标签推荐Top-N列表优化算法
2022-12-03朱小兵丁明玉
朱小兵 丁明玉 肖 玉
(赛轮集团股份有限公司信息中心 山东 青岛 266400)
0 引 言
信息爆炸时代,用户每天接收的信息量远远超过了自身所能消费的信息量,造成信息过载现象[1-2]。标签推荐系统允许用户为不同内容进行签注,用户可以用标签组织和搜索信息[3-4]。如今,社交媒体网站日益流行,标签推荐成为一个活跃且不断发展的研究课题[5]。
标签可以用来表征用户的偏好信息和物品的内容信息,用户可以根据个人的偏好,向网络上的物品资源添加各种标签描述信息。目前而言,业界常用的标签推荐算法主要包含了以下三个大类:基于协同过滤的标签推荐算法、基于图的标签推荐算法、基于内容的标签推荐算法。
基于协同过滤的标签推荐算法将用户、物品与标签的三元关系简化到更低的维数空间。Jaschke等[6]考虑到了不同的标签具有不同的流行度,提出了一种基于流行度的标签推荐算法。Rendle等[7]提出了一种基于张量(Tensor)的标签推荐算法,该算法称为成对交互张量分解模型PITF(two-two interaction tensor factorization)。PITF标签推荐算法可以很好地完成对用户、物品和标签三者之间的建模,因而取得了较好的实验结果。
基于图的方法的基本思想是基于用户的标记行为,以用户、物品和标记为顶点构造图,并构建边[8],该类算法不需要考虑物品的内容信息和标签语义信息。Jaschke等[9]提出了一种基于图的标签推荐算法,该算法可以有效地获取用户、物品、标签三者之间的内在联系,称之为FolkRank算法。Riaz等[10]考虑了标签的时间效应,作者认为较新的标签应该被赋予更大的权重,进而提出了TimeFolkRank标签推荐算法。
基于内容的标签推荐算法考虑更多是物品资源的内容信息。Feng等[11]提出了一个优化框架,通过最大化标签推荐曲线下的平均面积来学习最优特征权值。Wu等[12]提出一种生成模型,该模型是基于标签的分布状况进行构建的,以此实现标签推荐,精度有较高的提升。
但是上述所有的标签推荐算法为每个用户给出的标签推荐列表均为固定数量,导致推荐效果不好、用户的满意度不高。为提高标签推荐的准确性,本文采用了另一个方向,思考如何更好地求取最优的标签推荐列表长度,从而提高标签推荐算法的准确度。
针对标签推荐列表长度固定的问题,主要从以下两个方面进行优化:(1) 首先将大于Top-1标签分数的1/2的标签加入候选推荐列表,通过定义成对标签置信度指标,计算候选列表中的标签与Top-1标签的相关性,按照相关性的大小顺序,完成对标签推荐列表的重排序;(2) 对于重排序以后得到的标签推荐列表,通过计算每个子列表的相关性系数,相关性系数最高的子列表即为最佳推荐列表长度。
