基于SDN的数据中心流量负载均衡
2022-12-03杨耀忠刘宝军段鸿杰
杨耀忠 刘宝军 段鸿杰 罗 阳 程 鹏
1(胜利油田分公司信息化管理中心 山东 东营 257000)2(中国石油大学(华东)计算机科学与技术学院 山东 青岛 266580)
0 引 言
随着分布式业务的兴起,比如VM迁移、MapReduce、数据备份等,数据中心“东西向”流量大幅增加,数据中心网络(DCN)流量调度压力越来越大。为了避免拥塞,DCN通常在任意两台服务器之间设计有多条路径来提高带宽和容错[1],例如Fat-Tree架构。但多条路径之间的调度问题是一个很大的挑战,不合适的调度会导致拥塞和数据包丢失,随后的重传会进一步加重拥塞,因此多路径的合理调度是解决拥塞的关键。
传统网络具有纯分布式结构,转发和控制高度耦合在每个网络设备中,导致针对性高且复杂的调度模式难以在传统网络中部署,数据中心也很难根据网络状态动态调整策略。
软件定义网络(SDN)是一个新型的网络模型,其核心思想是数控分离,数据平面只负责高速转发,其控制功能全部集成在控制平面,控制器是控制平面的核心,管控整个网络,可以针对复杂场景制定复杂的流量调度模型,为数据中心流量调度问题提供了新思路。
1 相关工作
数据中心网络中的流量调度一直是一个活跃的研究领域,这个研究领域已经有很多成果。
等价多路径路由(ECMP)是一个基于流的负载均衡策略,通过计算五元组的哈希值或轮询调度这些路径转发数据,达到增加带宽的目的。ECMP不区分大象流和老鼠流,因此无法为大象流均衡地分配资源。Al-Fares等[2]提出了针对Fat-Tree拓扑的集中式流调度程序。一旦流量增长到阈值以上,边缘交换机将向控制器发送包含大象流量信息的通知,控制器负责将路径重新分配给大流量。Hedera[3]是另一种典型的Fat-Tree拓扑下集中式流量调度系统,Hedera在边缘交换机处检测到大象流量,对大象流使用模拟退火算法进行调度,对老鼠流使用ECMP进行调度。PIAS[4]是一种DCN流调度机制,通过最短作业优先原则和使用优先级队列来最小化流完成时间。这些方案忽略了存储器占用和数据速率,它们是拥塞的重要信号和流量的特征。同时,其中一些工作着眼于当前调度流程的有效性,这可能导致流量不平衡。
