基于高光谱图像的矿物种类深度识别方法
2022-12-04王吉源
王吉源
(江西理工大学信息工程学院,江西 赣州 341000)
0 引 言
随着社会的发展,我国对矿产资源的需求日益增加[1-2],如何更加高效地利用矿石,减少加工过程中产生的废料,是当前迫切需要解决的问题。 解决这个问题的关键之一是精准地识别矿物[3],为不同种类、不同大小的矿物选取合适的冶炼方法。
传统矿物识别方法[4-5]大多依靠专家经验遴选,也就是具有一定知识经验的人通过目测矿石颜色、光泽、纹路等进行经验判断,这种方法在现代规模化生产背景下效率相对低下,且过度依赖专家的检查能力,易受主观因素影响。 随着可见光—近红外光谱技术的发展和传感器精度的提高,一些研究者提出使用高光谱[6-11]来进行矿物识别[2,5-6]。 车永飞等提出一种基于主次光谱吸收组合特征的高光谱遥感矿物识别方法,该方法对多个特征赋予了不同权重,但如何为特征选择合适的权重仍有待进一步探讨[11];贺金鑫等提出一种基于朴素贝叶斯分类器的高光谱遥感矿物识别方法,该方法利用多种矿物光谱识别属性进行识别, 联合特征的识别表现比单一特征好,但是识别代价更高[10]。 以上方法大多依靠手动提取光谱特征, 然后进行匹配识别等大量计算,传统方法存在着不可忽视的缺陷,手动提取的特征通常不能精确表达矿物特征,且成本高,考虑到效率和成本因素, 需专家学者进一步研究探索。
随着人工智能技术发展, 研究者考虑将智能算法[8-10]引入矿物识别的研究[6,12-15]。甘甫平提出将岩矿的完全波形光谱输入神经网络中进行岩矿识别,但该方法仅能实现二分类,无法完成多类识别任务[15]; MOUNTRAKIS 等提出使用支持向量机对高光谱遥感数据进行分析,该方法能应对训练样本数量受限的分类任务,但学习过程中的参数分配问题对识别表现影响很大,如何选择合适的参数使得识别表现最优,需要再进行研究[16];张兵等提出利用蚁群算法对矿物进行识别,其后又针对蚁群算法提出了改进[17-18],在原来的基础上添加了启发信息,虽然性能较之前有了提升,但与目前广泛应用深度学习神经网络存在一定差距。 当前开发出来的深度网络模型在多个领域取得较好表现, 但其在矿物加工领域的应用尚未得到充分探索。 本文提出了一种利用高光谱数据识别矿物种类的深度学习算法, 比较分析了矿物RGB 数据和高光谱数据对于矿物特征的表达能力,并应用于矿物种类和矿物大小的分类。
1 采用的技术简介
1.1 高光谱图像处理技术
