我国图书馆大数据隐私主动式管理研究*
2022-12-06任贝贝
陆 康 刘 慧 任贝贝
图书馆智慧化转型是一项长期渐进的过程,构建科学、合理、完备的标准体系对智慧图书馆的健康发展至关重要。大数据时代,数据安全在实践中已受到高度重视,其中数据隐私问题成为未来智慧图书馆发展的挑战之一。一方面,图书馆需要数据的开放与共享,并形成支撑知识服务、智慧服务的保障体系,以满足服务创新需要;另一方面,面对数据在生产资料价值与隐私方面所具有的二元属性,图书馆也需要加强科学管理,有必要对大数据隐私保护的问题重新定位并重点思考,探索大数据隐私管理的方案,以平衡发展中数据隐私与数据价值关系。
1 图书馆大数据及其处理框架
大数据是高科技时代发展下的产物,在信息流通、人们之间的交流越来越密切,生活也越来越方便的当下呈现出快速地增长态势,并在以云计算为代表的技术创新大幕的衬托下,数据源及其数据格式、类型越来越具有多样化、广泛性等特征。就图书馆大数据的产生方式,可分为自然产生的“数字化”数据与自然产生的“模拟化”数据两种形式。
自然产生的“数字化”数据源自于计算机系统,图书馆这类数据包括用于学科与信息服务的电子邮件与文本信息、用于空间服务的无线网络位置数据[1]、关联不同系统的用户信息元数据、图书馆门户网页数据[2]以及RFID等物联网数据等[3]。
自然产生的“模拟化”数据源自于空间物理世界转化而来,通过各类型传感器的记录,最终产生计算机系统可以访问的数字化格式。图书馆这类数据包括RFID图书标签借阅、盘点产生的数据,门禁IC卡、二维码以及人脸系统识别产生的数据[4],以及支持移动图书馆等工具进行空间监测产生数据等。“模拟化”数据是物联网的产物之一,在万物互联的背景下,将模拟化数据与图书馆数字化数据有效结合,可以精确感知用户需求,从而实现图书馆的服务“智慧”。
图书馆大数据的处理框架,一般分为数据收集、数据存储、数据分析与数据解析四个部分,其中数据收集包括各系统公开的业务数据以及用户私有数据的收集;数据存储是将包括“数字化”和“模拟化”数据在内的数据汇聚、融合的过程,并处理数据的冗余、结构不一致与重复性关系;数据分析就是从存储的数据中提取智慧服务所需的有一定借鉴价值与规则的数据信息;数据解析就是用数据可视化或者溯源等技术来发布、展示数据分析的结果。
2 图书馆大数据隐私类别及其应用带来的风险
数据隐私一般是指个人或者机构等不愿意被第三方知晓的信息,如个人行为信息、个人偏好信息等。这类信息在大数据技术的快速应用和发展下与图书馆的业务息息相关,图书馆中的各系统所产生的数据都可以为智慧服务提供决策。但在图书馆的大数据应用中,这些数据的应用及其处理步骤都与用户数据的隐私性、模糊性与可用性等特征存在着一定关联,存在个人身份信息被泄露、个人行为信息被泄露、个人偏好信息被泄露[5],或是数据被破坏的风险,并随着互联网发展使个人隐私呈现出网络化、数据化趋势。在这种趋势作用下,大数据的多源性导致了大数据隐私存在着类别差异,其中人际关系、通信、身份等数据属于核心隐私,环境、内容、活动等数据属于用户使用图书馆各业务产生的。从来源角度进行分类,大数据的隐私可以分为“监视—隐私”“发布—隐私”“歧视—隐私”三类。从这三类特征来看,图书馆用户个人数据的隐私风险主要存在于以下四个方面。
