基于TPE-LSTM的区域超短期风电功率预测
2022-12-03查雯婷闫利成李亚龙
查雯婷 闫利成 陈 波 李亚龙 杨 帆
1(中国矿业大学(北京)机电与信息工程学院 北京 100083)2(内蒙古电力科学研究院 内蒙古 呼和浩特 010020)
0 引 言
风能作为一种不确定性电源,随着其在电力系统中的比例逐年升高,大规模集群入网的方式对系统调度带来了巨大的挑战[1-2]。同样电力系统的不确定性也急剧增加,如何提高风电功率的预测精度成为该领域的研究热点之一[3]。然而目前的研究对象多为单一风电场,鲜有对大区域的风电功率预测研究[4]。高精度的区域级超短期风电功率预测对风电并网、风电定价等方面有着重要的参考价值[5]。区域风电场和单一风电场的功率预测情况有所不同。单一风电场的研究数据可选用历史功率数据、天气预报(NWP)数据和风电场周围的物理信息数据等。但区域预测时由于不同地区的差异性导致大多特征数据都难以适用,只能选用历史功率数据作为研究对象,故预测难度也更高。因此能否从历史数据中挖掘到有用信息成为提高区域风电功率预测精度的关键。
目前区域级风电功率预测的方法或模型还很少,文献[6]通过气象预测数据与历史数据的相似程度,采用加权平均外推法得到区域功率预测值。文献[7]通过预测基准风电场功率而映射出各子区域功率,通过叠加再得到区域的风电功率。文献[8]采用统计升尺度方法获取区域风电功率。这些方法存在的问题是模型相对简单,而区域风电功率数据的规律性较差,传统的统计学习和机器学习模型难以获得较高的预测精度。随着大数据技术的进步和并行计算能力的提升,深度学习技术取得重大突破,神经网络在时序预测领域得到广泛应用[9]。其中循环神经网络(RNN)正是一种处理时序数据的神经网络,LSTM是RNN的改进模型,可以解决RNN在使用中存在的问题,同时兼顾数据的时序性和相关性[10],能充分反映时间序列数据中的长期历史信息[11]。