基于改进BERT模型的吸毒人员聊天文本挖掘
2022-12-03范馨月
张 立 范馨月
(贵州大学数学与统计学院 贵州 贵阳 550025)
0 引 言
受世界毒情形势影响,我国毒情形势严峻复杂,处于毒品问题蔓延期、毒品犯罪高发期和毒品治理攻坚期。我国现有吸毒人员300.6万名,且每年以10%的速度增长,合成毒品泛滥、新增吸毒人员上升、吸毒人员从事违法犯罪活动和肇事肇祸等问题日益突出。如何控制吸毒人数,从需求侧来对毒品问题进行源头治理,是缉毒工作不可回避的问题。目前用得最多的刑侦手段,是基于涉毒人员审问、线人提供的线索、通话记录和涉毒人员轨迹特征等对潜在涉毒人员进行跟踪和控制。
近年来,公安禁毒部门建立禁毒信息系统,集成了抓获的吸毒人员基本信息、犯罪信息,以及吸毒人员手机采集信息包括短信、微信、QQ等手机App即时聊天工具等文本信息。吸毒人员聊天文本数据包含海量的长文本和短文本,具有实时、涵盖信息量广等特点,为公安搜集犯罪涉毒证据提供了有效的背景支撑。但毒圈有特定的“毒语”,不管是贩毒人还是买毒人,都通过这个“语言体系”进行交流,以此来判断对方是否为“同道中人”,躲避公安机关的追捕,而且这些语言非常隐晦,极大增加了公安机关的查证和追捕难度,需要禁毒部门人工仔细浏览吸毒人员聊天文本并紧密联系上下文语境才能发现涉毒敏感信息。本文首次采用BERT模型对吸毒人员聊天文本进行挖掘,与贝叶斯预测模型的各评价指标值相比,BERT模型针对处理暗号多变的缉毒侦查文本而言效果显著。由于BERT模型有较好的上下文语境的学习能力,挖掘不在管理系统中的潜在涉毒人员,对禁毒部门的情报工作提供有力的数据支撑,可有效推广到禁毒警务工作中去,帮助相关部门快速精准地挖掘出海量复杂网络中涉毒人员并及时追踪调查。
1 文本分类方法
自然语言处理(NLP)中词语表示有非神经网络学领域[1-2]和神经网络领域[3-5]方法,通过预训练的词嵌入是现代NLP系统的重要方法。早期人们考虑1-of-N Encoding法,每个单词对应一个向量,但无法捕捉语义信息。Word class法将具有相同属性的词化为一类,却不能完全包含词之间所有的关联。Word Embedding法则利用词之间的距离长短表示关系强弱,词嵌入针对从头开始学习的方法改进[6]且可推广到了更粗的粒度:句子嵌入[7-8]或段落嵌入[9],之后的位置编码(Position Embedding)提供其捕捉顺序序列的能力。ELMo模型[10]对传统词嵌入研究进行了多维度概括,通过提取上下文敏感特征,很大程度上解决了传统LSTM模型单向学习的问题。此外,Salton团队[11]提出向量空间模型,将文本文件表示为标识符(比如索引)向量的代数模型,但是语义敏感度不佳。传统的分类算法利用特征工程和特征选择来从原始文本中提取特征,比如决策树、朴素贝叶斯和词频-逆文本频率(TF-IDF)等,更加注重分类器的模型自动学习挖掘和生成能力。