江苏高校图书馆网站分类模型构建及优化策略研究
——基于决策树算法和链接分析法
2022-12-05刘庆旭夏小青
刘庆旭,夏小青
(南京工业大学浦江学院 图书馆,江苏 南京 211200)
2012年3月,教育部颁发了《教育信息化十年发展规划(2011-2020)》,就“促进优质教育资源的建设与共享”等教育信息化资源建设内容作了重点阐述[1]。2018年教育部印发《教育信息化2.0行动计划》,强调以信息化引领构建以学习者为中心的全新教育生态,实现公平而有质量的教育,并提出要到2022年基本实现“三全两高一大”的发展目标,其中,“两高”指的是信息化应用水平和师生信息素养普遍提高[2]。高校图书馆网站是高校落实教育部规划,积极推进教育信息化的重要组成部分,高校图书馆网站建设水平直接关系到高校信息化的推进程度。
目前,高校图书馆网站研究是学术界研究的重点领域,国内外学者均给予重点关注和研究。White E等[3]研究了门户网站的内容对学术图书馆员和其他利益相关者的教育作用,同时还以恩克鲁玛科技大学作为案例,研究了图书馆门户网站在增强用户学术交流培训方面所起到的作用。Desmarais B等[4]描述了2020年春季学期在东北州立大学进行的一项研究,该研究详细介绍了网站重新设计过程的初始阶段,这些过程是从网站设计和功能的在线调查中收集到的反馈信息。用户体验调查后得到的结果用于衡量受访者对图书馆网站的满意度,并为以后的重新设计策略提供信息。数据将用于规划和评估大学网站设计项目的下一阶段。Brunskill A[5]采访了12名残疾大学生,了解他们对学术图书馆门户网站导航、搜索词以及网页界面的看法,这些访谈揭示了围绕网站可访问性和包容性的许多重要考虑因素,并据此编制了一份建议清单。国内学者张超[6]从用户角度对高校图书馆网站进行了多维分类。刘荟岭[7]选取30所农业类高校图书馆网站进行调查,针对传统服务、个性化信息服务、参考咨询服务和用户分类服务等栏目展开分析,并结合网站服务现状提出了一些建议。宋爱林[8]基于前期调查的结果,设计一个包含TAG标签的复合分类导航系统,并阐述了实现方案,力求创建一种允许读者参与的立体化数字资源导航模式。
从现有研究成果看,国内外学者对图书馆网站都保持了较高关注度和研究热情,但运用数据挖掘的方法,将决策树算法运用到高校图书馆网站分类的研究成果还较少。笔者将决策树算法和链接分析法相结合运用到高校图书馆网站分类研究中,以期解决如下三方面的问题:①哪些指标对高校图书馆网站分类能够产生较大影响?②各项指标按照重要性如何排序?③基于决策树算法和链接分析法的高校图书馆网站如何分类?文中的研究从理论层面可以推动我国高校图书馆网站分类研究的理论分析,在实践层面上可以为高校图书馆网站的建设和分类起到参考和借鉴作用。
1 理论基础
1.1 决策树算法
决策树算法是一种以决策树数据结构为基础的分类算法[9],其基本思想是通过一些判断条件对原始数据集逐步二分和细化。其中,每一个分叉点代表一个决策判断条件,每个分叉点下有两个叶节点,分别代表满足条件和不满足条件[10]。决策树算法的目标是发现数据中潜在的分类规则,因而其核心内容是构造一个高精度、小规模的决策树,通过从数据集中自动地构造决策树,从而可以根据这个决策树对任意实例进行判定[9]。
1.2 链接分析法
所谓链接分析法,是指一种基于引文分析法发展起来的,以网络链接为研究对象,利用搜索引擎、网络数据库和数学统计分析方法,对网络链接的分布规律和网络信息单元之间的链接规律进行分析研究的一种定量分析方法[11]。链接分析法是客观定量评价中较为重要的方法之一。它主要利用网络站点间链接正向肯定关系而对网站自身信息组织和揭示的科学性和合理性以及网站影响力进行间接评价[12]。
2 数据收集
2.1 数据来源
本次高校名单来源于2021年江苏省大学排名一览表中所发布的高等院校,共收集到江苏省高校数量137家,由于部分网站无法访问或收集不到数据19家,实际共收集高校数据118家。本次研究将以所收集到的118家高校图书馆网站数据为基础进行分析,部分高校图书馆网站原始数据及指标如图1所示。
