基于语料库的翻译汉语欧化现象分析
——以《心是孤独的猎手》为例
2022-12-02时健,李芬
时 健,李 芬
(西安科技大学 人文与外国语学院,西安710600)
一、引言
欧化是指传统汉语的词汇、语法、句法等受到欧洲语言的影响而发生的变化[1]。刁晏斌认为,欧化汉语是指中国人学习直接或间接传来的欧洲语言,在汉语中除旧布新,并留下痕迹而形成的语言形式[2]。欧化既指通过模仿和移植而产生的新型语法结构和句法形式,亦指汉语中罕见的语法形式由于受到印欧语言的推动和刺激而得到迅速发展的现象[3]。谢辉提出“翻译引发的过度或明显的欧化汉语实质上是一种中介语”[4]。蒋跃和马瑞敏通过计量语言学手段证实了翻译语言在组句方式和句子-小句动态关系方面既非源语也非目标原创语,是第三语码[5]。作为独立存在的第三语码,翻译汉语是一种处于英汉语之间的中介语连续统(continuum)。如果译者过多受到源语的束缚,则译语英语化倾向显著,即“洋腔洋调”式的欧化程度严重。
欧化汉语对汉语纯洁性的不良影响一直是国内的重点研究对象。余光中从英汉两种语言的差异出发,分析了当代人笔下白话文的西化之病[6]。谢耀基对词法和句法方面的欧化特征进行概述,并从语言因素和社会因素的角度对其成因进行了解释[7]。朱一凡引用大量数据分析阐述了翻译汉语语言特征的研究现状,表明基于语料库的方法是近年来翻译汉语研究的进路[8]。语料库翻译学是指利用语料库工具,在对翻译文本中的语言现象进行数据统计的基础上,系统分析翻译本质和翻译过程的研究[9],其具有“可信度高”和“客观性强”的特点,为翻译汉语的欧化现象研究提供了全新的视角。巩雪先和黄立波通过对比分析原创汉语和翻译汉语,分别探讨了翻译汉语中“人称代词+的”结构[10]和句首介词“在”[11]的欧化用法及其成因。邵莉基于历时语料库,考察了鲁迅小说译作中代词、量词、介词、连词等典型欧化词汇[12]。先前研究大多通过对比分析原创汉语语料库和翻译汉语语料库来描写翻译汉语的语体特征,而就不同译者对同一小说的汉译本的欧化程度差异探讨较少。
本文以短篇小说《心是孤独的猎手》的多译本为研究对象。该小说是美国南方文学代表作家卡森·麦卡勒斯的长篇处女作,讲述了主人公聋哑人辛格和四个次要人物之间悲惨的孤独故事。目前对该作品的研究主要从精神隔绝[13]、阈限空间[14]、孤独主题[15]等角度展开。王力曾指出,翻译是欧化的来源,译作最易欧化,译者顺着原文词序比较省力[16]。《心是孤独的猎手》国内译本众多,在其汉译过程中难免出现欧化现象,但鲜见有人研究该小说不同汉译本中的欧化语言现象,基于语料库的量化分析更是稀缺。
鉴于此,本文选取陈笑黎、楼武挺和秦传安的汉译文本,自建微型语料库,并以国家语委现代汉语语料库(下文简称“国语委”)和兰卡斯特汉语语料库(The Lancaster Corpus of Mandarin Chinese,下文简称LCMC)为参照来揭示三个译本的欧化程度及其差异的成因。
二、研究设计
(一)研究问题
本研究旨在回答以下几个问题:
1.《心是孤独的猎手》三个译本的欧化程度如何?导致其欧化程度差异的成因是什么?
2.如何基于语料库方法定量评估翻译汉语的欧化程度?哪些指标能合理评估欧化现象?
3.对译本欧化程度的定量评估能得到哪些启示?译者能否从定量评估中获益?