文献[12]使用LSTM预测居民用电负荷,并论证了LSTM相较于传统预测方法的优越性。文献[13]使用LSTM预测PM2.5的变化情况,实验结果表明该模型既可以较准确地预测变化趋势,又可以响应波动变化。文献[14]提出了一种基于LSTM的股票预测模型,并对损失函数做正则化处理,结果表明该模型可以获得较高的拟合程度。LSTM在时序预测领域中的广泛应用,也为区域风电功率预测提供了可能。
超参数是指在开始学习过程之前设置的参数集,它的选取将直接决定网络模型的拓扑结构。LSTM模型在构建过程中同样需要设置很多超参数。为了找到最合适的超参数组合,并尽量降低时间资源和计算资源的消耗。文献[15]提出了一种贝叶斯优化算法的变型,名为TPE(Tree-structured Parzen Estimator)的调优理论。贝叶斯优化算法可以看成通过先验分布使用启发式手段的一种间接的寻优方法,与网格搜索遍历参数空间和随机搜索[16]利用随机数去求函数近似的最优解明显不同。贝叶斯优化在搜索过程中会参考之前的参数信息,不断更新先验分布,因此可以迭代更少的次数,但精度更高。
为了提高区域超短期风电功率预测精度,本文采用TPE算法对LSTM模型中比较重要的部分超参数自动寻优,借助历史风电功率数据完成模型的训练。此外为了减小预测过程中存在的误差,加入误差校正环节对预测结果完成校正。为验证TPE-LSTM网络的预测精度,加入实际的工程预测数据、BP网络和RNN网络与其比较。同时为了进一步证实TPE算法对模型超参数寻优的有效性,将参考模型中重要的超参数同样采用TPE算法寻优。
1 算法原理与方法
1.1 长短期记忆网络
LSTM相比RNN在内部结构上多了一种自环结构的记忆单元(Memory Cell)。这样的设计虽然提高了模型的复杂度,但可以很好地解决RNN在使用过程中存在的梯度消失或梯度爆炸等问题,能够深入挖掘在时间序列中蕴含的内在规律。LSTM基本单元模型如图1所示。
