基于LightGBM-LSTM组合模型的商业建筑能耗预测
2022-12-03罗恒刘杭
罗 恒 刘 杭
1(苏州科技大学电子与信息工程学院 江苏 苏州 215009)2(苏州科技大学江苏省建筑智慧节能重点实验室 江苏 苏州 215009)
0 引 言
随着智能电网对于各个大型商业建筑的普及,建筑能源的节约使用已经成为了人们的关注要点。很多大型公共建筑通过建立能源节约系统,能够预测未来短期或中长期建筑能耗数据,起到节约资源以及节约企业成本的作用[1]。能够影响大型商业建筑能耗的因素有很多,例如天气影响、国家规定节假日因素等,所以能耗预测的准确度问题仍然是需要重点研究的对象。
建筑能耗预测中常用的传统机器学习方法主要有随机森林(Random Forest,RF)算法[2]、K-近邻(k-Nearest Neighbor,KNN)算法[3]和支持向量回归机(Support Vector Machine,SVM)算法[4]等。预测问题使用回归算法较多,例如,文献[5]提出一种基于核岭回归(Kernel Ridge Regression,KRR)的预测风速的方法,但预测通用性不高。很多研究人员使用决策树的算法对时间序列数据做出简单预测,随机森林算法使用Bagging思想[6],将多个决策树综合,提升决策树的预测效果。文献[7]使用(Gradient Boosting Decision Tree,GBDT)算法做预测,它是基于梯度的最小化损失函数的决策树算法。LightGBM[8]模型是GBDT模型的一种改进模型,对多特征数据处理效果较好。文献[9-10]使用神经网络对能耗预测,但是对于时间序列问题仍然具有局限性。针对时间序列数据,经典的自回归移动平均模型(ARIMA)[11]和目前基于循环神经网络(Recurrent Neural Network,RNN)[12]衍生的长短期记忆(Long Short-term Memory,LSTM)[13]网络都是经常使用的预测模型。LSTM增加具有门控单元的记忆功能,与其他方法相比,在处理时间序列问题上更能够捕捉时间序列项之间的依赖关系和模式。
