基于SNRESI信道选择的改进IMCRA语音增强算法
2022-12-03卢勇舒涛
卢 勇 舒 涛
(中国民用航空飞行学院空管中心 四川 广汉 618307)
0 引 言
随着科学技术的发展,语音增强算法在众多领域都有广泛应用。移动电话在进行语音通话时,发送端往往带有背景噪声,这些噪声会严重影响通话质量,为了改善语音质量,需要在声码器对语音进行压缩之前用语音增强算法作预处理[1]。在民航系统中,地空通信显得尤为重要,但是在通信时,飞机发动机周期性的噪声和机械振动引起的噪声会对飞行员的通话形成严重干扰,这时需要在带噪语音被放大之前用语音增强算法对其进行预处理,以改善语音质量及可懂度[2]。语音增强算法的目的就是去除含噪语音中的噪声,提高语音的质量和可懂度。
传统的语音增强算法有维纳滤波法、谱减法、基于统计模型的方法和子空间算法等一系列算法,但是这些算法只适用于平稳的噪声环境中,对于非平稳噪声信号不能进行有效抑制,而且在去噪过程中还会引入音乐噪声导致语音失真[3]。近些年来,基于深度学习的语音处理技术逐渐兴起,它不需要假设语音与噪声相互独立,而且可以有效抑制非平稳噪声[4],在改善语音质量方面取得了不错效果,但并没有提高语音的可懂度。语音增强算法在降噪过程中,对噪声谱的估计非常重要,如果估计太小,可能还会有残留噪声;如果估计太大,可能会去除有效成分,导致语音失真,造成语音可懂度的损伤。估计噪声最简单的方法是话音活动检测(Voice Activity Detection,VAD)算法,它是利用从输入信号提取的一些特征与无语音段得到的某个阈值进行比较来估计和更新噪声功率,但是在非平稳的信号中难以达到理想结果[5]。最小值统计(Minimum Statistics,MS)噪声估计算法是在一个有限长窗内对带噪语音功率谱的最小值进行跟踪,并将最小值作为噪声的估计值[6]。最小值控制的递归平均(Minima-Controlled Recursive Averaging,MCRA)算法是利用噪声谱估计的最小值来控制语音存在的条件概率和噪声估计中使用的时间平滑因子[7]。改进的最小值控制的递归平均(Improved Minima-Controlled Recursive Averaging,IMCRA)算法在计算语音存在的概率时是通过语音不存在的先验估计概率得到的[8]。此外,很多学者在这些算法的基础之上进行了改进,如在IMCRA算法中加入了最优平滑因子,用连续最小值跟踪取代在固定窗内的最小值搜索,这些改进在改善语音质量方面取得了一定效果,但是并没有提高语音的可懂度,反而在语音去噪时引入了失真,进一步损伤了语音的可懂度,因此需要设计一种算法,在改善语音质量的同时又能提高语音的可懂度。
