基于注意力机制的交通场景图像描述生成算法
2022-12-03宋禄琴玄祖兴王彩云
宋禄琴 玄祖兴 王彩云
1(北京联合大学北京市信息服务工程重点实验室 北京 100101)2(北京联合大学基础与交叉科学研究所 北京 100101)
Image caption
0 引 言
当前,深度学习迅速发展,图像描述作为计算机视觉和自然语言处理的交叉研究课题,具有十分广阔的前景。图像描述生成[1]任务是指将图像的视觉信息和图像的文本信息相结合,对输入图像的视觉特征和文本的关键词特征提取分析,得到一句或者一段关于该图像的文字描述。可应用在无人驾驶领域,主要体现在辅助视觉障碍人群、安全辅助驾驶、交管部门管理等方面都具有广泛的应用价值。例如,在现实交通环境中,经常出现行人横穿马路、司机随意变道、司机疲劳驾驶等不确定性复杂的行为,这些情况给人们的出行以及交管部门的管理带来了新的挑战。
目前,国内外出现许多自动驾驶企业,例如特斯拉、Mobileye、百度等,他们对汽车的智能驾驶主要是通过雷达、视觉图像、全球定位系统等传感器共同实现对汽车的智能驾驶。大多数学者和工业界从目标检测[2-3]、目标识别[4]和全景分割[5]等角度对交通场景图像进行研究,忽略了语义角度。现有资料表明,对交通场景图像的图像描述生成[6]研究较少,本文将从图像描述角度出发,利用神经网络实现对部分交通场景的图像描述。
1 图像描述生成算法研究现状
目前,图像描述生成算法大致分为三类:基于模板的方法、基于检索的方法、基于神经网络的方法。本文采用的基于神经网络的方法。
基于模板的方法,这类方法一般具有固定模板,句子中包含许多空白的位置用来生成标题。利用计算机视觉技术检测图像中存在的对象、属性,以及识别出图像可能发生的动作,最后将关键字填入模板中的空白处。Farhadi等[7]提出一种三元模型,该模型由对象、动作和场景三种元素组成,将模型检测出的关键字填充在句子的空白模块,生成与图像相匹配的图像描述。由于模板是预定义的,不能生成随意变换长度的句子,因此基于固定模板的方法生成句子比较单一。
基于检索的方法,文献[8]从训练数据集中匹配与目标图像标题视觉上类似的图像,然后将标题标记为候选标题。基于检索的方法生成的描述和语法正确的标题,但是对于特定语义的图像或者数据集从未出现的语句无法生成正确的图像标题。