基于深度卷积神经网络的文本语义特征学习方法,降低对文本数据预处理的要求,避免复杂的特征工程,改善了特征抽取过程中的误差累积问题。2018年由Google提出基于Transformer双向编码器表征的BERT模型[12],从语义层面挖掘文本中词之间潜在的语义关系,跨越句子表层句法结构的束缚,直接表征文本的寓意,在英文文本分类中取得了不错的效果。
2 潜在涉毒人员挖掘
实验数据来源于吸毒信息采集平台的吸毒人员聊天文本数据,包括微信、短信和QQ等即时聊天工具。每条文本记录均有唯一对应编号BJ,可即时跟踪对话者ID信息,时间跨度为2018年11月至2019年11月,共30万条原始数据。从原始数据中剔除广告信息、单个表情信息等无效数据后,随机抽取10 000条文本数据作为实验数据集,主要包含日常聊天、买卖毒品等信息。
做划分时,每条文本数据均只属于一个类别,不存在多次划分的情况。将划分后的数据集随机抽取70%的数据作为训练集,20%数据作为验证集,10%数据作为测试集。其中:训练集包含7 000条文本数据;验证集包含2 000条文本数据;测试集包含1 000条文本数据。
2.1 贝叶斯分类模型
对于汉语的自然语言处理是非常困难的,特别是在实际聊天文本中出现的方言尤为困难。吸毒信息采集平台的吸毒人员聊天文本数据,与规范的中文书面语不同,具有方言、同音和谐音等口语问题,采用传统的特征提取方法进行文本分类存在困难[13-14]。比如:
(1) 你今天克不克,整点嘎嘎和子子来吸。
(2) 好饿呀,我们克吃点嘎嘎。
利用实验省份吸毒信息采集平台的吸毒人员聊天文本数据,通过删除空白文本数据、表情数据和广告文本数据,得到有效无标签数据10 000条。在10 000条文本数据中,人工标记吸毒人员ID与其他人的聊天文本涉毒标签记为1,不涉及毒品交易文本标签记为0。
利用贝叶斯分类模型预训练标签文本数据,针对确定特征属性fj所获取的训练样本,先对不同类别计算概率值p(classi),再对每个属性特征fj计算所有划分情况的条件概率p(fj|classi),得每个判别类别概率为:
(1)
利用传统的词向量模型,采用TF-IDF及贝叶斯分类可以达到一定的效果,但对于样例(1)(2)中同样的词寓意却无法准确识别,“嘎嘎”在样例(1)中是某毒品的暗语词,在样例(2)中是当地方言“肉”的意思,即不同语境下相同的字或词有多种涵义。
2.2 BERT模型
一般经典的语言模型是按照从左到右的顺序计算下一个词出现的概率,如式(2)所示。而BERT是基于Transformer的双向编码器表征,即BERT模型的基础是Transformer[15],旨在联合调节所有层中的上下文来预训练深度双向表示,给出额外的输出层后对模型进行微调,就能为多个任务(回答问题和情感分析等)服务。
