是基于序列的模型,不能处理代码的非序列特征,只能捕获源代码文本的浅表结构,无法利用程序结构丰富且定义良好的语义。
为了应对上述的问题,本文提出了一种基于多关系结构图神经网络的漏洞检测方法。采用多关系结构图进行代码的图形表示,获取全面的程序结构信息。然后结合双向图神经网络以及关系结构图注意力机制进行表示学习得到最终的代码图全局特征向量,并使用softmax分类器进行分类。
1 相关工作
深度学习中用于漏洞检测的模型大致分为两类:基于token的模型和基于图的模型。在基于token的模型中,代码被认为是token序列。例如,Li等人提出了一种基于双向长短期记忆网络(Bidirectional Long-Short-Term Memory,BiLSTM)的 模 型SySeVR[5]来表示漏洞相关的语法和语义信息,其中使用程序切片技术生成更小的代码段(即一些可能不连续但语义性和漏洞相关的语句),使其适用于深度学习网络。虽然SySeVR提高了深度学习模型在漏洞检测方面的性能,但它仍然存在问题:SySeVR采用序列神经网络(如Long Short Term Memory,LSTM)对代码段进行纯文本编码,可能会丢失代码段中语句之间复杂的结构信息和依赖关系,无法有效地学习代码的非序列特征。如图1所示代码,第2行代码与第10行代码虽然都在token序列中,但是由于相隔较远,它们之间的依赖关系已经丢失,这将会导致模型的高漏报率和高误报率。

图1 漏洞代码示例
在基于图的漏洞检测模型中,为了保留源代码复杂的结构和语义信息,并有效地学习这些源代码的非序列特征,Zhou等人[6]提出了一种基于门控图神经网络[7](Gated Graph Sequence Neural Networks,GGNN)的漏洞检测模型Devign,该模型首先将源代码的语法和依赖信息集成到一个组合图表示中,然后借助GGNN从组合图中提取与漏洞相关的特征。然而,这会限制模型的表示能力。这种方法是通过在抽象语法树(Abstract Syntax Tree,AST)上添加语义边缘来构建图的。然而,程序表示仍然高度依赖语法,语义相对不足。此外,来自语法、数据流和控制流等不同方面的信息常常混合在一起,形成一个单一的视图,使得很难单独提取关键信息。而在本文中,采取了多关系结构图的方法进行代码表示,该方法将基于不同的语义关系把源代码划分为5种图形结构,可以从多个方面和层次来表示源代码的结构信息,并且更加强调了语义信息。
2 图神经网络模型设计
本文的目标是设计一个用于自动化漏洞检测的网络模型,图2显示了模型的框架。它包括四个部分:第一部分,将代码转换为多个关系结构图,以保留程序代码中的语法和语义关系(例如,数据依赖和控制依赖);然后第二部分,使用word2vec模型[8]将图形节点编码成向量,作为网络模型的输入;第三部分,对双向图神经网络进行训练,得到每个关系结构图的向量表示;第四部分,通过关系结构图注意力机制获得程序代码的最终全局嵌入向量,接着使用softmax分类器分类获得最终结果:代码是否存在漏洞。

图2 模型框架图
2.1 代码的图形表示
(1)关系结构图划分
CVE-2019-190753是一种内存泄漏漏洞,ca8210_get_platform_data函数执行失败可能会导致pdata无法释放内存空间,这使得攻击者通过触发ca8210_get_platform_data函数报错来导致拒绝服务攻击。如图3所示,假如priv-?spi-?dev.platform_data=pdata;语句在if语句之前执行就不会产生危害性。这种类型的漏洞不能通过单一的组合图来进行检测,在该漏洞代码特征中既包含了控制依赖也有数据依赖以及操作数读写关系,需要结合不同类型的关系图对代码语义进行细致分析。现实情况下,这种类似的漏洞代码结构还有很多。所以为了捕获更加全面准确的语义信息,采用多关系结构图来表示程序代码,分别基于以下4种节点之间的边的类型来对源代码进行结构图划分:

图3 CVE-2019-19075代码片段
①Jump连接存在控制依赖关系变量节点的边;
②RwFrom连接含有交互的操作数的边;
③Dfuses连接存在数据依赖关系节点的边;
④Next按操作顺序连接AST上的叶节点的边。
具体来说,首先通过开源工具Joern对源代码进行解析生成代码属性图(CPG),如图4所示,然后基于语义关系将代码属性图转化分割为多个分离的有向关系结构图,接着将这些关系结构图与CPG同时作为最终的程序代码图形表示。
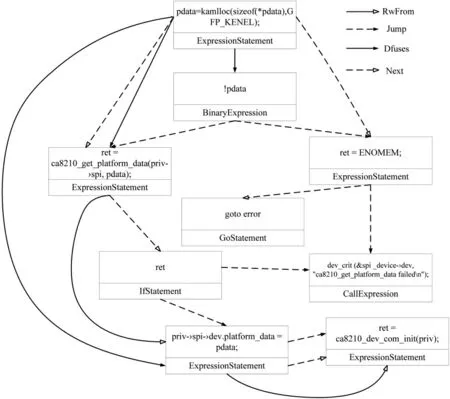
图4 代码属性图

算法1:关系结构图的分割输入:源代码P输出:CPG、GJump、GRwFrom、GDfuses、GNext Generate a CPG for P;for edge e in CPG do if e is Jump/RwFrom edge then Add node src(e),end(e)and edge e to GJump/GRwFrom end if else if e is Dfuses/Next edge then Add node src(e),end(e)and edge e to GDfuses/GNext end if end for
(2)双向边连接
由于源代码比自然语言更具逻辑性和结构性,含有漏洞的代码片段通常与其上下文相关。选择用于学习的神经网络模型应该能够处理向前和向后的序列,以获得更精细的表示,并实现更好的鲁棒性。本文通过添加后向边来构造一个双向图神经网络。通过转置邻接矩阵,对于一对连接边为ft的节点[u,v],可以同时考虑它的前向边[u,v]以及后向边[v,u]。因此,节点信息可以向前和向后传播,这有助于节点之间的信息传递。
2.2 构造图节点初始特征向量
为了生成代码的初始特征向量,使用Word2vec词向量模型[7]对关系结构图中每个节点的内容信息进行编码。首先对每个语句执行词法分析,并通过预先训练的word2vec模型创建词法标记向量。代码中的每个符号和word都会被映射到一个100维的词向量之中。其中经常出现在一起的单词会被映射到向量空间中接近的整数值,这样做可以捕获代码结构的大部分句法关系。例如,模型能够学习到if语句必须在else语句之前。为了进一步反映语料库中word之间的抽象语义关系,还需要考虑每个节点的类型信息。例如,与API函数调用相关的Call-Expression类型的语句节点可能包含漏洞相关的更多信息。对于节点类型信息使用one-hot编码,生成60维的类型特征向量。最后将内容特征向量与类型特征向量线性联结在一起,以获得节点的初始嵌入特征向量。
2.3 特征提取
(1)消息传递与邻域聚合
获得的初始节点特征向量只孤立的考虑了每个节点,缺少了整个图形结构的信息,因此使用GGNN通过消息传递和领域聚合机制来学习聚合信息生成全局图表示。首先通过消息传递机制来聚合节点v的邻域嵌入消息。然后,应用GRU[9]单元来聚合和更新关系结构图中节点的状态。模型使用前向传播来更新图顶点v的状态,以获得新状态,传 播公式如下:
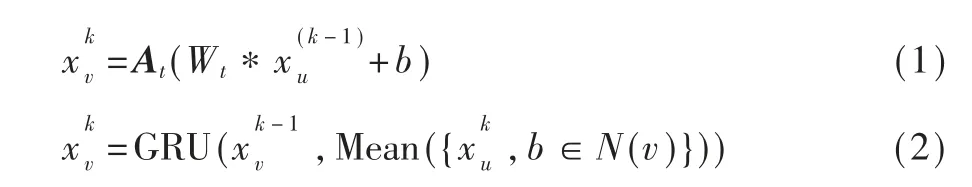
(2)关系结构图注意力机制
经过多轮消息传递与邻域聚合后,各个节点状态将包含足够多的结构图的信息,在获得最后一轮迭代生成的节点嵌入后,使用最大池化层对节点进行集成,以获得关系结构图的全局向量表示:

由于在代码结构里的不同特征的重要性因漏洞而异,例如,在与数组的使用相关漏洞中数据依赖可能比控制依赖更重要,因此在此引入注意力机制来生成最终的代码全局表示向量。这样可以关注关键的漏洞特征提高分类效率,计算公式如下:
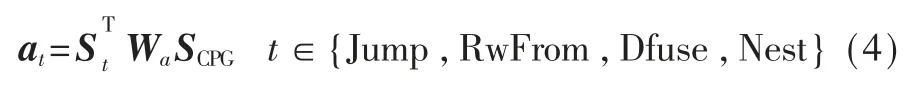
其中t表示与关系结构图相关的类型,at和分别代表注意力得分和对应关系图的特征向量,SCPG是组合图CPG的向量表示,Wa是要学习的权重矩阵。然后,通过softmax函数获得关系图的注意权重。最后,关系结构图特征向量通过加权求和进行线性组合,加权求和的计算如下:

其中Attentiont是对应关系结构图的注意力权重,SSG是关系结构图加权求和后的特征向量。

其中SEG是最终的图全局特征向量,⊕表示连接操作。
最后将最终的图全局特征向量SEG输入全连接神经网络通过softmax函数分类输出最终的预测结果,1为有漏洞,0为无漏洞。
综上所述,本文提出的方法如算法2所示。

算法2:本文方法输入:源代码P输出:代码的图嵌入表示Generate a CPG for P Construct GJump,GRwFrom,GDfuses,GNext based on CPG for Gi∈{GJump,GNext,GRwFrom,GDfuses,CPG}do for token in tokenized(v.code)do embeddings.append(word2vec(token))end for Dv=average(embeddings)for each node v in Vi do Tv=onehot(v.type)end for hv=concat(Tv,Dv)xu 0.append(hv)Iteratively update node state with Bi-GGNN for k steps(Eq.2);Compute the graph representation St as Eq.3;end for Obtain the program representation SEG as Eq.4-6;Feed SEG to downstream tasks
3 实验设计与结果分析
3.1 数据集
本文选用Lu等人提供的CodeXGLUE[10]的标准真实数据集进行漏洞检测实验。其中包括27 318个手动标记的漏洞样本集以及非漏洞样本集,这些样本是从两个大型且功能多样化的C、C++编程语言开源项目QEMU和FFmpeG中提取的。在非漏洞修复提交中提取修改前的源码函数作为非漏洞样本集,从漏洞修复提交中提取修改前的源码函数作为漏洞样本集,如表1所示。

表1 数据集信息
3.2 实验设置
现实情况下含有漏洞的程序代码往往在整个项目中占据非常小的比例,因此在真实代码数据集中存在着严重的类别不平衡现象。为了处理漏洞样本和非漏洞样本数量的不平衡,采用SMOTE[11](Synthetic Minority Oversampling Technique)算法对多数类进行子采样,同时对少数类进行超级采样(通过创建合成样本),直到所有类具有相同的比例。SMOTE已被证实在许多数据集不平衡的领域有效[12]。
采用分批次训练的方式,使用Adam优化器和SGD以及交叉熵损失函数训练模型,学习率为0.001,batch size设置为128。当损失小于0.005或达到最大100个epoch时,训练 终止。dropout设置为0.2以防止过拟合。
3.3 实验与结果分析
采用准确率(Accuracy,Acc)、精度(Precision,P)、召回率(Recall,R)和F1值(F1-measure)作为最终模型在测试集上效果的评估指标评价。其中含有漏洞的样本表示为正类,不含漏洞的样本表示为负类。TP(True Positive)是被模型预测为正类的正样本数量,FP(False Positive)是被模型预测为负类的正样本数量,TN(True Negative)是被模型预测为负类的负样本数量,FN(False Negative)是被模型预测为正类的负样本数量。
(1)Acc表示正确分类的概率,计算公式如下:
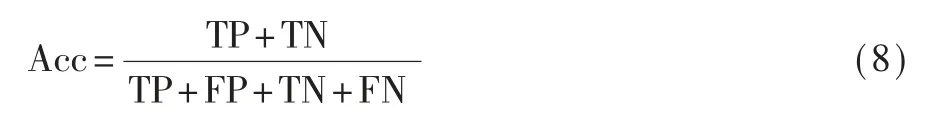
(2)P表示被判定为漏洞的函数中真正的漏洞的比例,计算式如下:

(3)R则表示样本中有多少漏洞被正确的预测了,计算公式如下:

(4)F1值是精度和召回率的加权平均值,计算公式如下:

上述四个指标的度量值越高,表示模型越理想。
表2总结了目前几种具有代表性的漏洞检测方法。其中包含经典的静态漏洞检测工具Flawfinder[13],两种基于切片的方法VulDeePecker[14]和SySeVR,以及两种基于图形的方法Devign和VdoRGCN[15]。为了证实本文方法的有效性,使用上述的方法作为基准进行实验对比,结果如表3所示。
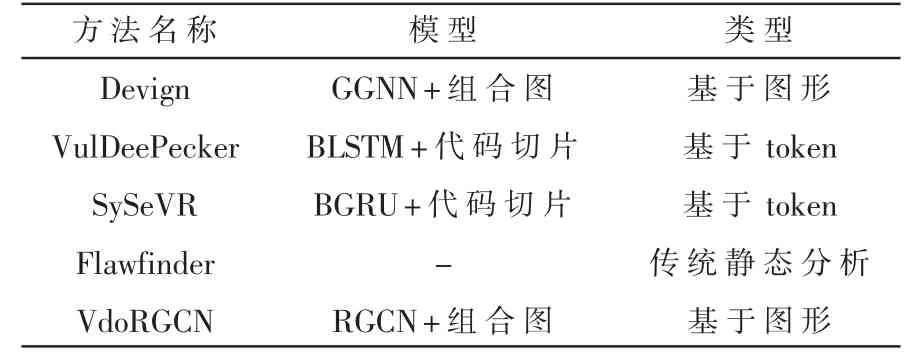
表2 漏洞检测方法

表3 实验结果
如表3中结果所示,与VulDeePecker相比,本文方法在准确率和F1分数上分别提高了5.5%和14.9%,与SySeVR相比在精度,召回率以及F1分数方面都有较大优势。SySeVR和VulDeePecker这类基于token的方法中使用了多个RNN(如LSTM、GRU)来训练检测模型。由于RNN处理数据的不连续特征的性能较差,一些重要的特征可能会被忽略或掩盖。相比之下,双向图神经网络在学习基于图的数据的特征和通过其双向边缘容纳上下文信息方面更加高效。与基于图形的方法相比,本文方法也是更有优势。Devign和VdoRGCN都只使用一个组合图来包含代码不同的信息,这会更加侧重语法而忽略程序语义的重要性,限制模型的表示能力。而多关系结构图的使用涵盖了多方面的程序表示提高了分类性能。
此外,Flawfinder这类静态分析方法的检测效果明显低于使用深度学习网络模型的方法。这是由于静态分析工具的局限性,只能依靠专家定义的规则检测特定类型的漏洞,从而导致准确率和召回率很低。
为了证实关系结构图注意力机制的有效性,使用不同的readout方法来进行对比实验。以常用的CONCAT方式作为基准进行比较。如表4所示,使用关系结构图注意力机制后,模型可以更加关注代码的结构和语义特征,比平均地集成所有节点信息的方式更具有优势,实验结果表明关系结构图注意力机制提高了模型的检测性能。
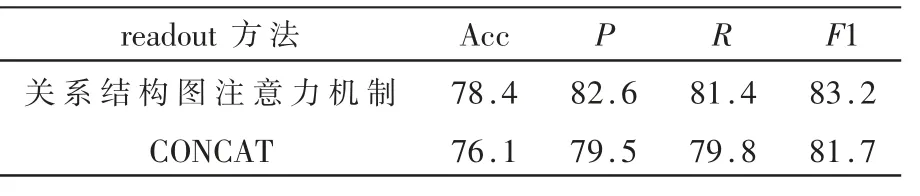
表4 不同readout方法的对比实验结果
现有的漏洞检测方法都是通过网络模型将源代码转换为数值特征向量。所以漏洞检测的效率取决于正类样本与负类样本特征向量的可分离性,类别可分离性越大,模型就越容易区分代码中是否含有漏洞。为了直观地显示本文方法可以获取更好的程序代码嵌入表示,使用UMAP算法[16]来可视化实验中模型生成的表示向量,如图5所示。
从图5可以看出,所有的方法在两个类别之间的特征向量空间上都有很大程度的重叠,但是本文的方法明显可以给出更清晰的两种类别的决策边界,这意味着本文方法比其他方法具有更高的表示能力,在漏洞检测方面更加有效。

图5 特征向量的可视化
4 结论
本文提出了一种基于多关系结构图和双向图神经网络的漏洞检测方法。通过考虑多个代码图形表示来更加全面地保留语法语义信息,接着采用双向图神经网络对编码后的图进行表示学习,然后利用关系结构图注意力机制关注关键的漏洞特征,最后通过全连接神经网络进行分类预测。在真实数据集上进行的对比实验结果表明,本文方法具有更高准确度和召回率。未来的工作将研究不同编程语言的通用漏洞检测模型。