为评估方法有效性,选择四个标签算法作为对比实验,分别是:基于流行度的标签推荐算法Pop[6]、Rendle和Schmidt-Thieme的成对相互作用张量分解模型(PITF)[7]、著名的基于三部图的标签推荐算法FolkRank[9]、考虑时间效应影响的TimeFolkRank标签推荐算法[10]。在两个真实数据集上进行实验验证,证明方法的有效性。
1 相关技术理论
一个标签推荐系统由用户集U、标签集T、物品集I组成[13],三者之间的内在关系可以表示为S∈U×I×T,其中,(u,i,t)∈S代表用户u给物品i打了标签t,对于用户u给物品i打标签t的兴趣通常由分数score(t|u,i)来估计。标签推荐的目的是计算待推荐的用户物品(u,i)的前N个得分最高的标签。

1.1 PITF算法
PITF标签推荐算法基于矩阵分解模型[14],矩阵分解模型被认为是性能最好的模型之一。PITF标签推荐算法从用户、物品、标签三元组中计算成对的排序约束[15],可捕获用户和标签之间以及物品和标签之间的交互行为。其模型公式为:
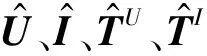
1.2 FolkRank算法
FolkRank是基于PageRank[9]的思想设计的基于图的标签推荐算法。FolkRank认为当一个重要用户使用标签或者标记重要的物品时,标签也应变得相对重要,对于用户或物品而言也采用相同原则。因此,FolkRank标签推荐算法将用户-物品-标签之间的关系表示为一个三部图,三部图可表示为一个邻接矩阵A:
式中:MUT代表用户标签矩阵;MUI代表用户物品矩阵;MIT代表物品标签矩阵;对角线为0矩阵。定义排序向量(列向量)ω:

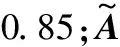
FolkRank标签推荐算法增加了个性化偏好向量。对于给定的目标用户和给定的目标物品,FolkRank标签推荐算法的排序向量计算公式如下:
f=w1-w0
(5)
式中:w1是个性化的排序向量,通过非均匀向量p得到,维度为|U|+|I|+|T|,对于待推荐的用户物品(u,i),在非均匀向量对应的元素有更大的权重,通常设置为1+|U|、1+|I|,此外,非均匀向量的其他元素均为1;w0是一个全局排序向量,通过均匀向量p得到,向量元素均为1;f是FolkRank推荐算法最终排序向量。
1.3 Pop算法
