改进的YOLOv5-ResNet相似目标检测方法
2022-12-05赵桂平邓飞王昀唐云
赵桂平, 邓飞*, 王昀, 唐云
(1.成都理工大学计算机与网络安全学院(牛津布鲁克斯学院), 成都 610059;2.中国石油化工股份有限公司石油物探技术研究院地震采集技术研究所, 南京 211103)
目标检测是一种与计算机视觉和图像处理相关的计算机技术,用于检测数字图像和视频中某类语义对象的实例,一直是计算机视觉领域的热门研究话题。目标检测作为场景理解的重要组成部分,广泛应用于现代生活的许多领域,如安全、军事、交通、医疗和生活领域。
传统的目标检测方法的主要流程为:首先要选定候选区域,使用如SIFT[1]、HOG[2]、Haar等方法提取候选区域中的特征,再使用如Adaboost[3]、SVM[4]等分类器进行分类。传统方法在目标检测中具有一定效果,但是当图像特征不明显或目标相似程度较高时,检测效果还不够理想。
近些年来,基于深度学习的目标检测方法发展迅速。Girshick等[5]首次提出了基于深度学习的目标检测方法R-CNN,先使用选择性搜索[6]得到候选区域,再提取候选区域的特征并分类,最后对目标框位置进行回归,而R-CNN的训练步骤繁琐,运行速度缓慢。Girshick[7]提出Fast R-CNN,简化了一定的训练步骤,运行速度有了一定提升。Ren等[8]提出了Faster R-CNN,使用区域推荐网络(region proposal networks, RPN)替代选择性搜索生成候选区域,同时将候选区域生成、特征提取与分类、边框回归统一到一个网络中,实现了端到端的训练测试。Redmon等[9]提出了YOLOv1将边框回归和目标分类整合于单个网络模型中,大大提高了检测速度,使实时检测成为可能,随后,Liu等[10]提出了SSD(single shot multiBox detector),采取了多尺度特征融合的方法,提高了检测的准确率。Lin等[11]提出RetinaNet,使用Focal loss解决了类别不平衡问题,提升了检测准确率。Bochkovskiy等[12]提出了YOLOv4,引入空间金字塔池化(spatial pyramid pooling, SPP)[13]的思想扩大感受野,加入多尺度特征融合,进一步提升准确率。郑伟等[14]利用空洞模块改进YOLOv4的特征融合模块,提取更多的位置信息和语义信息,进一步减少了目标的误报率。
在实际应用中存在相似目标检测问题。相似目标是指外形轮廓上相似,但存在一定细节差异的目标,因此相似目标具有不同的语义,必须加以区分,如周宇杰等[15]对输送带的损伤部位进行检测和布申申等[16]对带钢表面缺陷进行检测,近似相同的缺陷因为产生的原因不同导致修复的工艺不同,岳有军等[17]对温室内种植的番茄进行成熟度检测,形状和色彩相似的番茄,但成熟度不同,通过检测能够及时得到作物信息,减少管理成本,增加经济效益。在相似目标检测问题下,以Faster R-CNN为代表的两步法准确率较高,但检测速度慢,以YOLOv5为代表的一步法在检测速度上较快,但准确率较低,呈现出“一步法不准、两步法慢”的问题。
针对该问题,现以YOLOv5为基础并参考Faster R-CNN两步法,将网络分为边框生成网络和分类预测网络两个部分,其中边框生成网络以YOLOv5为主体,增强特征的融合能力,改进边框过滤算法,提高边框过滤速度,分类预测网络使用以添加注意力机制模块的轻量化ResNet34网络,加快分类计算速度的同时保持分类的高准确率,实现对相似目标快速、准确检测。
1 目标检测网络原理分析
目标检测方法分为一步法和两步法,它们主要的区别是:一步法将边框的生成和类别的预测由单个网络输出,再筛选出最佳的预测结果;两步法先生成众多的边框,再从其中筛选出含有前景的边框,接着计算边框中目标的分类,得到最终的预测结果。
一步法以YOLOv5为例,YOLOv5先将输入的图像切分为网格,经过主干网络提取到不同层级的特征,再将不同层级的特征进行融合,在融合操作中,特征尺度不改变,最后在不同层级的图像特征上进行预测,首先找出目标对象中心所在网格,根据网格中的局部图像对目标进行预测,如图1所示,每个网格都会预测含有前景的概率,生成前景概率分布图,最后筛选得到目标中心所在的网格(如图1中概率大小为0.9的网格)。
接下来,网络对每个网格预测一组类别概率序列,如图2所示,序列中每一个值分别代表一个类别在该网格的概率,同时生成锚定框并进行位置回归得到备选边框。网络最终输出的备选边框包含的信息为
bbox=(x,y,w,h,confobj)+
(confcls1,confcls2,…,confclsn)
(1)
式(1)中:(x,y)为边框左上角点的坐标;(w,h)为边框的宽度和高度;confobj为边框包含前景的概率;(confcls1,confcls2,…,confclsn)为边框的类别概率序列。
上述步骤中,网络产生了数量众多的边框,需要从中筛选出最好的检测结果。先以边框的类别概率序列为基础,依次对每一类别使用非极大值抑制算法(non-maximum suppression, NMS)[18],将被抑制的类别概率置零,再选出序列中的最大值,即

