基于相机拍照的油茶果形状特征提取研究
2022-11-30尹显明严恩萍蒋佳敏彭邵锋莫登奎
棘 玉,尹显明,严恩萍,蒋佳敏,彭邵锋,莫登奎*
(1.林业遥感大数据与生态安全湖南省重点实验室;国家林业和草原局南方森林资源管理与监测重点实验室;中南林业科技大学林学院,湖南 长沙 410004;2.湖南省林业科学院,湖南 长沙 410004)
油茶(Camelliaoleifera)产业作为我国湖南、广西、江西等南方地区农村经济的支柱和特色产业对推动农业经济的发展有重要作用[1-2]。特别是近年来在各级政府的大力扶持下,油茶种植面积不断扩大[3],因此,快速准确地获取油茶果形状特征信息,对掌握油茶果大小分布情况,指导果实分级和快速测产有重要意义。
目前,国内外学者对农林业果实、种子的形状特征提取主要基于图像检测[4-7]和高光谱检测[8-9]。图像检测用时短且成本低,更能满足实际需求。在利用图像检测方面,通常采用OTSU算法[10]、支持向量机[11]、人工神经网络[12-16]或多种算法相结合[17-18]对图像进行分割,然后基于Hu不变矩[19]、傅里叶描述子[20-22]、凸壳理论[23]、Hough变换[24-25]等方法提取目标果实的面积、周长等形状特征参数。然而上述研究均集中于采摘机器视觉和果实智能分选领域,其研究对象主要是自然条件相机拍摄树上局部果实或采摘后单个果实,对形状特征参数的描述大多是基于目标区域内像素点的数目、位置及比值,对果实特别是油茶果的长轴、短轴、面积、周长等形状特征批量获取的方法鲜有报道,若想得到果实长短轴等参数的实际值仍需要借助传统的人工测量,不仅耗时耗力、重复性差,还易出现人为测量和记录错误。
本研究基于油茶果智能识别技术提出利用相机拍摄采摘油茶果的方法实现对果实快速计数以及长短轴、周长、面积等特征参数的批量化提取,以期直观、快速、准确地获取大量油茶果尺寸信息,为指导油茶果实分级和快速测产提供科学依据。
1 材料与方法
1.1 数据采集及预处理
数据采集区域位于新邵县陈家坊镇江村华怡油茶种植标准化示范基地,通过随机抽样选择120棵油茶样本树,于2020年10月27日到10月28日,将采摘后的样本树油茶果随机摆放于含110 cm×110 cm刻度尺的水平放置背景板,且果与果之间不相互堆叠。自然光照条件下,从2 m附近垂直拍摄油茶果样本,每棵油茶样本树拍摄3~5张,共拍摄图像657张。研究采用哈苏L1D-20c相机,分辨率为3 648×5 472像素,图像格式为JPEG。
