基于深度学习的散射光场成像研究进展
2022-12-06林冰樊学强李德奎彭志勇郭忠义
林冰,樊学强,李德奎,彭志勇,郭忠义∗
(1合肥工业大学计算机与信息学院,安徽 合肥 230601;2天津津航技术物理研究所,天津 300192)
0 引言
散射介质(如大气[1,2]、水下环境[3,4]、生物组织[5−7]等)普遍存在于自然界中。光在散射介质中传播时,由于各种散射粒子的影响,其有序的波前相位将会发生畸变、强度信息将会有所衰减,进而造成探测器所接收到的图像出现细节模糊、分辨率低[8,9]等问题。同时,光在散射介质中的散射是一种复杂的物理现象,该散射过程不仅与散射粒子的相对尺度、种类和形状有关,还与散射体系中的粒子数密度以及散射粒子的分布等因素有关。对于散射介质中的目标探测问题,探测系统所获取的信息是由目标光和背景散射光共同组成的。一般情况下,当散射强度较小或传输距离较近时,探测系统仍可以有效分辨接收图像中的目标信息;但当散射强度增大或传输距离较远时,由于强烈的散射作用,目标信息将大幅衰减,背景散射光将相应增强、形成噪声,导致目标信息难以分辨。所以,如何抑制或去除背景散射光成为透过散射介质成像的主要研究内容。在以往的研究中,研究人员基于探究散射过程中总结的物理模型,例如记忆效应[10,11]、传输矩阵[12,13]、波前整形[14,15]和关联成像[16,17]等,抑制或消除背景散射光,进而突出目标信息、提高成像质量。近年来,随着硬件性能、计算设备算力的大幅提升,数据成为社会中最宝贵的资源之一,基于传统物理模型的成像方式也逐渐向数据模型[18,19]转变。各种基于数据驱动的人工智能算法开始应用于散射介质中的目标成像。
随着计算机技术的快速发展,机器学习(ML)在光学成像领域[20,21]的应用引起了越来越多研究者的关注。2015年,Horisakir团队使用支持向量机(SVM)实现了散射介质中目标的分类[22],基于此,2016年该团队实现了散射介质中目标信息的恢复[23],而后,研究人员开始尝试将深度学习(DL)技术应用到光学成像领域并取得了长足发展。DL算法作为ML中一个新的研究方向,其利用深度神经网络(DNN),从大规模数据中提取有价值的信息,同时选取合适的优化函数和损失函数进行迭代以优化网络参数,最终在特定的任务中获得较为优秀的预测结果。传统的散射成像技术普遍存在耗时、费力和实验环境要求苛刻等问题。由于其强大的数据挖掘能力,DL算法可以有效克服传统散射光场成像技术中存在的固有问题,同时,其相对简单的实验系统也在很大程度上减少了散射光场成像的实验成本。基于DL算法的散射光场成像技术的研究越来越深入,迄今为止,该领域取得了一系列突出的研究成果。
本文基于监督学习和无监督学习两种学习策略,对基于DL算法的散射光场成像技术所取得的进展进行总结;然后,从不同角度,包括应用场景以及网络结构等方面对比分析它们各自的优势和不足,并讨论了基于DL算法的散射光场成像技术问题所面临的挑战;最后展望了该技术的发展前景以及未来可能的研究方向。
1 基于监督学习的散射光场成像
现阶段,监督学习在基于DL算法的散射光场成像研究中占主导地位,主要基于两种学习策略,即强监督学习和半监督学习。强监督学习是指神经网络从具有严格配对关系的训练集与标签之间学习到散射图与原图之间的函数关系,进而构建“逆散射”模型来消除散射影响,恢复清晰目标,其基本原理如图1所示。半监督学习与监督学习的不同之处在于神经网络不需训练集与标签之间具有严格的配对关系。神经网络通过间接映射来拟合“逆散射”模型,实现对散射效应的有效去除。因此,半监督学习在一定程度上克服了网络训练过程中对于原始数据的依赖,大大增加了可用数据集。
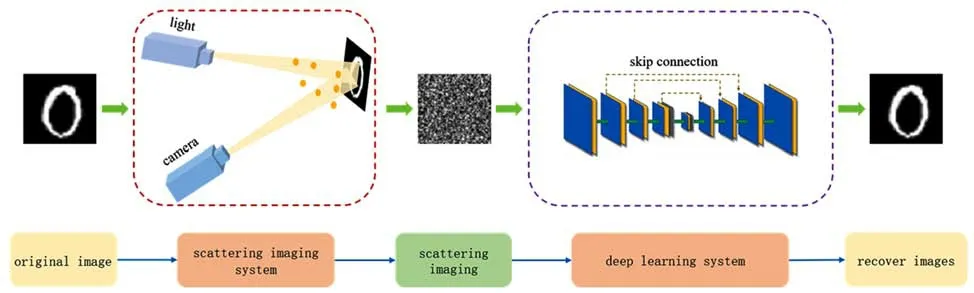
图1 基于深度学习算法的散射光场成像模型Fig.1 Imaging through scattering media based on deep learning
基于监督学习的散射光场成像设计思路比较简单,只需将训练集和标签输入到搭建好的神经网络模型中,然后选取合适的优化函数和损失函数,最终模型的计算由计算机来完成。但是,由于散射光场成像的数据集样本量匮乏、条件单一,导致神经网络模型的泛化能力较弱。因此,目前大多数研究人员在实现高质量成像的基础上,通过对训练数据的优化、采用更先进的网络结构和理论方法,不断提高网络模型跨条件泛化成像的能力,减少可变因素对模型的干扰,从而推动实现基于DL算法的散射光场成像在不同场景下的应用。
1.1强监督学习
目前,基于强监督学习策略的散射光场成像主要使用三种网络架构:卷积神经网络(CNN)、循环神经网络(RNN)和条件生成对抗网络(CGAN)。这三种网络架构各自具有不同特点,分别应用于不同情况下的散射光场成像。接下来,将分别对基于CNN、RNN和CGAN三种网络架构下的散射光场成像方法进行对比和分析。
1.1.1 卷积神经网络