为了解决以上问题,本文提出基于SNRESI信道选择的改进IMCRA语音增强算法,该算法首先利用基于统计模型的方法结合IMCRA估计的噪声功率谱对带噪语音进行降噪,然后再根据SNRESI准则保留衰减失真的有用信号,进而提高整个频带的信噪比和可懂度。
1 SNRESI信道选择标准
大部分语音增强算法无法准确估计背景噪声频谱,并且在降噪过程中引入了失真导致无法提高语音的可懂度。在某些情况下,引入的语音失真可能比背景噪声更具破坏性[9]。为了分析由降噪算法引入的失真对可懂度的影响,需要建立失真与可懂度之间的关系,频率加权分段信噪比(fwSNRseg)与噪声抑制语音的可懂度高度相关[10],具体公式如下:
式中:W(k,t)表示第k个频带的权重值;K表示频带数量;M表示信号的总帧数。

将式(2)中分子分母同除以X2(k,t),得到:
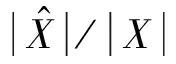
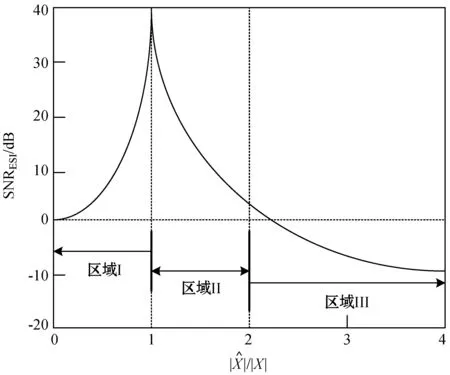
图1 SNRESI度量图
区域I和区域II的并集(称为区域I+II),有以下约束:


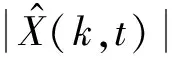
2 算法简介
2.1 IMCRA算法
假定带噪语音信号y(n)由纯净信号x(n)和噪声信号d(n)组成,即:
y(n)=x(n)+d(n)
(6)
两边进行分帧加窗和傅里叶变换得到:
Y(λ,k)=X(λ,k)+D(λ,k)
(7)
式中:λ表示帧数;k表示频点。
IMCRA算法是基于时间递归平均来对噪声谱进行估计,噪声估计形式如下:

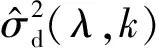
在IMCRA算法中,平滑因子αd(λ,k)由语音存在概率决定,语音存在概率需要通过两次迭代计算得到。第一次迭代主要是对各频点进行粗略的话音活动检测以此来判决语音活性,第二次迭代是通过时频平滑去除相对较强的语音分量,得出更准确的语音存在概率。
第一次迭代:
首先对带噪语音的功率谱做平滑估计,估计方式如下:
S(λ,k)=αsS(λ-1,k)+(1-αs)Sf(λ,k)
(9)
式中:αs为平滑因子。
式中:w(i)为窗函数,窗长为2Lw+1。当前帧的最小值Smin(λ,k)采用在D帧的固定窗长内进行最小值统计得到。
通过搜索得到Smin(λ,k)后,然后判决语音的存在性,判决规则如下:

第二次迭代:
这次迭代主要针对已经被判断为噪声的频率分量,平滑过程如下:
(12)
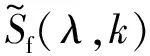

(14)
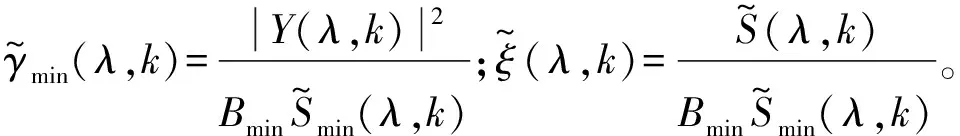
计算出不存在概率q(λ,k)后,可以通过以下计算得出语音存在概率p(λ,k):
式中:v(λ,k)=γk(λ)ξk(λ)/(1+ξk(λ)),γk(λ)和ξk(λ)分别为频点k的后验和先验SNR。计算出p(λ,k)之后,就可以更新本帧的噪声功率谱估计值。此外,为了最小化语音失真,引入了一个偏差补偿因子:
式中:β为常数1.47。
2.2 改进IMCRA算法
在IMCRA算法中,计算平滑功率密度谱的最小值Smin(λ,k)都是在固定窗内进行搜索,这种方法容易延迟,不能快速响应噪声谱的变换,因此在改进的IMCRA算法中使用连续最小值跟踪算法来计算Smin(λ,k)[12],定义如下:
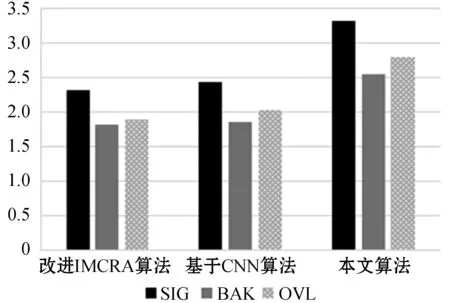
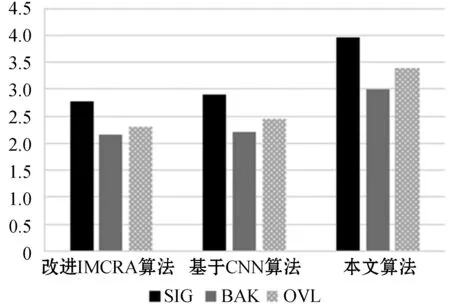
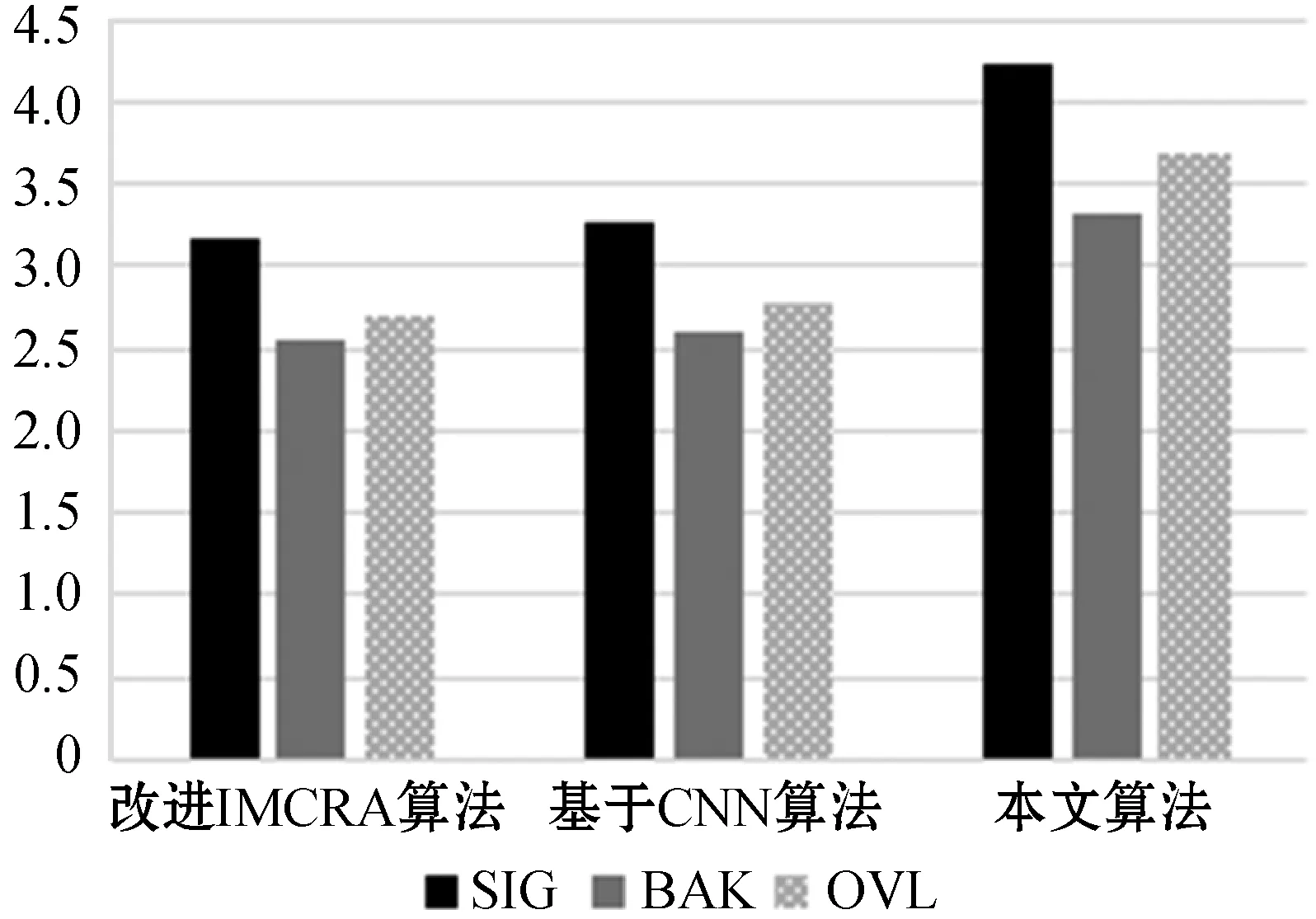
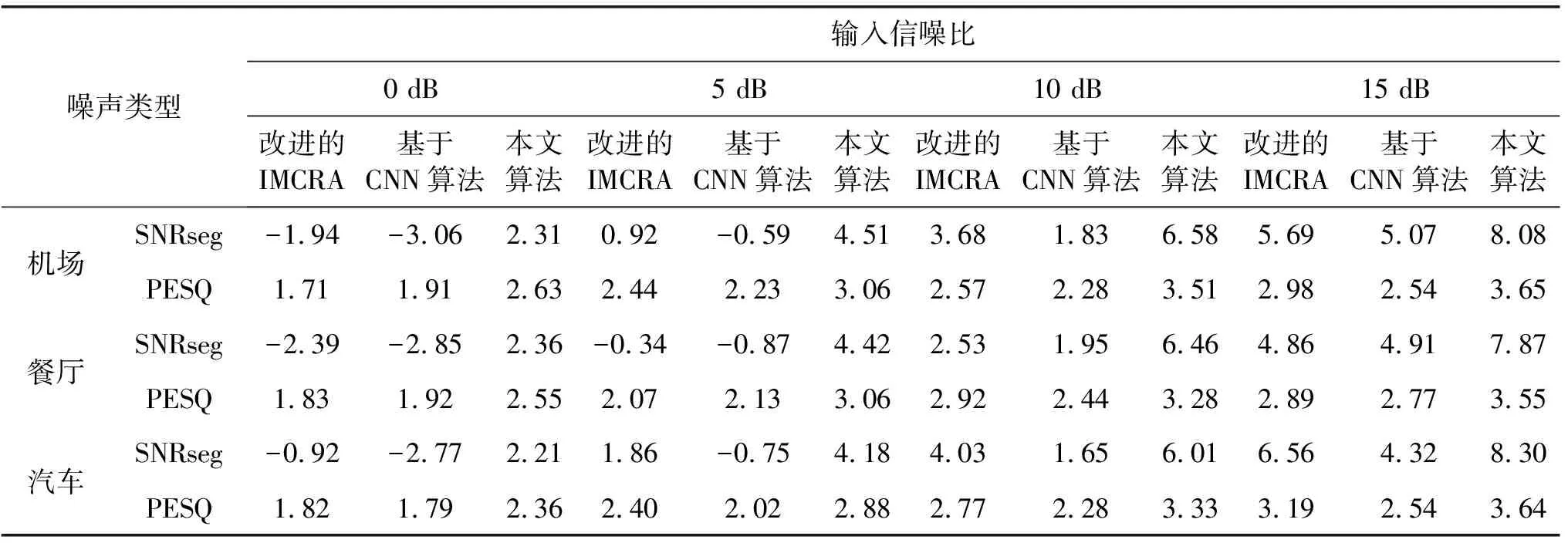
ifSmin(λ-1,k) βS(λ-1,k)) (17) else Smin(λ,k)=S(λ,k) end 式中:β=0.96;γ=0.998。 式中:β=1.47;θ为经验函数。 本文首先利用基于统计模型的方法结合估计的噪声功率谱对带噪语音进行降噪,然后再根据SNRESI准则,保留衰减失真的有用信道,消除放大失真的不利信道,最后对通过有用信道的信号进行合成得到增强的语音信号。整体算法的一般步骤如下: (1) 频谱分解:带噪语音信号通过短时帧加窗和傅里叶变换得到Y(k,t),Y(k,t)表示第t帧第k个频带的带噪信号频谱。 (3) 信道选择:通过SNRESI准则,只允许SNRESI>1的信道通过,消除放大失真的信道,得到通过选定信道的语音增强信号频谱XC(k,t)。 (4) 信号合成:对通过选定信道的信号频谱XC(k,t)进行傅里叶逆变换重构信号,最终得到增强语音信号。 整体算法的流程如图2所示。 图2 基于SNRESI信道选择的改进IMCRA语音增强算法流程 语音质量评估标准有主观音质测度和客观音质测度两种方法。主观测度是比较原始纯净语音和处理后增强语音的音质,并按照预设好的等级标准对增强后语音的音质进行评分;客观测度是用数值对原始纯净语音和处理后增强语音的音质进行量化对比[13]。