为消除相机拍照产生的几何畸变问题,采用ArcGIS10.7软件的配准工具,结合背景板中的校准格网对影像数据进行校准。对校准后的油茶果照片进行筛选,剔除模糊重复等无效数据,最后保留312张图片。利用开源计算机视觉库OpenCV对图像进行处理,将3 648×5 472像素的原图裁剪为大小为2 975×2 071像素的油茶果图像。
1.2 研究方法
1.2.1 数据集制作
为满足不同环境油茶果实识别的多样性,随机抽选不同数目、颜色、光照条件、摆放疏密度的油茶果图片样本26张,使用Label me标注软件进行数据标注,以人工目视为主,检验修正为辅,共标注2 874个油茶果实目标。为防止训练出现过拟合以及抵消外部光照等环境因素影响,对样本进行旋转、翻转等操作增强数据集,最终处理完成后得到420幅数据集样本。将数据集按照4∶1的比例随机划分,其中336幅图像作为训练集,另外84幅图像作为测试集。
1.2.2 特征识别网络
为对图像中油茶果进行像素级分割,采用由Facebook提出的Mask R-CNN[26]模型作为油茶果实检测识别的基础网络框架(图1),该模型在Faster R-CNN基础之上增加了图像分割分支并能够将结果以掩膜(mask)形式输出,可同时实现目标识别和实例分割且准确率较高,此外该模型使用感兴趣区域对齐(ROI Align)替换感兴趣区域池化(ROI pooling),利用双线性插值法解决了特征图(feature map)与原像素对准的精度问题,满足本研究高复杂度及多任务的需求。

图1 Mask R-CNN油茶果识别模型网络结构示意图Fig.1 A network structure diagram of the Mask R-CNN recognition model for Camellia oleifera fruits
研究将ResNet50与FPN相结合的网络作为油茶果特征提取的主干网络,得到对应的特征图,将其输入至区域候选网络(RPN)进行二值分类,使图像分为油茶果与背景,并对含油茶果的区域进行框选生成感兴趣区域(ROI)。将ROI输入基于双线性差值的ROI Align层得到固定大小的特征图,接着将其输入由全卷积网络(FCN)构成的分割掩膜(mask)生成网络得到与目标油茶果形状大小相同的掩码用于分割目标油茶果,并通过兴趣区域分类器和边框回归对ROI区域进行像素级的坐标对齐准确识别目标油茶果。最终得到包含目标油茶果提取结果以及与目标油茶果形状大小相同的mask图像。
本研究试验环境为Intel i7 6700k的CPU,6 GB GPU,运行内存为24 GB;软件环境为Google Colab,在此基础上搭建Pytorch1.4 深度学习框架,并用Python语言编程实现网络模型训练和测试。训练的参数设置为:迭代次数设置为15 000次,初始学习率为0.004,每次迭代训练图像的数量(batch size)为2,迭代8 000次后学习率下降为10%,迭代10 000次学习率下降为0.1%。