(二)研究方法
本文采用基于语料库的定量和定性相结合方法对《心是孤独的猎手》三个汉译本中的欧化现象进行对比分析。
定量分析是指通过软件WordSmith和AntConc检索出三个译本中欧化汉语出现的频率,并与LCMC和国语委的参数对照,结果以图表呈现。总的研究步骤分为两部分,详见图1。

图1 欧化现象定量分析研究流程图
1.语料库建设
本文的研究对象为小说《心是孤独的猎手》的三个译本。首先将扫描后的图像文件进行OCR识别,将电子译本转换为纯文本格式txt,运用EditPlus和Emeditor清洗文本,矫正错别字,清除乱码和冗余信息以降噪。然后利用“语料库在线”这一线上分词系统对译本进行分词和词性标注,并进行人工校对。由陈笑黎、楼武挺和秦传安分别翻译的三个译本的微型语料库就此建立。另外,为了更客观地反映翻译汉语与原创汉语之间的差异,本文引入LCMC和国语委作为参照库。
2.数据统计和分析
首先利用语料库检索软件WordSmith统计三个译本的类符/形符比和高频词,分析各译本的词汇丰富度和用词偏好,然后使用AntConc统计指定词频率、平均句长和句段长以及指定句式结构频率,分析连接词、数量词、句法总体特征以及典型句式结构的欧化程度。
定性分析是基于具体译例探讨陈笑黎、楼武挺和秦传安三个译本中的欧化现象,并从认知翻译学的译者主体性理论视角探讨三个译本欧化程度差异的原因。
三、数据分析
(一)词汇总体特征
1.标准类符/形符比
在语料库翻译学中,类符/形符比(Type/Token Ratio,TTR)是用来反映文本中词汇应用变化性的指标,即词汇丰富度。类符指文本中出现的不同词汇种类数,形符指文本的总词数。一般来说,TTR越高,词汇应用的变化性越高,反之越低[17]。然而,简单计算TTR会受到语料库库容和功能词重复次数的直接影响,统计结果不具备普适性,所以Scott提出标准类符/形符比(Standardized Type/Token Ratio,STTR)来衡量词汇应用的变化性,也就是文本中每千词的类符/形符比[18]。本文利用软件Wordsmith4.0分析得出三个译本的类符/形符以及标准类符/形符比,结果见表1。

表1 各语料库的标准类符/形符比
由表1可见,三个译本的标准类符/形符比相差不大,却都高于参照库LCMC。连淑能指出在英语等印欧语言中,句子之间的逻辑关系往往是用连接词如if,though,because等虚词来明确地表示,即主要采用形合法造句[19]。然而汉语并不用连接词显化地表明其相互关系,而是通过句子本身的意涵来体现,即主要采用意合法来造句。一般来说,连词、代词等虚词的使用频率越低的译本,其标准类符/形符比越高,欧化程度也就越低。就三个译本比较而言,楼译本的标准类符/形符相对较高,说明楼译本倾向于选择使用不同的词汇表达意义相近的原文,词汇应用的变化性较高,欧化程度较低。
2.高频词