能耗序列数据是具有长短期时间序列特性的数据,同时易受多种特征因素影响。针对能耗序列这两种特点,依据上海某商业建筑能耗数据开展实验,并提出一种基于LightGBM-LSTM组合模型的权重组合的预测方法。其组合方式使用文献[14]的方差-协方差法的权重组合方法,本实验分别使用LightGBM模型与LSTM模型对该商业建筑能耗时序数据进行建模,通过对于LightGBM模型和LSTM模型预测结果的权重组合,并将组合后的模型与KNN、RF和GBDT等模型进行实验结果对比,本文所提出的LightGBM模型与其他单项模型相比,具有较好的预测能力。
1 研究方法与理论
1.1 LightGBM模型
LightGBM是基于决策树基分类器的算法,它采用了几种策略优化方式,是泛化梯度提升树的一种模型。
决策树算法将特征集合映射,对于输入数据D={(x1,y1),(x2,y2),…,(xn,yn)}预生成k棵决策树,将训练集输入空间递归划分为两个子区域输出值:
计算R1、R2的域内方差:
(3)
式中:c1、c2为每个区域的输出。找出最优切分:
计算第m棵树子数划分区域的局部均值:
式中:Nm为该划分区域的数据个数。
式(5)表示对单个区域的预测结果。对于上述条件可以重复调用,获取满足条件的最小回归树。最终划分区域空间数为M的区域集合{R1,R2,…,RM},生成决策树为:
式中:I为指示函数,如果x∈Rm,则I为1,反之则为0。
根据平方误差最小化原则,输出区域内最优的值。其中对于第m棵子数的第j个预测值的损失函数定义为:
l(m,j)=L(yj,fm(xj))=(yj-(fm(xj)))2
(7)
式中:L为L2损失函数。
梯度决策提升树是一种使用Boosting方法预测的分类回归算法,在提升树中使用残差作为下一个树的输入,在梯度决策提升树中使用公式:
LightGBM模型基于GBDT的策略改进,使用直方图算法离散遍历数据,优化最优决策树分割点,在LightGBM模型中的决策树使用Level-wise策略[15],控制模型复杂度。模型的创新点在于基于单边梯度的采样算法(GOSS)和互斥特征打包(MEF)。MEF算法如算法1所示。