1.2.3 特征参数提取
本研究的油茶果形状特征参数为短轴长、长轴长、周长、面积(图2)。首先对利用Mask R-CNN识别模型生成的油茶果mask二值图采用腐蚀膨胀的形态学操作进行处理,去除图片噪声;然后采用开源计算机视觉库OpenCV提供的函数CV2,对油茶果mask图像进行Canny边缘检测提取油茶果边缘特征,采用基于最小二乘法的椭圆拟合算法[27],计算油茶果长轴和短轴对应的像元个数(图3);根据图像背景板中刻度尺计算像元大小,获取每个椭圆形的长轴长、短轴长、周长和面积,即为对应的油茶果形状特征参数。其中椭圆的面积、周长计算公式[28]如下所示:
S=π·ab;
(1)
(2)
式中:S为椭圆面积;L为椭圆周长;a为短半轴长;b为长半轴长。

图2 油茶果形状特征参数Fig.2 Shape feature parameters of Camellia oleifera fruit

A.原始图像original image;B.掩码图像mask image;C.椭圆拟合fitting ellipse;D-F.A、B、C中局部放大图partial enlarged image。图3 油茶果椭圆拟合过程Fig.3 Elliptic fitting processes of Camellia oleifera fruits
1.3 评价指标
1.3.1 模型性能评价
为对油茶果识别模型性能进行评价,选择召回率、准确率、测度以及平均精度作为模型预测性能的评价指标,各指标计算公式如下:
(3)
(4)
(5)

(6)
式中:p为准确率;r为召回率;F1为测度;TP为正确检测的样本数量;FP为错误检测的样本数量;FN为漏检样本数量;IAP为平均精度。
1.3.2 提取精度评价
为验证该方法对油茶果形状特征参数提取的准确率,随机抽取300个油茶果按照同样方法进行拍摄获取油茶果影像数据,并使用分辨率为0.01 mm的电子游标卡尺测得每个果实的长轴、短轴实际长度值;利用Label me软件标注出图像中所有果实,对生成的json文件进行批量转换得到油茶果mask二值图,并统计每个mask像元个数,结合图像中背景板刻度尺计算对应mask像元大小进而得到每个油茶果的周长和面积。用上述方法测得的特征参数作为实测值与经椭圆拟合法得到的特征参数估测值进行比对。采用实际值与估测值间的决定系数(R2)、平均绝对误差[MAE,式中记为σ(MAE)]和均方根误差[RMSE,式中记为σ(RMSE)]3个指标来评价油茶果形状特征参数提取的精度。R2越大,MAE及RMSE越小,则说明特征参数提取精度越高,各评价指标公式[29]如下:
(7)
(8)
(9)

1.4 数据分析
利用Python语言编程和IBM SPSS Statistics 26软件完成油茶果特征参数提取结果的数据分析及预处理。
2 结果与分析
2.1 油茶果识别结果及精度分析
利用经训练得到的油茶果识别模型对油茶果测试集进行测试,得到油茶果平均精度(IAP)为99.59%。该模型检测油茶果准确率为99.55%,正确检测出120棵油茶果树上的共17 783个油茶果,漏检1 716个,漏检率为8.80%,召回率为91.19%,测度(F1)为95.22%;模型共误判油茶果79个,原因是模型将图片中背景板上一些枝叶、油茶籽等杂物误判为油茶果。总体上,模型识别油茶果准确率为99.55%,总体精度95.22%,说明本研究网络模型性能良好,总体识别精度较高,未出现将阴影识别为油茶果的现象,可满足后续油茶果特征参数提取的精度要求。
油茶果模型训练过程中损失值随迭代次数变化的曲线如图4所示。模型迭代次数为15 000次,当迭代12 000次左右,损失值逐渐趋于稳定,最终损失值保持在0.13左右。

图4 Mask R-CNN训练时损失值曲线Fig.4 Loss curve of Mask R-CNN training
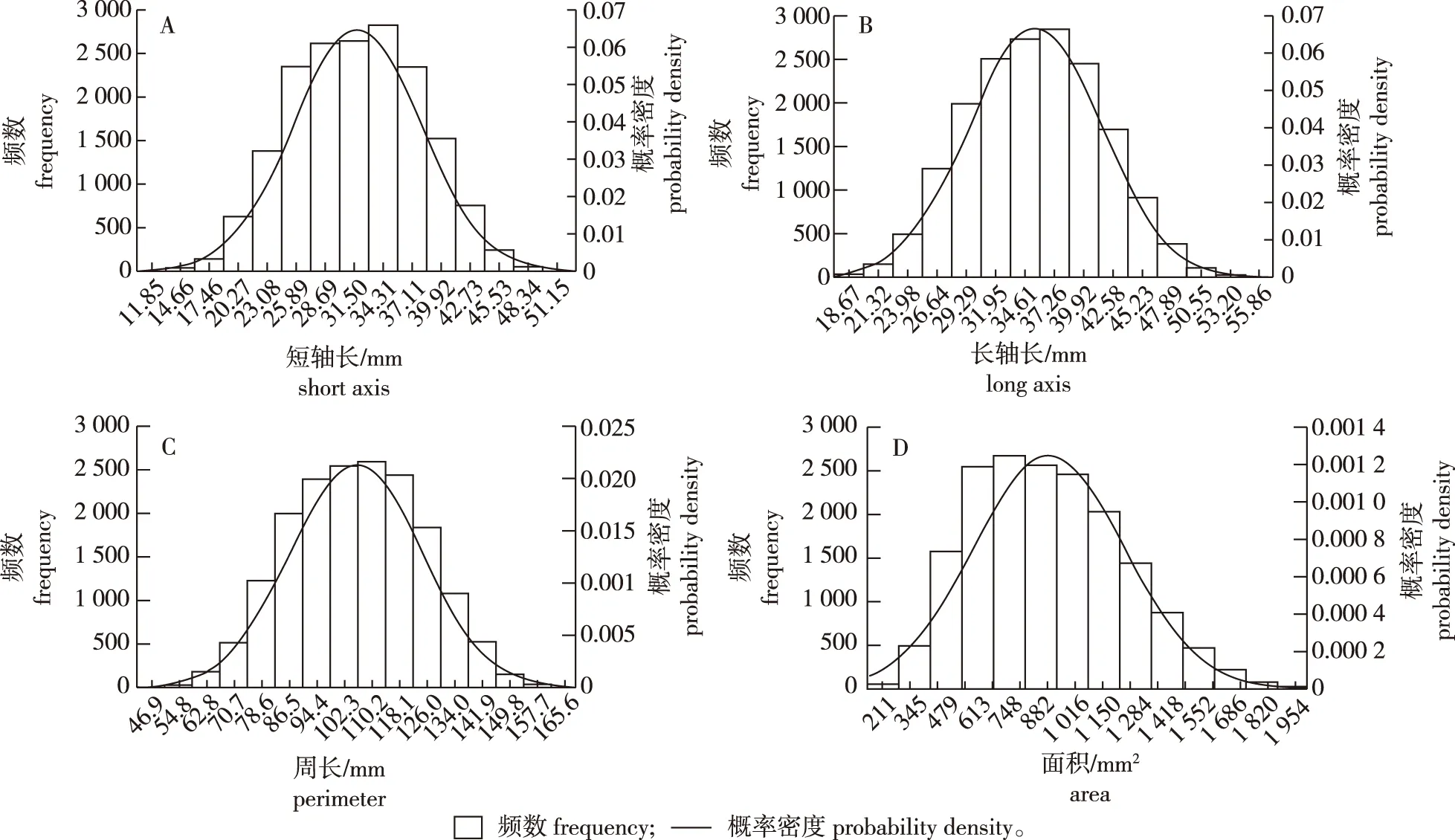
图5 油茶果形状特征分布频数Fig.5 Frequency distribution of quantitative traits parameter of Camellia oleifera fruit
2.2 油茶果形状特征参数提取结果
2.2.1 油茶果形状特征参数变异情况
结合油茶果识别模型检测出的油茶果提取其形状特征参数并进行统计分析。可知,油茶果实形状特征参数的变异范围为16.84%~34.87%,其中,面积变异程度最大(34.87%),其次为短轴长变异幅度(19.41%)和周长变异幅度(17.69%),长轴长变异程度最小(16.84%)(表1)。

表1 油茶果形状特征参数变异Table 1 Variation of morphological feature parameter among Camellia oleifera fruits
2.2.2 油茶果实形状特征参数的频率分布及正态性检验