图1 前景概率分布图Fig.1 Foreground probability distribution

图2 位置回归与类别预测Fig.2 Location regression and category prediction
confcls,并与confobj计算边框的最终概率值conf,即
conf=confobj×confcls=
max(confcls1,confcls2,…,confclsn)
(2)
接着去除conf较低的边框,再以边框的类别为分组,对剩下的边框使用非极大值抑制算法过滤得到最终检测结果。
两步法以Faster R-CNN为例,Faster R-CNN先将输入的图像经过主干网络提取到最终的特征图,再根据特征图的尺寸生成多组锚定框,如图3(a)所示,红点为每一组锚定框的中心点,图3(b)为其中一组锚定框。
在生成所有锚定框之后(图4),RPN对每一个边框都预测两个值,分别是表示锚定框中内容为背景的概率confbk和表示边框中内容为前景的概率confobj,接着过滤confobj较小的锚定框,使用NMS算法再过滤部分边框得到备选框。对备选框进行位置回归,并将备选框中的特征经过ROI pooling层统一尺度,再输入分类层得到框中目标的类别,最后,以类别为参考对备选框进行分组,使用NMS算法得到检测结果。
通过对比YOLOv5与Faster R-CNN的检测过程,可以发现两者都需要经过特征提取、边框位置的回归和类别预测3个步骤,但是最关键的两个步骤——边框位置的回归和类别预测,YOLOv5中这两个步骤是同时进行的,以网格为单位产生边框并回归位置,同时预测类别,而Faster R-CNN是分别进行的,RPN先对所有生成的边框做一次的二分类,判断边框中内容属于前景还是背景,由此选出包含前景的边框,再将边框中的内容输入到分类层预测类别。与Faster R-CNN相比,YOLOv5大幅减少了边框位置回归计算,因此YOLOv5检测速度快很多。但在分类预测方面,为了进一步提高检测效率,YOLOv5仅以网格中的局部图像进行类别预测,导致其分类准确率在相似目标检测中远低于Faster R-CNN,同时也可能漏检一些小目标。

图3 Faster R-CNN的锚定边框Fig.3 Faster R-CNN’s anchors

图4 RPN生成候选区域Fig.4 RPN generates proposal region
2 改进YOLOv5-ResNet相似目标检测方法
2.1 网络总体架构
为解决上述相似目标检测任务中“一步法不准,两步法慢”的问题,提出了改进的YOLOv5-ResNet网络模型,网络总体结构如图5所示,以YOLOv5为基准模型,参考两步法,将网络分为边框生成网络和分类预测网络两个部分。其中边框生成网络部分,凭借YOLO计算速度快的优势,大大减少生成预测框所需要的时间;小目标被噪声淹没等原因导致的漏检,而添加特征融合结构能够很好地解决噪声淹没的问题,因此改进特征融合结构,建立了原始特征与融合后特征之间的联系,使预测框的位置回归更加准确;针对改进后的边框生成网络输出的特点,改进过滤算法,提高过滤速度,降低因特征融合结构的添加在速度上的影响;原始的分类模块,结构简单,在分辨相似目标效果较差,需要进行强化,将拥有注意力机制的轻量化ResNet34[19]融合到分类模块,在增加少量计算参数的同时,强化原有分类结构,提高模型对相似目标的区分能力。

