基于深度学习的SAR图像目标在地表环境中的检测与伪装效果评估技术
2022-12-02刘青顾乃威张学文卢卫建
刘青 顾乃威 张学文 卢卫建
(北京航天发射技术研究所,北京 100076)
0 引言
合成孔径雷达(Synthetic Aperture Radar, SAR)全天时全天候对重点目标和战备设施如装甲车、坦克、飞机、舰船、港口等进行成像,完成目标检测与识别并提供目标位置、类型信息,具备实时探测隐蔽和伪装目标的能力,在效果评估领域发挥一定作用[1]。
传统的地面目标SAR 图像检测是包含两个相对独立的过程,即目标特征提取与特征分类。在目标特征提取阶段,通过人工设计的算法把原始图像转换为某种特征向量;在特征分类阶段,采用机器学习中的分类器算法,比如支持向量机等,对特征向量进行分类,得出原始图像所属的类别。由于分类器的学习和特征的提取是分离的,对于图像识别来说,所提取特征与学习的分类器是次优的,分类器性能受限于所提取的特征的区分能力。
相比于传统人工设计手动提取特征,深度学习可以自动提取高层语义特征,具有更强的特征表示能力。深度学习不再把图像识别分为特征提取与特征分类两个独立步骤,而是把两者连接在一起,构成一个深层卷积神经网络,模型输入为图像,输出为图像的类别。直接对该模型进行有监督训练,把特征提取与特征分类耦合在一起联合学习,得到了更好的特征和更好的分类器,大幅度提高了分类精度。这种端到端学习方式,提高算法自动化程度,有效减少人工参与,解决了计算机视觉领域的很多难题,引起了整个图像识别领域的跨越式进展。图1展示了传统图像识别与现代图像识别流程。
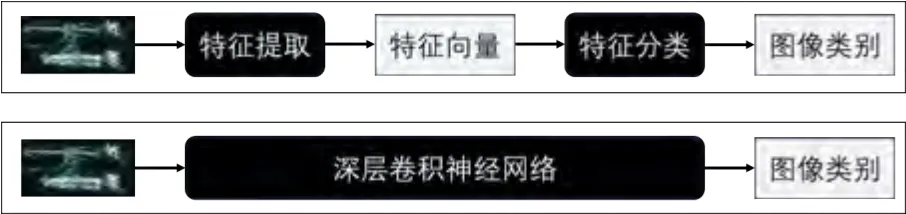
图1 图像识别方法:传统二阶段方法、深度学习端到端方法Fig.1 Image recognition method, traditional two-stage method、deep learning end-to-end method
1 伪装效果评估技术发展
伪装效果评估概念指的是是利用探测及识别方法对伪装前后的目标特性进行分析,查看经过伪装之后目标自身的暴露特征是否得以消除或降低。
传统的评估方法是采用野外实验的方法,对目标不同伪装状态进行高空/卫星拍摄成像,若干观察员对背景目标的图像进行读图判别,允许采用专业观测工具及方法,在有限时间内对目标所在位置和目标类型进行判断,结果以发现识别概率表示。该种方法能够获取目标真实数据,但是工作量大耗时长、受限于成像设备性能,并依赖于判读员的工作能力,往往用于武器装备最终的性能鉴定试验中。
为了缩短野外试验的时间和资源使用,美国构造了环境背景的地理数据库以及目标特征数据集,仿真生成全景模拟战场三维沙盘,能够部署军事目标、地形地物等信息,模拟设置战场中的迷彩巧装遮蔽,硝烟,假目标等多种伪装手段用进行性能评价,减少人力资源使用。但是该种仿真方法与真实目标背景的数据存在差异,影响评估结果。
近些年关于目标识别和性能评估集中在客观的图像解译领域,希望尽可能剔除判读过程中人的经验和知识,其中在SAR 图像目标检测算法中基于统计特性的算法研究最为广泛,该类方法是基于目标与背景间的灰度对比度来考虑的。主要包括全局阈值法[2]、恒虚警率检测法[3],广义似然比检测法[4]等。但是这些方法依赖于研究人员设计复杂算法来处理特征和致力于提高计算加速技术,无法通过人工设计算法全面提取目标数据。随着手动特征提取技术性能趋于饱和,该技术领域的发展在2010年之后达到缓慢瓶颈期。
随着人工智能等技术的快速发展,计算机自主学习能力和结果解释能力提升,2012年深度学习由于能够学习图像的鲁棒性和高层次特征,在全世界焕发生机[5]。2014年R.Girshick等人率先提出具有卷积神经网络特征的区域用于检测目标[6],这一年作为目标检测的分水领,彻底从传统手工特征提取转变为基于深度学习的特征提取,跨上新台阶。大规模图像数据集ImageNet的识别竞赛ILSVRC(ImageNet Large Scale Visual Recognition Chanllenge)是近年来机器视觉领域最具权威性的学术竞赛,代表了图像领域最高的水平,深度卷积神经网络(Deep Convolutional Neural Network,DCNN)在该项比赛中取得了远超其它传统方法的成绩,并且发展出了很多非常优秀的目标检测模型。YOLO(You Only Look Once)就是深度卷积神经网络的一种。2015年R.Joseph提出的深度学习第一个单级检测器YOLO[7],它将单个神经网络应用于整个图像,该网络将图像分割成多个区域,同时预测每个区域的边界框和概率。后来R.Joseph在第一版本基础上进行了多种改进,包括引入路径聚合网络、定义新的损失函数,并陆续形成了YOLO后续改进版v2[8],v3[9],该模型在保持了高检测速度的同时进一步提高了检测精度,兼顾检测效果与运行效率,在很多实际场合得到了广泛应用。
2 YOLO检测模型
YOLO的全图处理方式不同于穷举法和候选区优选法,它在测试阶段和训练阶段都是着眼于整幅图像,对包围框和类别的回归具有明显优点,与Fast-RCNN比较错误率下降了一半[10];其次YOLO速度非常快,它每秒钟能处理45帧图像,甚至都可用于实时检测系统,对于SAR图像较大、数据处理量较多的问题有很大的帮助[11]。最后YOLO的深度特征,泛化能力强,较之SAR图像使用的传统特征表述能力要强得多。□
2.1 YOLO-V3网络结构
YOLO V3是目前阶段综合性能最好的检测算法之一,在小目标的检测上取得了不错的结果,在科研界和工业界都有很好的应用和研究价值。本文采用YOLO系列第三个版本YOLO-V3作为检测模型。将输入图像分为S×S个单元格,每个单元格负责检测“落入”该单元格的对象,若某个物体的中心位置落到某个格子内,该格子负责检测出这个物体。每个格子输出B个包围盒bounding box信息,分别是坐标x,y,w,h以及类别概率,xy是边界框中心坐标w,h是边界框的宽高。YOLO-V3模型结构如图2所示。