算法1MEF算法流入:numData为输入数据的大小,F为互斥特征的一组打包。
输出:newBin,binRanges。
1. binRanges←{0},totalBin←0;
2.forfinFdo
3. totalBin+=f.numBin;
4. binRanges.append(totalBin);
5. newBin←new Bin(numData);
6.fori=1tonumDatado
7. newBin[i];
8.forj=1tolen(F)do
9.ifF[j].bin[i]≠0then
10. newBin[i]←F[j].bin[i]+binRanges[j];
1.2 LSTM模型
在使用基于时间序列的数据处理时,使用传统的神经网络模型无法得到前后数据的依赖关系结果。循环神经网络(RNN)是针对这一问题而设计的深度递归网络,它能够保留前面几个时间步的信息,但是在时间轴上会发生梯度消失或梯度爆炸,为了解决RNN梯度问题,LSTM使用门控单元来实现记忆功能,设置遗忘门(Forget Gate)、输入门(Input Gate)、状态更新(Status Updates)、输出门(Output Gate)。如图1所示,四种门控结构连接到乘法元件上,通过控制神经元细胞(Memory cell)的输入输出,达到提升神经元记忆能力的功能。

图1 LSTM神经元结构
定义图1的部件描述如下:
Input Gate:控制信息流入到记忆单元中,记为it。
Forget Gate:控制前一时刻的信息流入到当前时刻的记忆单元中,记为ft。
Output Gate:控制当前时刻的记忆单元信息流入隐藏状态ht中,记作ot。
Cell:存储单元,是神经元的记忆功能,有对数据保存处理的能力,记作ct。
在某一时刻t,LSTM神经网络内部隐藏层定义运算公式为:
ft=sigmoid(wf1xt+wf2xt-1+bf)
(9)
it=sigmoid(wi1xt+wi2xt-1+bi)
(10)
ot=sigmoid(wo1xt+wo2ht-1+bo)
(12)
ht=ot×tanh(ct)
(14)
