多任务学习的论文被引量预测
2022-12-06张德秀张思凡程雨轩史春雨
张德秀 ,毛 煜 ,张思凡 ,程雨轩 ,史春雨
(1.闽南师范大学计算机学院,福建漳州 363000;2.阿里巴巴AE技术部推荐算法团队,浙江杭州 310000)
1 研究背景
近年,随着教育水平的快速提高,论文学术资源呈指数型增长趋势,其论文质量也参差不齐,如何从这些海量的学术资源中获取高质量、有价值、具有潜在影响力的论文成为新的挑战.对于科研人员来说,优质的学习资源能提供科学有效的依据,使科研人员尽快掌握科研前沿动态、提高学习效率和加速科研成果的研究进度[1].
对于学术论文,论文主题越热门,那么该论文的影响力就越大,引用量也越多.然而随着逐年论文发表量的叠加,论文语料库也呈爆炸式增长,导致论文主题-词的概率分布离散化,无法更精确表达论文的主题特征.同时对于领域专家来说,其论文通常容易被关注,专家权威性越高,被关注度就越高,论文被引的概率也越高.但是同一作者在不同的研究领域权威性是不同的,当作者跨领域发表论文时,先前的权威性将不足以衡量其在新领域的权威.传统的论文引用量预测方法不能细粒度的对这种作者特性进行整体分析,这给论文特征表示方向的研究带来了新的挑战[2].因此,提出一种能准确有效预测论文引用量的方法具有重要的研究意义.如今,论文主题的不断动态演变、论文语料库的不断更新、主题流行度以及论文作者权威性的变动、论文的文本特征、作者相关特征、论文发表的期刊以及它们之间的关系网等诸多动态因素都对论文引用量预测造成了很大的困难.针对目前论文引用预测出现的这些问题,本文考虑多方面的因素,提出一种基于多任务学习的论文影响力预测模型.
2 国内外研究现状
对于论文引用量预测,目前学术界提出了一些相关方法,例如被引量、H-Index、g-Index、影响因子等,其中被引量是学术界广泛应用的一项学术影响力评价指标,H-Index、g-Index、影响因子是基于被引量延伸出的学术影响力预测方法,这些方法计算简单且具有普适性的优点,但其缺点在于引用数量可被人为操控,导致无法通过引用量准确客观的评估学术影响力.并且这些方法只能在学术成果发表一段时间后的论文引用量,无法及时反应当前的学术水平.除了使用基于引用量的方法之外,传统的方法还有网页排序算法HITS和PageRank[3],这两种方法考虑了学术网络的不同结构,其优势在于能充分利用学术数据和关系,从网络连接的角度来对论文引用量的预测.但该排序方法只能对作者整体权威性与影响力进行了粗粒度的表示,而对于论文主题资源无法充分表达,造成特定作者对于不同主题的权威性效果欠佳,同时该方法无法得出新论文的引用量评估,存在新论文引用量冷启动问题[4].针对该问题,Chakraborty等[5]使用支持向量机(support vector machine,SVM)来进行论文引用预测,该方法首先将论文进行分类,然后使用支持向量回归方法对引用量呈增加趋势的论文引用进行预测.Shen等[6]首先使用论文发表之后信息作为训练集,最后通过自增强泊松过程方法进行论文引用量的预测,利用同样的训练方法,Xiao等[7]使用自触发模型预测论文引用量.虽然这些预测方法取得了一定的效果,但是局限于传统方法自身的缺点,这些预测方法效果并不理想.
随着机器学习在各个领域的广泛使用,研究者们也将该方法运用到论文引用量预测领域中.Abrishami等[8]根据论文以往的被引量预测未来的引用量,在预测准确性上取得了显著的效果.Pobiedina等[9]提出了一种基于频繁图模式的引用量预测方法,首先构建引文网络,然后在该网络中引入频繁图模式挖掘方法,提高了引用量预测的准确性.针对论文、作者以及研究领域引用网络中的链接预测问题,Daud 等[10]通过朴素贝叶斯、决策树、支持向量机对引文网络中的相互链接预测进行分析对比.Bütün等[11]通过每位科研人员发表论文的被引用次数,以预测该论文未来的影响;将科研人员的未来被引次数预测问题形式化为动态引文网络的链接预测问题,基于不同的数量变化趋势引入动态指标,然后使用各节点的动态临近度量来预测被引次数.这些研究方法通过论文被引量和论文本身的特征来对论文未来引用量进行预测,虽取得了一些成效,但并未将论文自身特征和作者与论文关系、论文与期刊的关系等进行有效融合,使得预测模型的性能有待进一步的提高.