CNN被广泛应用于自动驾驶、目标识别、语义分割和图像重建等领域,同时也是散射光场成像研究的常用神经网络模块。经过多年发展,基于CNN的ResNet、VGG、DensNet、U-Net等性能优越的神经网络架构被提出。其中,U-Net一开始被广泛应用于语义分割[24]。近些年,U-Net在图像恢复方面也有着卓越的表现,并且已经成为散射光场成像领域的主流神经网络框架[25−30]。麻省理工学院的Li等[25]首次提出了一种以U-Net框架为基础的IDiffNet,以解决散射介质中的目标恢复问题,如图2(a)所示。该研究旨在通过IDiffNet学习散射图像和原图之间的映射关系,并以此重建隐藏在散斑背后的目标信息。从图2(b)、(c)中的测试结果可以看到IDiffNet对于复杂目标具有优越的泛化能力。同时,Li等对比了网络模型在负皮尔逊相关系数(NPCC)和均方误差(MSE)两种损失函数情况下的测试结果,证明NPCC更适用于空间稀疏目标和强散射条件的重建任务,为训练网络模型提供了一个可以更快收敛、成像效果更好的损失函数。
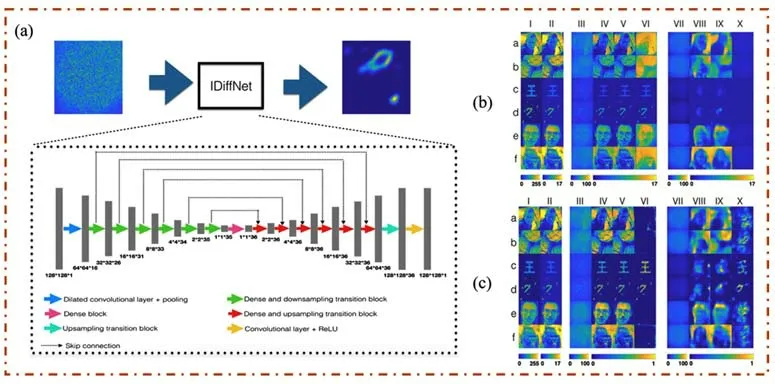
图2 (a)IDiffNet网络结构[25];(b)损失函数为MSE的测试结果;(c)损失函数为NPCC的测试结果Fig.2(a)Network structure of IDiffNet[25];(b)Test results trained by MSE;(c)Test results trained by NPCC
同一年,Li等[26]提出了一种利用CNN适应不同散射介质下的散斑相关性的成像方法。该方法利用大量宏观结构相同但微观构造不同的毛玻璃获得散斑数据,使得网络能够学习到一组具有相同宏观参数毛玻璃的统计信息,具体过程如图3(a)所示。训练收敛的模型可以恢复出通过不同散射介质的多种目标[图3(b)展示的是在训练集中出现的目标和未在训练集中出现的目标的测试结果],为散射光场成像的高度可扩展性提供了基础。

图3 (a)适应不同散斑相关性的成像方法[26];(b)未知散射介质中可见目标和不可见目标测试结果[26]Fig.3(a)Imaging methods adapted to different spot-related correlations[26];(b)Test results of seen and unseen targets in unknown scattering media[26]
在Li等研究的基础上,Zhu等[27]利用散斑的自相关先验信息作为训练集,以此驱动网络有效提取目标通过不同散射介质时的统计不变量,使得模型能够在不同散射场景下重建目标,具体过程如图4(a1)所示。与之前的研究方法相比,该方法只需要一种散射条件下的目标自相关信息作为训练集,数据采集效率更高,重建目标所需先验信息更少。由如图4(a2)的人脸重建结果可知,该方法对于未知散射介质中的目标重建具有较好的泛化能力。并且,当组成散射介质的毛玻璃块数较多时,网络可以获得更广义上的散射介质的统计特性,对于未知散射介质的泛化成像质量也更好。之后,该课题组的研究人员采用相同的方法实现了通过未知散射场景的彩色成像[28],如图4(b1)所示。由图4(b2)可以看到,在未知散射介质中,彩色目标可以通过该方法实现高保真度的重建。与通过网络获得散射图像与原图像素之间的映射不同,以上方法[26−28]趋向于让网络掌握散射介质本身的特性,并以此促进网络适应不同场景的散斑相关性。当然,从这个角度扩展泛化性需要对散射介质本身的特性有更深刻的理解,力求寻找到更广泛意义上散射过程的统计不变量,从而实现多场景的扩展成像。

图4 (a1)利用散斑自相关先验重建目标[27];(a2)人脸重建结果[27];(b1)利用散斑自相关先验重建彩色目标[28];(b2)彩色目标重建结果[28]Fig.4(a1)Process of reconstructing targets by using speckle autocorrelation[27];(a2)Reconstruction results of the faces[27];(b1)Process of reconstructing color targets by using speckle autocorrelation[28];(b2)Reconstruction results of the color targets[28]
针对通过厚散射介质的成像问题,司徒国海教授团队提出了一种基于DL算法的解决方案[29],该方案所使用的HNN结构由全连接层(FC)和CNN组成,如图5(a1)所示。研究人员通过实验证明了该方法能够重建隐藏在3 mm厚的聚苯乙烯板后(13.4倍散射平均自由径)的目标信息,结果如图5(a3)所示。该系统虽然需要收集大量数据,但它在经过一次训练后就能实现实时成像。与同样需要大量数据的波前整形和传输矩阵(TM)测量技术相比,该方法只需测量输入-输出的强度,对训练数据的要求更小,实验系统搭建更加方便。同样,它也不需要使用任何物镜对SLM上显示的图像进行去放大来适应特征通道的大小。此外,该研究通过实验结果证明了相机获得的散斑是高度冗余的,仅使用捕获散斑图案0.1%的信息内容就足以重建目标图像。除了对相干光源下的成像研究,该课题组研究人员通过使用端到端的DNN实现了非相干光条件下的散射光场成像[31],通过一种在中间部分多尺度提取特征的CNN[图5(b1)],实现了散射效应较强(光学厚度可达16τ,信噪比可低至−17 dB)时的高保真度的目标重建,其结构相似度(SSIM)可达到0.86,如图5(b4)所示。以上针对厚散射介质的研究结果为重建被噪声掩盖的目标信息提供了新的思路和解决方案,并有望在更大范围的散射环境中得到应用[29,31]。