式中:w和b分别代表不同门的权重和偏差矩阵;tanh与sigmoid表示激活函数;ht代表流入当前隐藏状态信息;xt-1、xt表示t-1时刻与t时刻数据。
LSTM在训练过程中,将数据输入进输入层,经过激活函数作用后输出,在输出后将t-1时刻数据经过隐藏层的输出t时刻输入节点,由图1和图2对应的遗忘门、输入门和输出门单元处理,最后输出到输出层或者是下一个层计算单元,输出层输出的数据经过输出层神经单元,通过反向传播算法,更新节点权重。
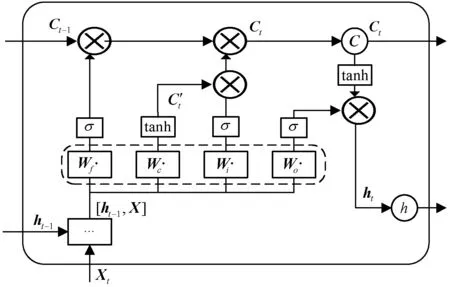
图2 LSTM隐藏单元结构
2 LightGBM-LSTM模型构建与预测
2.1 数据预处理及特征分析
实验采用上海市浦东新区某大型商业建筑平台提供的历史能耗数据,数据按照时间序列排序,包含两年每天每小时的能耗使用情况。经过预处理,得到整点能耗数据。根据文献[16],能耗数据受到天气因素影响,所以从某天气网站上获取到了这两年浦东新区的天气数据进行分析,经过预处理,时间间隔为一个小时。实验采用的日期准确范围为2018年1月1日至2019年12月31日,共17 514条能耗数据和17 514条天气数据。
本节主要根据历史能耗数据以及天气相关因素,筛选确定影响因素,从而能够进行准确的预测。
2.1.1能耗历史数据分析
使用文献[16]方法,根据能耗序列历史数据具有时间序列的关系,使用自相关系数和偏自相关系数来分析能耗历史数据的平稳性和滞后性,如图3所示。
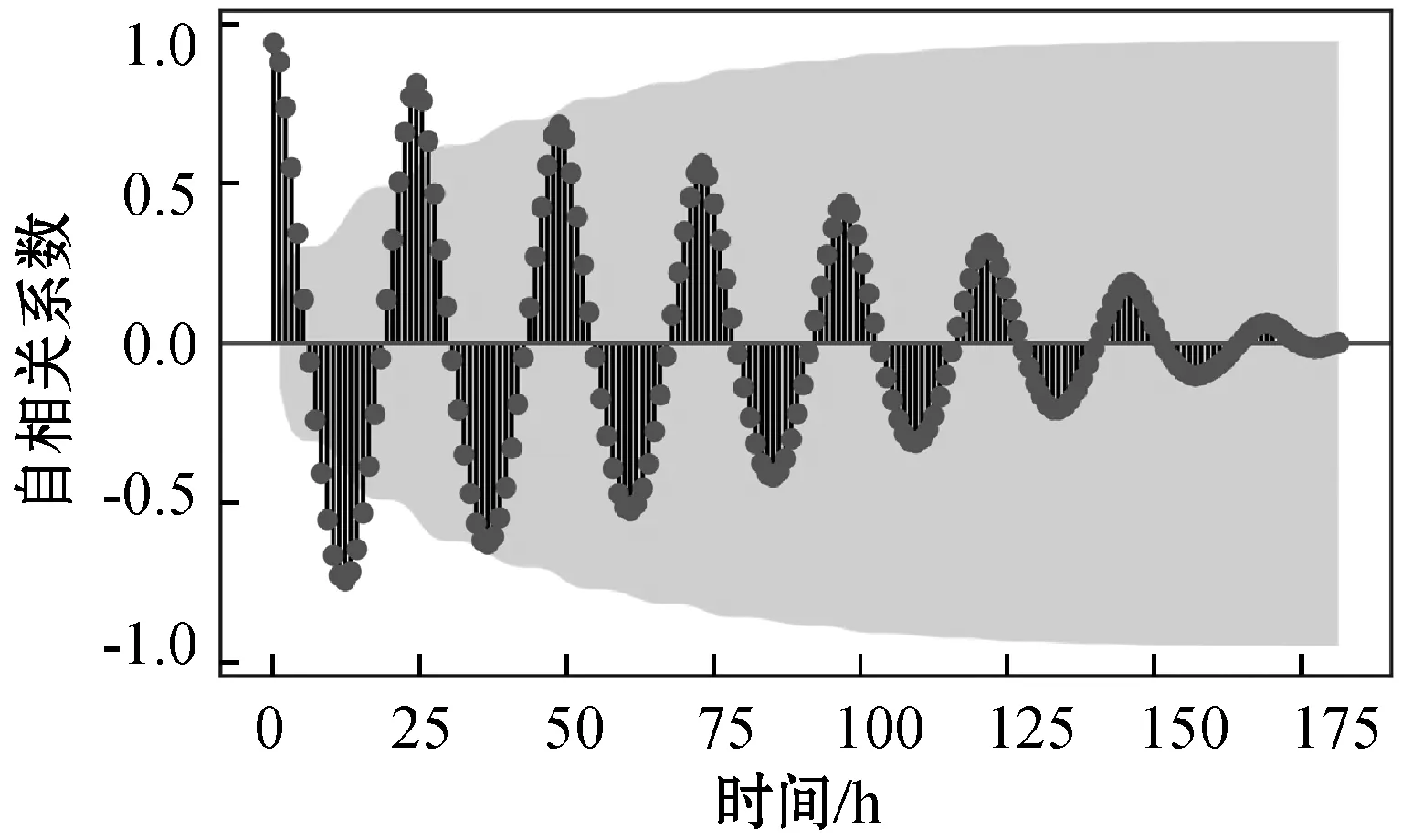
(a) 能耗数据自相关系数
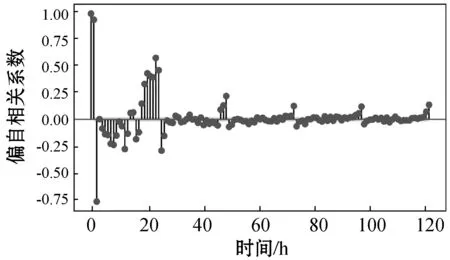
(b) 能耗偏自相关系数图3 能耗数据相关系数
从图3(a)中可以看出建筑能耗历史数据随着滞后时间增加,最终趋于平稳。通过图3(b)可以认为历史能耗数据具有滞后性,所以使用带时间滞的数据作为基本实验数据。
2.1.2特征因素
