基于Q-learning的随机接入碰撞问题的研究
2022-12-03徐方圆张治中
徐方圆 张治中 李 晨
(重庆邮电大学通信与信息工程学院 重庆 400065)
0 引 言
随着物联网的飞速发展,未来将会出现更多的机器与机器(M2M)场景。M2M通信的多样性取决于合适的无线接入网络。到2020年,M2M设备的数量会超过500亿,这意味着大大地增加了人控制机器的复杂性。蜂窝网络的覆盖性、漫游指标等特点使得无线空口通信更适合M2M,有利于M2M之间的通信[1]。LTE网络已经将M2M作为新服务应用的关键性技术[2]。然而,蜂窝网络的最初设计是为人与人(H2H)通信而设计的,故M2M与H2H共存的情况是必然的。M2M主要进行UL链路的传输,而H2H相比M2M而言,DL链路传输更为普遍。另外,由于H2H主要支持语音呼叫、视频流、上网和社交媒体,因此H2H需要基本的网络服务要求。相反,M2M更多的是面向设备与设备之间的业务,具有较小的数据业务载荷。另外,M2M设备在蜂窝中的数量可能是海量的,蜂窝网络的小区内可能有成千上万个M2M设备[3],会导致设备在接入基站的过程中发生随机接入拥塞。这是因为设备在访问基站的速率大大增加导致设备接入的冲突的概率加大。因此,随机接入信道的拥塞问题成为M2M中必要解决问题。
本文主要在M2M与H2H共存场景下提出了一种基于Q-learning随机接入退避算法来降低在随机接入信道中的拥塞率,从而增加了随机接入信道的吞吐量。3GPP提出的其他解决方案包括时隙接入方案、基于Pull的方案、M2M特定的退避方案和RACH资源的动态分配[4]。3GPP提出的解决方案的方法需要eNB的直接参与,因此需要修改现有网络标准和5G的信令。但是修改标准和信令改变了现有H2H用户的操作模式。本文主要目的是为了提高随机接入的吞吐量,同时又不会影响标准的统一性。