基于改进YOLOv5 的煤矸识别研究
2022-12-07张释如黄综浏张袁浩章鳌季亮
张释如,黄综浏,2,张袁浩,章鳌,2,季亮
(1. 西安科技大学 通信工程学院,陕西 西安 710600;2. 中煤科工集团常州研究院有限公司,江苏 常州 213015;3. 天地(常州)自动化股份有限公司,江苏 常州 213015)
0 引言
煤炭是我国的重要能源,国内原煤中矸石占15%~20%[1-2],严重影响了煤的品质。应急管理部和国家矿山安全监察局在《“十四五”矿山安全生产规划》中要求重点突破复杂条件下的智能综采,建设无人、少人智能化示范矿山。而目前大部分煤矿利用人工筛选矸石,不能满足煤矿智能化发展要求,亟需一种自动化程度高、检测效果好的煤矸识别方法。
深度学习是一种对数据进行表征学习的机器学习算法, 深度学习框架包括卷积神经网络(Convolutional Neural Network,CNN)、深度置信网络、递归神经网络等,已被应用在计算机视觉、语音识别等领域。深度学习在煤矸识别中的应用研究也取得了一定成果。曹现刚等[3]采用inception 模型有效提高了煤矸识别准确率,但利用softmax 分类需要大量数据样本。Pu Yuanyuan 等[4]通过迁移VGG16网络构建煤矸识别模型,极大减少了训练时间,但检测精度不高。杜京义等[5]利用K-means 聚类提高对前景区域的关注度,提高了煤矸检测精度,但检测稳定性有待检验。汝洪芳等[6]通过优化YOLOv5 网络交并比损失并增强极大值抑制效果,提高了煤矸识别精度,但模型含有大量参数,很难保证识别速度。桂方俊等[7]在YOLOv5 中串联空间注意力模块和通道注意力模块,有效避免了漏检和误检现象,但未解决小目标检测问题。沈科等[8]在YOLOv5s 中嵌入SCConv 作为特征提取网络,缓解了多尺度特征提取不充分问题,同时大幅提高了煤矸检测速度,但删除了模型中颈部网络和预测模块的部分区域,降低了特征提取能力,对检测精度影响较大,很难保证检测的鲁棒性。
现有方法基于深度学习实现了煤矸目标检测,但应用于井下复杂环境中时易出现误检和漏检情况,且对小目标煤矸识别缺少有效的解决方案。针对该问题,本文在YOLOv5s 的基础上,采用AdaBelief算法优化训练参数,提高收敛速度;在主干网络中引入空洞卷积和残差块,提取多尺度图像特征,在不增加模型复杂度的前提下增大感受野,提高图像特征提取能力,解决了小目标煤矸识别问题。