译本中高频词的使用能够反映出译者的用词偏好。本文通过WordSmith 4.0检索得到三个译本的高频词汇表。本节选取位居前10的高频词进行分析,结果见表2和图2。
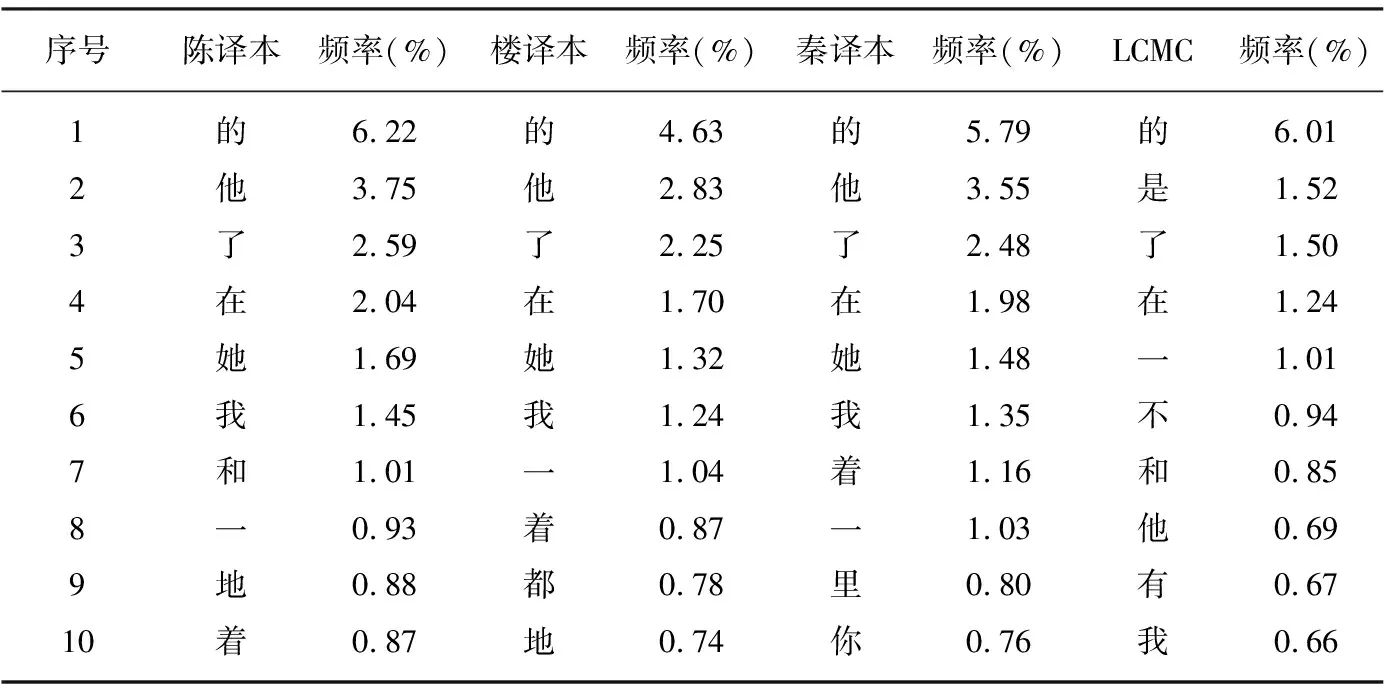
表2 各语料库前10位高频词

图2 三译本前10位高频词使用频率与其在LCMC中使用频率对比
从表2可知,三个译本和LCMC词表中排名前10的为“的、他、了、在、她、我、一、着、地、和”等单字词。其中结构助词“的”在四个词表中均位列第一;三译本词表前6的词更是完全一致,只是出现频率略有差异。此外,本文发现,人称代词在各个译本前6位的高频词中的占比达50%,分别是“他、她、我”,其中第三人称代词“他”高居第二位,且三个译本中人称代词的频率都显著高于LCMC。但是在LCMC前6位的高频词中并没有出现人称代词,说明三个译本中人称代词的使用频率明显高于现代汉语,这印证了秦洪武和王克非关于翻译汉语较原创汉语更高频地使用第一、第三人称代词的观点[20]。
王力认为现代汉语中第三人称代词三分是代词形式欧化的结果[21]。由于英语具有阳性、阴性、中性之分,所以原本不分性别的“他”衍生出了“她”和“它”。英语习惯用代词来回指前面提到的人或事物,但汉语往往通过省略主语、重复名词等方式来指代前文提及的内容。在翻译作品时,译者会受到英语原著行文措辞的影响。三个译本“他”和“她”的使用频率分别为5.44%、4.15%、5.03%,说明陈、秦译本对人称代词的使用高于楼译本,在人称代词的使用上,陈、秦译本的欧化程度高于楼译本。
(二)典型词类
1.连接词
余光中指出,在进行中文写作时,见“when”就“当”,五步一当,十步一当,当当不绝的现象极为突出[6]。“当……之后”、“当……的时候”一类的副词子句,已经滥于中文。柯飞对双语对应平行语料库中时间连词词组的使用频率的研究结果也表明“当……时”在翻译汉语中的使用频率要远远高于原创汉语[22]。因此“when”作连词引导状语从句时若不假思索地翻译成“当……”,这种情况可以视作典型的欧化现象。原文中“when”的出现次数为447次。通过AntConc的检索统计,发现三个译本中“when”处理成“当……时”的译法次数分别为:陈译本33次,楼译本3次,秦译本204次。可见,楼译本中“当……”的使用频率远低于陈、秦译本,在“当……”的使用上,楼译本的欧化程度最低,而秦译本则将几乎一半的“when”以欧化的形式进行了处理。
例1:Antonapoulos looked beneath all the tissue papers in the boxes very carefully.Whenhe saw that nothing good to eat had been concealed there, he dumped the gifts disdainfully on his bed and did not bother with them anymore.