首先是在安全监视方面。图书馆中数据隐私与信息安全虽然存在着区别,但是两者的目的是相似的,都是为了保障图书馆系统的安全、稳定与用户数据的私密性。信息安全主要是指信息或者信息系统是否存在未经授权的访问行为,包括非法使用行为、非法发布行为、破坏、篡改记录及恶意删除等,涉及数据的完整性、可用性与机密性等方面。对于信息安全主要是从访问控制与密码学方面实施相关方案,提供相应的保障。但是数据隐私方面仍然存在着被泄露的可能,因为数据隐私主要从数据层面进行用户数据的加密、匿名化、模糊化及差分隐私等方法为隐私提供保护。如果信息安全方面的密码泄露,就会导致数据窃取者仍然可以通过合法途径进入系统获取相关数据,造成隐私泄露。
其次是数据共享和发布等传输行为方面。由于图书馆需要感知用户需求才能有针对性地开展服务,那么在图书馆内系统及其图书馆与外部环境之间存在着数据共享和发布机制,需要通过传输控制协议(TCP)数据包层分析用户行为和用户感知,从而在定性和定量两个方面评估用户体验[6]。由此数据在进行共享或发布过程中就会存在着有、无意识行为的数据遗失或者泄露问题,就有可能导致个人隐私存在风险。
再次是在数字化数据源收集方面。图书馆部分系统和数据控制者由于片面追求全面数据,会造成数据被过度收集问题[7],这与图书馆智慧服务的初衷相悖。例如,图书馆提出利用大数据挖掘技术进行用户画像的个性化服务模型,以发现用户的偏好、兴趣、需求,以及活跃度等全貌信息,从而构建用户画像,实现用户和资源的精准匹配,提供以用户为中心、以需求为导向的个性化服务[8]。其中全面数据作为画像精准性的重要参数之一,就有可能存在数据的过度收集而导致的隐私风险。
最后是在数据汇聚方面存在滥用行为问题。中国工程院院士邬贺铨在2013年提出“大数据是下一个创新、竞争、生产力提高的前沿”①论断,可以说大数据已经进入人类生活的方方面面。然而现代生活的便利同时也需要牺牲部分个人隐私,但是个人隐私一旦被滥用,则会代价巨大[9]。图书馆在运用人工智能、区块链、虚拟现实等技术开展的服务中,是以汇聚的数据作为“原料”支持着图书馆智慧服务。与此同时在大数据环境下,由于数据控制者们的权限不同,拥有的数据量存在着差异,会导致数据鸿沟、数据霸权现象的存在,而这种现象一方面会形成数据滥用行为,使大数据存在隐私风险,陷于伦理危机之中;另一方面也容易导致数据透明性降低,用户无法知晓自身数据的应用,容易产生歧视心理。图书馆想要彻底摆脱数据霸权、数据鸿沟以及用户的歧视心理,需要从伦理、制度、法规等视角实施隐私保护。
3 图书馆大数据隐私保护研究
自1890年Warren等发表了《隐私权》[10]以来,个人隐私权作为一项独特的权利正遭受大数据的隐私风险。Bruce Schneier 认为“因为如果我们在所有的事情上都被观察,我们就会经常受到纠正、判断、批评的威胁,甚至会被剽窃我们的独特性。我们变成了孩子,在警惕的目光下被束缚着,不断地担心—无论是现在还是在不确定的未来—我们留下的模式将会把我们带回来,牵连到我们身上,无论什么权威现在已经把注意力集中到我们曾经隐私和无辜的行为上。我们失去了自己的个性,因为我们所做的一切都是可以被观察和记录的。”①出自于ALA网站的“声明和政策”。布鲁斯·施奈尔(Bruce Schneier)在《隐私的永恒价值》一书中对隐私的阐述,他认为当人们相信自己或可能受到审视时,他们的言论、思想和行动会受到寒蝉效应。在现实中大数据让我们处于透明的互联网环境中,图书馆也存在着类似的情形,因此,图书馆的大数据安全与隐私保护不仅是管理层所要重视的问题,也是用户所关切的对象。图书馆大数据隐私管理,不仅需要保障数据安全与用户隐私,也是对图书馆数据关联业务的有效实施起到保护作用,可以认为大数据隐私管理是图书馆发展的重要环节之一。
