利用非局部上下文信息的遥感图像小目标检测
2022-12-01李阳阳毛鹤亭张小龙陈彦桥柴兴华
李阳阳,毛鹤亭,张小龙,陈彦桥,柴兴华
(1.西安电子科技大学 人工智能学院,陕西 西安 710071;2.中国电子科技集团公司第五十四研究所 航天信息应用技术重点实验室,河北 石家庄 050081)
遥感图像目标检测作为一个基础且具有挑战性的视觉任务,在军事领域,如准确获取战场信息并对敌方进行精准打击;在民用领域,如土地利用、城市规划、矿产资源勘探等得到了广泛应用[1-2]。遥感图像中普遍存在小目标,但从遥感图像中精确的检测出小目标并不容易。遥感图像中小目标的检测主要面临两大难点:① 目标特征信息少。由于小目标本身在图像中所占的像素较少,且被复杂的背景信息包围,导致网络很难提取小目标的有效特征,进一步影响后续的定位和识别任务。② 目标定位困难。相对于大目标而言,小目标的正样本匹配率低,导致小目标在网络训练时没有太多贡献度,进而影响网络对小目标的检测能力。
基于深度学习的目标检测方法逐渐发展出两个分支:① 追求高精度的二阶段目标检测方法,具有代表性的算法有更快的区域卷积神经网络(Faster Region Convolutional Neural Network,Faster R-CNN)[3]、基于区域的全卷积网络(Region-based Fully Convolutional Network,R-FCN)[4]等;② 追求实时检测的单阶段目标检测方法,具有代表性的算法有一种快速和准确的实时目标检测算法(You Only Look Once,YOLO)[5]、RetinaNet[6]、CornerNet[7]等。对于遥感图像中的大尺寸目标而言,现阶段基于深度学习的目标检测方法已经取得了非常不错的检测效果。然而,这些优秀的目标检测方法在检测小尺寸目标时仍然存在巨大的挑战。由此,一些学者开始关注遥感图像中的小目标检测问题,提出了许多有效的改进模型。改善特征金字塔网络(Refine Feature Pyramid Networks,Refine FPN)[8]解决了特征金字塔网络(Feature Pyramid Networks,FPN)[9]在上采样过程中产生的混叠效应,并通过对构建模块进行改进以及在同一层的输入输出间增加了一个恒等映射,解决了小目标的特征在深层网络中易丢失的问题,提高了光学遥感图像小目标的检测性能。跨层注意力网络(Cross layer Attention Network,CA-Net)[10]设计了一种改进的非局部注意力模块,并将该模块嵌入到二阶段检测网络中,利用目标的上下文信息来辅助辨认小目标。实验结果表明,该网络在检测遥感图像小目标方面表现不错,并且能够很好地处理多尺度目标场景。以上两个网络均是从充分挖掘小目标特征信息的角度出发,网络能够很好地提取特征,但是在定位方面的性能并不算理想,存在重复检测与边界框定位不精准的问题,需要进一步的改进与完善。