2.2 统计指标
本次数据收集指标共包括12项,分别为总网页数、总链接数、网络影响因子、PC词数、移动词数、反链数、索引量、一月收录、百度权重、移动权重、360权重、搜狗权重,总网页数、总链接数、网络影响因子指标采集方式及其含义来自已有文献,总网页数指标数据采集方式为“site+域名”,总链接数指标数据采集方式为“http://+域名”,网络影响因子指标数据为总链接数与总网页数的比值。PC词数、移动词数、反链数、索引量、一月收录、百度权重、移动权重、360权重、搜狗权重均通过第三方网站站长工具查询获得。百度权重、移动权重、360权重、搜狗权重其含义类似,但是考虑到百度PC端、百度移动端、360搜索、搜狗搜索在我国搜索引擎中均具有较大数量的用户群,因此,笔者未做取舍,全部对数据进行了收集。各项指标的具体含义如下所述。
ZB1总网页数[12]:是指网站内网页的总数,在一定程度上反映了网站的规模和内容的丰富程度。
ZB2总链接数[12]:即所有链接到该网站的链接数量,被普遍用于衡量网站的影响力和网络辐射力。
ZB3网络影响因子=总链接数/总网页数,反映了网站网页被链接的能力。
ZB4 PC词数:指在电脑端有排名的关键词词数。
ZB5移动词数:指在移动端有排名的关键词词数。
ZB6反链数[13]:就是指从别的网站导入某网站的链接数量,导入链接对于网站优化来说是非常重要的一个过程,导入链接的质量直接决定了某网站在搜索引擎中的权重。
ZB7索引量:指的是搜索引擎抓取网页并经过层层筛选后选取的页面数量,即当网站提交给搜索引擎后,它会派蜘蛛或机器人去目标网站抓取页面,获取到的网址会被整理,按照一定层次分配到索引库中,对网站SEO优化有很大的帮助。
ZB8一月收录:指一个月内网站中的某个页面被百度收录的次数。
ZB9百度权重:指的是站长工具等第三方平台以百度关键词排名情况所带来的预估流量为标准,对网站划分等级。
ZB10移动权重:指的是站长工具等第三方平台以百度移动端关键词排名情况所带来的预估流量为标准,对网站划分等级。
ZB11 360权重:指的是站长工具等第三方平台以360关键词排名情况所带来的预估流量为标准,对网站划分等级。
ZB12搜狗权重:指的是站长工具等第三方平台以搜狗关键词排名情况所带来的预估流量为标准,对网站划分等级。
3 实证分析
3.1 数据描述
本次共收集到118家江苏高校图书馆网站数据参与研究,对高校所属地域和层次进行统计发现,南京占比最大,共有39家,紧随其后的是苏州、常州等城市,数量最多的为高职院校,普通本科院校、民办院校、重点高校的数量依次递减。具体统计结果如图2和图3所示。运用R语言软件对各项统计指标数据进行统计并总结,统计结果包括各项指标的最小值、第一分位数、中位数、平均值、第三分位数、最大值,各项统计指标具体描述结果如表1所示。

表1 原始数据统计指标数据
3.2 建立回归树
本次决策树构建使用rpart函数,因总网页数相对于其他指标更能反映出网站建设的规模和质量,因此选择“总链接数”“网络影响因子”“PC词数”“移动词数”“反链数”“索引量”“一月收录”“百度权重”“移动权重”“360权重”“搜狗权重”共11个变量对“总网页数”变量建立决策树,且选择树的类型为回归树。具体执行代码如下所示:
> setwd("D:")
> getwd
function ()
.Internal(getwd())
> dat<-read.csv("gaoxiaoshuju.csv",header=F)
> dat<-read.csv("gaoxiaoshuju.csv",header=F)[,7:18]
> library(rpart)
Warning message:
程辑包‘rpart’是用R版本4.0.5 来建造的
> dat<-read.csv("gaoxiaoshuju.csv",header=T)[,7:18]
> formula=总网页数~.