根据得到的油茶果形状特征参数绘制果实形状特征参数频率分布图(图5),对4个特征参数进行单个样本的Kolmogorov-Smirnov 正态性检验,长轴长、短轴长、面积、周长4个性状指标的Sig值均大于0.05,符合正态分布,计算各形状特征参数概率密度函数。概率密度函数[f(X)]计算公式[30]如下所示:
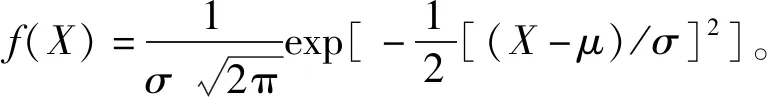
(10)
式中:σ为标准差,X为随机变量,μ为期望值。
在该研究区内油茶果短轴长平均值为31.80 mm,标准差为6.17 mm,变异幅度为10.45~58.17 mm,变异系数为19.41%,概率密度函数为f(X)=0.418 5exp[-0.013 1(X-31.79)2];长轴长平均值35.55 mm,标准差5.99 mm,变异幅度为14.68~70.47 mm,变异系数为16.84%,概率密度函数为f(X)=0.406 3exp[-0.013 9(X-35.55)2];周长平均值105.90 mm,标准差18.72 mm,变异幅度42.98~139.29 mm,变异系数17.69%,概率密度函数f(X)=0.1 339 exp[-0.001 4(X-105.90)2];面积平均值914.58 mm2,标准差318.95 mm,变异幅度1 44.12~2 960.25 mm2,变异系数34.87%,概率密度函数f(X)=0.007 9 exp[-4.915 0×10-6(X-105.90)2]。
2.3 油茶果特征参数提取精度分析
将随机抽取的300个油茶果特征参数实测值作为自变量,将经拟合椭圆法得到的特征参数估测值作为因变量绘制相关性散点图(图6),通过一元线性回归分析对提取结果进行精度评价。可以看出,采用椭圆拟合法估测油茶果形状特征参数时,对面积的提取精度最高(图6D),R2达到0.999 0,MAE为10.75 mm2,RMSE为14.88 mm2;对油茶果短轴长提取的精度最低(图6A),其R2为0.864 7,MAE为3.15 mm,RMSE为3.74 mm;对油茶果周长估测结果的MAE和RMSE最大,分别为22.81 mm、23.36 mm。利用椭圆法拟合估测油茶果长轴和短轴长存在高估现象(图6A、6B),可能是由于油茶果边缘存在噪声或受油茶果不同摆放角度影响使得对长轴和短轴长过高估测;对周长估测时存在低估现象(图6C),可能是由于油茶果边缘果壳裂开,边缘凹凸不平导致实际周长要大于拟合的椭圆形周长。此外,人工测量和校准以及周长、面积计算公式的选择等因素均可能对油茶果形状特征参数估算结果的鲁棒性、精度产生影响。
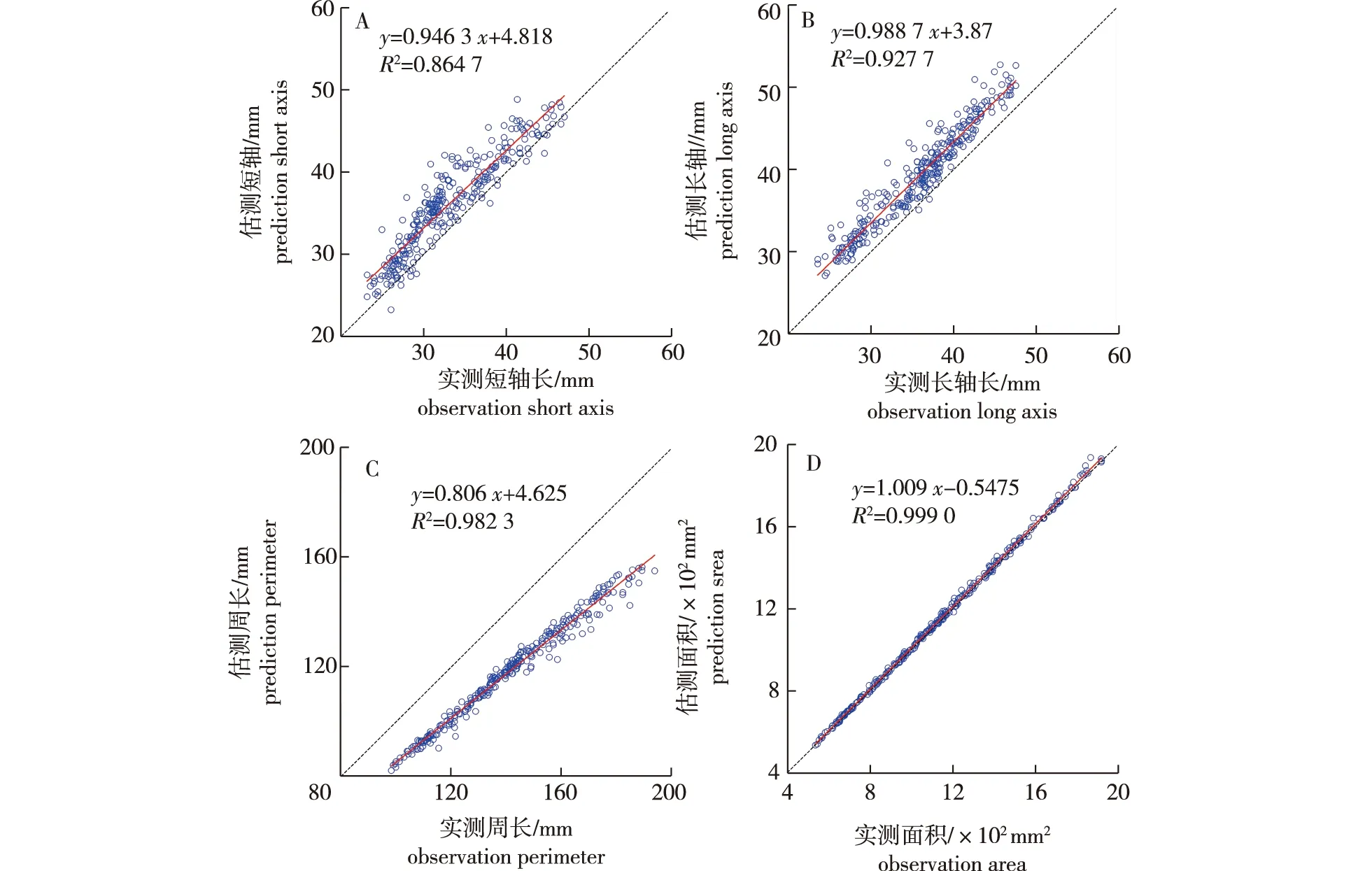
