基于残差网络的双路径图像超分辨率重建算法
2022-12-07谢余杭
谢余杭
(福建师范大学 光电与信息工程学院,福建 福州 350007)
0 引言
图像超分辨率(Super Resolution,SR)技术作为计算机视觉与图像处理中一项至关重要的技术,一直以来都是人们关注的焦点,其目的是从低分辨率(Low-Resolution,LR)的图像中恢复出清晰逼真的高分辨率(High-Resolution,HR)图像。图像超分辨率技术在医学影像、卫星图像以及监控成像等各个领域有着广泛的应用。
目前图像超分辨率重建算法主要被分为三大类:基于插值的SR方法、基于重建的SR方法以及基于学习的SR方法。基于插值的图像超分辨率算法[1]的思想是根据一个像素点的周围某一区域内的像素点来估计这一像素点的值。这类算法的优点在于原理简单、计算复杂度低、重建所需时间短,但是会产生过度平滑的现象,边缘产生明显锯齿。基于重建的图像SR方法[2],比较典型的有凸集投影法、迭代反投影法以及最大后验法。基于重建的方法在一般情况下会比基于插值的方法重建效果好,但是基于重建的方法有时也会出现生成一些具有图像边缘不自然的情况,从而导致重建图像质量变差。基于学习的图像SR方法[3],其基本思想是学习LR空间到HR空间的映射关系,然后利用相应的映射关系来恢复出高清的HR图像。
不过近年来大多数图像超分辨率网络都是采用基于学习的方法,然而大多数现有的基于卷积神经网络的模型在基于大量参数和极深结构的情况下才保持较高性能,而且这些网络也没有充分利用图像的低频特征信息。
因此,本文通过对残差网络进行改进,提出一种新的图像超分辨率重建算法。该算法将低分辨率图像作为输入,利用残差网络提取特征信息以获得残差图像,通过多尺度块来提取图像的低频信息,再将得到的残差图像与低频信息进行线性相加,最后进行上采样操作,从而得到最后的重建的高分辨率结果。所提算法去除残差网络中的批归一化层,可以有效降低网络的计算量,并且在残差块的尾部引入通道注意力来增强网络的高频特征提取能力。与此同时,该算法设计了多尺度块MSB作为跳层来提取输入图像的低频信息,从而提高了网络的重建效果。实验结果表明,该算法与大部分的图像超分辨率算法相比,能更好恢复出低分辨率图像中的纹理细节信息,重建出更清晰的高分辨率图像。
1 基于深度学习的图像超分辨率技术
1.1 应用深度学习的图像超分辨率算法
2014年,Dong等人[4]建立了基于深度学习的SR方法与传统的基于稀疏编码算法的SR方法之间紧密的逻辑联系,并提出了超分辨率卷积神经网络(Super Resolution Convolutional Neural Network,SRCNN)。SRCNN作为用深度学习实现超分辨率的先驱,开启了超分辨率的深度学习时代。尽管图像超分辨率重建技术已经进行了相当大的改进,但现有的基于CNN的模型仍然面临一些限制。随着网络的不断加深,每个卷积层中将具有不同的特征信息。而大部分SR方法没能充分利用这些特征信息,因此He等人[5]提出残差学习的思想,并提出了残差卷积神经网络(Residual Network,ResNet)。从此,在基于CNN的模型中,残差学习被广泛用于提取输入特征的残差信息。而在图像超分辨率重建领域,第一个使用残差模型的则是Kim等人[6]提出的极深卷积网络(Very Deep Convolutional Networks,VDSR)。VDSR证明了在图像超分辨率重建中残差学习可以提高网络的表征能力,加快网络的收敛速度。