图5 (a)相干光下厚散射光场成像方法[29]。(a1)网络结构;(a2)散射图;(a3)重建结果;(a4)原图。(b)非相干光下厚散射光场成像方法[31]。(b1)网络结构;(b2)散射图;(b3)原图;(b4)重建结果Fig.5(a)Method of imaging through thick scattering media with coherent light[29].(a1)Network structure;(a2)Scattering images;(a3)Reconstruction results;(a4)Original images.(b)Method of imaging through thick scattering media with incoherent light[31].(b1)Network structure;(b2)Scattering images;(b3)Original images;(b4)Reconstruction results
由于视场的局限性,光存储效应范围有限,无法将信息存储到实际成像中。所以,Guo等[32]在光记忆效应(OME)算法的启发下,提出了一种新的基于CNN的实用去散射卷积网络(PDSNet)结构,用于离散图像的重建,具体过程如图6(a)所示。实验表明,PDSNet不仅可以实时准确地恢复分散的图像,对于非训练尺度的目标重构还具有优越的泛化表现,实现了目标尺度上的“一对多”功能,并且这种能力能够使得在还原目标时不需严格要求输入数据具有统一的尺寸。文献[33]将DL算法应用到弱光环境中,以解决该环境下散斑携带信息少、存在泊松噪声等问题。在图6(c1)的网络结构中,研究人员通过前几层FC模拟散射过程,提高后续特征提取过程中可用信息的利用率。同时,由于泊松噪声的存在使得同一目标在不同时刻的散斑图像具有一定的差异。所以,该研究利用这一点对同一目标多次采样,不仅能扩充训练集,还能消除泊松噪声对网络鲁棒性的影响。如图6(c2)所示,对目标进行10次重复采样时,成像结果可以达到13.842 dB的平均峰值信噪比(PSNR)。此外,DL算法对实验系统要求不高,网络模型一旦训练完成就可以实现高效预测。所以利用这一点,可以通过一个网络模型实现多维信息的获取。文献[34]构建了一个新颖的深度预测和图像重构网络(DINet)框架[图6(b)],用来根据捕获的散斑图案预测隐藏物体的深度和结构,从而实现“一对多”的信息获取。在相空间约束和高效网络结构的条件下,该方法能够在深度平均误差小于0.05 mm的情况下定位目标并实现目标恢复。该方法不局限于讨论的两个任务,还可以应用于测量其他物理信息,如定位平面内坐标和对隐藏对象分类。
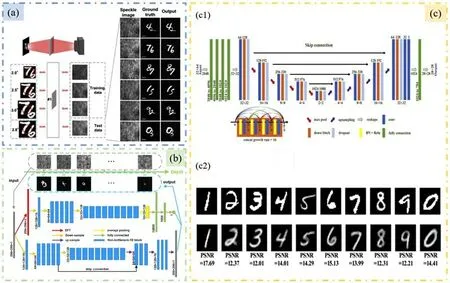
图6 (a)基于PDSNet实现目标尺度上的“一对多”功能[32]。(b)重建图像同时获取目标深度的具体方案[34]。(c)弱光下散射光场成像[33]。(c1)网络结构;(c2)对目标10次采样的重建结果Fig.6(a)Achieve“one-to-many”for target scales based on PDS Net[32].(b)Scheme for reconstructing image as well as obtaining target depth[34].(c)Imaging through scattering media in low light[33].(c1)Network structure;(c2)Reconstruction results with 10 samplings for the targets
除了对强度信息的恢复和重建,基于DL算法的偏振信息处理在目标检测[35,36]、水下成像[37]、图像去噪[38]和图像融合[39]等领域也有广泛的应用。偏振作为光的属性之一,同样携带着可以表征目标的大量信息。此外,目标的偏振特性相较于强度在散射介质中更不容易被破坏[40],而且利用偏振信息可以获得强度图像所不能得到的目标特征。例如,偏振度(DoP)图像和偏振角图像(AoP)在突出目标细微变化时具有良好的表现。但是,DoP图像和AoP图像在获取过程中很容易受到拍摄条件的影响,进而引入不必要的噪声。因此,为了实现对偏振图片的快速去噪,Li等[41]建立了Stokes偏振图像去噪数据集,通过调整偏振相机的增益水平和曝光时间来获取噪声图像和地面真实图像。基于此数据集,他们提出了一种基于残差密集网络的偏振图像去噪网络(PDRDN),具体结构如图7(b)所示。该方法将物理模型、偏振光学和噪声的先验知识嵌入到网络中来指导和约束学习过程。这样,基于DL的方法可以包含更多的物理意义,带来更好的性能。实验结果表明,PDRDN方法的性能优于其他方法,能够更好地恢复出被噪声掩盖的目标细节。通过不同材料、不同噪声水平的实验对比,研究人员验证了强度图像、DoP图像和AoP图像在视觉效果和量化指标上降噪的有效性和泛化性。该研究提出的方法不局限于Stokes成像仪的特殊情况,原则上可以应用于任何偏振成像仪,如Mueller成像仪和偏振差分成像仪。2001年,Schechner等[42]在大气去雾模型中加入偏振,通过偏振探测器在不同方向拍摄的图像实现了高效消除雾霾的效果。自此,偏振成像成为实现去雾的一种有效途径。Hu等[37]首次提出了一种基于DL算法的偏振水下图像去雾方法,网络结构如图7(a1)所示。该方法基于密集网络,可以有效地去除散射光,并且在浑浊水体中也优于现有的基于物理模型的算法,对比结果如图7(a2)所示。同时,该研究提出的基于DL的水下图像恢复方法还可以推广到其他复杂场景中。此外,文献[43]将偏振信息与强度信息融合,实现了更为浑浊水体中的目标恢复。该研究通过四组对比实验[图7(c)]探究了两种信息流在网络哪一部分融合的效果最好,得出了将强度图像和偏振图像放在神经网络的最前端融合是恢复水下目标的最佳方案。