我国图书馆数据隐私保护研究主要集中在以下三个方面:一是法律制度方面,统一立法完善行业立法健全我国个人隐私保护法律体系[11],借鉴美国图书馆协会(ALA)和美国国家信息标准组织(NISO)隐私管理规范构建图书馆隐私管理的内控体系[12];二是技术保障方面,遵循安全性、匿名性、用户同意、服务与数据对等原则基础上,对数据使用提出相应的措施[13];三是技术与制度融合方面,从国家层面法律政策、图书馆行业规范、隐私保护技术措施和馆员与用户意识四个方面探讨用户隐私的保护策略[14]。关注数据开放中安全与隐私问题,从制度、技术及思想层面进行控制与防范[15]。
国外图书馆数据隐私保护主要围绕三个角度展开研究:一是人的教育角度。Noh,Younghee认识到用户隐私问题的重要性,并通过向图书馆员提供有关隐私主题的教育计划和测量其效果来帮助减少侵犯隐私的行为[16];二是法律伦理角度。Shayna P认为图书馆在法律和道德上有责任保护读者的隐私,同时也面临着用户需求不断变化的挑战,图书馆需要在用户体验和隐私保护之间做出选择[17];三是技术制度角度。Obrien P认为图书馆应在安全网络协议、用户教育、隐私政策、知情同意和风险、收益分析等五个相互关联的领域协调一致,以降低网络追踪对用户隐私的影响[18]。Billey A认为实时调整编目规则,保护权威文件中作者和贡献者的个人数据隐私[19];Singley E认为学术图书馆一直被视为用户信息的可靠管理者,但大数据环境中图书馆安全保护能力包括隐私保护等受到了挑战[20]。
国外图书馆制度也体现了对用户隐私保护的重视,英国CILIP、澳大利亚ALIA等都强调了图书馆用户隐私保护的重要性,并制定用户隐私保护实施细则,如用户个人信息搜集、保存、使用限制、披露限制等隐私保护相关政策,尤其注重通过技术方案来解决大数据时代个人信息保护和信息获取之间的矛盾。
4 图书馆大数据隐私管理框架及实现目标
数字图书馆的系统安全一直受到关注,并将随着以大数据为基础的图书馆的到来,其安全、隐私问题将得到进一步规范化制度管理,以保证业务开展的正常化。图书馆大数据隐私主动式管理框架,意在用技术、制度等方法在图书馆领域掀起探索隐私管理的研究热潮,正如Willes.J所说“当普通法适用于新的主题,在没有先例可循的情况下,只有基于私性正义、合乎道德及公众便利等原则方可为之。如果这种处理能够被习惯上的接受或认可尤为重要。”①参见Willes,J.,in Millar v.Taylor,4 Burr.2303-2312.基于此,本研究在图书馆用户个人数据基础上从法律、伦理与制度、稳定可靠的机制,主动隐私管理技术,隐私影响主动评估与隐私风险主动监控等五个方面创建图书馆大数据隐私主动式管理框架(如图1所示)。
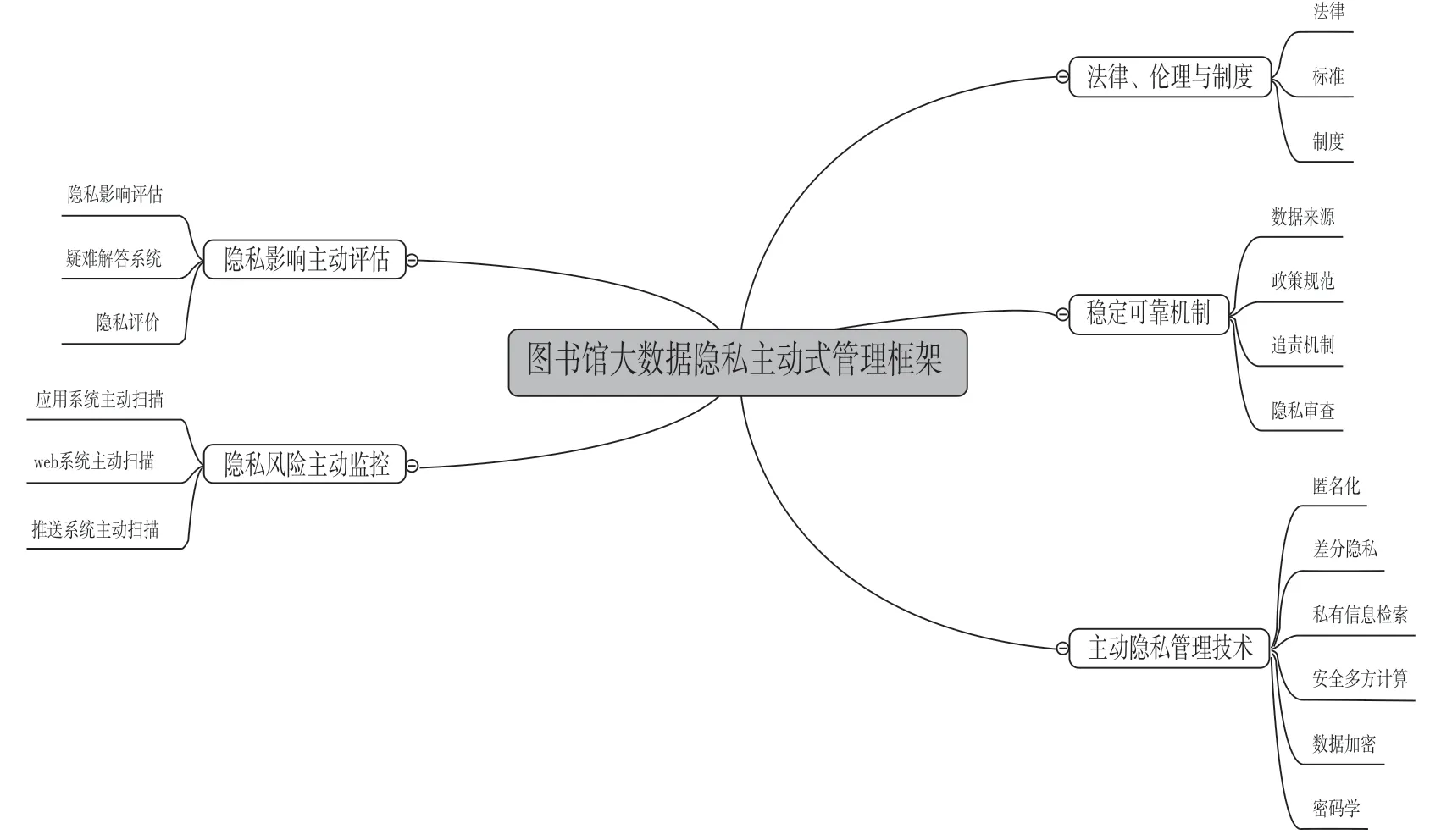
图1 图书馆大数据隐私主动式管理框架
随着社会科学及信息技术的进步,当人们通过数据库搜索所需信息时,数据库系统将更好地去解读有意义的信息数据,使大数据的价值不断被利用。然而对于隐私保护来说,隐私管理需要确定明确的目标。图书馆隐私管理的总体目标是运用图书馆自己的管理理念与方法,如管理文献资源一样管理图书馆大数据的隐私,具体目标包括以下三点。