通过某天气网站气象应用程序接口(API)调用该地区一年的天气情况,包括温度、湿度、风速等。为了判定不同的因素影响程度,使用斯皮尔曼相关系数表示其相关性,筛选相关性较高的因素作为实验影响因素。从图4中看出风向对于建筑能耗数据的影响呈无相关性,其余三种因素呈现中相关性,因此可以将风速、湿度、温度作为影响因素。
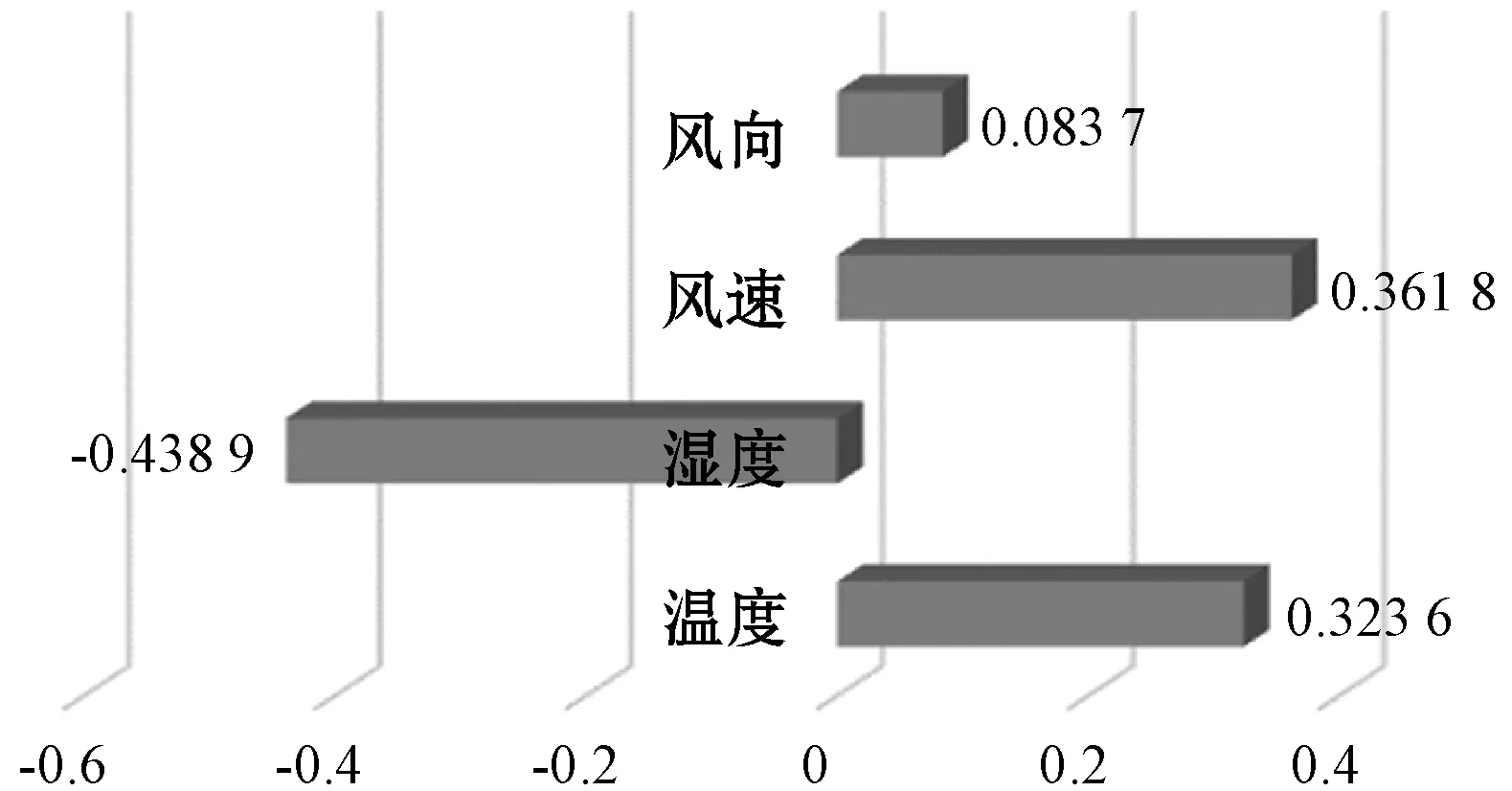
图4 斯皮尔曼相关系数
考虑到该大型商业建筑是公共娱乐建筑,所以在节假日会比平时使用电能多。从图5中可以观察到,2018年和2019年的寒暑假时期,数据呈现上升的趋势,两年内的同一季节,数据的趋势变化也大致相同。图6是2018年节假期能耗、工作日能耗、全年能耗的小时均值对比图。可以看出假期的能耗小时均值比工作日的能耗小时均值高。综上,将工作日因素以及季节周期性因素等列为特征因素。
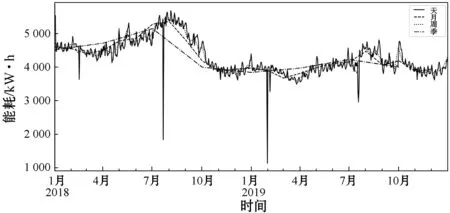
图5 2018年-2019年能耗序列观测
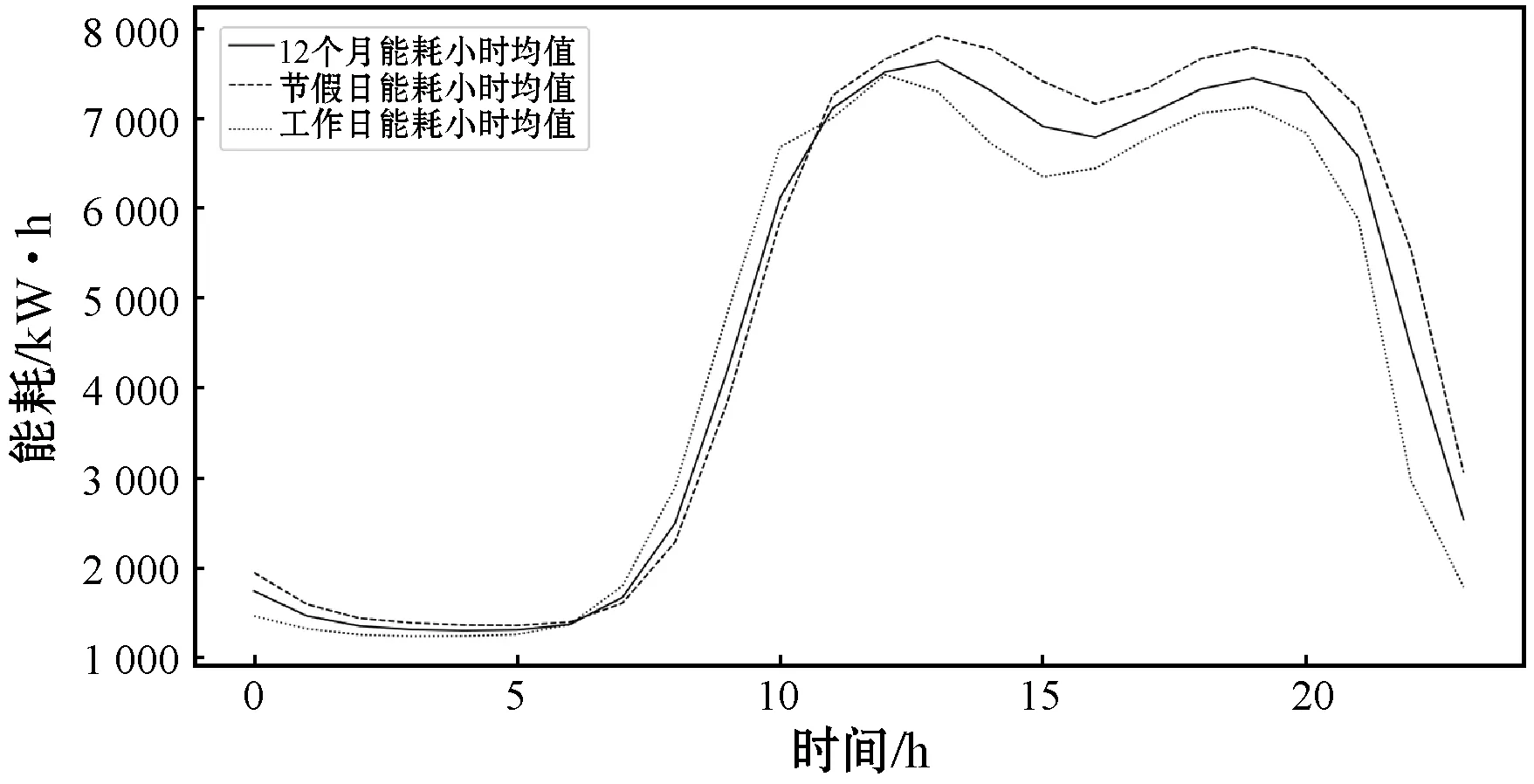
图6 2018年节假期能耗小时均值对比
根据特征分析,可以看出序列数据在20~30之间趋于稳定,因此选取窗口为1~30进行特征重要度分析。使用决策树被分割后的信息增益(Gain)选取得到特征值的排序,如图7所示。
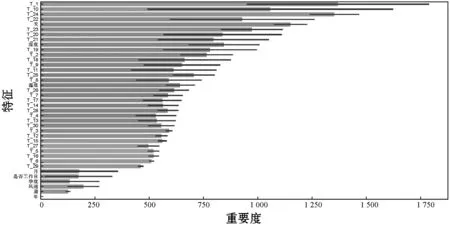
图7 特征重要度分析
2.2 LightGBM-LSTM组合模型预测
为了充分使用LightGBM模型与LSTM模型的特点,构建使用基于LightGBM与LSTM组合模型的预测方法,使用方差-协方差方法确定两种模型的权值,方差-协方差方法使用了误差指标作为权重计算,首先计算对两种模型预测结果的方差为:
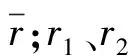
根据如上的方法得到每个预测模型的权重,其中:v1、v2分别表示两种模型同一时间范围内计算的方差;w1、w2为两种模型设定的权重。将每个模型的预测结果加上权重组合,预测结果的组合公式为:
Y=w1y1(t)+w2y2(t)
(19)