流调度的另一个方向是集中在小粒度数据的传输上。VL2[5]利用VLB和ECMP两种技术来提供无热点的性能。VL2使用VLB实现负载均衡,ECMP实现多路径传输。TinyFlow[6]是一种新颖的大象流调度方法,通过将大象流分割成老鼠流来改变数据中心网络的流量特性,使其适合ECMP,并利用ECMP实现负载平衡。上述解决方案可能会导致重新排序问题,尽管有些提案指出通过某些方法进行重新排序,但会导致大量开销。
考虑到以上解决方案的局限性,我们使用稳定匹配理论[7]为数据中心中大象流调度问题建模。然后本文提出一种基于稳定匹配的大象流调度算法TPLM,它可以在数据中心中提高设备资源利用率和网络吞吐量。
2 系统分析与建模
2.1 系统总览
如图1所示,K-pod Fat-Tree网络分为三个层次:自下而上分别为边缘层(edge)、汇聚层(aggregate)和核心层(core),拓扑含有(k/2)2个核心交换机,其中汇聚层交换机与边缘层交换机构成一个pod,每个pod有k个汇聚层交换机。在此网络拓扑中,定义三种流量调度模式:pod间流调度、pod内流调度和机柜流量调度。pod间流调度指不同pod间任何主机对之间的通信,由拓扑结构可知,pod间流必须经过其中核心交换机,所以当pod间流到达时,只需要为其选择合适的核心交换机,就能确定此流量的最短路径[8]。机柜流量调度指连接在同一交换机上的任意两台主机间的通信,因此只有一条传输路径。pod内流调度指同一pod内任意两个不连接在同一交换机上的主机间的通信,同pod间流调度类似,只需为流分配汇聚交换机。例如,主机h1到h2的路径只有h1-e1-h2;h1到h3的路径有h1-e1-g1-e2-h3和h1-e1-g2-e2-h3;h1到h5的路径有四条,分别是h1-e1-g1-c1-g3-e3-h5,h1-e1-g1-c3-g3-e3-h5,h1-e1-g2-c2-g4-e3-h5,h1-e1-g2-c4-g4-e3-h5。
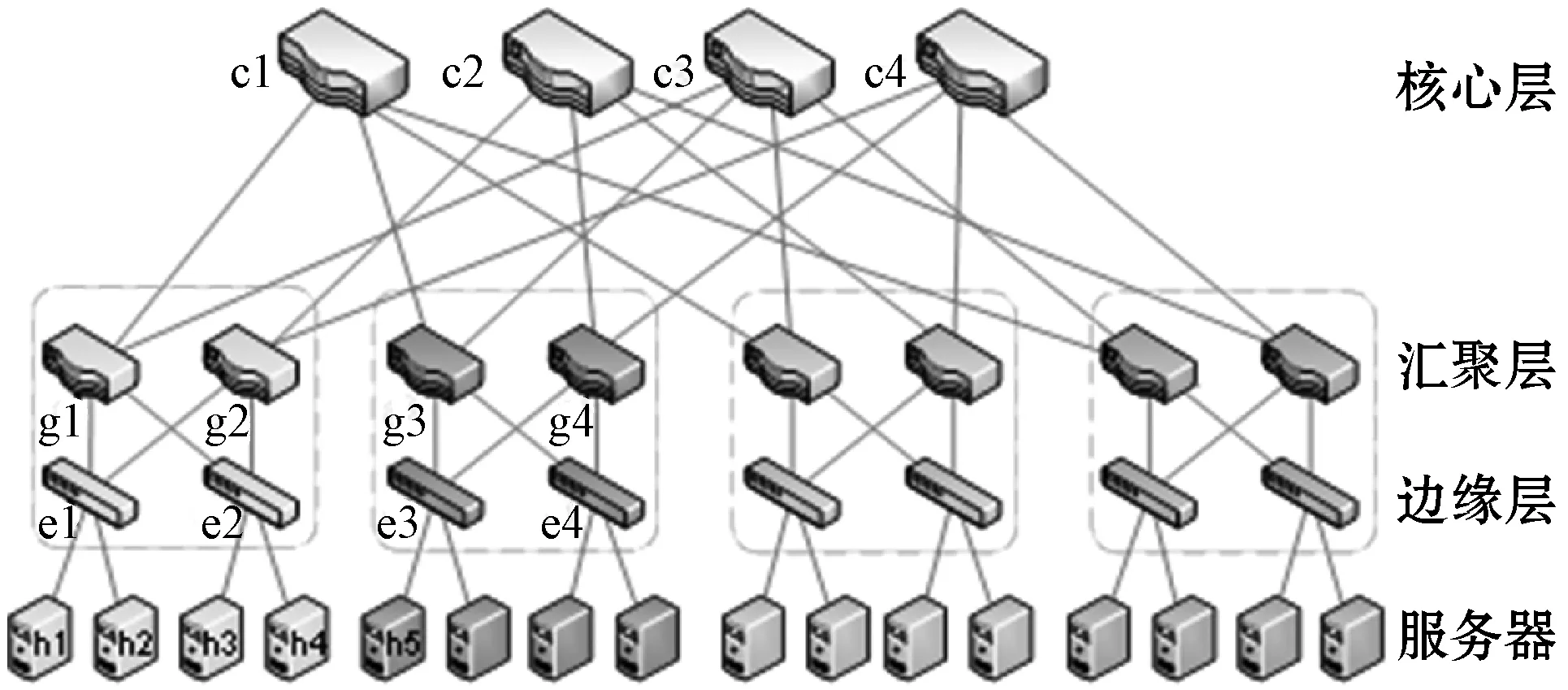
图1 4-pod Fat-Tree网络架构
如上述所示,当数据中心在进行流量调度时,我们的关注对象由路径和流变为交换机和流。
1) 交换机:数据中心中的所有交换机,同大多数商用交换机一样,数据中心的交换机通常是共享内存式的交换机,即所有交换机端口共享数据包缓冲区来提高内存利用率[9]。以下提到的交换机均认为是共享内存式交换机。图2为共享内存式交换机的示例。