本文中,Q-Learning算法主要对M2M设备中随机接入流量进行智能控制。本文基于这两种方案上M2M与H2H场景进行建模,将5G无线帧划分为H2H帧和M2M帧,利用Q-learning智能算法对M2M场景中的设备进行状态分析、动作转移,奖励更新。
1 随机接入碰撞分析
在M2M场景中,主要是机器连接4G基站然后进行上行数据的传输。而在H2H中,主要是用户连接5G基站进行下行传输。图1描述了H2H与M2M共存的场景,主要从两个方面来分析:(1) 5G网络满足多用户接入和低时延传输,多用户的传输速率过高会导致用户接入时发生碰撞,故在此场景下需要解决H2H的接入通信问题;(2) M2M大量的设备容易造成随机接入信道发生过载,故在此场景下需要解决容量过载问题。最后,5G与4G基站同时关联核心网中MME/S-GW。在关联的过程中,容易导致H2H与M2M的帧发生冲突。时延敏感的机器类通信设备MTCD直接和基站进行通信,对时延不敏感的M2M终端按照业务属性或位置划分成不同的群组,通过机器类通信网关MTC和基站进行通信[7]。
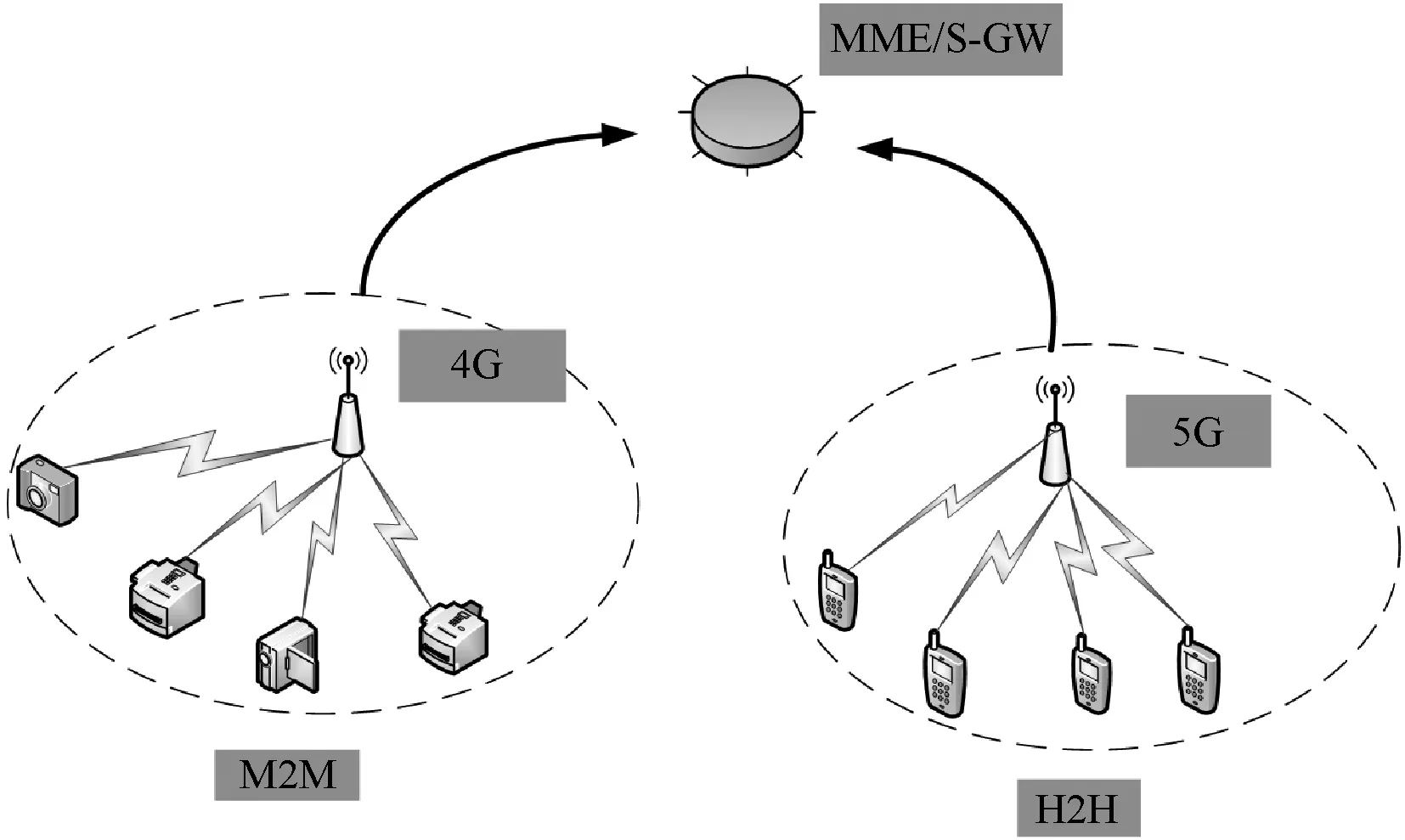
图1 H2H与M2M共存场景
1.1 时隙Aloha RACH接入(SA-RACH)方案
SA-RACH是H2H用来访问蜂窝网络中的RACH的现有方案,该方案对于所有蜂窝网络标准都是通用的,因为它们都将RACH用于控制信道。但是,随机接入信道的结构和排列方式有所不同。例如,GSM协议将时间划分为多个相等大小的时隙,称为RACH时隙,这些时隙映射到网络中的重复帧结构上[5]。