(1)能为图书馆业务的实施提供技术支持。大数据虽然是图书馆智慧服务开展的基础,但隐私保护是大数据应用的前提。如果隐私问题成为图书馆发展路上的绊脚石,那图书馆智慧服务将成为一纸空谈。图书馆应该正确处理、规范数据控制者、处理者在大数据生命周期内的收集、存储、处理、转换与销毁的数据行为,防止隐私泄露,保障数据主体的信息安全。
(2)可为图书馆隐私危机提供方案。互联网社各领域虽然已经拥有熟悉使用大数据的案例,但是隐私保护策略方面仍然未找到合适的策略,例如在图书馆服务中,如何挖掘用户文献资源需求而不让隐私泄露,如何在获取用户空间行为偏好而不存在让用户产生“被监视”的心态,如何确保在给用户文献资源推送中不被用户误解成“信息垃圾”等。
(3)为图书馆数据共享与用户隐私提供安全保障,打消图书馆安全与用户隐私顾虑。数据共享虽然让图书馆各系统数据变得更有价值,而对于数据隐私保障是需要首要考虑的。在隐私得到保障的前提下,才能更好发挥数据共享的效能,达到实现图书馆智慧服务的理想状态。例如图书馆的数据共享需求由来已久,从最初的文献资源共享到现在的大数据环境下的数据共享,可让图书馆用户获得更好的文献资源与空间保障服务。然而近些年来的互联网隐私泄露事件让用户对隐私的关注度逐渐提高。面对隐私泄露问题,构建完善的隐私管理框架,让图书馆数据共享、用户隐私得到更好的保障,也是图书馆智慧服务得以健康发展的前提。
5 图书馆大数据隐私主动式管理策略
图书馆隐私主动监控主要是在大数据处理时,能够主动监测到可能存在的恶意行为。对这种恶意行为的监控需要建立在法律、伦理与制度的基础上,从两个方面提升主动监控能力:一是在监控应用环境中具有是否存在外部攻击及是否拥有合法授权(图书馆与用户双方)辨别的能力,即用户在使用图书馆系统时是否存在着外部恶意攻击的风险,如移动图书馆系统中的链接是否存在着“环境-位置”的记录程序等;二是具有保障整个隐私管理体系发布风险危机通知的能力,类似于杀毒软件的主动防护功能(博弈论,cost-optimal game-theoretical)[21]。总之,图书馆的隐私管理需要从不同的风险角度,建立综合性的隐私管理模式,并积极拓展隐私管理技术、制度方面的研究。
5.1 图书馆应参照法律和政策,建立隐私保护法律制度
大数据时代的信息资源过度开发与利用引发了隐私危机成为包括图书馆在内的信息服务机构关注的焦点,而IFLA与ALA一直关注并推动制定用户隐私保护政策[22]。我国《网络安全法》《数据安全法》《个人信息保护法》及《信息安全技术 个人信息安全规范》(以下简称《个人信息安全规范》)①参见《信息安全技术 个人信息安全规范》第5、6、7章关于个人信息收集、存储、使用部分。对个人信息收集、保存、使用、流转等环节提出要求,并规定了个人信息主体具有查询、更正、删除、撤回授权、注销账户、获取个人信息副本等权力,填补了国内个人信息保护在实践上的不足。图书馆大数据隐私管理应该参照《网络安全法》 《数据安全法》及《个人信息安全规范》的相关规定,制定、改进、完善行业内的隐私保护制度,从法律、国家标准角度为用户提供安全、规范、稳定的隐私保护措施。
5.2 图书馆应围绕业务需求提供主动隐私管理技术保障
随着互联网的发展,技术创新已经成为社会服务创新的重要支撑,隐私技术也随着技术创新应运而生。无论是位置服务(LBS)的隐私技术-扭曲法的隐私保护,还是针对大数据隐私的完全同态加密方案,都应围绕业务对系统进行隐私保护,采取大数据主动式隐私管理框架的技术保障核心内容来开展。