图2 共享内存式交换机原理
这组交换机由S={s1,s2,…,sj}表示,|S|表示交换机的总数,cj表示交换机sj的容量。交换容量代表交换机各接口之间所能进行的数据交换的最大能力。一定程度上来说,交换机的容量是一个单位时间内能接收的数据包个数,因此交换机的容量与流的传输速率有关。
2) 流:数据中心的流量可以分为大象流和老鼠流两类,根据以往的研究表明,数据中心的流量服从长尾概率分布,大象流数量只占流总数的20%,但却占据了90%的网络流量[9],本文的重点关注数据中心中服务器之间传输的大象流集合。如没有特殊说明,以下提及的流皆指大象流。
该组流被定义为F={f1,f2,…,fi},|F|表示流的数量。流具有许多特征,例如生存时间、数据大小和数据速率。如上所述,交换机的容量与流的传输速率有关,因此我们注意流的速率特性,并用ri表示流量的速率。这里,ri可以是特定时间间隔内的平均配对流量速率,并且可以适当地设置间隔长度以匹配环境的动态,同时不响应瞬时流量突发。这是合理的,许多现有的数据中心流量测量的研究表明,流量随着时间的推移呈现缓慢变化的现象[10]。
2.2 流-交换机匹配模型
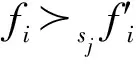
μ(sn)≻sn∀fmfm∈[F-μ(sn)]
(1)
μ(fm)≻fm∀snsn∈[S-μ(fm)]
(2)
定义1流的交换机优先级列表顺序由交换机内存大小决定。
流将占用路径上的交换机内存资源,在一个时间单位内,交换机接收的总流量速率不能超过交换机的容量,即cj≥∑ri。为了避免拥塞,流更喜欢具有更大容量的交换机。所以定义流的交换机优先级列表P(fi)={s1,s2,…,sj}中交换机的顺序是由交换机内存大小决定的,pod间流优先级列表对应核心交换机,pod内流对应汇聚层交换机。
定义2交换机的流优先级列表顺序由流的传输速率决定。
每个交换机sj也会有一个流优先级列表:P(sj)={f1,f2,…,fi},交换机优先考虑传输速率低的流,所以列表中流的顺序由通过他们的速率决定。由于每个交换机可以接受多个流,并且为了不超过交换机的容量,交换机需要检测内存状态。
定义3给定S和F,流-交换机匹配问题要找的是最佳匹配集合M={(fi,sj)|fi∈P(sj),sj∈P(fi)}。