随着网络的不断加深,网络运行所需的计算时间和内存也会不断增加。为了简化网络结构、减少网络的参数量,Kim等人[7]提出了应用循环思想的深度递归卷积网络(Deeply-Recursive Convolutional Network,DRCN)。为了进一步获取在超分辨率重建过程中的丢失的细节信息,Lai等人[8]提出了拉普拉斯金字塔超分辨率网络(Laplacian Pyramid Super-Resolution Network,LapSRN)。Lai等人通过将拉普拉斯金字塔传统图像算法与深度学习相结合的方法,采用金字塔级联结构实现超分辨的多级放大。LapSRN将LR图像作为输入,并以从粗到细的方式逐步预测子带残差并进行上采样,也就是说若要将图像放大4倍,需要先将图像放大2倍然后再放大2倍,从而达到放大4倍的目的。通过这种多级放大的模式,拉普拉斯金字塔超分辨率网络可以更加有效地利用图像不同特征间的相互关系。
1.2 通道注意力机制
在不同的环境情况下,人们可以快速找到自己所关注的事物。例如人们拿到一张新照片时,会迅速地把目光放在自己感兴趣的部分上。受此启发,研究人员将通道注意力机制引入到计算机视觉领域,其目的是模拟人类的视觉感知系统。在应用深度学习进行图像超分辨率的时代,注意力机制已经成为计算机视觉领域不可或缺的一门技术。所谓的通道注意力机制,就是通道注意力转移到图像的最重要区域并忽略不相关部分。从本质上来说,这种通道注意力机制可以被视为基于输入图像的特征的动态权重调整过程。自从2018年Hu等人[9]在SENet(Squeeze-and-Excitation Networks)中提出通道注意力之后,通道注意力就被广泛应用在图像超分辨率重建领域。
2 方法
2.1 网络框架
图1展示了本文的网络结构,网络主要由跳层和主体两个部分组成。其中,主体部分又细分为浅层特征提取、深层特征提取以及重建三个部分。浅层特征提取部分由一个3×3卷积构成,深层特征提取部分则由16个残差块组成,而重建部分则由一个卷积和自适应亚像素重建层[10](Adaptive Sub-pixel Reconstruction Layer,AFSL)构成。该网络将浅层特征、主体部分生成的残差图像以及跳层MSB提取的低频信息线性相加,然后进行重建,得到最终的重建图像。
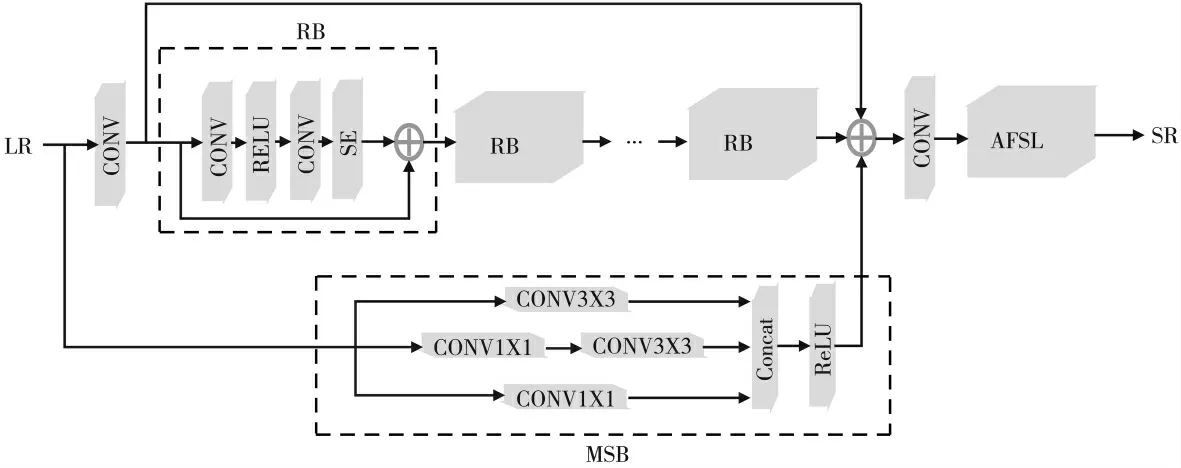
图1 基于残差网络的双路径图像超分辨率网络
2.2 残差块(Residual Block,RB)
如图2(a)所示,ResNet的残差块由两个卷积层、两个批归一化层(Batch Normalization,BN)以及两个ReLU激活函数组成。其中,一个批归一化层的计算量几乎和一个卷积层的计算量相当。然而在图像超分辨率与图像复原领域,批归一化层的表现并不好,加入批归一化层反而会使得网络训练速度变慢、变得不稳定。因此本文网络中去除BN层,同时在残差块的尾部引入通道注意力机制——压缩-伸展块(Squeeze-and-Excitation block,SE)来对特征图潜在的信息进行深度挖掘。在深度卷积神经网络中,不同特征图的不同通道分别代表着不同对象。通道注意力可以根据自身需求给每个通道的分配权重,从而选择关注的部分。而且SE可以有效地获得各个特征图通道间的通道注意力信息。SENet的核心就是SE,SE用于收集全局信息、捕获各个通道间的关系并提高网络的表征能力。SE的结构如图2(b)所示,通过将输入的特征图进行全局池化操作(Global Pooling)来收集全局信息,然后通过两个全连接层(Fully Connected layers,FC)对输入的特征进行升维和降维处理。而SE块中嵌入ReLU激活函数则是为了降低模型的复杂度,以便网络更好地进行训练。最后通过sigmoid函数来有选择地提取有用的特征信息,避免无用的特征信息对网络的训练造成干扰。