假设一个标签t对于用户u或物品i而言是非常流行的(即经常使用的),那么当用户u给物品i打标签时,标签t则具有强相关性。Pop模型在对标签的受欢迎程度进行归一化以及加权后,得到如下计算公式:
参数ρ调整基于用户的标签流行度以及基于物品的标签流行度的权重。当ρ=1时,仅考虑物品的热门标签,将其设置为0时,仅考虑用户的热门标签,默认情况下,将ρ固定为0.5,认为两者同样重要。Pop算法的优点是可以快速计算,同时给出较好预测结果。
1.4 TimeFolkRank算法
TimeFolkRank是由传统的FolkRank算法驱动的。TimeFolkRank感兴趣的是标签在一段时间内的重要性,几个月前出现的标签显然比几年前出现的更重要。通过对每个标签进行加权来优化FolkRank算法。利用式(7)计算时间加权FolkRank值。
TimeFolkRank=wi×FolkRank
(7)
式中:wi是每个标签基于时间的权重。取决于标签t的标记日期,标签出现得越早,时间权重则越小。选择指数方式衰减权重[16]。
W1=DR(y-ti)/12
(8)
式中:y是当前时间;ti是标签t的标记时间;(y-ti)是以年为单位的时间间隔;DR是一个参数,参数值为0.5。
2 算法模型
标签推荐算法的推荐列表长度常为固定值,这将导致推荐精度下降,用户体验感很差。为解决该问题,提出一种优化Top-N标签推荐列表的算法,从如下两个方面展开介绍:
(1) 详细介绍Top-N标签推荐列表的重排序算法,算法思想是首先将大于Top-1标签分数的1/2的标签加入候选推荐列表,通过定义成对标签置信度指标,计算候选列表中的标签与Top-1标签的相关性,按照相关性由小到大进行排序,完成推荐列表的重排序。
(2) 介绍最佳Top-N推荐列表长度求取算法,算法思想是对重排序后的标签推荐列表,通过计算每个子列表的相关性系数,相关性系数最高的子列表即为最佳推荐列表长度。
2.1 Top-N推荐列表重排序算法
本节介绍改进标签推荐Top-N列表的算法模型(Top-N list reordering algorithm,LRA),该算法旨在对Top-N列表进行重排序。此外,因其是对标签推荐Top-N列表进行的优化,所以LRA模型可以在许多标签推荐算法中使用,是一个较通用的算法模型。
LRA模型思想:对于待推荐的用户物品对(u,i),在将Top-N标签列表推荐给用户之前,LRA对其进行改进。LRA需要个数大于N的候选标签,然后对其重新进行排序,保留相关性更高前N个标签作为最终的Top-N标签推荐列表。
2.1.1算法相关定义
定义1对于给定待推荐的用户u和物品i,用户对标签的兴趣指数通常通过分数score(t|u,i)来估计。因此,标签推荐算法的目的是推荐给用户物品对(u,i)前N个得分最高的标签:
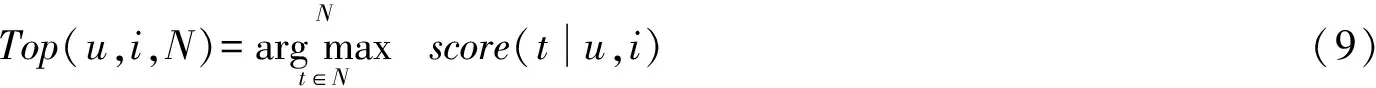
定义2标签的用户列表U(t)代表的是使用过标签t的一组用户集合,标签的商品列表I(t)代表的是由标签t标注的一组商品集合。
定义3为衡量标签t与标签t′的相关性度量,定义成对置信度度量PCM(t→t′),用来表示两个标签之间的相关性。成对置信度度量PCM在一定程度上决定了用户在使用标签t的基础上使用标签t′的兴趣。成对置信度度量PCM同时考虑了用户与物品:
成对置信度度量PCM从两个维度(用户和物品)挖掘标签之间的关联规则,能同时考虑标签在用户和物品上的共现频率。
2.1.2LRA建模
对于标签推荐算法来说,LRA可以作为附加算法使用,首先需要对Top-N标签推荐列表进行扩展,然后再对扩展以后的标签推荐列表进行重排序,并返回最终的Top-N标签推荐列表。
按照Top-1标签获得的分数为基准进行Top-N标签推荐列表的扩展,将分数大于Top-1标签获得分数的二分之一的标签均加入到候选标签推荐列表中,一个简单的例子可以更好地理解标签列表的扩展过程。
假设,待推荐的目标用户为u,目标物品为i,通过标签推荐算法输出的Top-5推荐结果如表1所示。
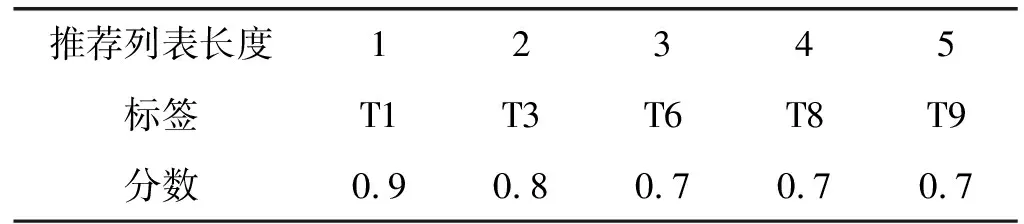
表1 Top-5推荐结果
扩展后的标签列表如表2所示。只要是分数大于Top-1分数(0.9)的一半(0.45)即可。
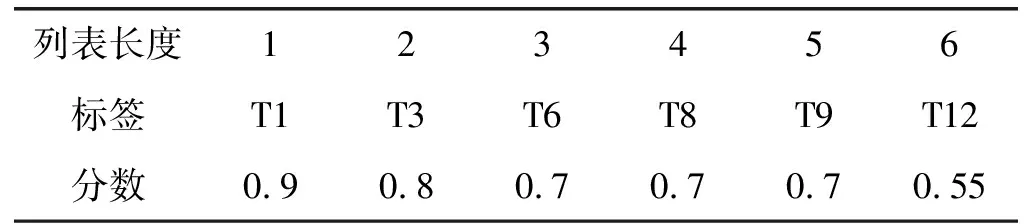
表2 扩展后的推荐结果
由5个扩展为6个,该算法就是从6个中重新排序选择5个作为最终标签推荐列表。
用D表示给定的标签推荐列表,D是按照分数降序排列的,最高得分标签是D[1]。相比D中的其他标签更关注D[1]标签,因为它是标签推荐算法给出的最好的标签选择。LRA对其进行了修正,并计算所有候选标签与D[1]相比较的成对置信度,最后根据新的分数计算公式对D中的所有标签进行重新排序。
用新的分数计算公式对每个标签t进行二次排序:
scorePCM(t|u,i)=(1+PCM(D[1]→t))·
score(t|u,i)
(11)
通过从用户角度和物品角度来考虑,通常出现在标签推荐列表D中第一个推荐标签比旁边的标签应该具有更高的被推荐可能性。
2.2 Top-N推荐列表长度优化算法