基于神经网络的方法,该方法通常采用编码器-解码器的组合架构。在编码阶段使用卷积神经网络(Convolutional Neural Network,CNN)算法提取图像特征信息,解码阶段使用循环神经网络(Recurrent Neural Network,RNN)或者长短期记忆网络来(Long Short Term Memory,LSTM)描述图像。
其中,最具有代表性的算法是多模态循环神经网络(multimodal RNN,m-RNN)[9],Mao等首次将图像描述生成任务分为两个子任务,在CNN任务中,通过AlexNet对提取图像特征,用独热编码将文字编码为词向量,将图像特征和词向量共同传送至RNN网络。由于RNN结构单一,随着网络深度的加深,容易产生梯度消失,存在学习能力下降的缺点。Vinyals等[10]提出了神经图像描述生成(Neural Image Caption,NIC)算法,使用LSTM代替普通的RNN,同时在CNN结构中使用批处理操作,在之前的算法基础上,精度和速度得到大幅度的提升。该算法的不足之处在于,LSTM的输入部分为图像经过CNN提取出的全局特征,并未考虑图像中存在的关键信息,导致图像在生成句子描述上语义表达模糊。Xu等[11]首次将注意力机制使用在图像描述生成任务上,使图像在生成语言文字序列时,选择关注区域,提升图像描述生成模型的精度。在提取特征过程中,随着网络深度的增加,网络存在学习能力退化问题[12],He等[13]提出残差网络(Residual Network),有效解决了网络退化问题。Xu对图像特征提取后,语言模型的输入为固定特征向量,并不能及时获得图像表达的完整语义,Wang等[14]提出了多注意力机制,可以充分地使用图像特征进行语言描述。
You等[15]提出语义注意力模型,卷积神经网络通过top-down和bottom-up提取图像特征,通过分类图像特征信息提取出图像的语义属性特征,最后利用注意力机制选择语义特征向量生成图像描述。随着网络深度的加深,该模型出现图像信息逐渐丢失的问题。Lu等[16]提出视觉标记的Adaptive Attention算法,该算法在生成描述句子时,自适应地选择依赖输入图像的视觉特征信息来生成视觉词或者依赖LSTM语言模型来生成非视觉词。