图2 YOLO-V3网络结构图Fig.2 YOLO-V3 network structure diagram
该模型使用了三个不同尺度进行目标检测,图中绿色的三个层(第82、94、106层)是目标检测层,这三层的特征图大小分别是输入图像的1/32,1/16,1/8,这几个层的神经元感受野不同,第82层感受野最大,适合检测比较大目标,第106层感受野比较小,适合检测比较小目标。为了融合不同尺度的特征,网络第84层经过上采样之后,与第61层的特征图进行拼接,再经过若干卷积层之后,得到第94层检测层;第96层特征图经过上采样,与第36层特征图拼接融合,随后经过若干卷积之后得到第106层检测层。在这个设计中,将低层次(细粒度)特征与高层特征(粗粒度)融合,使得网络可以检测较小的目标。
原始YOLO-V3模型使用COCO数据集训练,每个网格设置9个参考包围盒。这些参考包围盒大小经过对COCO上的包围盒聚类得到,一共聚为9类。根据特征图的大小,分配到三个不同的检测层,每个检测层使用三种不同大小的包围盒,表1中列出了输入图像大小为416×416时,各个检测层的特征图大小,以及所分配的参考包围盒尺寸。
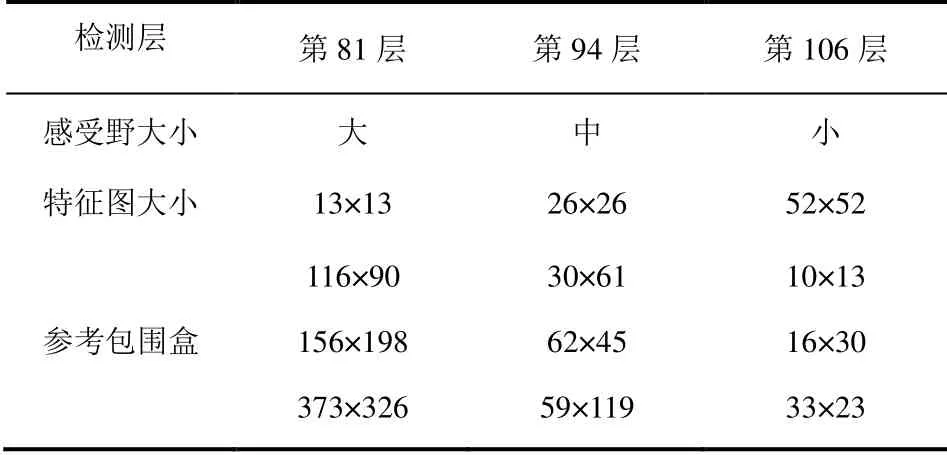
表1 YOLO-V3不同检测层的包围盒尺寸Table1 YOLO-V3 size of bounding box for different detection layers
本文目标的大小集中在60×60左右,因此,我们对模型做了修正:仅使用第94层检测目标,并且只设置一个参考包围盒,参考包围盒大小设置为60×60。经过改造之后,第94检测层每个网格只预测一个目标包围盒。
2.2 训练样本的标注
训练样本标注采用PASCAL VOC格式,每个目标位置用一个轴向包围盒表示。对每张训练图像,图中的每个目标都对应一个包围盒以及目标类别名称,标注信息都记录在一个xml文件中。图3展示了一个训练图像及其标注文件,图中有三个目标,在对应的标注文件中,记录了每个目标的类别名称以及包围盒坐标。