近年,由于多任务学习方法不仅能有效优化多个目标函数,得出最优解,且能通过辅助任务改善自身任务的学习性能,从而提高模型的泛化能力,使该方法成为新的研究热点.本文为了解决论文建模表示困难的挑战,提出一种基于多任务学习的论文影响力预测模型,模型首先预处理论文相关数据,获取论文的网络拓扑特征和文本特征,通过一个带有注意力机制的图卷积神经网络(graph convolutional network,GCN)和Transformer[12]分别处理这两种特征.然后,为了使模型能够获取对于被引量更重要的内在特征,在预测目标论文被引量的基础上,通过采样对比论文样本,引入额外的论文被引量差值预测任务.这两个任务共享部分网络架构,且针对后者,设计了对应的交互网络提取中间特征从而完成预测.
3 基于多任务学习的论文被引量预测模型
为了让神经网络学习到更好的论文表示,以精准地预测论文的被引量,提出基于多任务学习的框架.本节将从以下四个方面进行介绍:模型预处理、论文被引量预测、论文被引量差值预测和联合学习.
3.1 模型预处理
针对待预测的论文x,首先通过数据预处理构建它的输入特征,包含网络拓扑特征Gx和文本特征Dx.其中,文本特征Dx可以通过论文x相关文本(标题、摘要)的分布式表示方法获取,例如Doc2vec[13];网络拓扑特征Gx=(E,R,T)主要描述论文实体与其他类实体之间的相互关系,例如论文x发表于某期刊v,其中E、R、T分别表示实体集合、关系集合、边集合.形式化地,本文定义了如表1所示的实体类型和关系类型.
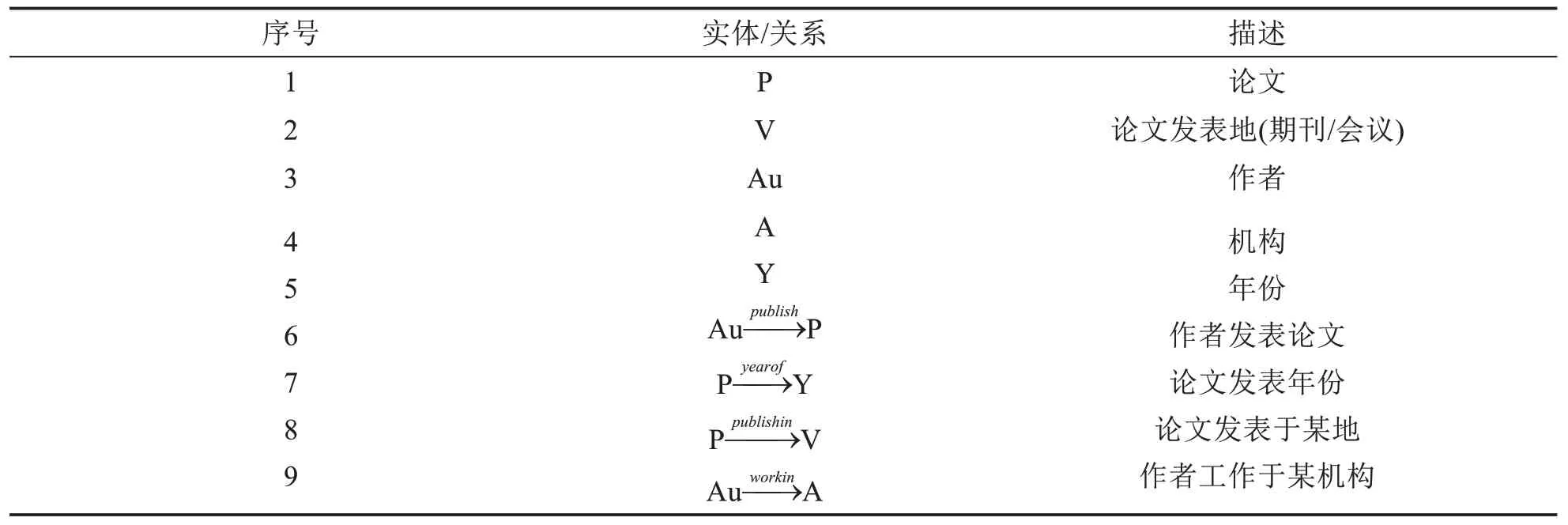
表1 实体和关系类型Tab.1 Entity and relationship types
以上的方式将科研论文及相关的实体通过不同类型的关系构成一个异构网络拓扑结构G(类似于知识图谱),每个论文节点及其邻居构成其网络拓扑特征.对于论文x,在进行预测时,本文在G中抽取以x为中心节点的k阶子图作为x的网络拓扑特征Gx.为了在神经网络的输入表示中初步具备网络拓扑特征,本文使用TransR[14]算法首先对G进行预处理得到每个节点及关系的初始表示.
对于论文x,为了让模型能够获取到对预测被被引量更全面的潜在表示,本模型引入对比论文y来进行多任务学习,模型的整体架构图如图1 所示.其中L1表示神经网络预测x被引量的损失,L2是额外的多任务损失,表示预测x与y被引量之差的损失.L2通过神经网络处理x与y的交互实现,而并不单是通过两者的最终表示,这样会让模型能够在每个阶段都受到多任务学习的引导,进而产生更加精准、更加鲁棒性的预测结果.
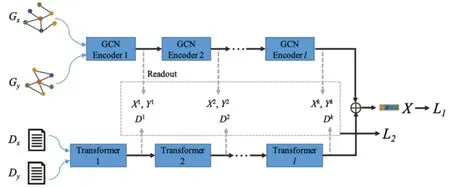
图1 基于多任务学习的被引量预测模型的整体框架Fig.1 The framework of a citation prediction model based on multi-task learning
3.2 论文被引量预测
对于论文x,模型首先通过网络拓扑特征Gx和文本特征Dx预测其被引量.具体地,分别使用图卷积神经网络GCN 和Transformer 处理Gx和Dx.Gx作为关于x的k阶多关系异构图,其中每个节点和关系的初始化表示通过TransR获得,后续处理时,它们的更新遵循GCN的迭代消息传递模式.其第k+1层的表示由第k的表示通过注意力消息传递方式计算得到.