Anderson等[17]提出结合bottom-up and top-down 两种注意力机制,在提取图像特征阶段使用Faster R-CNN[18]网络模型,该模型中的区域生成网络(Region Proposal Network,RPN)可以提取图像相对应的目标。不足之处在于RPN提取候选框较多,模型中存在较多的重复计算。文献[19]提出在注意力机制中使用全卷积替代全连接操作,使得模型参数量减少,在一定程度上提升了运行速度。上述网络模型在图像描述生成任务中各有其优点,能够良好地使用自然语言描述图像。
本文提出一种基于注意力机制的图像描述生成模型。主要有以下特点:(1) 使用改进的卷积神经网络提取丰富的图像特征,将图像特征分为不同区域,分别依次连接注意力机制,使得算法在生成描述时,可以自主选择各区域的特征;(2) 得到带有注意力权重的图像特征与多层LSTM语言模型相连,使其更加准确地完成对交通场景图像描述生成;(3) 在解码阶段,对图像的自然语言描述采用Word Embedding中的Word2vec编码方式,相对以前常用的one-hot编码,能够有效地解决文本的有序性问题和文本向量维度灾难等问题。
为了验证算法的可靠性,本算法在MSCOCO[20]数据集上进行了验证,该算法在评估指标BLEU-1至BLEU-4上分值分别为0.735、0.652、0.368和0.323。实验表明,本文算法能够准确地对交通场景图像进行描述生成。
2 本文算法
对交通场景图像理解,本文从语义角度出发,提出一种基于注意力机制的图像描述算法,本文算法分为编码阶段和解码阶段。编码阶段,为了得到更加准确的图像描述,本文算法利用深度残差网络提取图像特征,重点是在图像特征中增加了注意力权重,得到带有权值的图像特征,定义为集合C,解码阶段结合LSTM语言模型共同完成图像的描述生成。如图1是本文算法的总体流程。
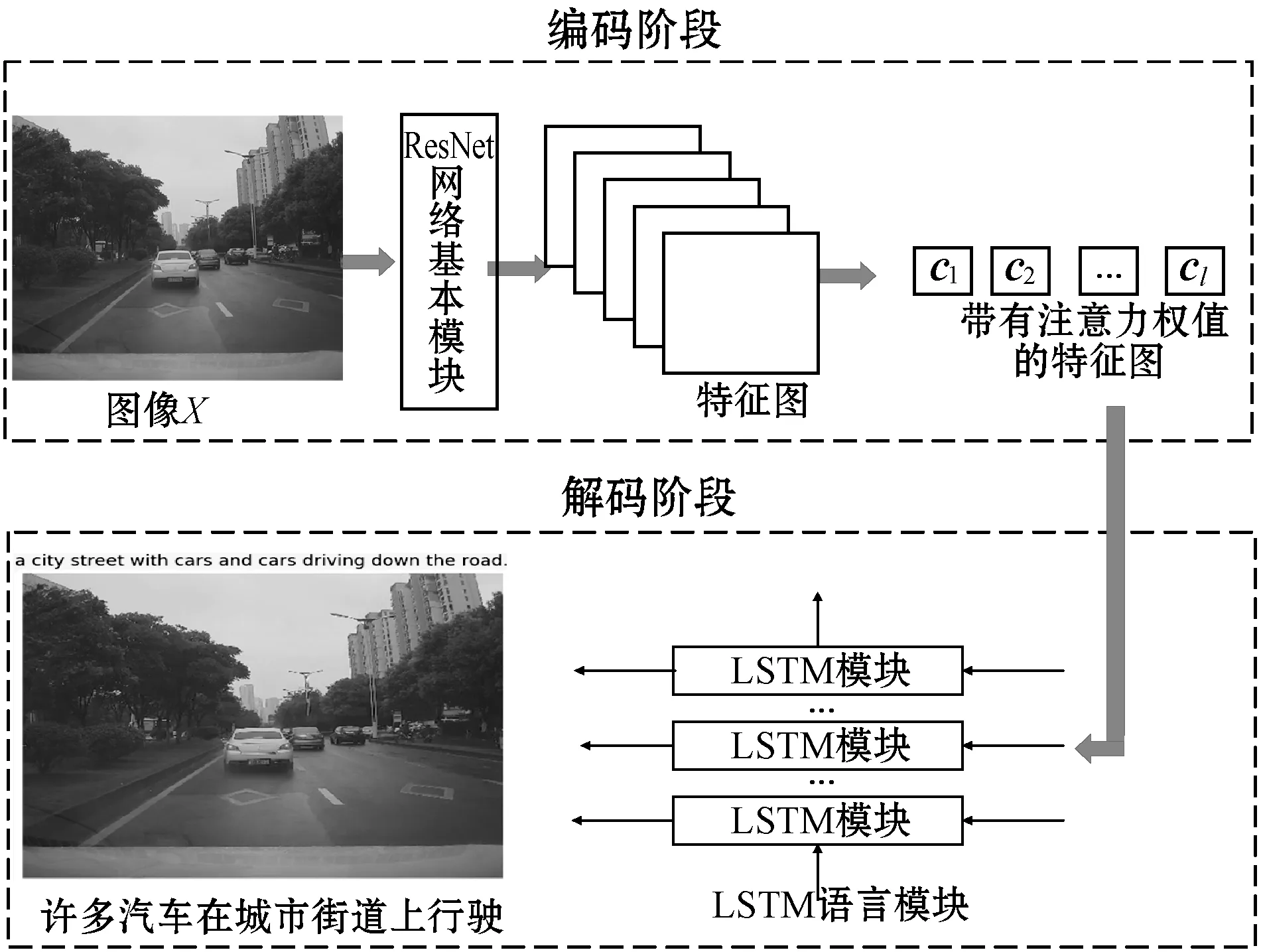
图1 本文算法的总体流程
用X表示输入的训练图像,对应的文本描述为S={S1,S2,…,Sn},其中:Si表示输入句子的第i个单词;n表示文本句子中单词的最大长度。C为带有注意力权值的图像特征集合。
网络结构中,图像X经过LSTM生成的单词概率如式(1)所示。
模型在训练中,训练目的即使图像特征与描述句子之间的映射关系最大化,模型所需学习的模型参数表示为式(2)。