楼译本:安东纳普洛斯十分仔细地查看盒子里的包装纸,发现下面并没有藏着好吃的后,便不屑地把礼物扔到床上,再也懒得搭理了。
陈译本:安东尼帕罗斯仔细地检查盒子里的包装纸,当他发现包装纸下面并没有藏着好吃的东西,不屑地将礼物一古脑地倒在床上,再也不看它们了。
秦译本:安东尼帕罗斯非常仔细地检查了盒子里所有包装纸的底下。当他看到并没有什么好吃的东西藏在里面时便轻蔑地把礼物倾倒在床上再也不理睬它们。
例1是辛格带着礼物去看望他的好友安东尼帕罗斯时发生的情景。陈译本、秦译本在处理这个句子时,都使用了“当”这个词,译文略显僵硬。秦译本更是受到原文结构的影响,采用逐字转换的直译且没有断句,欧化现象突出。楼译本则抛开字面的束缚,按照主语安东尼帕罗斯行动的顺序层层揭示原文的意义。前文已说明安东尼帕罗斯是个吃货,因此该句想表达他没看见好吃的东西后失望的表现。楼译本对该动作的描写如行云流水,在读者脑中呈现的画面更为生动,完美地传达了原文意义。
2.数量词
谢耀基指出,根据汉语的使用习惯,没有强调数目需要时就不用量词;且在中世纪以后,如果量词前面的数字是“一”,这个“一”字通常也会省略不用[23]。因此汉语中“一+量词”结构的出现频率理应比较低。但随着汉语的发展,现代汉语开始习惯在数词之后使用量词,有形的事物用“个”,无形的事物用“种”。王力认为汉语中“一”、“一个”和“一种”的表达是受到英语中不定冠词“a/an”的影响而产生的欧化现象[24]。因为“a/an”具有“一”的数量含义,译者往往将“a/an+名词”的结构翻译成“一+量词”结构。本文用AntConc对各语料库中“一个”和“一种”进行词频统计,同时根据公式:
相对偏差=(实际值-参考值)/参考值
计算出三译本中“一个”和“一种”词频相对国语委语料库的偏差,结果如表3和图2所示。

表3 各语料库“一个”和“一种”词频
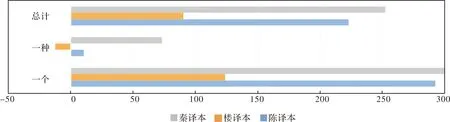
图3 三个译本中“一个”和“一种”词频相对国语委语料库的偏差
李颖玉对国语委库的2000万字进行了统计,结果显示“一个”和“一种”的词频分别为15.17和4.97,即不定冠词出现的总频次为20.14[25]。由表3可见,陈、楼和秦译本中“一个”和“一种”的总频次分别为65.03、38.34和70.97,均远高于参照库国语委(相对偏差分别为222.89%,90.37%,252.38%),说明三个译本都受到了英语不定冠词不同程度的影响。但值得一提的是,楼译本中“一种”的词频甚至低于国语委语料库的参考值。另外,相对于陈、秦译本,楼译本中“一个”和“一种”的词频远远较低,说明楼武挺为了更加照顾目的语读者的语言表达习惯而采用了归化策略,因而较少使用“一+量词”的用法,而其他两个译本在不定冠词的处理上这两个译本采用了更加忠实于原文而非目的语的异化策略,从而欧化现象严重。
(三)句法总体特征
王力曾指出句子的延长是欧化最明显的特征[24]。平均句长是指文本中句子的平均长度,其计算是以总的形符数除以句点标记的个数而得出的。而句段是指语句中由句段标记隔开的短句或短语,因此平均句段长的计算是用总形符数除以句段标记的总个数得出的。在本研究中,汉语句子的分隔标记为句号、问号、感叹号;汉语句段的分隔标记为句号、问号、感叹号、逗号、分号和冒号。用AntConc对三个译本和原文分别检索统计,结果如表4所示。

表4 各语料库的句法总体特征
翻译汉语受源语影响平均句长和句段长都明显高于原创汉语[20]。徐欣认为这一现象是由于作为源语的英语中存在大量长句,译者作为一个语言习得者在对英语长期、大量的接受过程中受到长句表达方式和语言思维模式的影响,逐渐习惯性地以“长句长译”为策略进行翻译实践[26]。但从表4可见,三个译本的平均句长均低于LCMC,却与原文相近,这与以往的研究结果相悖,可能因为原文中人物之间的对话出现频率高,句子简短,即源语本身句段就短,因此翻译语言特征不明显。然而,秦译本的平均句段长远高于其他译本和参照库,且平均句段长约等于平均句长。在统计过程中,本文发现秦译本即使在原文以逗号结尾的位置也使用句号或者不断句,几乎通篇以句号断句,句子读来冗长拖拉,欧化现象突出。
例2:In the town there were two mutes, and they were always together.Early every morning they would come out from the house where they lived and walk arm in arm down the street to work.