图5 模型整体框架Fig.5 Model framework
图5中边框生成网络的主干部分用于提取出不同层级的特征,由Focus模块、卷积模块、C3模块、空间金字塔池化模块组成。如图6所示,Focus模块将输入图像在不同通道上分别在纵向和横向进行切片再拼接,输入的深度由3提升到了12,输出深度比卷积下采样提升了4倍,以此保留更多的信息。

图6 Focus操作Fig.6 Operation of Focus
Conv模块对输入依次进行Conv2d、BN、ReLU操作,为网络的基本卷积模块,其结构如图7(a)所示。C3由若干个残差单元[图7(b)]组成,在不增加输出深度的同时完成特征传递,其结构如图7(c)所示。空间金字塔池化对输入执行3种不同尺寸的最大池化操作,并将输出结果与原始值进行拼接,其结构如图7(d)所示。
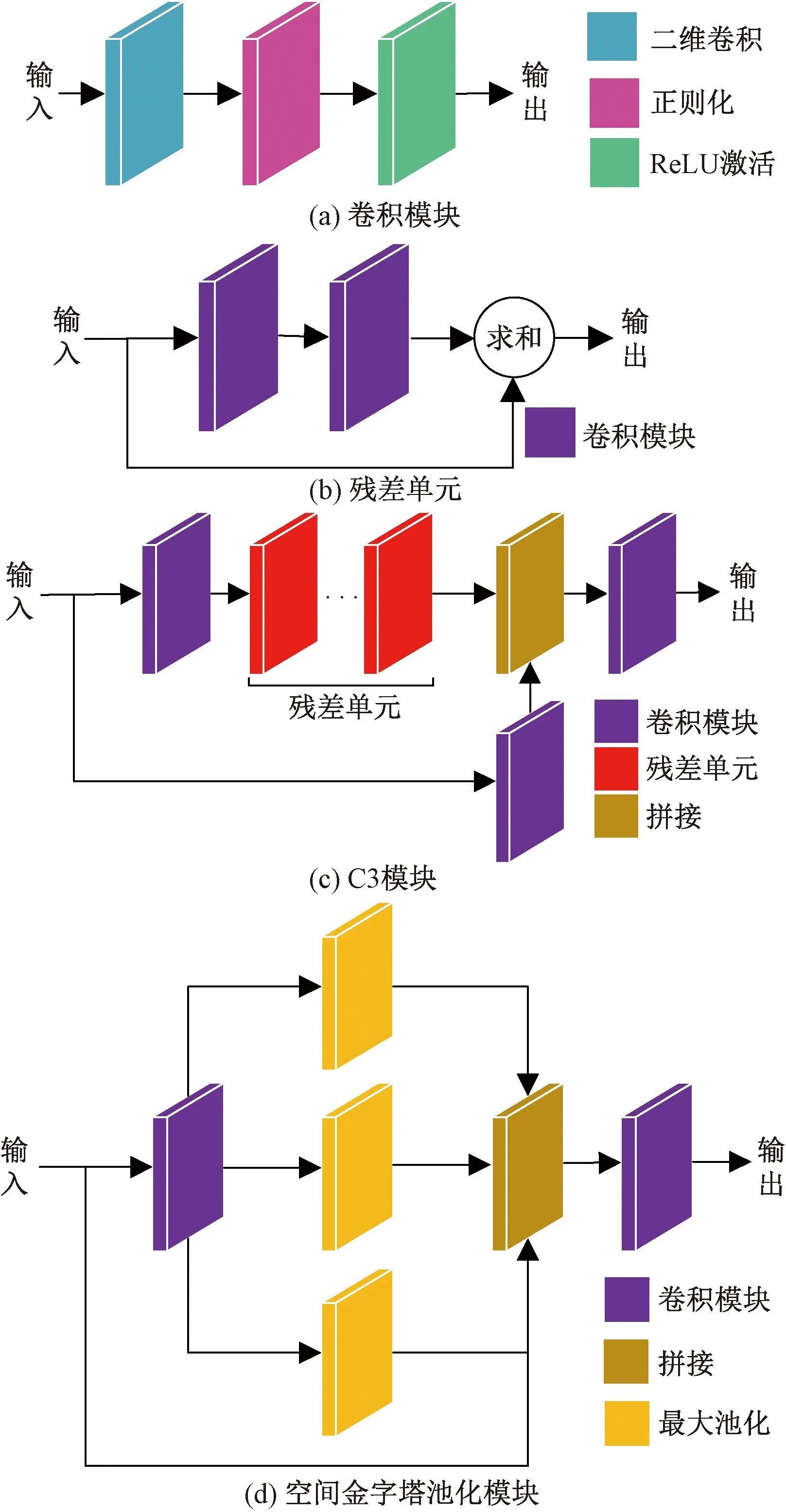
图7 主要模块结构Fig.7 Main modules structure
特征融合部分的作用是将主干部分提取的不同层级的特征进行融合,其核心为特征融合结构,由特征金字塔(feature pyramid networks,FPN)[20]结构和路径聚合网络(path aggregation networks,PAN)[21]结构组成,主要由C3和卷积模块构成。特征融合结构中,按照特征传递方向,分别在2倍上采样和2倍下采样后与下一层级特征做add操作达到融合不同层级特征的目的,强化特征提取能力。
检测部分用于在特征图中进行检测,将特征融合部分得到的3种不同层级的特征输入检测模块进行检测,得到边框的位置信息(x,y,w,h)和框中包含前景的概率大小confobj,最后使用边框过滤算法,得到前景框。
上述产生的前景框尺度不统一,不能直接输入到分类网络。在输入分类网络前,截取前景框中的目标特征,首先以前景框的长宽中最大者确定缩放比例进行重塑,然后对另一个方向进行填充,再输入到分类网络,预测得到类别值id与类别概率值confcls,结合边框的信息计算输出(x,y,w,h,conf,id),其中conf为目标框的最终概率值。