式中:S为图像X生成的句子且长度不固定;θ为模型需要学习的参数,训练时通过优化θ的方式来最大化图像生成正确的图像描述概率。
2.1 编码阶段
2.1.1图像特征提取
网络层数越多,提取的特征越丰富,但是随着网络的深度加深,网络在训练集上的准确率容易趋近饱和。为了得到丰富的特征,本文使用深度残差网络,该网络在普通卷积网络结构中引入跳跃式连接方式构成残差模块,有效地解决了随着网络层数的加深,网络的准确率和学习能力降低等网络退化问题。
深度参数网络由残差模块(residual block,RB)组成,图2为一个残差模块结构示意图。
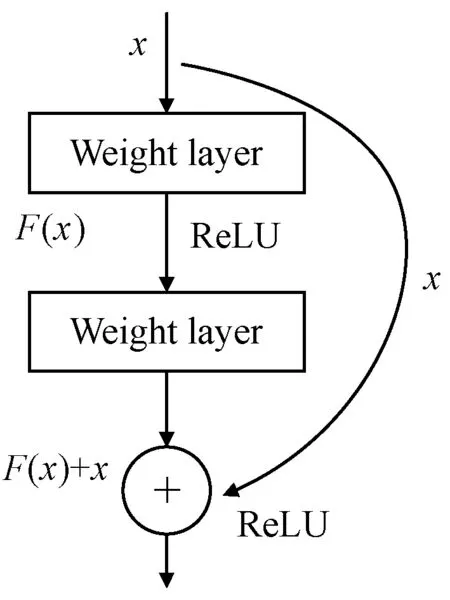
图2 一个残差模块示意图
用x表示网络的输入,H(x)表示网络的输出,x通过跳跃连接方式直接作为输出的初始结果,得到输出结果H(x)见式(3)。
H(x)=F(x)+x
(3)
当F(x)=0时,构成恒等映射H(x)=x,网络的学习目标发生改变,即H(x)和x的差值,训练目标为将残差结果无限趋近0。将求恒等映射H(x)=F(x)转变为求式(4),拟合残差函数比直接拟合函数H(x)=x更加容易。
F(x)=H(x)-x
(4)
本文采用50层的深度残差网络,网络中包含4种不同参数的残差模块,每个残差模块由三层卷积组成。残差模块第二层采用3×3卷积先经过第一层卷积核大小为1×1的卷积降维,用来减少参数的计算量,在最后一层1×1卷积时做了维度还原操作,保持了精度的情况下减少了计算量。网络结构中包含16个残差模块,具体网络结构如图3所示。
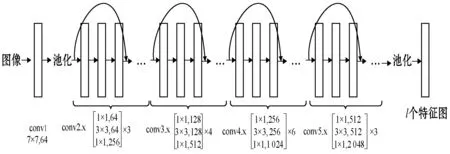
图3 ResNet50网络结构
图像经过卷积、池化操作后得到l个特征图,用集合A表示,见式(5),其维度为D。
A={a1,a2,…,al}ai∈RD
(5)
2.1.2融合注意力机制
在图像描述生成中融合注意力机制,可以更准确地表达图像突出的特征信息,注意力机制的本质是把图像对应的文本描述和图像中的不同区域做一个映射。在以往的图像描述模型中,在预测t时刻单词时,其映射关系为式(6)。
ht=f(ht-1,xt-1)
(6)
式中:ht-1表示上一时刻隐层的输出信息;ht是当前时刻的隐藏层输出值。编码阶段在提取特征向量过程后,在解码阶段预测单词均使用最初输入的图像特征,并不能在每个时间节点关注到图像的突出区域。