本文客观测度采用分段信噪比(SNRseg)和感知语音质量评估(PESQ)标准,主观测度采用ITU-T P.835[14]评价标准。ITU-T P.835评价增强语音信号有如下方面: (1) 仅语音信号,使用五分制信号失真(SIG)量表,1代表严重失真,2代表明显失真,3代表有些失真,4代表几乎不失真,5代表无失真。 (2) 仅背景噪声,使用五分制背景失真(BAK)量表,1代表十分明显且十分烦扰,2代表明显且烦扰,3代表可觉察但不烦扰,4代表有些觉察,5代表不可觉察。 (3) 整体效果,采用平均意见得分(OVL)量表,1代表很差,2代表差,3代表一般,4代表好,5代表非常好。 本文采用的实验数据来自NOIZEUS噪声语音库[15],该语音库中包含30个由不同人员发音的纯净语句,噪声信号包括来自人群、机场、餐厅、汽车、街道等不同地方的录音。仿真实验时,噪声分别按照0 dB、5 dB、10 dB、15 dB的不同信噪比添加到纯净语音中,然后再利用语音增强算法进行去噪。为了验证在非平稳噪声环境中的去噪效果,本文随机选择了三段纯净语音sp01.wav、sp07.wav和sp10.wav,分别叠加人群、机场、餐厅、汽车、街道等不同类型的噪声,然后再利用改进的IMCRA算法、基于卷积神经网络(CNN)的语音增强算法和本文算法对其进行去噪处理。通过主客观测度来评价三种算法的去噪效果。去噪处理时,语音采样频率为8 kHz,短时帧为320个样本点,使用汉明窗加窗处理,FFT的分析点数为640。 图3表示纯净语音sp01.wav叠加0 dB、5 dB、10 dB、15 dB四种不同信噪比的人群背景噪声,分别采用改进的IMCRA算法、基于CNN的语音增强算法和本文算法得到的SIG、BAK、OVL评分等级。可以看出,对于四种不同信噪比的人群背景噪声,三种算法都有一定的去噪效果,但采用本文算法后得到的SIG、BAK、OVL评分最高,其次是基于CNN的语音增强算法,最后是改进的IMCRA算法,说明本文算法在降噪和引入失真方面效果更好,进一步提高了语音的质量和可懂度。 (a) 0 dB人群噪声 (b) 5 dB人群噪声 (c) 10 dB人群噪声 (d) 15 dB人群噪声图3 不同信噪比的人群背景噪声下采用三种算法得到的SIG、BAK、OVL评分 为了验证本文算法在各种非平稳环境下的去噪效果,进一步选取纯净语音sp07.wav,分别叠加0 dB、5 dB、10 dB、15 dB四种不同信噪比的机场、餐厅、汽车三种背景噪声,分别采用改进的IMCRA算法、基于CNN的语音增强算法和本文算法进行语音去噪处理,去噪后得到的SNRseg和PESQ得分情况如表1所示。 