整体来说,针对目标节点u的第k层表示,其第k+1 层的表示由和其邻居节点v的表示通过转换加和得到,分别表示两者的转换矩阵.N(u)表示节点u的邻居节点-关系对集合,表示节点u和其邻居节点-关系对(v,r)的注意力得分,它决定了在消息传递时,周围邻居被增强或者抑制的程度,通过这种方式增强有益信息传递,并削弱噪声信息的影响.具体地如式(2)和式(3)所示.
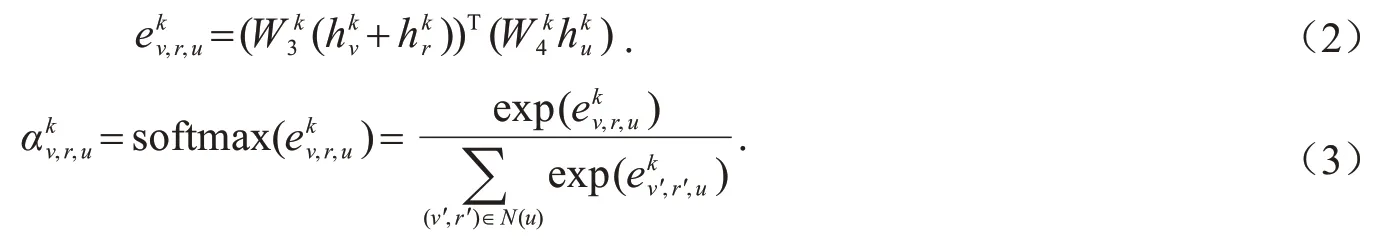
式(3)表示首先通过邻居节点-关系对及目标节点的表示向量计算注意力得分,并通过softmax进行归一化.其中表示注意力计算时的转移矩阵.通过以上的方式,处理x的网络拓扑结构,在经过l层的GCN迭代之后,其网络特征表示为所有节点表示的平均.具体如式(4)所示.