将一幅图像分为l个不同区域,对不同区域使用卷积神经网络提取特征,在l个不同区域融合注意力机制,赋予不同区域不同的权值,使得网络在预测单词过程中,可以时刻关注到图像的重点区域。图4是融合注意力机制的结构。
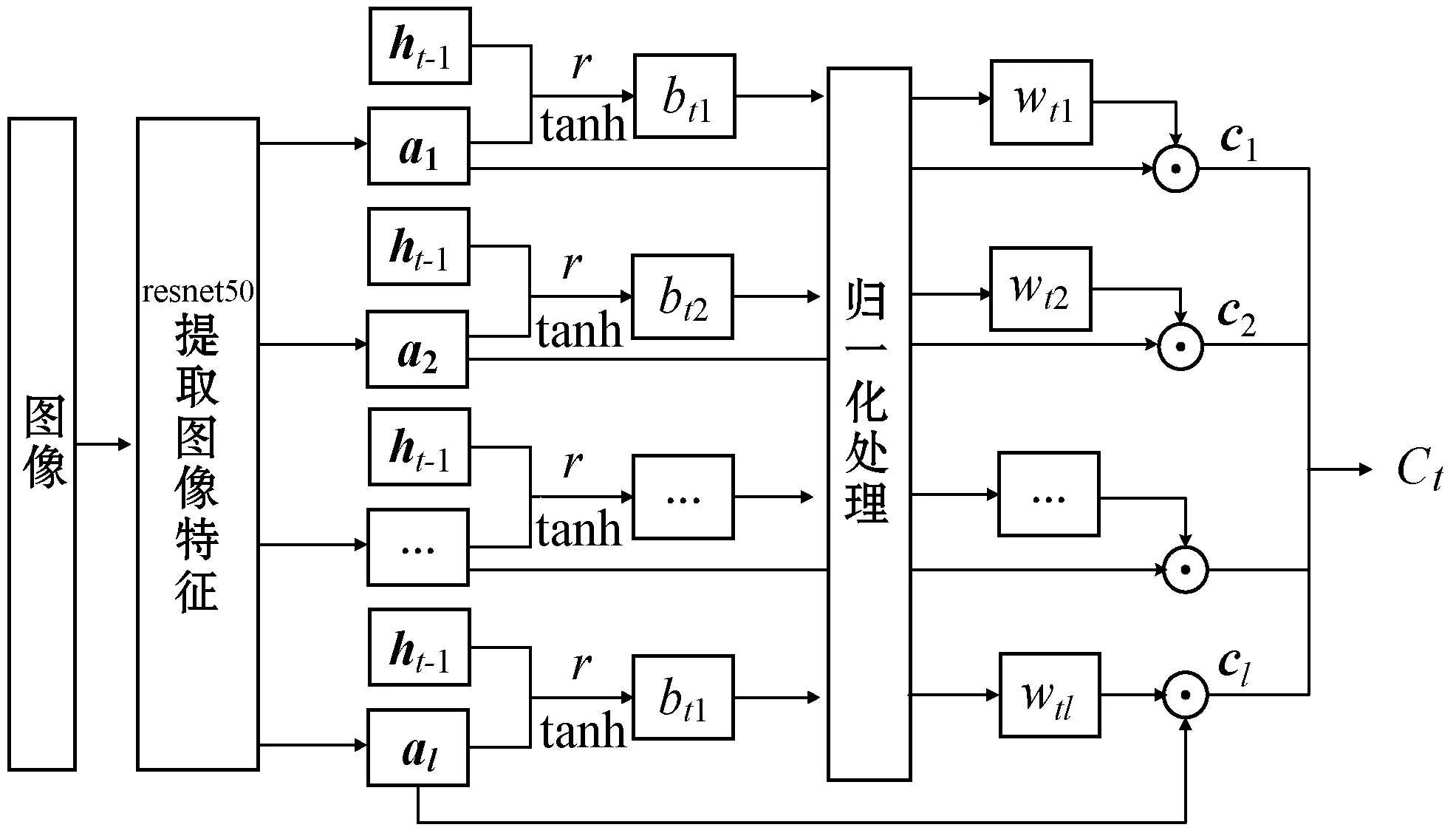
图4 融合注意力机制的结构
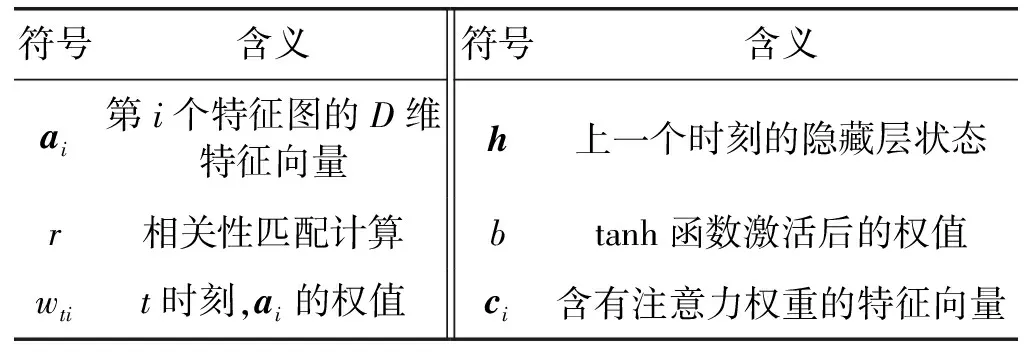
表1 符号说明
用集合A表示一幅图像共有l个特征图,其维度为D,将图像分为l个待关注区域,集合A见式(5)。
wt={at1,at2,…,atl},wti是t时刻ai的权值,在训练注意力机制时,模型的输入是图像与相应的句子描述,句子通过词嵌入(Word Embedding)方式向量化,保存在上一时刻的隐藏层状态中。
图4中C={c1,c2,…,cl},ci∈RD经以下形式融合而成,r表示相关性匹配计算操作,用来计算句子中每个单词与每个特征图ai的相关性,再通过tanh激活函数得到bti,用式(7)表示。
bti=fatt(ai,ht-1)
(7)
式中:fatt通常为一层神经网络,其映射关系如式(8)所示。
fatt=tanh(wsrht-1+warai)
(8)
式中:wsr表示单词S的权值;war表示图像区域的权值,为了突出重要特征权值,采用Softmax归一化处理,使其得到的结果映射在(0,1)之间。wti表达式如式(9)所示。
式中:bti中t表示t时刻,i表示ai对应的权重。带有注意力权值图像特征向量ct见式(10)。
2.2 解码阶段
在LSTM语言模型中,采用多个LSTM网络结构,使图像的底层的卷积特征连接底层的LSTM模块,图像的高层卷积特征连接高层的LSTM模块,不同模块之间赋予不同的注意力,充分地利用图像特征信息。
本文的语言模型结构如图5所示。
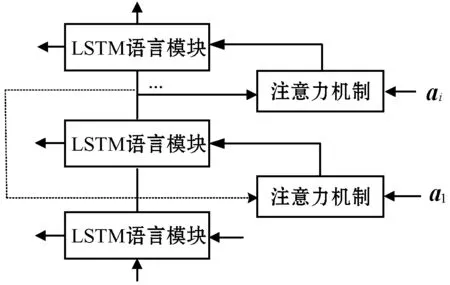
图5 语言模型结构
本文网络结构中使用多个LSTM基本单元,随着网络的不断加深,使得网络在训练过程中容易饱和。LSTM提取图像特征的注意力结构时,设计将多个LSTM基本单元使用残差连接,可以有效地避免网络无法收敛的情况。
LSTM作为语言生成模型的基本单元,模型基本结构如图6所示。
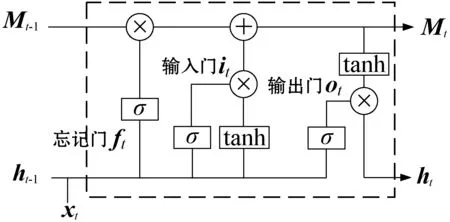