max |M|
(3)
E(fi,μ(fi))=0
(5)
|μ(fi)|≤1
(6)
式中:j=1,2,…,|S|;i=1,2,…,|F|。
式(4)确保所有交换机的容量不会溢出,式(6)确保每个流最多与一个交换机匹配。
2.3 匹配冲突问题
由于交换机的内存限制、流的交换机偏好的存在,可能会导致pod间流量和pod内流量在匹配交换机的过程中发生冲突。如图3所示,在Fat-Tree网络中,一个容量为9的核心交换机A,汇聚层交换机B、C的容量分别是10和7,B和C在一个pod内。两个大象流a和b,假设流a是一个pod间流,其数据速率是8;流b是一个pod内流,其数据速率是6。流a选择A作为合适的核心交换机,并途经交换机B转发到交换机A。同时,如果同一个pod内的流b选择交换机B作为合适的汇聚层交换机,这就导致了交换机B内存溢出。原因在于pod内流调度选择汇聚层交换机时忽略了该汇聚层交换机是否有足够的内存来传输该流,这可能导致交换机的拥塞或流的重传。我们称此为汇聚层交换机上的pod内流和间流冲突。
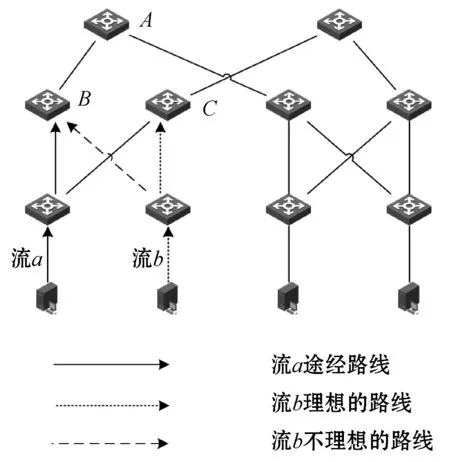
图3 匹配冲突示例
为了解决此问题我们需要分别执行pod内流调度和pod间流调度,此外由于冲突的原因是汇聚层交换机的资源有限,所以在执行pod间流调度时,为流匹配合适的核心交换机,之后根据资源消耗修改路径上的汇聚层交换机的内存状态。
3 系统方案与实现
3.1 TPLM算法
以上定义了一个稳定匹配问题,G-S算法[11]是求解稳定匹配问题的常用算法,但是G-S算法是一对一的匹配,流-交换机匹配问题是多对一的关系,而且由于交换机优先选择传输速率低的流,流优先考虑选择容量大的交换机,导致网络中的很多流或交换机会具有相同的优先级列表,会使得容量大的交换机非常繁忙,容量小的交换机非常空闲。因此不能直接应用G-S算法到流-交换机匹配问题中。TPLM算法如算法1所示。
算法1TPLM算入:F,S,C,R。
输出:最优解集合M。
1.计算得到P(F)、P(S)
2.初始化M为空
3.While(F中存在任意一个未匹配的流fi)do
4.sj=优先级最高且未拒绝sj的交换机inP(fi)
5.ifsjis未匹配then
6.M=M∪(fi,sj)
7.elseiffi≻sjfksjthen