对于文本特征Dx,本文使用Transformer 进行处理.Transformer 使用多头的self-attention 处理序列输入.具体如式(5)所示.
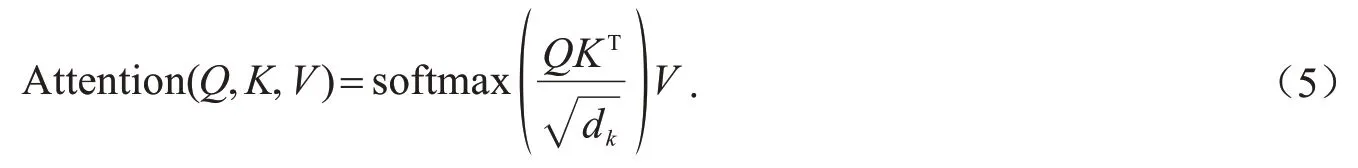
其中:Q、K、V分别表示查询、键、值,本文计算目标被引量时,三者都为序列中单词的表示.同样地,经过l层的处理之后,通过平均池化得到论文x的文本表示特征.论文x的最终表示X及其被引量预测损失通过式(6)和式(7)计算.

该损失为均方误差损失,FF1为前馈神经网络,用于将论文表示X计算得到预测值,lx为真实被引量,n为样本总量.
3.3 论文被引量差值预测
为了使模型能够获取对于被引量更重要的特征,同时增强模型的泛化能力,本文在预测目标论文x被引量的基础上,引入论文被引量差值预测的额外任务.具体思路是:对于目标论文x,在数据集中采样对比样本y,通过神经网络的中间过程计算两者的交互特征,并基于此预测两者的被引量差值.这样,被引量的差距预测能够有效指导神经网络的中间计算过程,进而影响被引量预测模型,使其具有更高的预测能力和泛化性.
对于x、y的网络特征Gx、Gy,使用GCN进行处理,进而能够获得它们在每层的表示.对于文本特征,除了使用Transformer分别处理得到文本表示之外,本文通过它们之间的交互来增强表示,如图2所示.
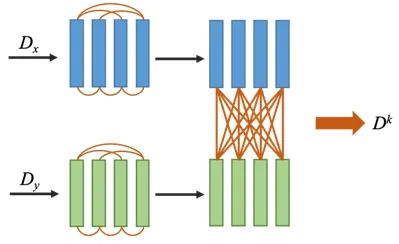
图2 文本特征融合示意图Fig.2 The text feature fusion
将3.2 节中经Transformer 处理后的文本表示矩阵分别表示为(用于后续论文被引量预测),之后计算两者之间的交互.具体来说,在式(5)所示的self-attention 中,将Q进行彼此替换,其他设置保持不变,这样相当于对x、y的文本进行逐词对比,期望获取文本差异对于被引量的影响因素.基于此,得到两者对应的交互表示,进而将两者进行平均池化并加和得到x、y在第k层的文本交互表示Dk.综上,论文被引量差值的特征表示可通过式(8)计算为:

类似地,其损失函数也可通过式(9)均方误差损失函数计算为:

其中:lx、ly分别表示x、y的真实被引量;m表示总的对比样本对数;FF2为计算被引量差值的前馈神经网络.
3.4 联合学习
基于论文被引量预测和被引量差值预测的损失,设计了如下的联合损失函数来进行统一的多任务联合训练:

其中,λ是用于权衡模型对于被引量预测和被引量差值预测损失的权重.
4 实验结果与分析
4.1 实验数据集
通过网络爬虫采集了2010—2019 年间在交通领域30 本期刊上发表的相关论文,包含论文标题、摘要、作者、发表地、机构、年份和实际被引量等,相关数据统计如表2所示.在进行实验时,2010—2018年的论文作为训练集,2019年度发表的论文作为测试集.

表2 数据集相关统计Tab.2 Dataset related statistics
4.2 对比模型与实验参数设置
为了验证本文基于多任务学习模型的有效性,实验设置了如下的神经网络对比模型.
神经网络模型(NN)[15].通过带有隐藏层的前馈神经网络处理论文的相关特征,最后相加融合来进行论文被引量预测.
基于神经网络的被引量预测(NNCP)[8].一种基于编码-解码框架的深度神经网络模型,其将论文发表后某个时间段内的被引量作为输入,之后某时间段内的被引量作为输出.
基于图卷积嵌入与特征交叉(GCN-FC)[16].一种考虑论文关键词、作者、机构和国家等相关因素,使用GCN进行特征提取,并利用循环神经网络与注意力机制来挖掘被引量与论文特征之间的关联.
混合LSTM 注意力模型(Hy-LSTM-Att)[17].构建论文相关的异构数据,包含图结构、时序数值和文本等,初始化后通过双向注意力LSTM处理,将最终的表示通过前馈网络计算预测被引量.
在实验过程中,首先将图结构通过TransR 方法进行预处理,得到128维的向量表示;并将论文的标题和摘要文本通过Doc2vec处理,也表示为128 维的向量.从总图结构G中抽取目标论文的k阶子图时,k默认设置为3.在进行训练时,对于目标论文x,随机采样同一年度发表的论文y作为对比进行多任务学习;模型最大层数l设置为5,每层嵌入的维度都默认设置为128,模型使用学习率为0.001 5的Adam算法[18]进行优化,最大迭代次数设置为15.在整体的损失函数中,权重λ被设置为0.2.模型测试时,仅仅使用论文被引量预测部分,论文被引量差别预测部分不进行计算.
4.3 评价指标
本文使用回归任务常用的均方误差(mean square error,MSE)和平均绝对误差(mean absolute error,MAE)作为主要评价指标,它们都用来衡量预测值与真实值之间的差距,MSE 与MAE 越小,说明模型的预测更准确.它们的计算方式如式(11)和式(12)所示.