ALOHA协议和它的后继CSMA/CD都是随机访问或者竞争发送协议。ALOHA是按照用户的需求进行随机接入和发送数据。然而,当多个用户同时需求发送数据时,容易产生碰撞。当发生碰撞时,传输帧容易受到破坏。因此,在ALOHA协议中,发送方可以在发送数据的过程中进行冲突检测,将接收到的数据与缓冲区的数据进行比较,就可以知道数据帧是否遭到破坏。如果发送方知道数据帧遭到破坏(即检测到冲突),那么它可以等待一段随机长的时间后重发该帧。时隙ALOHA协议的思想是用时钟来统一用户的数据发送。办法是将时间分为离散的时间片,用户每次必须等到下一个时间片到来才能开始发送数据,从而避免了用户发送数据的随意性,减少了数据产生冲突的概率,提高了信道的利用率。
纯时隙ALOHA的实现方案:当用户进行上行传输时,会开启一段时间窗,等待基站的回应。基站收到上行传输数据时,会发送ACK信号。当多个用户同时收到ACK信号时,会发送碰撞,多个用户会等待一段时间后再继续传输。Slotted ALOHA是在纯ALOHA帧的基础上进行分段处理,它把频道在时间上分段,每个传输点只能在一个分段的时隙开始处进行传送。每次传送的数据必须少于或者等于一个频道的一个时间分段。这样极大地减少了传输频道的冲突。
由图2和图3可知,两种时隙下的随机接入吞吐量呈现先增大后减小的趋势。在随机接入吞吐量一定的情况下,Slotted ALOHA时隙适用于流量更大的场景。由于所有标准都使用Slotted Aloha的盲目性质来访问RACH,所以当多个用户在同一时隙中发送请求时会发生冲突。故此方案应用在设备量巨大的情况下行不通。由于分槽ALOHA适用于流量大的场景,故在本文中以分槽ALOHA为基准,对H2H与M2M场景共存下的随机接入过程碰撞进行研究。当前学术界主要是用分槽ALOHA对随机接入碰撞为题进行研究。进一步分析基于Q-learning的分槽时隙方案。
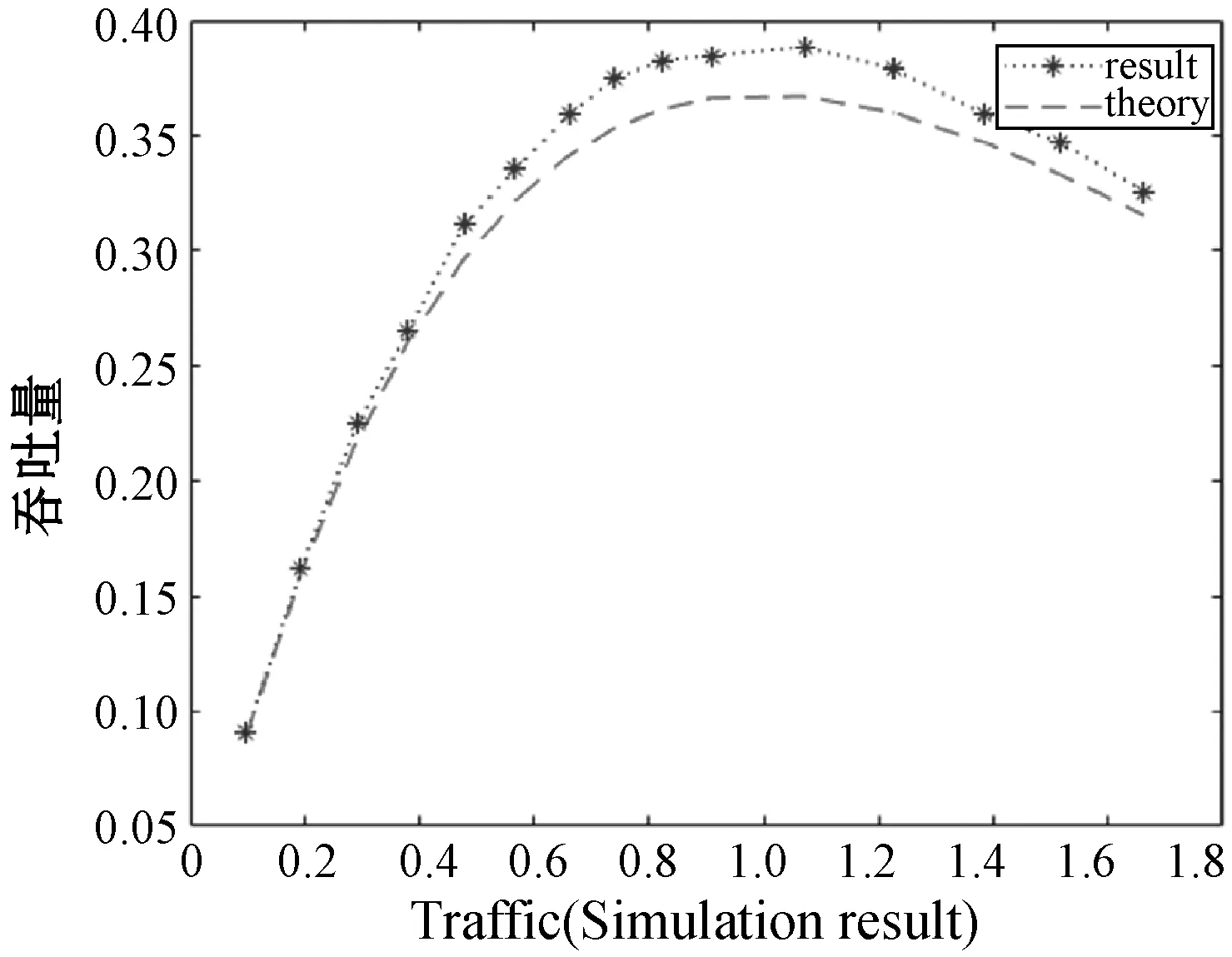
图2 Slotted ALOHA协议吞吐量