针对涉毒人员聊天文本此类特殊文本数据而言,BERT模型的双向关注为特殊文本增添了语境的学习能力,即在处理同一个词语时,基于这个词同时关注该词前后的信息,获取上下文的语境,如图1所示。

图1 BERT模型结构
将打好标签的缉毒文本数据的词embedding、位置embedding和类型embedding三个embedding的拼接作为BERT模型的输入,在已预训练好的BERT中文模型上进行微调,使其带入具体涉毒语境训练上下文关系,理解敏感词一词多义情况。BERT模型流程如图2所示。
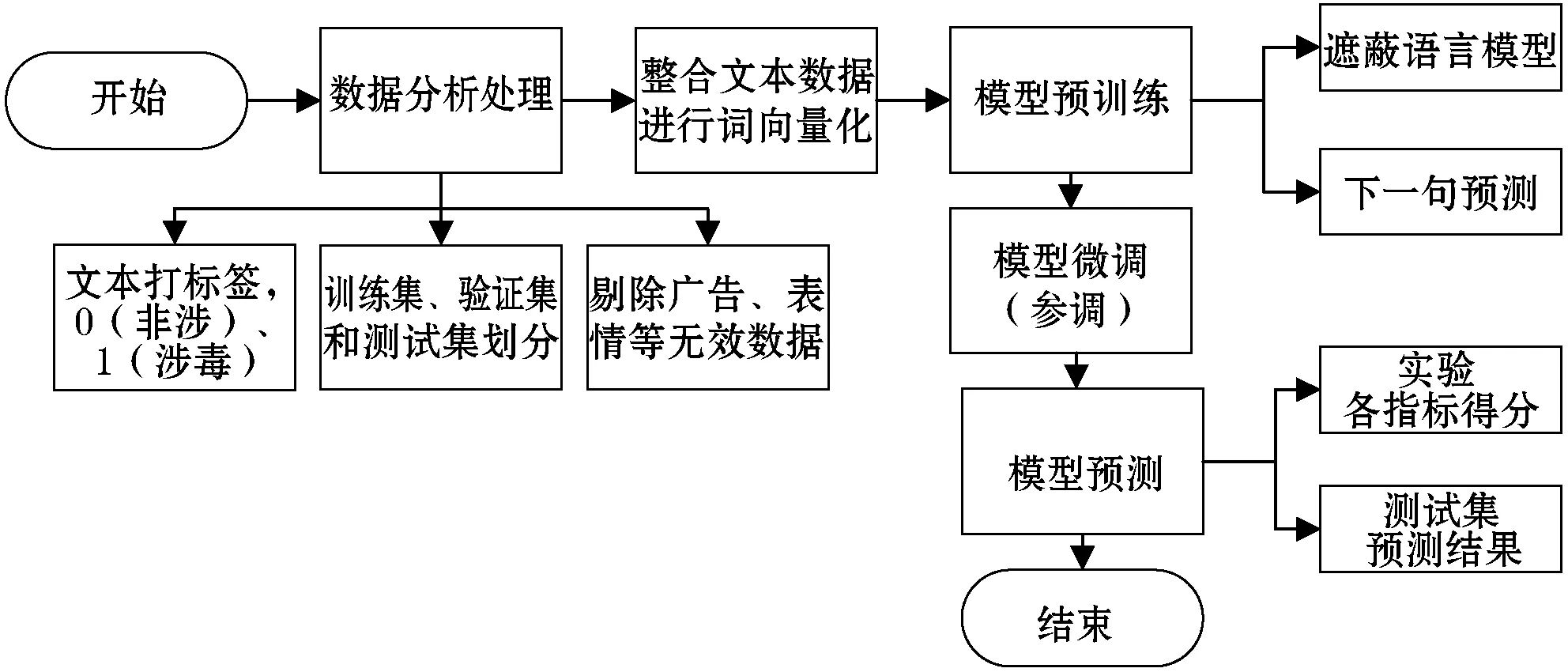
图2 BERT模型流程
BERT模型来自Transformers模型的Encoder部分,在Transformer的Encoder中,数据首先进入“self-attention”模块(如图3所示),为每条输入文本的第i(i=1,2,…,N-1,N)个字学习其权重,得到特征向量Attention(Qi,K,V):

Step1将输入的字转换成嵌入向量(word embedding)。
Step2借助嵌入向量(word embedding)乘上对应的权值矩阵得到Qi、Ki、Vi三个向量。
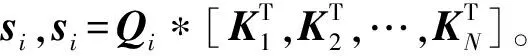

Step5为确保将每一个元素的范围压缩至(0,1)之间,对si做Softmax激活函数,点乘Vi,得到加权后每个输入向量的分数Vi。
Step6将所有的Vi相加后最终输出第i个字的特征向量Zi。
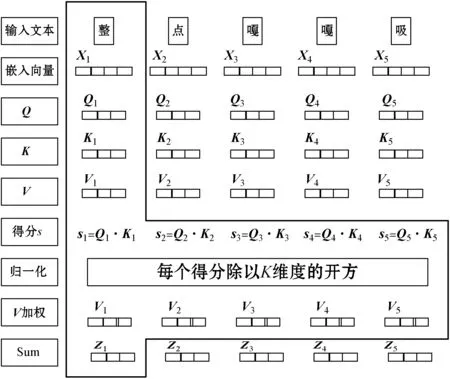
图3 “self-attention”模块结构
得到字的特征向量后,将Zi作为Feed Forward Neural Network模块的输入向量,使用线性整流激活函数进行输出:
式中:W为学习的参数向量;b为偏差向量。
在实际应用过程中,为了模型去关注多个不同方面的信息,Transformer运用了多个“self-attention”,等价于h个不同的self-attention的集成:
MultiHead(Q,K,V)=[head1,head2,…,headh]×W0
(5)
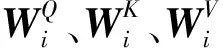
由于Transformers模型的网络结构没有RNN或者LSTM,不具有捕捉顺序序列的能力,为了解决这个问题,在编码词向量时引入位置向量(Position Embedding):
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(7)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(8)