> rp=rpart(formula,dat,method="anova")
> print(rp)
n= 118
node), split, n, deviance, yval
* denotes terminal node
1) root 118 92068310000 13660.840
2) PC词数< 38 78 2358097000 3125.372 *
3) PC词数>=38 40 64170020000 34205.000
6) 一月收录>=23.5 15 2327233000 4866.667 *
7) 一月收录< 23.5 25 41185080000 51808.000
14) 百度权重< 1.5 10 1300020000 18900.000 *
15) 百度权重>=1.5 15 21836120000 73746.670 *
3.3 决策树结果分析
通过R语言软件对本次构建的决策树进行总结,得出如下研究结果。
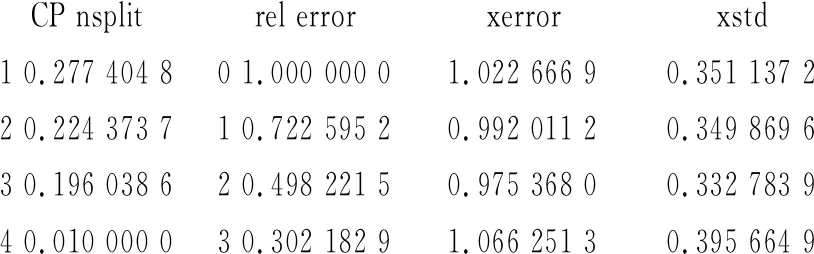
> summary(rp)
Call:
rpart(formula = formula, data = dat, method = "anova")
n= 118
CP nsplit rel errorxerrorxstd1 0.277 404 80 1.000 000 01.022 666 90.351 137 22 0.224 373 71 0.722 595 20.992 011 20.349 869 63 0.196 038 62 0.498 221 50.975 368 00.332 783 94 0.010 000 03 0.302 182 91.066 251 30.395 664 9
Variable importance

PC词数移动词数百度权重一月收录移动权重总链接数收录量反链数 2017151512777
Node number 1: 118 observations, complexity param=0.2774048
mean=13660.84, MSE=7.802399e+08
left son=2 (78 obs) right son=3 (40 obs)
Primary splits:
PC词数 < 38 to the left, improve=0.277 404 8, (0 missing)
百度权重 < 1.5 to the left, improve=0.266 369 3, (0 missing)
移动词数 < 20 to the left, improve=0.241 070 4, (0 missing)
总链接数 < 84950 to the left, improve=0.179 401 9, (0 missing)
收录量 < 710.5 to the left, improve=0.152 049 4, (0 missing)
Surrogate splits:
移动词数 < 20 to the left, agree=0.924, adj=0.775, (0 split)
百度权重 < 1.5 to the left, agree=0.881, adj=0.650, (0 split)
收录量 < 710.5 to the left, agree=0.873, adj=0.625, (0 split)
一月收录 < 4.5 to the left, agree=0.839, adj=0.525, (0 split)
移动权重 < 1.5 to the left, agree=0.839, adj=0.525, (0 split)
Node number 2: 78 observations
mean=3125.372, MSE=3.023201e+07
Node number 3: 40 observations, complexity param=0.224 373 7
mean=34205, MSE=1.604 25e+09
left son=6 (15 obs) right son=7 (25 obs)
Primary splits:
一月收录 < 23.5 to the right, improve=0.32192150, (0 missing)
总链接数 < 14 to the left, improve=0.29964500, (0 missing)
网络影响因子 < 0.93 to the left, improve=0.26043570, (0 missing)
收录量 < 6566.5 to the right, improve=0.12198390, (0 missing)
反链数 < 87 to the right, improve=0.06842155, (0 missing)
Surrogate splits:
总链接数 < 7.5 to the left, agree=0.800, adj=0.467, (0 split)
移动词数 < 62.5 to the right, agree=0.800, adj=0.467, (0 split)
PC词数 < 198 to the right, agree=0.775, adj=0.400, (0 split)
反链数 < 95.5 to the right, agree=0.775, adj=0.400, (0 split)
移动权重 < 2.5 to the right, agree=0.775, adj=0.400, (0 split)