式中:计算结果Y为最后组合模型权重相加的预测结果;y1(t)、y2(t)分别表示两种模型的预测值。以上流程最终构成LightGBM-LSTM模型。图8为组合模型的预测流程。
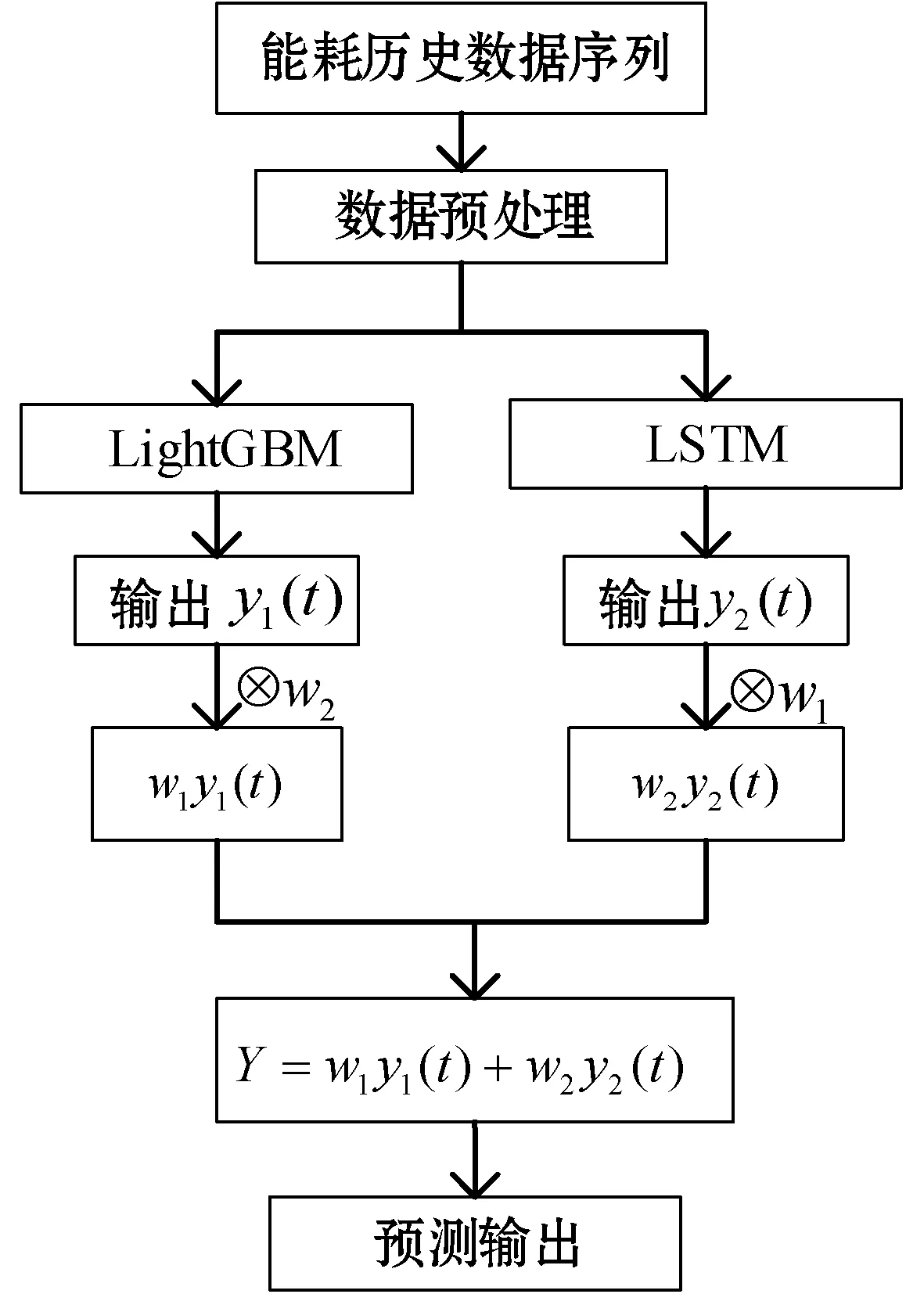
图8 基于LightGBM-LSTM能耗时间序列预测流程
2.2.1LightGBM模型构建
将历史序列能耗数据经过周期性变换后,使用LightGBM模型[17]构建,设计此模型的构架流程如图9所示。
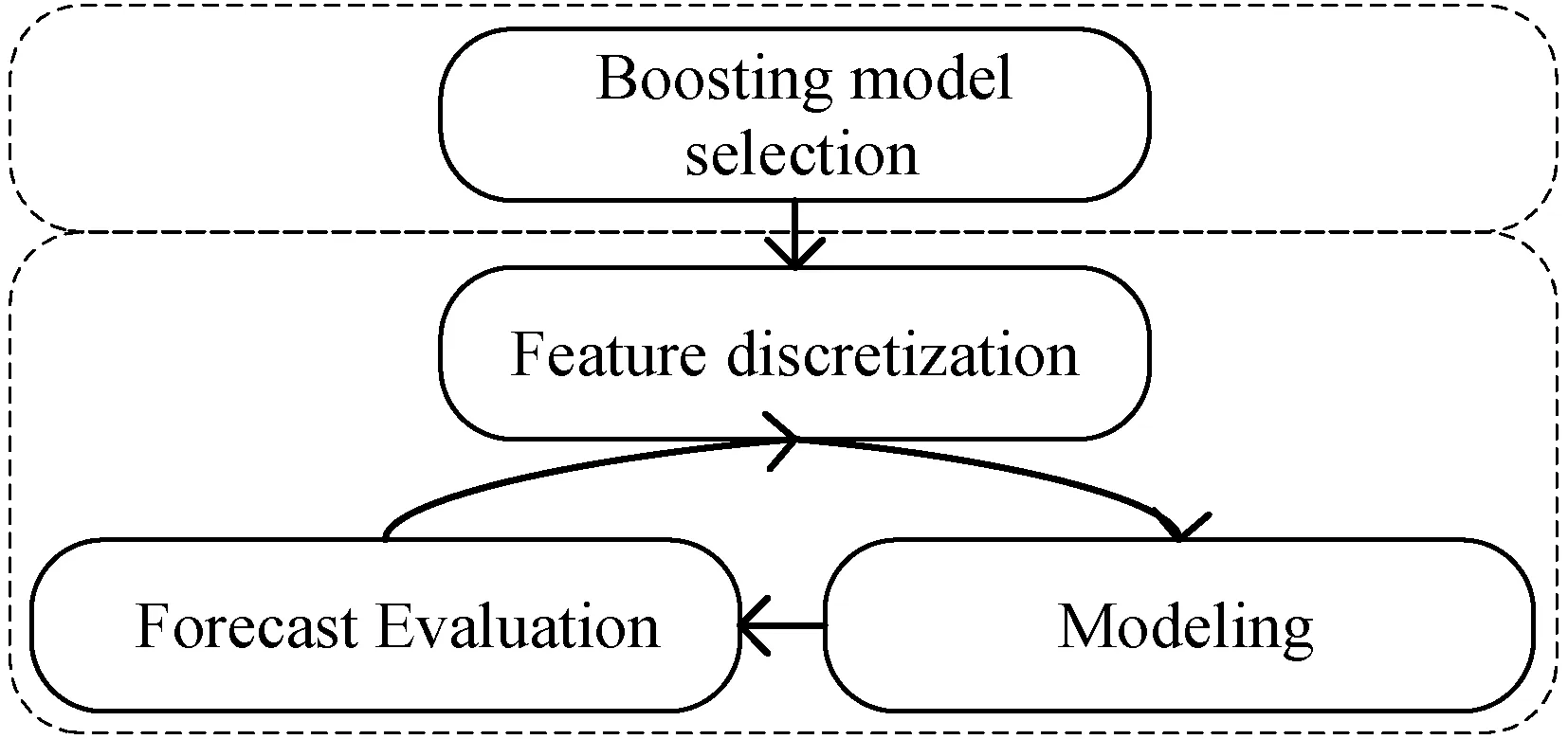
图9 LightGBM模型构建流程
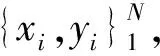
构建模型分类器:
式中:M代表类别数;h(x;αm)是GDBT的弱分类器。设置m次迭代,优化决策树参数值,得到m次迭代值:
Fm(x)=Fm-1(x)+βmh(x;αm)
(22)
根据式(8)构造残差作为下一个决策树的输入。αm和βm的计算式为:
式中:α和β为迭代中的基函数h的参数和系数。
图10所示为构建GBDT的框架。
对特征数据遍历,使用直方图算法得到容器内离散数据值累积量,划分决策树最优分割点。能耗历史数据中的噪声部分会在真实数据值附近缓慢波动。使用MEF算法将关联较少的特征绑定部分密集特征上,通过图9循环迭代的方式训练模型。
2.2.2LSTM模型构建
为了准确地预测历史能耗数据,对LSTM众多参数和网络方法设置,包括对学习率(Learning Rate)、梯度优化控制等,使用梯度优化方法Adam算法[18]:
mt=μ×mt-1+(1-μ)×gt
(25)
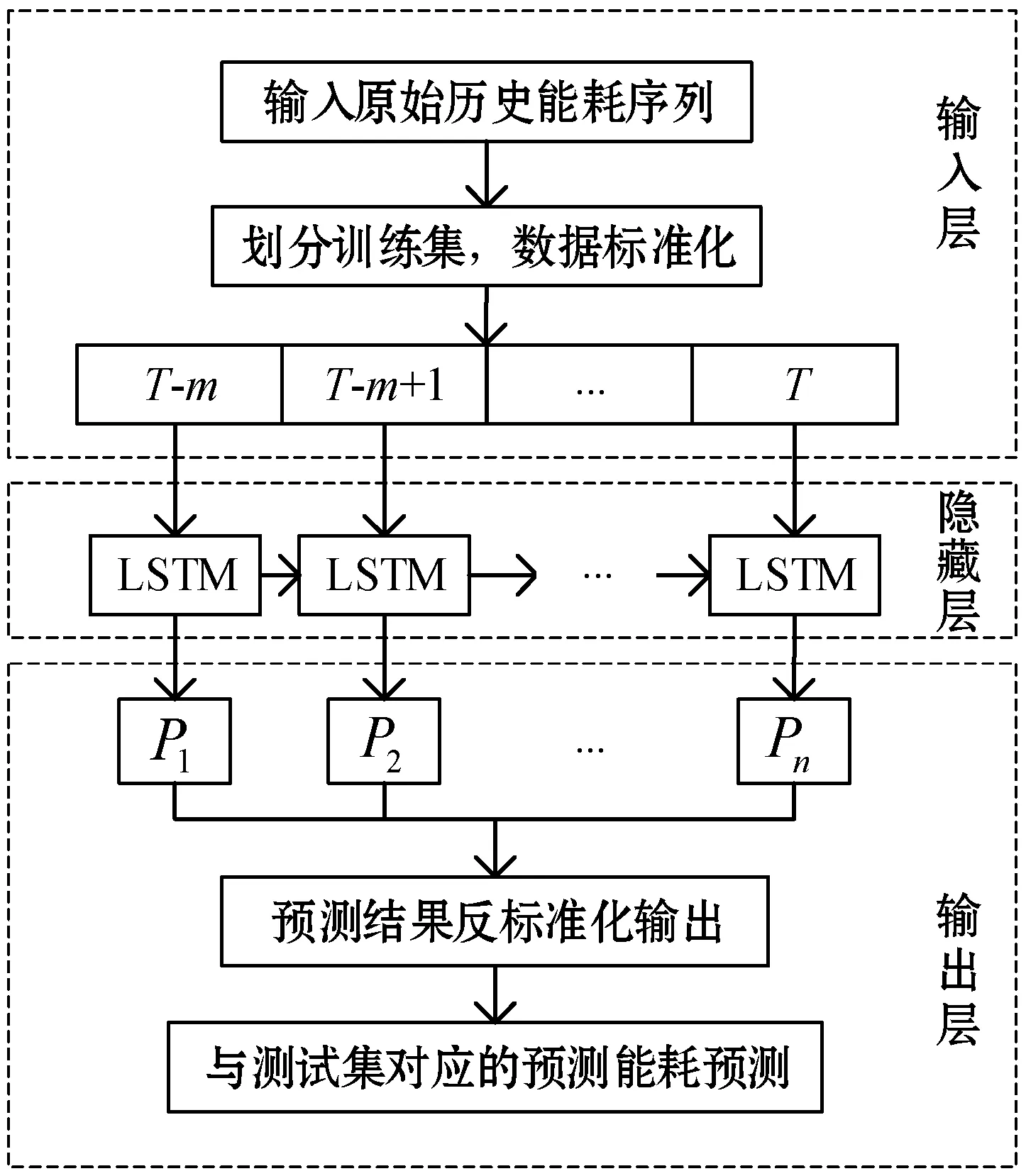
图11 LSTM预测能耗数据框架
根据综上所述,根据所设计的LSTM预测能耗的框架结构进行训练,训练过程如下:
(1) 定义能耗原始数据序列:X={x1,x2,…,xn}。
(2) 初始化数据集,为了加快训练速度,使用min-max标准化方法对数据集进行标准化处理,在训练结束后,对预测结果进行反标准化输出,与原始数据比较。这里使用的min-max标准化与反标准化为:
(3) 设置LSTM模型参数,根据经验进行初始化,设计训练迭代次数step,迭代次数涉及从150逐渐递增,每次递增步长为100,多次实验找到最优的迭代次数。
(4) 对数据集进行数据集划分,将原始数据集序列划分训练集、验证集和测试集。定义{r,m,s}为训练集、验证集与测试集的长度。
(5) 根据第4节特征选取,设置向前取的窗口长度L=24,模型输入输出为:
P=LSTMforward{Xp,Cp-1,…,Hp-1}
(32)
式中:LSTMforward表示LSTM前向传播计算。
(6) 选取均方根误差作为误差计算,设定损失函数为最小化误差。
(7) 通过不断迭代,更新权重,得到训练好的LSTM模型,最终应用LSTM模型对原始数据进行预测,输出预测结果。
3 实验与结果分析
实验采用2018年1月1日至2019年11月30日作为训练数据,将训练数据自动划分为6 ∶1比例的训练集和验证集,使用2019年12月1日至2019年12月31日作为预测数据。根据3.1节特征处理,得到表1所示特征统计表。
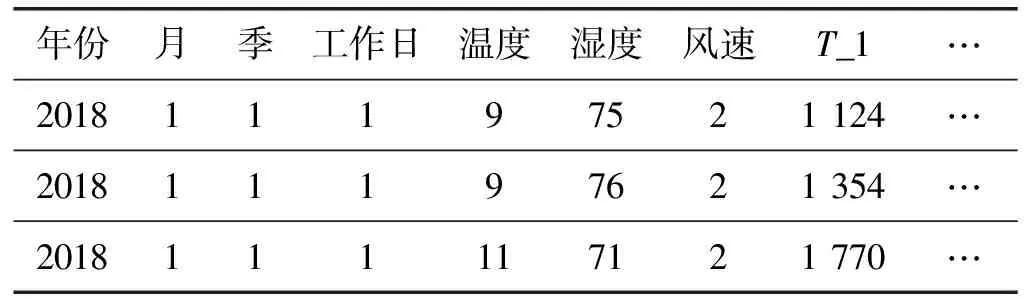
表1 某商业建筑历史能耗特征统计
为了更好地判定预测结果准确度,根据文献[19],选取指标函数均方根误差(RMSE)、相对误差(CV-RMSE)、使用平均绝对误差(MAE)作为额外的评估指标,可以更加准确地评估组合模型预测的效果。三种评估指标的表达式为:
使用验证集选取模型的权重系数,计算每天数据的权重系数,最终取每种权重系数的均值作为最后的权重系数,经过均值化的权重系数w1=0.5、w2=0.5。图12是组合模型预测12月份小时均值,可以看出预测的效果符合节假日影响因素,在节假日时期,能耗的使用偏高。
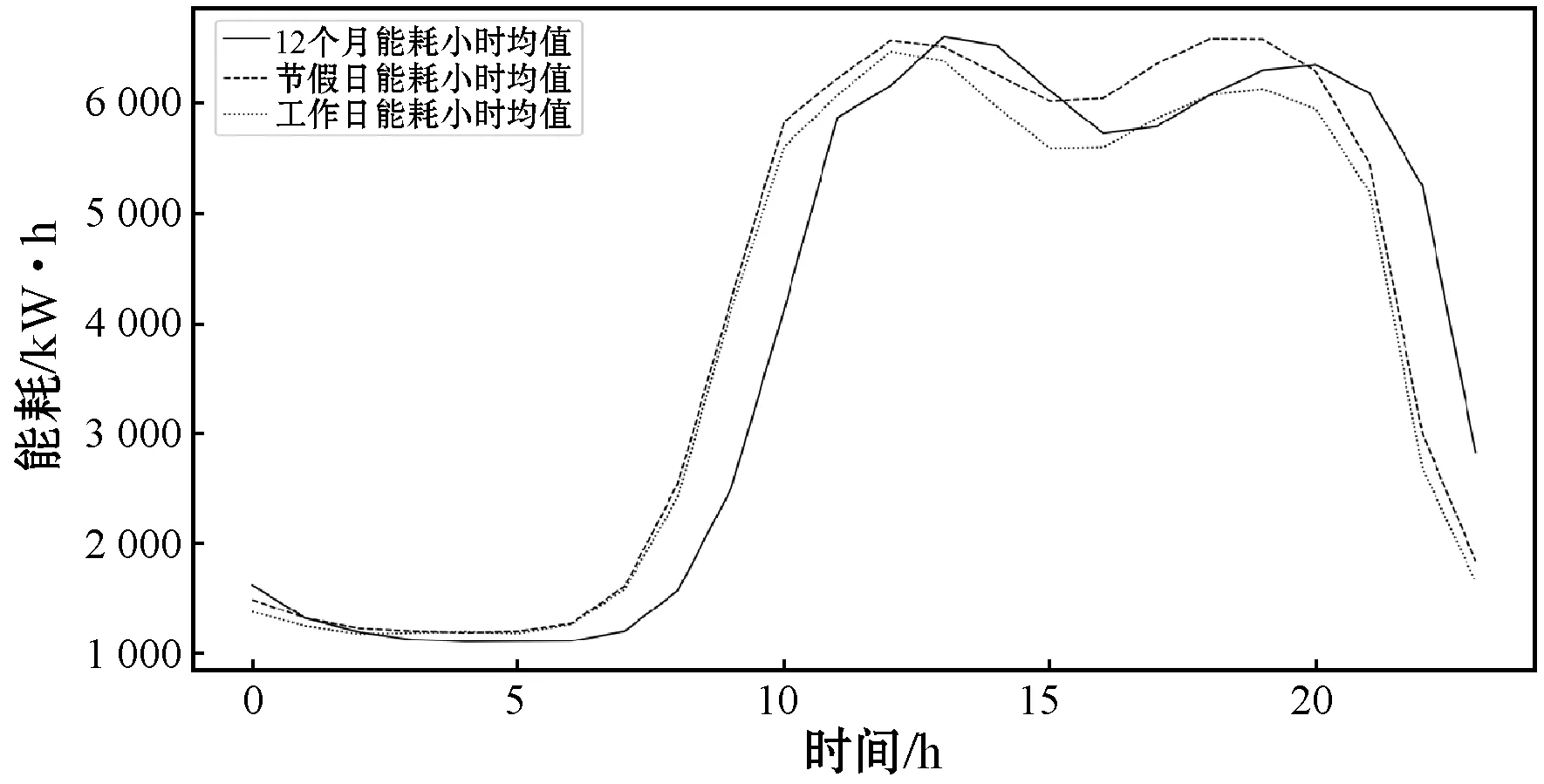
图12 组合模型预测结果的12月份小时均值
图13展现了组合模型的预测效果,由于组合模型的真实值与预测值相差很小,所以使用了按天和周的预测数值做进一步分析,可以看出组合模型预测效果基本介于LightGBM和LSTM之间,相对有效。