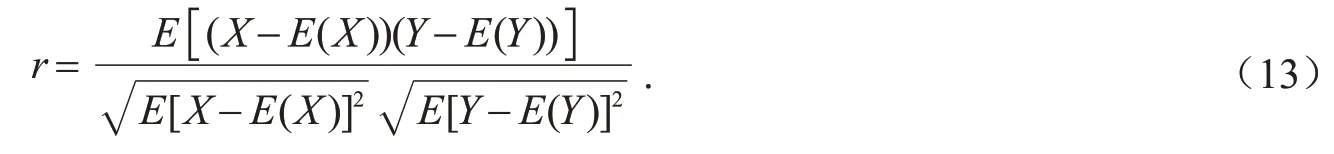
其中:E(X)表示随机变量X的数学期望;r>0表示两个随机变量呈正相关,且绝对值越大,说明其相关程度越高.
4.4 模型对比结果
不同模型在各个指标上的得到的结果如表3所示.可以看出,提出的基于多任务学习的模型取得了最好的预测效果.其中NN模型表现最差,MSE与MAE较本文模型分别差34.26和1.65,这是因为它仅通过简单的神经网络处理原始论文数据;NNCP、GCN-FC 和Hy-LSTM-Att 都取得了良好的效果,这是由于它们都挖掘了论文相关数据的对应特征,并设计了特定的方法进行建模;在之前最优模型Hy-LSTM-Att 的基础上,本文的模型在三个指标上分别获得了3.49、0.44和0.02的提升,这说明本模型的先进性,显示出通过挖掘论文预测相关任务并进行多任务联合学习对于提升论文被引量预测的潜力.

表3 各模型的性能对比Tab.3 Performance comparison of each model
4.5 消融实验
为了验证模型中各个模块的作用,进行了消融实验.实验结果如表4所示(w/o表示消融某个模块).

表4 各模块的消融实验结果Tab.4 Ablation experiment results of each module
其中w/o L2表示模型去掉论文被引量差值预测部分.从显示的结果可以看出,随着论文被引量差值预测部分的去除,各项指标都会大大降低.这表明论文被引量差值预测在整个模型中具有积极的作用,其原因在于该差值可以有效地挖掘文献之间的隐性关联特征,并且可以对模型中神经网络的中间计算过程进行正确的引导.
w/o Inter则表示在论文被引量差值预测部分,去掉论文对的交互表示计算,仅保留本身的Transformer 计算.由表4 可知,该模块也会影响模型的性能,但是较L2的程度低,这是因为Inter 事实上是L2计算的一部分,并不能完全体现被引量差值的功能,因此对模型的影响力相较L2部分较弱一些.
另外,w/o GCN 和w/o GCN-Att分别表示去掉整个GCN 计算和去掉GCN 计算中的注意力机制.前者在预测时仅仅使用TransR 的嵌入结果,从结果可以看出,去掉整个GCN 计算后各项指标均大幅下降.这表明图卷积神经网络对模型的预测结果具有积极的作用.而仅仅去掉GCN 计算中的注意力机制虽然影响效果不如去掉整个GCN 计算模块,但还是会产生一定的影响.这表明模型中注意力机制的引入能够很好地挖掘出被引量与论文特征之间的关联,从而更好的对文献被引量进行预测.
5 结语
基于多任务学习的思想,针对论文被引量预测任务,提出了额外的被引量差值预测方法来增强模型的建模能力,进而提升了模型的预测性能和泛化性.在多任务学习中,两个任务共享部分模型架构,对于被引量差值预测,使用额外的神经网络进行建模,使得模型整体上既有耦合的部分,又有分散的部分.实验结果证明本模型取得了优异的性能,且本文提出的模块对于预测结果都具有积极作用.这显示通过构造相关的任务,并使用多任务学习框架来提升论文被引量预测的巨大潜力.