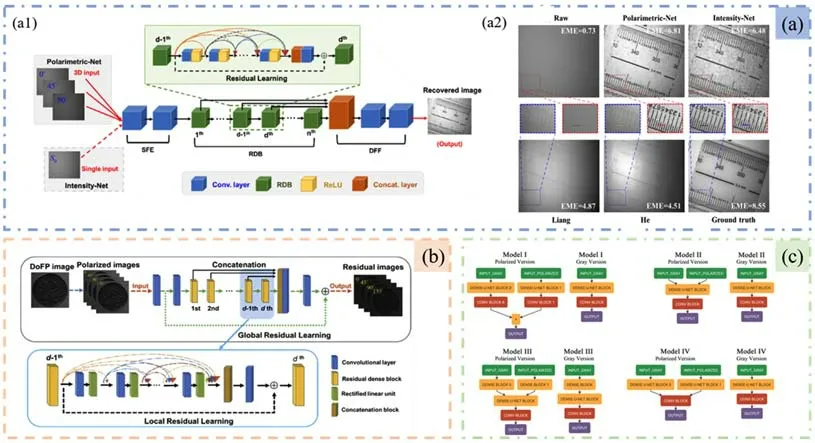
图7 (a)Hu等提出的水下偏振去雾成像方法[37]。(a1)偏振密集网络(PDN)结构;(a2)不同水下去雾成像方法结果对比。(b)Li等提出的PDRDN网络结构[41]。(c)偏振信息与强度信息在网络不同位置的融合方案[43]Fig.7(a)Method of underwater polarization defogging imaging proposed by Hu,et al.[37](a1)Polarimetric dense net work(PDN)structure;(a2)Comparison of different underwater defogging imaging methods.(b)Network structure of PDRDN proposed by Li et al.[41].(c)Fusion method of polarization information and intensity information at different locations of the network[43]
合肥工业大学郭忠义课题组考虑到光与目标发生相互作用过程中偏振信息的改变以及偏振信息在浑浊体系下的传输特性,将偏振信息融入到神经网络的训练中,设计端到端的网络进行散射环境下的目标重建[44]。文中对常见的U-Net网络进行了改进,网络示意图如图8所示,合理构造偏振数据集在一定程度上提升了目标重建的效果以及泛化性。

图8 适用于偏振信息恢复的U-Net网络结构[44]Fig.8 The U-net structure for polarization information reconstruction[44]
光的偏振状态可以用斯托克斯(Stokes)矢量表征,物质对光偏振状态的改变可以用穆勒矩阵(MM)表征。光与物质的相互作用可以用Stokes-MM理论表征,即当入射光与散射环境中的目标与粒子相互作用时,探测器接收到的出射光的Stokes矢量可以表示为

式中M代表散射系统的MM,该矩阵对于散射系统的变化十分敏感。当散射系统发生改变,使得M发生变化,进而形成的散斑特征就会不同。当散射系统较为复杂,或者散射介质中粒子浓度较高时,利用传统的光强信息所形成的散斑无法实现目标的高精度恢复,此外,利用强度信息所训练的网络泛化能力也会较差。而偏振信息可以很好地消除散射的影响,从而更好地突出目标的特征。因此,利用偏振信息训练的网络模型可以达到更好的恢复效果,并且具有良好的泛化性能。
郭忠义教授课题组在该研究中基于蒙特卡洛算法搭建实验平台[45],目标是由钢铁组成的数字,背景是由木头组成的方块,散射介质的光学厚度为2.5τ,发射偏振光S=(1,1,0,0)T进入散射环境,与目标、背景以及散射介质发生作用后利用探测器捕获反射光的Q分量,用于训练所设计的U-Net网络。随后该课题组又从多个方面探究了网络的泛化性。首先,保持其他条件不变,增加了目标的复杂程度,即将目标的形状换成字母和汉字,将在实验系统中得到的散斑输入到网络中恢复,结果如图9(a)所示。然后,保证其他条件不变而改变散射介质的光学厚度,分别得到了当散射介质光学厚度分别为2.3τ、2.55τ、2.6τ、2.65τ、2.7τ和2.75τ时的散斑,并将其输入到训练好的网络模型中进行恢复,结果如图9(b)所示。从图中可以看出,利用偏振信息训练得到的网络模型对于散射介质的光学厚度具有很好的泛化性。接着,保持其他条件不变,将目标的材质换成铝和大理石,得到散斑后利用已有模型进行恢复,结果如图9(c)所示。结果表明,目标的恢复效果与测试目标和训练目标之间的折射率差异有关,当测试集和训练集目标的折射率比较接近时,恢复效果较好。最后,对发射光的偏振态进行泛化重建。保证其他条件不变,将发射光调整为其他的偏振态,并利用探测器探测与之对应的参量的散斑,然后利用已有模型进行恢复,得到结果如图9(d)所示。由于探测到的分量对应于发射光的偏振态,所以接收到的散斑依然滤除了部分散射,突出了目标的信息,所以目标结构可以很好地被网络恢复出来。