Node number 6: 15 observations
mean=4866.667, MSE=1.551 489e+08
Node number 7: 25 observations, complexity param=0.196 038 6
mean=51808, MSE=1.647 403e+09
left son=14 (10 obs) right son=15 (15 obs)
Primary splits:
百度权重 < 1.5 to the left, improve=0.4382398, (0 missing)
搜狗权重 < 1.5 to the left, improve=0.3660384, (0 missing)
PC词数 < 87 to the left, improve=0.3509475, (0 missing)
移动词数 < 24.5 to the left, improve=0.2264878, (0 missing)
总链接数 < 78 to the left, improve=0.1951082, (0 missing)
Surrogate splits:
PC词数 < 65 to the left, agree=0.88, adj=0.7, (0 split)
移动词数 < 19 to the left, agree=0.84, adj=0.6, (0 split)
总链接数 < 14 to the left, agree=0.76, adj=0.4, (0 split)
反链数 < 14.5 to the left, agree=0.76, adj=0.4, (0 split)
移动权重 < 1.5 to the left, agree=0.76, adj=0.4, (0 split)
Node number 14: 10 observations
mean=18900, MSE=1.300 02e+08
Node number 15: 15 observations
mean=73746.67, MSE=1.455 741e+09
> library(rpart.plot)
Warning message:
程辑包‘rpart.plot’是用R版本4.0.5 来建造的
> rpart.plot(rp)
>
由图4可知,在分类模型构建过程中,PC词数、一月收录、百度权重3个指标对整个决策树构建起到至关重要的作用。通过运用决策树算法和链接分析法对江苏高校图书馆网站收集的数据进行分析,发现本次高校图书馆网站的决策树构建共产生4个叶子节点,且以PC词数、一月收录和百度权重作为了主要分类标准,最终分类结果被划分为四大类。第一类为PC词数<38,占据样本量的66%;第二类为PC词数>38且一月收录≥24,占据样本量的13%;第三类为PC词数>38且一月收录<24且百度权重<2,占据样本量的8%;第三类为PC词数>38且一月收录<24且百度权重≥2,占据样本量的13%。在建立决策树的过程中,各个变量按照重要性排序依次为:PC词数、移动词数、百度权重、一月收录、移动权重、总链接数、收录量、反链数。PC词数和一月收录指标和网页内容的丰富度密切相关,百度权重和网站的浏览量和检索量密切相关。因此,优化高校图书馆网站的重点在于网页丰富度和网站浏览量。
4 优化策略
以上研究成果表明,江苏高校图书馆网站的决策树分类模型构建结果与PC词数、一月收录、百度权重3个指标有较大关系,而这3个指标又最终落脚于网页丰富度和网站的浏览量。因此,笔者提出如下优化策略:①合理设置网页版面,丰富网页内容。网页版面的设置并非越多越好,也并非越少越好,需要找到合适的数量。简洁明快的网页版面会增加网站内容的清晰度,让用户对其使用功能一目了然,同时,也会增加用户了解和使用图书馆网站的兴趣。因此,需要在明确网站版面的同时,扩充网页的内容。②及时更新网页内容,增强网站与用户间的交流,提高用户黏度。网站内容的新颖度直接影响用户对网站的浏览量,网站更新越及时、内容越新颖,越容易提高用户的检索兴趣和检索行为。因此,当与用户和图书馆相关的通知、会议、新闻报道等出现时,应及时对图书馆网站的内容进行更新。③广泛运用新媒体资源,增加宣传和推广。当今时代是新媒体盛行的时代,以“两微一端”为代表的新媒体汇集了大量的用户群体。新媒体的广泛应用增加了用户接触和了解图书馆网站的机会,同时新媒体信息传播范围广、受众面大的特点也有利于图书馆网站使用功能的传播。传播量的增加必然会增加网站的索引量。因此,高校图书馆网站可综合运用微信、微博、App客户端以及抖音短视频等平台,增加图书馆网站功能的传播。
5 结论
笔者将数据挖掘中的决策树算法引入高校图书馆网站分类研究中,利用决策树算法和链接分析法相结合的方法,对高校图书馆网站的相关指标数据进行了收集和分析。研究结果表明,本次高校图书馆网站可分为四大类,在涉及的所有指标中,PC词数、一月收录、百度权重3个指标在决策树分类模型构建中占据重要位置。除此之外,PC词数、移动词数、百度权重、一月收录、移动权重、总链接数、收录量、反链数指标对整个决策树分类模型构建的重要性依次降低。基于以上研究成果,笔者提出合理设置网页版面,丰富网页内容;及时更新网页内容,增强网站与用户间的交流,提高用户黏度;广泛运用新媒体资源,增加宣传和推广。诚然,本次研究还有诸多不足,如数据量较小,指标维度较少等,在日后的研究中,将进一步收集网站信息,增加数据样本量,同时拓宽指标维度范围,以提升研究成果的科学性。