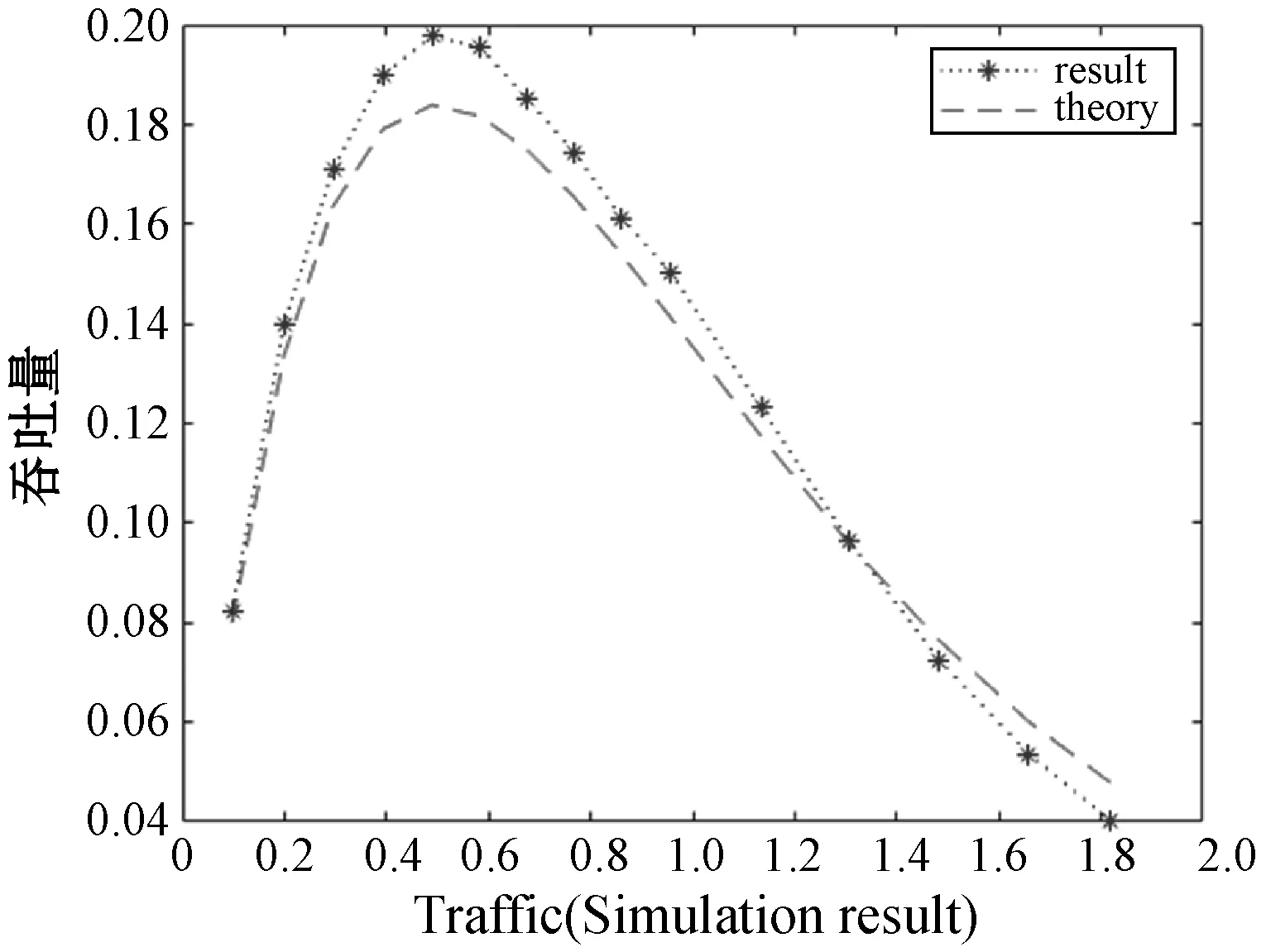
图3 纯ALOHA协议的吞吐量
1.2 基于Q-learning的Slotted ALOHA方案
在这种方法中,Q-learning用于控制RACH访问中的M2M流量。Q-learning是强化学习的简化版本,其中算法在学习时提供最佳的系统收敛性。将此方案与SA-RACH结合使用可减少冲突的总数,因为在学习收敛后(每个M2M用户都有唯一的专用RACH时隙时),M2M用户之间不会发生冲突。文献[8]已经使用类似的方法来提高Slotted Aloha在无线传感器网络中的吞吐性能。因此,本文方法是在H2H与M2M场景下结合RACH接入方案。为了实现强化学习,M2M流量利用RACH或虚拟时隙(RA)的虚拟帧,称为主蜂窝帧中的M2M帧,如图4所示。为了获得最佳的学习结果,使M2M帧的大小(时隙数)等于M2M用户数。通过M2M基于帧这种形式来进行RACH访问,每个用户仅访问M2M帧中的一个时隙。通过式(1)更新Q值。
Q′=(1-A)×Q+A×r
(1)
式中:Q为当前的Q值;A为学习因子;r为奖励/惩罚因子取决于随机接入请求的状态,当随机接入成功时,r的取值为1,当随机接入失败时,r的取值为0。此过程导致每个M2M的时隙具有不同的Q值,用户始终选择具有最大Q值的时隙,如果多个时隙具有相同的Q值,则用户将随机选择一个。在稳定状态下(每个用户找到专用时隙时),由于随机访问和重传策略会增加冲突,因此H2H用户仍然会受到干扰。这将导致比专用M2M时隙中获得更多的惩罚,在某些情况可能会使用户丢失该时隙。
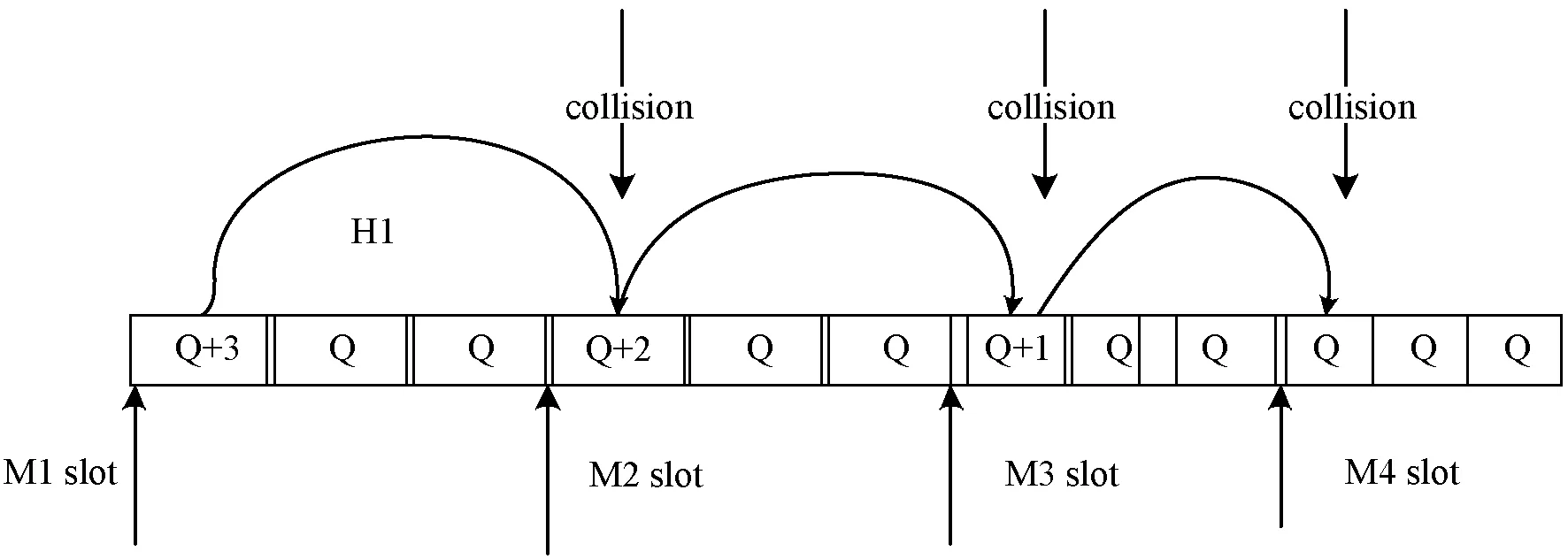
图4 重复冲突丢失专用时隙例子