2.1节介绍了Top-N列表重排序LRA模型,该算法实现了Top-N标签推荐列表的重排序,但是推荐给用户的标签列表仍然是长度固定的Top-N列表,当N很大时,推荐的标签列表中包含大量与待推荐的用户、物品相关性较低的标签,从而造成推荐质量不高。针对该问题,本节在LRA完成Top-N列表重排序的基础上,进一步提出一种确定推荐列表最优大小的无参数算法(Parameter-free algorithm with optimal size of recommendation list,PFA),引入关联性度量,以从给定的推荐标签列表中找到最相关的标签。通过推荐一些更相关的标签,排除相关性较低的标签,从而调整列表的长度,提高标签推荐的质量。
2.2.1PFA基础
标签推荐算法旨在推荐最合适的标签,这是以用户为中心的Web 2.0的重要组成部分。标签推荐的主要挑战之一是其推荐列表的有效性,现有的标签推荐算法通常使用固定数量的标签推荐列表。
本节提出的算法遵循另一个方向,通过优化推荐列表长度以提高标签推荐的准确性。给目标用户u推荐的标签列表为LN={t1,t2,…,tN},PFA的目的是求取出推荐列表LN的一个子列表,该子列表与待推荐的用户物品的相关性最大,并用该子列表替换推荐列表LN,实现更好的用户体验,更好的推荐精度。
LN的所有子列表的大小是递增的,以便保持标签顺序,如图1所示。
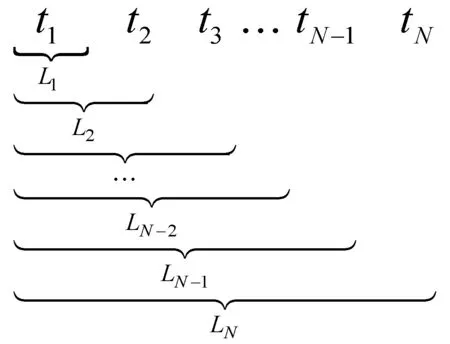
图1 子列表示意图
为标签推荐列表LN引入了相关性的度量方法,相关性度量Rel(LN|u,i)估计了用户u使用LN中所有推荐标签对物品i进行打标签的可能性。基于该相关性度量,计算出将向用户推荐的最佳列表(the one having the optimal size,bls):
bls=max(s|s∈S)
(12)
S={s|s≤N∧∀n≤N,Rel(Ln|u,i)≤Rel(Ls|u,i)}
(13)
算法可以动态调整推荐标签列表的大小,从而提高推荐的准确性。PFA是建立在2.1节提出的LRA的基础之上,并对LRA进行了扩展,PFA与LRA都是标签推荐算法的附加算法,可以认为标签推荐算法的一个顶部过滤器,PFA与LRA的目的都是通过优化标签列表进而提高标签推荐算法的准确度。
2.2.2PFA建模
本节将详细介绍PFA的相关性度量计算方式以及用于从给定标签推荐列表中检索最佳子列表的算法。假设Rel(LN|u,i)代表的是用户u、物品i与标签t的相关性,LN是一个N个标签组成的有序标签推荐列表,用户u和物品i与标签t推荐列表LN的相关性定义如下:
式中:ω(LN|u,i)表示调整标签推荐列表相关性的权重,使得列表相关性计算不会一味地倾向于更短的标签推荐列表,推荐列表长度越长则ω(LN|u,i)越大。Rel(LN|u,i)是标签对用户u和物品i的相关性,表示用户u使用标签t标记物品i的可能性。