图3 目标检测训练样本的标注Fig.3 Labeling of target detection training samples
2.3 模型训练
在YOLO系列检测模型中,每个网格设置了B个参考包围盒,每个参考包围盒用于预测1个目标包围盒,因此一个网格的B个参考包围盒都是训练样本,但是每个样本的真实值需要根据标注信息确定:对第i个网格的第j个参考包围盒,在所有中心位于该网格的真实包围盒中,选取与的交并比最大的分配给作为真实值;如果一个参考包围盒没有被分配真实值,那么该包围盒用于预测背景。
3 地面目标检测与伪装效果评估
3.1 构建训练样本
采用美国桑迪亚国家实验室数据MSTAR (Moving and Stationary Target Recognition),该数据集共有8类不同军事车辆目标切片,包含自行榴弹炮、装甲车、运输车、坦克等,每个目标约570幅图像,分辨率为54×54到178×178不等。除此之外,还包含100幅不同场景SAR图像,分辨率为1784×1476,如图4所示。

图4 MSTAR中的8类地面目标和环境背景SAR图像Fig.4 Eight kinds of ground target and environment background sar images in MSTAR
为得到检测器的训练样本,采用数据融合技术将上述背景图像和目标图像合成训练图像样本。数据融合包括原始数据级融合、特征级融合和决策级融合[12]。本次选取特征级数据进行匹配,以混合前后图像的亮度直方图的分布一致性作为融合衡量标准。
随机选取一幅背景图像,根据YOLO模型支持输入的图像分辨率从中随机裁剪出一个416×416大小的子图,然后从目标集合中随机选取若干个图像,并把这些目标图像粘贴到背景图像中的随机位置上。由于背景图像与目标图像的成像条件不同,两者之间存在亮度差异,直接把 目标图像粘贴到背景图像中,粘贴区域与背景之间的区域边缘非常明显,目标不能融入到背景中,容易造成过拟合。因此采用加权融合,根据背景图像的亮度模式对目标图像进行亮度修正,使得两者亮度分布比较一致。
目标图像与背景图像的融合算法如下:假设目标图像为Q,我们从背景图像上对应的融合区域截取出一块与Q同样大小的图像块P。然后用P作为参考图像,对Q做直方图匹配,使得Q的亮度分布与P接近一致。然后,构造一个与Q同样大小的高斯权值图像W,用W对两者进行融合,得到融合后的图像R:

其中权值


图5 图像融合权值 Fig.5 Image fusion weight
图6 展示了一个背景图像块P,目标图像块Q,直方图匹配之后的目标图像块以及融合的结果。可以看到经过处理之后,目标区域与背景区域的亮度分布比较接近。自左至右依次为:背景图像P,目标图像Q,直方图匹配之后的目标图像,两者融合的结果。
图7展示了图6中四个图像块的直方图,可以看出,经过上述处理之后,融合结果的直方图(最右)与原始背景图像块的直方图(最左)比较接近。自左至右依次为图6中对应图像的直方图,当原始图像块内部亮度非常均匀时,直方图呈明显的尖峰分布,不宜用直方图匹配方法修改目标图像块的整体亮度;当原始图像块内部亮度非常低时,融合目标图像块之后,该区域出现明显的亮斑,目标与背景对比明显,形成容易区分的样本;另一方面,如果原始图像块内部亮度范围比较宽(亮度方差大),不适宜放置目标。为了避免出现这些情况,在合成样本时,首先要对合成区域的平均亮度和亮度方差进行限制,当平均亮度低于0.1,亮度标准差低于0.1或者高于0.2时,放弃合成。这样可以使得合成的目标出现在有一定纹理的背景区域。

图6 目标图像融合效果Fig.6 Target image fusion effect

图7 亮度直方图对比Fig.7 Brightness histogram comparison
图8 对比不同方法得到的训练样本图像,其中:左上角是原始背景图像;右上角是直接把目标图像粘贴到背景图像之后的结果,很明显这种合成方式得到的图像中目标区域与背景区域亮度差异非常大;左下角是把直方图匹配之后的目标直接粘贴到背景图结果,效果明显变好,但是目标左上角区域仍然有一些亮斑是目标图像中的背景噪声;右下角是对直方图匹配之后的目标图像与原图进行加权融合的结果,这个结果中,目标左上角的背景噪声基本去掉了,目标与背景融合的比较自然真实。

图8 不同方法得到的样本图像Fig.8 Sample image obtained by different methods
由于数据集中的目标图像中,目标所占的区域很小,图像背景区域比较大,为了更紧凑的检测目标区域,本文在合成过程中,对分辨率超过64×64的样本,截取其中心位置的64×64区域融合到背景图像中。因此,训练样本中目标的包围盒大小约为60×60。
采用上述方法合成了1326个样本,每个样本中包含1~6个目标。从中随机选取1000个样本用于训练,其余的326个用于评测。图9显示了部分生成样本,其中红色包围盒是自动计算的标注框。