图4显示了M2M用户(M1)如何由于重复冲突而丢失专用时隙的示例。M1在M2M时隙1中,此时M1的Q值为Q+3,H1为H2H时隙并在M1时隙处开始传输,那么M1时隙与H1时隙发生冲突。然后M1的值就会变成Q+2。由于H2H的窗口值为3,当处于M2时隙时,H1正好又与M2时隙发生碰撞,此时M2的值就会变成Q+1。当到达M3时隙时,H1正好又与M3发生碰撞。此时M3时隙的值变成Q+1。最后再经过一次碰撞到达M4时隙,此时M4的Q值就会变成Q。在这个过程中,M2M时隙会不断地接受惩罚使得Q值减小。当减小到低于一个阈值时,该时隙丢失。这就造成了M2M时隙重复冲突丢失。为了解决这个问题,文献[5]中提出了一种改进的Q-learning的算法。为减少影响,更改上面介绍的惩罚规则。这里,惩罚已经变得可变,这取决于参与其中的用户观察到的重传次数碰撞。因此,当发生碰撞时,Q值使用以下方法更新(惩罚)受影响的时隙:
Q′=(1-α)Q-αK
(2)
式中:(KH2H)i是参与冲突的第i个H2H用户观察到的重传次数;KM2M是受影响的M2M用户观察到的重传次数。此方程的目的是为了减小惩罚值,从另外一个角度来说是为了降低H2H用户接入流量对M2M时隙的影响。
在现有的蜂窝网络上支持M2M意味着H2H用户将与M2M用户共享/竞争蜂窝网络资源。因此,应该通过解决资源竞争来设计一种更好的共存方式。用户之间的交互级别由生成的单个负载控制,以构成系统的总流量负载。总流量的表达式如下:
Gtotal=GH2H+GM2M
(4)
式中:G为流量的总负载;GH2H为H2H场景下的用户流量负载;GM2M为M2M场景下机器流量的总负载。仿真参数如表1所示。
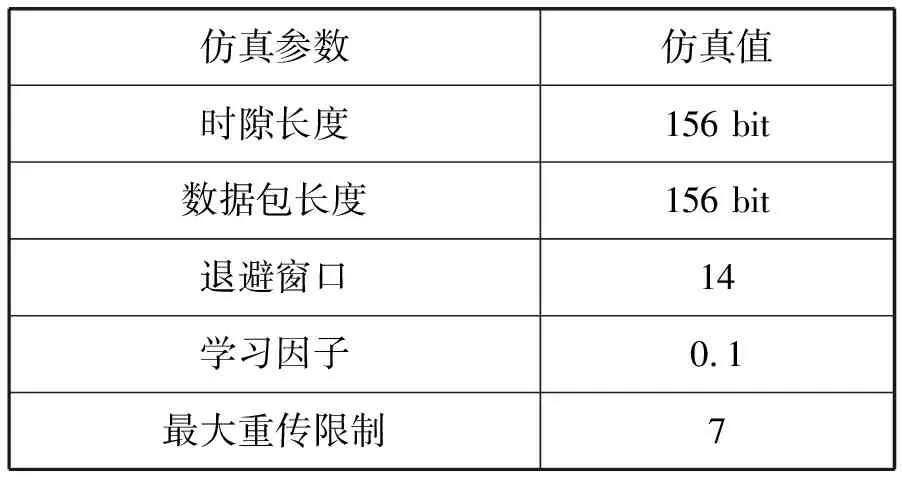
表1 仿真参数