陈译本:镇上有两个哑巴,他们总是在一起。每天清早,他们从住所出来,手挽手地走在去上班的路上。
楼译本:镇上有一对总是形影不离的哑巴。每天清晨,他俩走出住处,手挽手,步行去上班。
秦译本:镇上有两个哑巴他们总在一起。每天一大早两个人就从他们住的那幢房子里出来手挽手走到大街上去上班。
英语是右分枝结构语言(right-branched),句子呈现末端开放的递归(recursion)特征,其修饰语、插入语可以后置,又有关系词与被修饰语连接,从句之间层层环扣,可以不断扩展句子的结构容量,因此英语句子总是显得复杂且冗长。汉语是左分枝结构语言(left-branched),句子呈现首端开放的递归特征。句首虽可开放,向左伸展,但扩展的长度和程度受到种种限制,因此中文句子往往短小精悍[19]。例2中陈、楼译本均按照意群划分句子,用独立的短句进行翻译。而秦译本则局限于原文结构,将定语从句以前置的方式翻译出来且没有断句,是典型的欧化翻译。由此可见,在句段长度方面,秦译本的欧化程度最高。
(四)典型句式结构
1.“被”字结构
“被动”在汉语中只是一个语义概念,没有严格的形式标记,而“被动句”是西方语法中的一个重要概念。汉语被动句主要有两种形式:第一种是不加标记的被动句,可以从语义和思想的角度来理解句子的被动意义;第二种是带标记的常规被动句,常用标记词有“被”、“受”、“为”、“使”等。这种被动句通常也被称为“被”字结构。余光中指出中文西化最触目、最刺耳的现象就是被动语气[6]。谢耀基也认为句式欧化最明显的特征是表示被动的“被”字句的普遍使用[7]。因此本文用AntConc检索统计带标记词“被”字结构的使用情况,以此来考察三个译本在句法层面的欧化程度,结果见表5。

表5 各语料库“被”字结构的使用
李颖玉对国语委库“被”字结构的出现频率和每百万字词频进行了统计,本文选取每百万字词频673作为参考值(国语委“被”字结构的出现频率如此之大是由于该语料库的字词数巨大,约两千万)[25]。对比发现三个译本中“被”字结构每百万字词频远远高于原创汉语,甚至达到了近三倍。这表明译者为了忠实于原文,保留了原文的句式结构,从而导致了欧化现象。如表5所示,陈、楼和秦译本中“被”字结构的使用频率分别为223次、190次、225次,可见陈、秦译本在“被”字结构的使用上,欧化程度相似,而楼译本在翻译被动语态时处理灵活,适当减少了“被”字结构的使用,欧化程度较低。
例3:That is the way Marx says all of the natural resources shouldbeowned—notbyone group of rich people butbyall the workers of the world as a whole.
陈译本:这就是马克思说的所有天然资源应该被占有的方式——不是被一群富人而是被世界上一切劳动者集体来占有。
楼译本:这便是马克思所说的自然资源应有的占有方式——并非属于一群富人,而是属于全世界所有劳动者。
秦译本:马克思说所有自然资源也应当以这种方式拥有——不是被一群富人所拥有而是被作为整体的全世界一切劳动者所拥有。
例3中出现了被动结构“be owned by”,陈、秦译本分别将其翻译成了“被……来占有”和“被……所拥有”,被动标记显化倾向严重。虽然满足了“信”的要求,但译文略显僵硬,失去了“雅”的意韵。楼译本则化被动为主动,将其译成“属于”,译文自然地道,更加符合目的语读者的语用习惯。
2.“如此……以至于”结构
秦洪武和王克非对用来表示程度深的“so...that”结构在汉语译文中对应句式的研究发现,与英语so...that对应的五类结构使用的对应词有前对应词“如此、非常、太、实在”等,后对应词“以致、因此、所以、结果、以便”等,前后对应词“如此……以致、非常……于是、实在……以致、很……所以、太……所以”等[27]。然而,英语学习者或者部分翻译者在翻译该结构时第一反应往往是汉语的“如此……以至于”组合,因此这一组合的滥用带来了不少欧化翻译。本文用AntConc分别检索统计“以至于”和“如此……以至于”在各译本中的使用情况,结果显示“以至于”在陈、楼、秦译本中的使用频率分别为6次、0次和70次;“如此…...以至于”结构的使用频率分别为3次、0次和8次。由此可见,楼译本中没有出现“以至于”的用法,秦译本则大量使用该译法,欧化程度较高。
例4:Then in late June there was a sudden happeningsoimportantthatit changed everything.