图2 ResNet的残差块和SE层结构
2.3 多尺度块
跳跃连接的思想第一次是在ResNet中引入,而后在图像恢复与语义分割等各种计算机视觉任务中被人们广泛应用。由于普通图像超分辨率重建网络无法通过一直加深网络深度来增加网络的性能,因此可以通过引入各种跳跃连接方式来获得额外的性能增益。为了获得输入在不同尺度上的特征表示,本文进一步引入了一个多尺度块(Multi-Scale Block,MSB)作为跳层来直接从LR图像中检测图像的低频信息。MSB块由几个不同卷积核大小的卷积组合而成,卷积后的结果通过Concat层进行级联输出。在图像超分辨率重建任务中,通过将多尺度块作为跳层的方式可以将低分率图像和高分辨率图像连接起来,以此来学习两张图像之间的残差映射关系,从而捕获图像重建过程中丢失的低频细节信息。
2.4 自适应亚像素重建层
现有的大部分图像超分辨率网络都是使用单个的尺度模块来进行重建操作,这样是无法充分利用网络提取到的高频和低频特征信息的。因此,所提算法使用多尺度重建模块来作为网络的重建模块。如图3所示,自适应亚像素重建层使用4个不同卷积核大小的亚像素卷积结构分支并行实现上采样,并能按照网络中不同分支的权重剔除部分比例较小的分支,这么做可以在不损失网络性能的前提下减少网络的参数量。自适应亚像素重建层采用的卷积核的大小分别为3、5、7、9,这里采用的是多尺度融合思想。4个分支的输出通过Concat层进行级联,然后再通过卷积层得到最后输出结果。
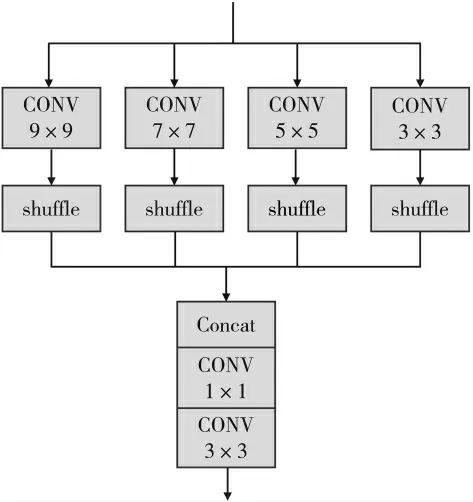
图3 自适应亚像素重建层
2.5 损失函数
本文的网络采用的是L1损失函数,该损失函数的计算公式如(1)所示:

其中ISR表示的是网络生成的SR图像,而IHR指的是真实的HR图像。虽然L2损失函数是之前图像超分辨率网络中最常用的损失函数,但是近几年的研究表明尽管最小化L2损失函数可以提升峰值信噪比,然而与L1损失函数相比,L1损失函数可以提供更好的收敛性和重建效果。因此,本文最后选用L1损失函数来优化网络的性能。
3 实验
3.1 数据集及训练细节
本文的训练集为DIV2K数据集,将其中的800张高分辨率图像用于训练,第801~810张图像用于验证。同 时 在Set5、Set14、Urban100以 及B100数 据 集上进行测试。其中,批尺寸为16,使用Adam作为优化器,其学习率初始值为0.000 1,β1和β2分别设置为0.9和0.999。每迭代200 000次学习率就衰减为原来的一半。本文的网络是通过型号为NVIDIA GTX 1060的GPU和16 GB内 存 在PyTorch框 架 上 训练的。如果没有特殊标注,文中的卷积层均采用卷积核大小为3的卷积。
3.2 对比实验