如图5所示,比较了常规的蜂窝的SA-RACH方案的吞吐量与经过Q-learning学习后QL-RACH方案吞吐量,得出结论:(1) 两种接入方式中,经过Q-learning学习的QL-RACH吞吐量随流量的增大呈线性增加,而常规的蜂窝SA-RACH的吞吐量随随机接入信道流量的增大而先增加后减小。(2) Q-learning学习的QL-RACH的吞吐量会收敛于最佳的吞吐量值,由于SA-RACH信道的容量较低,信道性能变得不稳定,RACH吞吐量在临界点后立即下降。这是由于聚合的流量超过了Slotted Aloha支持的信道容量,导致随机接入信道不稳定。
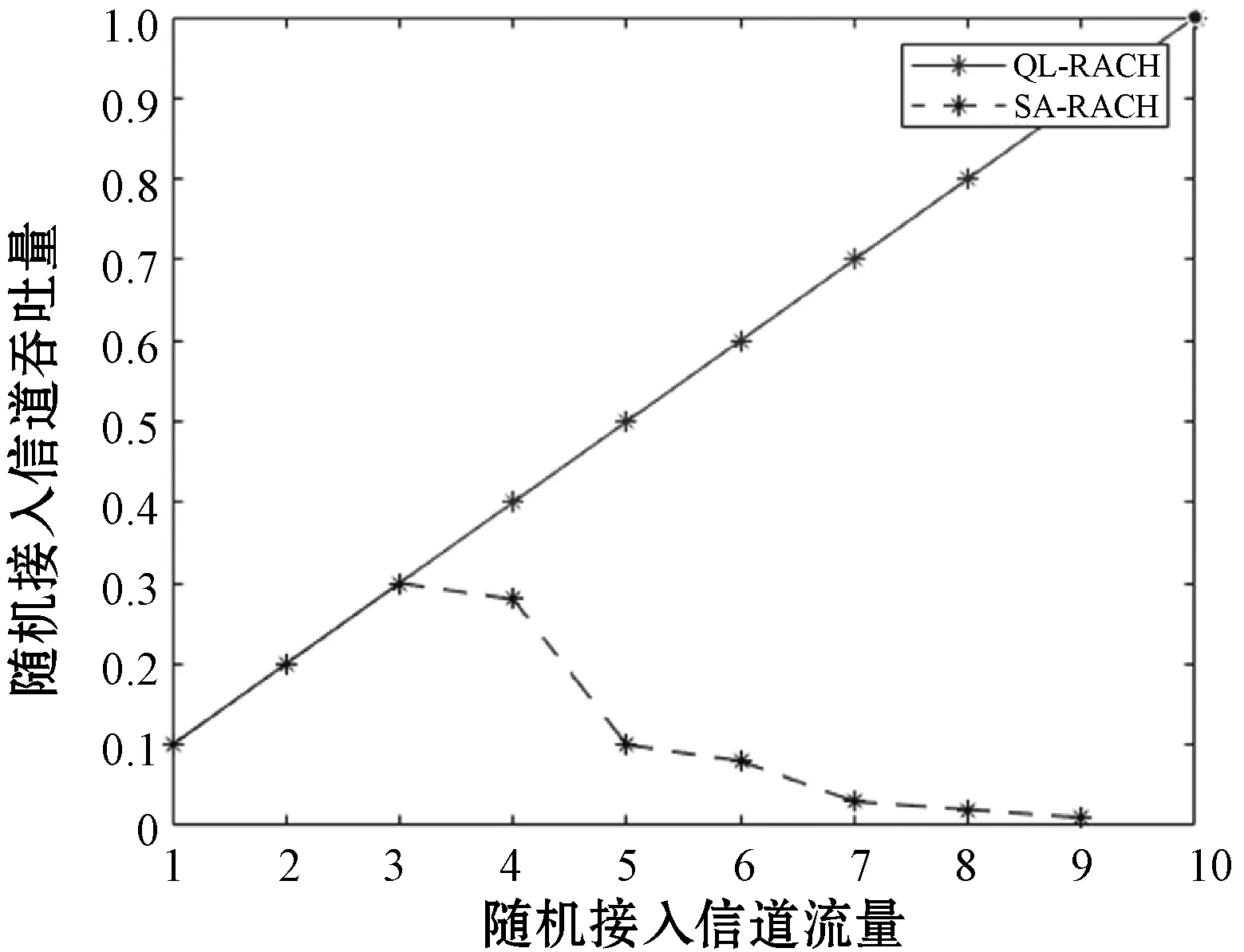
图5 QL-RACH与SA-RACH方案的吞吐量比较
2 改进的基于Q-learning的Slotted ALOHA方案
在使用Q-learning来学习单用户组的随机接入信道存在着很多缺陷。当单一接入M2M组或者接入H2H组时,Q-learning学习时的吞吐量明显比SA-RACH好。但是,多个用户组同时接入SA-RACH时,当达到临界点时会出现吞吐量急速下降,而使用Q-learning学习后的多用户组同时接入QL-RACH能够降低吞吐量急剧下降对系统的影响。因此,本文提出了多用户组随机接入方案。
2.1 Q-learning场景建模
对于多用户的接入方案,使用改进的方案是基于Q-Learning的分槽ALOHA方案。它的优点是对于高流量场景下的接入问题根据用户接入阈值K能够迅速判别UE的接入状态,大大增加了系统接入效率,同时能够满足海量吞吐量指标。具体步骤如下:
步骤1初始化多个用户组场景。
步骤2定义M2M组用户状态矩阵S(X,Y)定义,M2M组用户动作A(X,Y)。
步骤3初始化Q值矩阵,M2M用户组开始学习。