图9 U-net网络泛化性测试的结果。(a)结构泛化结果。(a1)、(a4)、(a5)散斑图;(a2)、(a6)、(a7)模型重建结果;(a3)、(a8)、(a9)原图。(b)不同光学厚度重建结果。(b1)∼(b6)光学厚度依次为2.3τ、2.55τ、2.6τ、2.65τ、2.7τ和2.75τ的重建结果;(b7)原图。(c)不同材料重建结果。(c1)、(c2)背景木头不变,目标分别为铝和大理石;(c3)、(c4)目标钢铁不变,背景分别为铝和大理石;(c5)原图。(d)接收偏振状态与入射偏振状态相关的重建结果。(d1)∼(d3)分别为U、V以及任意偏振重建结果;(d4)原图Fig.9 Results of U-net generalization.(a)Results of structural generalization.(a1),(a4),(a5)Speckle patterns;(a2),(a6),(a7)Reconstruction results;(a3),(a8),(a9)Original images.(b)Reconstruction results of different optical thicknesses.(b1)∼(b6)Optical thicknesses are 2.3τ,2.55τ,2.6τ,2.65τ,2.7τand 2.75τin sequence;(b7)Original images.(c)Results of different materials.(c1),(c2)The materials of targets are aluminum and marble respectively while the material of background remains unchanged;(c3),(c4)The materials of background are aluminum and marble respectively while the material of targets remains unchanged;(c5)Original images.(d)Results related to the received polarization state and incident polarization state.(d1)∼(d3)Reconstruction results of U,V,and arbitrary polarization respectively;(d4)Original images
神经网络泛化性的研究结果体现了偏振信息在散射介质中传输的抗散射特性,为动态体散射系统(包括大气、水下或生物组织成像等)提供了一种新的方法。此外,偏振信息可以拓宽信息感知维度,也为新一代人工智能技术提供了有利方案。
1.1.2 循环神经网络
与CNN等前馈网络不同,RNN是一种输出既依赖于当前输入、也依赖于之前输出的DL算法框架[46]。RNN对有序数据特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息。在图像处理领域,RNN被广泛应用于高光谱图像分类[47,48]。在散射光场成像中,Kang等[49]利用RNN实现了一种动态情况下通过任意复杂信道的散射光场成像,如图10(a)所示,该方法利用不同角度的多个散斑组成一个图像序列用于训练,以增强训练过程中图像之间的相关性。同时,RNN有效地平均了动态随机散射介质的影响,更好地提取了目标的静态特征。最终,训练后的模型可以恢复未经训练的目标与信道特性。这种方法充分利用连续信息的相关性,同样也适用于其他涉及时空动态的成像应用。对于追求低采样率的单像素成像,文献[50]提出了基于结合卷积层的RNN的单像素成像方法,如图10(b1)所示。在该方法中,研究人员将测量数据划分为块,使每个块的测量数据数量较小,然后通过RNN积累图像之前的信息来达到对重构图像进行平均的效果。由图10(b2)结果可知,该方法对于复杂场景有较强的泛化性,对由于降低采样率带来的噪声有较强的抑制作用。
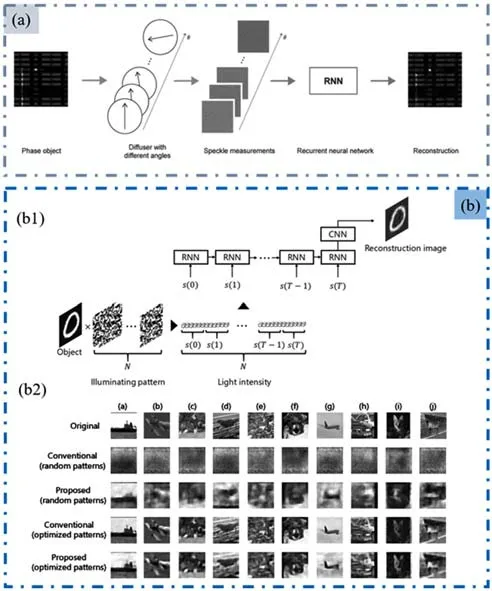
图10 基于RNN的散射光场成像方案。(a)利用不同角度散斑组成训练序列的RNN目标重建方法[49]。(b)基于RNN的单像素成像方法[50]。(b1)具体流程;(b2)不同方案的结果对比Fig.10 The method of imaging through scattering media based on RNN.(a)The method of using different angles of speckles to train RNN for target reconstruction[49].(b)The single-pixel imaging based on RNN[50].(b1)Specific process;(b2)Comparison of results from different methods
1.1.3 条件生成对抗网络
生成对抗网络GAN的提出旨在通过生成器与鉴别器[51]学习到大量数据的分布,进而生成新的样本。而原始GAN不能控制生成数据的类别,这不利于一些定向问题的解决。为此,Mirza和Osindero[52]提出了一种训练生成式模型的新方法—CGAN。CGAN是对原始GAN的一个扩展,生成器和鉴别器都增加额外信息y为条件。y可以是任意信息,例如类别信息、其他模态的数据等。与一般CNN像素之间的约束相比,CGAN通过鉴别器提取更高维度的特征,对生成器的约束更有通用性和有效性。同时,生成器的结构可以为一些计算复杂、获取条件苛刻的图像提供新的获取方式。