图6 油茶果形状特征参数估测值与实测值相关性散点图Fig.6 A scatter map of the correlation between prediction values and observation values of Camellia oleifera fruit morphological feature parameters
3 讨 论
3.1 油茶果特征识别的影响因素
已有研究表明,光照条件、遮挡重叠、背景相似以及表面阴影等因素会给油茶果图像的准确识别带来一定困难[7,23,25,31]。由于本研究对象为采摘后的油茶果,因此不涉及果实重叠、叶片遮挡方面的问题,但是背景相似、果实颜色和表面阴影方面的影响不能忽视。本研究采用的Mask R-CNN网络包含全卷积神经网络FCN分支,能够通过大量油茶果特征的标注和训练,减少表面阴影和背景相似等因素的影响,这与相关学者采用CNN网络检测苹果的研究结论相似[32];其次,本研究通过对油茶果样本进行缩放、旋转和翻转等数据扩增操作,结果表明适当的数据扩增操作,能够减少外界因素对油茶果识别的影响,提高油茶果特征提取的精度,这与有关学者采用数据扩增缓解模型过拟合的研究结论相似[33]。
现有的油茶果检测研究均集中于单株油茶树的局部果实识别,拍摄仪器多采用尼康D5200数码相机,分辨率为1 000~2 000像素[7,17,23],单果的最快识别时间为0.491 s。本研究油茶果数据的采集设备为哈苏L1D-20c相机,分辨率为3 648×5 472像素,能够满足基于Mask R-CNN的油茶果识别,实验表明本研究油茶果的识别准确率达99.55%,单果识别速度为0.45 s,具有用于实际生产中对果实快速准确批量提取的潜力。随着研究的持续开展,后续将围绕缩短油茶果相机拍照以及图像裁剪、标注、转换等前期处理时间进行深入研究,以期进一步优化油茶果自动检测的效率。
3.2 油茶果特征提取的精度
对本研究油茶果特征参数提取结果进行分析发现均符合正态分布,与陈永忠等[34]通过人工测量油茶果实得到的特征参数分布情况相一致,说明利用该方法提取参数无异常值。虽然本研究对油茶果面积估测精度高达0.999 0,但是对短轴估测精度不高,仅为0.864 7,可能有两方面原因:首先油茶果的随机摆放使得相机在垂直方向无法拍摄到最小直径;其次采用椭圆拟合方法获取的果实短轴略大于油茶果实际短轴。由此看出仅从单一角度拍摄油茶果提取特征参数具有片面性,另外人工图像校准方式也会对参数估算结果的鲁棒性、精度产生影响。同时考虑到果实是一种三维物体,为更精确地按尺寸对油茶果进行分级,必须考虑油茶果的高度信息[35],因此结合多视角拍摄图像进行三维建模[36],提取油茶果高度信息将是下一步的研究重点。