式中:dmodel为位置向量的长度;i表示字的维度;pos表示字的位置,字在偶数位置时,采用正弦函数进行计算,字在奇数位置时,采用余弦函数进行计算,而且根据正余弦加减定理,在k+p位置向量可以表示为位置k的特征向量的线性变化,使模型能学习到词之间相对位置关系。
为了训练模型深度双向学习上下文语境的能力,需同时进行两种训练:遮蔽语言模型(masked language model)和下一句预测(Next Sentence Prediction)。现列举四条较有代表性的文本细致描述:
(1) 好多警察啊,我不敢再等你哦,60一颗你看要不要,赏到东西了你不会觉得不值。
(2) 感冒了,注意多喝水,先吃颗感冒药。
(3) 昨晚我和他谈了下,他说有人说我有红酒,我说那个,他说是你说的,那天你来我拿给你吃的,所以昨天他才叫你来找我要几个红酒。
(4) 来吃饭,我有个朋友带了瓶红酒。
主要错误分类存在两种情况,一种是对“颗”字非常不敏感,直接将它判定为涉毒文本,另一种是当文本含有“红酒”就判断为涉毒文本。两种较为突出的分类错误均是未对语境进行学习,现利用BERT训练深度双向表示的遮蔽语言模型来做这件事情。
有句子“整点嘎嘎和子子来吸”(如图1所示),现在有15%的概率随机屏蔽掉“嘎”这个字(BERT对中文是按字划分的),其中:有80%的概率将“嘎”用[MASK]替换;10%的概率随机用“天”替换;10%的概率为原意“嘎”。将“嘎”字对应的embedding输入到一个多分类模型中,去预测被盖住的单词。迫使模型在编码的时候不过于依赖当前的词,而是考虑该词上下文的情况。假设现在被覆盖的字被“天”替换,在编码“天”字时根据上文下文的字,应该把“天”编码成“嘎”的语义而不是“天”的语义。
2.3 敏感词预训练的融入
对于缉毒类别的判断学习,BERT模型能双向学习上下文语境关系,可较好处理一词多义的情况。但针对毒圈特定的“毒语”(例如“整点嘎嘎和子子来吸”),BERT模型并不能自己理解“嘎嘎”“子子”是毒品敏感词,不知道其中具体的含义,考虑在文字编码中添加敏感词的影响,重新学习输出任务具体场景中字的向量表示,可通过增加任务实现:根据自建敏感词库,提取输入文本中的敏感词,将敏感词学习融入BERT预训练模型,建立BERT-sen预训练模型。


图4 BERT-sen模型结构

GELU(x)=xP(X≤x)=xΦ(x)
(11)
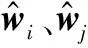
图4中,以“整点嘎嘎和子子来吸”为例,“整点嘎嘎和子子来吸”作为输入序列,“整”“嘎”“子”“吸”作为敏感字,将输入序列和敏感字分别放入“Multi-head Self-Attention”层学习输出特征向量(实线输出)和敏感向量(虚线输出);随后特征向量和敏感向量作为“敏感信息融合层”的输入,利用字的位置编码关系,将含有敏感字的特征向量融入敏感向量信息后输出输入序列的融合向量;为保证语境学习的时效性,将融合向量进入“Multi-head Self-Attention”层继续学习上下文结构关系,得到输入序列最终向量表示。