表1 不同信噪比输入下的不同类型噪声语音增强后的SNRseg和PESQ得分情况 可以看出,在不同信噪比的不同背景噪声下,针对同一类型的噪声输入,相比其他两种算法,本文算法在SNRseg和PESQ得分方面均最高,说明本文算法在语音增强方面更好,进一步提高了语音的质量和可懂度。另外,在低信噪比的机场、餐厅背景噪声下,基于CNN的语音增强算法在PESQ方面要好于改进的IMCRA算法,但是在SNRseg方面要低于改进的IMCRA算法;在高信噪比的机场、餐厅背景噪声下和在汽车背景噪声下,改进的IMCRA算法要好于基于CNN的语音增强算法。以上说明,改进的IMCRA算法和基于CNN的算法在语音增强方面各有利弊,本文算法效果最好。 图4表示纯净语音sp10.wav受到输入信噪比为0 dB的非平稳街道噪声干扰时,分别使用改进的IMCRA算法、基于CNN的算法和本文算法后得到的增强语音时域波形图。可以看出,纯净语音受到噪声干扰后,出现了许多毛刺,通过三种语音增强算法后,波形都有明显改善,但是采用本文算法得到的波形和纯净语音波形最接近,说明本文算法的去噪效果最好。相比本文算法,改进的IMCRA算法和基于CNN的算法在去噪过程中引入了失真,去除了部分有用信息,而且在末尾阶段还残留了部分噪声,使语音质量和可懂度受到影响。通过增强语音时域波形图对比,进一步说明了本文算法对语音的质量和可懂度均有所提高。 (a) 纯净语音波形 (b) 带噪语音波形 (c) 改进的IMCRA算法语音波形 (d) 基于CNN算法语音波形 (e) 本文算法语音波形图4 纯净语音、带噪语音和增强语音时域波形图 传统的语音增强算法主要对语音质量进行改善,但是在改善质量的同时引入了失真,使语音可懂度受到影响,为了能提高语音的质量和可懂度,本文提出基于SNRESI信道选择的改进IMCRA语音增强算法。该算法首先利用基于统计模型的方法结合估计的噪声功率谱对带噪语音进行降噪,然后再根据SNRESI准则保留衰减失真的有用信道,最终对通过有用信道的信号进行合成得到增强的语音信号。本文对比分析了在不同信噪比、不同噪声环境下采用不同语音增强算法后得到的SIG、BAK、OVL评分和分段信噪比SNRseg、PESQ得分,结果表明本文算法在语音增强方面有更好的效果,进一步提高了语音的质量和可懂度。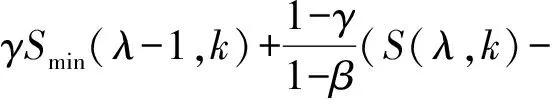

2.3 基于SNRESI信道选择的改进IMCRA语音增强算法

3 实 验
3.1 语音质量评估标准
3.2 实验结果与分析






4 结 语