1 YOLOv5 模型
YOLOv5 包括4 种模型,规模从小到大分别为YOLOv5s,YOLOv5m,YOLOv5l 和YOLOv5x。随着模型参数增加,检测速度会降低[9]。煤矿现场大多是算力较低的嵌入式设备,无法部署较大规模的检测模型,检测速度和模型大小是完成实时检测的关键。为保证实用性,本文选择最小的YOLOv5s 作为基础模型。
1.1 YOLOv5s 模型框架
YOLOv5s 主要包括输入端、主干网络、颈部网络和头部输出端4 个部分。输入端对数据进行预处理,如数据增强[10]、图像填充等。主干网络主要通过空间金字塔池化(Spatial Pyramid Pooling,SPP)[11]对特征图进行不同尺度的特征提取,提高检测精度。颈部网络通过特征金字塔网络(Feature Pyramid Networks,FPN)自上而下传递语义信息,通过路径聚合网络(Path Aggregation Network, PAN)自下而上传递定位信息,两者互补,提高模型特征提取能力。头部输出端用于输出网络预测结果。
1.2 SPP 模块
SPP 模块通过3 种不同尺度的池化将特征向量固定为相同长度并传递给下一层,如图1 所示。输入特征图经过1 个卷积模块(Conv)后,通道数减半,然后经过3 个不同尺度的池化层(Maxpool)进行采样,将3 种池化结果与输入特征图进行拼接(Concat),再通过卷积操作恢复图像。
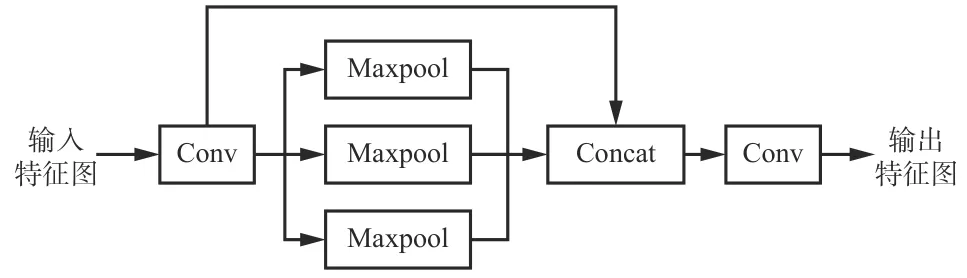
图 1 SPP 模块Fig. 1 Module of spatial pyramid pooling
SPP 不仅增大了感受野,能够分离出上下文的重要特征,而且对推理速度几乎没有影响[12],可以处理不同尺寸、不同分辨率的图像,极大地降低了训练门槛,但也损失了图像的大量原始特征,降低了空间分辨率。选煤厂环境复杂,受光照条件制约及煤尘干扰,获取的图像质量较差,大幅降低了煤矸识别准确率。
2 YOLOv5s 模型改进
2.1 SPP 模块结构改进
YOLOv5s 模型中,图像通过常规卷积进入池化层时尺寸减小,通过上采样恢复图像时丢失了部分数据。对于分辨率较低的图像,内部信息损失对图像识别的影响尤为严重。空洞卷积可在不增加计算量、不损失特征图分辨率的情况下增大感受野,获得更丰富的图像特征。基于空洞卷积的空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)[13]模块如图2 所示。利用3 种空洞率r不同的空洞卷积(Dilated Conv)并行采样,可获得多个不同尺寸的感受野,实现不同目标的分类。