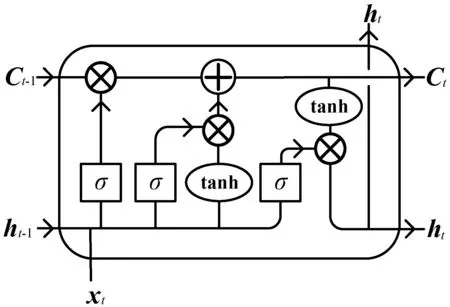
图1 LSTM基本单元模型
记忆单元中的三个控制门:输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)。输入门有条件地决定单元中存储的信息,遗忘门确定计算单元历史状态信息的保留,输出门控制信息输出。Sigmoid激活函数可以将控制门的输出映射到区间[0,1]内,当输出值越接近0时,表示上一状态的信息被舍弃得越多;当输出值越接近1时,表示上一状态的信息被保留得越多。LSTM的原理可以由式(1)-式(6)进行描述。
ft=Sigmoid(wf·[ht-1,xt]+bf)
(1)
it=Sigmoid(wi·[ht-1,xt]+bi)
(2)
ot=Sigmoid(wo·[ht-1,xt]+bo)
(5)
ht-1=ot×tanh(Ct)
(6)
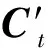
1.2 TPE算法原理
超参数寻优的目的是最大程度提高模型的性能或效果。优化过程如式(7)所示,其中配置空间X由所有需要优化的超参数组成,经过不断调节模型的超参数,可以得到一组最优值x*。
x*=argminf(x)
(7)
式中:X是配置空间;f(x)是目标函数;x*是X中使得目标函数f(x)取得最小值的一组超参数。
贝叶斯优化是一种对模型超参数自动寻优的搜索方法,原理是基于目标函数在先前的评估结果建立以概率模型为依据的替代函数。与其他搜索算法相比,贝叶斯优化将搜索问题转换成一个优化问题,并且在每次更新超参数时都会参考先前的观测空间和优化结果。在文献[15]中,Bergstra等提出一种贝叶斯优化的变体TPE算法来优化模型的超参数,其采用对p(x|y)和p(y)同时建模的方式代替只对p(y|x)建模。其中:p(y)代表解的分布情况;p(x|y)代表已知解的情况下,参数x的分布情况。此外引入优化标准EI用于引导搜索配置空间。p(x|y)计算如下:

式中:y′是已经定义好的阈值;l(x)表示观测值x(i)的损失函数比y′小的密度估计值;g(x)表示观测值x(i)的损失函数比y′大的密度组成。
为了防止在寻优过程中陷入局部最优,确保能够遍历所有有希望的配置区域。EI正好可以满足这样的要求,它可以理解为相对于阈值y′,新的超参数所对应的解所能提高的幅度。EI的定义如式(9)所示。

从式(10)可以看出,在最大化EI寻找更优的超参数过程中,EI应该逐步迭代到使g(x)/l(x)更小的值,即逼近最大概率的l(x)和最小概率的g(x)。
1.3 最小二乘多项式拟合校正
超参数寻优后的LSTM模型虽然具有强大的泛化能力,但是仍然存在一定的误差。为了尽可能缩小模型预测误差,采用最小二乘多项式以n阶多项式拟合预测数据前的s个数据,拟合完成后得到拟合曲线并求取右端点外一个数据点的数值f(x′)。拟合过程使用的多项式如式(11)所示,具体的误差校正过程如式(12)所示。
2 模型构建
为了实现风电功率预测,需要构建合适的神经网络模型,以达到理想的预测效果。具体包括数据的修复及预处理、超参数优化、预测流程的确定和模型预测精度评价指标的选取。
2.1 数据的修复及预处理
由于获取的数据中存在部分缺失,按照缺失数据时间间隔的长短分别采用线性插值和相似天填补的方法完成修复,并对其完成降噪以提高信噪比。
确保数据的完整性后,需要对数据进行归一化处理。归一化是一种无量纲的数据处理手段,把带有单位的物理量线性映射到区间[0,1]内,处理成不含单位的相对值。此过程有利于降低运算量、加快收敛的速度和降低量值之间因为量纲和数量级的差异而带来的影响。计算公式如式(13)所示。
式中:P′为归一化后的风电功率值;Pt为当前的风电功率值;Pmax和Pmin为当组实验数据中的风电功率数据的最大值和最小值。