图9 合成样本与标框Fig.9 Composite sample and label box
3.2 卷积层目标响应
输入学习训练图像和反馈传递中卷积层是最重要的环节,卷积层中有非常多神经元,每个神经元是能够对某种特征敏感的提取器,当图像中出现某种特征的时候,对其敏感神经元就会呈现激活状态。为了解内部如何对背景与目标进行区分,采用可视化工具,选取第三个卷积层第22、44以及205个神经元对三幅图像响应进行特征可视化操作,如图10所示。图10分别表示原图(第1行)、第22层(第2行)、第44层(第3行)、第205层(第4行),其中在第三层的卷积上的第22、44个神经元对目标产生了很强响应,而对背景进行了忽略,第205个神经元主要是对树木背景区域产生强响应。这表明,不同的神经元能够对图像中不同物体进行响应,这就是后期进行目标和背景分离的基础。
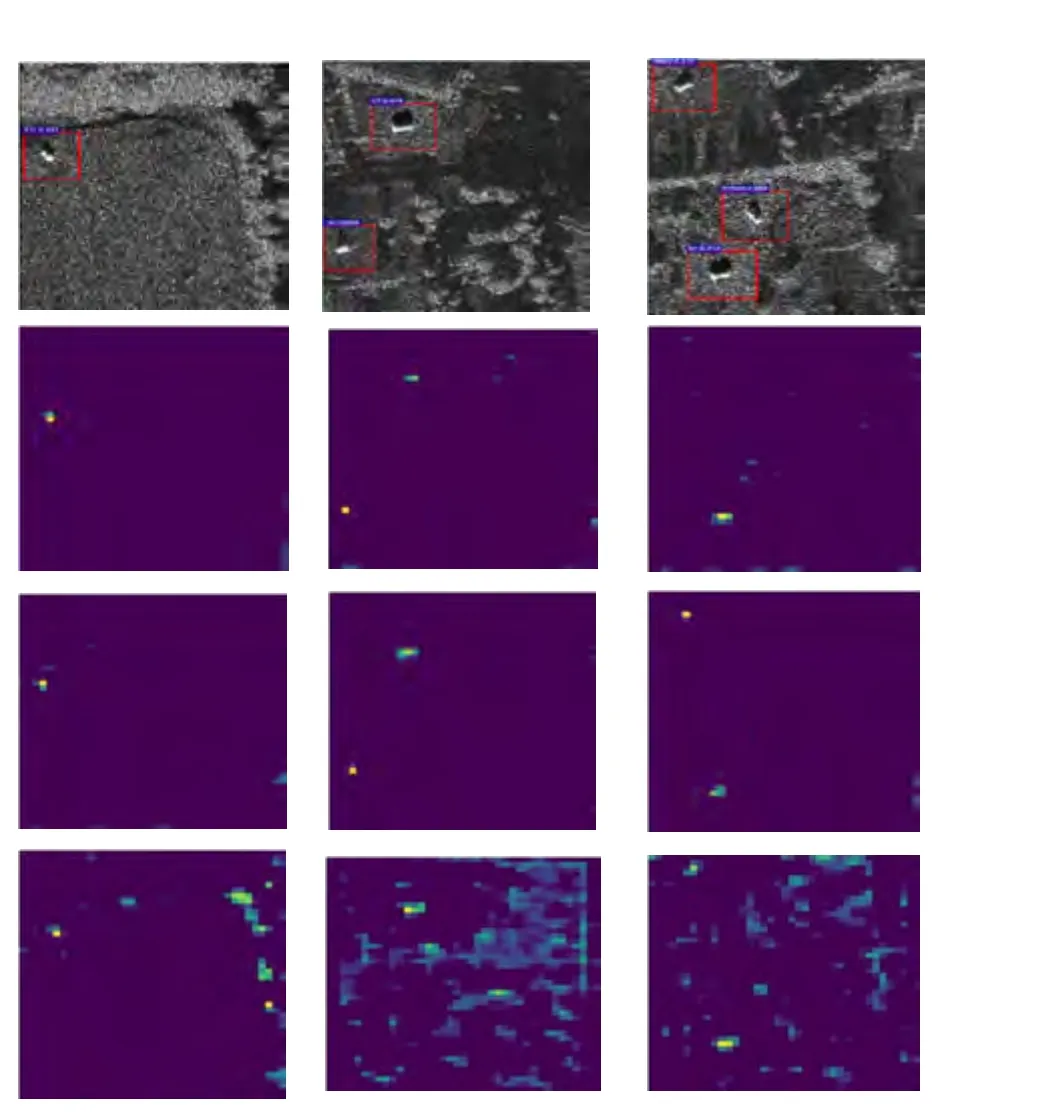
图10 卷积神经元响应Fig.10 Convolution neuron response
3.3 试验结果
目标识别认为算法能够找出目标所在位置并对类型识别正确,也就是说能够区分地面目标和背景特征,同时还能区分不同目标之间的特征。采用YOLO模型训练之后,测试集平均精度为97.87%,8种不同类别目标精度如表8所示。
在机器学习中,标注样本产生的噪声引入数据误差、学习样本的多样性、预训练模型对框架的影响等会影响识别准确性。上述测试结果相比于其它模型数据,SSD检测精度为95.36%[13],FCNN检测精度为96.51%[13],YOLO的检测模型具有很好的检测性能,用来评价伪装效果。