(1)系统支持图书馆中不同方式、内容、类型的检索、查询需求,特别在隐私管理方面,交互式环境的构建,成为图书馆大数据的主要应用方式。交互式查询差分隐私保护是主要的方式。其中包括关联性分析的数据无关性处理模型(Data-independent processing model based on correlation analysis, DPMCA)、并行梯度下降矩阵分解模型(Parallel gradient matrix decomposition model, PGMDM)、差分隐私的自适应加噪模型(Adaptive noise model based on differential privacy,ANMDP)等[23]。
(2)系统支持图书馆不同方式、内容、类型的数据发布、可视化需求。图书馆中的自然产生的数字化数据还是模拟化数据,经过系统转换(数据挖掘)后都可以表示成不同的数据类型,通过一定的方式,发布相关的内容。例如关联数据、人文数据可视化、流媒体视频、原创音乐等。一般认为非交互式的环境有助于行业内部的技术创新。
(3)系统支持图书馆人工智能(机器学习)与大数据挖掘等分析需求。数据分析是支持图书馆智慧服务的核心基础,也是发掘数据价值的具体过程。大规模性与可计算性、多模态性与有效性、增长性与时效性已成为数据价值发掘的重要特征,同时机器学习、支持向量机分类、线性与逻辑回归及top-k频繁模式挖掘也成为图书馆等领域常用的挖掘方法。
5.3 图书馆应注重优化传统隐私保护技术
图书馆由于现有应用环境的制约,离不开传统隐私保护技术的支持,其中隐私主动式管理方案也是如此。传统的隐私保护技术,一般围绕限制发布、数据加密、数据失真等方面进行相关应用开发,其中限制发布技术是有选择的发布原始数据或者发布精度较低的敏感数据,从而实现隐私保护。主要表现为“数据匿名化”(Data anonymization),代表性技术为k-anonymity、l-diversity、t-closeness等。而数据加密技术也是常用的隐私保护方法,加密方法使用较多的为同态加密技术与安全多方计算等。这些方法与技术都较多被运用到数据安全保护与隐私管理中。
目前,“用户画像”被图书馆广泛用以开展智慧服务实践,其中需要日志分析等操作来完成对用户的“画像”。所谓日志,就是按照一定的规则将操作系统、应用程序、网络设备中发生的事件记录下来,用以对系统管理、网络安全策略实施状况以及其他安全防御系统的评估。近些年来,有关用户的日志数据分析,用来监测用户行为,感知用户所需。然而“画像”精度的提升需要大量的数据。从日志产生的来源角度分类,日志主要分为三大类:操作系统日志(UNIX/Linux,Windows等)、网络设备日志(路由交换设备、防火墙等安全设备)、应用服务日志(Web等各种网络应用)。
长期以来,图书馆对电子资源的使用行为一直无法做到有效监测,无法客观评估其效率。部分图书馆实践者采用应用服务日志和网络设备日志等方法,获取电子资源访问数据,并采用系统汇聚,分析的方式,以访问、浏览、下载与检索等不同形式集成至统一的平台,取得了一定的效果。其中的匿名化(以源IP形式来标注),既可以让图书馆决策者获取用户使用电子资源的详细情况,又可以保护用户的隐私,达到“用户画像”的隐私主动式管理的目的。