步骤4产生随机值Rand(0,1),当此值大于用户设定的阈值K,且为接入态时,在用户动作矩阵A选择一个合适的值在帧上进行传输,否则被判定为非接入态。此时更新Q值矩阵,并把更新的最大的Q值赋给动作矩阵A。
步骤5生成两个Q值分别为Q1和Q2,其中Q1代表当前的M2M用户组下学习的Q值,Q2代表更新后的Q值。计算Q2=reward+r×max(Q[next_state]);
步骤6将Q2-Q1的值更新到Q矩阵中,将下一状态更新为当前状态。
多用户组Q-learning接入方案流程如图6所示。
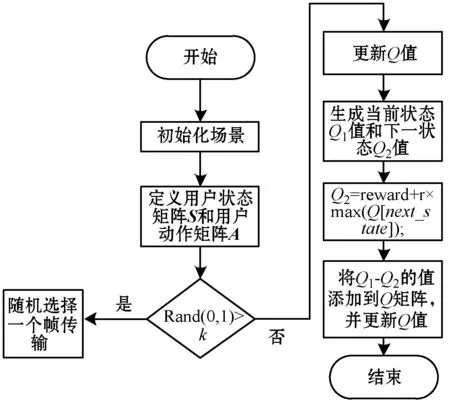
图6 多用户组Q-learning接入方案
多用户组是将H2H用户组和M2M用户组进行分类。在H2H场景中,将用户组优先级分为高、中、低三个等级。分别记为H2H_1、H2H_2、H2H_3。H2H_1代表抢占用户,H2H_2代表紧急用户,H2H_3代表普通用户。在M2M场景中,将设备分为M2M_1、M2M_2两种类型。M2M_1代表着M2M中访问流量高的设备组,M2M_2表示着访问流量低的设备组。如图7所示,a1、a2、a3分别代表H2H_1、H2H_2、H2H_3的优先级权重。b1、b2分别代表M2M_1和M2M_2优先级权重。权重越大,代表优先级越高,在流量相同的情况下分配的信道资源越多,吞吐量越大。在H2H与M2M共存的情况下,分别在H2H与M2M中选择一组进行Q-learning学习。
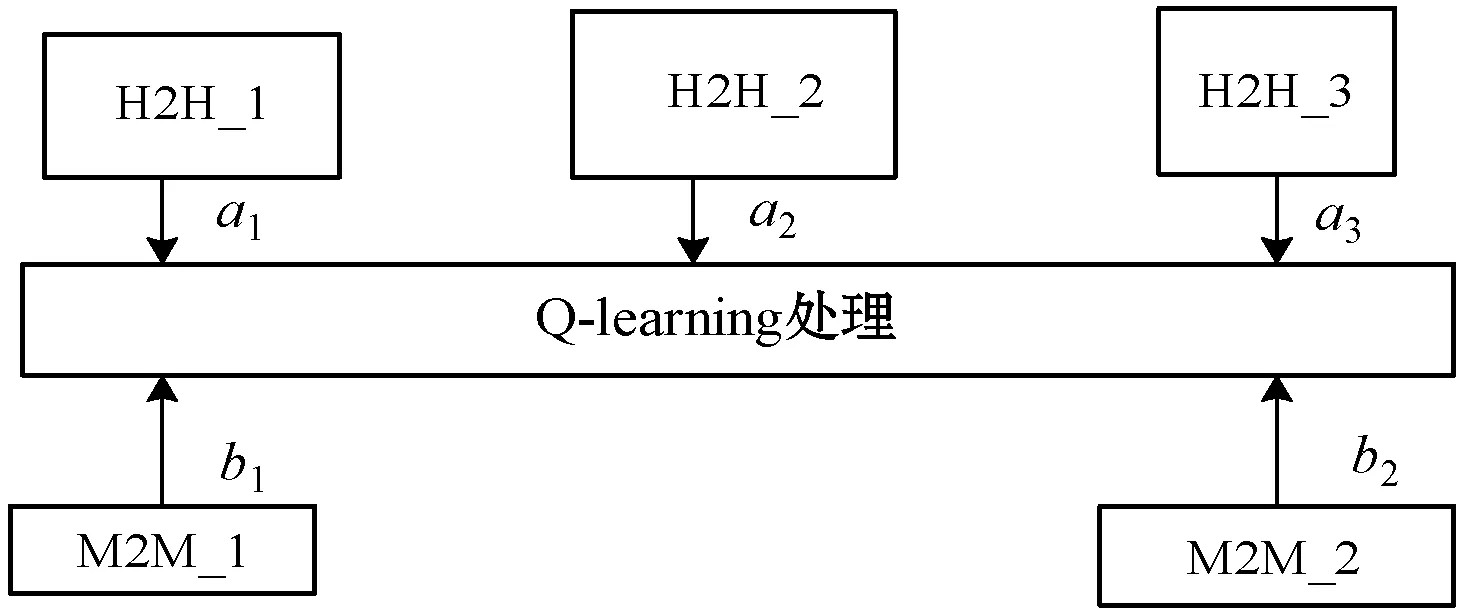
图7 H2H和M2M场景下不同优先级用户的学习方案
2.2 多用户组SA-RACH与QL-RACH方案