表2 8种不同类别目标的精度Table2 Accuracy of eight different types of targets

图11 MSTAR目标检测结果实例Fig.11 MSTAR example of target detection results
3.4 伪装效果评估
机器学习技术对原型样本训练检测和识别,以此算法作为基准,再测试伪装样本,通过检测和识别的结果变化来评价伪装效果。原型样本(即训练样本)与伪装样本(即测试样本)存在明显的差异,两者的概率分布不同,存在分布漂移,即不满足统计机器学习中的基本假设:独立同分布假设(Independent Identical Distribution, IID)。在这种情况下,机器学习模型的推广能力没有理论保障,在发生了分布漂移的测试集上,其性能会下降。由于算法的其它条件没有变化时,那么在测试数据上出现一致性的识别性能下降问题,可认为是测试数据与训练数据之间不满足前述IID假设,即测试数据与训练数据之间存在系统性的偏差。该偏差的产生是由于目标伪装前后样本的差异欺骗了算法,引起算法得出检测概率较低的预测结果甚至是错误的结果,这种性能下降的程度就可以反映出了目标伪装性能的优劣。本文就是应用IID假设来评价伪装效果。
模拟目标采用雷达吸波材料的隐身效果,降低雷达接收器接收到反射波能量。模拟方法为:在融合目标和背景时,把目标图像的像素权值随机降低,使得目标像素的最大权值在0.5~0.8范围内,因此,伪装图像中目标的亮度比较低,象征着雷达接收到的反射波比较弱。随机生成86幅原型样本图像和86张伪装样本图像,每一张图像之间目标的位置、数量以及种类都相同,区别仅在于融合权值不一样。图12显示了原型样本(左)与伪装样本(右)的对比效果。
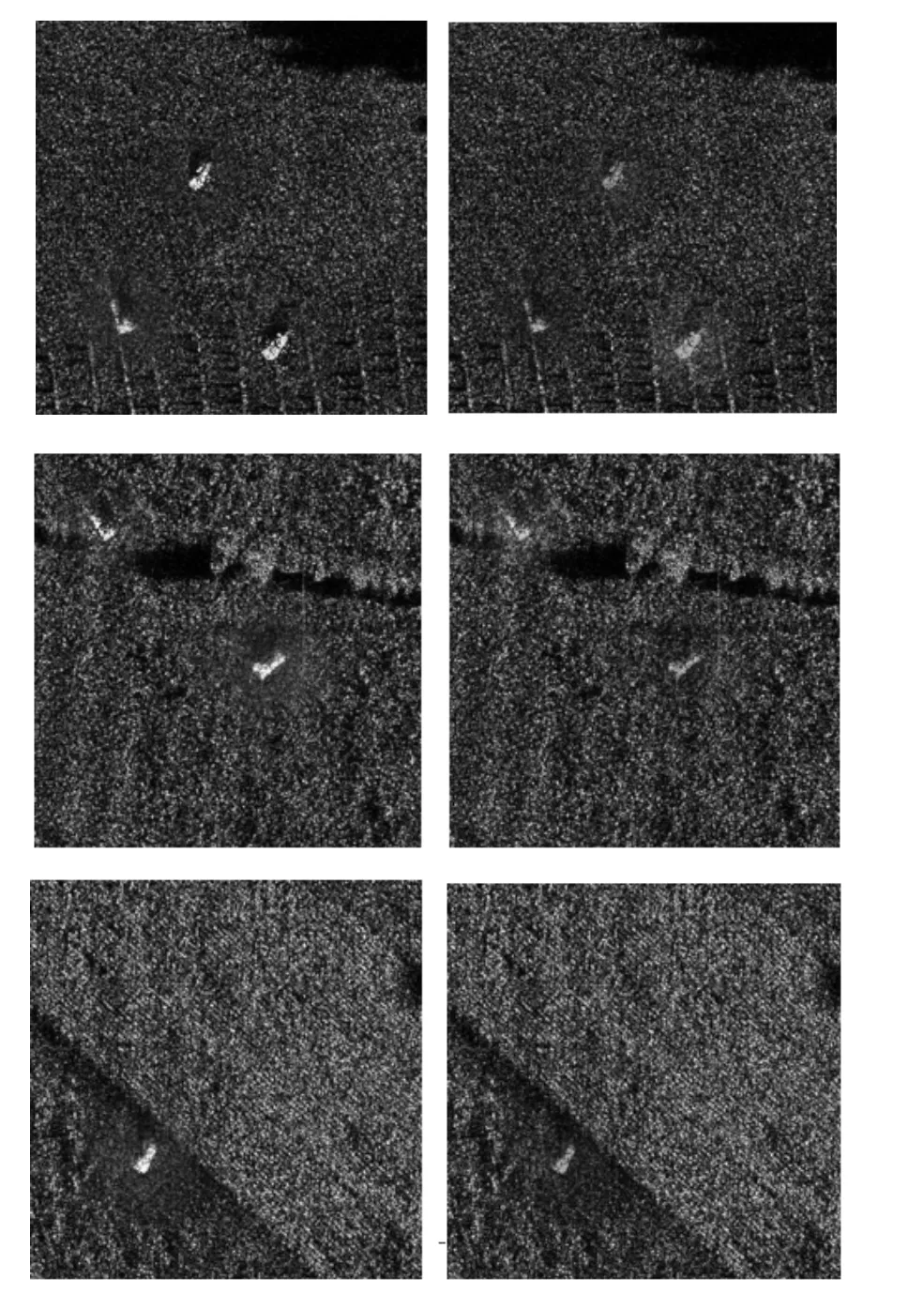
图12 原型样本和伪装样本Fig.12 Prototype sample and camouflage sample
准确率是正确结果占总样本的百分比,也叫做查准率;召回率是实际为正确的样本中被预测为正确样本的概率,也叫做查全率。准确率和召回率取值在0和1之间,数值越接近1,检测效果越好。表3和表4分别统计了每个类别的准确率(Precision,P)和召回率(Recall,R)。伪装样本比原型样本的两个指标均有明显下降,根据独立同分布假设的意义,这种数值下降是伪装性能带来的目标识别偏差。