图6 LSTM单元存储结构
1个LSTM单元存储结构包括3个门和一个记忆细胞M。i、f和o分别代表输入门、遗忘门和输出门。it、ft和ot分别表示输入门、遗忘门和输出门向量。ht-1表示上一个LSTM存储单元的隐藏层的状态信息,ht表示当前单元的隐藏层输出信息。xt表示当前输入的文本向量信息,Mt-1表示上一个LSTM单元的存储信息,Mt表示当前时刻即t时刻的存储信息,σ为sigmoid(x)激活。it、ft和Mt分别用式(11)、式(12)和式(13)表示。
it=sigmoid(Wixt+Wiht-1+bi)
(11)
ft=sigmoid(Wfxt+Wfht-1+bf)
(12)
Mt=it×tanh(Wcxt+Wcht-1+bc)+ft×Mt-1
(13)
最后,通过输出门控制当前LSTM单元的输出信息,见式(14)、式(15)。
ot=sigmoid(Woxt+Woht-1+bo)
(14)
ht=ot×tanh(Mt)
(15)
3 实 验
3.1 数据集与实验环境
本文采用微软提供的MSCOCO数据集,该数据集包含图像识别、图像分割和图像描述生成等任务。图像描述生成数据集由图像数据和带标注的JSON文件两部分组成。JSON文件中包含图像的类别、物体的轮廓坐标、边界框坐标、image_id,对应于图像数据中的存储id和该图像内容的描述,其中每幅图像的描述均至少有5种。表2为实验的训练集和验证集图像,对于测试集,本文选用了交通场景的图像作为测试集,更好地验证该算法的准确性。

表2 数据集
文本实验采用的硬件平台是DELL深度学习工作站,显卡为NVIDIA GeForce GTX 1080 Ti,操作系统为Ubuntu 16.04.3,深度学习框架为TensorFlow 1.14。
3.2 主要参数设置
网络模型中,提取图像特征选取改进的ResNet50,batch为11 290,训练网络时batch_size大小为32,epoch=50次,初始学习率0.001,衰减率设置为0.9。句子S生成词向量,采用了词嵌入方法,训练过程中,为了防止在训练过程中出现过拟合现象,使用正则化dropout方法,其取值为0.5。
3.3 实验结果与分析