8.M=M-(fi,sk)
9.M=M∪(fi,sj)
10.else
11.sj拒绝fi
12.endif
13.ifM不在变化&&存在fi未匹配then
14.根据当前匹配结果M更新C
15.endif
16.endWhile
17.ReturnM
针对上述问题,本文改进G-S算法,提出一种流优先层次匹配算法TPLM,流优先指流-交换机匹配的过程中,由流主动匹配交换机,交换机是被匹配方,这样做的目的是保证交换机内存资源不溢出。层次匹配指,将匹配分为pod间流调度匹配和pod内流调度匹配两层,先匹配pod间流,pod间流匹配完成后,更新交换机剩余内存信息再匹配pod内流,目的是解决2.3节描述的匹配冲突问题。
TPLM的算法流程如表1所示,TPLM通过多次迭代匹配得到交换机和流的一对多最优匹配。定义流选定交换机的状态称为“延迟接受”。迭代过程如下:
步骤1选择流集合F中的任意一个不是“延迟接受”状态的流fi,并且请求P(fi)中优先级最高且没有拒绝过它的交换机sj作为匹配对象。
步骤2若交换机sj已经匹配了流fk,则比较P(sj)中fi和fk的优先级,若fi的优先级高于fk,则sj拒绝fk接受fi。否则sj拒绝流fi,然后fi按步骤1选择下一个交换机作为匹配对象,直到匹配成功。
步骤3多次迭代直到“延迟接受”匹配对,sj没有改变。如果每个流已经处于“延迟接受”状态,则迭代结束,并且当前流和交换机匹配结果是最佳匹配。否则,记录当前匹配结果,并将当前匹配结果的存储容量C与其匹配流量的数据速率R之间的差值作为新的交换容量C′,转到步骤1。
通过多次迭代,交换机和流的匹配结果将呈现“小而多,大而少”的状态。即具有大容量的交换机匹配较多的具有相对小的数据速率的流,小容量的交换机接收较少的具有数据速率相对大的流,这避免了贪婪的出现并提高了交换机的利用率。
一般来说,流量负载均衡专注于将一个流分配给当前的最优路径,但是却忽略了该路径继续承载其他流时会发生流量碰撞,使得两个流的传输都受阻。TPLM的思想是为每个流匹配一条合适的路径,而不是单个流转发的最优路径,这就意味着TPLM为整个网络流调度找到了全局最优解,从而提高了整个网络的性能。
3.2 系统方案