在散射光场成像中,CGAN已被应用于提高图像质量[53]和数据增强[54]等方面。同时,对于一些CNN结构难以实现高质量成像效果的复杂散射环境,研究人员利用CGAN减轻训练难度。在文献[55]中,Sun等利用分类网络和CGAN实现动态散射介质的目标重建,如图11(a1)所示。该研究通过生成器与鉴别器之间相互博弈自动学习目标与散射图像之间的映射关系,减轻动态散射介质对模型的影响,以获得更好的成像效果;采用分类部分提供先验信息,以提高后续CGAN重建部分的性能。如图11(a2)所示,该方法对未在训练集中出现过的目标类型依然具有较好的泛化能力。此外,对于未知浓度的散射介质,该方法可以通过分类网络找出最接近的散射条件,然后通过相应的CGAN重构部分进行目标恢复。对于一些特别的场景,CGAN可以发挥其灵活的性能以突破一些传统网络结构的限制。文献[56]设计了一种Y-GAN[图11(c1)]用于实现两个相邻物体的散射图像恢复。研究人员还探究了物体成像类型(灰度图和二值图像)和相邻两个物体之间的距离对成像保真度的影响。由图11(c2)的实验结果可知,该方法具有较强的泛化能力,即使在两物体之间插入另一种散射介质,Y-GAN仍然能高质量地重建目标。此外,GAN独特的生成模型也为一些需要复杂计算才能获得的参量图片提供了新的方法。马辉教授团队设计了一个端到端的DL算法模型,可以基于一个Stokes图像生成基于MM的特定偏振基参数(PBPs)图像[图11(b)][57]。MM表征了复杂介质的偏振特性,并蕴含了关于宏观和微观结构的丰富信息。MM派生的偏振参数的检索图像在一些特定场合具有更为显著的信息表达。但是获取MM图像的过程十分复杂,而且该过程对微小环境的变化非常敏感,这就导致获取PBPs图像对实验系统的精度要求十分严格,所以在这项工作中,研究人员基于CGAN设计了具有自定义损失函数的转换模型,实现了单次曝光下从Stokes矢量生成PBPs图像的过程。这种数据后处理方法能够消除多次曝光带来的误差,降低成像时间和硬件复杂度。
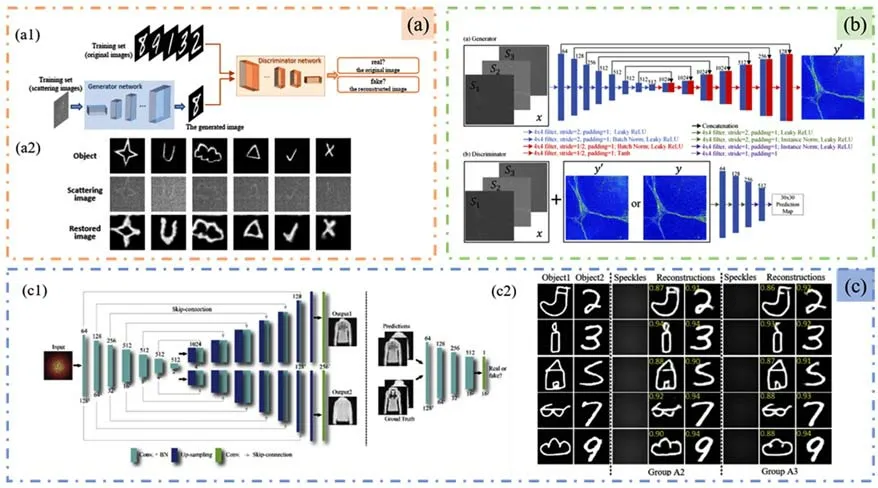
图11 (a)基于CGAN动态散射光场成像[55]。(a1)网络结构;(a2)不在训练集的目标重建结果。(b)马辉教授团队提出的生成特定偏振基参数的网络结构[57]。(c)文献[56]中恢复相邻两个目标的方法。(c1)Y-GAN的结构;(c2)两个目标之间有散射介质的重构结果Fig.11(a)Method of imaging through dynamic scattering media based on CGAN[55].(a1)Network structure;(a2)Reconstruction result of unseen targets.(b)Network structure of generating specific polarization basis parameters proposed by Ma,et al[57].(c)Method of recovering two adjacent targets in[56].(c1)Structure of Y-GAN;(c2)Reconstruction results of scattering media between two targets
CGAN通过条件的输入使GAN的生成变得可控,其独特的结构和约束方式使CGAN具有强大的学习能力,能够简单高效地解决极端环境下的散射光场成像问题,同时为散射光场成像开辟了全新的应用场景。
1.2半监督学习
由于大部分实际场景的数据信息难以获取,或无法获得数量足够多的样本以保证网络模型的训练效果,所以大部分基于监督学习散射光场成像方法的训练集都是在实验室环境中获得的,或者采用公开数据集。随着人工智能领域的快速发展,一种不需要严格配对的数据集的训练方式[58]开始走进研究人员的视野。最近,一种特殊的网络结构CycleGAN[59]被提出,这种网络结构通过两个GAN网络之间的交互来实现两个域之间的模式转换。Yamazaki等[60]基于CycleGAN,利用捕获的模糊图像和未用于捕获模糊图像的目标图像,通过间接回归实现目标恢复,具体过程如图12所示。不同散射水平、相干和非相干光源下的实验结果验证了该方法的有效性和泛化性,然而该工作没有在目标结构完全被隐藏的情况下进行成像实验。这种训练过程中不需要训练集严格配对的方法缓解了研究人员获取标签数据的压力,避免了监督学习过程中训练集需要强对应关系的限制。但是,仍需进一步探究该方法能否适用于重建完全被噪声掩盖的目标信息。
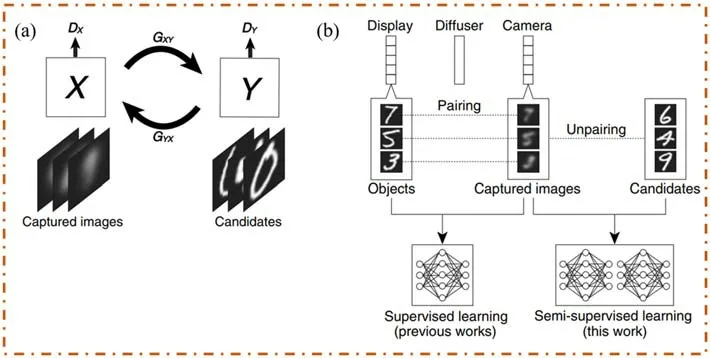
图12 基于CycleGAN的目标恢复[60]Fig.12 Target recovery based on CycleGAN[60]
除了可以从视觉效果上直观地反映出基于DL算法的散射光场成像的优越效果,从具体的定量评价标准中也可以反映出基于DL算法的散射光场成像能够实现高分辨率、低噪声干扰的成像效果。表1中的数据展示了上述方案的部分量化指标。

表1 基于监督学习策略的散射光场成像部分方法定量分析Table 1 Quantitative analysis for imaging through scattering media based on the supervised learning strategies
2 基于无监督学习的散射光场成像