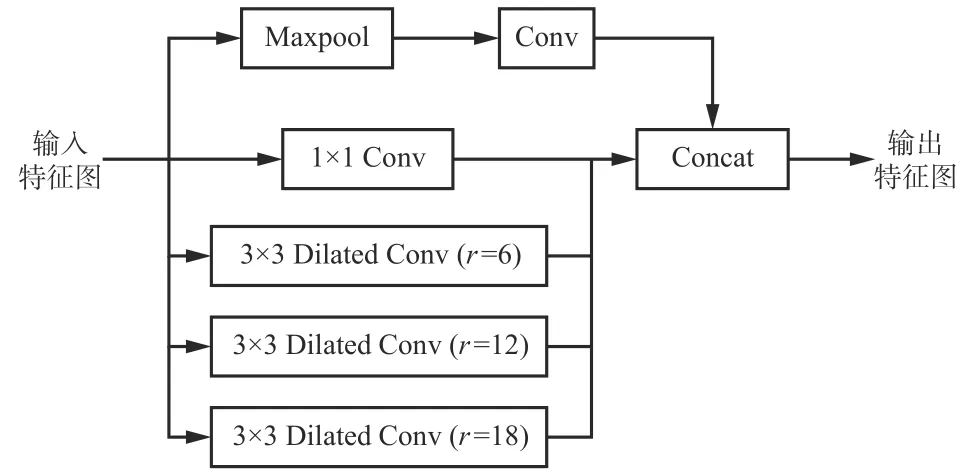
图 2 ASPP 模块Fig. 2 Module of atrous spatial pyramid pooling
ASPP 通过组合空洞率不同的空洞卷积,一定程度上弥补了遗失的信息,但固定的空洞率仍会导致特征提取时遗失部分重要信息。采用大空洞率时对大目标有较好效果,但会遗失小目标的有效信息;采用小空洞率时可获得更多小目标语义位置信息,但会遗失大目标轮廓信息。因此,选择合适的空洞率组合对检测效果至关重要。
针对ASPP 存在的问题,考虑煤矸目标的特点,对ASPP 模块结构进行改进,提出一种残差ASPP 模块,如图3 所示。残差ASPP 模块在ASPP 的基础上增加了残差块,通过残差块可在提取图像特征时实现恒等映射,补充目标在经过空洞卷积后所遗漏的信息。残差块在普通卷积的基础上增加了快捷连接组合,可匹配特征图的空间维度。
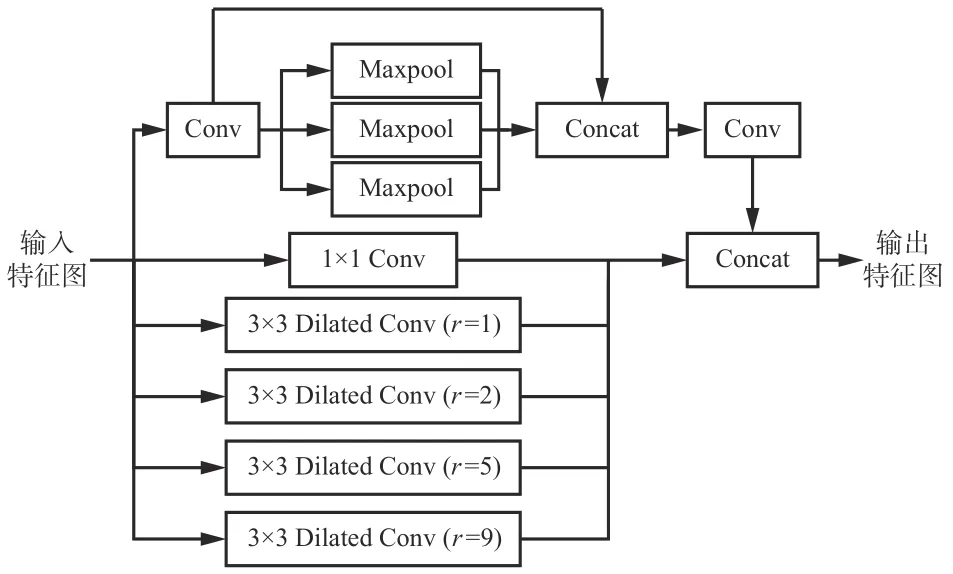
图 3 残差ASPP 模块Fig. 3 Module of atrous spatial pyramid pooling with residual blocks
在煤矸数据集中,每张图像中至少存在1 个目标煤矸,针对多目标、多尺寸的情况,通过残差ASPP 模块可提取到不同尺寸的感受野,利于多目标共存情况下的图像分割。
2.2 优化算法改进
YOLOv5 模型采用自适应矩估计(Adaptive Moment Estimation,Adam)算法[14],与前几代YOLO模型使用的带动量梯度下降法(Stochastic Gradient Descent Momentum,SGDM)[15]相比有一定改进,但仍存在收敛能力差、检测精度不稳定等问题。本文在YOLOv5 中引入AdaBelief 优化算法。
AdaBelief 优化算法基于反向传播算法,通过参数迭代更新优化网络,通过参数梯度的一阶和二阶矩估计动态调整学习率,并在模型的每次迭代中分配1 个自适应学习率,以快速获得预测结果,同时达到收敛速度快、泛化性能好、训练稳定3 个目标。根据当前梯度方向上的“belief ”调整步长,将噪声梯度的指数移动平均值作为下一时刻步长梯度的预测值。如果观测到的梯度与预测值偏差较大,说明当前预测值不够准确,步长应减小;如果观测到的梯度与预测值接近,说明预测精度较高,步长应该增大。基于AdaBelief 优化算法的YOLOv5 模型训练过程如图4 所示。