本次实验结果测评选取当前主流的双语评估指标(Bilingual Evaluation Understudy,BLEU)[21],该方法分析生成的候选句子和标准参考句子中n元组共同出现的概率,通过n-gram概率模型计算打分,取值范围在0至1之间,取值越高,表示算法在“B-n”概率模型上效果越好。
BLEU评估指标计算为:
式中:wn为n-gram的权重;BP为惩罚因子,当生成候选句子的长度小于标准参考句子的情况,其值用式(17)表示。
式中:c为生成候选句子的长度;r为标准参考句子的长度。pn见式(18)。
Countclip(t)=min{Count(t),MaxRefCount(t)},t=n-gram
式中:pn为n-gram的匹配精度;Count(n-gram)为某个n元词在生成的候选句子中出现的次数;MaxRefCount(n-gram)是该n元词在标准参考句子中出现的最大次数。
本文算法与Google NIC[10]、Hard-Attention[11]、Sem-ATT[15]、Adaptive[16]和文献[6]算法在BLEU上的对比结果如表3所示。
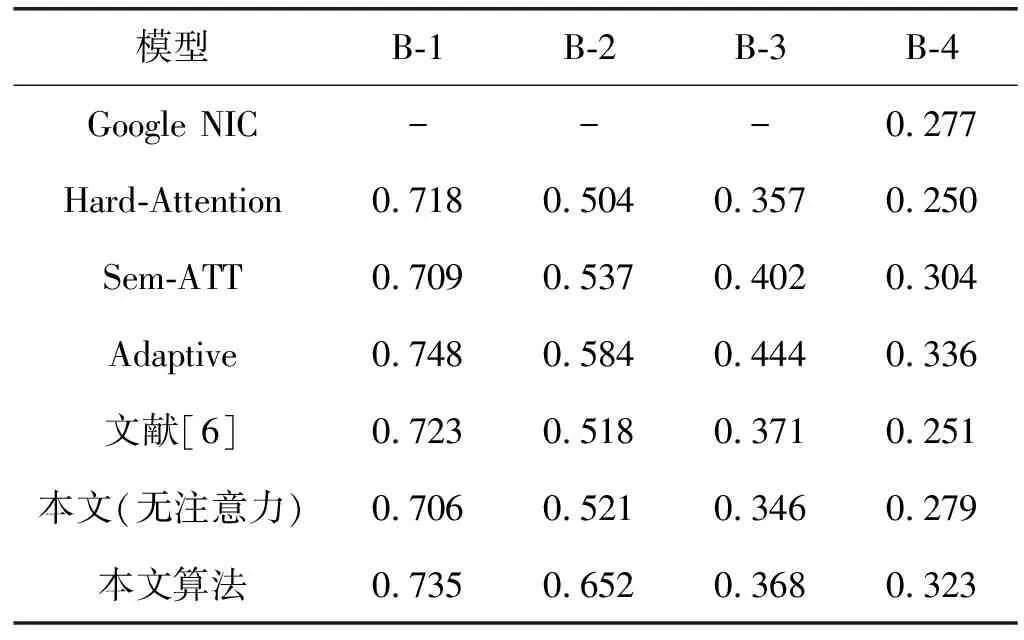
表3 MSCOCO数据库上实验结果比较(B-n代表BLEU分数,n=1,2,3,4)
表3表明,在MSCOCO数据集中,本文算法在BLEU-1至BLEU-4评估指标中取得了较高的分值,提升了图像描述的性能。具体算法分析如下:
(1) Google NIC算法利用卷积神经网络提取深层抽象的特征信息,再将图像的特征信息传送至长短期记忆网络模型中,得到图像的描述,在BLEU-4指标上,本文算法对比Google NIC算法提升了16.6%。
(2) Hard-Attention算法在图像特征提取过程中,获取浅层的图像特征信息,在浅层信息中增加了注意力权值,然后将这些信息输入至长短期记忆网络模型。在BLEU-1至BLEU-4指标上,本文算法对比Hard-Attention算法分别提升了2.4%、29.4%、3%和29.2%。
(3) Sem-ATT算法在单词属性方面增加了注意力机制处理同时与图像经过卷积神经网络提取t=0时刻的图像特征,同时传入长短期记忆网络模型中。在BLEU-1、BLEU-2、BLEU-4指标上,本文算法对比Sem-ATT算法分别提升了3.7%、21.4%和6.3%。