3 模型评价
使用Python3.7作为实验工具,将缉毒文本数据的7 000条训练集、2 000条验证集、1 000条测试集放入贝叶斯、BERT和BERT-sen三类模型中进行检验对比,如表1所示。在类别1(涉毒)测试文本中,贝叶斯模型的准确率为0.52,BERT模型的准确率为0.81(提高了0.29),BERT模型在学习类别1(涉毒)文本数据时,比贝叶斯模型更加敏感有效;而通过添加敏感词预训练学习后的BERT-sen模型,学习判断类别1(涉毒)文本数据的准确率较BERT模型有效提高了0.01。BERT模型在缉毒文本分类任务上总体优于贝叶斯模型,且添加敏感词预训练后的模型通过更多专业词汇学习后加深对缉毒数据的认识,有效提高了学习判别能力。
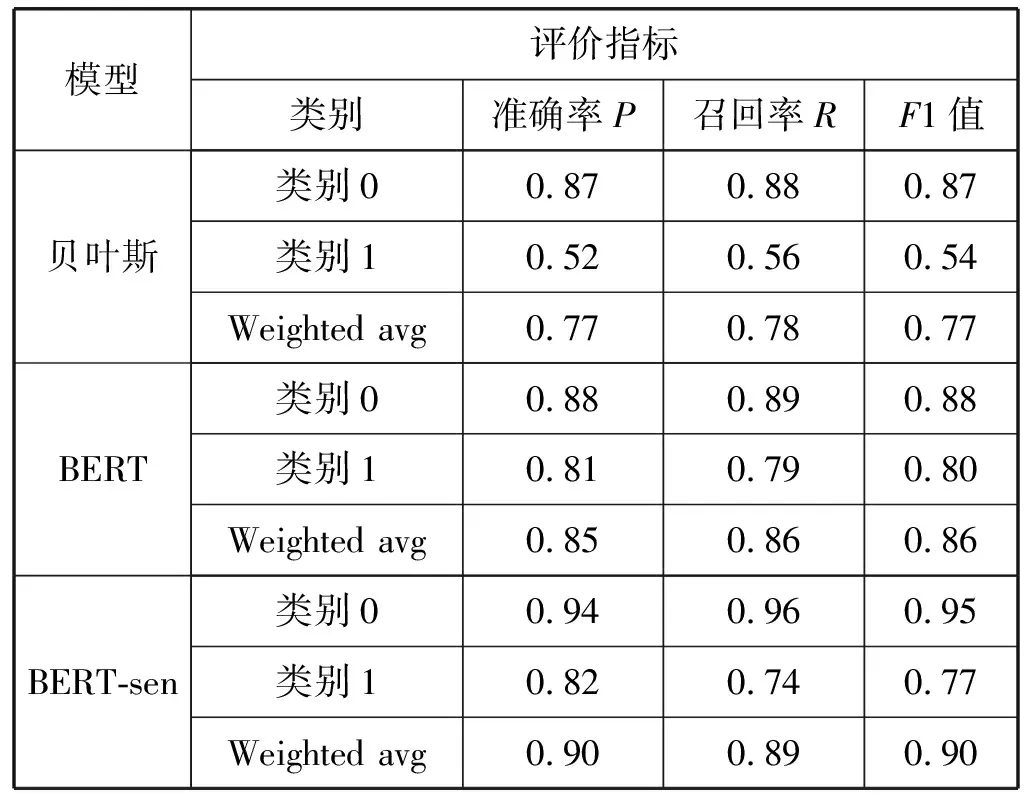
表1 缉毒文本数据实验结果
与BERT训练深度双向表示的遮蔽语言模型有关,当模型有机会学习到上下文语境时,部分敏感词对模型分类的影响将会增加,现从涉毒文本数据分类错误中提取部分内容进行分析。如表2所示,列举四个样例,样例4内容中含有“冰毒”,但是贝叶斯模型未能成功检测到它;样例1-样例3内容中虽然未含有毒品字样,但结合整段文本分析,可以清晰地认定其为涉毒文本。

表2 涉毒文本部分错误分类显示

续表2
鉴于缉毒文本数据的特殊性,当把本属于涉毒文本的数据划分为非涉毒数据时,意味着会遗漏重要的犯罪线索,不能及时将犯罪人员绳之以法甚至使其继续逍遥法外,此类错误成本较高,对社会影响极大。考虑选取可以学习句子上下文语境和深层次语义特征的BERT模型,并有效增加敏感词预训练的融合,能较好地避免此类错误,针对表2中同类型的文本均较好完成分类工作。
4 结 语
由于吸毒人员聊天文本数据的敏感性和分类工作要求的精准性,需寻求能学习上下文语境的分类模型,作为缉毒文本分类工作的有力工具。本文建立了增加敏感词预训练的BERT-sen分类模型,实验数据表明,BERT-sen模型能更精准地对潜在涉毒人员进行挖掘,其主要原因在于其能更好地学习敏感词及其上下文语境。因此,针对缉毒侦查文本数据寻找证据的这项工作,BERT-sen模型可以作为一个有力的侦查工具,为相关禁毒部门管控和打击涉毒犯罪嫌疑人提供了强有力的数据支撑。本文的研究基于禁毒部门的实际需求,可以有针对性地推广到禁毒警务工作中去,高效地挖掘潜在涉毒人员,可以在本地吸毒人员管控工作中提供决策辅助。
然而模型深受训练数据集的影响,数据集可以直接影响训练文本中的具体语境情况,因此在挑选数据工作的花费较昂贵。在今后的工作中,随着大数据产业的不断发展,也将继续优化文本数据分类模型在缉毒文本分析中的应用,力求更加快速、精准地锁定犯罪者,为后续工作实施提供有效证据。