本文采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)与结构相似度(Structural Similarity Index Measure,SSIM)来作为图像超分辨率网络算法的评价指标。峰值信噪比和结构相似度是有损变换(如图像压缩、图像修复)中最常用的重建质量度量指标之一。本 文 通 过 与Bicubic、SRCNN、VDSR、DRCN、LapSRN以及MSLapSRN进行数值和视觉对比,来验证所提算法的性能表现。在对数据集测试时,需要将RGB通道的图像转换到YCrCb色彩空间上,然后再对Y通道计算峰值信噪比与结构相似度。表1展示了在4个不同的数据集上Bicubic、SRCNN、VDSR、DRCN、LapSRN、MSLapSRN以及本文所提算法进行4倍放大的重建结果的PSNR值和SSIM值。其中,PSNR值越高越好;SSIM值越接近1,则表明重建的SR图像越接近真实的HR图像。
由表1可知,所提算法在Set5、Set14、Urban100以及B100数据集上的PSNR和SSIM值都达到了最优,粗体字表示最佳。在Urban100数据集中,所提算法的PSNR值为26.03 dB,比MSLapSRN高了0.52 dB,比LapSRN高了0.82 dB;本文所提算法的SSIM值为0.783 4,比MSLapSRN高了0.015 3,比LapSRN高了0.027 4。该算法性能的提升主要归功于在网络中加入多尺度块作为跳层,以及应用了自适应亚像素重建层和通道注意力机制。

表1 不同超分辨率算法对4个公共数据集进行4倍放大的重建结果的PSNR和SSIM
为了进一步验证所提算法的优越性,文中给出了不同SR算法的重建效果图。图4展示了不同的方法对Urban100数据集中编号为img087的图像进行重建后效果的视觉比较。由图可知,所提算法与Bicubic、SRCNN、VDSR、DRCN、LapSRN以 及MSLap-SRN相比,没有产生大量的伪影,噪声更少,同时恢复出更好的纹理细节。而图5展示的是不同方法对Set14数据集中编号为ppt3的图像进行重建后效果的视觉比较。从图中可以很明显感受到该算法的重建效果比其他方法要好,能够较为清晰地恢复出图像中的单词信息,重建的图像更加贴近真实的原始图像。由此可知,所提算法不仅在客观指标上高于其他方法,而且在视觉感知上也优于其他方法。

图4 不同超分辨率算法对Urban100-img087放大4倍的视觉比较

图5 不同超分辨率算法对Set14-ppt3放大4倍的视觉比较
本文对网络中的MSB和AFSL模块做了消融实验,具体如表2所示。其中,sub-pixel代表的是常用的亚像素卷积上采样方式。由表2可知,在对Urban100数据集放大4倍的情况下,网络使用MSB+AFSL比只使用AFSL的PSNR值高出了0.08 dB,这就证明了MSB作为跳层对网络的重建起到了一定的作用;而使用MSB+AFSL的网络比使用MSB+sub-pixel的网络在PSNR值上高出了0.03 dB,这就证明了将AFSL作为上采样方式可以使网络重建的效果有一定的提升。经过对网络中的MSB和AFSL模块做消融实验,可以证明在图像超分辨率领域使用多尺度特征融合的思想能够有效地提高网络重建能力。
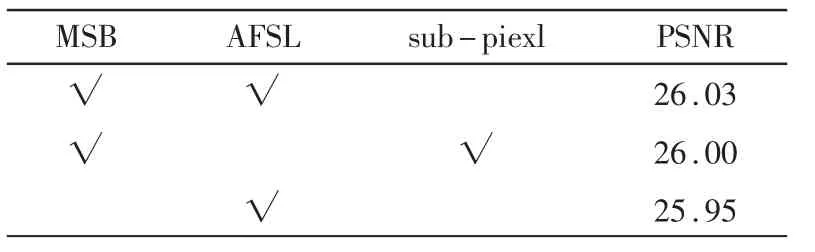
表2 在Urban100数据集进行4倍放大的情况下,对MSB和AFSL的消融实验
4 结论
本文以残差网络为研究对象,提出了基于残差网络的双路径图像超分辨率网络。在残差块中去除BN层并引入压缩-伸展卷积层以及使用多尺度块MSB作为跳层,然后通过自适应亚像素重建层来恢复LR图像。实验结果表明,本文所提方法具有良好的性能,能获得图像更多的纹理细节信息,从而恢复出质量更好的SR图像。