无监督学习本质上是一种统计手段,其在没有标签的数据里发现潜在的一些数据特征。对于图像来说,迄今为止最成功的生成模型是GAN。它由两个网络组成:一个生成器和一个鉴别器[52],分别负责伪造样本和判断真假。对于从散射图中恢复原始目标来说,不需要标签就意味着要找到一种约束条件来控制输出方向。最近,新兴的研究试图将不同光学成像系统的物理特性整合到DNN中[61],通过网络训练过程模拟优化求解[62]的迭代操作,开辟了DNN的新领域。研究人员们将经典的优化迭代过程或者可用公式表达的成像物理过程融入到网络层中,使其成为能够代替标签的约束条件。无监督散射光场成像技术的研究,不仅能在线获得高质量成像,又可以摆脱大量标签数据的约束,为基于DL算法的散射光场成像能够应用于实际工程做出巨大贡献。
2.1基于GAN的无监督学习
无监督学习要求输入数据本身就含有较强的结构信息,因此使用GAN恢复隐藏在散射介质背后目标的方法大多也是基于监督策略的。随着对散射现象的研究不断深入,研究人员已经实现以无监督学习的方式通过GAN重建隐藏在散斑后的目标信息,主要是通过改变生成器的训练方式,例如文献[63]利用自编解码器作为生成器,文献[64]通过物理约束实现在线优化。文献[63]提出了一种基于无监督学习的非均匀光场水下图像复原方法。在去雾模型中,估计背景光是能否获得清晰图像的关键因素之一。所以,这项研究将背景光作为一个需要生成的参数,设计了一个端到端的生成网络来生成背景光,具体流程如图13(a1)所示。生成器采用自编解码器,如图13(a2)所示,从输入背景图中精炼背景光信息,再通过解码获得完整的背景光,利用判别网络产生对抗损失提高性能。实验结果表明该方法能在较短时间内恢复水下模糊图像,恢复结果的图像细节增强评价指标(EME)可达到1.2847。特别是在非均匀光场中,该方法可以很好地应用于经典方法模型。文献[64]提出一种融合物理过程的无先验无监督GAN,从完全没有目标结构的散斑图中重建目标,具体过程如图13(b1)。首先,研究人员探究了不同散射介质的散斑图自相关和原图自相关之间的关系,如图13(b2)所示。然后,通过鉴别器约束和散斑自相关与原图自相关一致性约束实现无监督的在线优化。该方法不需要任何配对数据(即鉴别器不需要输入与散斑对应的原图)和先验信息来提前训练网络,仅需要对一帧散斑图在线优化就可以重构未知散射介质后的隐藏目标。但是,当目标的大小超出记忆效应范围时,自相关结构会逐渐退化,该方法可能无法有效重构隐藏目标。
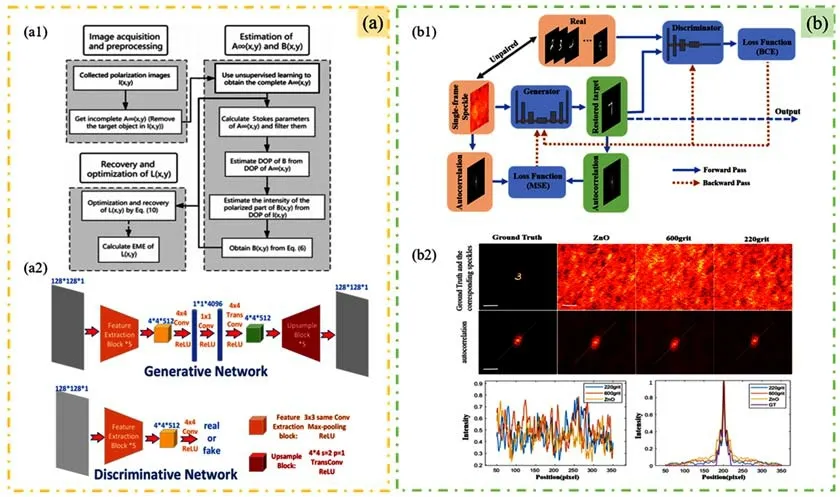
图13 (a)无监督水下去雾[63]。(a1)具体流程;(a2)网络结构。(b)无监督在线优化[64]。(b1)具体流程;(b2)原图自相关与不同散射介质下散斑自相关Fig.13(a)Unsupervised underwater-defogging imaging[63].(a1)Flow chart of the method;(a2)Network structure.(b)Unsupervised online optimization[64].(b1)Flow chart of the method;(b2)Autocorrelation between the original images and speckles from different scattering media
2.2 Physics-aware网络
Physics-aware网络是一种新兴的学习方式,该方式起源于Skoltech、Yandex和牛津大学的学者们在文献[65]中提出的Deep Image Prior。他们让一个CNN去学习复制被破坏的图像时,发现深度卷积网络先天就拥有一种能力,即先学会图像中“未被破坏的、符合自然规律的部分”,然后再学习图像中“被破坏的部分”。所以,一个卷积网络在对一张被破坏的图片进行反复迭代时,它能自动利用图像的全局统计信息重构图像中丢失的部分信息。该研究也通过实验证明了这一过程,但该方法的迭代过程不可控,因为网络最终向退化图方向演化。所以,之后的研究将光学成像系统的物理模型加入到DNN中,通过光学成像的物理过程来约束网络向着重构图像方向进行优化。Wang等[66]提出在传统的DNN中加入一个完整的表征图像形成过程的物理模型来克服需要大量标签数据的限制,具体过程如图14(a)所示。该研究通过在整体训练过程中加入衍射成像过程H,将输出图像output再次转换成z=d时的衍射图像˜I,然后通过损失函数使网络产生的˜I与实际输入的I不断靠近。最终,网络“中间”输出output就是去除散射效应的结果。物理增强深度神经网络(PhysenNet)只需一个相位对象的衍射图就可以自动优化,通过神经网络和物理模型的相互约束生成理想的清晰图片,这种方法为神经网络的设计开辟了一个新的范式,物理模型整合到神经网络的概念可以推广到其他计算成像问题中。该课题组研究人员在此基础上又提出了BlindNet[67],该网络模型在PhysenNet的基础上改善了物理模型表征不准确的问题,如图14(b)所示,该模型将物理模型参数的优化H(z=d′)一同纳入到训练过程中,即损失函数在驱动网络权值更新的同时还驱动物理模型参数d的优化,实现整个训练过程只需要初始化网络模型后就可以自动优化成像过程。