首先执行pod间流调度,得到核心层最优匹配。根据Fat-Tree网络架构的特点,我们根据源主机和核心交换机可以唯一确定一组路径,从而确定一组汇聚层交换机,通过减去其流经的pod间流的传输速率来更新汇聚层交换机的剩余容量,得到最新的剩余内存。然后通过算法1进行pod内流量调度,最终得到汇聚层最优匹配。
考虑到老鼠流对时延敏感的特性,对于老鼠流我们使用时延最小调度策略,即老鼠流到达时,控制器选取当前时延最小的路径为其路由。
定理1TPLM算法中,所有的流都能匹配到交换机。
证明随着迭代次数的增加,总有一个时候所有流都有交换机与之匹配。因为流会根据自己的交换机优先级列表排名依次进行匹配。假如存在一个流没有匹配到交换机,那么这个流必定是向所有交换机进行请求匹配了。但是交换机只要被请求一次就一定会进入“延迟接受”状态,这与存在一个流没有匹配到交换机假设相悖,所以假设不成立。该算法一定会使得所有流都能够配对成功。
定理2TPLM所得的匹配一定稳定。
证明假设匹配结果M中有两个匹配对(f1,s1)、(f2,s2),f1认为s2好于s1,s2认为f1好于f2。这两个匹配的形成是有先后顺序的,假设f1先和s1先匹配,由于f1认为s2好于s1,那么f1已经向s2请求过了,请求的结果有两种:1)s2当时接受了f1。我们可以发现,算法中交换机一旦接受了某个流的请求,就一定会一直处于“延时接受”状态,且从交换机的视角而言,匹配的流只会越来越好。这与结果中f2和s2匹配是矛盾的。2) 如果s2当时没有接受f1的请求,那么s2当时一定有比f1更好的流与之匹配,最后也不会选择f2。所以TPLM返回结果中不存在不稳定配对。
3.3 负载均衡架构
负载均衡架构如图4所示,主要共包含三个模块:Monitor、Statistics Collector、Schedule。
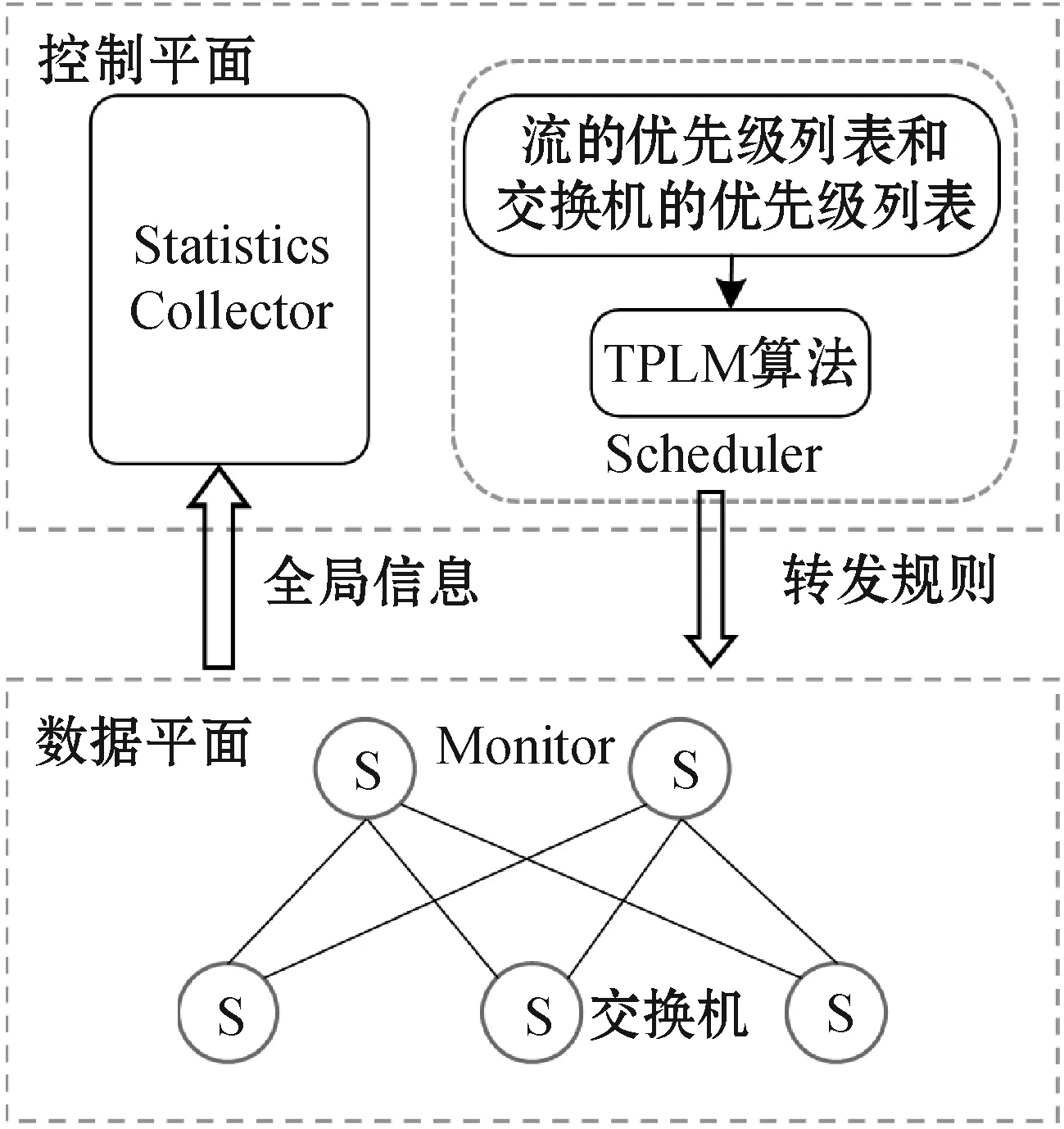
图4 负载均衡架构
Monitor:该模块主要负责收集流量信息和交换机信息。流的传输速率和交换机的内存信息是匹配过程中最重要的两部分,这些数据必须在数据平面获取。
Statistics Collector:主要负责统计获取底层网络的数据信息。统计收集模块在控制器中完成,与底层Monitor通信,获取Monitor收集的流量和交换机信息,并向Schedule模块提供接口。
Schedule:该模块主要的工作是执行TPLM算法,得到最优匹配后把匹配结果转化为流表规则的形式下发到数据平面。