而在目标检测定位方面,目前常见的目标检测算法,如Faster R-CNN、R-FCN和YOLO等均采用单一交并比(Intersection-over-Union,IoU)阈值进行判断。然而,文献[11]发现单一的IoU阈值不能同时权衡边界框的数量与质量,故提出了一种级联目标检测网络Cascade R-CNN。该网络通过设置逐渐增大的多个IoU阈值来训练一组多阶段的目标检测网络,实验表明在自然图像中能够获得更高质量的预测边界框。
针对上述问题,笔者提出一种基于非局部上下文信息的检测方法,用来改进小目标检测网络中的定位性能。该算法的主干网络提取的特征更加丰富且包含了非局部信息,此外,将级联网络应用到遥感图像中,改善小目标定位框质量,并针对遥感图像小目标特性设计了一个上下文转移模块,为区域生成网络(Region Proposal Network,RPN)生成的每一个感兴趣区域(Region of Interest,RoI)赋予上下文信息,进一步辅助小目标的定位。
1 网络模型结构的设计
众所周知,定位难一直都是遥感图像小目标检测的难点问题之一。之前的一些研究解决了小目标的特征在深层网络中易丢失的问题,但在定位方面的性能并不算理想。笔者对遥感图像小目标检测的检测网络进行了改进,整体结构如图1所示。算法采用Refine FPN和CA-Net的组合结构作为主干网络,用于提取小目标的更强特征信息,采取级联区域卷积神经网络(Cascade Region Convolutional Neural Network,Cascade R-CNN)作为检测网络,用于提高边界框质量。同时,提出了一个上下文转移模块(Context Transfer Module,CTM),将目标的上下文信息传递给对应的感兴趣区域,赋予其上下文感知能力,使其更适用于遥感图像小目标检测问题。
1.1 主干网络
使用的主干网络由Refine FPN和CA-Net组成。Refine FPN是基于特征金字塔网络FRN进行改进的,作用于深度残差网络(deep Residual Network,ResNet)[12]各个阶段最后一个残差块输出的特征激活输出,分别将其表示为C2、C3、C4和C5。在高阶特征图与低阶特征图融合之前,对低阶特征进行的上采样过程中,使用最近邻插值和卷积的组合代替反卷积或简单的插值操作,能够有效减少棋盘效应或混叠效应。此外,为了更好地使用小目标,Refine FPN中对构建模块进行了改进。网络中使用一个1×1的卷积(可以减少通道维度)和一个3×3的卷积来进一步提取低层的详细位置信息,并在两个卷积层之间应用线性整流函数(Rectified Linear Unit,ReLU)来获得非线性表示。然后,通过元素相加将高级语义特征与低级位置特征融合,并通过一个 3×3 卷积和两个 ReLU 层获得融合后的特征图。重复这个过程,直到生成最高分辨率的特征图。最后,会得到一组多尺度特征图,对应每一层的融合特征图,定义为{P2,P3,P4,P5}。图1中P6是P5通过最大池化得到的特征图,它是为了匹配更大尺寸的候选框而引入的,这与FPN的相同。