通过分别使用两种方案得出不同优先级的用户组学习的情况。当采用传统的SA-RACH处理时,仿真参数由表1可知。由图8可知,H2H使用传统的蜂窝接入方案时吞吐量会随着流量的增加而降低。M2M使用传统的蜂窝接入方案时,吞吐量会随着流量的增加先增加后减小。在H2H和M2M中,随着随机接入流量的增加,优先级高的用户组随机接入吞吐量要比优先级低的用户组随机接入吞吐量要低。使用传统的方案进行接入都存在这一个共同的问题,在高流量的场景下,由于随机接入信道容量有限,故吞吐量都会趋近于0。
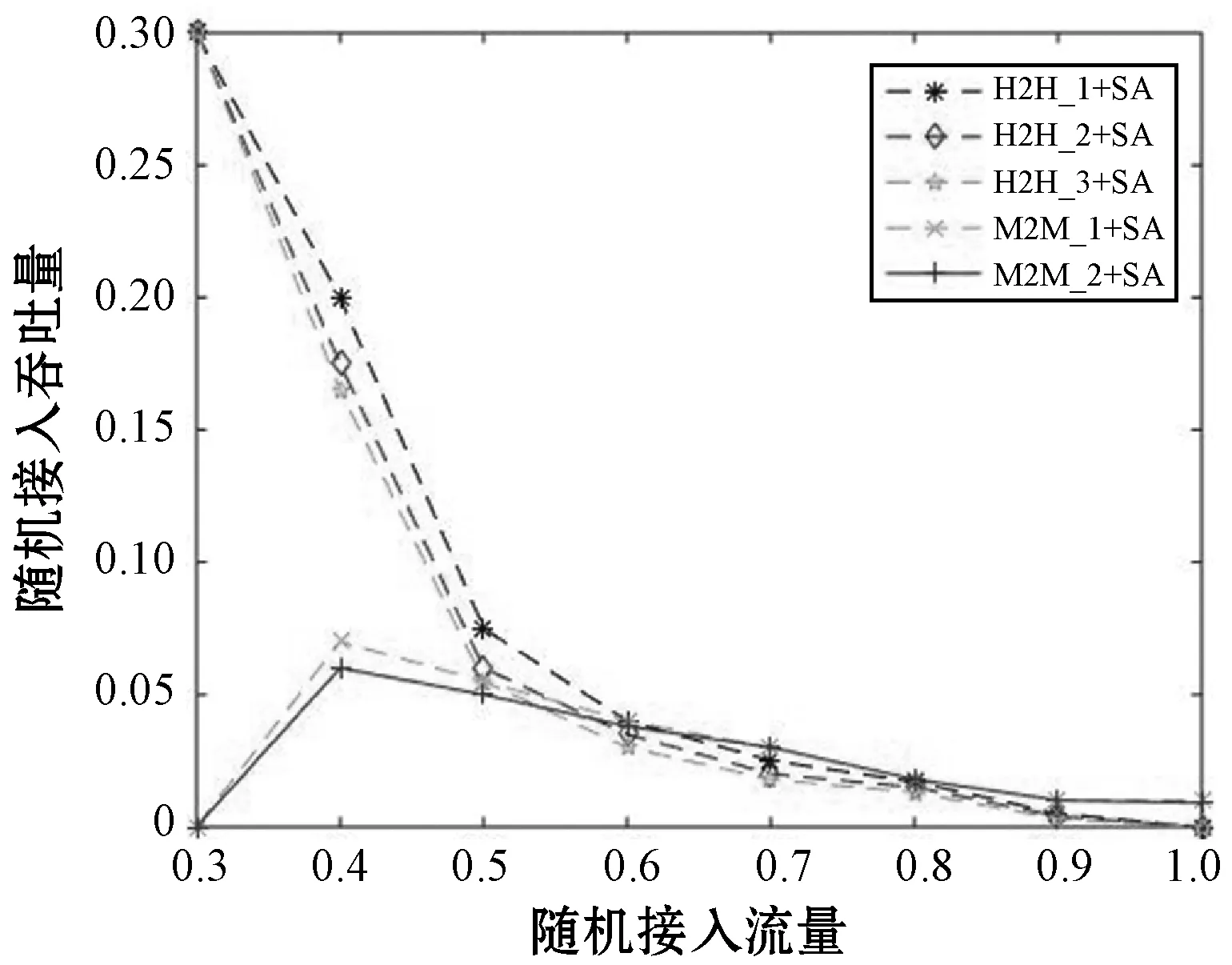
图8 多用户组采用SA-RACH方案处理仿真图
由图9可知,同一用户组使用Q-learning学习的多用户组方案的吞吐量会随着流量的增大收敛于一个最优值。不同用户组在同一场景下吞吐量取决于优先级大小,优先级越大,在流量一定的情况下,吞吐量越大。这样解决了在M2M和H2H共存场景中随机接入信道容量不足而引起的吞吐量下降的问题。
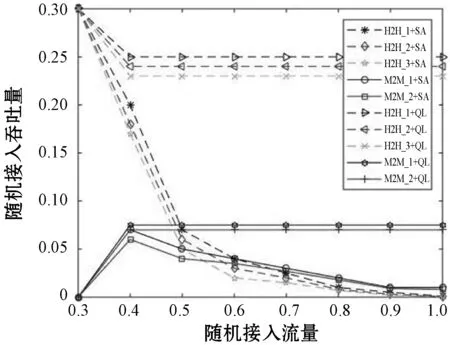
图9 多用户组采用SA-RACH与QL-RACH方案吞吐量对比
3 结 语
本文分析了H2H与M2M共存场景。分别分析了纯时隙ALOHA与Slotted ALOHA的吞吐量,结果显示:当流量很大时,这两种接入方式吞吐量趋近于0。为了解决这个问题,本文又分析了一种基于Q-learning的随机接入方案,这种方案是学习用户数量接入问题。然而,在H2H用户较多的时候,容易在时隙上面发生碰撞,导致最终的Q值不断减小。在此基础上提出了一种降低H2H用户接入流量对M2M时隙的影响的方案。最后,提出了Q-learning具体算法,并在不同优先级用户组进行分析。最后通过仿真对比,发现使用Q-learning学习的多用户组方案吞吐量最终会收敛于一个最优值,而使用传统的SA-RACH方案的吞吐量最终会趋近于0。故解决了在信道容量有限的情况下吞吐量不足的问题。后期将会在D2D与M2M共存场景中分析随机接入碰撞问题。