4 仿真与评估
4.1 仿真环境
我们在Floodlight控制器上实现了TPLM,在Mininet上搭建6-pod Fat-Tree网络拓扑,仿真中的其他参数如表1所示。Floodlight控制器和Mininet都运行在一台装有Ubuntu 18.04系统的服务器上。

表1 仿真参数
本文采用如下三种流量模式:
1) Stride(i):拓扑中主机从左向右依次编号,编号为m的主机向编号为(i+m)/n的主机发送数据。
2) Random(i):拓扑中主机从左向右依次编号,每台主机等概率地向任意i台主机发送数据。
3) Staggered Prob(EdgeP,PodP):主机以概率EdgeP发送到同一边缘交换机中的另一个主机,并以概率PodP发送到其相同的pod,并以概率1-EdgeP-PodP发送到网络的其余部分。
4.2 仿真结果与分析
我们从平均流完成时间(FCT)、大象流吞吐量、平均网络吞吐量和平均网络延迟中比较了TPLM,Hedera和ECMP的三种策略,以证明性能的实际提高。
图5显示了三种调度策略下不同模式老鼠流的FCT。可以看出,由于老鼠流在机柜流量的调度几乎没有优化空间,因此这三种调度算法在Stride(1)模式下的区别并不明显。随着系数i的增加,pod间流传输增多,TPLM表现出优势。在Random(i)模式下,随着参数的增加,TPLM的优势越来越明显。图6显示了三种调度策略在不同调度模式下大象流的FCT。总体而言,TPLM性能最好,而ECMP性能最差。在Stride(i)模式下,TPLM调度大象流相比调度老鼠流时效果更好。在Random(i)模式下,随着系数i的增加,TPLM的优势变得越来越明显。
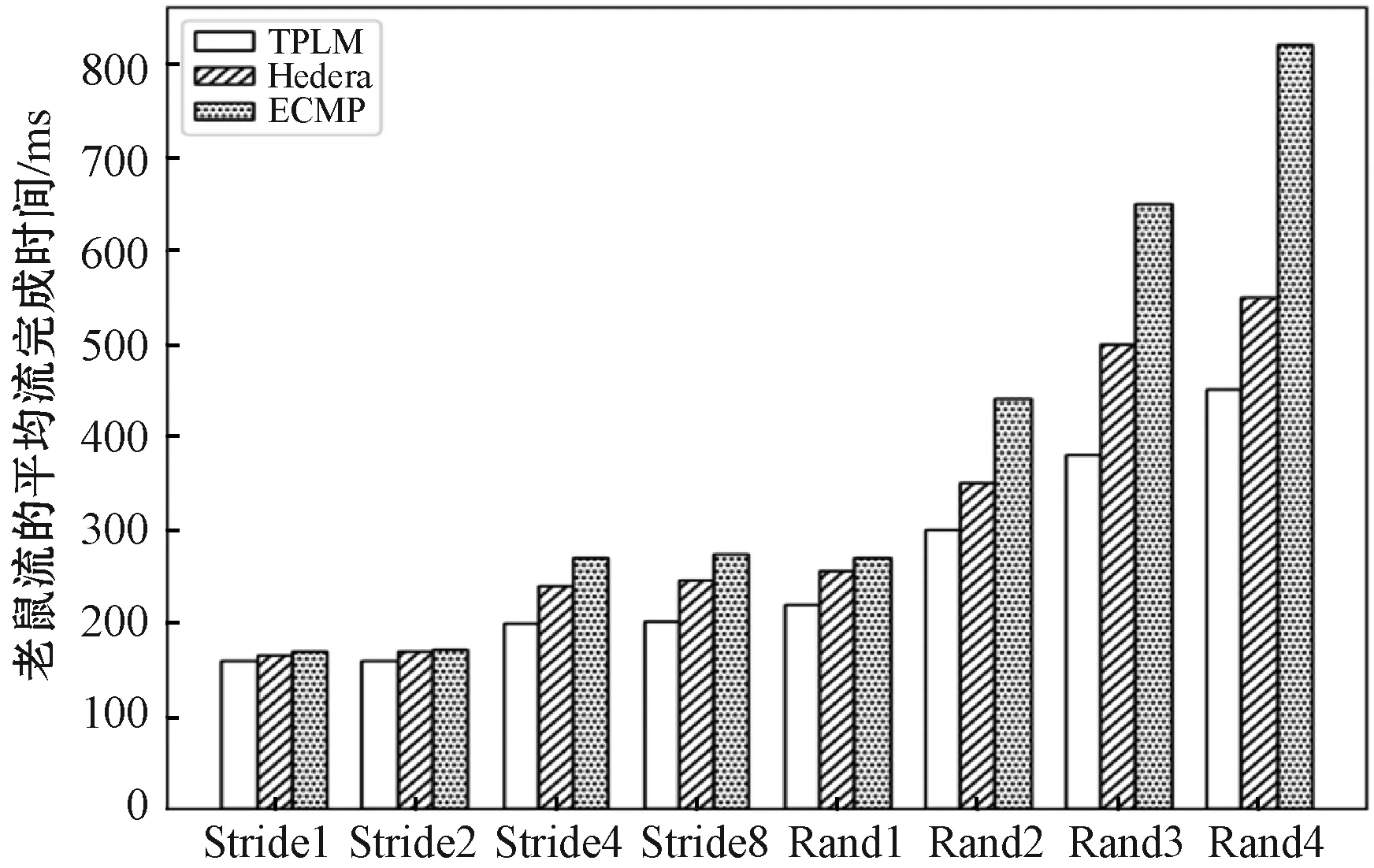
图5 老鼠流的平均流完成时间
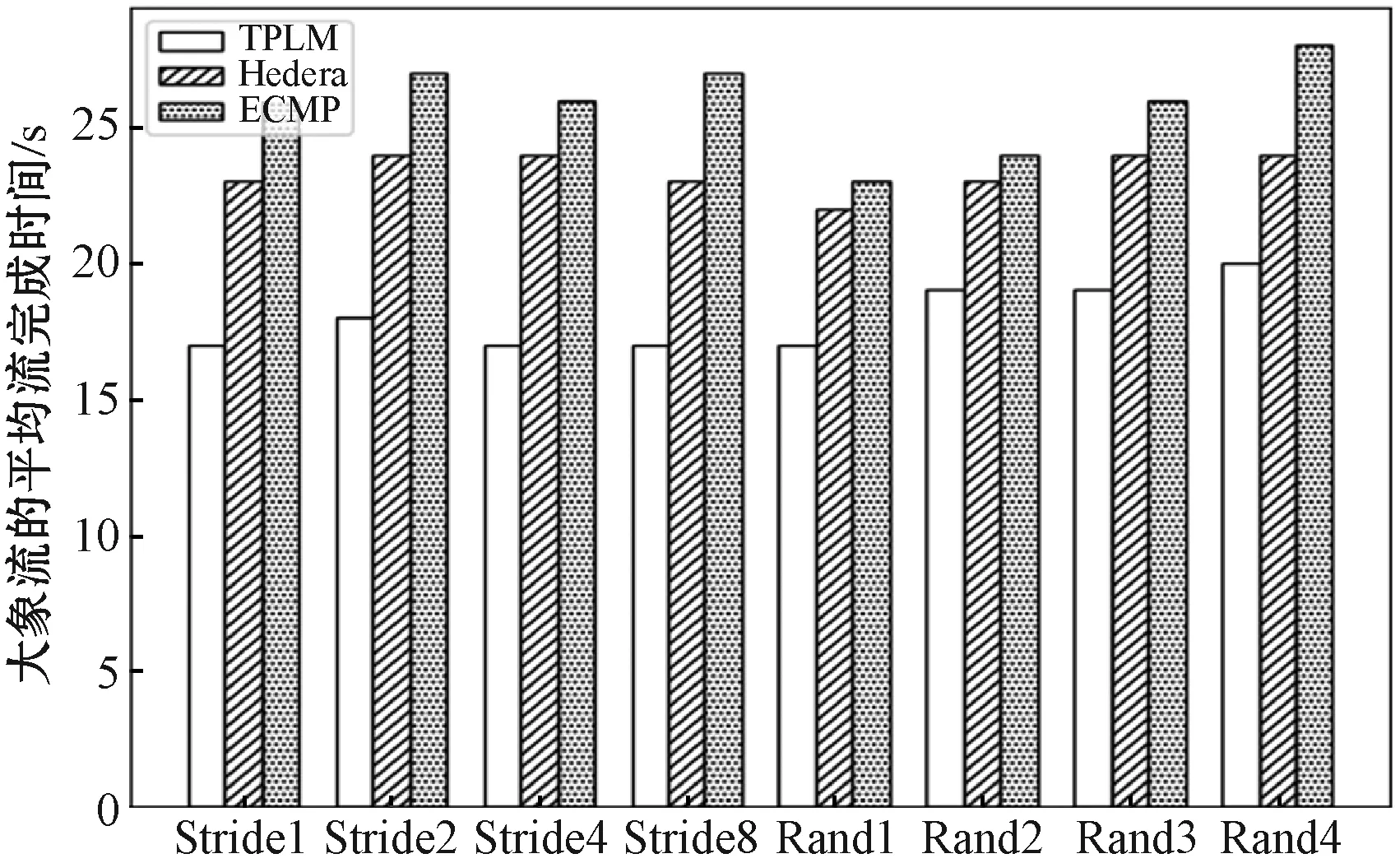
图6 大象流的平均流完成时间
图7是在Staggered Prob(0.2,0.3)模式下的三种调度策略的图示。网络负载的增大,意味着网络中发生流量碰撞的概率的增大,使得无法做到负载均衡的调度策略性能较低。可以看出,随着网络负载的增加,三种调度策略下的大象流吞吐量逐渐增加,而增量逐渐减小。与ECMP相比,Hedera和TPLM在高负载条件下具有显著提高的吞吐量。