2.2 损失函数
损失函数是衡量网络的输出结果与期望结果一致性的指标。相似目标检测方法的输出结果中,每个预测框具有位置和置信度,其中,置信度又分为对象置信度与类别置信度。损失函数则必须对上述的位置和置信度进行评价,分别计算位置损失、对象损失和类别损失,最后加权计算得到整体的损失。因此,本文方法的损失函数由3部分组成,计算公式为
loss=lossbbox+lossobj+losscls
(3)
式(3)中:lossbbox为位置损失;lossobj为对象损失;losscls为分类损失。
lossbbox采用了完全交并比损失(complete intersection over union loss, CIoU Loss)进行计算。CIoU Loss相比传统的交并比损失(intersection over union loss, IoU Loss),不仅考虑到了重叠面积,还考虑到了中心点距离和框的长宽,对框的位置进行了全面评估,使得模型能够产生位置更加准确的预测框。其中CIoU计算公式为
(4)
式(4)中:IoU为预测框与真实框的交并比;ρ为预测框与真实框中心点的距离;c为预测框与真实框的最小外接矩形对角线的长度;ν为预测框与真实框长宽比距离;wgt和w分别为真实框和预测框的宽度;hgt和h分别为真实框和预测框的高度;α为一个权重系数。最终的lossbbox计算公式为
lossbbox=1-CIoU
(5)
lossobj采用二元交叉熵损失(binary cross entropy loss, BCE Loss),BCE Loss是交叉熵损失(cross entropy loss, CE Loss)的一种特例,并且同时考虑正样本和负样本的共同影响。CE Loss计算公式为
lossCE=-[glogap+(1-g)loga(1-p)]
(6)
式(6)中:g为真实值;p为预测值;a为底数,一般情况下a取自然常数e。
预测框中是否存在目标对象只存在两种情况,因此式(6)中的参数g预测框中有对象时为1,否则为0。lossobj的计算公式为