针对模型不确定性的新型DNN框架可以应用于一类具有明确成像模型的计算成像中,文献[68]将这种训练方式与水下去雾算法相结合,如图14(c)所示,提出了一种未经训练的网络和偏振成像协同进行全场景水下成像的方法。该方法充分利用了神经网络的非线性拟合能力,改善了经典IFM在不同场景下参数设置不完善造成的不良成像效果,在不需要额外的标签进行网络训练的情况下提高了成像质量(成像结果的平均对比度可以达到0.2739)。除此之外,文献[69]将大气传输模型中的所有参数都由网络进行全局在线优化,使训练过程形成闭环。最终,利用PSDNet-L获得清晰的去雾图像,如图14(d),该方法在训练过程中不需要场景的清晰图像进行约束,并且在训练完成后可以直接通过PSDNet-L预测结果。研究人员对公共数据集和拍摄的实际浓雾环境的图片进行测试,证明了该方法在保持原始图像颜色和增强图像细节方面具有良好的表现。

图14 Physics-aware网络。(a)PhysenNet的具体流程[66];(b)BlindNet的具体流程[67];(c)IFM-guided network的具体流程[68];(d)大气传输模型中所有参数在线优化的具体流程[69]Fig.14 Physics-aware network.(a)Flow chart of PhysenNet[66];(b)Flow chart of BlindNet[67];(c)Flow chart of IFM-guided network[68];(d)Flow chart of optimizing parameters of the atmospheric transport model online[69]
研究人员通过在训练过程中引入物理约束,使部分条件下的散射光场成像可以摆脱大量标注数据的限制。对于目前无法总结具体成像模型和迭代优化方法的散射光场成像仍没有基于无监督的解决方案。但是,随着研究人员对散射过程的探究不断深入,未来可能会陆续提出可用于一般条件散射光场成像的无监督高效学习方法,基于无监督的散射光场成像领域也会产生更多有意义的科研成果。
3 优势与挑战
上文总结了基于DL算法的散射光场成像技术的各类方案,具体性能对比如图15所示。通常,传统技术需采用物理模型的显式解析公式解决逆成像问题,而DL算法则可以绕过已知模型的严格要求。同时,DL算法还可以缓解光学实验中严格的系统要求,并从计算上补偿实验系统所带来的系统误差。此外,一旦训练完成,DL算法允许实时重建和快速预测。总的来说,DL算法可以在大范围的散射光场成像任务中显著提高成像效果,并对于未知任务具有一定的可扩展性。同时,DL算法实现简单、设计灵活,能够有效降低光学成像实验的复杂度,为散射光场成像开拓了全新的应用场景。
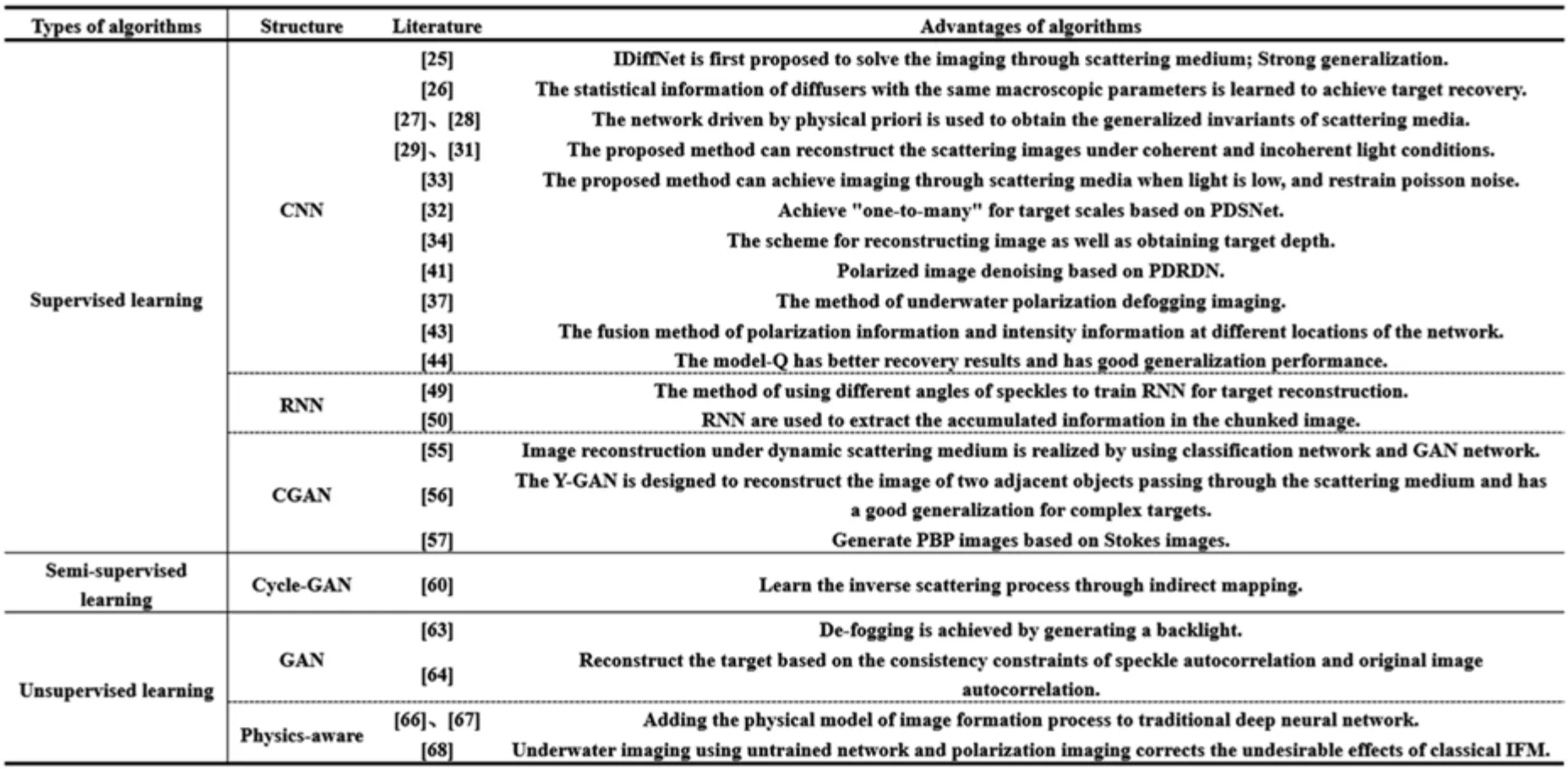
图15 基于深度学习算法的散射光场成像性能对比图Fig.15 Performance comparison of imaging through scattering media based on deep learning algorithm
然而,DL算法在散射光场成像中的应用仍存在一些潜在的问题。首先,大部分实验数据都是在实验室环境下获得的,缺少对真实环境的表达;此外,不同类型的成像系统和不同的光学设置都会导致捕获的数据集之间有很大的差异,影响DNN模型的稳定性和泛化性。DL算法缺乏可解释性对散射光场成像领域来说也是一个问题,部分学者会质疑DNN所具有的良好的实验性能是一种巧合,而不是逆问题正确建模的结果;最后,由于不能保证获得物理上准确的解释,其故障排除也具有一定的挑战性。以上问题严重阻碍了DL算法技术在散射光场成像工程实现中的应用,总体而言,DL算法在散射光场成像中的应用仍处于探索阶段,仍然有很多亟需解决的问题。
4 总结和展望
DL算法为散射光场成像的研究提供了新思路。基于DL算法,国内外研究人员尝试从提升神经网络的泛化性、减少数据的依赖性、拓宽散射环境的适用性等方面改善散射光场成像技术,并取得了一系列的研究成果。以监督学习作为训练策略的DL算法方案通过采用具有不同特征提取倾向的网络结构、优化输入数据,使训练后的网络模型可以去除散射影响、突破传统成像系统的限制、适应各种散射环境,实现看得清、看得远的成像目标。而以无监督学习作为训练策略的DL算法方案,利用物理模型约束和神经网络强大的拟合能力实现高质量在线成像。虽然该种方案对于部分散射光场成像有一定限制,但仍然能推动散射光场成像领域向着更加智能化的方向发展。
随着人工智能技术的快速发展,越来越多先进的DL算法被引入到散射光场成像中,如迁移学习[70]和注意力机制[71]等。DL算法正因其在数据拟合方面独特的优势而在散射光场成像领域大放异彩,本综述总结了基于DL算法的散射光场成像的最新研究进展,对比分析了现有方法存在的优势和不足。DL算法具有优秀的拟合能力,但是物理机制尚不十分清晰,进一步探究DL算法网络结构、损失函数、以及数据特征提取过程的物理机制,将散射光场成像的物理原理与DL算法有机结合起来,实现小样本学习,快速学习、拓宽网络的泛化性是基于DL算法的散射光场成像的未来发展方向。同时,得益于计算设备算力的提升、探测设备性能的提高,基于科学家的杰出成果,对现有方法取长补短,基于DL算法的散射光场成像技术正在向着更清晰、更远、更快、更小、更智能的方向发展。