[5]This conduct threatens our national interests,undermines the value of U.S.investments and technology,weakens the global competitiveness of our firms,and harms American workers.(2018.3.23)
3 实验分析
3.1 数据采集及预处理
在某煤炭仿真实验室进行实验,通过矿用防爆相机采集964 张分辨率为1 280×960 的图像,为了模拟真实场景,部分煤矸有重叠和遮挡情况,总计有近4 000 个煤矸目标。为了丰富数据集,提高数据利用率,采用Mosaic 数据增强技术对原始数据集进行处理,以提升模型的鲁棒性和泛化能力。对4 张图像进行随机缩放、裁减、翻转、加噪声等处理,拼接成1 张含丰富信息的图像,结果如图5 所示。
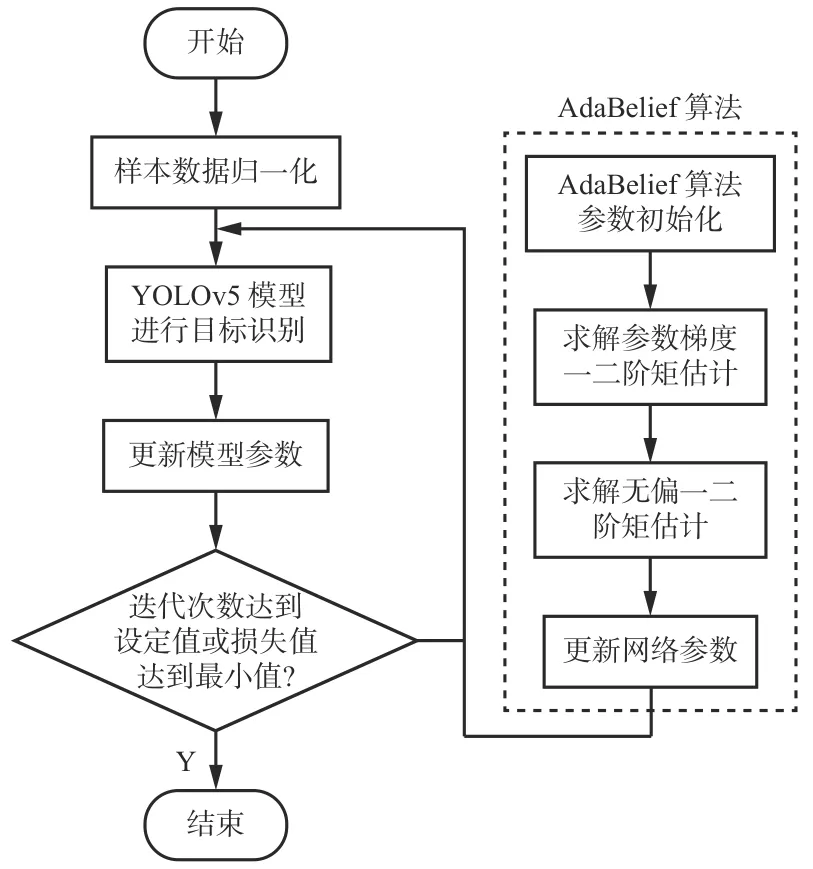
图 4 基于AdaBelief 优化算法的YOLOv5 模型训练过程Fig. 4 YOLOv5 model training process based on AdaBelief optimization algorithm

图 5 数据增强效果Fig. 5 Effect of data enhancement
将数据集以9∶1 的比例划分训练集和测试集,选取增强处理后的867 张图像作为训练集。利用原始图像作为测试集更能模拟井下真实检测环境,增强模型的鲁棒性,因此选取未经数据增强的97 张图像作为测试集。
实验采用Pytorch 深度学习框架,训练平台为深度学习专用服务器,使用Tesla P100 16 GB 显卡。利用YOLOv5s 预训练模型进行迁移学习。输入图像尺寸为608×608,通道数为3,初始学习率为0.01,批处理大小为16,动因子为0.937,最大迭代次数为1 000。
3.2 模型性能验证
3.2.1 优化算法性能
以原始YOLOv5 模型为基准模型,分别使用SGDM,AdaBelief 和Adam 优化算法进行训练。设置训练周期为300,SGDM 的动量为0.9,Adam 权重衰减参数为0.000 5,AdaBelief 的指数衰减率为0.9 和0.999。