图1 笔者提出算法整体网络的示意图
为了给像素对的位置关系进行建模,在主干网络中又添加了CA-Net所提出的非局部注意力机制,以及跨层聚合与均衡模块。文献[13] 提出非局部注意力机制可以计算出某个像素点的全局上下文信息,而文献[14]发现对于同一个特征图上的不同查询点,注意力特征图几乎相同。因此,CA-Net网络使用了一个改进的非局部注意力模块,特征图上每个像素点不再单独计算注意力特征图,而是共享同一张注意力特征图,该模块可以在得到全局上下文信息的同时,减轻网络的计算量。又由于注意力模块在各层上捕获的信息会各有侧重,因此使用跨层聚合与均衡模块,先聚合各层的特征信息,而后再均衡分配给各层,使得最终给检测网络提供的特征强且均衡。
1.2 上下文迁移模块
使用Faster R-CNN提出的区域生成网络在图像上生成一组与目标相关的感兴趣区域,然后基于感兴趣区域预测目标的位置。由于使用的网络主干属于金字塔结构类型,所以区域生成网络需要在多层特征图上计算感兴趣区域。区域生成网络计算出感兴趣区域之后,需要根据感兴趣区域的尺寸将其划分到主干网络对应的层级上,计算方式如下所示:

(1)
其中,w和h分别表示RoI的宽和高,k0表示FPN中的P4层,对应感兴趣区域的尺寸为w×h=224,该尺寸为标准的ImageNet[15]预训练尺寸。根据式(1)可知,当感兴趣区域的尺寸变得更小时(如w×h=1122),它将会被分配到更低的一层的特征图上(如P3层)。接着,在对应的特征层上应用感兴趣区域对齐(Region of Interest Align,RoI Align)[16]提取RoI的特征得到区域候选框,送入下一阶段的网络中。
根据式(1)可以看出,小尺寸感兴趣区域会被分配到低层,而大尺寸感兴趣区域会被分配到高层,而每一个感兴趣区域的层级从某种程度上可以代表其所属的上下文环境。基于此,笔者提出了如图2所示的上下文转移模块(Context Transfer Module,CTM)。具体的操作是,对RoI所属层级对应的特征图进行平均池化操作获取上下文信息,与感兴趣区域的局部信息进行元素相加,得到一个拥有上下文感知能力的RoI。

图2 上下文转移模块结构示意图
1.3 级联检测网络
CAI等人提出了一种级联目标检测网络——Cascade R-CNN,其核心思想是通过多阶段级联的检测子网络来不断提高预测边界框的质量。基于其核心思想,设计了适用于小目标检测的级联检测网络,具体结构如图3所示。
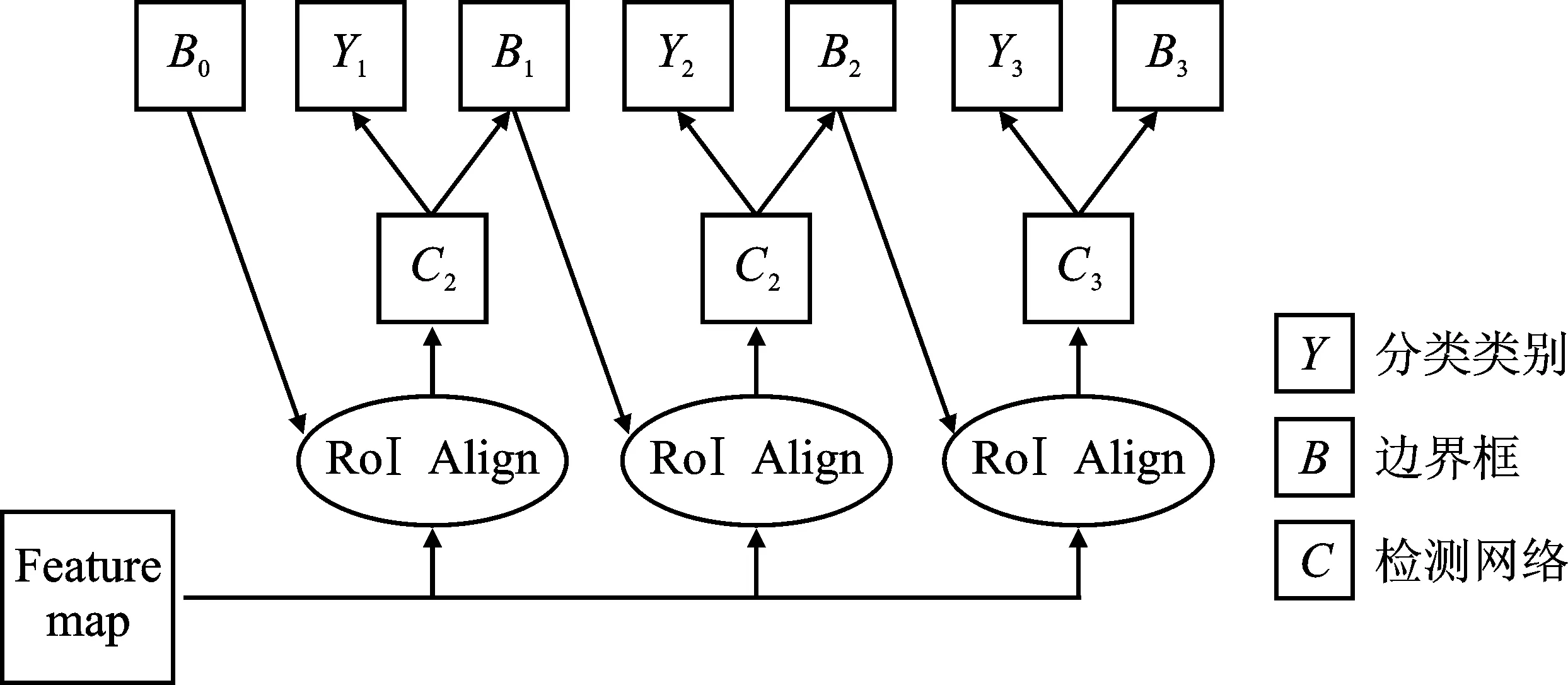
图3 级联检测网络结构示意图