表3 伪装样本与原型样本的检测准确率PTable 3 Detection accuracy of camouflage samples and prototype samples

表4 伪装样本和原型样本的检测召回率RTable 4 Detection recall rate of camouflage samples and prototype samples
图13所示的是一个样本的伪装前后检测结果对比,其中一个目标(中间目标,真实类别为ZIL13)伪装之后被误检为其它目标(BTR_60),对于这个目标来说,它的伪装度为1;另两个目标的置信度均有所下降,但是下降幅度很小,这两个目标的伪装程度接近0。

图13 伪装前后检测结果对比Fig.13 Comparison of detection results before and after camouflage
表5统计了伪装样本与原型样本中各类目标平均检测精度,可以看出几乎所有类别上,伪装样本的精度均低于原型样本,表明伪装之后,检测器正确检测并识别出目标的难度变大。由于两种样本中目标的位置、类别、背景都是相同的,唯一区别在于伪装样本中模拟了雷达接收信号变弱,因此,这种检测精度降低的唯一原因在于目标经过了伪装,并且起到了一定的伪装效果。

表5 伪装样本与原型样本的检测精度Table 5 Detection precision of camouflage samples and prototype samples
对伪装进行量化评价,我们定义伪装程度为:
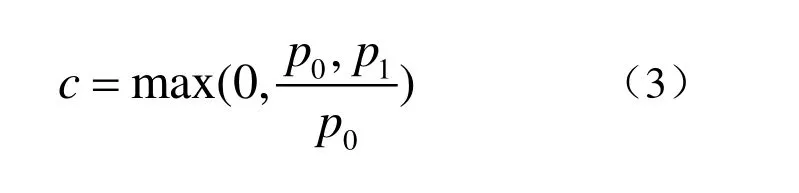
其中,01,pp分别为伪装前后目标检测器对该目标输出的正确类别的检测概率。
假设某个目标的真实类别是D7,伪装前,目标检测器输出该目标为D7的概率为0.9,伪装后检测器输出改目标为D7的概率为0.5,那么对该目标的本次伪装的程度为0.44。
对多个目标都进行同样的伪装,可以测出每个目标的伪装程度,这些目标的平均伪装程度可以用来衡量伪装的伪装效果。本文中使用的86幅图像中,一共有179个目标,通过计算每个目标的伪装程度,得出本次实验所用的伪装方式的伪装效果为49.7%。
4 结论
本文研究了基于深度学习的自动目标识别技术,采用了YOLO系列第三个版本YOLO-V3作为检测模型,该检测算法属于判别式算法,这类算法试图从训练样本中找到最适于区分不同类别的特征,对目标类型做出准确判断。针对合成孔径雷达图像的地面目标的检测识别,图像数据集采用真实雷达SAR图像,并用灰度融合方式得到了背景目标融合图像,比训练单目标图或仿真模拟图像更具准确性。最后利用独立同分布假设的识别性能下降理论来评价伪装效果,通过用原型样本来训练检测算法,以此算法作为基准,伪装样本与之存在明显差异,通过比较检测概率的数值关系得出伪装效果。