2.2 超参数优化
使用TPE算法对LSTM网络寻优时,首先应确定需要寻优的超参数和各超参数的取值范围。本文模型主要优化的超参数包括输入时间长度L、隐含层层数N和隐含层节点个数J等。输入时间长度L表示训练和预测过程中的历史数据序列长度,其数值确定既需考虑历史时序信息的完备利用,也需考虑预测模型的有效训练。隐含层层数N即LSTM层的层数,它的选取需要衡量数据规模和训练时间。隐含层节点个数J即LSTM层每一层中的神经元数量,可依据经验公式得到取值范围。经验公式如式(14)所示。
式中:nh为隐含层的节点数;n为输入层的节点个数;l为输出层的节点个数:α为[1,10]之间的常数。
此外学习率R、迭代次数Epochs和批次大小Batch_size同样很重要。其中,合适的学习率及批次大小设置有助于显著提升深度学习模型迭代收敛速度与预测精度。
2.3 预测流程
考虑到风电功率受天气和政治经济等因素的影响,在超短期内具有一定的规律性。因此选取连续的一段数据作为数据集,并将其按照t∶v∶e的比例将数据划分成训练集、验证集和测试集。训练集和验证集同为n∶l的多输入、多输出训练模式,在完成训练和验证过程后保存最佳的模型,使用此模型实现对测试集的数据预测,完整的预测过程如图2所示。
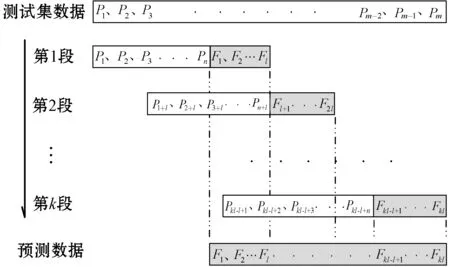
图2 预测过程
网络的输出层采用LSTM网络与全连接层连接的方式,并将此层的激活函数设为线性激活函数,目的是将具有强非线性特征的预测问题简化成线性回归问题。完整的模型预测流程如图3所示。
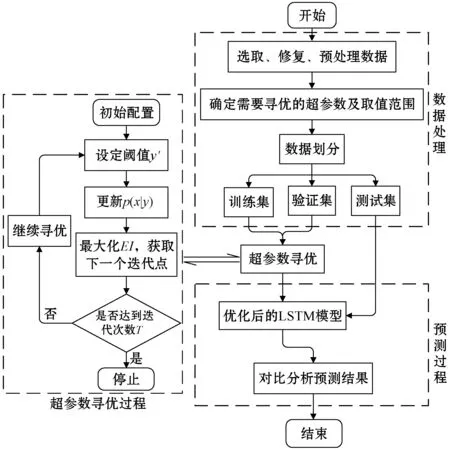
图3 模型预测流程
2.4 模型预测精度评价指标
以输出层节点长度为单位统计每一次的预测结果,建立以均方根误差(RMSE)、平均绝对百分误差(MAPE)和合格率Q为评价指标的评价体系。RMSE和MAPE的计算如式(15)、式(16)所示,合格率的计算如式(17)、式(18)所示。