Max代表最长标签推荐列表长度,Rel(LMax|u,i)代表用户u物品i与推荐列表LMax的相关性。算法从Max依次递减至1,寻找最佳的推荐列表长度,每当递减一次,都会计算当前子列表与用户u、物品i的相关性,记录并更新推荐列表的最佳长度,如果两个不同长度的标签推荐子列表具有相同的相关性,算法则将优先选择最长的作为推荐列表的最佳长度。
现在常用的计算相关性的方法是将已知标签(用户曾使用过或者物品曾被打过)与其他标签区分开来,与其他标签相比,历史上与用户或物品相关的标签更值得进行推荐,下面介绍该算法的思想。
用PN=LN∩T(u)∩T(i)来表示在推荐列表LN当中包含已知标签的子列表,为已知标签子列表中的标签赋予一个较大的权重,而为其他非已知标签赋予一个较小的权重,从而做到突出已知标签:
式中:rmax和rmin由我们指定某一具体数值,rmax设置为原推荐列表固定长度,通常设置为5,rmin设置为1。式(15)经过化简可以得到式(16)。
(16)
通过式(16)可以看出相关性Rel(LN|u,i)仅与|PN|与N的比值相关,当且仅当|PN|与N相同时(即推荐列表当中所有标签均为已知标签),相关性最大,相关性为1。因此,推荐列表的相关性可以进一步化简为:
上述方法优点是思路清晰简单,所需计算数据均可从数据集中统计得到;缺点是当推荐列表当中的标签全为已知标签时,相关性为1,无法继续筛选其他的推荐子列表,从而无法得出最佳列表长度。
为了更加准确地计算标签列表的相关性,本文使用另一种改进的方案:将标签的相关性值与从可用数据(训练集)中获得的一些统计数据联系起来,简称为bls算法。本节提出的相关性度量方法同时考虑了用户以及物品的标签流行度,式(18)给出了标签的相关性计算方法。
式中:U(i,t)代表给物品i打标签t的用户集合;I(u,t)代表用户u使用标签t打过的物品集合;U(i)代表给物品i打标签的用户集合;I(u)代表用户u打过标签的物品集合。此外,标签的相关性根据其在推荐列表中的排名降低(第一个标签的相关性高,最后一个的相关性低),为了避免算法一味地偏向于较短的标签推荐列表,因此有必要在计算标签推荐列表的相关性时使用加权方法。考虑到标签随着其位置的靠后,相关性自然减少,定义推荐列表的权重:
此权重函数计算了推荐列表大小的重要性,可以在推荐长推荐列表的同时惩罚短的推荐列表。因此,结合式(19),得出了一个新的列表相关性度量:
至此,本文提出的优化标签Top-N推荐列表的PFA介绍完毕,PFA的总结如算法1所示。
算法1PFA
输入:LRA算法重排序后的列表LMax。
输出:bls。
bls←Max
//bls:最佳列表长度