(4) Adaptive算法利用哨兵机制,生成图像单词时先计算单词是属于视觉词或者上下文语义词的概率,再由概率值分配权重得到总体特征,最后输入至长短期记忆网络模型生成图像描述。在BLEU-2指标上,本文算法对比Adaptive算法提升了11.6%。
(5) 文献[6]提出利用颜色注意力因子,对图像中颜色赋予不同的权值,使其对黑、白和灰有很好的辨别能力。在BLEU-1、BLEU-2、BLEU-4指标上,本文算法对比文献[6]算法分别提升了1.7%、25.9%和28.7%。
对交通场景图像做图像描述生成,本文提出的基于注意力机制的算法在BLEU指标上获得了较高的分值。融合注意力机制的网络使得图像在训练过程中更加关注图像中的重要信息,如图像中车、人的信息,使其对图像的描述更加精确。为了进一步测试本文算法的效果,测试图像选取了城市主干道路和十字路口图像,融合注意力机制算法与无融合注意力机制算法对比测试结果如图7所示,图7左列与右列分别表示融合注意力机制算法与未添加注意力机制算法的图像描述生成,结果表明:本文算法可以准确地用自然语言来描述交通场景图像。

(a) 停在建筑物前面的汽车 (b) 在道路上行驶的一辆卡车

(c) 有交通信号灯和指示牌的一条城市道 (d) 城市街道上有许多交通工具

(e) 许多汽车在道路上行驶 (f) 一辆汽车停在路边

(g) 一群人在道路上骑自行车 (h) 一个人在道路上骑自行车图7 本文算法与无注意力机制算法描述对比测试图像
4 结 语
交通场景的图像描述生成重点是关注图像中的行人和车辆,本文提出基于注意力机制的图像描述生成算法,编码阶段将一幅交通图像分为多个区域,不同的区域提取图像特征后融合注意力权重,对图像中的重点信息,如人和车赋予不同的权值,使得网络在预测句子单词过程中,可以时刻关注到图像的重点区域。解码阶段采用多个LSTM网络结构,底层的带有注意力的卷积特征与底层LSTM单元结构连接,高层的带有注意力的卷积特征与高层LSTM单元结构相连接,实现端到端的图像描述。
本文算法在BLEU指标上进行评分,对比其他几种注意力机制模型,评分结果表明,基于改进的残差网络和融合注意力机制图像描述生成的算法能很好地描述交通场景图像,包括交通场景中的重要信息,例如人和车。下一步研究工作重点是对交通场景中人和车之间相互关系进行准确描述,使得图像描述生成在无人驾驶、安全辅助驾驶等方面发挥出更大的价值。