式中:Pp是风电功率预测值;Pr是风电功率真实值;n是目标预测数量;Sop为开机总容量。3个不同的评价指标均能反映模型的预测精度,其中:ρRMSE和ρMAPE越小表示预测误差越小;Q则是越大表示预测误差越小。
3 实验与结果分析
根据上文建立的LSTM模型,选取北方某区域所有风力发电厂在2018年9月至2018年11月中旬共76天的历史风电功率数据(时间分辨率为15分钟)作为实验数据。按照7 ∶3 ∶6的比例划分成训练集、验证集和测试集。本文将测试集的比例提高是因为预测过程中用到的模型是已训练好的模型,模型不需要重复训练,提高测试集的比例以证明模型的泛化能力。模型的输出尺度为4,将预测结果反归一化后得到的数值即代表在未来1个小时的预测功率值。
3.1 LSTM网络模型的确定
在超参数寻优过程中为了降低主观判断对模型预测精度的影响,在设置各超参数的选取范围时尽可能做到广泛、全面,这样才能寻找到最佳的超参数组合。理论上3层的网络已经可以逼近任何的非线性函数,从而将LSTM层数控制在4层以内。依据前文中需要确定的超参数,对超参数的取值范围设置如表1所示。
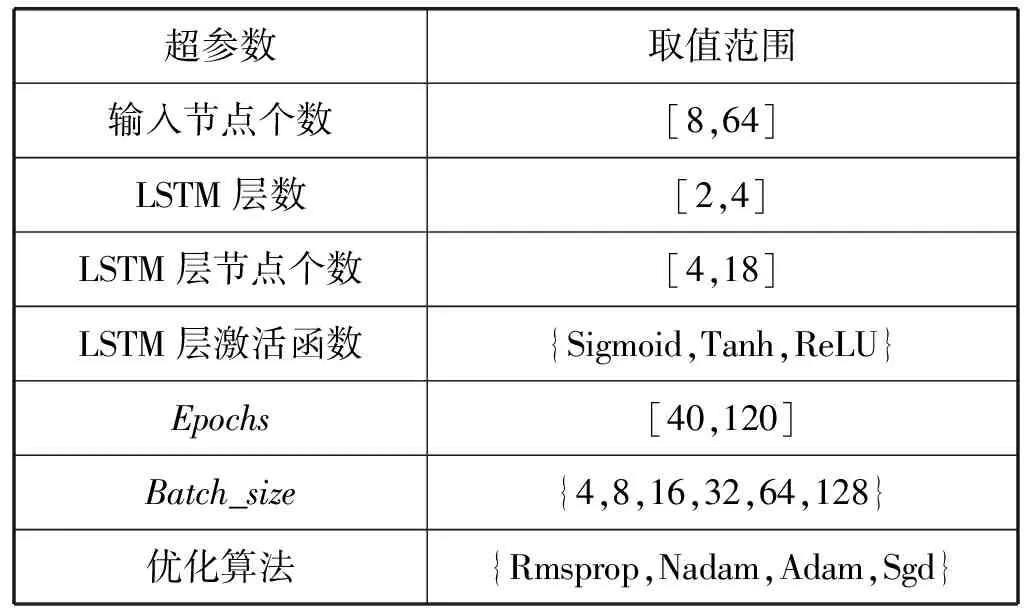
表1 模型超参数取值范围
经过TPE寻优得出的超参数配置如下。输入节点个数为16;LSTM的层数为2,其中第一层LSTM网络的节点个数为9,第二层LSTM网络的节点个数为6,构成一个16- 9- 6- 4的四层神经网络;激活函数为Sigmoid;Epochs为78;Batch_size为8;优化算法为Adam。
3.2 网络模型对比实验
为了验证经TPE算法优化得到的LSTM模型可以更好地提升预测精度,进行对比实验的BP和RNN同样使用TPE算法寻优。由于受到数据数量级大小的影响,实验结果的RMSE较大。模型预测精度如表2所示。