通常情况下,人类可以识别出与红色、蓝色和绿色相关的3 个波长区域,而高光谱相机则可以收集整个跨电磁波谱的信息。 不同的矿物具有的光谱信息不同,因此可以利用高光谱信息进行矿物的识别。随着成像光谱仪的光谱分辨率和空间分辨率的不断提高,高光谱图像被广泛地应用于矿物识别、植被研究[19-21]、海洋遥感[22-24]等领域,并发挥着越来越重要的作用。
矿石光谱通常包含一系列特征吸收谱带,在不同的矿物中所提取的特征谱带信息不同。矿物的诊断性吸收特征可以用光谱吸收特征参数表征,如吸收波段波长位置、深度、宽度、对称度、面积等,从这些参数中可以提取各种矿物的定性和定量信息。一些研究者对这些特征进行手动提取、后续分析,从而实现矿物种类识别。但手动提取特征的识别表现受限于所提取特征的表达能力,且成本高昂。 考虑到高光谱图像包含大量高分辨率的光谱波段,数据量大,可以考虑将其输入适合大数据的深度学习神经网络中训练学习,自动提取矿物表示特征。
1.2 神经网络模型介绍
近年来,随着计算机技术的发展,越来越多的计算机视觉识别方法和深度学习在各个领域中得到应用。 为了提升网络的学习表示能力,越来越多的深度网络模型被开发出来。 主流的深度网络模型有BP、CNN 和GAN。
BP[25-26]的全称是Back Propagation,是一种按误差逆传播算法训练的多层前馈网络。 该神经网络的核心在于反馈,即模型对学习成果进行评判,评判后的结果重新反馈给模型, 从而使模型获得更好的学习成果。
CNN 的全称是Convolutional Neural Networks,即卷积神经网络[27]。 该网络包含3 层结构,分别是卷积层、池化层和全连接层。 卷积神经网络中每层卷积层由若干个卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到。卷积运算的目的是提取输入的不同特征。池化层是对卷积后的特征进行池化操作,使其数据维度更小,表示能力更强。全连接层将所有局部特征连结起来形成全局特征,得到物质的全局表示信息。
GAN 的全称是Generative Adversarial Network,即对抗生成网络[28]。 该网络包含两个子网络:生成网络和判别网络。 其中,生成网络是利用一些生成技术去生成和学习数据相似的数据, 目标是尽量生成真实的数据去欺骗判别网络; 判别网络则要判断输入的数据是原始数据, 还是生成网络生成的数据。 两个子网络相互博弈,通过博弈的过程提升整体的表现能力。
考虑到CNN 的广泛适用性以及在其他领域的杰出识别表现,本文选择CNN 中的经典Resnet 框架对矿物的RGB 数据和高光谱数据进行学习训练, 比较两者的表示能力。 所提方法应用场景如图1 所示,对开采出来的矿石进行初步分选之后,考虑到高光谱在矿物识别中的重要作用,利用高光谱相机对矿石进行拍照获取高光谱图像,然后将高光谱数据输入神经网络进行学习训练, 实现矿物种类以及大小的分类,有助于后续冶炼方法的选择。