采用平均精度均值(mean Average Precision,mAP)、精确率、召回率和帧率4 个指标对采用不同算法的目标检测模型进行评价,结果见表1。与Adam算法相比,采用AdaBelief 优化算法时YOLOv5 模型的精确率提高了0.33%,召回率提高了1.05%,mAP提高了0.39%,帧率降低了0.02 帧/s,表明AdaBelief优化算法可以提高模型的拟合能力和泛化能力。
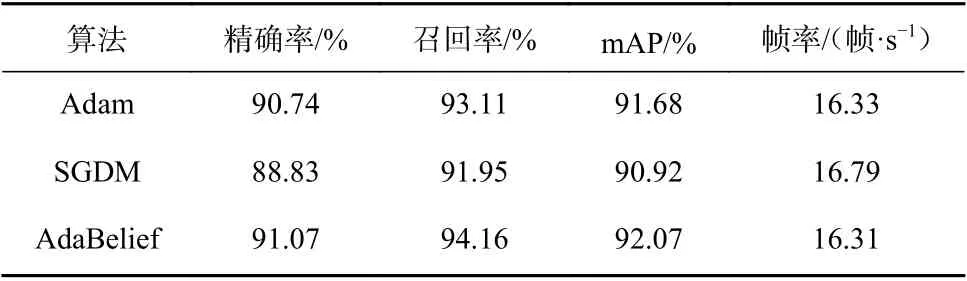
表 1 优化算法对比实验结果Table 1 Comparison of experimental results of optimization algorithms
3.2.2 残差ASPP 性能
虽然空洞卷积能够有效增大感受野,但存在网格问题,叠加使用不合适的空洞卷积时网格问题更加严重,因此要选择合适的空洞率。空洞卷积中,一个组内的卷积不应该有一个固定的变换因子,即空洞率不要有大于1 的公约数,否则无法减小网格效应[16]。在原始YOLOv5 模型基础上,分别设计正常卷积及空洞率组合为[6,12,18,24],[1,3,5,7],[2,3,7,13],[1,2,5,9]的空洞卷积进行实验,其中[6,12,18,24]为ASPP 使用的空洞率组合。采用不同空洞率组合时的实验结果见表2。与正常卷积相比,采用空洞率组合为[1,2,5,9]时的空洞卷积时,模型精确率提高了1.75%,召回率提高了2.52%,mAP 提高了1.61%,性能最优。
同样以原始YOLOv5 模型为基准,分别使用SPP,ASPP 和残差ASPP 进行对比实验,结果见表3。相较于原始模型,采用残差ASPP 模块后,精确率提高了1.81%,召回率提高了1.76%,mAP 提高了1.36%。
3.3 主流目标检测模型性能对比
将改进YOLOv5 模型与目前主流的目标检测模型进 行 对 比,包 括SSD,Faster R-CNN,YOLOv3,YOLOv4 和原始YOLOv5 模型。采用本文获取的数据集对上述模型进行训练,训练周期为1 000。各模型实验结果见表4。可见,原始YOLOv5 及其改进模型的性能优于其他模型,改进YOLOv5 模型的mAP 达到94.43%,比原始YOLOv5 模型提高了2.27%,帧率降低了0.03 帧/s。