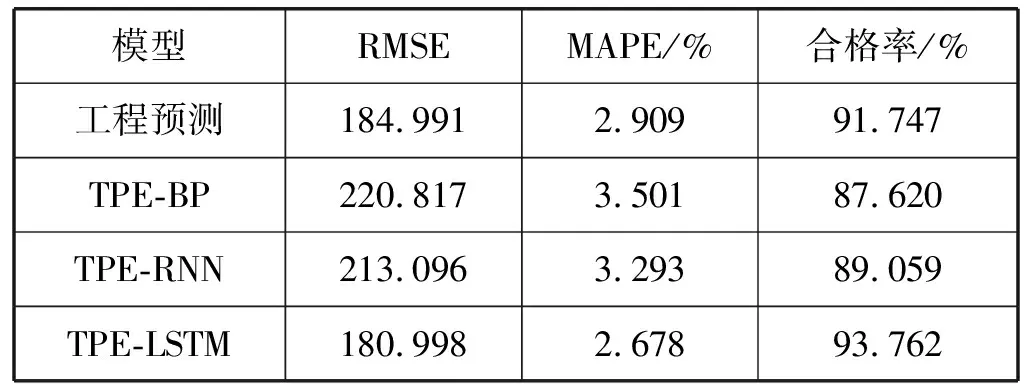
表2 模型预测精度对比
可以看出,TPE-LSTM模型与工程预测数据相比均方根误差、平均绝对百分误差分别只低了3.993、0.231百分点,合格率也高了2.015百分点,这说明TPE-LSTM已经超过了工程预测数据的预测精度,但是还比较有限。为进一步研究误差校正对模型预测精度的影响。根据式(11)、式(12)对预测数据进行误差校正。表3给出了TPE-BP、TPE-RNN和TPE-LSTM算法经过误差校正之后的RMSE、MAPE和合格率。

表3 误差校正后模型预测精度
为了更好地对比误差校正对预测精度的影响,将TPE-BP、TPE-RNN和TPE-LSTM三种模型校正前后的数据结果进行对比,如图4、图5和图6所示。
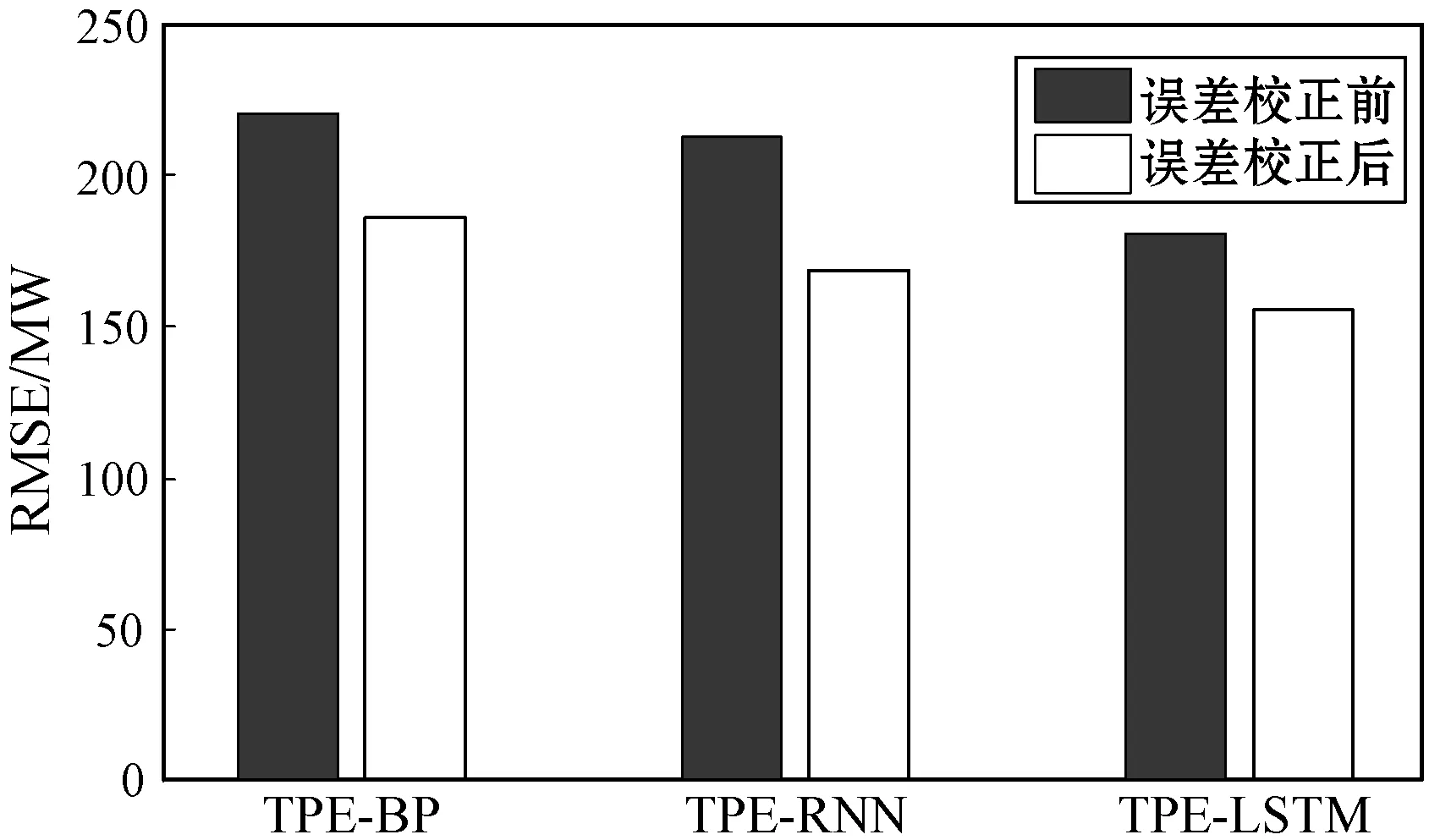
图4 误差校正前后RMSE对比

图5 误差校正前后MAPE对比
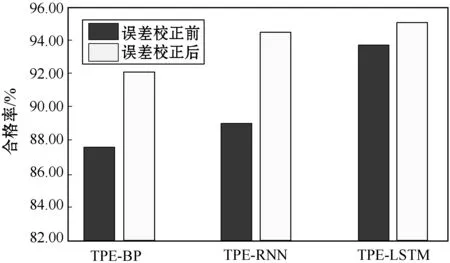
图6 误差校正前后合格率对比
可以看出误差校正前后,三种模型的RMSE和MAPE均有不同程度的降低,合格率也均有不同程度的提升,其中TPE-LSTM的RMSE相较于误差校正前降低了25.504,相较于工程预测数据较低了30.396;TPE-LSTM的RMSE相较于误差校正前降低了0.497百分点,相较于工程预测数据较低了0.728百分点。从图6中可以看出误差校正前后,三种模型的合格率也均有不同程度的提升,其中TPE-LSTM的合格率相较于误差校正前提高了2.579百分点,相较于工程预测数据提高了4.594百分点,此外TPE-BP和TPE-RNN的预测精度也同样有较大的提升。实验结果表明,误差校正策略能够有效降低算法预测误差,提高算法的预测精度。
3.3 误差校正有效性分析