级联检测网络包含3个阶段的检测子网络,每一阶段的检测子网络都旨在寻找一组更好的基准边界框用于训练下一阶段,并且每一个阶段的检测子网络采用的IoU阈值会越来越高,以确保边界框的质量越来越高。在这个过程中,每一阶段预测的边界框于下一阶段的检测子网络而言都是一组感兴趣区域,在送入下一阶段的检测子网络进行预测之前都需要通过感兴趣区域池化(Region of Interest Pooling,RoI Pooling)或者RoI Align 计算出对应的区域候选框。B0表示RPN阶段生成的所有感兴趣区域,每一阶段预测的边界框于下一阶段的检测子网络而言都是一组感兴趣区域。考虑到小目标问题,在送入下一阶段的检测子网络进行预测之前,使用RoI Align提取前一阶段得到的边界框特征,避免RoI Pooling的多次量化过程造成小目标的特征丢失问题。
在Cascade R-CNN中,回归任务被构建为一个级联回归问题,因此定义一个级联回归器:
g(x,b)=gT∘gT-1∘…∘g1(x,b0) ,
(2)
其中,T是级联阶段数目。需要注意的是,每一阶段的回归器gt都是以t-1阶段预测得到的边界框为基准进行优化的,b0则表示区域生成网络阶段生成的所有感兴趣区域,如图3中的B0。
根据前述分析可做一个假设。假设经过逐阶段的训练之后,检测质量得到了改善,那么最后一阶段的检测器质量是最佳的,因此Cascade R-CNN的整体损失函数可以定义如下:
L(xt,l)=Lcls(ct(xt),yt)+λ[yt≥1]Lreg(gt(xt,bt),l) ,
(3)
其中,bt=gt-1(xt-1,bt-1),表示t阶段得到的边界框,l是对应的标签框。Lcls(·)是Cascade R-CNN的分类损失函数,可以由下式计算:
Lcls(c(x),y)=-∑c(x)logy,
(4)
其中,c(x)表示分类器,y表示预测框x的类别,其定义为
(5)
其中,ly表示标签框l的类别,u表示预先设定的IoU阈值。
上式中的λ和Lreg(·)分别表示平衡参数和网络定位损失,其中l的值为1。Lreg(·)计算公式如下:
(6)
其中,t和t*分别表示目标的预测边界框与候选框之间的偏移量和标签边界框与候选框之间的偏移量。
2 实验结果及分析
文中使用的硬件环境是一张Intel Core i7-7800X CPU与一张NVIDIA GeForce RTX 2080 Ti GPU,基于Ubuntu18.04作为实验平台,编程使用Python 3.6编程语言,PyTorch 1.0.0深度学习框架,Cuda 10.0环境。实验使用的数据集是Small-DOTA数据集、DIOR数据集和OHD-SJTU-S数据集。对实验结果分析时,采用定量评价指标平均精度(Average Precision,AP)和平均精度均值(mean Average Precision,mAP)对算法性能做定量分析,并展示算法的最终检测结果图以做定性分析。