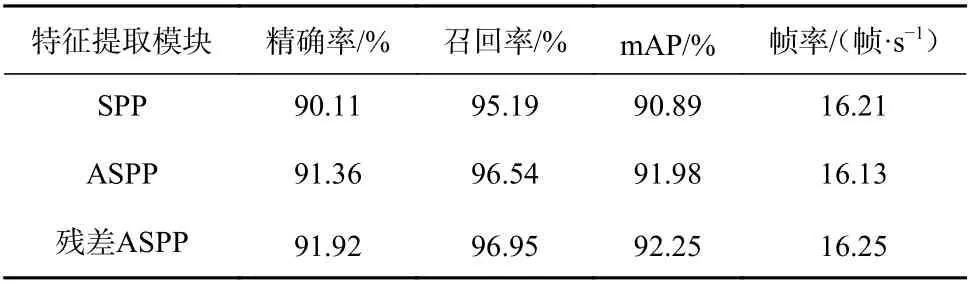
表 3 特征提取模块对比实验结果Table 3 Comparison of experimental results of feature extraction modules
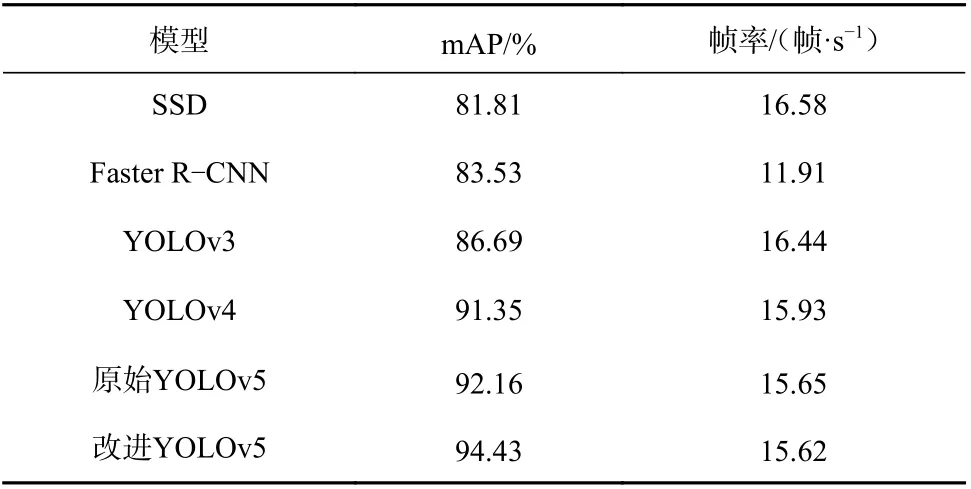
表 4 主流目标检测模型性能对比Table 4 Performance comparison of mainstream target detection models
3.4 同类改进模型性能对比
文献[6]以YOLOv5 为基本模型,将损失函数替换为CIoU,同时将极大值抑制替换成soft NMS(Non Maximum Suppression,非极大值抑制),得到mAP 为91.3%。文献[8]采用的训练集与本文相同,得到mAP 为89.2%,但帧率达到28.4 帧/s,检测速度较快。本文模型的mAP 为94.43%,较上述文献中的2 种模型均有提高。
在井下黑暗环境中的检测结果如图6 所示。图6(a)为文献[6]和文献[8]中2 种模型的检测结果,图中共有4 个煤矸目标,总计出现1 个矸石漏检情况和2 个背景误检情况,将背景判定为目标的概率最高达到了60%,说明检测模型存在明显缺陷。图6(b)为本文模型的检测结果,可见即使在极端黑暗的环境中,本文模型也能准确划定目标边界,鲁棒性强。
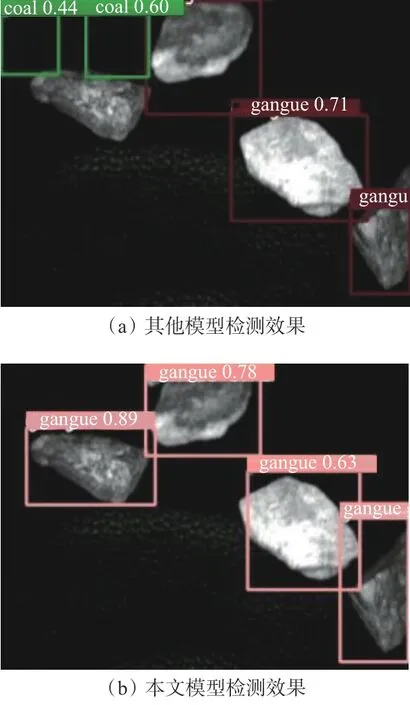
图 6 井下黑暗环境中的检测效果Fig. 6 Detection effect in underground dark environment
4 结论
(1) 提出了一种改进YOLOv5 模型,通过引入空洞卷积和残差块优化SPP 模块结构,强化多尺度特征融合,增强对煤与矸石的特征提取能力;通过引入AdaBelief 优化算法,提高模型的收敛速度和识别精度。
(2) 实验结果表明,与原始YOLOv5 模型相比,改进YOLOv5 模型在保证检测速度的情况下,全类别mAP 达94.43%,高于SSD,Faster R-CNN 及YOLOv3等模型,精确率和召回率也有所提高。
(3) 由于改进YOLOv5 模型不是轻量化模型,所以帧率不高,当煤与矸石流量较大时,检测效果不够理想,未来将尝试解决该问题,提高模型在各种环境下的鲁棒性,进一步改善煤矸识别效果。