lossobj=IobjlossCE(1,pobj)+λnoobjInoobj×
lossCE(0,pobj)
(7)
式(7)中:Iobj用于判断预测框中是否有对象,有对象时为1,没有对象时为0;Inoobj则反之,λnoobj为负样本权重,一般为1。
losscls采用CE Loss,对正样本的分类预测进行评估。计算公式为
losscls=-IobjlossCE(gcls,pcls)
(8)
式(8)中:Iobj用于判断预测框中是否有对象;gcls为目标实际的分类;pcls为目标预测的分类。
2.3 特征融合结构的改进
特征融合结构中,FPN将特征从高层向低层传递,PAN将特征从低层向高层传递。原YOLOv5的特征融合结构中,如图8(a)所示,高层特征中感受野大,大目标特征明显,小目标特征容易被背景和噪声淹没,低层特征中感受野小,上下文信息缺乏,容易产生小目标漏检,而小目标漏检是检测准确率下降的一个非常重要的原因。为克服小目标被淹没而导致漏检的问题,如图8(b)所示,原始特征经1×1卷积之后,与PAN结构中经过2倍下采样后的高层特征和FPN结构的同层特征进行求和操作,融合更多的特征,强化每个层级的目标特征。
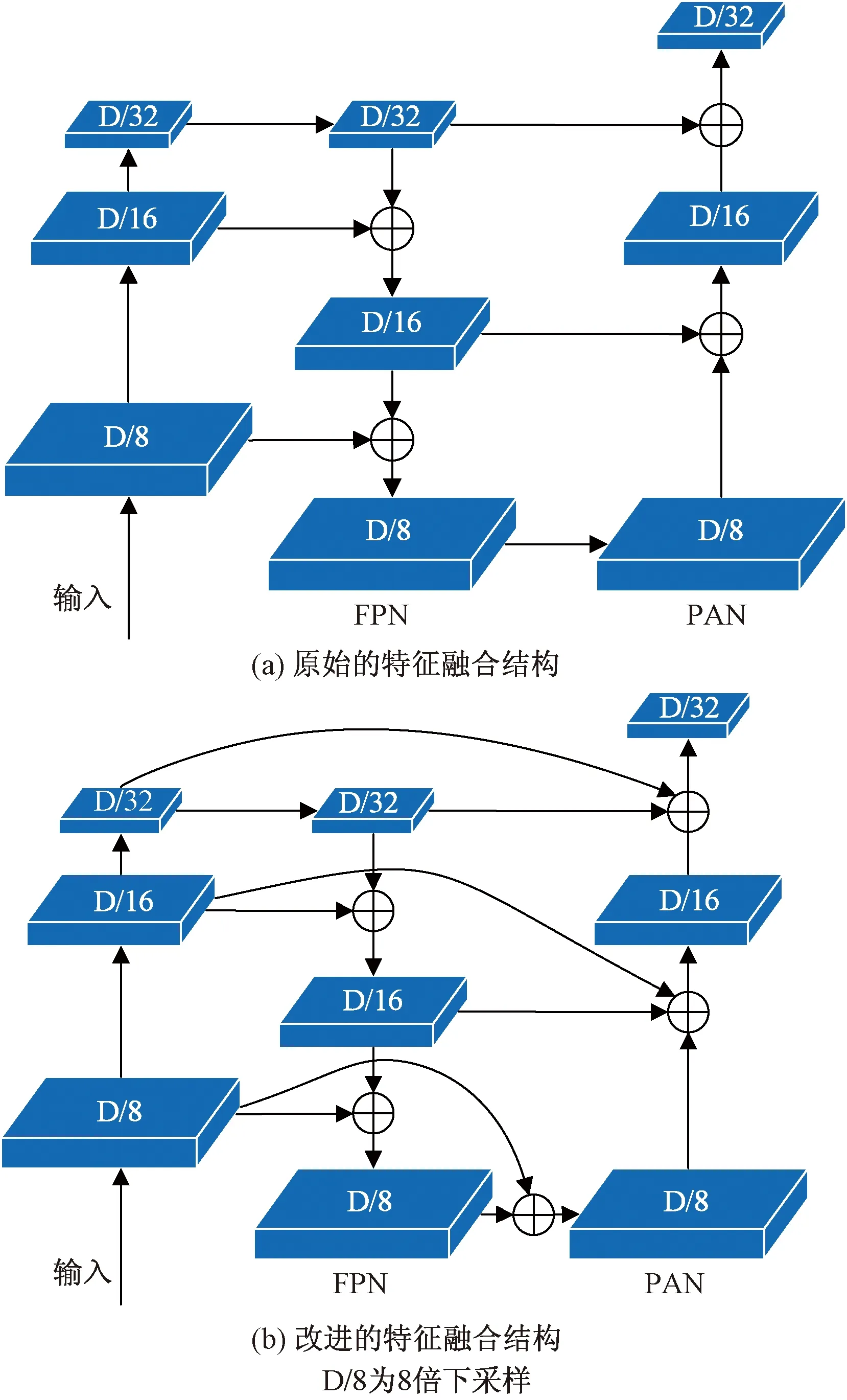
图8 原始与改进特征融合结构对比Fig.8 Comparison of original and improved feature fusion structures
针对上述改进,使用相同训练参数对未添加特征融合结构的边框生成网络、添加特征融合结构但未改进的边框生成网络和本文的边框生成网络进行消融实验,训练时损失变化曲线如图9(a)所示,可以看出改进后方法相比其他方法损失值更小,表明改进后的特征融合结构使边框生成网络能够产生更加准确的边框和前景判断,使用训练模型对验证集进行测试,准确率结果如图9(b)所示,添加特征融合结构的边框生成网络比未添加的准确率高约3%,而改进后的边框生成网络比未改进的高约10%,表明本文的改进有效地降低了网络的漏检率。