blR←Rel(LMax|u,i)
//blR:最佳列表的相关性
forN=(Max-1) to 1 do
ifRel(LN|u,i)>blRthen
bls←N
blR←Rel(LN|u,i)
end
end
Returnbls
3 实验结果
3.1 实验数据和实验准备
3.1.1实验数据
数据集为HetRec于2011年发布的MovieLens数据集(HetRec-MovieLens)和MovieLens-10M数据集。这两个数据集既包含了物品的属性信息,也包含了用户打标签的行为。HetRec-MovieLens数据集包含2 113个用户、5 908个物品、9 079个标签和47 957个打标签记录;MovieLens-10M数据集包含4 009个用户、7 601个物品和95 580个打标签记录。
首先,对MovieLens-10M数据集中的标签进行了预处理,剔除无效标签,合并相似标签。由于标签数据过于稀疏,采用p-core=5对两个数据集进行预处理,即保留出现超过5次的用户、物品和标签的数据。数据预处理后数据集的具体统计信息如表3所示。

表3 两个数据集的统计信息
3.1.2评价指标
使用训练集推荐算法进行训练,使用测试集进行预测。评价指标选择F1值,因为F1既考虑到了准确率也考虑到了召回率。下面给出准确率、召回率、F1的计算公式:
式中:A代表算法推荐的标签;B代表用户实际打的标签。
3.1.3实验准备
为了测试PFA的性能,实验采用以下方法作为baseline算法:
(1) Pop:基于流行度的标签推荐算法。
(2) PITF(成对交互张量分解):一种基于张量分解的标签推荐算法。
(3) FolkRank:FolkRank标签推荐算法扩展了自适应PageRank算法,该算法的核心思想是利用用户偏好向量对标签进行排序。
(4) TimeFolkRank:基于FolkRank标签推荐算法,考虑标签时间信息,标签越新推荐的权重就越大。
3.2 实验设置和实验结果
3.2.1实验设置
为降低实验结果的偶然性,将整个数据集按照随机划分的原则将其划分成完全相等的十个部分,每次随机选取其中的八个部分当作训练集,剩下的作为测试集,将以上步骤重复五次,最终将五次实验结果取平均值,以此作为最终实验结果。
3.2.2实验对比与分析
PFA是FolkRank以及其他标签推荐算法的一个附加算法,是对以上算法推荐列表的改进。选择四个标签推荐算法进行对比实验,在命名上,以FolkRank标签推荐算法为例,对比算法命名为FolkRank,改进算法命名为PFA-FolkRank,其他算法也是如此。本文实验结果如表4所示。