陈译本:六月下旬,发生了一件突然的事,它如此重要,以至于改变了一切。
楼译本:然后,六月末突然发生了一件大事,一切都随之改变。
秦译本:六月底突然发生了一件重要的事以至于改变了一切。
英语是形合语言,汉语是意合语言。英语为了强调前文所述事实的程度之深时,往往会使用“so...that”的结构,但汉语有时单靠其意合特性也能表强调意义。例4中陈、秦译本采用直译法,将“so...that”与“如此......以至于”一一对应,没有考虑到目的语读者的语用习惯,显得生硬刻板。楼译本则采用句法结构转换译法,有效改善译文的同时增加了译语的丰富度。
四、讨论
(一)欧化指标整体评估
本文从词汇和句法两个维度出发,分别考察了《心是孤独的猎手》三个译本的词汇总体特征、典型欧化词类、句法总体特征以及典型句式结构。本节首先对前文的数据统计进行总结和量化评估,并列出了这些指标相对于参考值的偏差,同时根据公式
评分= 90相对偏差20
给出评分,如表6所示。
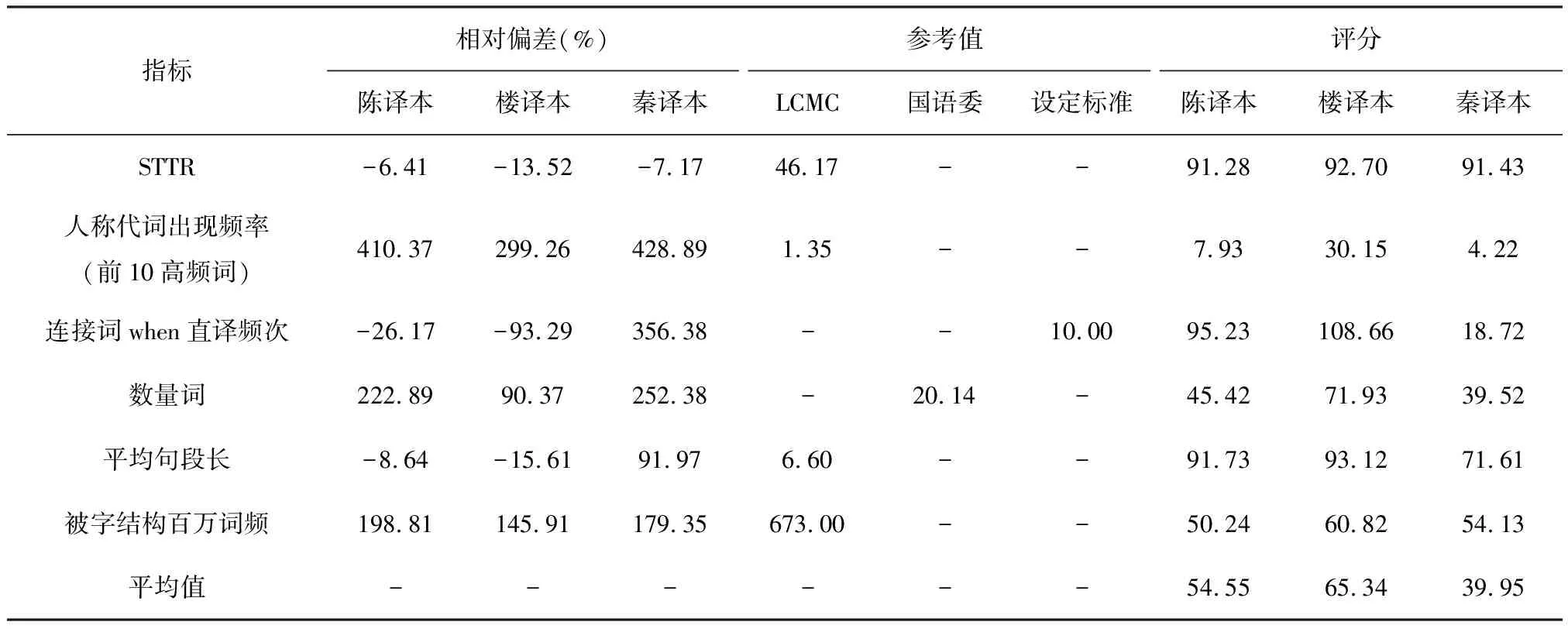
表6 三译本欧化指标的整体评估
从上述评分公式易看出,对参考值的评分设定为90,且评分越高代表欧化程度越低。如表6所示,三译本的评分均远低于90,说明三个译本均具有很大的改进空间。而陈译本、楼译本和秦译本的平均值分别为54.55、65.34和39.95。说明楼译本的欧化程度最低,而秦译本的欧化现象最严重。
(二)欧化程度差异的认知成因
翻译是以现实体验为背景的认知主体将一种语言映射转述成另一种语言的认知活动[28]。作为翻译活动的认知主体,译者与原文文本、原文作者和译文读者之间有一定的互动关系。麦卡勒斯在《心是孤独的猎手》中较少用生僻词汇,句式也十分简单。译者在与原文文本互动的过程中,必然会受到原文文本的影响。本文通过分析高频欧化结构对应的原文文本发现,秦译本中长句对应的原文结构特点往往是:句子结构复杂,多数带有表示时间、地点等较长的后置修饰成分。这表明秦传安在与译文读者进行互动时,选择忠于原文,保持原小说的完整性和真实性,以求最大限度的传达原文作者想要表达的意思。因此他采用了直译和异化的翻译策略,从而导致欧化译文频现。然而,从认知翻译学来看,译者的思维具有创造性,也就是说译者在翻译过程中会发挥其主观能动性。但由于不同译者的文化背景和所处的社会环境不同,再加上个人语言水平差异,他们的认知方式和能力也会有所差别,从而影响到原文文本社会文化信息的传递以及作者精神文化层面的再现。例如,在本研究中,陈译本和楼译本均克服了原文文本的干扰,对译文进行重构和变换,充分考虑到读者的认知习惯和接受度等问题,因此选择了意译和归化的翻译策略,降低了译本的欧化程度。