图9 特征融合结构消融实验结果对比Fig.9 Comparison of ablation experimental loss of feature fusion structure
2.4 边框过滤算法
改进的网络模型采用两步法,边框生成网络只预测前景而不再预测具体类别,因此可以删除原YOLOv5中检测部分的预测类别步骤,生成的边框信息变为(x,y,w,h,confobj),与原来式(1)生成的边框信息相比,少了类别概率序列。
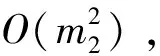

上述过程中,m1、m2、m3是过滤后得到的,其值远小于n,因此,原始生成目标框的算法时间复杂度可近似为O(n2),而本文算法时间复杂度可近似为O(n),因此在边框过滤步骤中,本文方法会快于原YOLOv5。
2.5 分类网络
YOLOv5原网络模型的类别预测模块,但该模块参数量较小,使用提取到的特征预测分类的结果很差,需要使用分类效果更好的网络替代,而在众多的分类网络中,目前最近发表的准确率高的分类网络普遍参数量大,如果直接应用与类别检测模块,将直接拉低整个网络的检测速度,而ResNet的准确率仅低于这些网络几个百分点,但参数量适中,速度远快于上述网络,因此能够很好地胜任类别预测模块的工作。本文使用的分类网络是由ResNet34修改得到的LiteResNet34-SE,由于ResNet34的参数量远大于原始YOLOv5的检测模块,直接使用会导致整体检测速度大幅降低。为此,首先对ResNet34进行轻量化操作得到LiteResNet34,将4个主要层级中的卷积通道分别从64、128、256、512降低到16、32、64、128,减少参数量,加快计算速度。降低卷积通道采样倍数后,网络的特征提取能力会减弱,区分出相似目标的性能会下降,为此在轻量化网络模型中引入SE模块[23]得到LiteResnet34-SE。在特征的通道方向上施加注意力机制,通过学习的方式获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征。SE模块使用卷积得到的维度大小为C×H×W的特征,计算出维度大小为C×1×1的向量,向量中的每个值就是特征中对应通道的权重,最后将权重施加到对应通道。添加SE模块后的轻量化残差块如图10所示。
针对上述改进,使用相同训练参数将Resnet34、LiteResnet34和LiteResnet34-SE3个网络各训练100轮并且每一轮设置验证,验证准确率曲线如图11所示,可以发现LiteResNet34相比ResNet34验证准确率下降近20%,而LiteResNet34-SE,在100轮左右准确率上升到与ResNet34近似,具有较好的分类力,保证了分类准确率。
通过统计模型的参数量和FLOPS得到表1,可以发现,LiteResNet34总参数量和FLOPS相比ResNet34大幅减少,而添加了SE模块后,参数量只有小幅增加,相比原ResNet34,降低了参数量,加快了类别的预测计算速度。
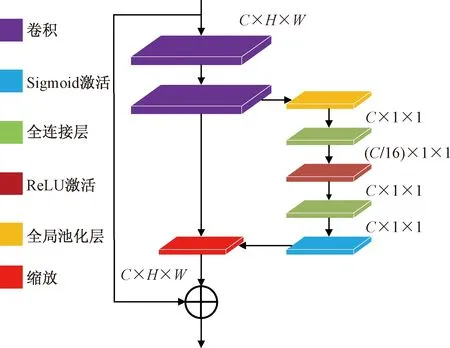
C、H、W分别为该输入输出的通道数、高度、宽度图10 拥有SE模块的轻量化残差块Fig.10 Lightweight residual block with SE module