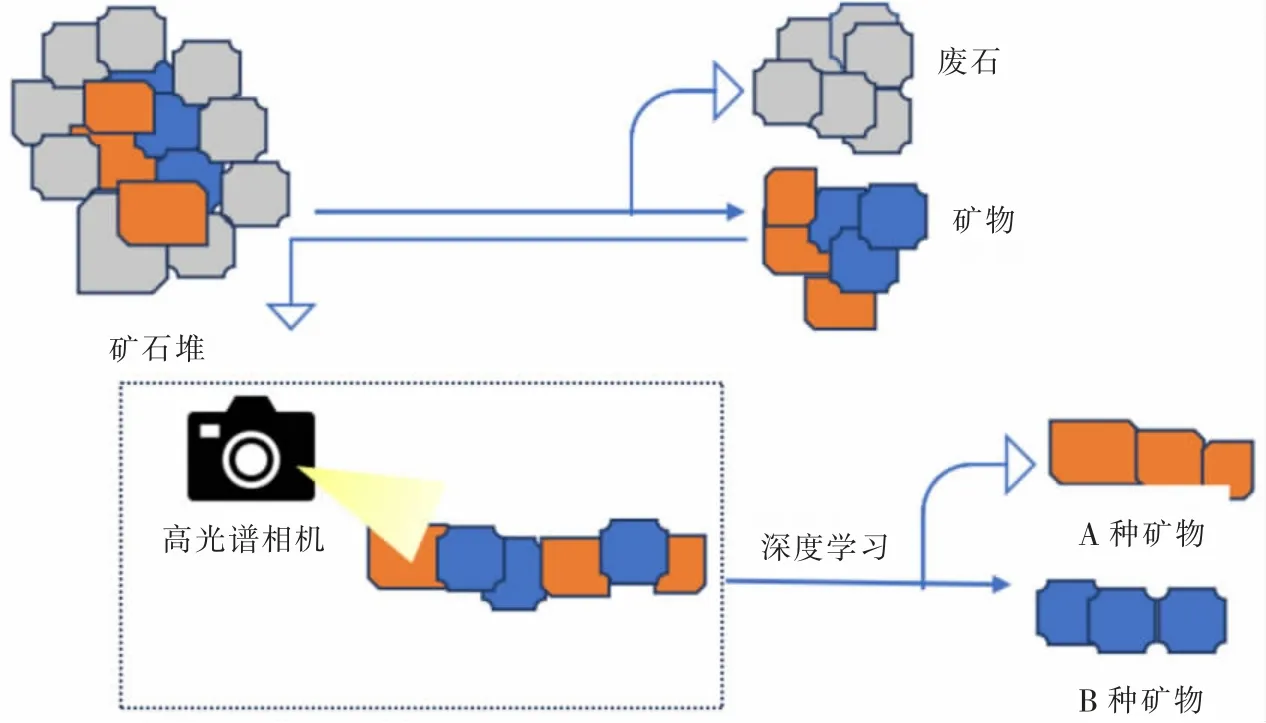
图1 利用高光谱图像和深度学习分类的矿物识别示意Fig. 1 Schematic representation of mineral identification using hyperspectral images and deep learning classification
2 基于高光谱图像的矿物种类深度识别算法
2.1 采用的深度识别算法的网络结构
选用了在图像分类领域取得杰出表现的R esNet 框架构建矿物识别的深度模型。 图2 所示为ResNet 模型的结构, 其输入为矿物图像, 经过5 层设计好的卷积层后,再经过一个全连接层得到分类概率。

图2 矿物识别模型Fig. 2 The module of mineral recognition
矿物识别模型中的残差模块能够有效地消除由于模型层数增加而导致的梯度弥散或梯度爆炸问题。 残差模块如图3 所示,由2 个3×3 的卷积层组成。

图3 矿物识别残差模块Fig. 3 The module of Residual
同一层的残差模块的输入和输出维度相同,采用恒等映射:y=F(x)+x;图2 中的降采样残差模块表示当输入和输出维度不同时, 采用线性投影匹配维度:y=F(x)+Wxx。 其中,y表示残差块的输出,x表示残差块的输入,F(x)表示x经过卷积后的输出,Wx表示投影系数。
2.2 采用的深度识别算法的损失函数构成
为了增加模型的内聚性,用中心损失替换原模型中的softmax 损失。 令xi∈Rd(i=1,2,···,t)表示模型最后输出的特征向量,yi表示输出类别矿物种类,d表示特征向量的维度。t表示每一个pouch 训练图像的数量。Wi∈Rd(i=1,2,···,n)是最后一个全连接层权重W∈Rd×n的第i列,n表示类别总数,b表示偏置项参数。
原始的softmax 损失构造如下:

式(1)中:ai表示softmax 的第i个输出值。Yi表示真实的分类结果。
中心损失在其基础上增加了一个限制模型参数扩张的变量, 使最终的模型能够在内聚性上表现更好。 中心损失函数构造如下:

式(2)中:cyi∈Rd表示第yi类的中心。 全局损失函数构造如下:
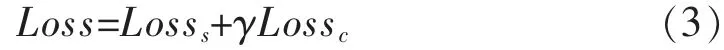
中心点在每个批次训练后更新,其更新公式为:
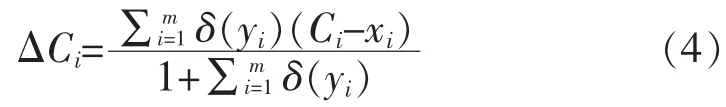
当x为真时,δ(x)的值等于1,否则等于0。
3 实验配置及结果分析
3.1 数据集和数据扩增
为了验证本文所提的深度方法能否有效识别矿物种类,选用了黄铜矿、方铅矿和3 种不同粒径的赤铁矿作为实验样本拍摄图像制作实验数据集,选择以上5 种矿物基于以下两方面的考虑:首先,黄铜矿和方铅矿是硫化物矿物, 赤铁矿是一种氧化物矿物,可以分析该方法是否能对硫化物和氧化物矿物进行分类。 其次,选择3 种不同粒径的赤铁矿是为了考察该方法是否能对不同尺寸的矿物进行区分,从而提高选矿加工效率。 由于实际取得的矿物图像数据较小,深度网络难以充分训练获得较为鲁棒的表示,本文对获取的矿物图片使用了水平翻转、平移、旋转、高斯模糊等多种增广方式,经过增广后的实验所用矿物数据集大小设置如表1 所列。
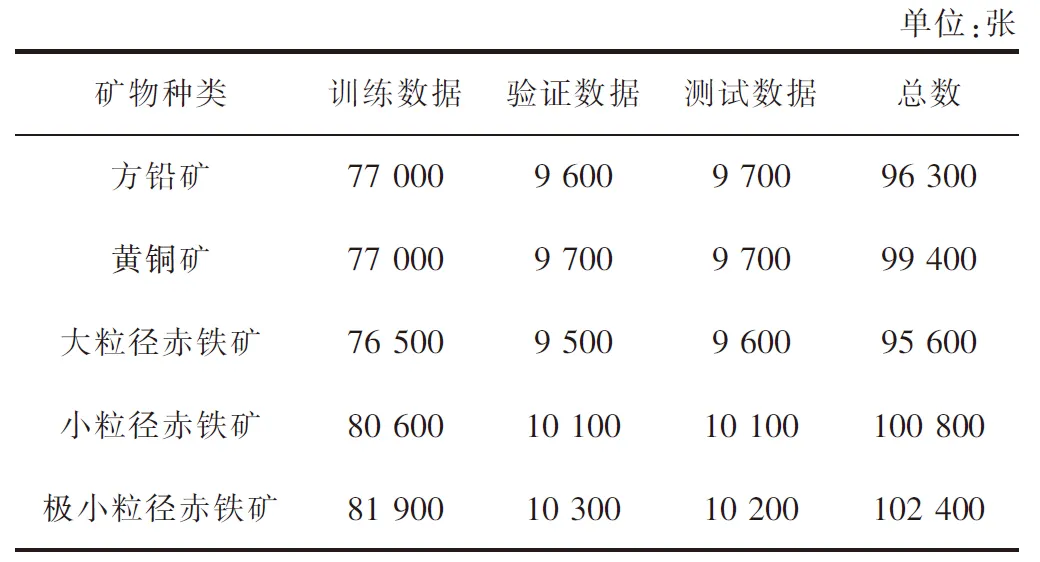
表1 矿物数据集大小设置Table 1 Mineral dataset settings
3.2 实验结果与分析
3.2.1 基于矿物RGB 图像的识别效果分析
为了加快数据的处理速度,选用预训练好的网络模型进行训练,节省了从头开始训练的时间。 实验结果表明, 利用RGB 图像进行识别时,5 种矿物的分类准确率为39.52%。 这可能是因为矿物的RGB 图像中包含的信息不足以判断矿物的种类。例如专家在判定矿物种类时会综合考虑矿物的颜色、光泽、条纹、重量等多个因素,而RGB 图像中所含信种类较单一。 矿物识别的准确度和损失函数的值如图4所示。
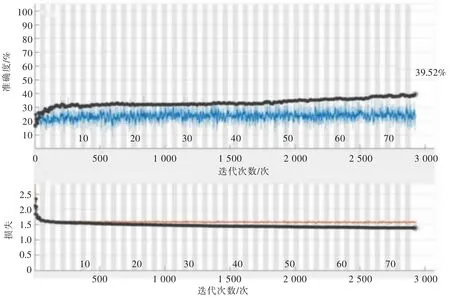
图4 利用RGB 图像的识别表现Fig. 4 Recognition performance using RGB images
3.2.2 基于矿物高光谱图像的识别效果分析
首先对黄铜矿、 方铅矿的高光谱图像进行训练分类,验证该网络是否能正确识别不同的矿物种类,表2 展示了两种矿物在数据集上测试的混淆矩阵。

表2 两种矿物的实验结果Table 2 Result of the two minerals in the test set
实验测试集包含19 400 张高光谱图像,其中,方铅矿9 700 张,黄铜矿9 700 张。9 387 张方铅矿图像被正确识别,占测试集比例为48.39%;313 张方铅矿图像被识别为黄铜矿,占测试集比例为1.61%。 9 511张黄铜矿图像被正确识别,占测试集比例为49.03%;189 张黄铜矿图像被识别为方铅矿,占测试集比例为0.97%。 识别正确的图像共计18 898 张,识别正确率为97.41%。 实验结果表明本文所提出的深度学习神经网络在利用高光谱数据学习时,能有效区分矿物的种类。