此外,谭业升提出,运用认知翻译学研究某个具体翻译问题时,要善于结合人文解释方法考察文本翻译中的制约因素,如互联网介导调查法、问卷调查等,从而更好地揭示译者的认知状态、认知能力的过程和认知加工机制[29]。本文通过互联网检索发现,楼武挺的另一译著《我想念我自己》的译者介绍中提到,楼武挺在翻译时倾向于逐字逐句打磨,力求把原文翻译成地道、流畅的中文;同时,用心体会原文作者设置各情节的良苦用心和主人公的喜怒哀乐,力求重现原作的风格和神韵。陶纯翔从翻译转换的视角分析了陈笑黎所译小说的语言风格,发现陈习惯增加一些情态助动词或者保留本该省略的结构以保证其逻辑的清晰连贯,但她对倒装、被动语态等句法结构的处理不够到位[30]。由此可见,译者的翻译观念和翻译风格也是导致译本质量差异之成因。
(三)欧化现象对翻译实践的启示
欧化现象是英汉两种语言接触的必然结果,也是翻译汉语的重要特征。随着不同文化间的交流,欧化翻译已经演变为一种不可避免的现象。因此,译者在翻译时要充分发挥其主体性作用。从本文的数据分析结果来看,陈笑黎、楼武挺和秦传安《心是孤独的猎手》三个汉译本均出现了欧化现象,但各译本的欧化程度却大相径庭。陈译本的平均句长和平均句段长均偏高,被动语态的翻译出现了大量的“被”字结构;楼译本则善用短句,典型欧化结构出现频率较低;秦译本多采用直译法,句子较长,译文晦涩难懂。为了尽量降低译本的欧化程度,本文建议在翻译文学作品时,译者应保持较高的词汇和表达丰富度;控制句长和句段长,按照意群划分句子,化复杂句为简单句,化长句为短句;避免对典型欧化词类、句式结构的直译。译者可以按赵秋荣、孙玉清提出的“自我重译假说”来具体操作,即初译完成后进行自我重译,刻意减少“的”字使用频率和“数量名”结构容量等,以减少源语的长定语透过效应①[31]。实际上,自我重译不仅限于定语的重译,译者要全面考量,打破源语句法型式,摆脱源语思维桎梏,重组信息结构后按目标语习惯表达,从而提高重译本的去欧化程度。
注释:
①翻译汉语因受到源语英语长定语影响而具有的遗留特征:多重定语修饰而使小句变长。