图11 3种残差网络在验证集的准确率曲线Fig.11 Accuracy curves of three residual networks on val dataset

表1 3种残差网络参数量、性能以及训练时间对比Table 1 Comparison of parameters, performance and training time of three residual networks
3 实验结果与分析
3.1 数据集
为了验证本文提出的相似目标检测方法,实验使用了斯坦福宠物狗数据集[24]和自制音符卡片数据集。
斯坦福宠物狗数据集中,如图12所示,各个类别之间在外形、动作上存在一定相似性,能够用于验证改进后方法的有效性,但是各个类别之间在色彩、体貌上还是存在一定差异。
为了进一步验证改进后方法的有效性,使用了自制的音符卡片数据集,如图13所示,音符种类多并且存在许多相似度非常高的种类,如图14所示,截取了小部分音符卡片在数据集中的图像,可以看出不同种类的音符卡片在不仅在外形,还在色彩、内容上保持了非常高的相似性,因此使用该数据集能够更好地证明本文方法对相似目标检测的有效性。

图12 斯坦福宠物狗数据集样本Fig.12 Stanford dogs dataset samples

图13 音符卡片数据集样本Fig.13 Note card dataset samples

图14 部分相似的音符卡片截取图Fig.14 Screenshots of several similar music note cards
斯坦福宠物狗数据集包含120种不同种类的狗,每种有148~252个样本图像,共20 580张图像,其中12 000张作为训练集,2 000张作为验证集,6 580张作为测试集。
音符卡片集包含273种不同类别的音符,每种有140~150个图像样本,共40 000张图像,其中25 000张作为训练集,5 000张作为验证集,10 000张作为测试集。
3.2 模型评估方法
实验分别对模型的准确率和性能两个方面进行评估。准确率方面选用平均准确率@0.5: 0.95作为模型精度衡量指标,衡量模型在不同IoU阈值下的综合表现,平均准确率@0.5: 0.95的值越高表示模型高精度边框回归能力越强,检测结果与原始标签拟合越精准。性能方面,指标使用帧率(frame per second, FPS)进行评估,如式(9)所示,其中T为测试所用总时间,countimg为进行测试的图像总张数。
(9)
3.3 实验结果对比
本文实验环境为:NVIDIA RTX 3060,Pytorch 1.8.0,CUDA 11.1。实验将改进的YOLOv5-ResNet与一些主流的目标检测网络进行了对比,分别包括YOLOv5、SSD、RetinaNet和Faster R-CNN,使用3.1节中的两个数据集对网络进行训练测试。训练期间在斯坦福宠物狗验证集上的正确率曲线对比图,如图15(a)所示,本文方法收敛速度和验证准确率都高于其他方法。在自建的音符卡片数据集上,如图15(b)所示,本文方法收敛速度仅略慢于Faster R-CNN,准确率均高于其他方法。