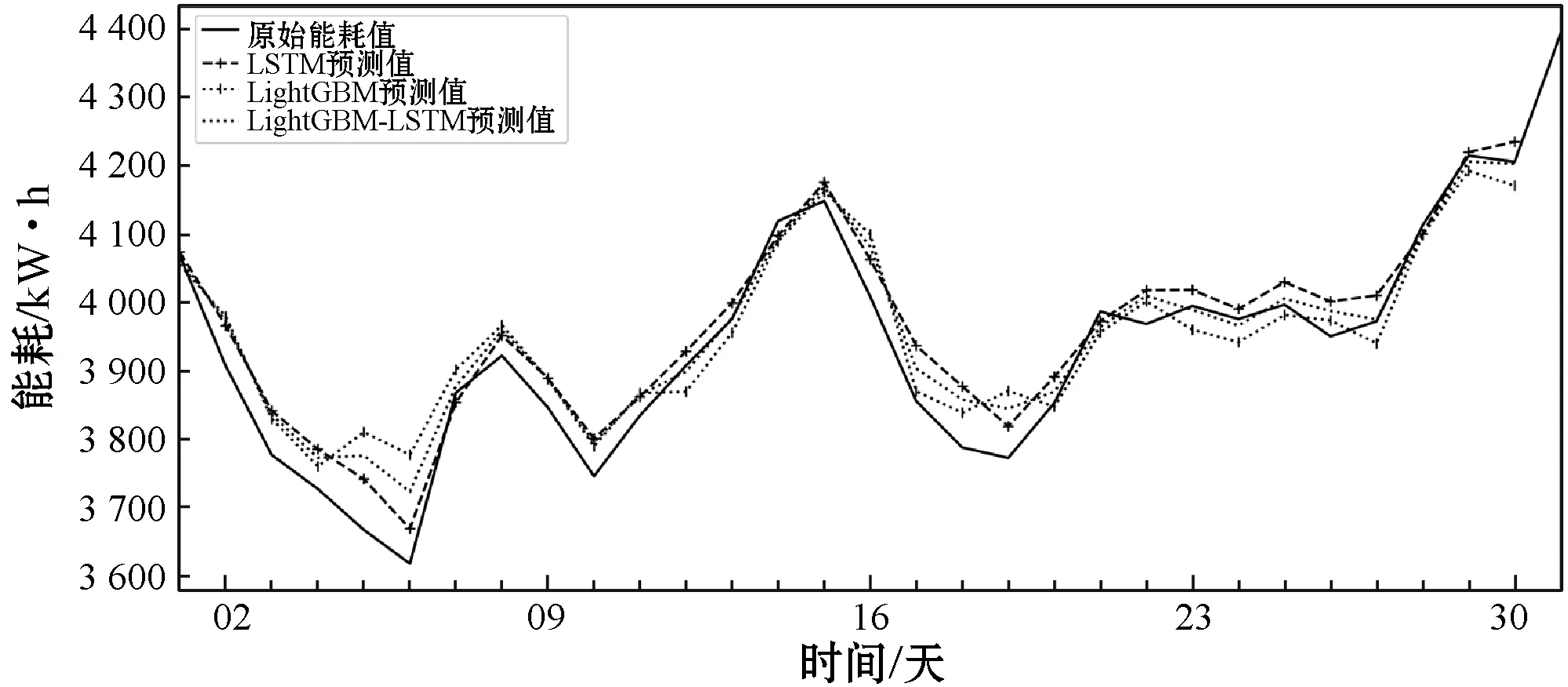
(a) 建筑能耗序列模型每天预测结果
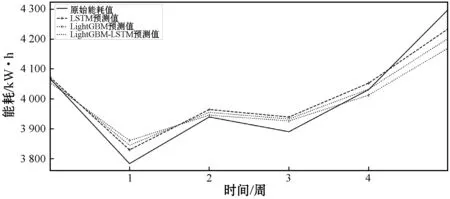
(b) 建筑能耗序列模型每周预测结果图13 能耗预测结果
为了进一步验证LightGBM-LSTM模型的性能,类比文献[20],本文选取了几种算法做对比实验,将所选取的模型与本文设计的LightGBM-LSTM组合模型实验结果做对比,使用24 h的滑动窗口均值拟合,如图14所示,LigthGBM-LSTM预测效果相对较好。
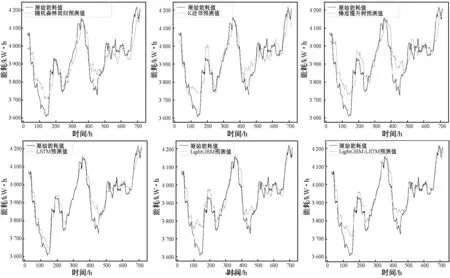
图14 24 h滑动窗口拟合均值模型对比
指标评估结果如表2所示,可以看出,在单项模型中,LSTM与LightGBM模型预测的误差较小。LightGBM-LSTM组合模型的CV-RMSE误差为3.08%,与其他各种单项模型相比相对最小,MAE的误差指数也是最小。这表明LightGBM组合模型通过权重组合的方式,对预测精度做了提升。
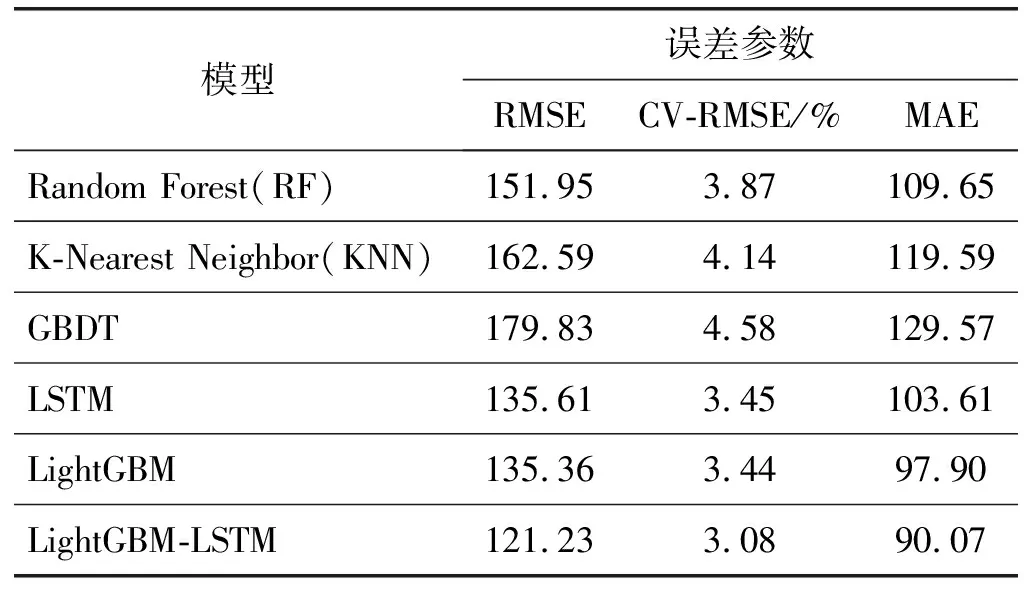
表2 模型性能对比
4 结 语
分析建筑能耗使用规律和相关特征对企业节约成本、节约资源使用有着重要作用。本文依据上海某大型商业建筑历史能源使用序列,提出一种基于LightGBM-LSTM组合模型预测的方法,构建经LightGBM模型与LSTM模型的方差协方差方法加权预测模型,并且与组合前单项模型以及其他几种经典的机器学习模型进行实验对比。实验结果表明,LightGBM模型与LSTM模型本身的单项模型的预测能力都高于其他模型的预测能力,经过组合后的模型的预测性能优于其他模型,表现了LightGBM对特征合并以及LSTM时间序列预测的优越性,总体来说,通过加权方式,充分发挥了两种模型的优势。
本文只设计了两个优势不同的模型的组合预测,针对建筑能耗短期数据做出的预测,未来可以在此基础上设计能耗长期预测的方法。后续会继续改进LSTM模型相关实验,选取更多的特征因子做进一步研究,寻求更优秀的建模方式以及提升长期预测效果的方法。