DOTA数据集[17]是一个大型的、公开的用于遥感图像目标检测任务的数据集。DOTA 1.5版本是一个更新版本,与DOTA 1.0相比包含更多小目标,总共有涵盖16个类别的400 000个目标实例。所以从DOTA 1.5中选择了小目标占比较高的类别,组成了Small-DOTA数据集,专门用于遥感图像小目标检测。Small-DOTA数据集总共包含1 508幅遥感图像和227 656个目标实例,图像尺寸从800×800到4 000×4 000像素不等,囊括的4个类别有小型车辆、船、储油罐和大型车辆。在实验中,采用Small-DOTA数据集中的1 157幅图像用于训练、351幅图像用于测试。此外,考虑到图像尺寸过大,使用大小为1 024×1 024、重叠为200个像素的滑动窗口将Small-DOTA数据集的每幅图像裁剪为尺寸大小为1 024×1 024,尺寸不足则进行补0处理,处理后将其送入网络模型中用于训练和预测。
DIOR[18]是一个大型的用于评估遥感领域目标检测的公开数据集,包括23 463个图像和190 288个目标,总共有20个目标类别:棒球场、飞机、篮球场、火车站、高速公路服务区、风车、快递收费站、立交桥、船舶、港口、高尔夫球场、桥梁、地面场地、烟囱、大坝、储罐、体育场、网球场、机场和车辆。DIOR数据集中使用水平边界框标记,图像的大小为800×800像素,“Google地球”是DIOR数据集的数据来源。在实验中,使用11 725幅图像用于训练,11 738幅图像用于测试。
OHD-SJTU-S数据集[19]是杨学团队新开源的用于遥感图像目标检测的大型场景图像数据集。该数据集图像同样来源于“Google 地球”,图像尺寸大小为10 000×10 000像素和16 000×16 000像素,共有43幅图像,包含飞机和船这两个类别。对OHD-SJTU-S数据集做了两个预处理工作:① 由于OHD-SJTU-S数据集使用任意四边形标注目标实例,将每个目标实例的原始任意四边形标签转化为水平边界框标签;② 在送入模型训练或者测试之前,使用窗口大小为600×600、重叠为200像素的滑动窗口将OHD-SJTU-S数据集中的所有图像裁剪为600×600像素的小图。
考虑到数据集的规模,在Small-DOTA数据集和DIOR数据集上使用101层的ResNet、Refine FPN和CA-Net作为主干网络用于提取图像特征,而在OHD-SJTU-S数据集上使用的主干网络则是50层的ResNet、Refine FPN和CA-Net。鉴于文中所提算法属于基于候选框的算法,需要事先设置候选框的尺寸,具体尺寸为{322,642,1282,2562,5122},分别对应FPN的5层特征图,每层上设置的候选框比例为{1∶1,1∶2,2∶1}。在模型训练阶段,采用随机梯度下降算法训练网络模型,训练图像的批大小设置为2,动量设置为0.9,权值衰减设置为0.000 1,学习率设置为0.002 5,并且在前500轮的时候使用预热策略对学习率进行了预热操作。模型总共需要训练12代,并且在第8代和第11代的时候,学习率会衰减到0.000 25和0.000 03。文中所提算法总共包括3个检测阶段,每个检测阶段设置的IoU阈值分别为0.5,0.6和0.7,以逐步优化边界框的质量。另外,每个检测网络的损失权重分别设置为1.00,0.50和0.25。