由于ECMP是基于五元组来计算哈希选择路径的,因此它不会考虑可能导致链接或交换机拥塞的负载情况,从而导致数据包丢失。与Hedera相比,TPLM具有优势,由于TPLM预先匹配了收集到的大象流量,因此不会由于新大象流量的统计而导致资源分配不均。图8显示了在Staggered Prob(0.2,0.3)模式下,三种负载均衡策略的全网吞吐量随网络负载变化的曲线。由于网络中的大部分流量都是由大象流贡献的,因此全网吞吐量曲线和大象流吞吐量变化曲线基本相同。
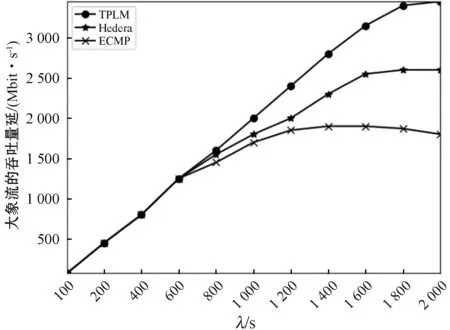
图7 大象流的吞吐量随网络负载变化
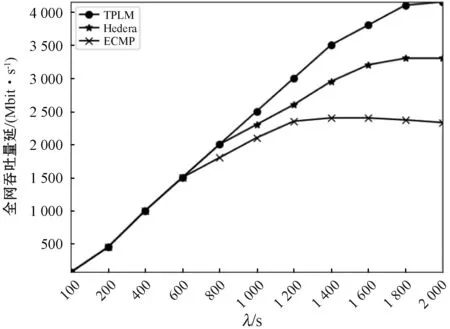
图8 老鼠流的吞吐量随网络负载变化
图9是在Staggered Prob(0.2,0.3)模式下平均网络时延随网络负载变化的曲线,随着网络负载的增大,TPLM的优势越来越明显,可以看出,TPLM有效地改善了整个网络的平均延迟。
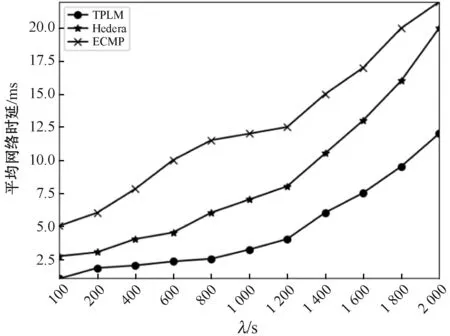
图9 网络时延随网络负载变化
由于将稳定匹配应用于大象流调度,这将为数据传输和网络容量均获得最佳结果,因此,网络吞吐量、FCT、时延的性能均显示了TPLM的有效性。
ECMP通过哈希的手段得到流的转发路径,由于哈希冲突的存在,哈希在同一路径上的多个流会发生拥塞,从而增加时延,减少了网络吞吐量。Hedera专注于将一个流分配到当前最佳路径,却忽略了该路径承载多个流时的冲突问题,从而使多个流的传输都无法获得最佳性能。TPLM使用稳定匹配理论将所有流分配给适当的路径,其匹配机制有效地避免了拥塞,从全局的角度调度流量,为整个网络流调度找到全局最优解。因此,与ECMP和Hedera相比,TPLM具有更好的性能。
5 结 语
本文研究了数据中心大象流调度问题,发现数据中心内“东西向”大象流的合理调度是数据中心流量负载均衡的关键点,并应用稳定匹配理论提出解决方案TPLM,TPLM主要考虑了交换机和大象流之间的关系,建立大象流和交换机的层次匹配模型,TPLM可以有效地避免网络拥塞。基于Floodlight和Mininet的实验结果表明,大象流的吞吐量和全网吞吐量得到显著提升,老鼠流的平均流完成时间在显著降低。