5.4 图书馆应建立隐患事故溯源机制
随着图书馆中关联数据、众包及自媒体等新型的信息环境出现,数据来源及数据流动性的真实、可靠越来越重要。为了保障数据安全和隐私保护,图书馆可通过溯源机制排查隐私风险,对违规操作人员起到追究责任的作用。溯源也称起源, 英文为“provenance”,源于法语“provenior”,即“to come from”,意思是有关历史对象的所有权、保管、位置的编年史[24]。溯源机制的初衷并非为了惩戒,而是通过数据溯源技术等对隐患事故起到预警作用。溯源机制是由社会科学、计算机与互联网技术以及法律法规组合而成的对图书馆大数据主动式隐私管理框架进行监督作用的制度体系,其中包括操作是否存在着能力不足,数据标识是否违反隐私策略,以及是否有对应的惩戒措施等内容。当然溯源机制也需要隐私审查等方法的支持。图书馆隐患事故溯源机制是隐私管理技术机制与法律制度之间的桥梁,也属于隐私管理技术体系的补充。
5.5 图书馆应开展隐私影响主动评估工作
隐私影响评估(Privacy Impact Assessment,PIA)作为政府保护公民隐私的重要工具,是一种运用阈值技术来评估隐私风险的方法,已在西方发达国家隐私管理实践中有着二十多年的应用与发展历程[25]。隐私影响评估方法是适应社会公众隐私保护诉求及政府隐私管理需要的产物。而隐私影响主动评估作为隐私风险主动监控后的管理体系,也是为图书馆大数据应用提供基础性服务,同时是支持大数据挖掘的重要方法。
隐私影响主动评估也有两个方面的意义:第一,对图书馆隐私影响风险大小提前预判,将风险危机扼杀在萌芽状态;第二,具有上传下达的隐私管理技术的选择能力。通过疑难问题解答与隐私评价进行实时性风险评估,从而选择合适的隐私保护方案或者技术。例如,图书馆进行数据挖掘时,当出现新的与用户本人相关的信息—运动轨迹、浏览轨迹等,如果不涉及到具体的用户则对结果做模糊化处理,以供图书馆进行数据决策,开展相应的空间服务、文献资源推送等。
隐私影响主动评估也需要一定的技术方法支持,除了上述PIA工具外,EBIOS(Expression of needs and identification of security)也是常用的评估方法,是一种具有预测性、严重程度大小的衡量隐私影响的方案[26]。隐私影响评估应该避免与原始数据的直接接触,运用安全多方计算。图书馆业务在差异性方面进行隐私影响的等级评估时,需建立量化的隐私风险影响机制,以起到隐私预警的作用。
6 结语
大数据时代图书馆的发展避免不了对数据的使用,尤其是“智慧服务”环境下对用户的“画像”。图书馆在注重业务发展的同时也应有责任对用户隐私进行保护,以体现图书馆对用户的人文关怀。“以用户为中心”的理念不仅仅体现在服务方面,也应该扩展、延伸至用户个人保护方面。本文借鉴互联网安全领域的主动式隐私管理方法,尝试摆脱传统的被动式隐私保护技术约束,构建适应大数据时代的图书馆主动式隐私管理框架,再次体现了图书馆“以用户为中心”的服务理念。针对图书馆大数据隐私管理相关问题,图书馆也需要从技术与制度挑战方面加以讨论和研究。在面对传统匿名化技术、用户数据加密、隐私特征判定等方面多角度综合考虑,制定出符合法律、制度、标准及伦理的优化方案。建立综合性的隐私主动管理模式,并积极拓展隐私管理技术、制度方面的研究,将是一个长期的、动态的、周期性的过程,需要图书馆、企业、政府部门共同努力。