采用AP和mAP这两个评价指标来评估模型的检测性能,对比算法有Faster R-CNN、FPN、Refine FPN、Cascade R-CNN以及CA-Net*。其中CA-Net*是Refine FPN与提出的CA-Net的组合结构,没有上下文转移模块和级联检测网络,即,仅使用文中主干网络的算法。通过与CA-Net*比较,能够进一步说明文中提出的两个改进模块的有效性。各种算法在Small-DOTA、OHD-SJTU-S和DIOR数据集上的检测结果分别如表1至表3所示。
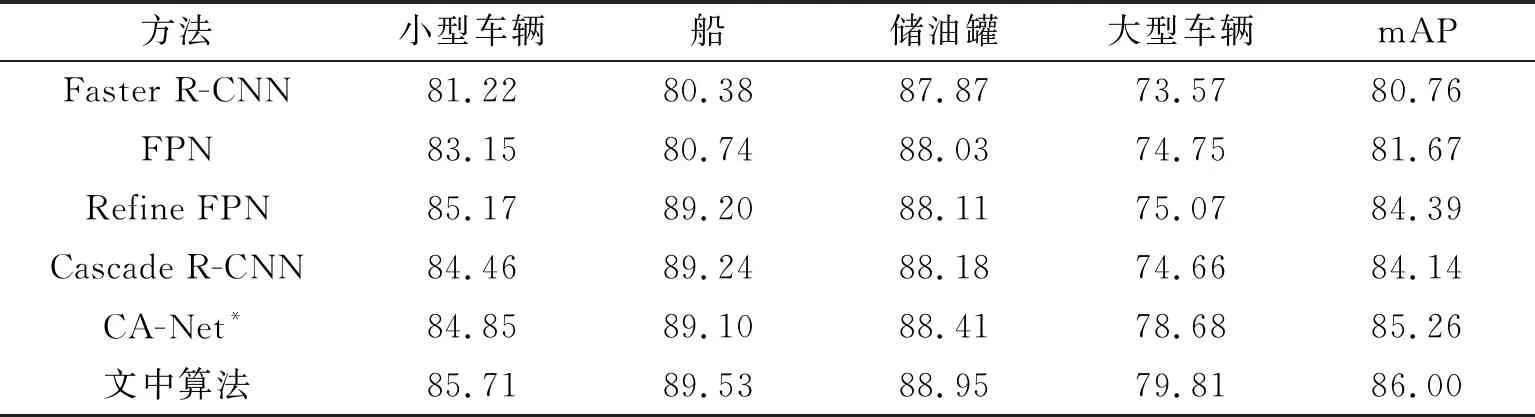
表1 不同方法在Small-DOTA数据集上的实验结果 %

表2 不同方法在OHD-SJTU-S数据集上的实验结果 %

表3 不同方法在DIOR数据集上的实验结果 %
根据表1、表2和表3的实验结果可知,笔者提出的算法在3个数据集上都取得了最佳成绩,其mAP与对比方法相比达到了最高。值得注意的是,相比于Refine FPN和CA-Net*,笔者提出的算法在3个数据集上都有不同程度的提升。而且在DIOR数据集中小目标比较多的船、车辆和风车这3个类别上,笔者提出算法的AP也达到了最高,这说明了笔者提出方法的有效性,表明文中算法确实能进一步改善遥感图像小目标检测性能。
为了更好地展示笔者提出的检测方法对遥感图像中小目标定位的性能提升,将文中方法、Refine FPN和CA-Net*在DIOR数据集上的检测结果进行了可视化。如图4所示,其中图4 (a) 为Refine FPN的检测结果,图4 (b) 为CA-Net*的检测结果,图4 (c) 为文中算法的检测结果。3个算法中使用了相同IoU阈值下的非极大值抑制操作。可以看出,在图4 (a) 和图4 (b) 中均出现了近似假阳性边界框问题,由曲线标注。这些近似假阳性样本无法精准地表示小目标的位置,形成了噪声检测框,而在文中算法的检测结果中,近似假阳性边界框的问题并未出现。由此可见,笔者提出的算法具有较强的对抗近似假阳性样本的能力,并且能够有效提升遥感图像小目标的预测边界框质量。

(a) Refine FPN检测结果
3 结束语
笔者主要研究了遥感图像小目标检测难的问题,在现有算法的基础上进行改进,提出了一种基于非局部上下文信息的遥感图像小目标检测方法。实验使用了Small-DOTA、DIOR和OHD-SJTU-S遥感图像数据集。其中Small-DOTA数据是由DOTA 1.5中小目标较多的4个类别组成,能够评估模型应对密集小目标场景的能力。从定量角度分析,所提方法在3个数据集上的平均精度均值都高于其他方法;从定性角度分析,所提方法相比其他方法,检测结果中的近似假阳性检测框更少,获得了高质量的小目标预测边界框。
但是,笔者提出的方法仍然存在改进空间。在今后的研究中,可以尝试模型轻量化操作,进一步缩减模型的规模和计算量,便于工程应用和轻量级硬件(如无人机)的部署。