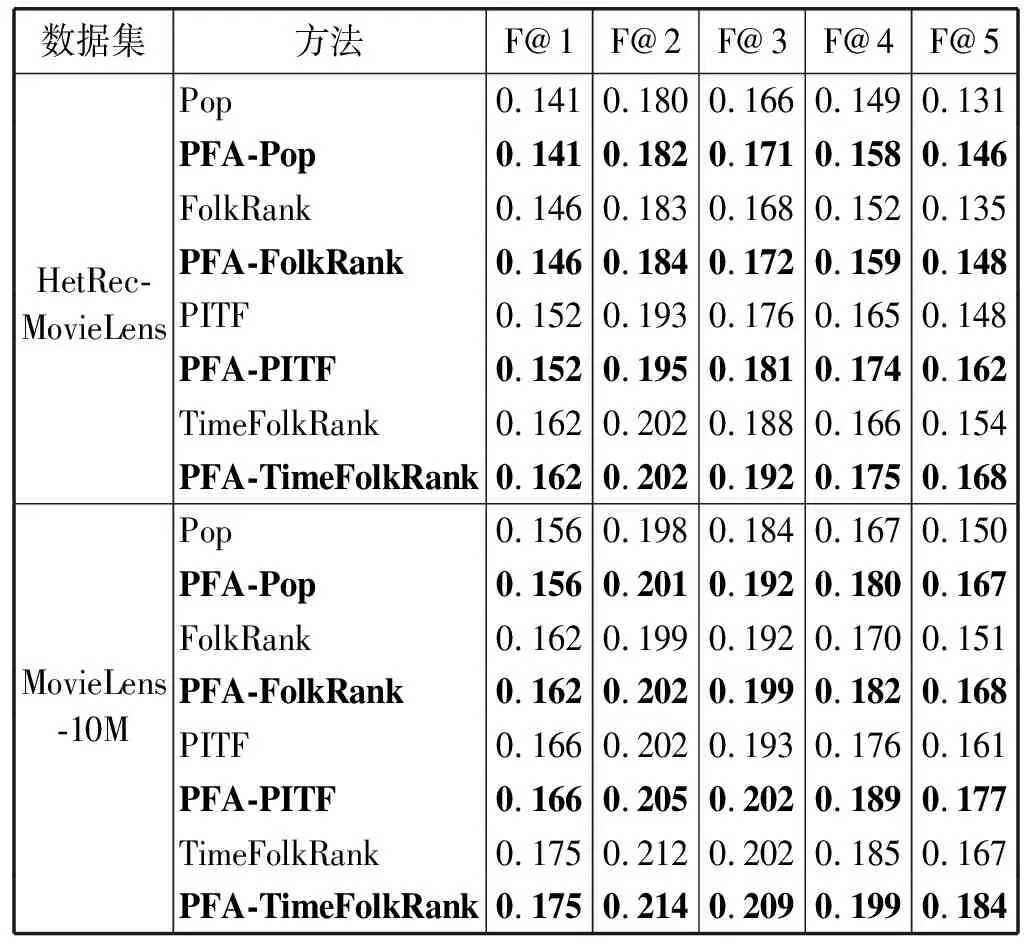
表4 两个数据集的统计信息
为更加直观地显示实验结果,对每个对比算法的实验结果逐一进行画图,其中,横坐标为标签推荐列表长度,纵坐标为标签推荐算法的F1数值。具体的实验结果如图2-图5所示。
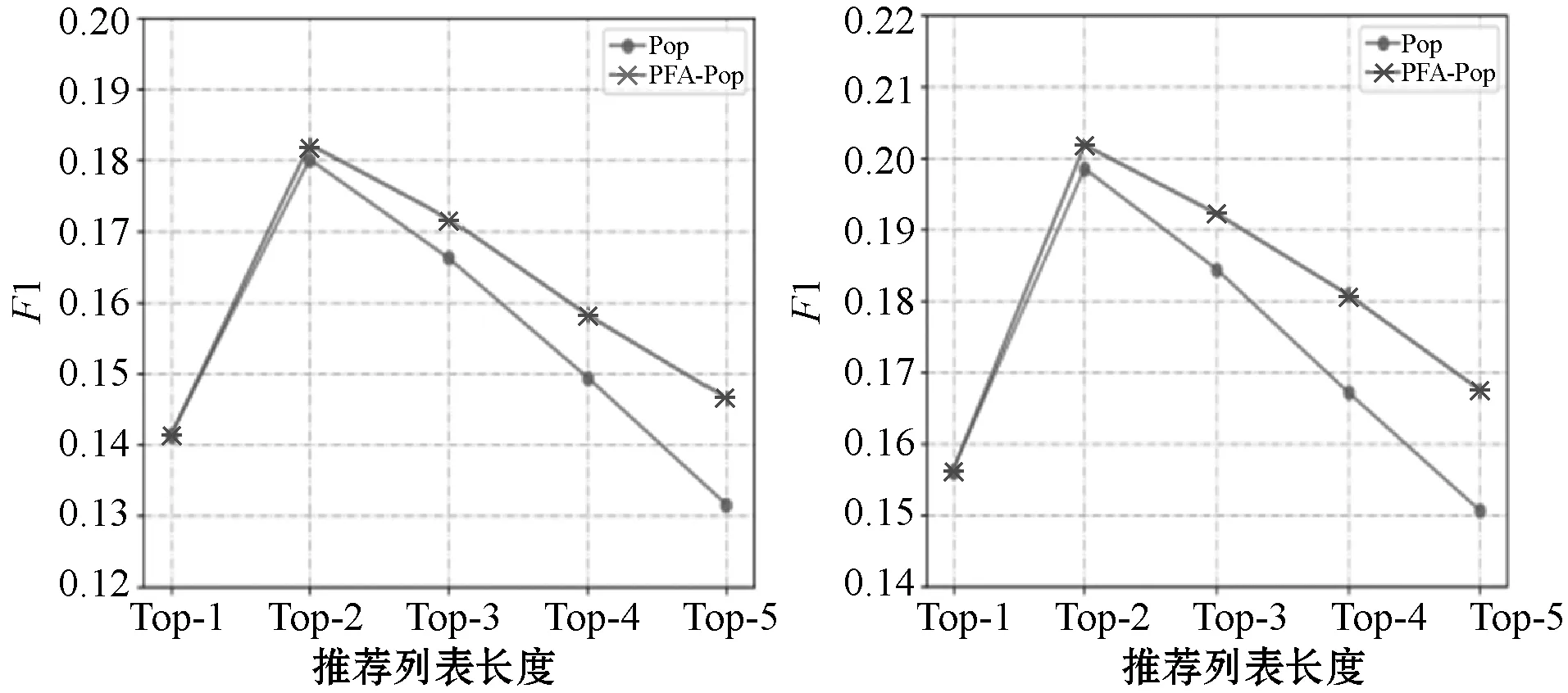
(a) HetRec-MovieLens(b) MovieLens-10M图2 Pop算法在两个数据集上的F1值
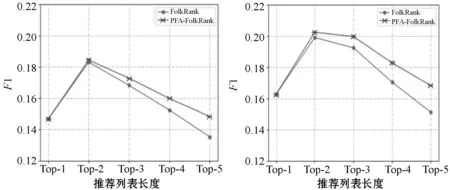
(a) HetRec-MovieLens(b) MovieLens-10M图3 FolkRank算法在两个数据集上的F1值
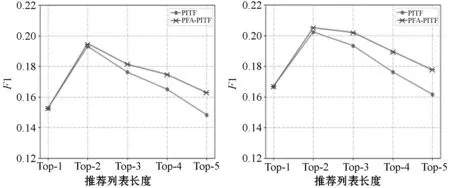
(a) HetRec-MovieLens(b) MovieLens-10M图4 PITF算法在两个数据集上的F1值

(a) HetRec-MovieLens(b) MovieLens-10M图5 TimeFolkRank算法在两个数据集上的F1值
PFA可以作为标签算法的一种附加算法,主要用于对各种标签推荐算法生成的Top-N推荐列表进行改进优化。传统的标签推荐算法,如FolkRank标签推荐算法,通常都是为目标用户目标物品生成一个固定长度的推荐列表,这种方式,在一定程度上降低了用户的满意度,而PFA可以有效缓解该问题。PFA首先对Top-N标签推荐列表进行了重排序,又对重排序后的推荐列表挑选出来最佳的子列表,从而在优化列表的基础上实现了列表变短的操作,保留下的标签理论上是与待推荐的目标用户与目标物品相关性较高的标签,从而提高了标签推荐的性能。经过两个数据集的验证,本文提出的PFA对于标签推荐算法是有效的。
4 结 语
本文提出一种优化标签推荐算法Top-N推荐列表的算法。首先,详细介绍了Top-N标签推荐列表的重排序算法,算法的思想是首先将大于Top-1标签分数的1/2的标签加入候选推荐列表,通过定义成对标签置信度指标,计算候选列表中的标签与Top-1标签的相关性,按照相关性大小,完成推荐列表的重排序;其次,介绍了最佳Top-N推荐列表长度求取算法,算法的思想是对重排序后的标签推荐列表,计算每个子列表的相关性系数,相关性系数最高的子列表即为最佳推荐列表长度。
在HetRec-MovieLens和MovieLens-10M数据集上的实验表明,本文提出的RFA优化Top-N列表算法可以有效地提高传统算法的F1值,因此,作为FolkRank以及其他标签推荐算法的附加算法,该算法可以有效地提高标签推荐的质量。