图15 训练期间在验证集的mAP曲线Fig.15 mAP curve in validation dataset during training
训练结束后,使用未参与训练的测试集在准确率、性能方面进行评估,各个网络的测试结果对比如表2所示。
在斯坦福宠物狗数据集上,本文方法的mAP相较于YOLOv5、SSD、RetinaNet、Faster R-CNN,分别提升8.1%、15.2%、9.2%、8.3%,检测帧率相较于YOLOv5降低18.19帧,相较于SSD、RetinaNet、Faster R-CNN分别提高20.64、32.19、33.69帧。
在音符卡片数据集上,本文方法的mAP相较于YOLOv5、SSD、RetinaNet、Faster R-CNN,分别提升45.4%、11.2%、1.2%、1.9%,FPS相较于YOLOv5降低14.91帧,相较于RetinaNet、SSD、Faster R-CNN分别提高27.33、20.64、26.38帧。
图16和图17所示为检测效果图,3组测试图像是分别从2个数据集的测试集中随机挑选的。
在图16和图17中,测试分为3组,每一行从左至右分别为YOLOv5、SSD、Faster R-CNN、RetinaNet和本文方法的检测结果。从对比中可以看出,YOLOv5测试结果效果最差,存在大量的漏检;SSD、RetinaNet、Faster R-CNN虽然漏检率少于YOLOv5,但存在将多个目标检测为一个目标的情况并且目标框有越界的情况;而本文方法没有漏检,且目标框也更加准确。

表2 不同方法在测试集的结果对比Table 2 Comparison of results of different methods in test dataset

图16 Stanford dogs dataset不同算法检测部分结果对比Fig.16 Comparison of detection results of different algorithms in Stanford dogs dataset
实验结果表明,原始YOLOv5在有一定相似度的Stanford Dogs Dataset上有一定准确率,但在自制的音符卡片数据集上准确率较差,因为YOLOv5仅以局部特征进行类别预测,目标物体差异越小越近似,YOLOv5的识别能力就越差,而改进后的网络有效克服了YOLOv5的这些问题,因此能够很好地处理相似目标的检测。Faster R-CNN网络虽然在两个数据集中准确率都比较高,但检测速度缓慢,本文方法虽然较原始YOLOv5损失一定的检测速度,但也远快于Faster R-CNN,并且满足实时检测的需要。综上,本文方法很好地解决了相似目标检测“一步法不准,两步法慢”的问题。

图17 音符卡片数据集不同算法检测部分结果对比Fig.17 Comparison of detection results of different algorithms in notes cards dataset
4 结论
针对实际应用中的相似目标检测问题,提出了一种改进的YOLOv5-ResNet网络模型。其主要特点如下。
(1)以YOLOv5作为边框生成主干网络,并借鉴了两步法,使用专门的分类网络预测目标分类。
(2)改进边框生成网络的特征融合结构,加强特征融合,克服目标因卷积下采样被噪声或背景淹没的问题,降低了漏检率、错检率。
(3)使用了轻量化ResNet34网络进行分类预测,并引入了SE模块,提升有用特征的权重,保证了分类准确率。
两种相似目标检测数据集的测试表明,本文提出的网络模型不仅具有较高的检测速度,能够满足实时检测任务的需求,而且具有很高的准确率,整体效果优于现有常规目标检测网络,可以很好地应用到实时的近似目标检测问题中。