为了验证误差校正可以有效减小模型在预测过程中存在的误差,真正提升模型的预测精度。此节着重对比误差校正后TPE-BP、TPE-RNN和TPE-LSTM三种模型的预测数据与工程预测数据之间的差异,对RMSE和MAPE以每4个数据为统计长度统计每次预测结果的RMSE和MAPE,统计后的RMSE分布情况如图7所示,MAPE分布情况如图8所示。
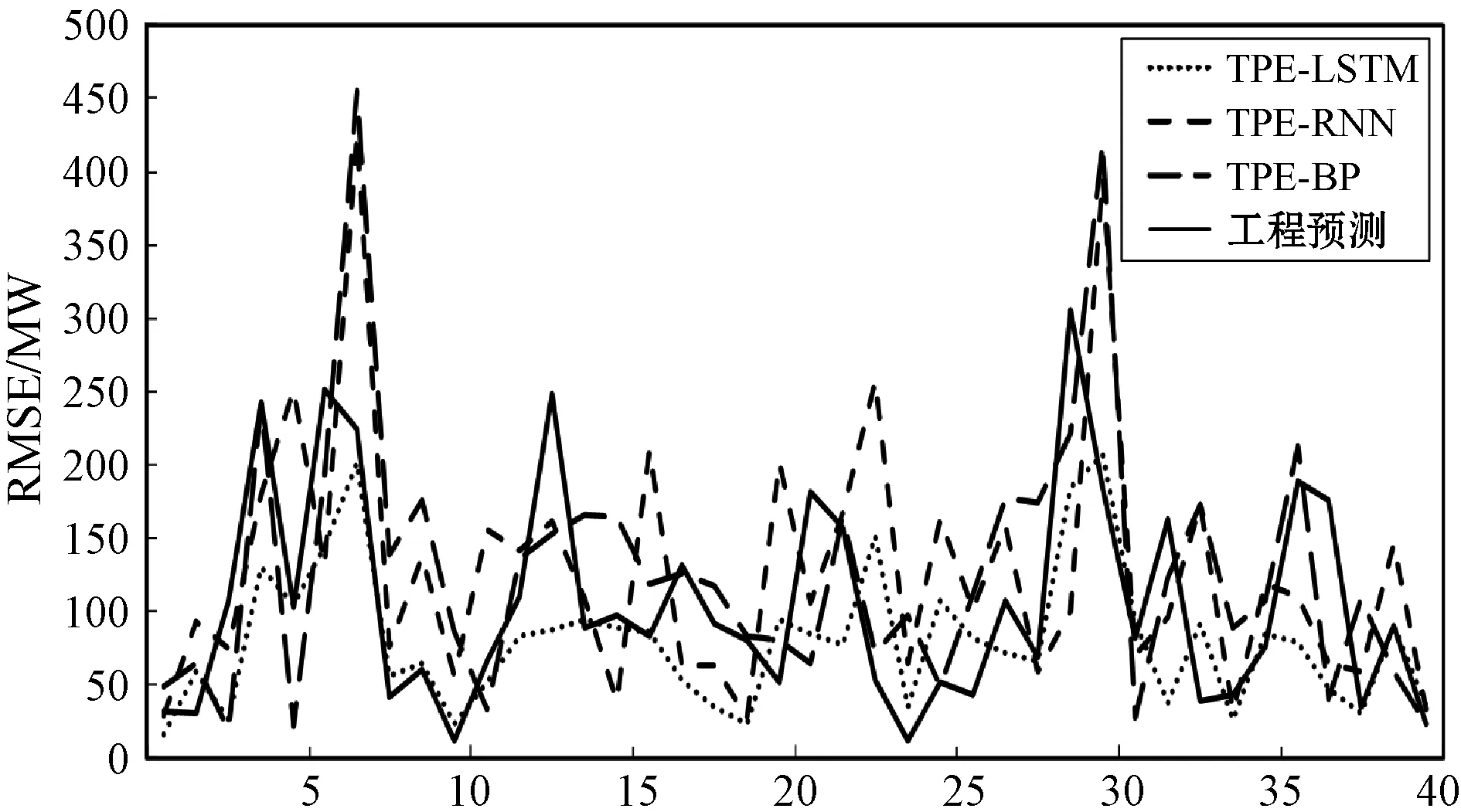
图7 前40次预测结果的RMSE
图7给出了误差校正后TPE-LSTM、TPE-RNN、TPE-BP和工程预测数据在前40个预测点的RMSE对比。可以看出,TPE-LSTM的RMSE在四种模型中总体变化稳定且幅值也更小,这同时也证明TPE-LSTM模型的预测结果变化趋势与真实数据更接近。
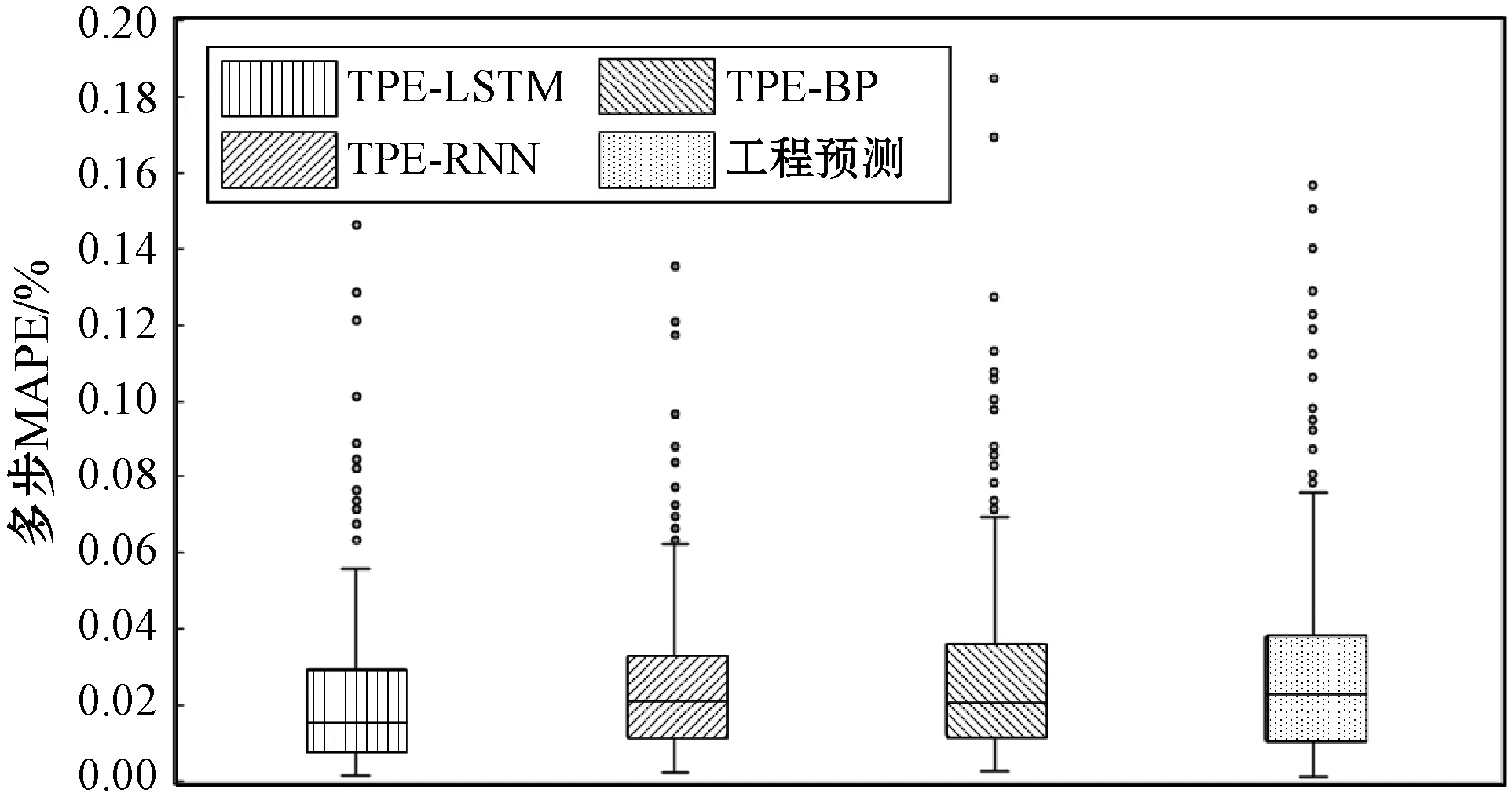
图8 MAPE分布情况
从图8中可以看出,误差校正后TPE-LSTM数据的误差分布情况更集中。其上边缘、上四分位数、中位数和下四分位数也都是4种模型中最低的,并且其异常值也并不大,因此可以推断出误差校正后TPE-LSTM的MAPE应该也是最低的,表3中的数据也证明了这一点。因此相比之下,TPE-LSTM算法的预测效果具有更好的拟合效果和预测精度。
以上实验结果表明,本文提出的TPE-LSTM模型预测结果精度更高,且预测结果波动小,误差相对稳定,验证了该算法的有效性。
4 结 语
利用历史风电功率数据,提出一种基于TPE算法和LSTM的区域超短期风电功率预测方法,结果表明基于贝叶斯优化方法中的TPE算法可以解决神经网络模型的超参数优化问题,具有迭代次数少、用时短等优势。依据寻优后的超参数组合搭建的LSTM网络模型具有较强的泛化能力,在区域超短期风电功率预测方面相较工程预测数据和其他模型具有较高的预测精度,是一种实际且可行的方法,在此领域中具有较好的应用前景。