对不同粒径大小的赤铁矿训练,验证该网络是否具有区分不同尺寸矿石的能力,3 种不同尺寸的赤铁矿在测试集上的混淆矩阵如表3 所列。
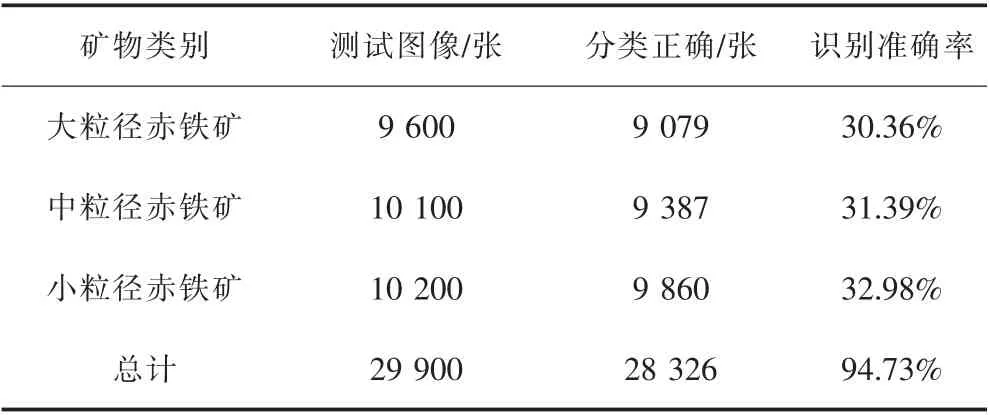
表3 3 种不同尺寸矿物的实验结果Table 3 Experimental results of three minerals of different sizes
实验测试集合共包含29 900 张不同粒径的赤铁矿高光谱图像,其中,大粒径赤铁矿图像9 600 张,中粒径赤铁矿图像10 100 张, 小粒径赤铁矿图像10 200 张。 9 079 张大粒径赤铁矿图像被正确识别,占测试集比例为30.36%;378 张大粒径赤铁矿图像被识别为中粒径赤铁矿,143 张被识别为小粒径赤铁矿。 9 387 张中粒径赤铁矿图像被正确识别,站测试集比例为31.39%;252 张中粒径赤铁矿图像被识别为大粒径赤铁矿,461 张中粒径赤铁矿图像被识别为小粒径赤铁矿。 9 860 张小粒径赤铁矿图像被正确识别, 占测试集比例为32.98%;168 张小粒径赤铁矿图像被识别为大粒径赤铁矿,172 张小粒径赤铁矿图像被识别为中粒径赤铁矿。 识别正确的图像共计28326张,识别正确率为94.73%。 结果表明,本文所提的利用高光谱数据的卷积神经网络能满足矿物加工时的分类需求。
4 结 论
针对目前矿石种类复杂、大小不一、加工方法难以选择的情况, 提出利用卷积神经网络对矿石自动分类分级,为后续生产过程中,对不同矿物选择不同矿物加工方法,提升精选效率,并减少废渣提供有效的保障。
为了筛选出矿物表达能力强的数据,本文比较了矿物的RGB 图像和高光谱图像经深度网络学习后的识别结果,发现前者的识别结果仅为39.52%,而基于高光谱图像的识别结果达到了94.7%以上(黄铜矿和方铅矿的分类准确率为97.41%,3 种粒径大小的赤铁矿分类正确率为94.73%)。 因此,本文采用的卷积神经网络能有效学习到输入数据的隐藏特征,达到矿物种类分类分级的要求,解决了矿物加工方法选择过程中顾此失彼的问题。 矿物RGB 的识别表现低下的原因可能是因为RGB 图像所携信息较为单一, 不足以判断矿物种类,后续关于选矿方法的研究所采用的特征可重点考虑高光谱信息。 另外,由于以上实验数据是针对实验环境,有限矿物种类下,脱机训练完成的。 未考虑实际生产中矿物种类多、分类时间要求短的情况,因此,后续研究将着重于解决复杂条件下的多种矿物快速分类问题。
